【G検定対策】AI倫理・AI法律とは?AI時代に必要な考え方をわかりやすく整理
seo-webmaster
G検定対策ブログ
生成AIは、ただ大量の文章を学習するだけで、最初から人間にとって使いやすい回答ができるわけではありません。
事前学習によって言葉のつながりや知識の土台を身につけても、そのままでは不自然な回答、危険な回答、意図に合わない回答を返すことがあります。
そこで重要になるのが、RLHF です。
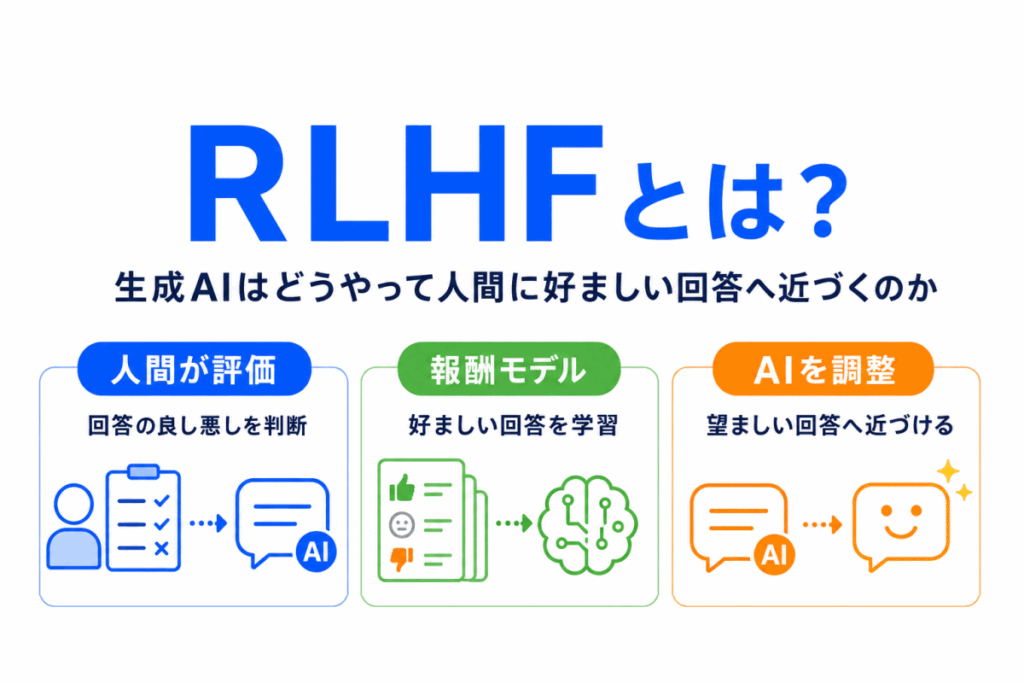
RLHFは、人間の評価を使って、生成AIの回答をより望ましい方向へ近づけるための考え方です。
この記事では、RLHFとは何か、ファインチューニングや強化学習とどう関係するのか、G検定ではどのように問われやすいのかを整理します。
RLHFとは、Reinforcement Learning from Human Feedback の略です。
日本語では、人間のフィードバックによる強化学習 と説明されることが多いです。
簡単に言うと、RLHFは、AIの回答に対して人間が評価を行い、その評価をもとに、AIの出力を人間にとって望ましい方向へ調整する仕組み です。
たとえば、生成AIが複数の回答を出したとします。
その中で、人間が
といった評価を行います。
この評価を使って、AIが「どのような回答が人間に好まれやすいのか」を学習していくのがRLHFです。
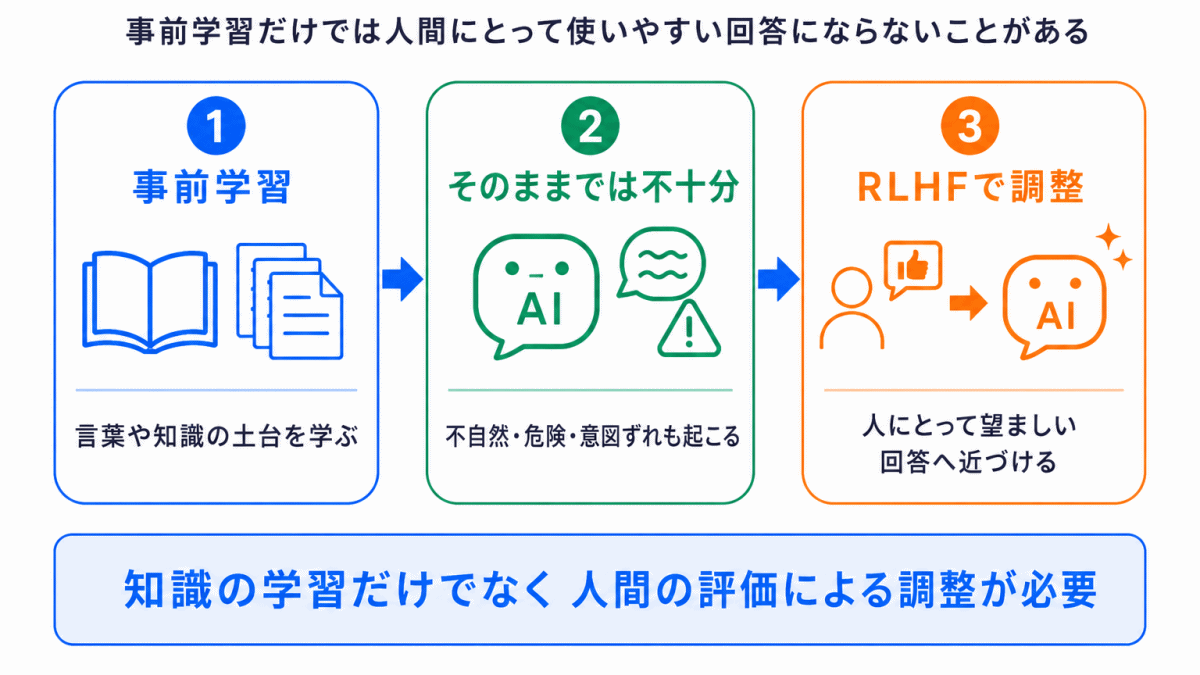
生成AIは、事前学習によって大量の文章から言葉のパターンを学びます。
しかし、事前学習だけでは
まで十分に調整できるとは限りません。
事前学習は、あくまで大量データから言葉の関係や知識の土台を学ぶ段階です。
そのため、生成AIを実際に人間が使いやすい形に近づけるには、人間の価値判断に近づける調整 が必要になります。
ここで使われる考え方の1つがRLHFです。
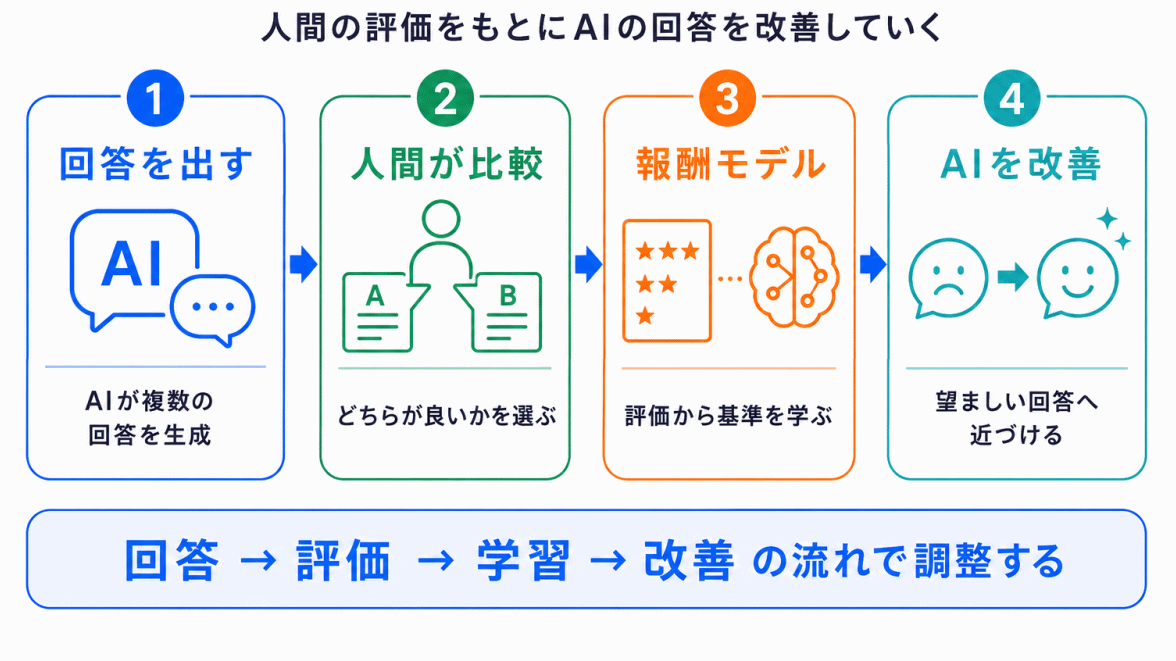
RLHFは細かく見ると複雑ですが、AIの学習をはじめたばかりの人向けには、まず次の流れで理解するとわかりやすいです。
重要なのは、RLHFでは単に「正解・不正解」を教えるだけではないという点です。
生成AIの回答では、数学の答えのように明確な正解が1つに決まらないことも多くあります。
たとえば
といった判断が必要になります。
RLHFは、こうした人間の好みや評価を使って、生成AIの振る舞いを調整する仕組みです。
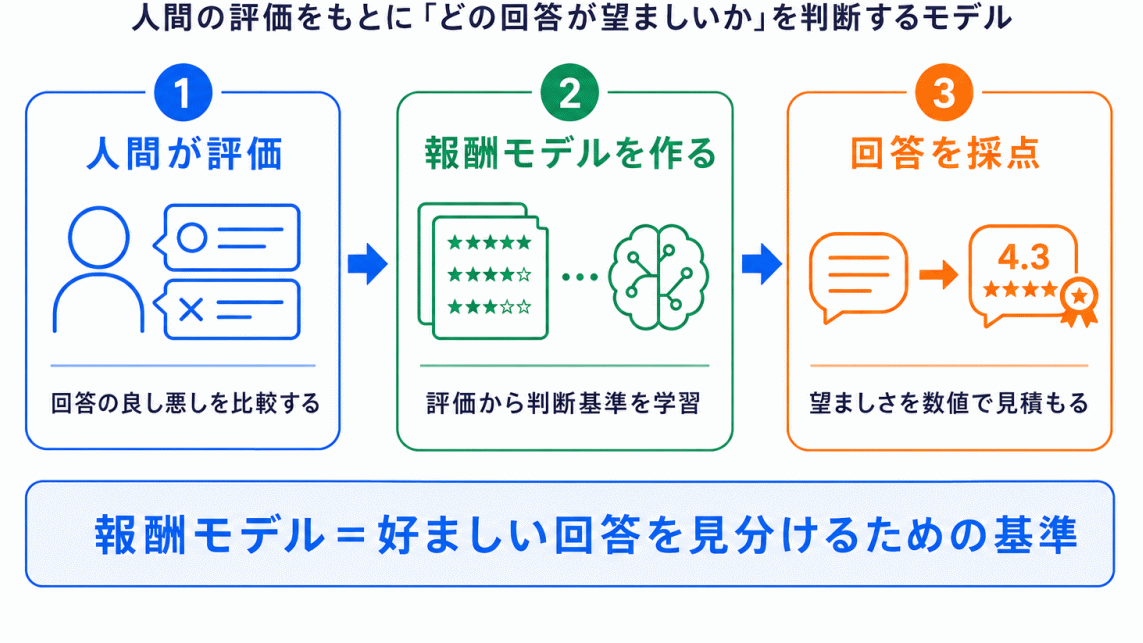
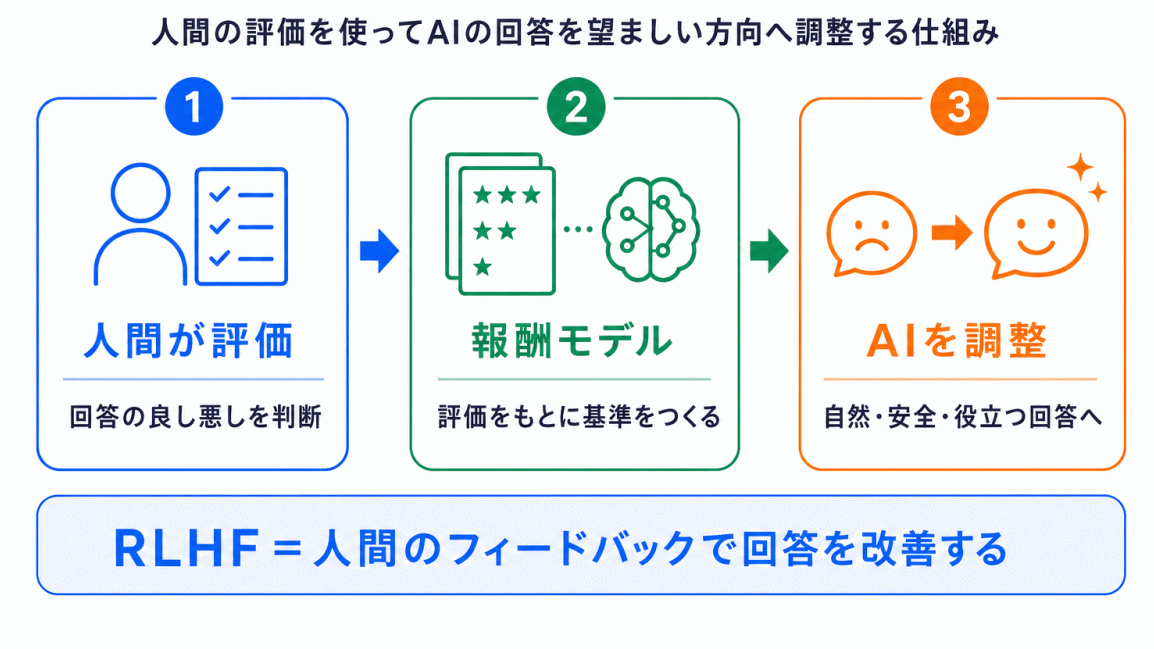
RLHFを理解するうえで重要なのが、報酬モデルです。
報酬モデルとは、簡単に言うと、AIの回答がどのくらい望ましいかを評価するモデル です。
人間がすべての回答を毎回評価するのは大変です。
そこで、人間の評価データをもとに
と判断するモデルを作ります。
これが報酬モデルです。
生成AIは、この報酬モデルから高く評価されるように、出力を調整していきます。
つまり、RLHFでは、人間の評価 → 報酬モデル → AIの出力調整 という流れが重要になります。
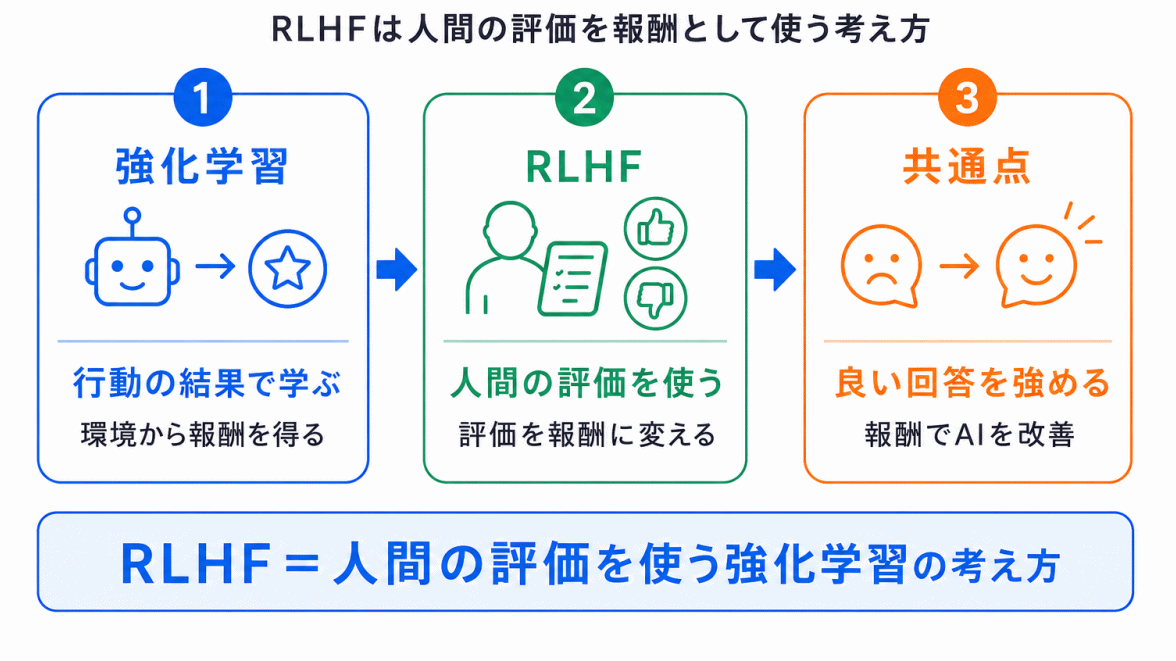
RLHFの中には、強化学習の考え方が含まれています。
強化学習では、AIは行動の結果として得られる報酬をもとに、より良い行動を選ぶように学習します。
RLHFの場合、この「報酬」にあたるものが、人間の評価をもとに作られた報酬モデルです。
つまり、通常の強化学習では環境から報酬を得ますが、RLHFでは、人間のフィードバックをもとにした報酬 を使う点が特徴です。
ただし、G検定向けには、数式や細かいアルゴリズムまで深追いするよりも、人間の評価を使って、生成AIの回答を望ましい方向へ調整する と理解しておく方が重要です。
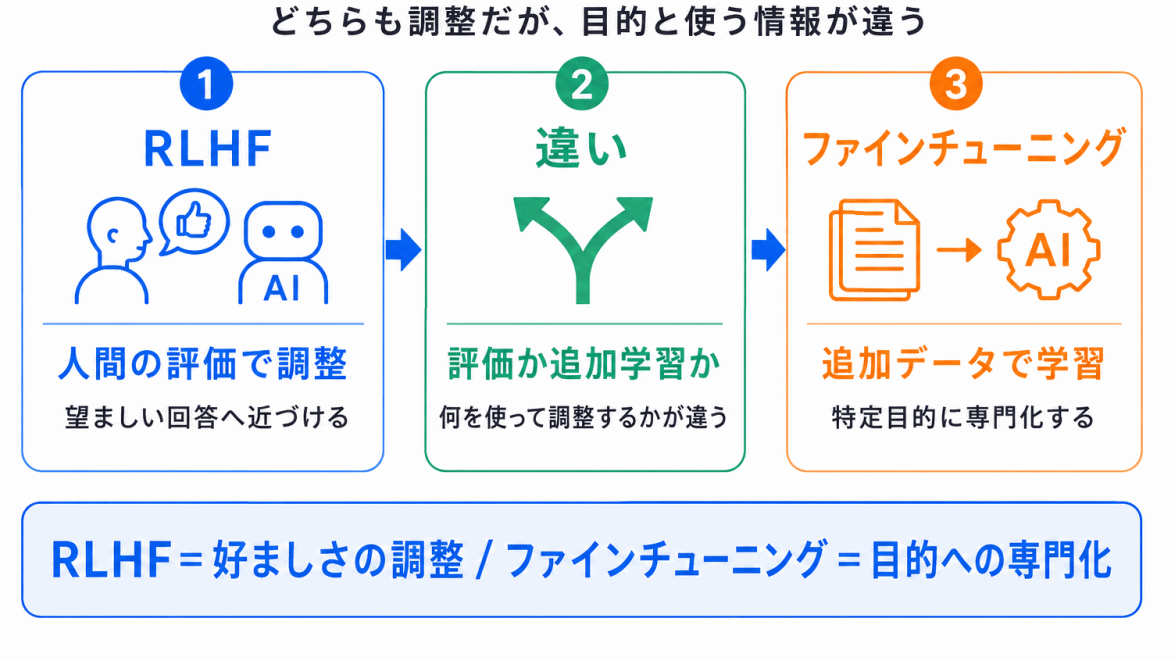
RLHFは、ファインチューニングと混同しやすいテーマです。
どちらも、事前学習済みモデルを調整するという点では似ています。
しかし、目的や使うデータの考え方が少し違います。
| 項目 | ファインチューニング | RLHF |
|---|---|---|
| 主な目的 | 特定タスクに適応させる | 人間に好ましい回答へ近づける |
| 使う情報 | 教師データ・タスク別データ | 人間の評価・好み |
| 注目点 | 正しい出力を学ばせる | 望ましい出力を選ばせる |
| 関係 | 追加学習の一種 | 人間のフィードバックを使った調整 |
ファインチューニングは、たとえば医療文書、法律文書、社内文書など、特定の目的に合わせてモデルを調整するイメージです。
一方でRLHFは、生成AIの回答を
ための調整として理解するとわかりやすいです。
事前学習は、生成AIの土台を作る段階です。
大量のテキストデータを使って、言葉の関係、文脈、知識のパターンを学びます。
一方でRLHFは、事前学習で作られたモデルを、人間にとって使いやすい方向へ調整する段階です。
整理すると、次のようになります。
| 段階 | 役割 |
|---|---|
| 事前学習 | 大量データから言葉や知識の土台を作る |
| ファインチューニング | 特定目的に合わせて追加調整する |
| RLHF | 人間の評価を使って望ましい回答へ近づける |
ここで大事なのは、RLHFはゼロからAIを作る仕組みではないということです。
基本的には、すでに事前学習されたモデルを、より人間に合う形へ調整するために使われます。
RLHFは、アライメントとも深く関係します。
アライメントとは、AIの出力や行動を、人間の意図・価値観・安全性に合うように調整する考え方です。
RLHFは、そのための代表的な方法の1つと考えるとわかりやすいです。
つまり
という関係です。
RLHFによって、生成AIは次のような方向へ調整されます。
ただし、RLHFを使えば生成AIが完全に正しくなるわけではありません。
RLHFは、あくまで人間にとって望ましい回答へ近づけるための調整です。
事実確認の誤りやハルシネーションを完全になくすものではありません。
RLHFにはメリットがありますが、注意点もあります。
人間の評価を使うため、評価する人の価値観や判断基準が影響します。
たとえば
は、人や文化、状況によって変わる可能性があります。
そのため、RLHFは単なる技術ではなく、AI倫理やアライメントとも関係するテーマです。
生成AIを人間にとって使いやすくする一方で「誰の評価を基準にしているのか」という視点も重要になります。
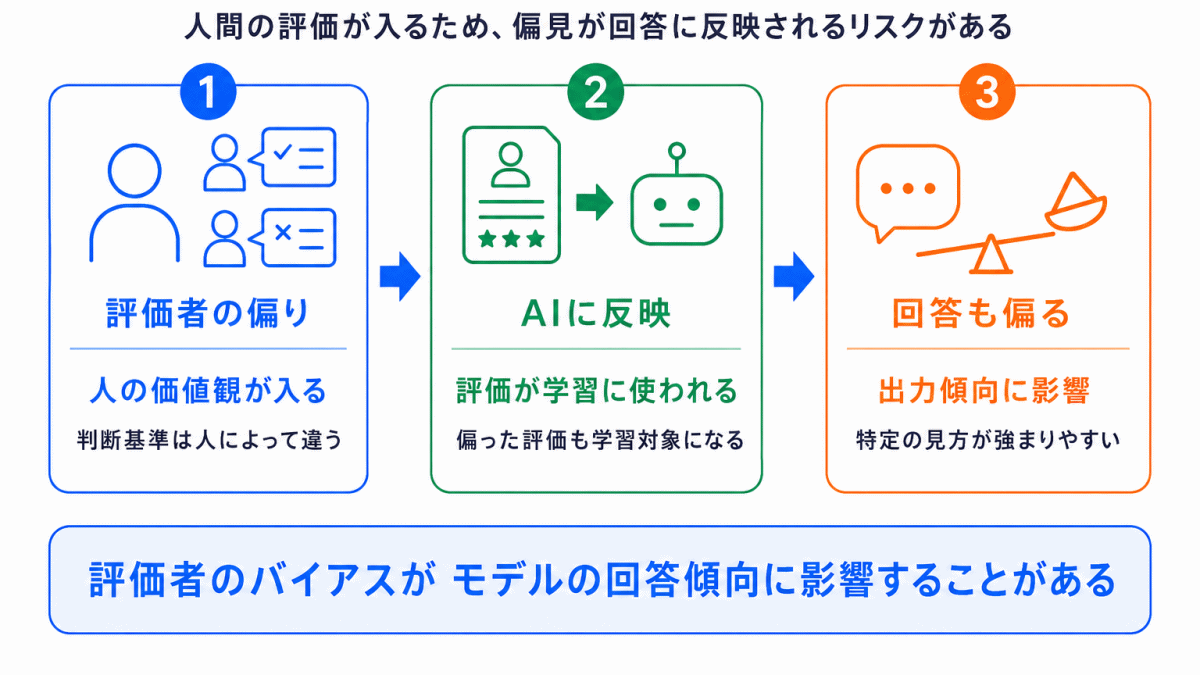
人間の評価を使うため、評価する人の価値観や判断基準が影響します。
また、人間のフィードバックを介在させる以上、評価者自身が持つ偏見(バイアス)が、モデルの出力傾向に反映されてしまうリスクもあります。
たとえば、ある評価者グループに特定の価値観や判断基準が偏っている場合、その評価をもとに調整されたAIも、同じような偏りを含んだ回答を選びやすくなる可能性があります。
そのため、RLHFでは「人間が評価しているから安心」と単純に考えるのではなく、誰が、どのような基準で評価しているのかも重要になります。
たとえば
は、人や文化、状況によって変わる可能性があります。
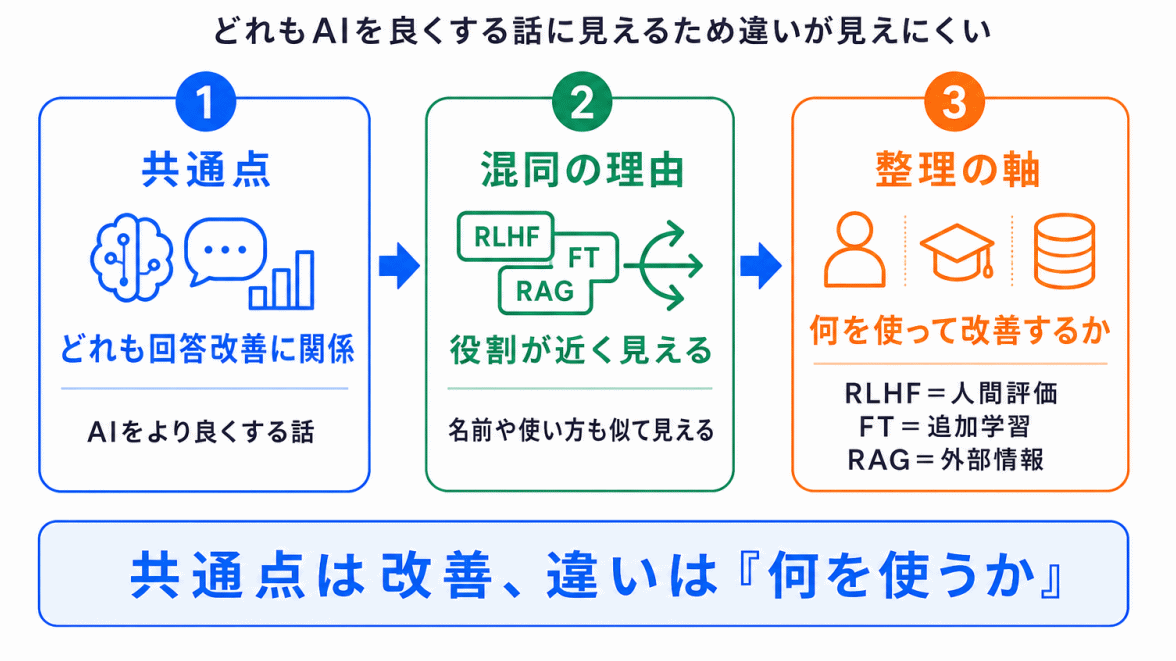
RLHFが混同しやすい理由は、生成AIの改善方法が複数あるからです。
たとえば
はいずれも、生成AIの回答に関係します。
そのため、すべてを「AIをよくする方法」としてまとめてしまうと、違いが見えにくくなります。
混同を防ぐには、何を使って改善するのかで整理するとわかりやすいです。
| 方法 | 何を使うか | 目的 |
|---|---|---|
| 事前学習 | 大量データ | 知識や言語の土台を作る |
| ファインチューニング | 追加データ | 特定目的に適応させる |
| RLHF | 人間の評価 | 好ましい回答へ近づける |
| RAG | 外部情報 | 最新情報や根拠を補う |
| プロンプトエンジニアリング | 入力の工夫 | 望む回答を引き出す |
このように見ると、RLHFの特徴は、人間の評価を使うこと にあります。
事前学習、ファインチューニング、RAG、RLHFは、生成AIやLLMの理解で混同しやすい用語です。
どれもAIの性能や使いやすさに関係しますが、役割は異なります。
| 用語 | 意味 | 見分け方 |
|---|---|---|
| 事前学習 | 大量のデータから、言葉や知識のパターンを広く学ぶ段階 | 土台を作る |
| ファインチューニング | 事前学習済みモデルを、特定の目的に合わせて追加調整する方法 | 目的に合わせて専門化する |
| RAG | 外部情報を参照しながら回答を生成する仕組み | 外部情報を使って補う |
| RLHF | 人間の評価を使って、好ましい回答に近づける調整方法 | 人間の評価で調整する |
G検定では、RLHFについて細かい実装手順を問うというより、何を目的とした仕組みなのか が問われやすいと考えられます。
特に注意したいのは、次のような混同です。
G検定向けには、次のように整理しておくと安全です。
RLHFは、人間のフィードバックを使って、生成AIの回答を人間にとって望ましい方向へ調整する仕組み。
この一文を軸にすると、選択肢で迷いにくくなります。
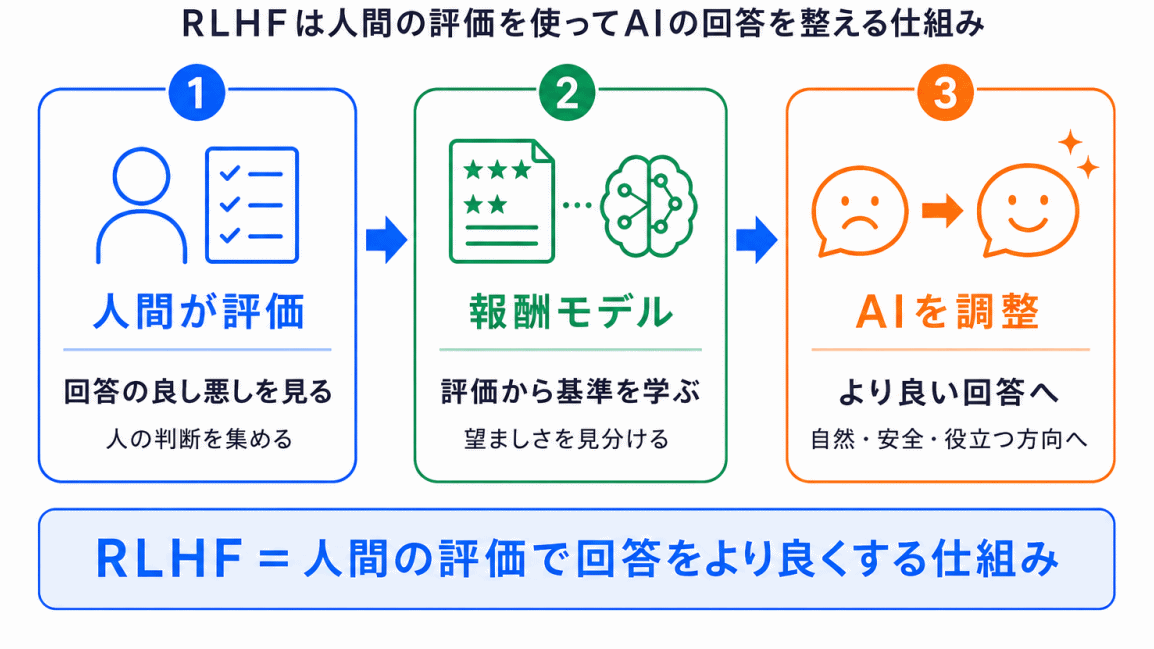
RLHFは、生成AIを理解するうえで重要な考え方です。
事前学習によってAIは大量の言語パターンを学びますが、それだけで人間にとって使いやすい回答ができるとは限りません。
そこで、人間の評価を使って、より望ましい回答へ近づける仕組み が必要になります。
RLHFでは、人間が回答の良し悪しを評価し、その評価をもとに報酬モデルを作り、生成AIの出力を調整します。
ただし、RLHFは万能ではありません。
AIの回答を人間に好ましい方向へ近づけることはできますが、事実の正しさを完全に保証するものではなく、ハルシネーションを完全になくす仕組みでもありません。
G検定では、RLHFを「人間のフィードバックを使う生成AIの調整方法」として理解しておくことが重要です。
特に、事前学習、ファインチューニング、RAG、アライメントとの違いを整理しておくと、選択肢で迷いにくくなります。
RLHFだけを覚えるのではなく、「生成AIはどのように学習し、なぜ間違え、どう安全に使うのか」までつなげて理解しておくことが大切です。関連する記事もあわせて確認しておきましょう。
| 読む記事 | 確認できる内容 |
|---|---|
| 法律・倫理・ガバナンスまとめ | AIを安全に使う考え方/法律・倫理・ガバナンスの違い/生成AIリスクとの関係 |
| 法律・倫理・ガバナンスの重要用語 | 法律・契約・AI倫理の用語/AIガバナンスの用語/生成AIリスクの整理 |
| 事前学習とは? | 大量データから知識を身につける流れ/LLMの土台作り/ファインチューニングとの違い |
| ファインチューニングとは? | 事前学習済みモデルの専門化/追加学習の考え方/転移学習との関係 |
| LLMとGPTの違い | 大規模言語モデルの意味/GPTの位置づけ/生成AIとの関係 |
| ハルシネーションとは? | AIが誤情報を出す理由/自信満々に間違える仕組み/生成AI利用時の注意点 |
| RAGとは? | 外部情報を参照する仕組み/生成AIの弱点補完/ハルシネーション対策との関係 |
| バイアスと分散とは? | 過学習・未学習の原因/汎化性能との関係/モデルの複雑さとのバランス |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。



