【G検定対策】エッジAIとは?|端末側でAIを動かす仕組みをわかりやすく整理
seo-webmaster
G検定対策ブログ
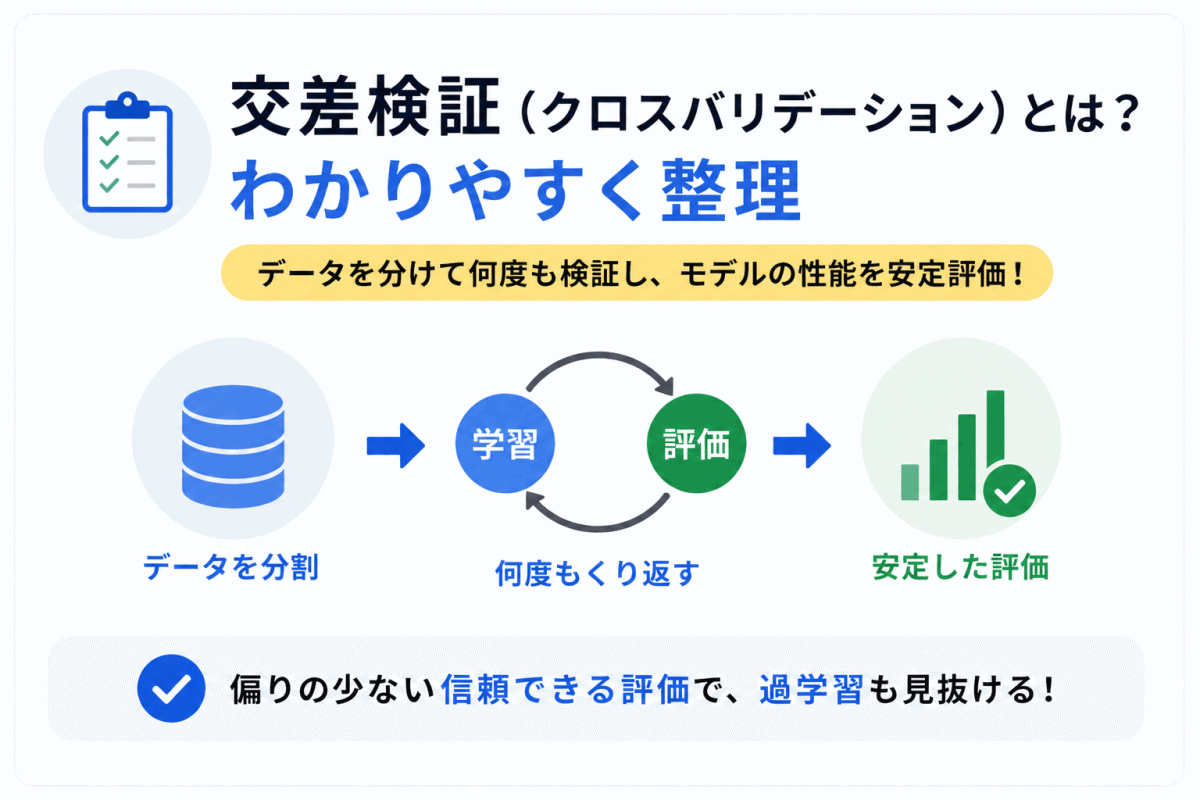
交差検証とは、データをいくつかに分け、学習と評価を複数回くり返すことで、モデルの性能を安定して確認する方法です。
1回だけデータを分けて評価すると、たまたま良い結果や悪い結果になることがあります。
交差検証を使うと、データの分け方による偏りを減らし、未知のデータにも対応できるかを確認しやすくなります。
G検定では、K-分割交差検証、ホールドアウト法との違い、過学習や汎化性能との関係を整理しておくことが大切です。
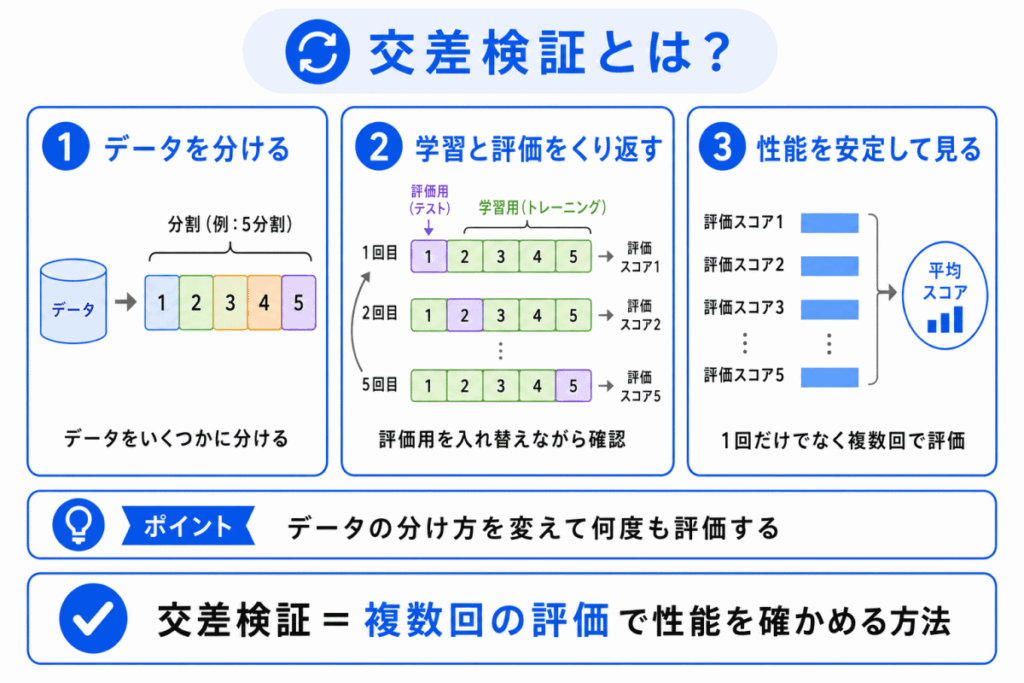
交差検証とは、データを複数に分け、学習用データと評価用データを入れ替えながら、モデルの性能を確認する方法です。
AIのモデルは、学習に使ったデータでは高い性能を出せても、新しいデータではうまくいかないことがあります。
そのため、モデルを評価するときは、学習に使っていないデータで確認する必要があります。
| 用語 | 一言でいうと |
|---|---|
| 学習用データ | モデルを学習させるためのデータ |
| 評価用データ | 学習後の性能を確認するためのデータ |
| 交差検証 | データの分け方を変えながら複数回評価する方法 |
交差検証は、1回だけの評価に頼らず、何度か評価して性能を確かめる方法 と考えるとわかりやすいです。
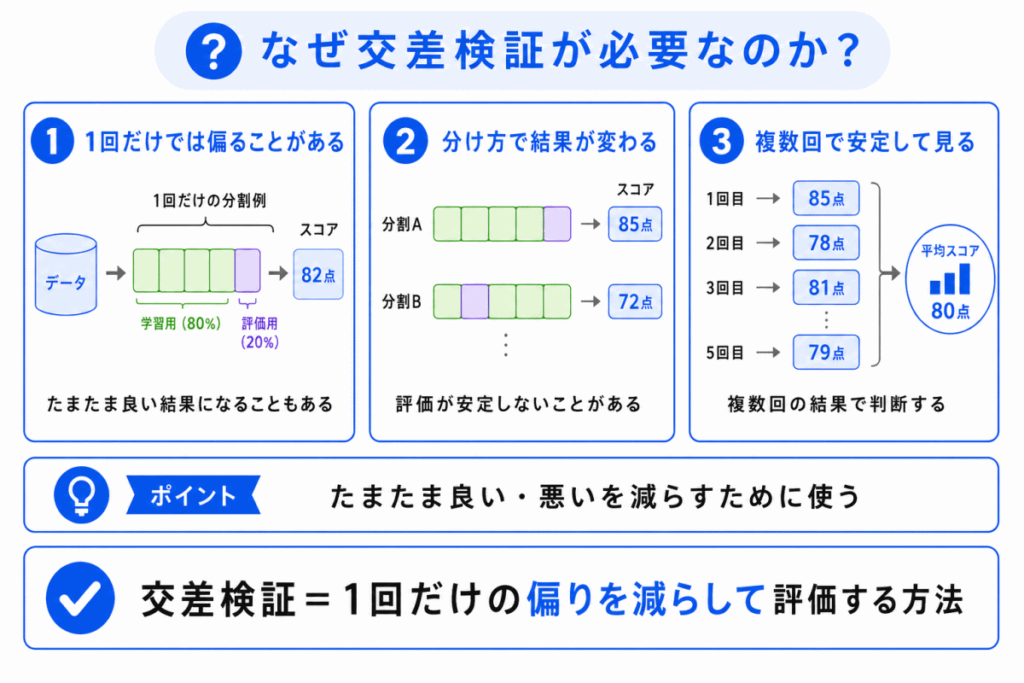
交差検証が必要な理由は、1回だけの評価では、結果がデータの分け方に左右されやすいからです。
たとえば、たまたま簡単なデータが評価用に集まると、モデルの性能が高く見えることがあります。
反対に、難しいデータばかりが評価用に集まると、実際より性能が低く見えることもあります。
| 評価のしかた | 起きやすいこと |
|---|---|
| 1回だけ評価 | 分け方によって結果が偏ることがある |
| 複数回評価 | 性能を安定して見やすい |
| 交差検証 | データを入れ替えて複数回評価する |
つまり、交差検証は たまたま良かった・悪かった という評価のブレを減らすために使われます。
モデルの本当の実力を見たいときに役立つ考え方です。
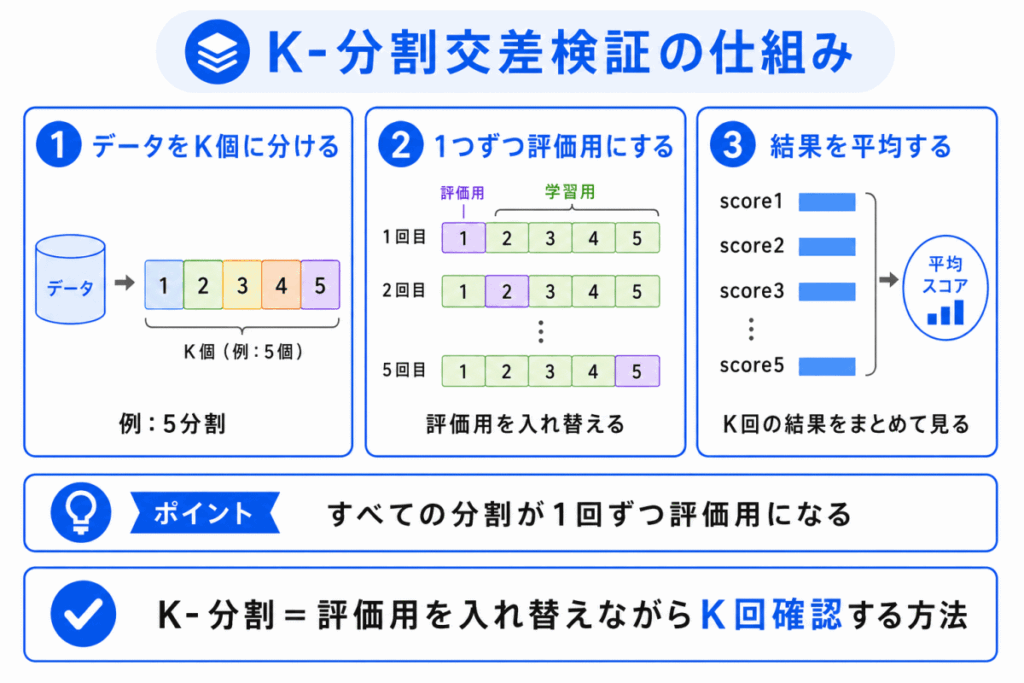
G検定対策では、まず K-分割交差検証 を代表例として押さえると理解しやすいです。
K-分割交差検証では、データをK個のグループに分けます。
そのうち1つを評価用データ、残りを学習用データとして使います。
これを、評価用データの場所を入れ替えながらK回くり返します。
| 手順 | 内容 |
|---|---|
| 1 | データをK個に分ける |
| 2 | 1つを評価用データにする |
| 3 | 残りを学習用データにする |
| 4 | 評価用データを入れ替えてくり返す |
| 5 | 複数回の評価結果を平均する |
たとえば5分割交差検証なら、データを5つに分け、5回評価します。
1回ごとに評価用データを変えるため、データ全体を評価に使いやすくなります。
交差検証と混同しやすいものに、ホールドアウト法があります。
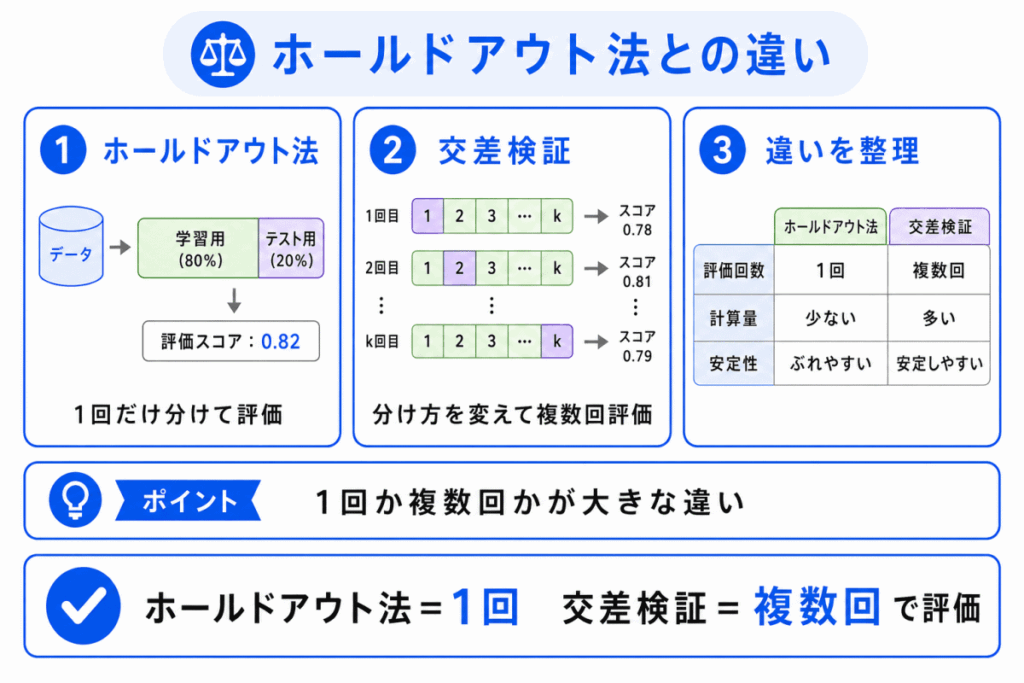
ホールドアウト法とは、データを一度だけ学習用と評価用に分けて、モデルを評価する方法です。
| 方法 | 特徴 |
|---|---|
| ホールドアウト法 | 1回だけ学習用・評価用に分ける |
| 交差検証 | 分割を入れ替えながら複数回評価する |
ホールドアウト法はシンプルでわかりやすい方法です。
ただし、1回だけ分けるため、分け方によって評価結果が変わりやすくなります。
一方、交差検証は複数回評価するため、より安定して性能を見やすいという特徴があります。
| 比較 | ホールドアウト法 | 交差検証 |
|---|---|---|
| 評価回数 | 1回 | 複数回 |
| 計算量 | 少ない | 多い |
| 結果の安定性 | 分け方に左右されやすい | 安定しやすい |
| 使いやすさ | シンプル | 少し手間がかかる |
G検定では、1回だけ分けるのがホールドアウト法、何度も分け直すのが交差検証 と整理しておくと判断しやすくなります。
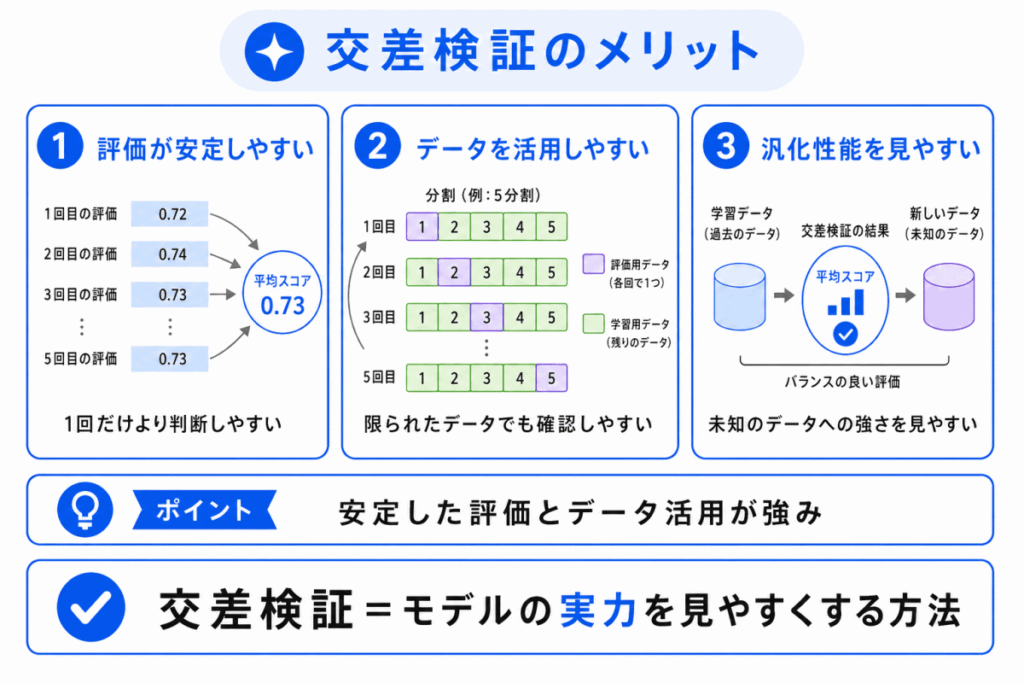
交差検証のメリットは、モデルの性能を安定して評価しやすいことです。
1回だけの評価では、データの分け方によって結果が変わることがあります。
交差検証では、評価用データを入れ替えながら複数回評価するため、偏りを減らしやすくなります。
| メリット | 内容 |
|---|---|
| 評価が安定しやすい | 複数回評価して平均を見る |
| データを有効活用しやすい | 各データを評価にも使いやすい |
| 汎化性能を見やすい | 未知のデータへの対応力を確認しやすい |
| 過学習に気づきやすい | 学習データだけでなく評価用データで確認できる |
特にデータ数が限られている場合、交差検証は便利です。
1回の分割だけに頼らず、データ全体を使ってモデルの性能を確認しやすくなります。
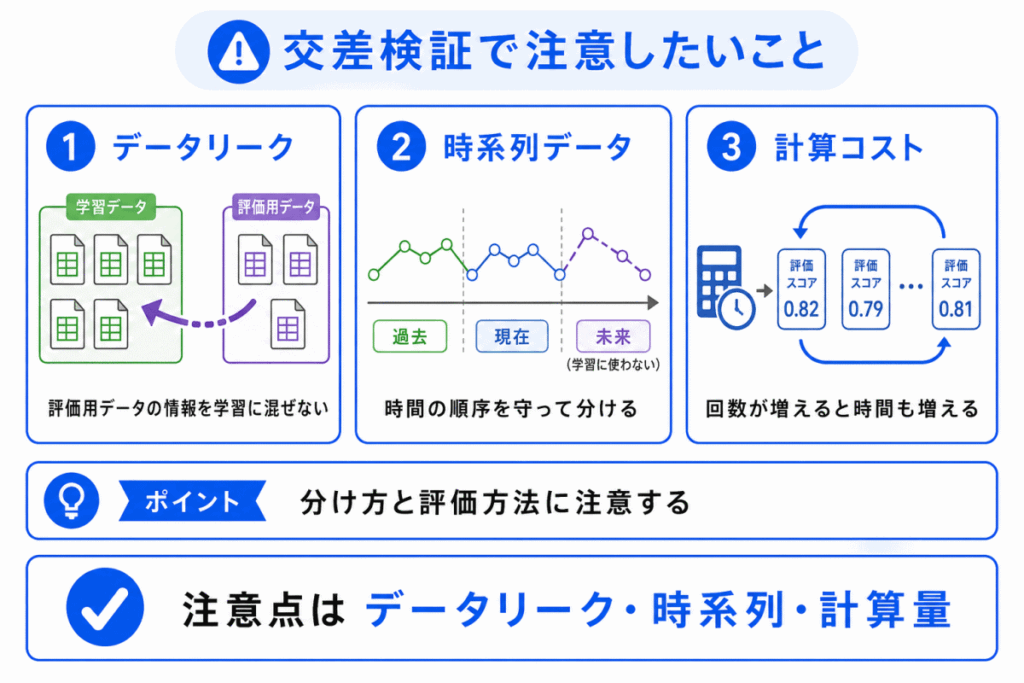
交差検証は便利ですが、注意点もあります。
特に重要なのは、データリークや分割の偏りです。
| 注意点 | 内容 |
|---|---|
| データリーク | 評価用データの情報が学習に混ざる |
| 分割の偏り | 分け方によって評価が偏る |
| 時系列データ | 通常のランダム分割が合わないことがある |
| 計算コスト | 学習と評価を複数回行うため時間がかかる |
交差検証は何度も学習と評価を行うため、ホールドアウト法より計算に時間がかかります。
また、データの分け方が不適切だと、正しい評価にならないことがあります。
つまり、交差検証は 何度も評価すれば必ず正しい というものではありません。
データの性質に合わせて、分け方を考えることが大切です。
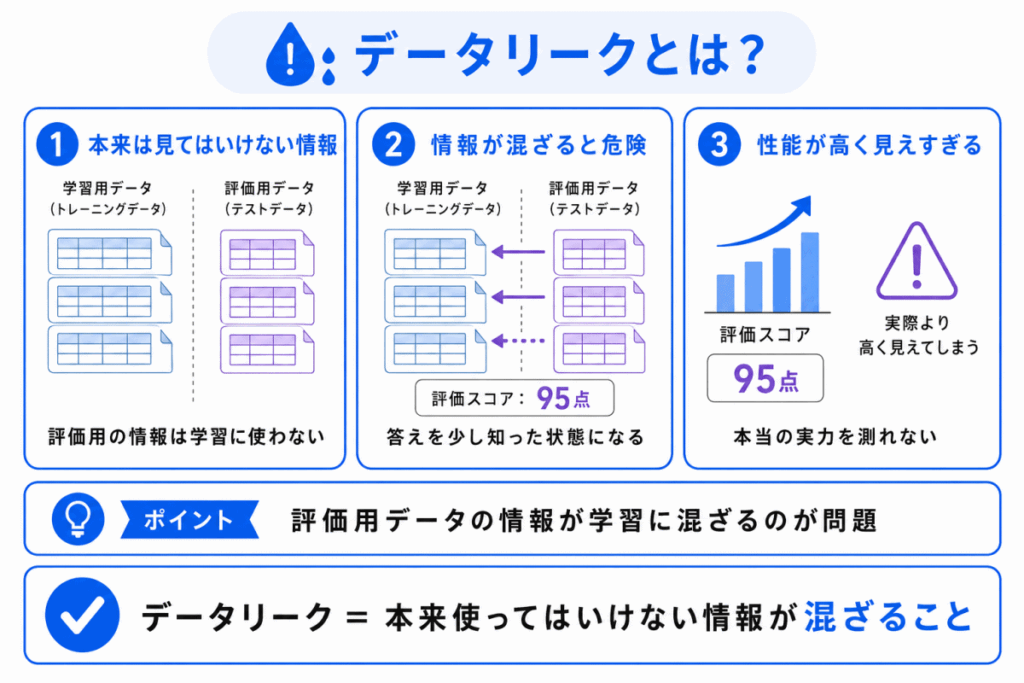
データリークとは、本来は学習に使ってはいけない情報が、学習データに混ざってしまうことです。
たとえば、評価用データの情報が学習時に入ってしまうと、モデルは答えを少し知った状態で評価されることになります。
その結果、本当の性能よりも高く見えてしまうことがあります。
| 状態 | 問題 |
|---|---|
| 評価用データの情報が学習に混ざる | 性能が高く見えすぎる |
| 前処理を分割前にまとめて行う | テスト側の情報が混ざることがある |
| 時系列の未来情報が混ざる | 実際には使えない情報で予測してしまう |
交差検証では、データを分けたあとに、学習用データだけで前処理や調整を行う必要があります。
データリークがあると、モデルの汎化性能を正しく評価できません。
G検定では、データリークを 評価が不自然に良く見えてしまう原因 として押さえておくとよいです。
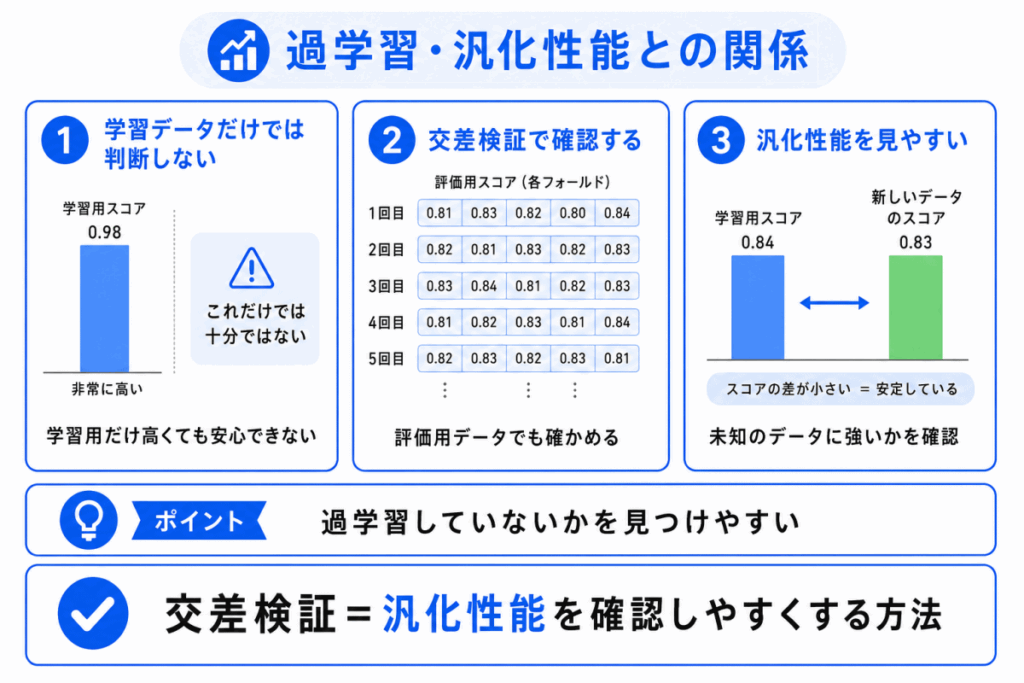
交差検証は、過学習や汎化性能を確認するためにも使われます。
過学習とは、学習データに合わせすぎて、未知のデータに弱くなる状態です。
汎化性能とは、学習していない新しいデータにも対応できる力です。
| 用語 | 一言でいうと |
|---|---|
| 過学習 | 学習データに合わせすぎること |
| 汎化性能 | 未知のデータにも対応できる力 |
| 交差検証 | 汎化性能を安定して評価する方法 |
学習データでの性能が高くても、交差検証での評価が低い場合は、過学習している可能性があります。
反対に、複数回の評価でも安定して良い結果が出るなら、未知のデータにも対応しやすいモデルだと考えやすくなります。
交差検証は、モデルの性能を 学習データだけで判断しないための工夫 です。
G検定では、交差検証の細かい実装よりも、目的や考え方が問われやすいです。
特に、ホールドアウト法、過学習、汎化性能、データリークとの関係を整理しておくと判断しやすくなります。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| 交差検証の目的 | モデルの性能を安定して評価する |
| K-分割交差検証 | データをK個に分けて、評価用を入れ替える |
| ホールドアウト法との違い | 1回だけ分けるか、複数回分けるか |
| 過学習との関係 | 学習データ以外で性能を確認する |
| 汎化性能との関係 | 未知のデータへの対応力を見る |
| データリーク | 評価用データの情報が学習に混ざる問題 |
交差検証は、単に「データを分ける方法」ではありません。
未知のデータにも通用するかを、安定して確認する方法 として理解しておくことが大切です。
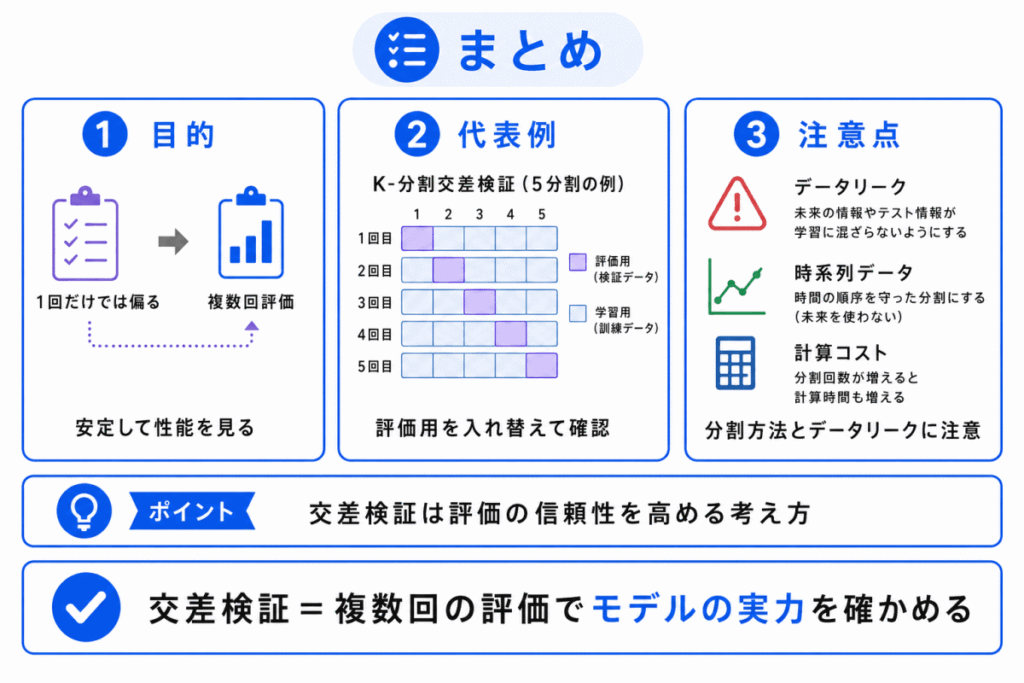
交差検証とは、データを複数に分け、学習用データと評価用データを入れ替えながら、モデルの性能を確認する方法です。
1回だけ評価するよりも、データの分け方による偏りを減らし、安定して性能を見やすくなります。
| 用語 | 一言でいうと |
|---|---|
| ホールドアウト法 | 1回だけ学習用・評価用に分ける |
| 交差検証 | 分け方を変えながら複数回評価する |
| K-分割交差検証 | データをK個に分けてK回評価する |
| 過学習 | 学習データに合わせすぎること |
| 汎化性能 | 未知のデータにも対応できる力 |
| データリーク | 本来使ってはいけない情報が学習に混ざること |
G検定では、交差検証を数式で覚えるよりも、1回だけの評価に頼らず、複数回評価して汎化性能を確認する方法 として整理しておくと理解しやすくなります。
過学習やデータリークとセットで問われることもあるため、評価方法の目的まで押さえておきましょう。
交差検証で評価した結果をどう見るかは、評価指標の使い分け方とあわせて理解すると整理しやすくなります。

交差検証は、学習データだけに合わせすぎていないかを確認するためにも使われます。
評価結果のばらつきやモデルの傾向を考えるときは、バイアスと分散の考え方も関係します。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認