【2026年初旬版】G検定はどの分野からどのくらい出る?受験者目線で割合を整理してみた
seo-webmaster
G検定対策ブログ

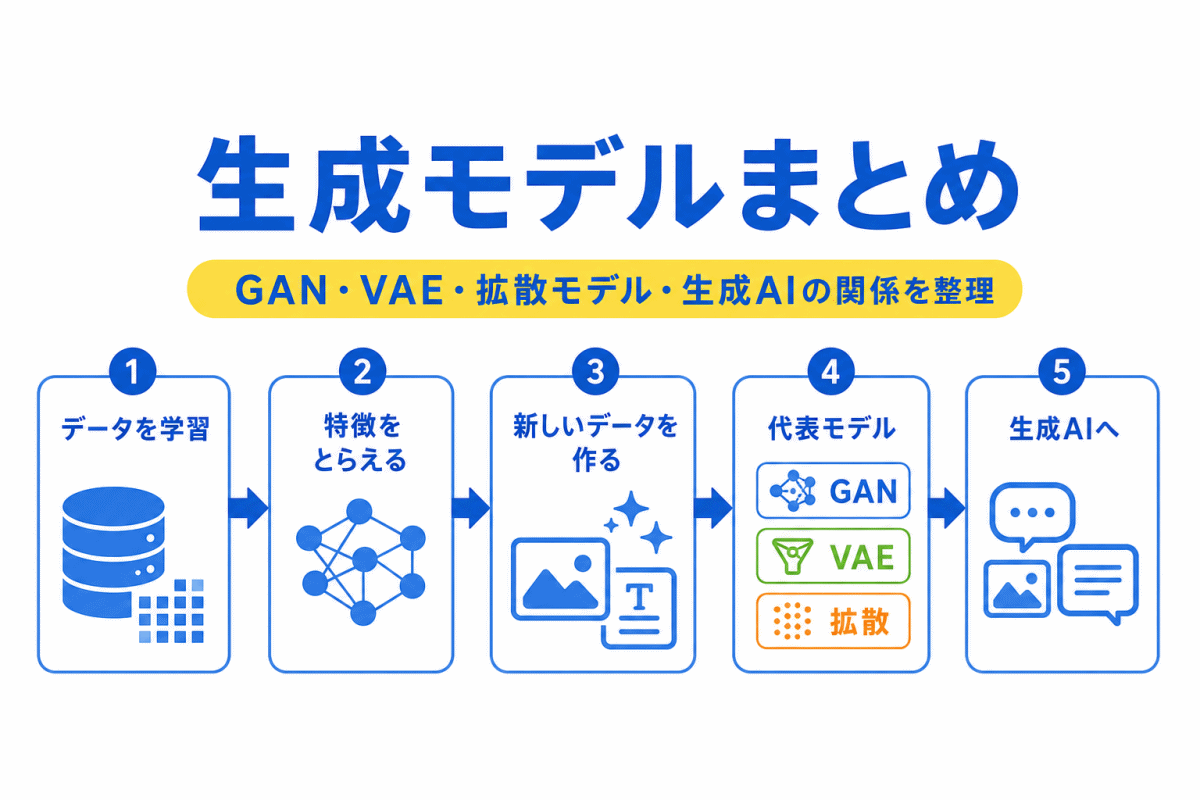
G検定の学習では、AI・機械学習・ディープラーニング・生成AI・AI倫理など、たくさんの用語が登場します。
ひとつずつ覚えようとすると、似た言葉が多く、どこが違うのか分からなくなりやすいです。
特に、事前学習・転移学習・ファインチューニング、適合率・再現率、損失関数・評価指標のような用語は、言葉だけを暗記しても混同しやすい部分です。
この記事では、AIの学習をはじめたばかりの人向けに、G検定で覚えておきたいAI用語を分野別に整理します。
意味だけでなく、似ている用語との違いや見分け方もあわせて確認することで、点ではなく流れで理解できるようにしていきます。
記事内の用語がリンクになっている場合、サイト内の詳細記事へのリンクです。詳細が見たい方はリンクをクリックしてください。
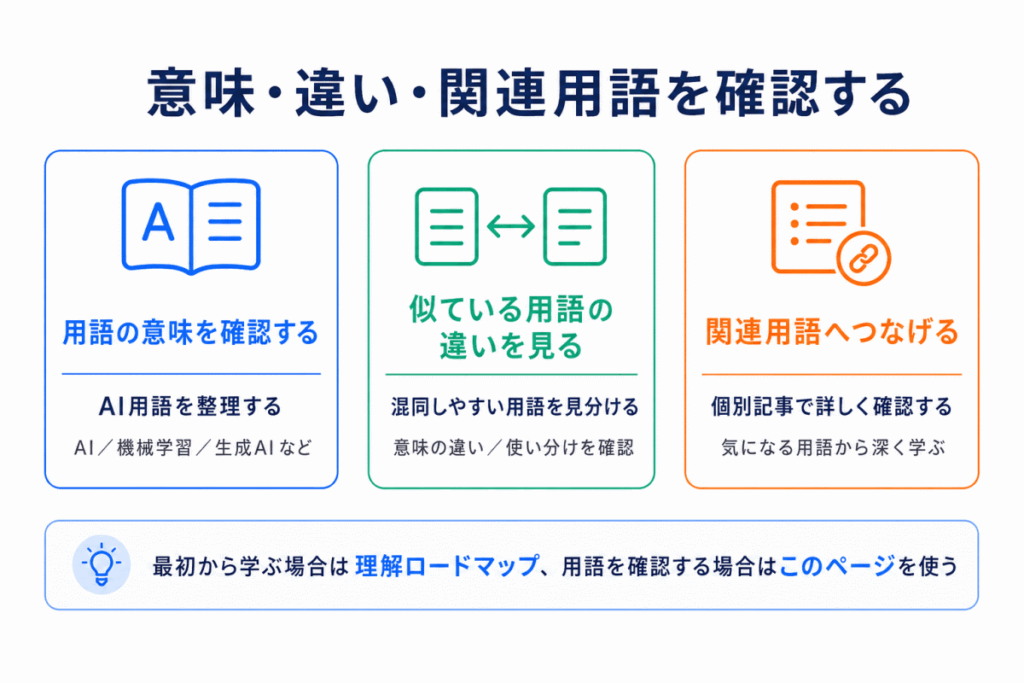
このページは、G検定でよく出てくるAI用語を、意味、違い、関連用語とあわせて確認するための一覧ページです。
最初から順番に学びたい場合は理解ロードマップを使い、用語の意味を確認したい場合や、似ている用語の違いを整理したい場合はこのページを使うと便利です。
| 使い方 | 見る場所 | 確認する内容 |
|---|---|---|
| 用語の意味を確認したい | 各分野の用語表 | AI/機械学習/ディープラーニング/生成AI/AI倫理 |
| 似ている用語を整理したい | 混同しやすい用語まとめ | 適合率と再現率/損失関数と評価指標/RAGとファインチューニング |
| 詳しく学びたい | 用語表内のリンク | 個別解説記事/関連用語/具体例 |
| 試験前に確認したい | チェックシート・予想問題 | 重要用語/見分け方/問題形式での確認 |
どの記事から読めばよいか迷う場合は、まず理解ロードマップで学習順を確認してから、この用語一覧で意味や違いを整理すると進めやすいです。
G検定の8分野ごとの用語まとめ、記事一覧まとめもおすすめです。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 理解ロードマップ | 学習順/8分野別の入口/重要用語/チェックシート/理解型予想問題 |
| 重要用語まとめ8分野 | G検定の8分野別にした用語まとめ |
| G検定整理記事を8分野で分類 | G検定の8分野別に記事の一覧 |
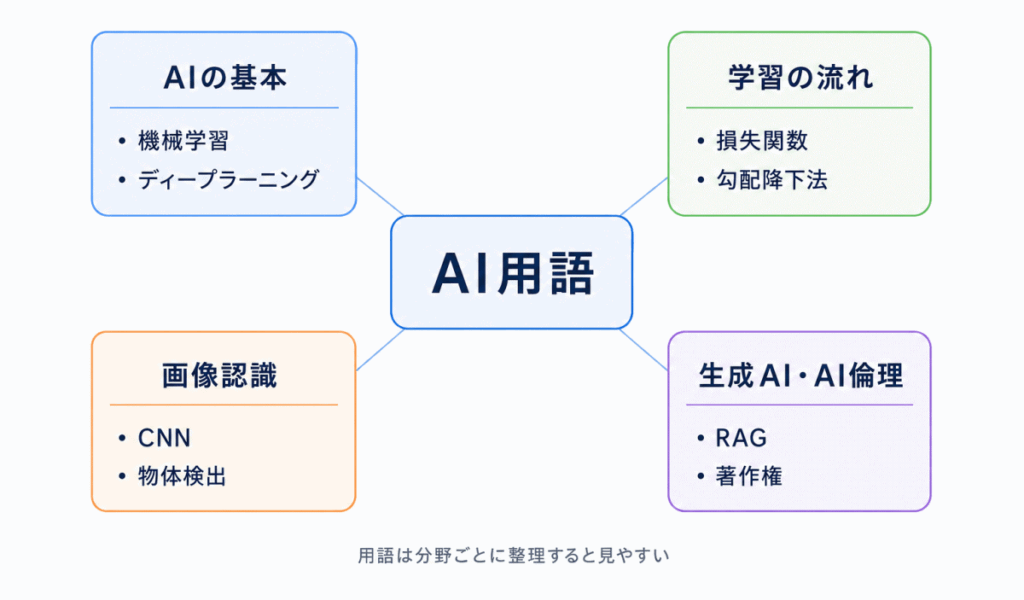
G検定の用語は、バラバラに覚えるよりも、分野ごとに分けて見ると整理しやすくなります。
| 分野 | 主な用語 |
|---|---|
| AIの基本 | AI 、機械学習、ディープラーニング、教師あり学習、教師なし学習、強化学習 |
| AIの学習 | 損失関数、勾配降下法、学習率、SGD 、ミニバッチ 、Adam |
| 過学習対策 | 過学習、汎化(※1)、正則化 、ドロップアウト 、交差検証、データ拡張 |
| 評価指標 | 精度、適合率、再現率、F1値(※2) |
| 画像認識 | CNN 、画像分類 、物体検出 、セグメンテーション 、転移学習 |
| 自然言語処理 | トークン、単語埋め込み、Seq2Seq、Attention、Transformer |
| 生成AI | LLM、GPT、BERT、事前学習、ファインチューニング、RAG 、RLHF、アライメント |
| AI倫理・法律 | ハルシネーション、著作権、個人情報保護、アルゴリズムバイアス、説明可能AI(XAI)、AIガバナンス、ディープフェイク |
※1:未知のデータに対応できること
※2:適合率と再現率のバランス
用語を覚えるときは「どの分野の言葉なのか」を先に確認すると、混同しにくくなります。
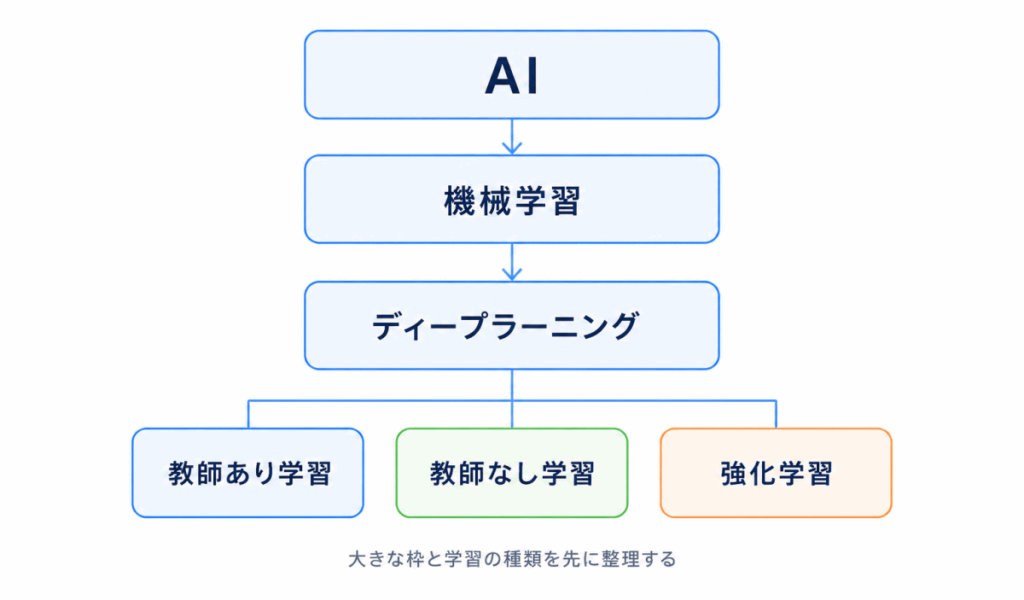
AIの基本用語は、G検定の土台になります。ここを曖昧にしたまま進むと、あとでディープラーニングや生成AIの用語が分かりにくくなります。
| 用語 | 一言でいうと | 関連用語 |
|---|---|---|
| AI | 人間の知的な働きをコンピュータで実現しようとする技術 | 機械学習、ディープラーニング |
| 機械学習 | データからパターンを学ぶ方法 | 教師あり学習、教師なし学習、強化学習 |
| ディープラーニング | ニューラルネットワークを深くした機械学習の方法 | CNN、RNN、Transformer |
| 教師あり学習 | 正解データを使って学習する方法 | 分類、回帰 |
| 教師なし学習 | 正解データなしでデータの構造を見つける方法 | クラスタリング、次元削減 |
| 強化学習 | 行動と報酬をもとに学習する方法 | エージェント、報酬 |
AI・機械学習・ディープラーニングは、同じ意味ではありません。
大きな枠としてAIがあり、その中に機械学習があり、さらにその中にディープラーニングがあります。
AIの基本用語を確認したあとは、AIの定義や歴史、知識表現、探索・推論の流れもあわせて整理しておくと理解しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 人工知能 | AIの定義/強いAI/弱いAI |
| AIブームの歴史 | 第一次AIブーム/第二次AIブーム/第三次AIブーム |
| 知識表現 | 知識をAIで扱う考え方/ルール/関係性 |
| エキスパートシステム | 専門家の知識/ルールベース/第二次AIブーム |
| 探索・推論 | 探索/推論/答えを導く流れ |
| AIの限界と議論 | フレーム問題/シンボルグラウンディング問題/中国語の部屋 |
教師あり学習、教師なし学習、推薦システムで使われる代表的な手法を整理します。
G検定では、どの学習方法に含まれるのか、どのような考え方で判断するのかを押さえることが大切です。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| SVM | 境界線とマージンでデータを分ける分類手法 | マージン最大化 |
| 決定木 | 条件分岐を使って判断する手法 | 木構造の判断 |
| ランダムフォレスト | 複数の決定木を組み合わせて予測を安定させる手法 | 複数の木 |
| k-means法 | 似たデータを代表点に近いグループへ分ける手法 | クラスタ中心 |
| クラスタリング | 正解ラベルなしで似たデータをグループに分ける方法 | 似たもの同士 |
| レコメンデーション | ユーザーに合う商品やコンテンツを推薦する仕組み | おすすめの提示 |
| 協調フィルタリング | 似たユーザーや行動の関係をもとに推薦する方法 | 行動の類似 |
| コンテンツベースフィルタリング | 商品やコンテンツの特徴をもとに推薦する方法 | 中身の特徴 |
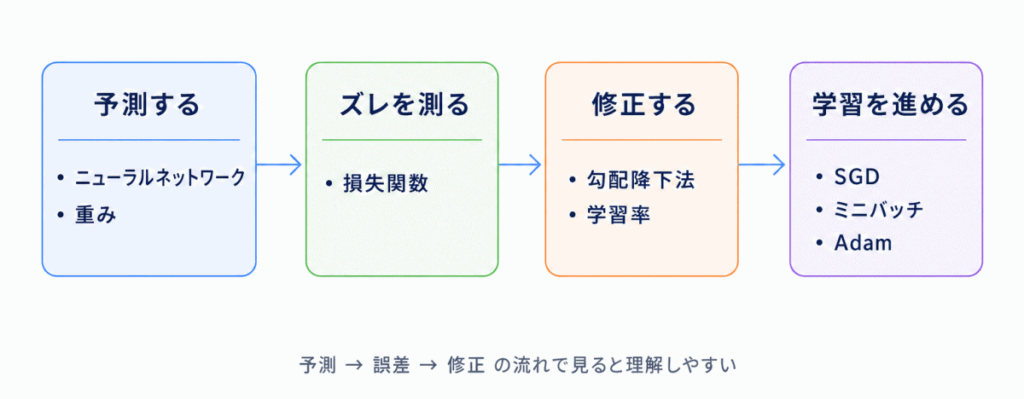
AIの学習では、予測して、間違いを確認し、少しずつ修正していく流れが重要です。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| ニューラルネットワーク | 人間の神経回路を参考にしたモデル | 入力層・中間層・出力層 |
| 重み | AIがどこを重要視するかを決める値 | 学習で調整される |
| 損失関数 | 予測と正解のズレを数値化するもの | 学習中に使う |
| 勾配降下法 | 損失を小さくする方向へ重みを調整する方法 | 最適解の模索 |
| 学習率 | どのくらい大きく修正するかを決める値 | 大きすぎても小さすぎても問題 |
| SGD(確率的勾配降下法) | データの一部を使って少しずつ学習する方法 | 全データではなく、一部のデータで重みを更新する |
| ミニバッチ | データを小さなまとまりに分けて学習する方法 | 効率と安定性のバランス |
| Adam | 学習率を調整しながら効率よく学習する最適化手法 | 勾配降下法の発展 |
| 誤差逆伝播法 | 誤差をもとに、重みを修正する仕組み | 重みの更新 |
| 活性化関数 | ニューラルネットワークに非線形性を加える関数 | 出力の調整 |
| 勾配消失問題 | 層が深くなると、重みを更新しにくくなる問題 | 勾配の減少 |
| LSTM・GRU | RNNの勾配消失問題を補う仕組み | 記憶の保持 |
| オートエンコーダ | 入力を圧縮して、元に戻すニューラルネットワーク | 圧縮と復元 |
| VAE | 潜在表現を確率的に扱う生成モデル | 確率的な生成 |
| GAN | 生成器と識別器を競わせて学習する生成モデル | 競わせて生成 |
この分野では、損失関数・勾配降下法・学習率の関係が特に重要です。
損失関数でズレを見つけ、勾配降下法で修正し、学習率で修正幅を決める、という流れで整理すると理解しやすくなります。
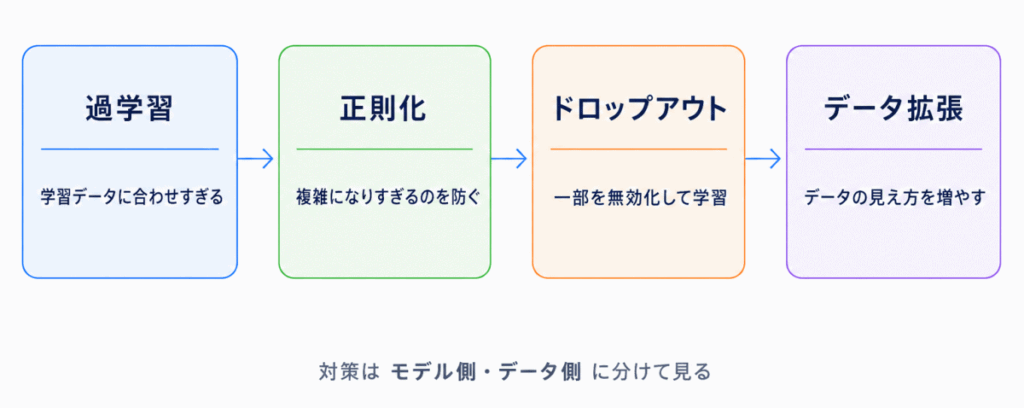
過学習とは、学習データに合わせすぎて、新しいデータに弱くなる状態です。反対に、未知のデータにも対応できる状態を汎化といいます。
正則化・ドロップアウト・交差検証・データ拡張は、汎化しやすくするための工夫として整理できます。
| 用語 | 一言でいうと | 位置づけ |
|---|---|---|
| 過学習 | 学習データに合わせすぎること | 避けたい状態 |
| 汎化(※) | 未知のデータにも対応できること | 目指したい状態 |
| 正則化 | 複雑になりすぎないように制限する方法 | モデル側の工夫 |
| ドロップアウト | 一部のニューロンを無効化して学習する方法 | モデル側の工夫 |
| 交差検証 | データを分けて性能を確認する方法 | 評価方法の工夫 |
| データ拡張 | データの見え方を増やす方法 | データ側の工夫 |
※:過学習状態の場合、未知のデータに対応できません
過学習対策では、データ側の工夫か、モデル側の工夫か、評価方法の工夫かで分けると整理しやすくなります。
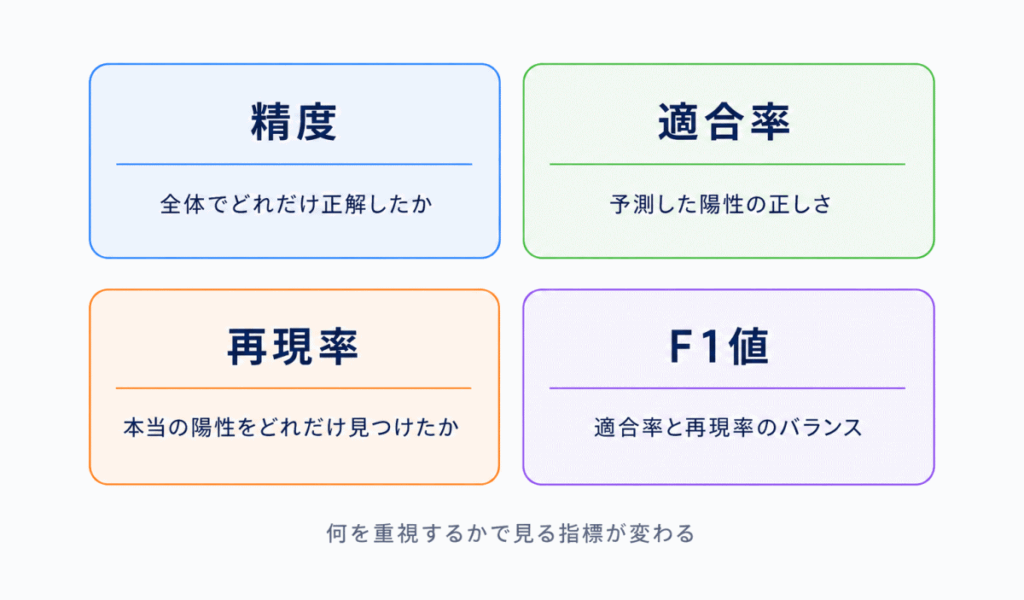
AIの評価では、単に「正解率が高いか」だけでは判断できない場合があります。特に、医療・不正検知・異常検知のように、見逃しや誤検出が問題になる場面では、適合率や再現率が重要になります。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| 精度 | 全体のうち、どれだけ正解したか | 全体の正解率 |
| 適合率 | 陽性と予測したもののうち、どれだけ正解か | 間違って拾いたくない |
| 再現率 | 本当の陽性をどれだけ見つけられたか | 見逃したくない |
| F1値(※) | 適合率と再現率のバランスを見る指標 | バランス重視 |
※:適合率と再現率のバランス
適合率と再現率は、G検定でも混同しやすい用語です。
適合率は「予測した中身の正しさ」、再現率は「本来見つけるべきものを見つけた割合」と整理すると分かりやすくなります。
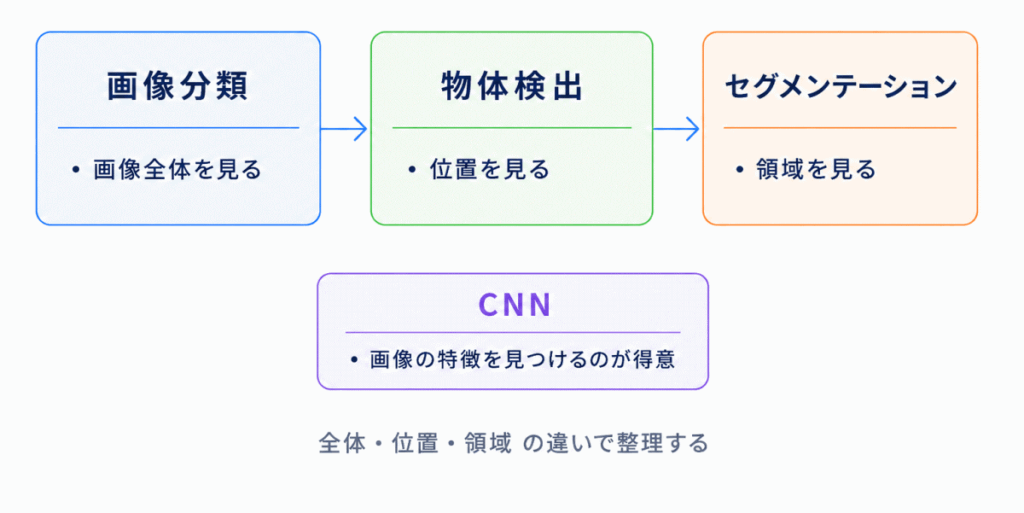
画像認識では、画像全体を見るのか、物体の位置を見るのか、領域ごとに分けるのかで用語が変わります。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| CNN | 画像の特徴を見つけるのが得意なニューラルネットワーク | 画像認識 |
| 画像分類 | 画像全体が何かを判断する | 全体を見る |
| 物体検出 | 画像の中のどこに何があるかを判断する | 位置を見る |
| セグメンテーション | 画像を領域ごとに分ける | 領域を見る |
| 転移学習 | 学習済みモデルを別の課題に活用する | 学習済みモデル |
| データ拡張 | 画像の見え方を増やす | データ側の工夫 |
画像分類・物体検出・セグメンテーションは、次のように整理できます。
この3つは、画像認識分野で特に混同しやすい用語です。
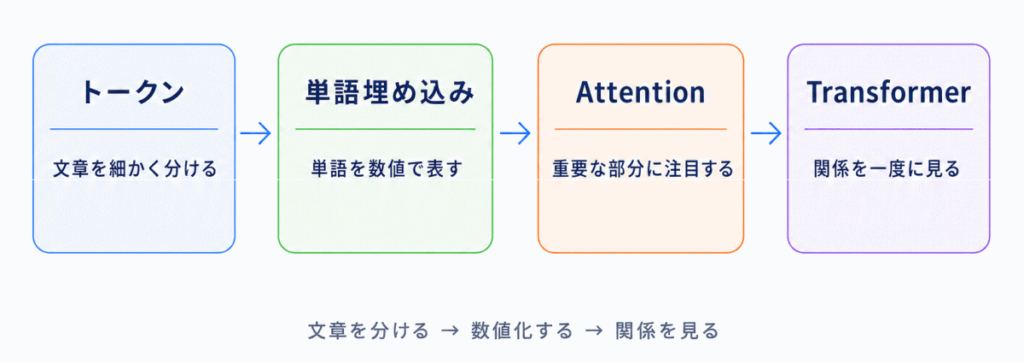
自然言語処理は、文章をコンピュータで扱う技術です。生成AIやLLMの理解にもつながります。
| 用語 | 一言でいうと | 補足 |
|---|---|---|
| 自然言語処理 | 人間の言葉をコンピュータで扱う技術 | NLPとも呼ばれる |
| トークン | 文章を細かく分けた単位 | 単語、文字、サブワード |
| 単語埋め込み | 単語を数値ベクトルで表す方法 | Embeddingとも呼ばれる |
| Seq2Seq | 入力系列から出力系列を作るモデル | 翻訳、要約などで使われる |
| Attention | 重要な部分に注目する仕組み | Transformer理解につながる |
| Self-Attention | 同じ文の中で単語同士の関係を見る仕組み | Attentionの一種 |
| Multi-Head Attention | 複数の視点で関係を見る仕組み | Self-Attentionを複数並べるイメージ |
| 位置エンコーディング | 単語の順番をモデルに伝える仕組み | Transformerで重要 |
自然言語処理では、文章をどう分けるか、どう意味を数値にするか、どう単語同士の関係を見るかが重要です。
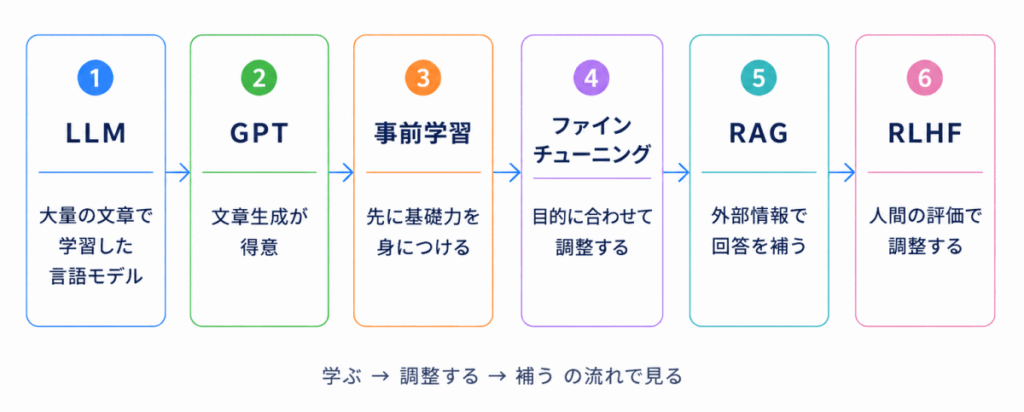
生成AIでは、文章や画像など、新しいコンテンツを作る仕組みが中心になります。G検定では、LLM・GPT・BERT・RAG・RLHF・アライメントなどの関係を整理しておくと理解しやすくなります。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| 生成AI | 新しい文章・画像・音声などを作るAI | 作るAI |
| LLM | 大量の文章で学習した大規模言語モデル | 言語モデル |
| GPT | 次の単語を予測しながら文章を生成するモデル | 生成が得意 |
| BERT | 文の前後関係を見て意味を理解するモデル | 理解が得意 |
| 事前学習 | 先に大量データで基礎力を身につける段階 | 先に学ぶ |
| ファインチューニング | 目的に合わせて追加調整する方法 | 追加調整 |
| RAG | 外部情報を使って回答を補う仕組み | 検索+生成 |
| RLHF | 人間の評価を使って回答を調整する方法 | 人間の好みに近づける |
| アライメント | AIを人間の意図に沿わせる考え方 | 安全性・意図 |
| GAN | 生成器と識別器を競わせて学習する生成モデル | 競わせて生成 |
| VAE | 潜在表現を確率的に扱う生成モデル | 確率的な生成 |
| オートエンコーダ | 入力を圧縮して、元に戻すニューラルネットワーク | 圧縮と復元 |
| マルチモーダルAI | 画像・文章・音声など複数の情報を組み合わせて扱うAI | 複数情報の統合 |
| Zero-shot・One-shot・Few-shot学習 | AIに見せる例の数によって使い方を分ける考え方 | 例の数 |
生成AIの用語は、何をしている段階なのかで分けると理解しやすくなります。
| 段階 | 関係する用語 |
|---|---|
| 先に大量データで学ぶ | 事前学習 |
| 目的に合わせて調整する | ファインチューニング |
| 人間の評価で調整する | RLHF |
| 外部情報を使う | RAG |
| 人間の意図に沿わせる | アライメント |
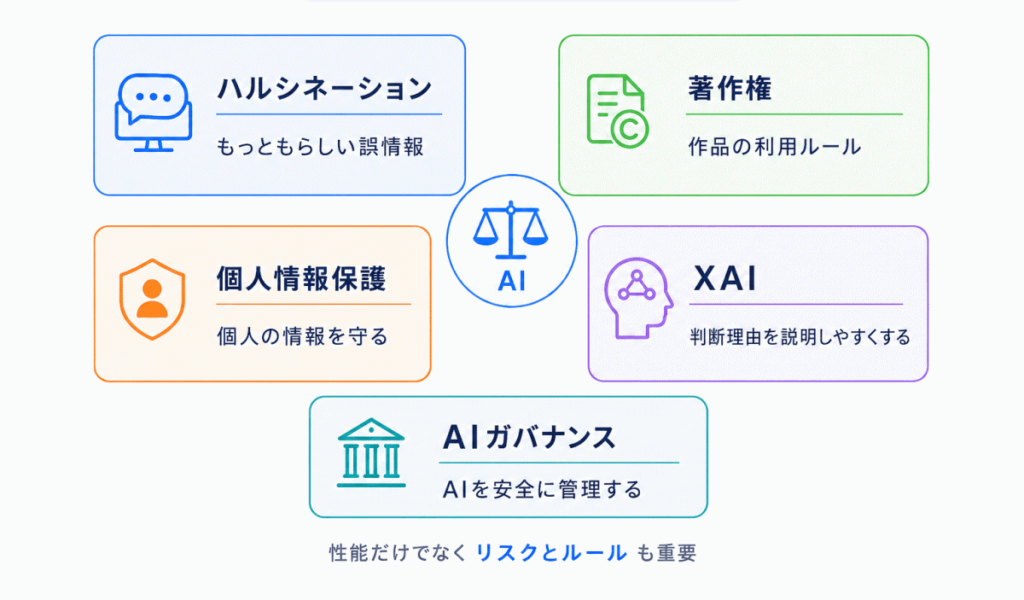
AIを社会で使うときは、性能だけでなく、リスクやルールも重要になります。G検定では、AI倫理・法律・ガバナンスの用語も押さえておきたい分野です。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| ハルシネーション | AIがもっともらしい誤情報を出すこと | 事実性 |
| 著作権 | 作品の利用や権利に関するルール | 学習データ・生成物 |
| 個人情報保護 | 個人を識別できる情報を守る考え方 | 入力情報・顔・声 |
| アルゴリズムバイアス | AIの判断が偏る問題 | データの偏り |
| 説明可能AI(XAI) | AIの判断理由を説明しやすくする考え方 | 透明性 |
| AIガバナンス | AIを安全に管理・運用する仕組み | 組織的な管理 |
| ディープフェイク | 本物らしい偽コンテンツを作る技術 | 偽情報 |
この分野では、技術そのものよりも、AIを使うことで何が問題になるのかを意識すると理解しやすくなります。
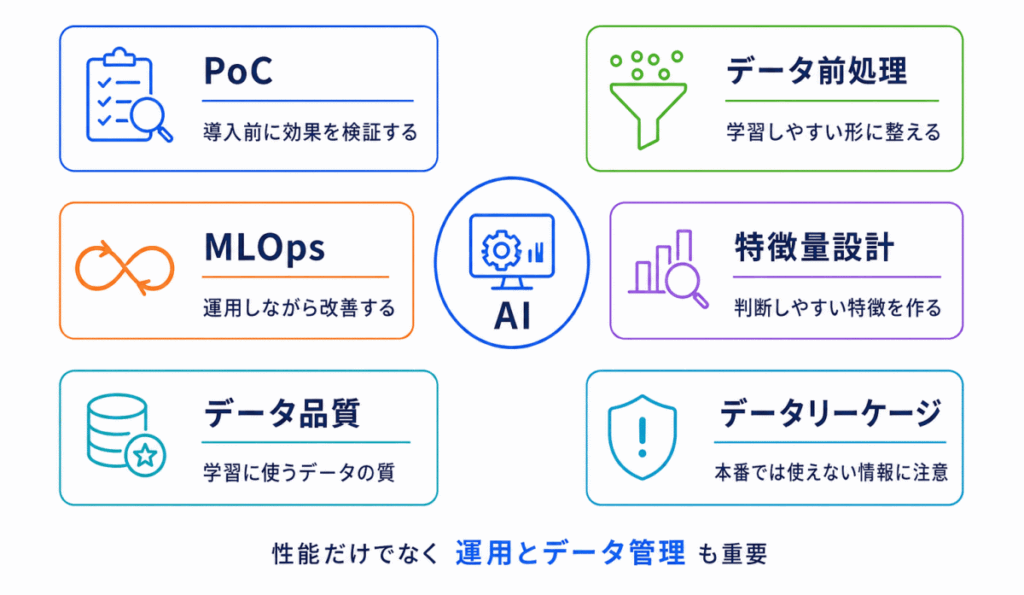
AIは、モデルを作って終わりではありません。実際の現場で使うには、検証、データ整備、運用、軽量化、継続的な改善まで含めて考える必要があります。
| 用語 | 意味 | 確認できる内容 |
|---|---|---|
| PoC | AI導入前に、実現できるか・効果があるかを小さく検証すること | 検証/本格導入前の確認/AI導入の失敗防止 |
| MLOps | AIモデルを継続的に運用・改善するための考え方 | 運用/監視/再学習/継続的な改善 |
| エッジAI | クラウドではなく、端末や現場側でAIを動かす仕組み | 端末側での処理/低遅延/通信量削減 |
| モデル軽量化 | AIモデルを小さく・速くして、使いやすくする工夫 | 軽量化/高速化/端末での利用 |
| アノテーション | AIに学習させるため、データに正解ラベルを付ける作業 | 正解ラベル/教師データ/データ作成 |
| データ品質 | AIの学習や予測に使うデータの良し悪し | 欠損/偏り/ノイズ/精度への影響 |
| データ前処理 | AIが学習しやすいように、データを整える作業 | 欠損値処理/外れ値処理/スケール調整 |
| 特徴量設計 | AIが判断しやすいように、データの特徴を作る考え方 | 特徴量/データの表現/予測しやすい形 |
| データリーケージ | 本番では使えない情報が学習時に混ざってしまう問題 | 学習時のズル/過大評価/本番での性能低下 |
AIの社会実装では、モデルの性能だけでなく、データの品質、運用体制、本番環境で使える形にする工夫も重要です。
G検定では、数式そのものよりも、AIや機械学習の考え方と数理・統計の用語がどうつながるかを理解しておくことが大切です。
| 用語 | 一言でいうと | ポイント |
|---|---|---|
| 確率 | 起こりやすさを数値で表す考え方 | 分類/予測/不確実性 |
| 条件付き確率 | ある条件のもとで起こる確率 | ベイズの定理につながる |
| ベイズの定理 | 観測した情報から可能性を考える方法 | 推論/分類/ナイーブベイズ |
| エントロピー | 不確かさを表す考え方 | 情報量/分類/損失関数 |
| 交差エントロピー | 正解と予測のズレを見る損失関数 | 分類問題で使われる |
| KLダイバージェンス | 2つの確率分布のズレを見る指標 | VAE/分布の比較 |
| 次元削減 | 特徴量を少なくして扱いやすくする方法 | PCA/可視化/過学習対策 |
| PCA | 重要な方向を残して次元を減らす方法 | 主成分分析/特徴量の圧縮 |
G検定では、似た用語の違いを問われることがあります。意味を丸暗記するよりも、見分ける軸を持っておくことが大切です。
| 混同しやすい用語 | 見分け方 |
|---|---|
| AI / 機械学習 / ディープラーニング | 大きな枠の違いで見る |
| 教師あり学習 / 教師なし学習 / 強化学習 | 正解データ・構造発見・報酬で見る |
| 損失関数 / 評価指標 | 学習中に使うか、学習後に見るか |
| 適合率 / 再現率 | 間違って拾いたくないか、見逃したくないか |
| 正則化 / ドロップアウト | 複雑さを抑えるか、一部を無効化するか |
| データ拡張 / 転移学習 | データ側の工夫か、モデル側の工夫か |
| 事前学習 / 転移学習 | 先に学ぶ段階か、別の課題に使う考え方か |
| 転移学習 / ファインチューニング | 活用する考え方か、追加調整する方法か |
| GPT / BERT | 生成が得意か、文脈理解が得意か |
| RAG / ファインチューニング | 外部情報を使うか、モデルを追加調整するか |
| ハルシネーション / ディープフェイク | 誤情報の回答か、偽コンテンツか |
| 説明可能AI(XAI) / AIガバナンス | 判断理由の説明か、AI活用全体の管理か |
G検定では、用語の定義だけでなく、似た用語の違いやどの場面で使うのかが問われやすいです。
たとえば、次のような形です。
| 問われやすいポイント | 見るべき軸 |
|---|---|
| 教師あり学習・教師なし学習・強化学習の違い | 正解データ・報酬の有無 |
| 損失関数と評価指標の違い | 学習中か、評価時か |
| 再現率と適合率の違い | 誤検出を避けるか、見逃しを避けるか |
| 過学習対策の違い | データ側・モデル側・評価方法 |
| 画像分類 ・物体検出・セグメンテーションの違い | 全体・位置・領域 |
| 事前学習・転移学習・ファインチューニングの違い | 学ぶ・使う・調整する |
| RAG ・RLHF・アライメントの違い | 外部情報・人間の評価・人間の意図 |
用語を見たときに、「これは何のための言葉か」を考えると、選択肢で迷いにくくなります。
G検定の学習では、用語を1つずつ覚えるだけでは限界があります。
たとえば、転移学習だけを覚えても、事前学習・ファインチューニング・データ拡張との違いが分からないと、問題文で迷いやすくなります。
同じように、適合率だけを覚えても、再現率との違いが分からないと、どちらを選べばよいか判断しにくくなります。
そのため、用語は次のように整理すると理解しやすくなります。
| 覚え方 | 例 |
|---|---|
| 分野で覚える | 画像認識、自然言語処理、生成AI |
| 流れで覚える | 入力、予測、誤差、修正、評価 |
| 違いで覚える | 適合率と再現率、事前学習と転移学習 |
| 目的で覚える | 過学習を防ぐ、回答を補う、リスクを管理する |
用語を「単語」としてではなく、関係の中で見ることが大切です。
G検定では、多くのAI用語が登場します。すべてを丸暗記しようとすると、似た言葉が混ざりやすくなります。
特に、AIの学習をはじめたばかりの人は、用語の意味だけでなく、どの分野の言葉なのか、何のために使うのか、どの用語と混同しやすいのかをセットで整理することが大切です。
最後に、重要な見分け方をまとめます。
| 見るポイント | 代表的な用語 |
|---|---|
| AIの大きな分類 | AI 、機械学習、ディープラーニング |
| 学習方法 | 教師あり学習、教師なし学習、強化学習 |
| 学習の流れ | 損失関数、勾配降下法、学習率 |
| 過学習対策 | 正則化、ドロップアウト、データ拡張、交差検証 |
| 評価 | 精度、適合率、再現率、F1値(※) |
| 画像認識 | CNN、画像分類、物体検出、セグメンテーション |
| 自然言語処理 | トークン、単語埋め込み、Attention、Transformer |
| 生成AI | LLM、GPT、BERT、RAG、RLHF、アライメント |
| AI倫理・法律 | ハルシネーション、著作権、個人情報保護、説明可能AI(XAI)、AIガバナンス |
※:適合率と再現率のバランス
用語一覧は、単なる暗記表ではありません。
関連用語をつなげて見ることで、G検定の問題文が変わっても対応しやすくなります。
用語一覧で全体像を確認したら、次は分野ごとに詳しく整理していくと理解しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 理解ロードマップ | 学習順/8分野別の入口/重要用語/チェックシート/理解型予想問題 |
| 重要用語チェックシート | G検定の重要用語/8分野別の確認/一言まとめ/印刷用チェック/試験直前の見直し |
| 8分野別の記事一覧 | G検定8分野の分類/苦手分野別の記事確認/作成済み記事一覧/学習順の整理 |
| AI学習の流れ | 入力/予測/正解との比較/間違い確認/修正/再予測までの流れ |
| 生成AIの仕組み | 事前学習/ファインチューニング/RLHF/RAG/アライメント/ハルシネーション |
| 画像認識の歴史 | 画像認識の発展/CNN/AlexNet/ILSVRC/物体検出・セグメンテーションへの流れ |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。