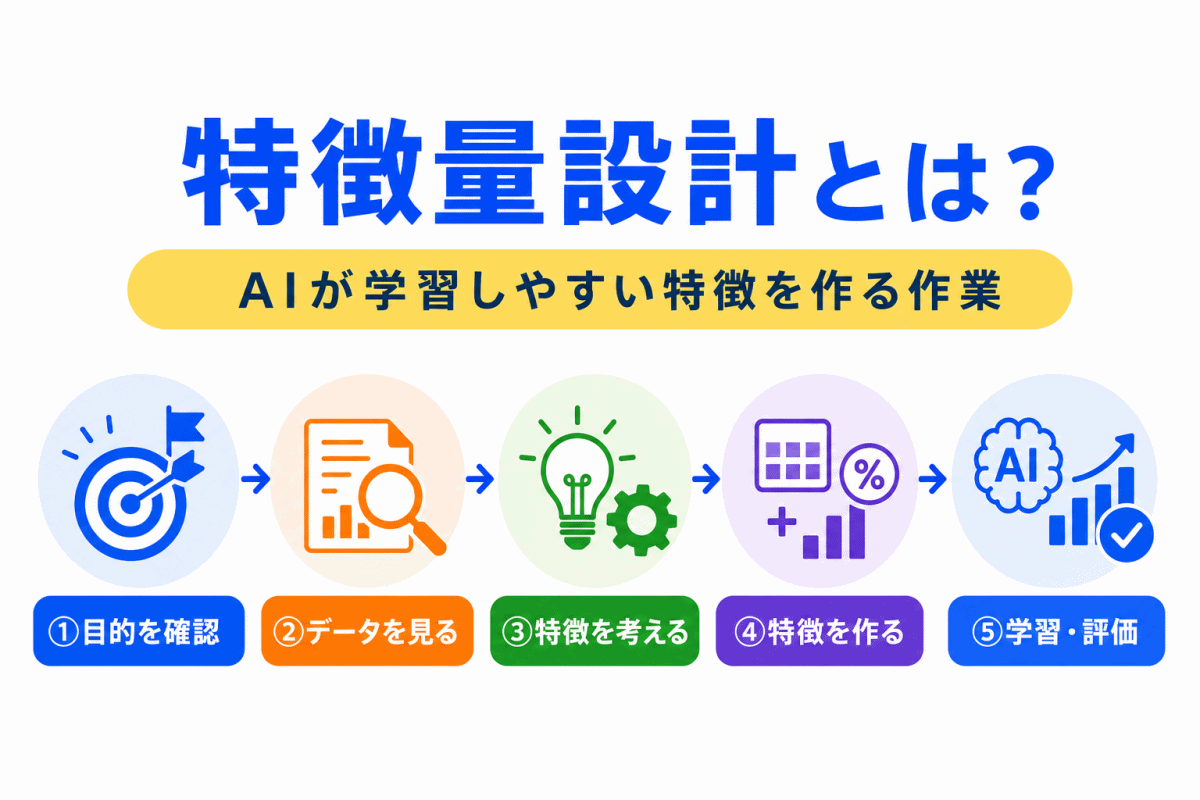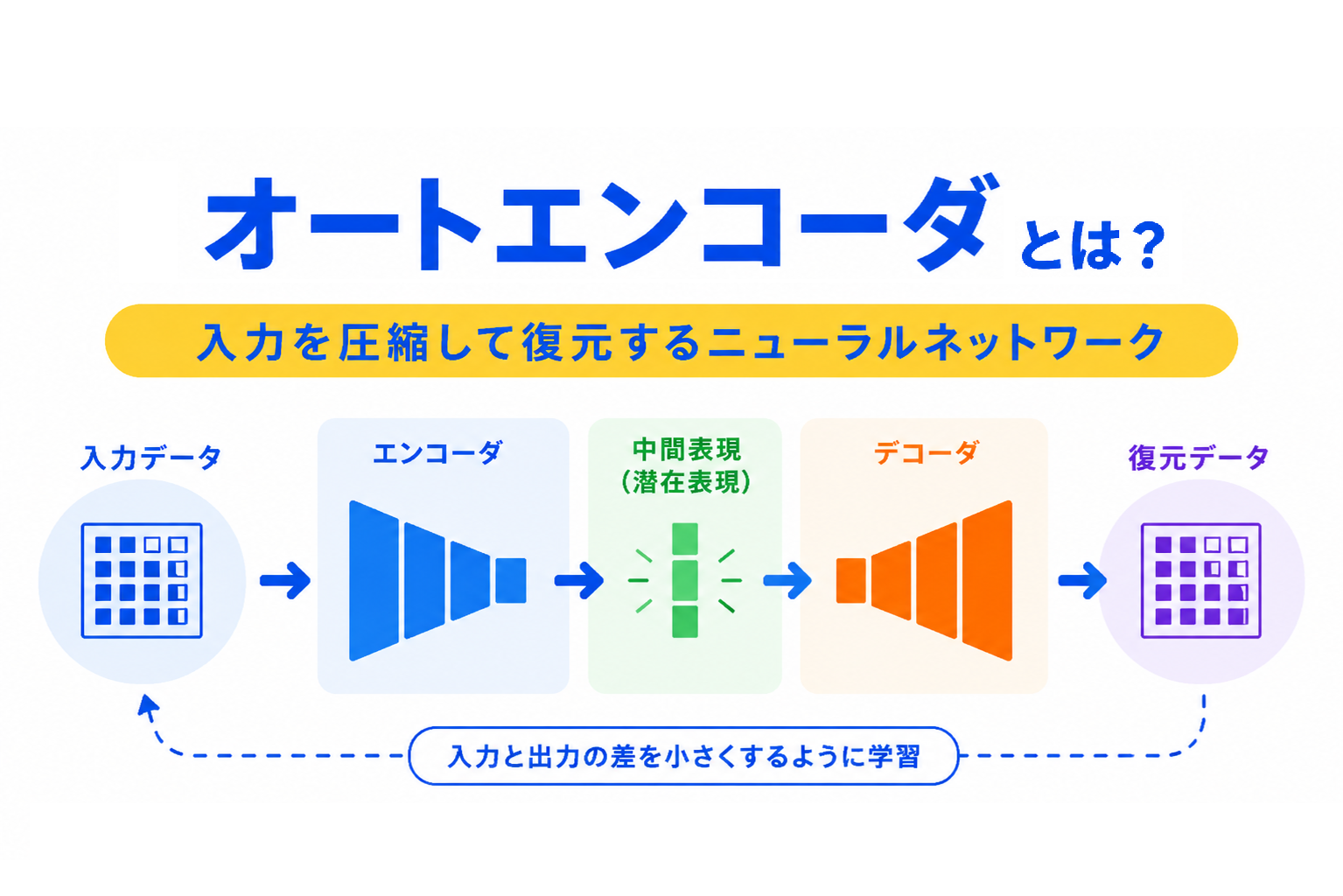
【G検定対策】オートエンコーダとは?|入力を圧縮して復元するニューラルネットワークをわかりやすく整理
seo-webmaster
G検定対策ブログ
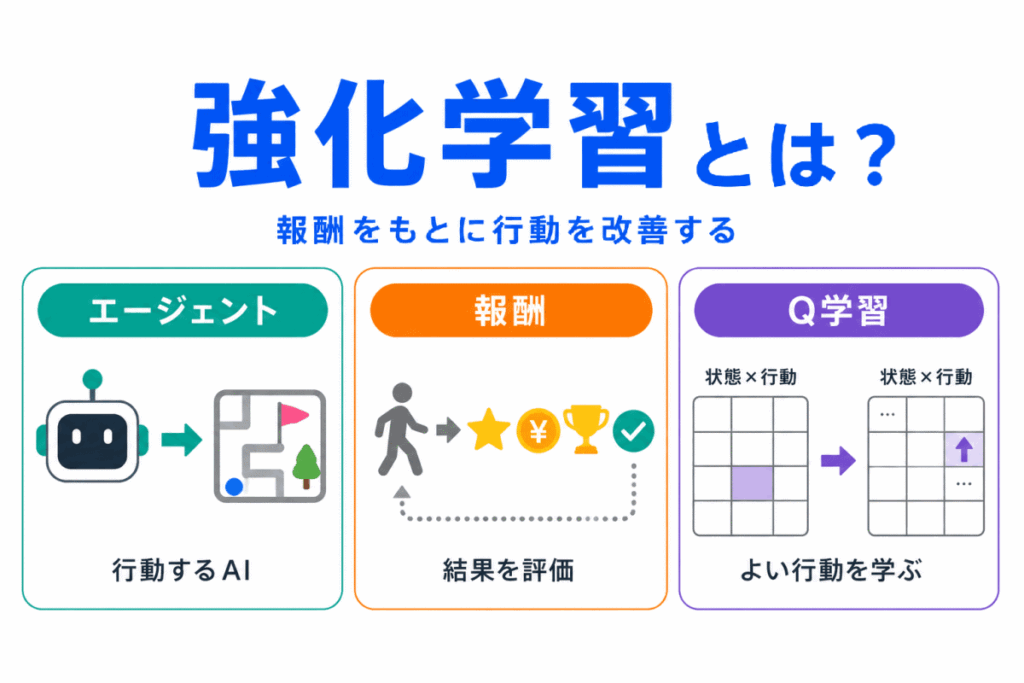
強化学習とは、AIが行動を試し、その結果として得られる報酬をもとに、よりよい行動を学んでいく方法です。
教師あり学習のように、最初から正解ラベルが用意されているわけではありません。また、教師なし学習のように、データのまとまりを見つけることが主な目的でもありません。
強化学習では、AIが環境の中で行動し、その結果を見ながら少しずつ行動を改善していきます。
G検定では、エージェント・環境・状態・行動・報酬・方策・価値関数などの用語が混同されやすいため、まずは全体の流れで整理することが大切です。
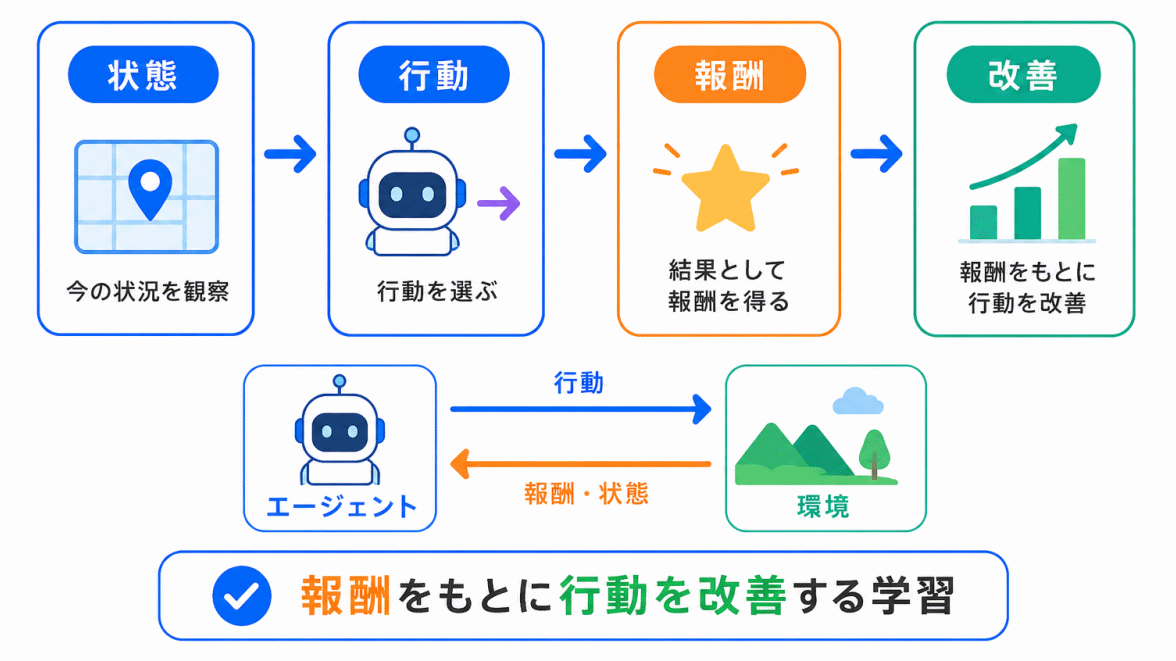
強化学習は、報酬をもとに行動を改善する学習方法です。
イメージとしては、AIが何かを試し、その結果がよければその行動を選びやすくなり、結果が悪ければ別の行動を選ぶように調整していきます。
| 用語 | 一言でいうと |
|---|---|
| エージェント | 行動するAI |
| 環境 | エージェントが行動する場所 |
| 状態 | 今の状況 |
| 行動 | エージェントが選ぶ動き |
| 報酬 | 行動の結果として得られる評価 |
| 方策 | どの状態でどの行動を選ぶかのルール |
| 価値関数 | どの行動や状態がよさそうかを評価する考え方 |
重要な整理は、次の流れです。
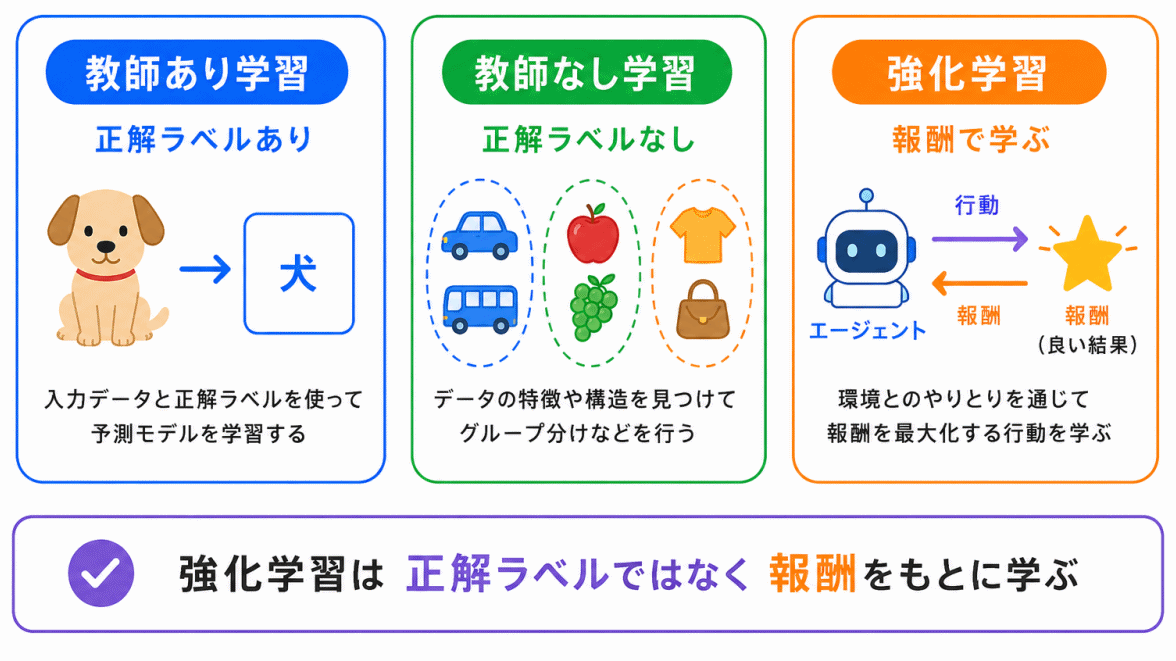
強化学習は、教師あり学習や教師なし学習と並ぶ、機械学習の代表的な学習方法です。
| 学習方法 | 何をもとに学ぶか | 目的 |
|---|---|---|
| 教師あり学習 | 正解ラベル | 正解に近い予測をする |
| 教師なし学習 | 正解ラベルなしのデータ | データの構造を見つける |
| 強化学習 | 報酬 | よい行動を選べるようにする |
教師あり学習は、あらかじめ正解がある状態で学習します。
教師なし学習は、正解ラベルなしでデータの特徴やまとまりを見つけます。
強化学習は、行動した結果として得られる報酬をもとに学習します。
強化学習=正解を教わるのではなく、報酬をもとに行動を改善する学習
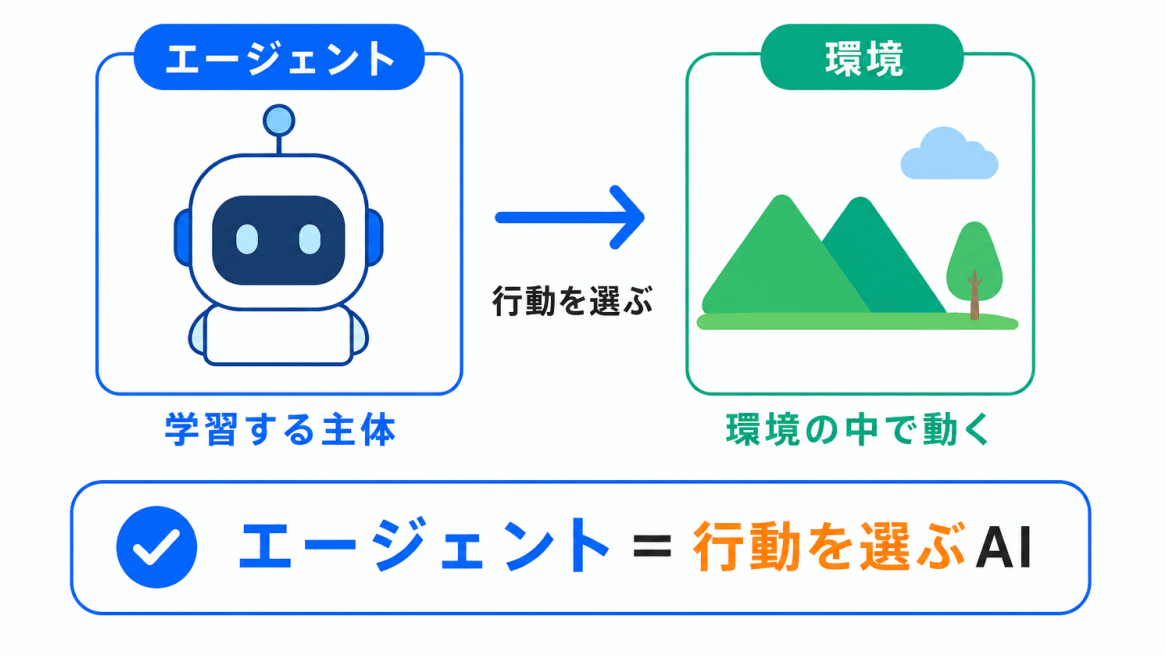
エージェントとは、環境の中で行動する主体のことです。
強化学習では、AIやロボット、ゲーム内のプレイヤーのように、何かしらの行動を選ぶ存在をエージェントと呼びます。
| 用語 | 役割 |
|---|---|
| エージェント | 行動を選ぶ |
| 環境 | 行動の結果を返す |
たとえば、ゲームAIであれば、エージェントはゲーム内で操作を選ぶAIです。
右に進む、ジャンプする、攻撃する、といった行動を選び、その結果として報酬を受け取ります。
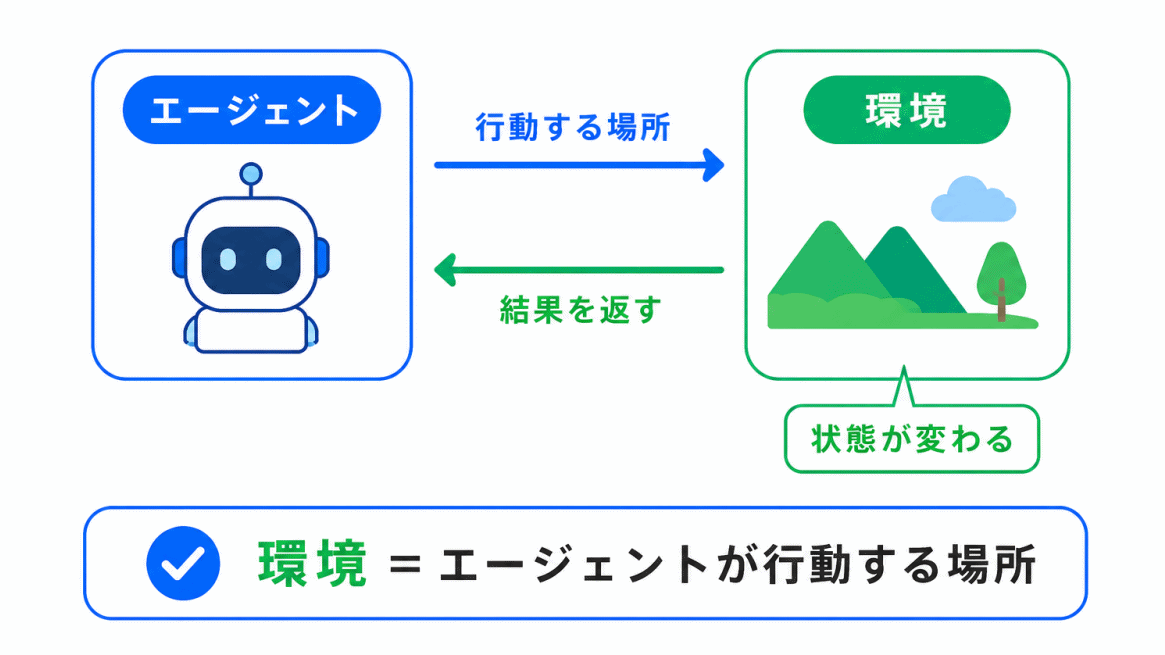
環境とは、エージェントが行動する対象や場所のことです。
エージェントが行動すると、環境はその結果を返します。
たとえば、ゲームであればゲーム画面やルールが環境です。ロボットであれば、ロボットが動く現実世界やシミュレーション空間が環境になります。
| 例 | 環境 |
|---|---|
| ゲームAI | ゲームの世界 |
| ロボット | 動く場所や周囲の状況 |
| 自動運転 | 道路や交通状況 |
エージェントは環境の中で行動し、その結果として状態が変わったり、報酬を受け取ったりします。
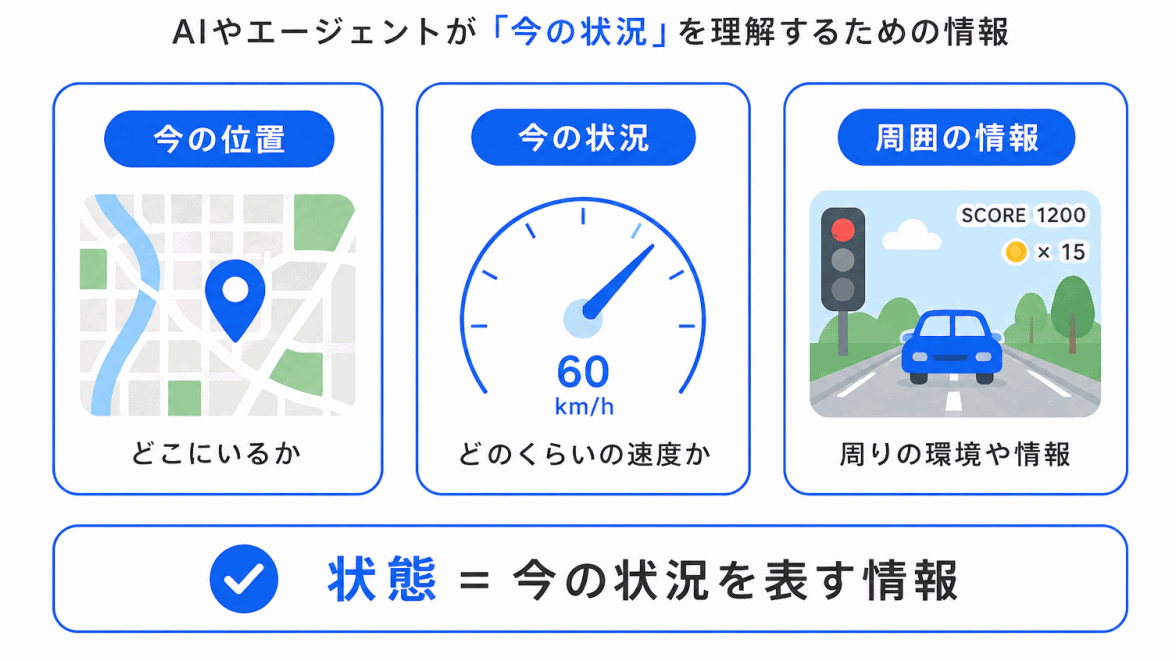
状態とは、エージェントが今置かれている状況のことです。
強化学習では、エージェントは現在の状態を見て、次にどの行動を選ぶかを決めます。
たとえば、ゲームであれば、敵の位置、残り時間、自分の場所などが状態になります。
| 例 | 状態のイメージ |
|---|---|
| ゲーム | 自分や敵の位置 |
| ロボット | 現在の姿勢や周囲の状況 |
| 自動運転 | 車線、速度、周囲の車 |
状態が変われば、選ぶべき行動も変わります。
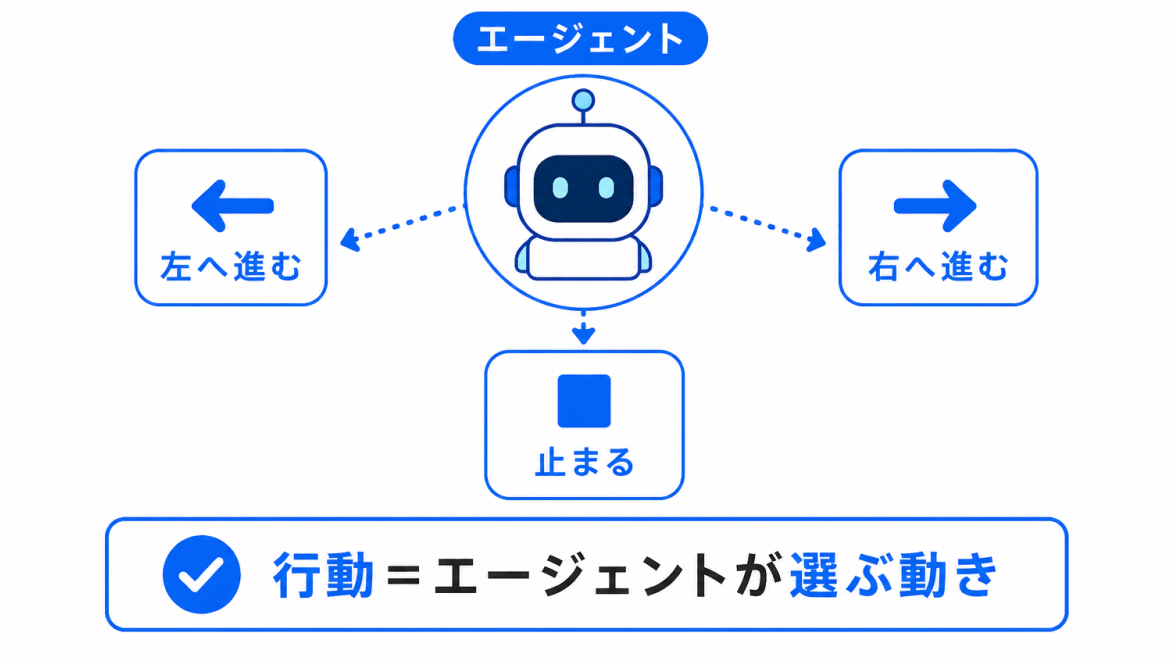
行動とは、エージェントが選ぶ動きや選択のことです。
エージェントは、状態を見て行動を選びます。
たとえば、ゲームAIであれば、右に進む、左に進む、ジャンプする、攻撃するなどが行動です。
| 例 | 行動 |
|---|---|
| ゲームAI | 移動する、攻撃する |
| ロボット | 曲がる、進む、止まる |
| 自動運転 | 加速する、減速する、車線変更する |
強化学習では、この行動の選び方を少しずつ改善していきます。
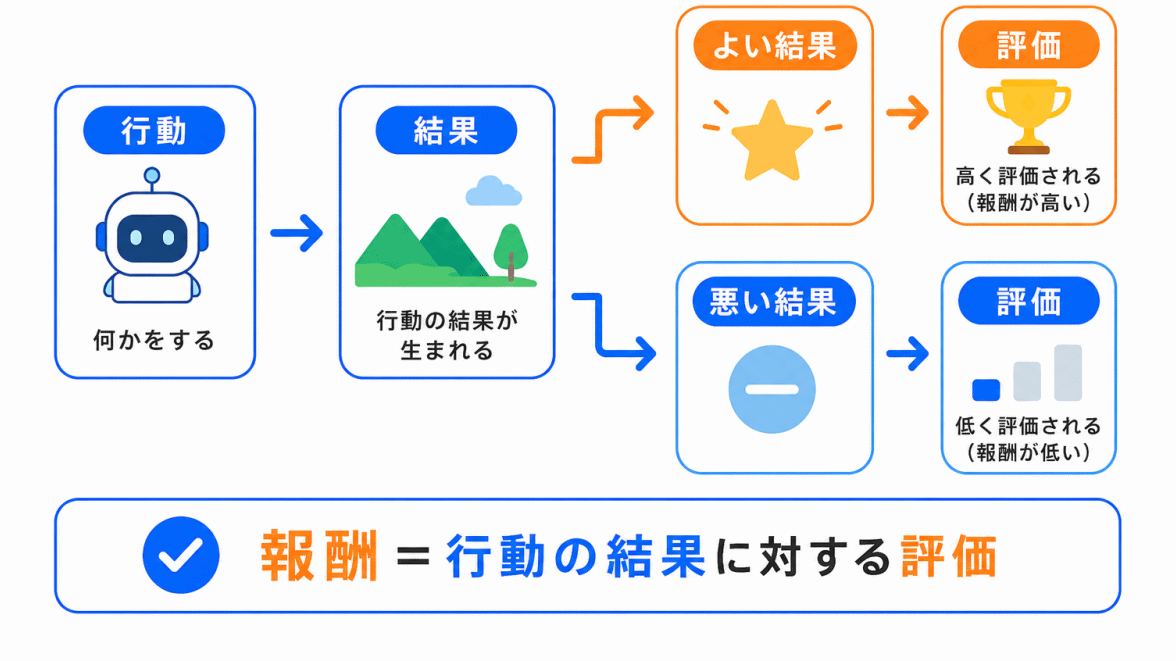
報酬とは、行動の結果として得られる評価のことです。
よい結果につながる行動にはプラスの報酬が与えられ、よくない結果につながる行動には小さい報酬やマイナスの報酬が与えられます。
| 行動の結果 | 報酬のイメージ |
|---|---|
| 目標に近づく | プラスの報酬 |
| 失敗する | マイナスの報酬 |
| 何も進まない | 小さい報酬 |
強化学習では、エージェントが報酬を最大化するように行動を改善していきます。
ただし、報酬は「すぐにもらえる評価」だけではありません。長い目で見てよい結果につながる行動を選ぶことも重要です。
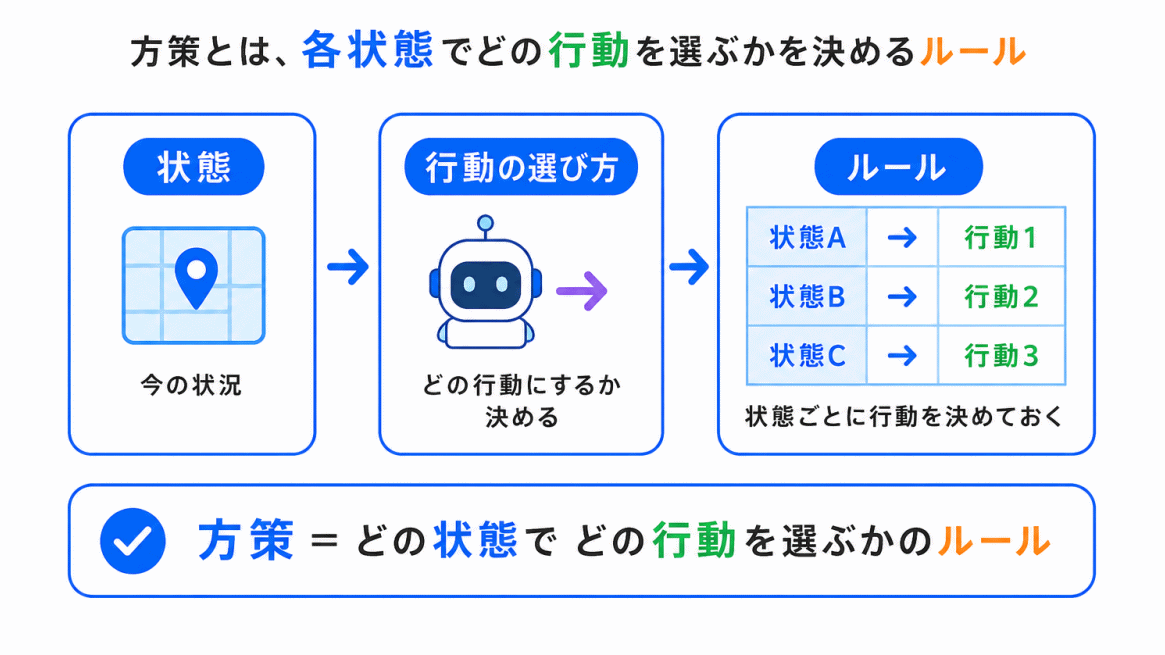
方策とは、どの状態でどの行動を選ぶかのルールです。
エージェントは、状態を見て行動を選びます。この行動の選び方が方策です。
| 状態 | 行動 |
|---|---|
| 敵が近い | 逃げる |
| ゴールが近い | 進む |
| 障害物がある | 避ける |
強化学習では、報酬をもとに、この方策をよりよいものにしていきます。
G検定では、方策は「行動を選ぶルール」として整理すると理解しやすいです。
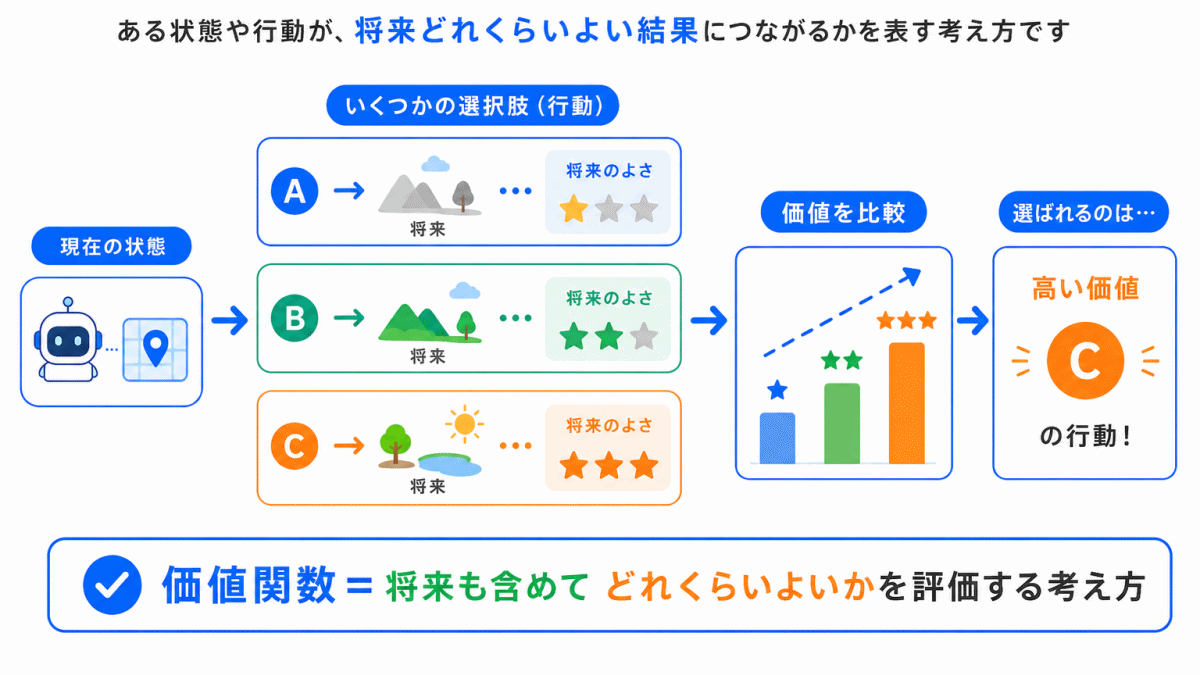
価値関数とは、ある状態や行動がどれくらいよさそうかを評価する考え方です。
強化学習では、今すぐの報酬だけでなく、将来的にどれくらいよい結果につながるかも考えます。
たとえば、すぐには報酬が少なくても、後で大きな報酬につながる行動があるかもしれません。
| 見方 | 意味 |
|---|---|
| 今の報酬 | すぐにもらえる評価 |
| 将来の報酬 | 後で得られる可能性のある評価 |
| 価値 | 長い目で見たよさ |
価値関数は、どの状態や行動を選ぶと将来的によさそうかを判断するために使われます。
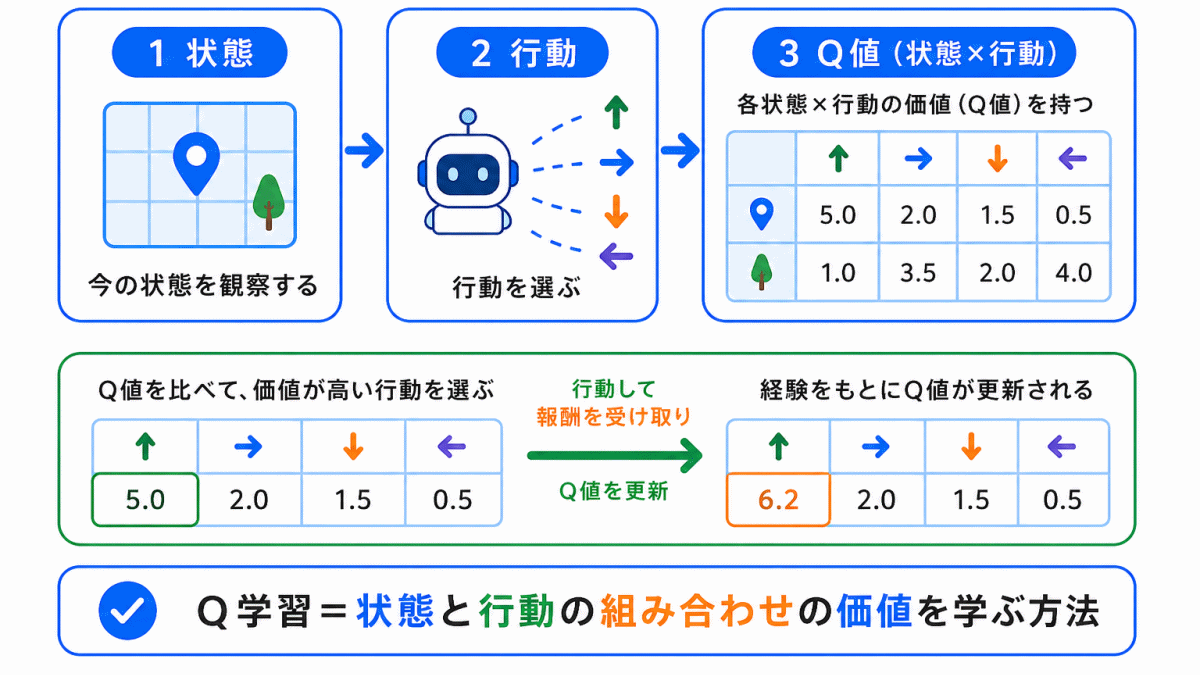
Q学習とは、強化学習の代表的な手法のひとつです。
Q学習では、ある状態である行動を選んだときに、どれくらいよい結果につながりそうかを学習します。
| 用語 | 一言でいうと |
|---|---|
| Q値 | 状態と行動の組み合わせのよさ |
| Q学習 | Q値を更新しながらよい行動を学ぶ方法 |
たとえば、ある場所にいるときに「右へ進む」、「左へ進む」、「止まる」のどれがよさそうかを、経験を通じて学習していきます。
G検定対策では、細かい計算式よりも、次の整理で押さえると十分です。
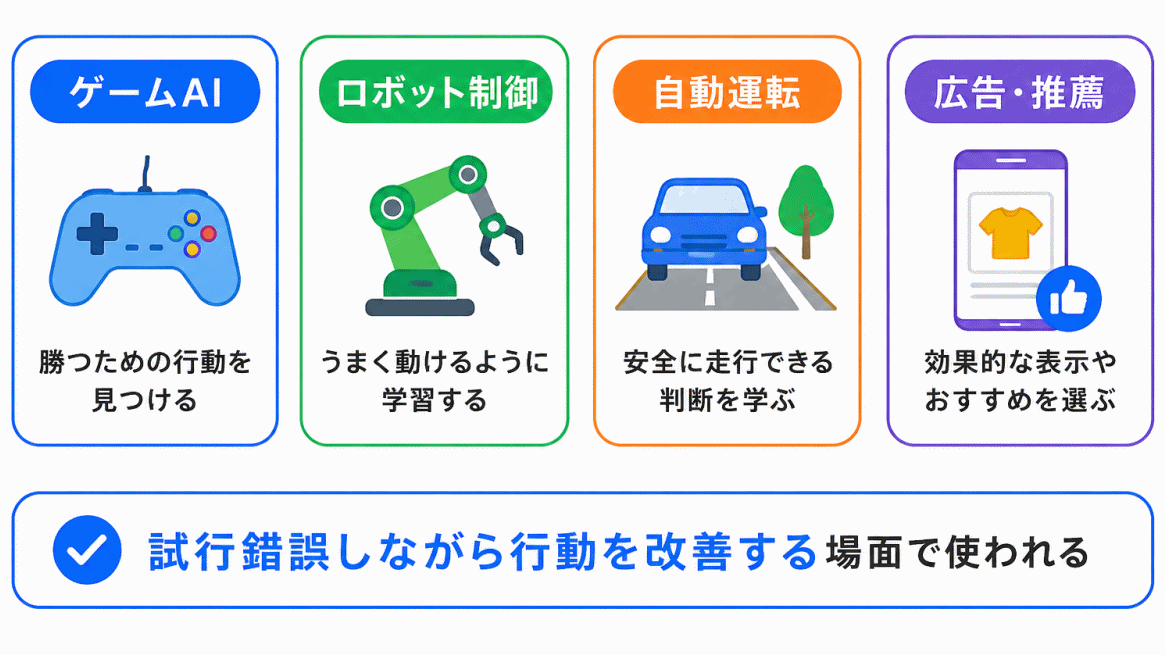
強化学習は、行動を試しながら改善する場面で使われます。
| 例 | 何を学ぶか |
|---|---|
| ゲームAI | 勝ちやすい行動 |
| ロボット制御 | うまく動く方法 |
| 自動運転 | 安全な運転行動 |
| 広告配信 | 反応がよい表示方法 |
ただし、現実の場面では、強化学習だけですべてを解決するわけではありません。
安全性やコストの問題があるため、シミュレーション環境で学習したり、ほかの機械学習手法と組み合わせたりすることもあります。
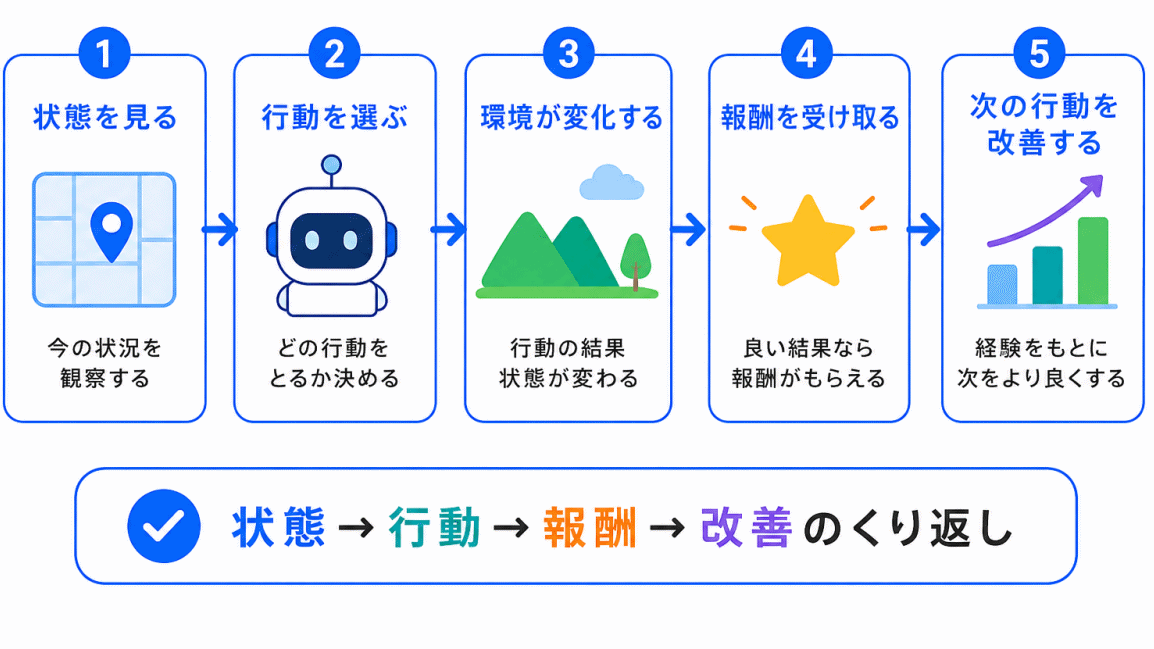
強化学習は、次のような流れで進みます。
この流れをくり返すことで、エージェントはよりよい行動を選べるようになります。
重要なのは、強化学習では「正解をそのまま教える」のではなく、行動の結果を見て学習することです。
| ステップ | 内容 |
|---|---|
| 状態を見る | 今の状況を確認する |
| 行動を選ぶ | 次に何をするか決める |
| 報酬を受け取る | 行動の結果を評価する |
| 改善する | 次の行動選びに反映する |
G検定では、強化学習の細かい数式よりも、用語の関係が問われやすいです。
| 問われ方 | 選ぶ用語 |
|---|---|
| 行動する主体 | エージェント |
| エージェントが行動する場所 | 環境 |
| 今の状況 | 状態 |
| エージェントが選ぶ動き | 行動 |
| 行動の結果として得られる評価 | 報酬 |
| 行動を選ぶルール | 方策 |
| 状態や行動のよさを評価する考え方 | 価値関数 |
| 状態と行動の組み合わせの価値を学ぶ手法 | Q学習 |
特に、方策と価値関数は混同しやすいです。
方策は、どの行動を選ぶかのルールです。
価値関数は、その状態や行動がどれくらいよさそうかを評価する考え方です。
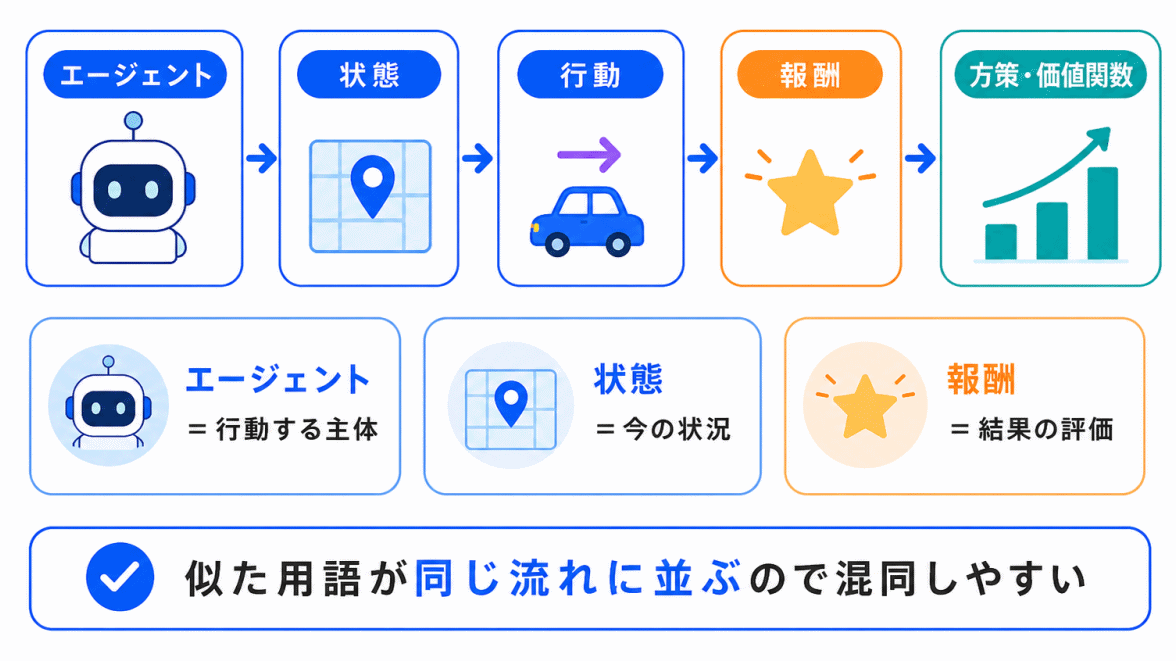
強化学習が混同しやすい理由は、似た用語が一つの流れの中にまとめて出てくるからです。
| 混同しやすいもの | 違い |
|---|---|
| エージェント | 行動する主体 |
| 環境 | 行動する場所 |
| 状態 | 今の状況 |
| 行動 | 選ぶ動き |
| 報酬 | 行動結果の評価 |
| 方策 | 行動の選び方 |
| 価値関数 | 状態や行動のよさの評価 |
用語だけを暗記すると、エージェント・環境・状態・行動・報酬がバラバラに見えます。
しかし、流れで見ると整理しやすくなります。
この一文で整理すると、強化学習の全体像がつかみやすくなります。
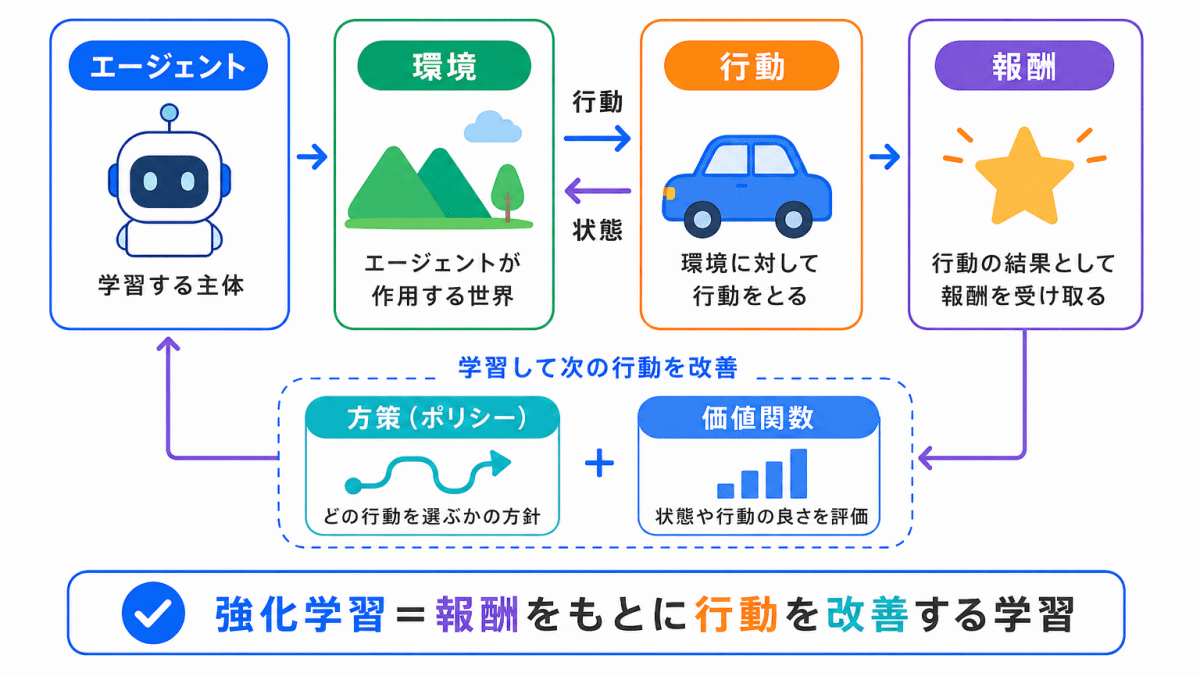
強化学習は、エージェントが環境の中で行動し、その結果として得られる報酬をもとに、よりよい行動を学んでいく方法です。
教師あり学習は正解ラベルをもとに学習します。
教師なし学習は正解ラベルなしでデータの構造を見つけます。
強化学習は、行動の結果として得られる報酬をもとに学習します。
G検定では、次の関係を整理しておくことが大切です。
強化学習は、細かい計算よりも、まずは「報酬をもとに行動を改善する学習」として理解すると整理しやすくなります。
強化学習を理解するときは、教師あり学習・教師なし学習との違いもあわせて整理しておくと、機械学習全体の中での位置づけがわかりやすくなります。
関連する記事もあわせて確認しておきましょう。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 深層強化学習とは? | 強化学習/DQN/Q学習/AlphaGo/探索との関係 |
| 教師あり・教師なし・強化学習の違い | 正解ラベルを使う学習/正解なしで構造を見る学習/報酬で行動を改善する学習 |
| 教師あり学習と教師なし学習 | 正解データの有無/分類・回帰との関係/クラスタリングとの違い |
| 教師あり学習の代表的なアルゴリズム | 分類・回帰の考え方/決定木・SVM・ランダムフォレスト/どう予測するかの違い |
| 教師なし学習の代表的な手法 | クラスタリング/次元削減・PCA/正解ラベルなしで特徴を見つける方法 |
| 機械学習とディープラーニングの違い | 機械学習とディープラーニングの関係/学習方法との違い/特徴量設計の考え方 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。