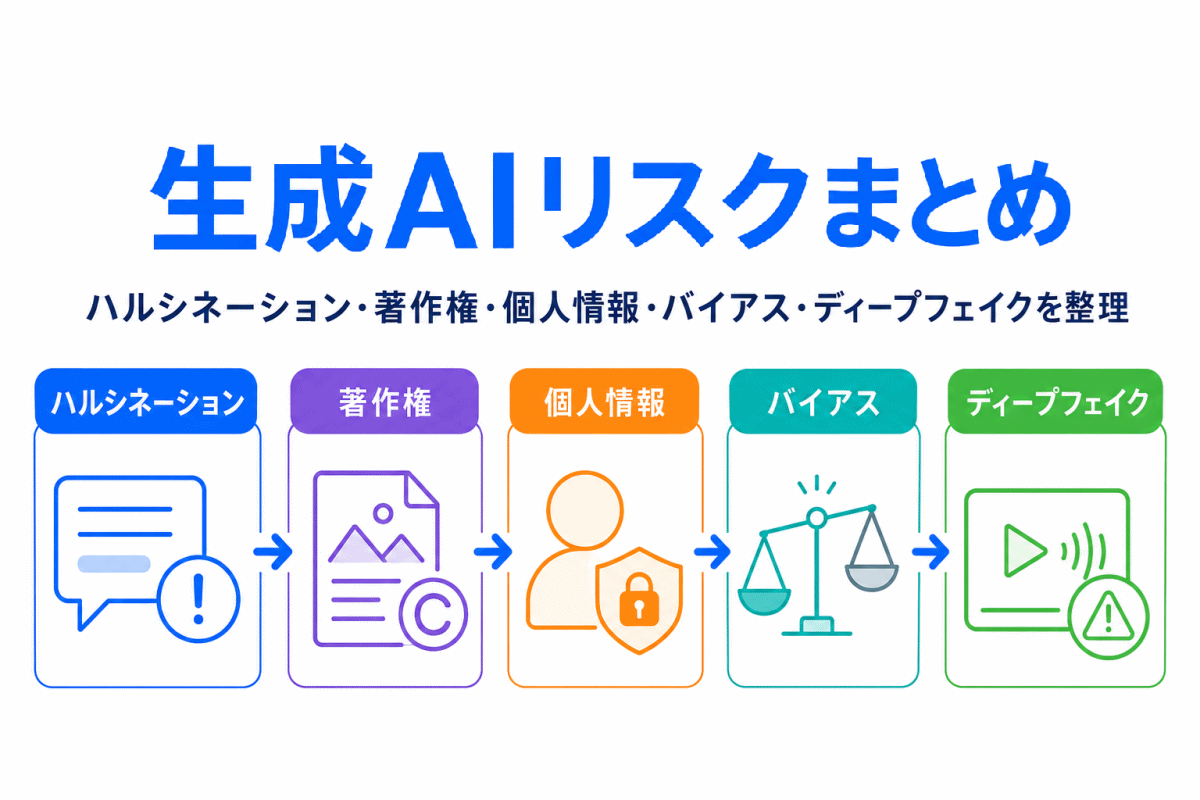
【G検定対策】確率分布とは?|正規分布・二項分布・ベルヌーイ分布・ポアソン分布をわかりやすく整理
seo-webmaster
SEO・ウェブマスターブログ
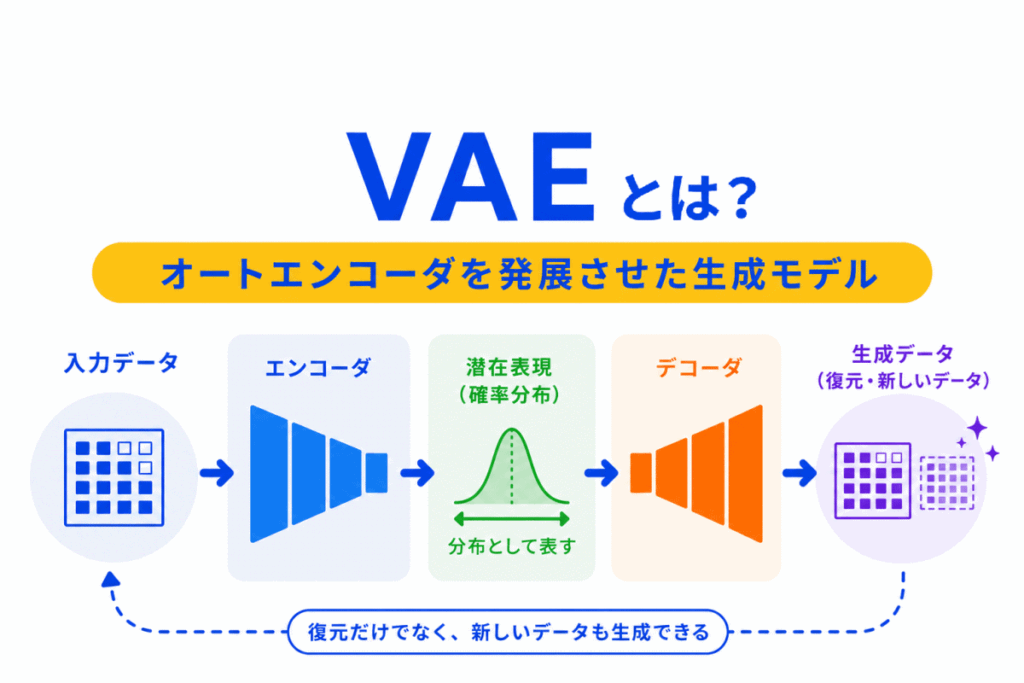
VAEとは、オートエンコーダの考え方を発展させた生成モデルです。
オートエンコーダは、入力データを一度小さな表現に圧縮し、そこから元のデータに近い形へ復元するモデルです。
一方、VAEでは、圧縮された表現を1つの固定された値として扱うのではなく、「このあたりにありそう」という確率的な分布として扱います。
そのため、VAEは入力を復元するだけでなく、新しいデータを生成する考え方にもつながります。
G検定では、VAEを細かい数式で覚えるよりも、オートエンコーダとの関係、潜在表現、生成モデル、GANとの違いを押さえることが大切です。
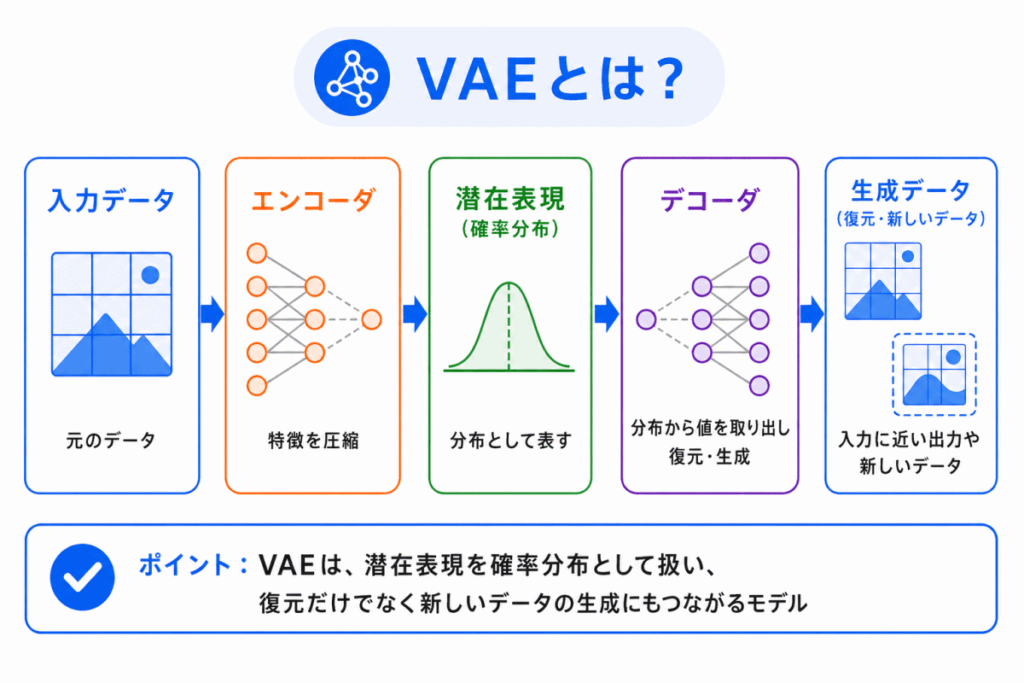
VAEは、Variational Autoencoderの略です。
日本語では、変分オートエンコーダと呼ばれます。
VAEは、オートエンコーダの仕組みをもとにしたモデルです。
オートエンコーダと同じように、VAEにもエンコーダとデコーダがあります。
ただし、VAEでは、圧縮された表現をそのまま1つの値として扱うのではなく、確率的な分布として扱います。
この考え方によって、VAEはデータの復元だけでなく、新しいデータの生成にも使えるようになります。
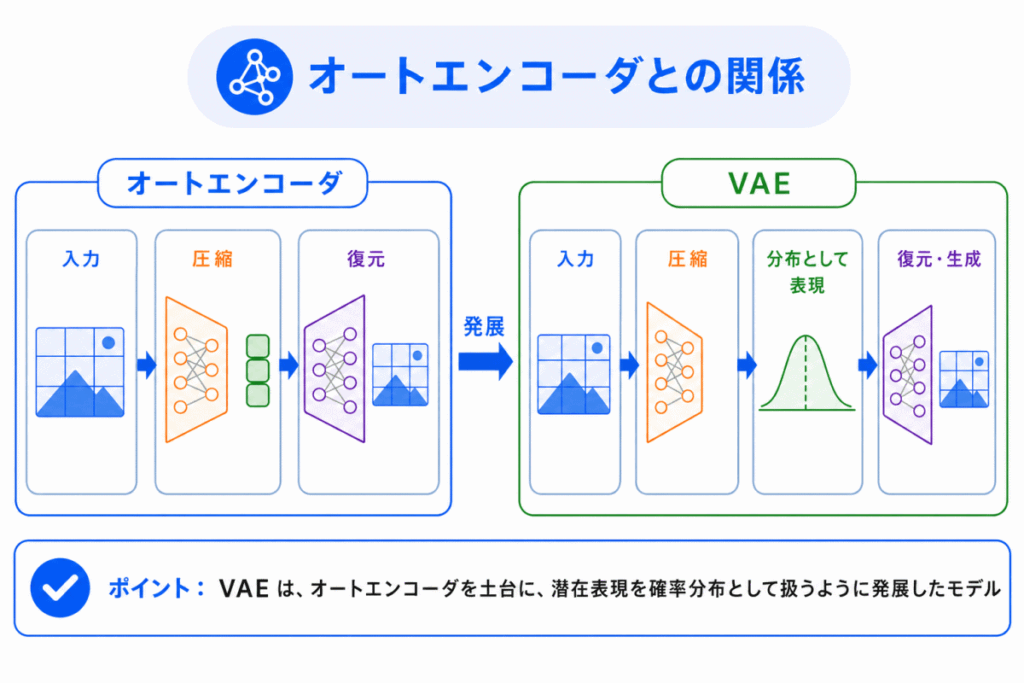
VAEを理解するには、まずオートエンコーダとの関係を押さえるとわかりやすいです。
オートエンコーダは、入力を圧縮して復元するモデルです。
VAEは、その圧縮された表現を確率的に扱うように発展させたモデルです。
流れで整理すると、次のようになります。
通常のオートエンコーダでは、入力データは中間表現に圧縮されます。
VAEでは、その中間表現を「点」ではなく「範囲」として考えます。
この「範囲」として考える部分が、VAEの大きな特徴です。
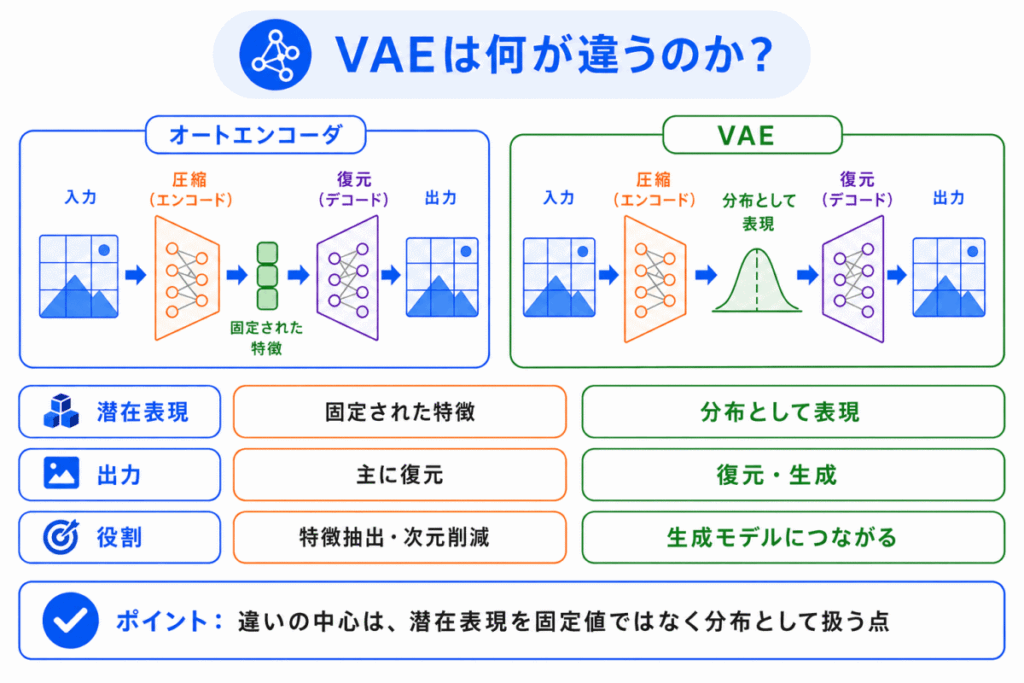
通常のオートエンコーダとVAEの違いは、潜在表現の扱い方にあります。
通常のオートエンコーダは、入力を決まった中間表現に圧縮します。
VAEは、入力を潜在空間上の確率分布として表します。
| 項目 | オートエンコーダ | VAE |
|---|---|---|
| 基本の考え方 | 入力を圧縮して復元する | 入力を確率的な潜在表現に変換して復元・生成する |
| 潜在表現 | 1つの固定された表現として扱う | 確率分布として扱う |
| 主な役割 | 特徴抽出、次元削減、異常検知など | 特徴学習、データ生成、潜在空間の活用など |
| 生成モデルとの関係 | 生成モデルとしては扱いにくい | 生成モデルとして使いやすい |
VAEは、オートエンコーダの「圧縮して復元する」という考え方を保ちながら、潜在表現を確率的に扱うことで生成モデルに近づいたものです。
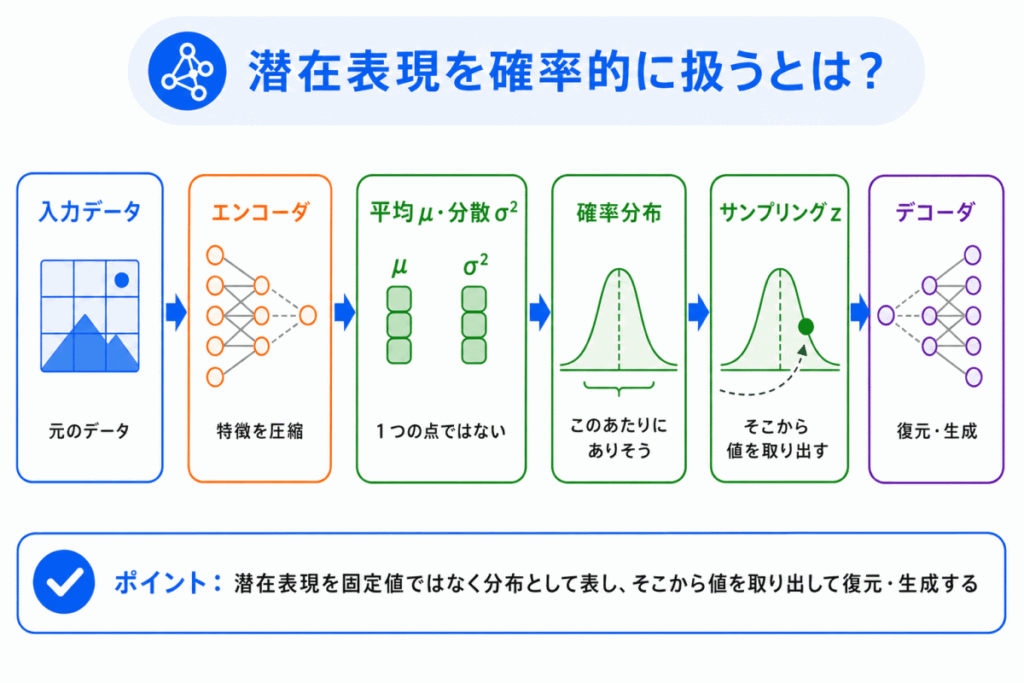
VAEで大切なのは、潜在表現を確率的に扱うという考え方です。
通常のオートエンコーダでは、入力データをエンコーダに通すと、1つの中間表現が得られます。
たとえば、ある画像を入力したら、その画像を表す特徴が1つの点のように表されます。
一方、VAEでは、入力データを1つの点に変換するのではなく、「このあたりにありそう」という分布として表します。
もう少し言うと、VAEのエンコーダは、潜在表現そのものではなく、潜在表現を生み出すための分布を出力します。
G検定対策としては、次の理解で十分です。
VAEは、圧縮された特徴を1つの固定値として扱うのではなく、確率的なゆらぎを持つ表現として扱う。
この確率的なゆらぎがあるため、VAEは新しいデータを生成しやすくなります。
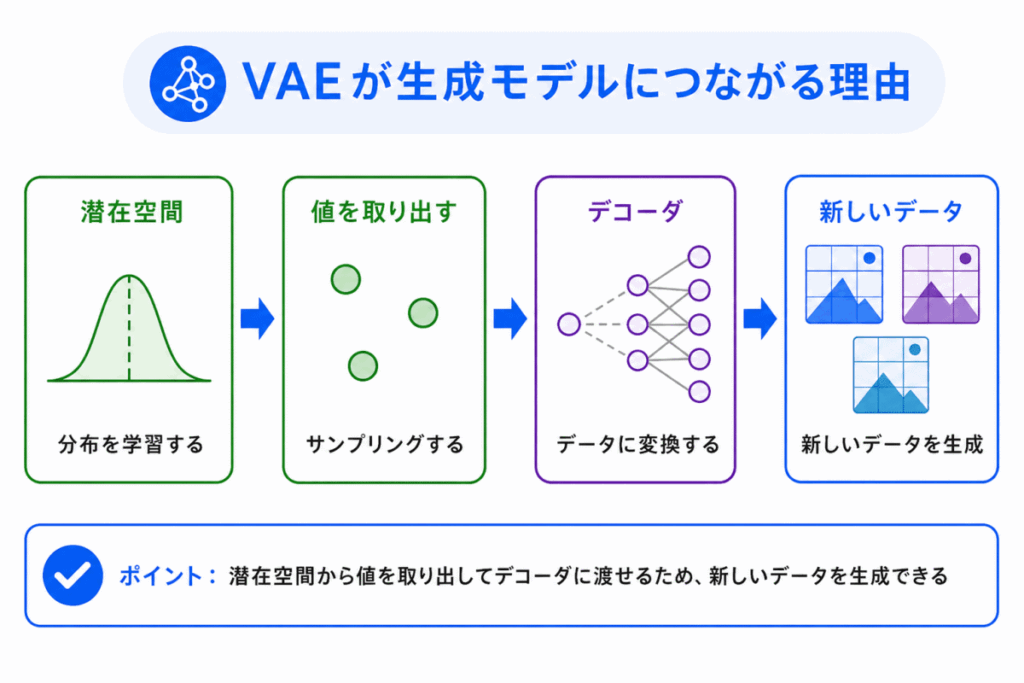
VAEが生成モデルにつながる理由は、潜在空間から新しい値を取り出し、それをデコーダに渡せるからです。
通常のオートエンコーダは、入力されたデータを復元することが中心です。
しかしVAEでは、潜在表現を確率分布として学習します。
そのため、学習後に潜在空間から値を取り出し、デコーダに渡すことで、新しいデータらしいものを生成できます。
たとえば、画像データを学習したVAEであれば、潜在空間から値を取り出して、学習データに似た新しい画像を生成できます。
ここで重要なのは、完全に丸暗記した画像を出すのではなく、学習したデータの特徴をもとに、それらしいデータを作るという点です。
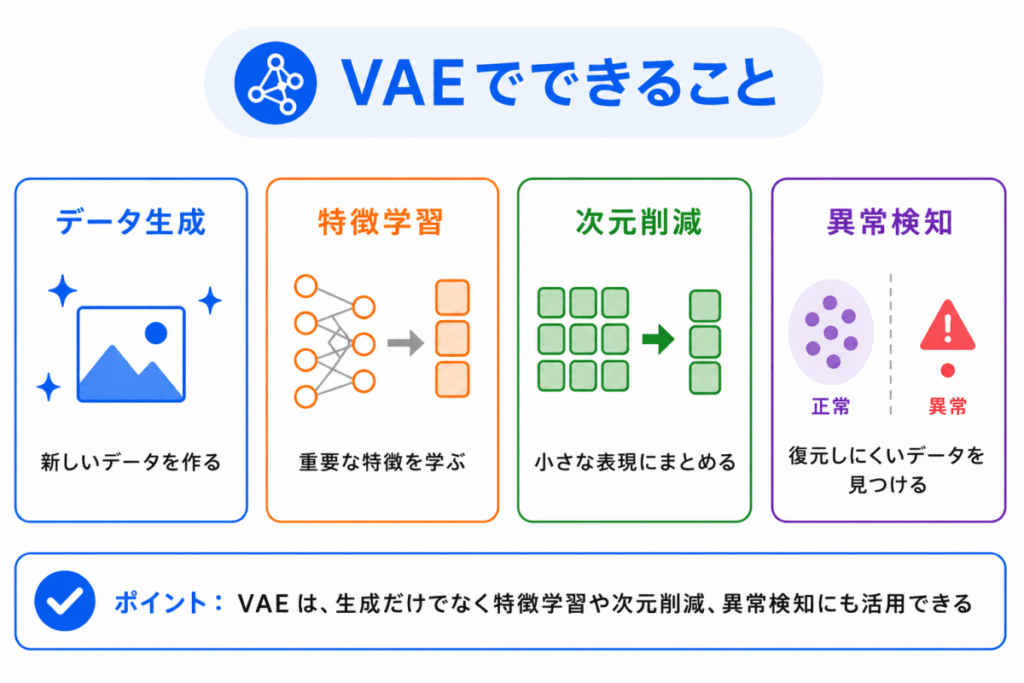
VAEは、データの特徴を確率的に学習するため、いくつかの用途に使われます。
代表的な用途は、次のように整理できます。
| 用途 | 説明 |
|---|---|
| データ生成 | 学習した特徴をもとに、新しいデータらしいものを生成する |
| 特徴学習 | データの重要な特徴を、潜在表現として学習する |
| 次元削減 | 高次元のデータを、低次元の潜在表現にまとめる |
| 異常検知 | うまく復元できないデータを、通常と異なるデータとして扱う |
VAEは、生成AIを理解するうえでも重要な考え方です。
ただし、現在よく話題になる文章生成AIや画像生成AIのすべてがVAEで動いているわけではありません。
G検定では、VAEを「生成モデルの一種」として整理しておくと理解しやすくなります。
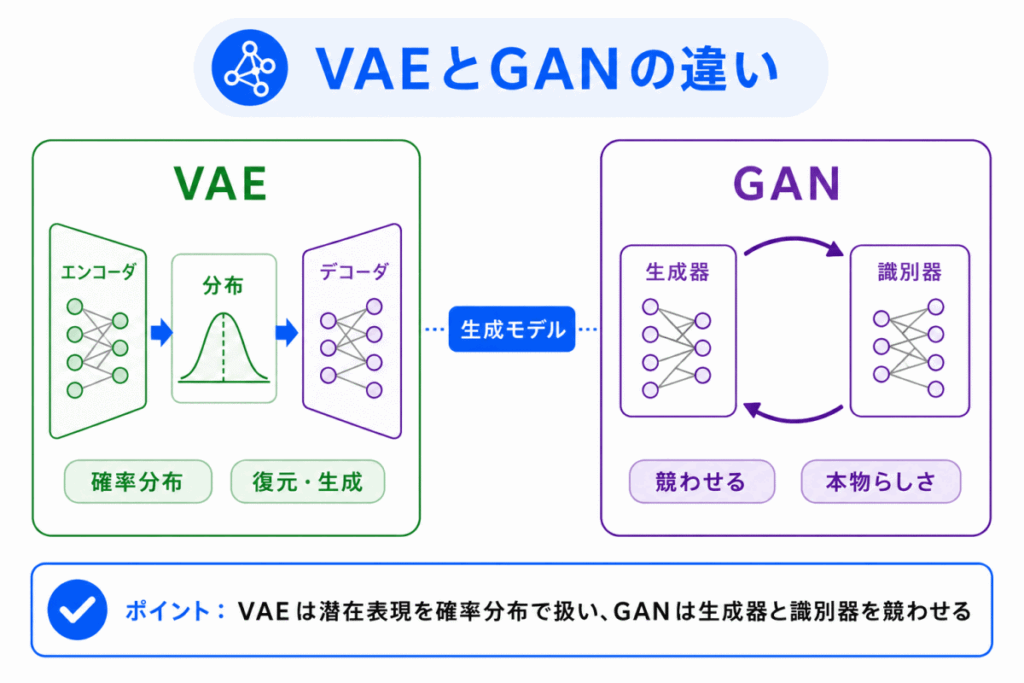
VAEとGANは、どちらも生成モデルとして扱われます。
ただし、仕組みは大きく異なります。
VAEは、オートエンコーダの流れをもとにして、潜在表現を確率的に扱うモデルです。
GANは、生成器と識別器を競わせることで、本物らしいデータを生成するモデルです。
| 項目 | VAE | GAN |
|---|---|---|
| 基本構造 | エンコーダとデコーダを使う | 生成器と識別器を使う |
| 学習の考え方 | 潜在表現を確率的に学習し、データを復元・生成する | 生成器と識別器を競わせて、本物らしいデータを作る |
| オートエンコーダとの関係 | オートエンコーダの発展形として整理できる | オートエンコーダとは別の考え方で整理される |
| 押さえ方 | 潜在表現と確率分布が重要 | 生成器と識別器の競争が重要 |
G検定では、VAEとGANをどちらも生成モデルとして覚えるだけでは不十分です。
VAEは「オートエンコーダの発展形」、GANは「生成器と識別器を競わせるモデル」と区別しておくことが大切です。
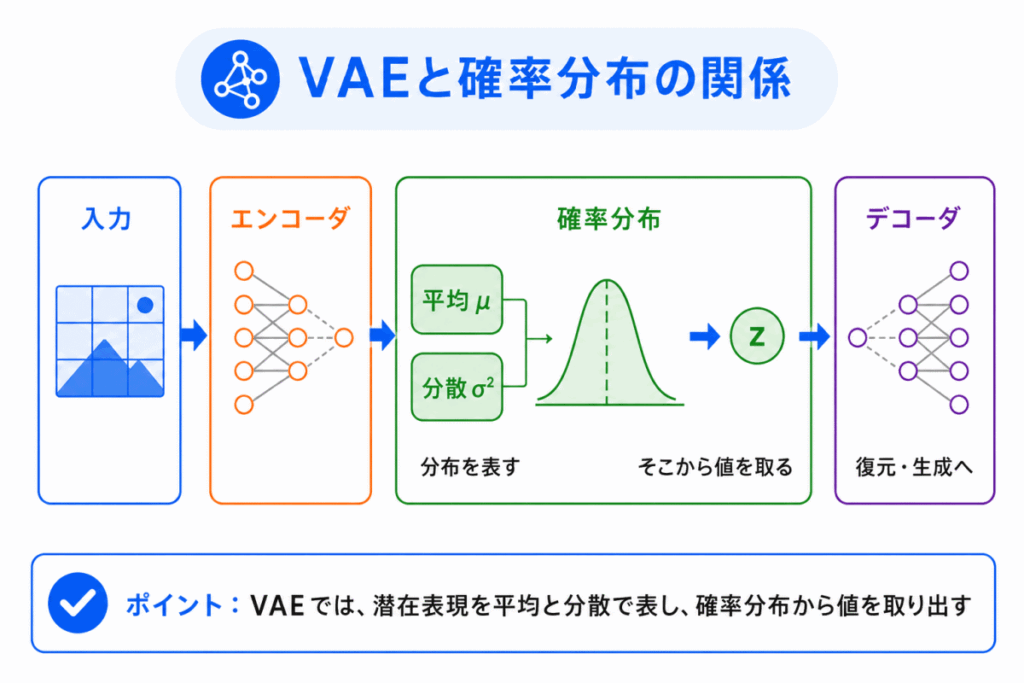
VAEでは、潜在表現を確率分布として扱います。
そのため、確率分布の考え方と関係があります。
ただし、G検定対策では、細かい数式を深く追いかけすぎる必要はありません。
大切なのは、次の考え方です。
通常のオートエンコーダは、入力を1つの中間表現に圧縮する。
VAEは、入力を確率分布として表し、その分布から値を取り出して復元や生成を行う。
この違いを理解しておくと、VAEがなぜ生成モデルにつながるのかが見えやすくなります。
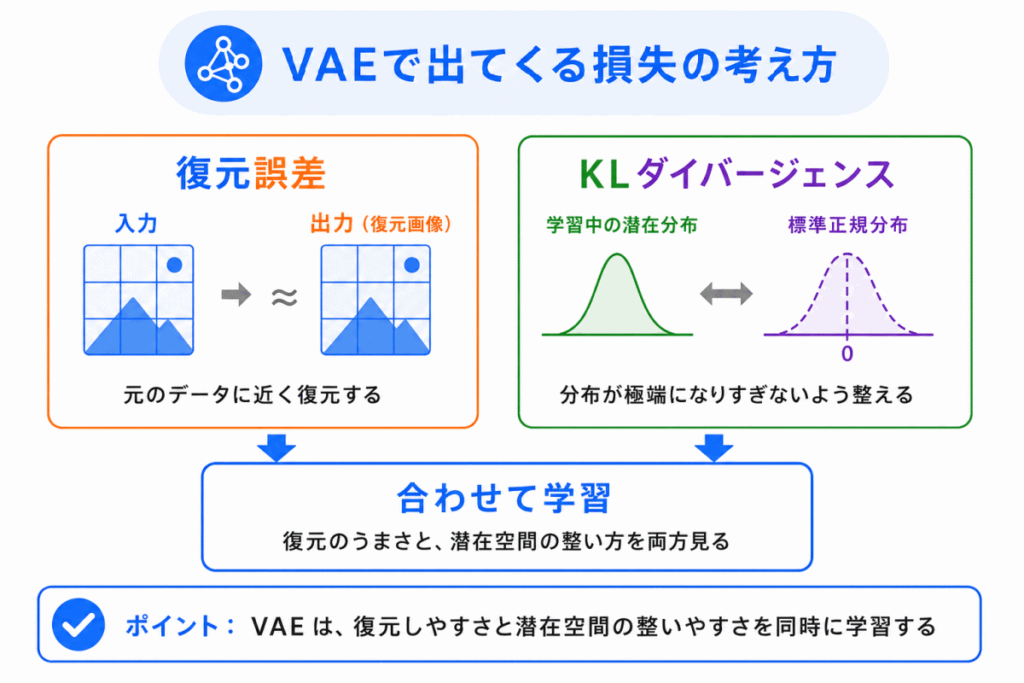
VAEの学習では、大きく2つの方向からモデルを調整します。
1つ目は、入力データをうまく復元できるようにすることです。
2つ目は、潜在表現の分布が極端になりすぎないように整えることです。
専門的には、復元誤差やKLダイバージェンスといった言葉が出てきます。
ただし、AIの学習をはじめたばかりの人は、まず次のように理解すれば十分です。
VAEは、元のデータに近く復元することと、扱いやすい潜在空間を作ることを同時に学習している。
細かい式よりも、「復元」と「確率分布を整える」という2つの方向を押さえておくとよいです。
G検定では、VAEの数式を細かく計算するよりも、関連用語との違いが問われやすいです。
特に、オートエンコーダ、潜在表現、生成モデル、GANとの関係を整理しておきましょう。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| VAEとは何か | オートエンコーダを発展させ、潜在表現を確率的に扱う生成モデル |
| オートエンコーダとの違い | 通常のオートエンコーダは固定的な中間表現、VAEは確率分布として潜在表現を扱う |
| 生成モデルとの関係 | 潜在空間から値を取り出し、デコーダで新しいデータを生成できる |
| GANとの違い | VAEはエンコーダ・デコーダ型、GANは生成器・識別器型 |
VAEは、単独で暗記するよりも、オートエンコーダから生成モデルへつながる橋渡しとして理解すると覚えやすいです。
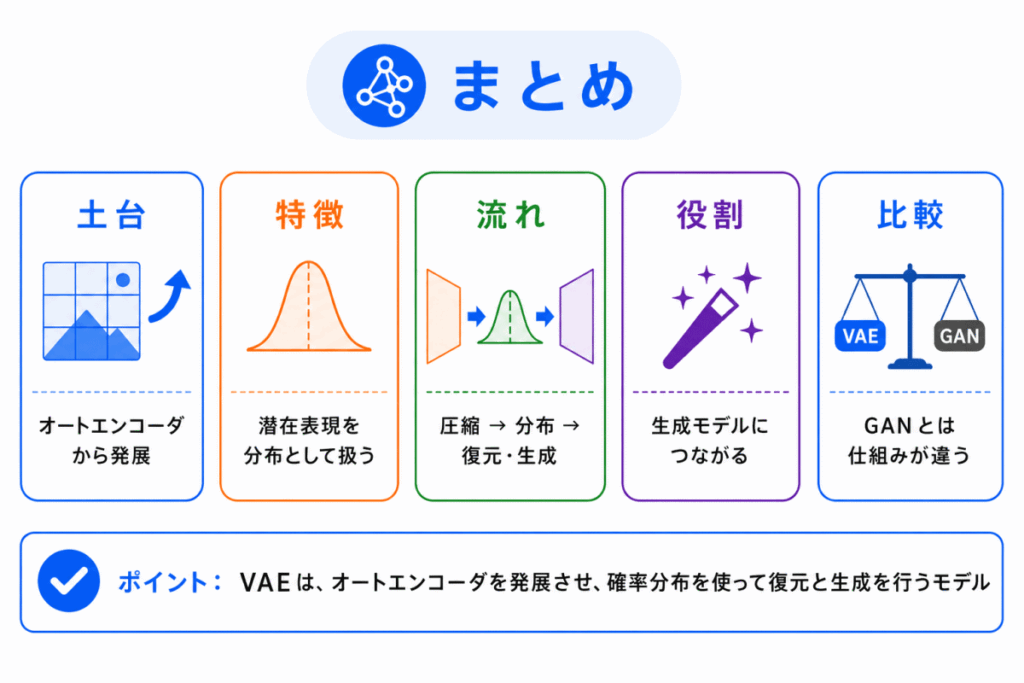
VAEは、オートエンコーダの考え方を発展させた生成モデルです。
通常のオートエンコーダは、入力を圧縮して復元します。
VAEは、その圧縮された潜在表現を確率分布として扱います。
この仕組みにより、VAEはデータを復元するだけでなく、新しいデータを生成することにもつながります。
重要ポイントを整理すると、次のようになります。
G検定では、VAEを「難しい数式のモデル」として覚えるよりも、「オートエンコーダ」、「潜在表現」、「確率分布」、「生成モデル」、「GAN」との関係で整理することが大切です。
オートエンコーダとの関係を確認するなら、こちらの記事がおすすめです。
潜在表現や次元削減との関係を理解するなら、こちらの記事がおすすめです。
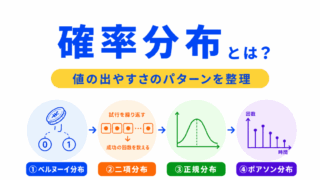
確率分布の考え方を確認するなら、こちらの記事がおすすめです。
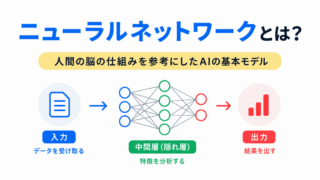
ニューラルネットワークの基本から確認するなら、こちらの記事がおすすめです。
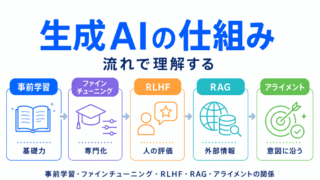
生成AIとのつながりを確認するなら、こちらの記事がおすすめです。
ディープラーニングの要素技術をまとめて確認するなら、こちらの記事がおすすめです。

数理・統計とのつながりを確認するなら、こちらの記事がおすすめです。

重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認