【G検定対策】エッジAIとは?|端末側でAIを動かす仕組みをわかりやすく整理
seo-webmaster
SEO・ウェブマスターブログ
AIは、データをもとにパターンを学習します。
そのため、どれだけ高性能なモデルを使っても、学習に使うデータの品質が低いと、正しく予測できないことがあります。
G検定でも、データ品質はAI開発や社会実装と関係する重要な考え方です。
特に、欠損値、ノイズ、ラベルミス、データの偏り、アノテーション品質との関係を整理しておくと、AIがなぜ失敗するのかを理解しやすくなります。
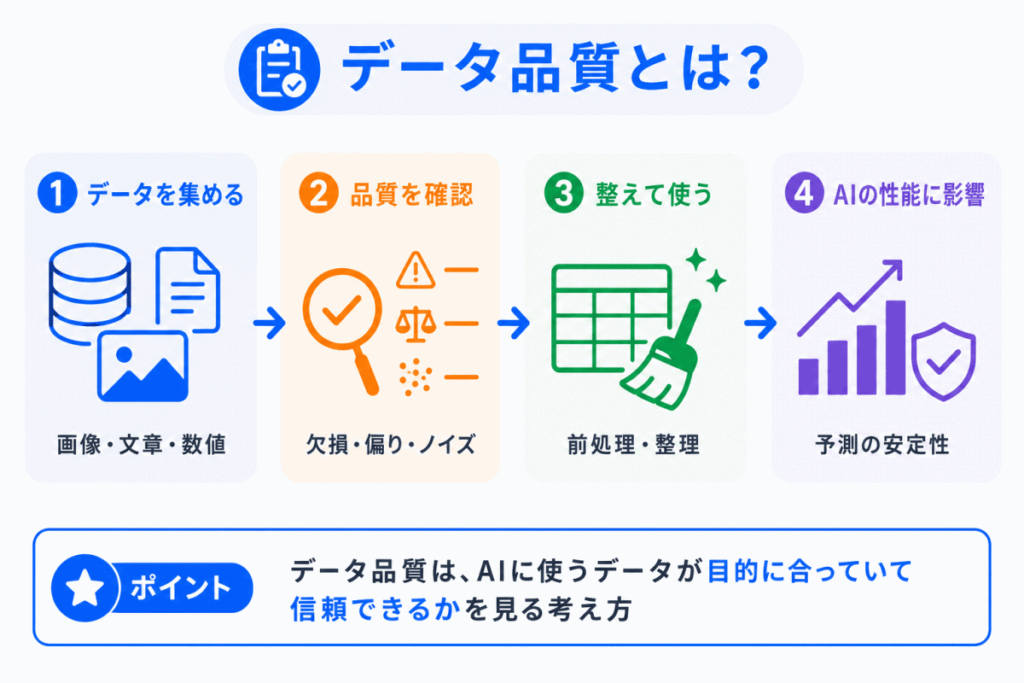
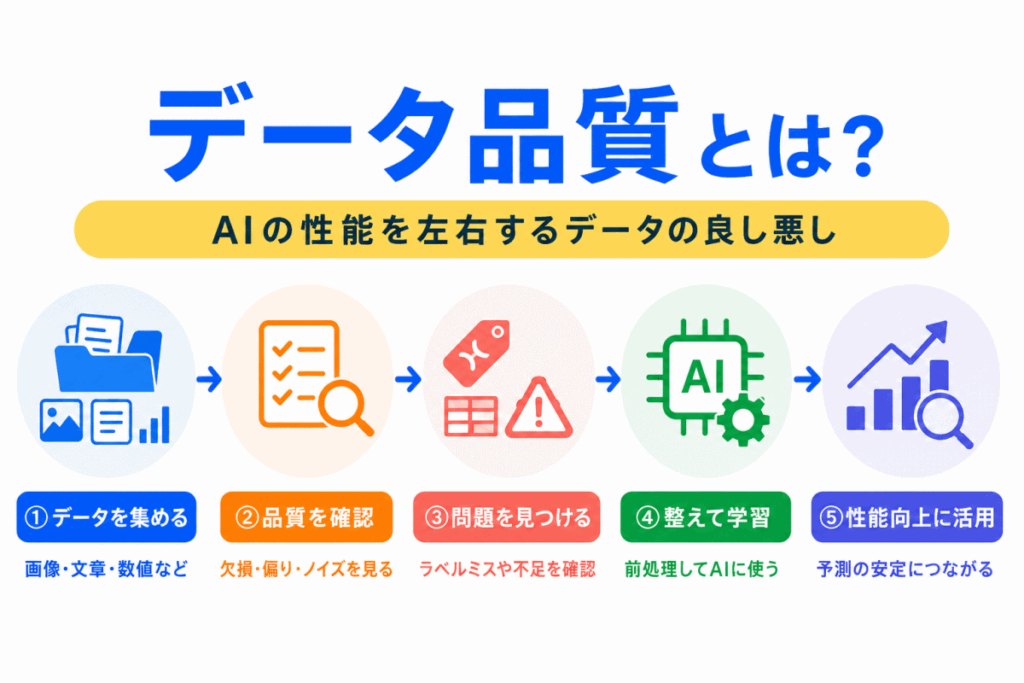
データ品質とは、AIの学習や予測に使うデータが、目的に対してどれだけ適切で信頼できるかを表す考え方です。
AIは、データの中にある特徴やパターンを学習します。
そのため、データに間違いが多かったり、偏りがあったり、必要な情報が不足していたりすると、AIもその影響を受けます。
たとえば、犬と猫を見分けるAIを作る場合、犬の画像ばかり集めて猫の画像が少ないと、猫をうまく判定できない可能性があります。
また、犬の画像に「猫」というラベルが付いていれば、AIは間違った正解を学習してしまいます。
つまり、データ品質は、AIモデルの性能だけでなく、AIを実際に使えるかどうかにも関係します。
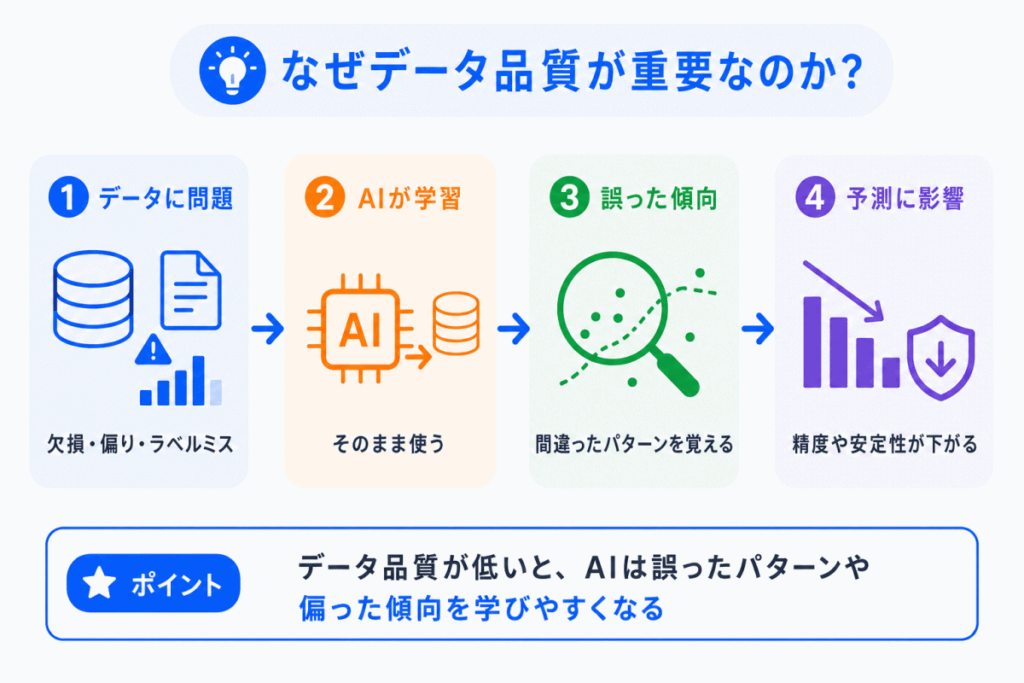
AIは、与えられたデータをもとに学習します。
そのため、データの品質が低いと、AIは間違ったパターンや偏った傾向を学んでしまうことがあります。
特に、教師あり学習では、入力データと正解ラベルのセットを使って学習します。
この正解ラベルが間違っていると、AIは「間違った答え」を正解として学んでしまいます。
データ品質が重要な理由は、次のように整理できます。
| 理由 | 説明 |
|---|---|
| AIはデータから学ぶ | データに含まれる特徴や傾向をもとに予測するため |
| 間違ったデータも学習してしまう | ラベルミスやノイズがあると、誤ったパターンを覚えることがある |
| 偏ったデータは偏った判断につながる | 特定の条件に片寄ったデータで学習すると、公平性や汎化性能に影響する |
| 実運用で性能が下がることがある | 学習時のデータと実際のデータが違うと、予測が不安定になることがある |
G検定では、データ品質は単独の用語としてだけでなく、教師データ、アノテーション、バイアス、過学習、AIの社会実装などとつながって問われることがあります。
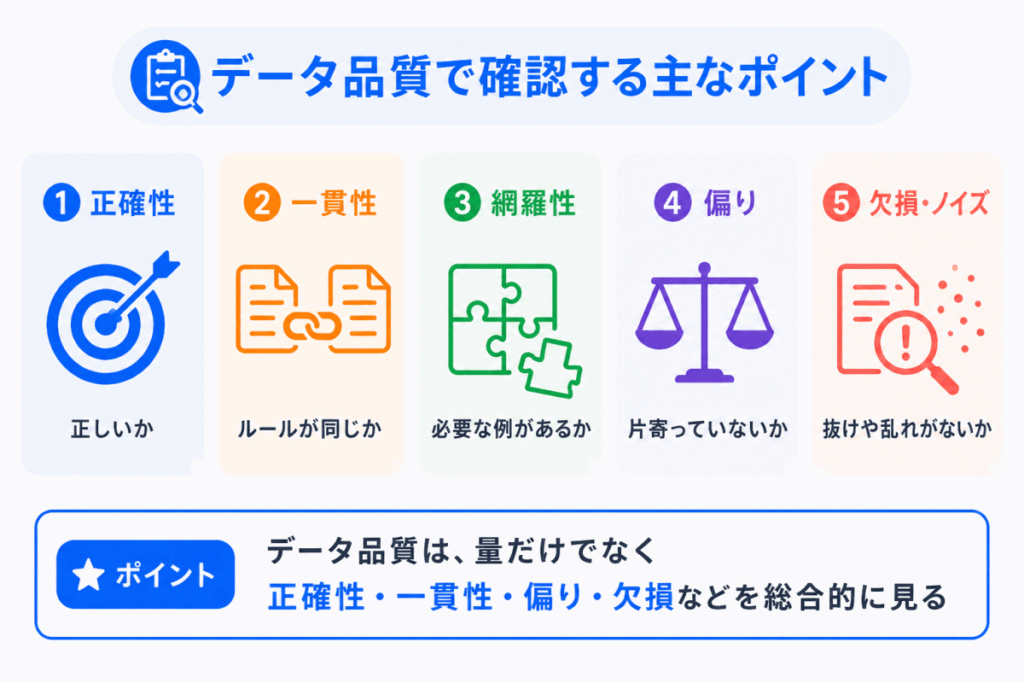
データ品質を見るときは、単に「データ量が多いか」だけでは不十分です。
量だけでなく、正しさ、偏り、欠損、ノイズ、一貫性なども重要になります。
データ品質は、ひとつの観点だけで判断するものではありません。
正確で、目的に合っていて、偏りが少なく、学習に使いやすい状態になっているかを総合的に見る必要があります。
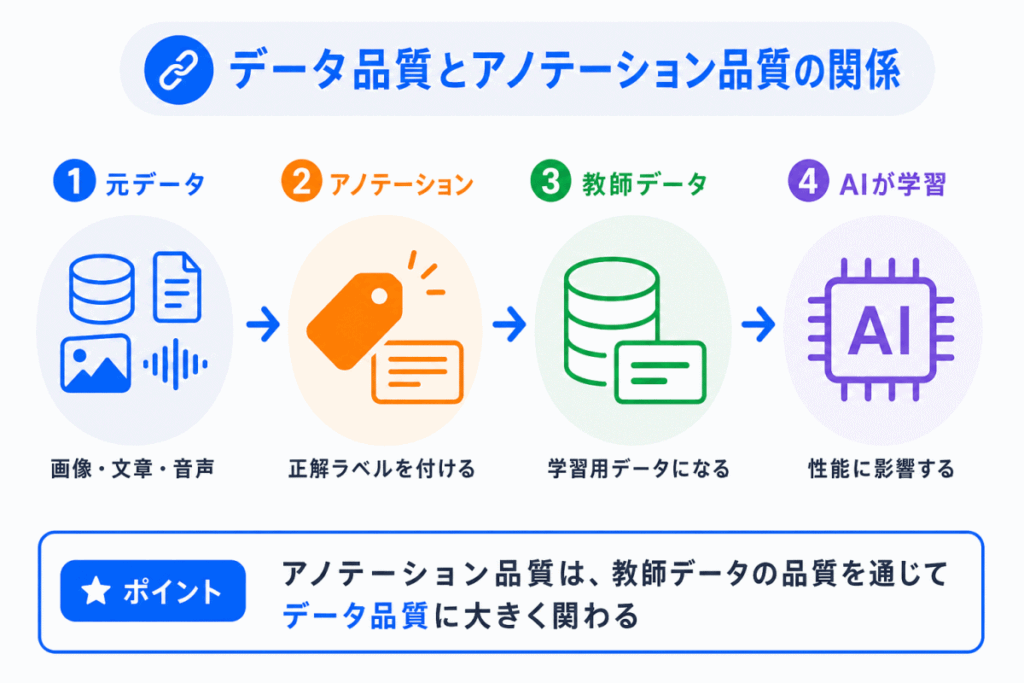
データ品質とアノテーション品質は、かなり近い関係にあります。
アノテーションとは、AIが学習できるように、データへ正解ラベルや意味づけを付ける作業です。
このアノテーションが間違っていると、教師データの品質も下がります。
つまり、アノテーション品質は、データ品質を左右する重要な要素のひとつです。
教師あり学習では、教師データの品質がとても重要です。
どれだけモデルが優れていても、正解ラベルが間違っていれば、AIは間違った答えを学んでしまいます。
データ品質が低いと、AIは正しく学習できないことがあります。
たとえば、ラベルミスが多い場合、AIは間違った正解を覚えます。
データに偏りがある場合、特定の条件ではうまく予測できても、別の条件では性能が下がることがあります。
ノイズが多い場合、本来学習すべき特徴ではなく、不要な情報に影響されることもあります。
このように、データ品質の問題は、AIモデルの精度だけでなく、実際に使えるAIになるかどうかにも関係します。
データ品質を考えるうえで、バイアスも重要です。
バイアスとは、データや判断が特定の方向に偏っている状態です。
AIはデータから学習するため、学習データに偏りがあると、その偏りを反映した予測をする可能性があります。
たとえば、ある地域や年齢層のデータだけで学習したAIは、別の地域や年齢層に対してうまく働かないことがあります。
G検定では、データ品質とバイアスは、AI倫理やアルゴリズムバイアスともつながります。
「データが偏ると、AIの判断も偏ることがある」と整理しておくと理解しやすいです。
データ品質を高めるために行う作業のひとつが、データ前処理です。
データ前処理とは、AIが学習しやすいように、データを整える作業です。
欠損値を補ったり、不要なデータを取り除いたり、表記ゆれをそろえたりします。
ただし、この記事ではデータ前処理を細かく覚えるよりも、「データ品質に問題がある場合に、前処理でデータを整え、AIが学習しやすい状態にする」と押さえておけば十分です。
データ品質は、AI開発の前半で特に重要になります。
AI開発では、いきなりモデルを作るのではなく、目的を決め、データを集め、データを確認し、必要に応じて整えます。
この段階でデータ品質を確認しないまま進めると、あとからモデルの性能が出ない原因になります。
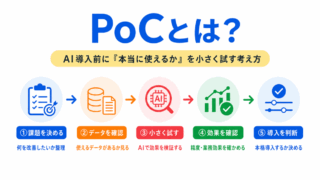
PoCでは、そもそも使えるデータがあるのかを確認する必要があります。
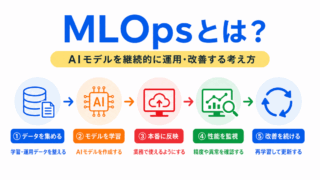
MLOpsでは、運用後にデータの傾向が変わっていないかを継続的に見る必要があります。
そのため、データ品質は「AIを作る前の準備」だけでなく、「AIを使い続けるための管理」とも関係します。
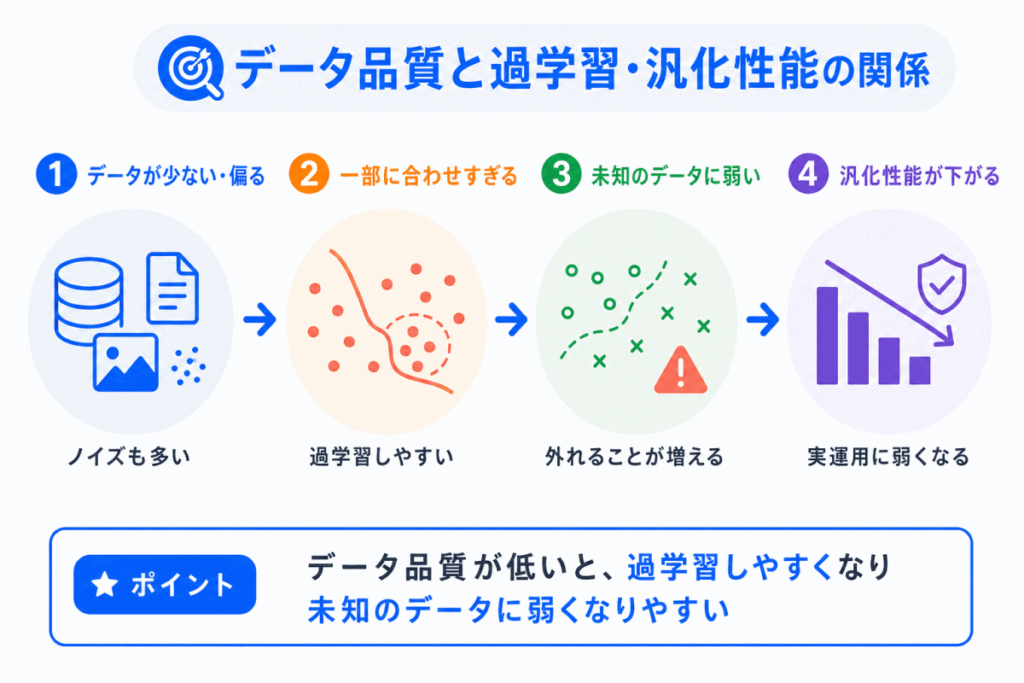
データ品質は、過学習や汎化性能とも関係します。
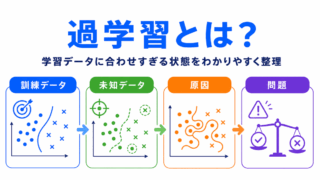
過学習とは、学習データにはよく合うのに、未知のデータに弱くなる状態です。
学習データが少なかったり、偏っていたり、ノイズが多かったりすると、AIは限られたデータに過度に合わせてしまうことがあります。
また、学習データが実際に使うデータと大きく違う場合、実運用で性能が下がることもあります。
これは、AIが学習したパターンが現実のデータにうまく当てはまらないためです。
G検定向けには、「データ品質が低いと、学習データに問題が残り、AIが偏ったパターンや不要な特徴を学びやすくなる。
その結果、未知のデータに弱くなることがある」と押さえておけば十分です。
G検定では、データ品質そのものの定義を細かく問うというより、AI開発や社会実装の文脈で問われる可能性があります。
特に、次のような整理が重要です。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| データ品質の意味 | AIに使うデータが目的に対して適切で信頼できるか |
| ラベルミス | 教師あり学習では誤った正解を学習する原因になる |
| データの偏り | AIの判断の偏りや公平性の問題につながる |
| 欠損値・ノイズ | 学習や予測を不安定にする要因になる |
| アノテーションとの関係 | アノテーション品質は教師データの品質に影響する |
| 社会実装との関係 | PoCやMLOpsではデータの確認・管理が重要になる |
G検定では、モデルの仕組みだけでなく、AIを実際に使うための準備や管理も問われます。
データ品質は、その中でも「AIに何を学ばせるか」に関わる重要な考え方です。
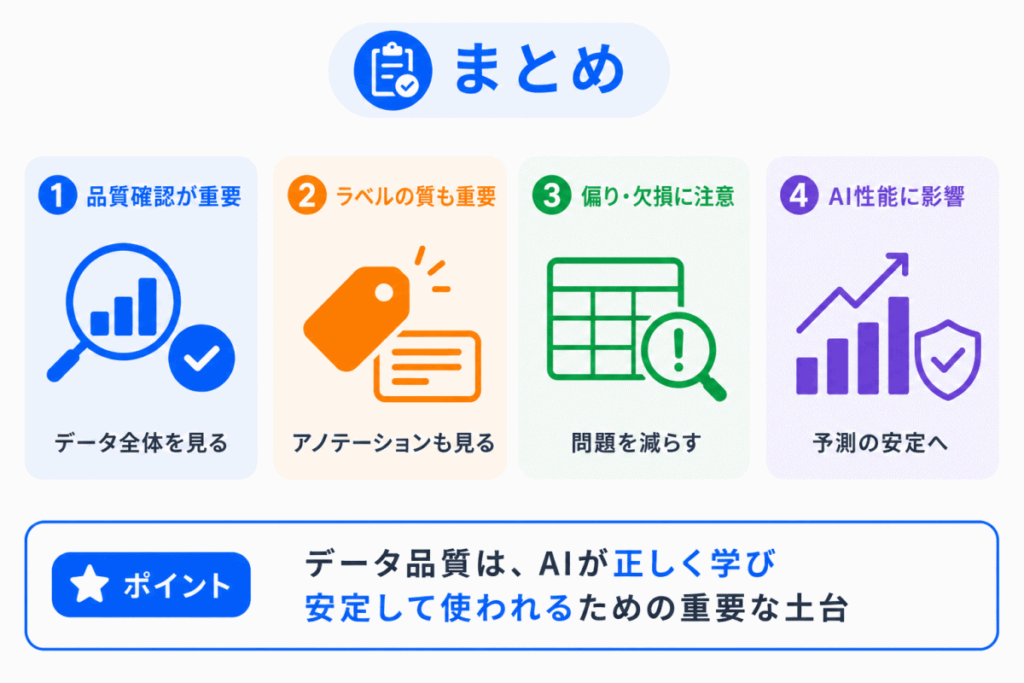
データ品質とは、AIの学習や予測に使うデータが、目的に対してどれだけ適切で信頼できるかを表す考え方です。
AIはデータから学習するため、データに欠損、ノイズ、偏り、ラベルミスがあると、その影響を受けます。
つまり、AIの性能を上げるには、モデルだけでなく、学習に使うデータの質を見ることが重要です。
G検定では、データ品質を単なるデータ管理の話としてではなく、教師データ、アノテーション、バイアス、過学習、AIの社会実装とつなげて理解しておくことが大切です。
アノテーションは、データ品質に大きく関係します。正解ラベルを付ける作業から整理すると、教師データの品質が理解しやすくなります。
データ品質は、教師あり学習で特に重要です。正解付きデータで学ぶ仕組みを確認しておくと理解が深まります。
データの偏りは、AIの不公平な判断につながることがあります。倫理分野とのつながりも押さえておくと安心です。

データ品質が低いと、過学習や汎化性能の問題にもつながります。モデルが失敗する理由として整理しておきたい内容です。
PoCでは、AIモデルを作る前に、そもそも使えるデータがあるかを確認することが重要です。
運用後もデータの傾向や品質は変化することがあります。継続的な管理の考え方としてMLOpsも確認しておきましょう。
社会実装分野全体の中で、データ品質がどこに位置づくかを整理したい場合はこちらもおすすめです。
用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認