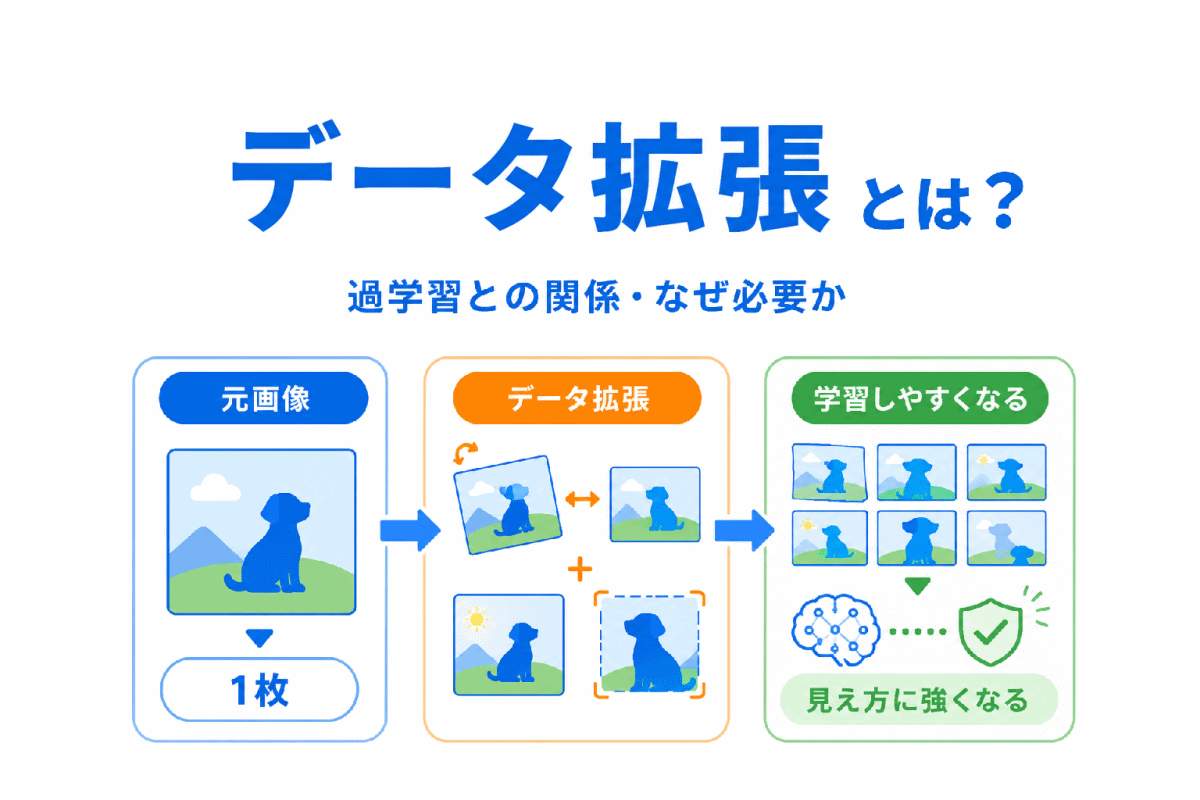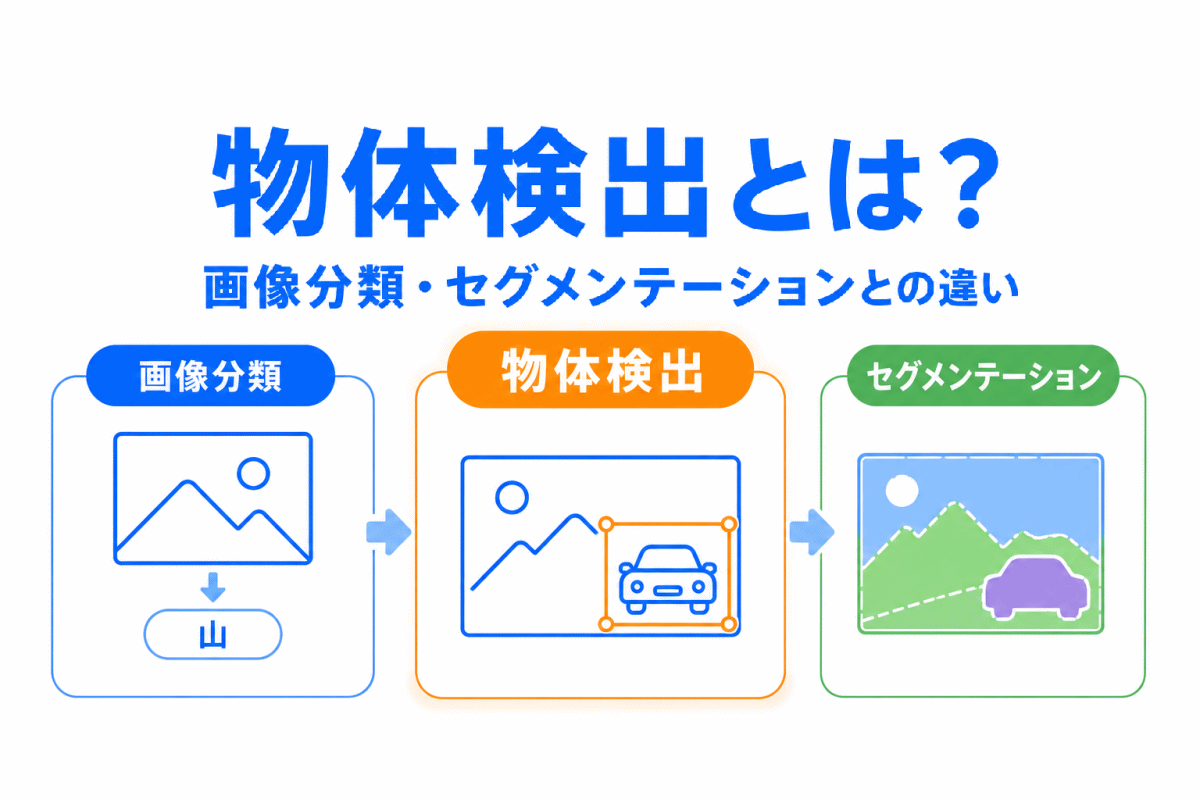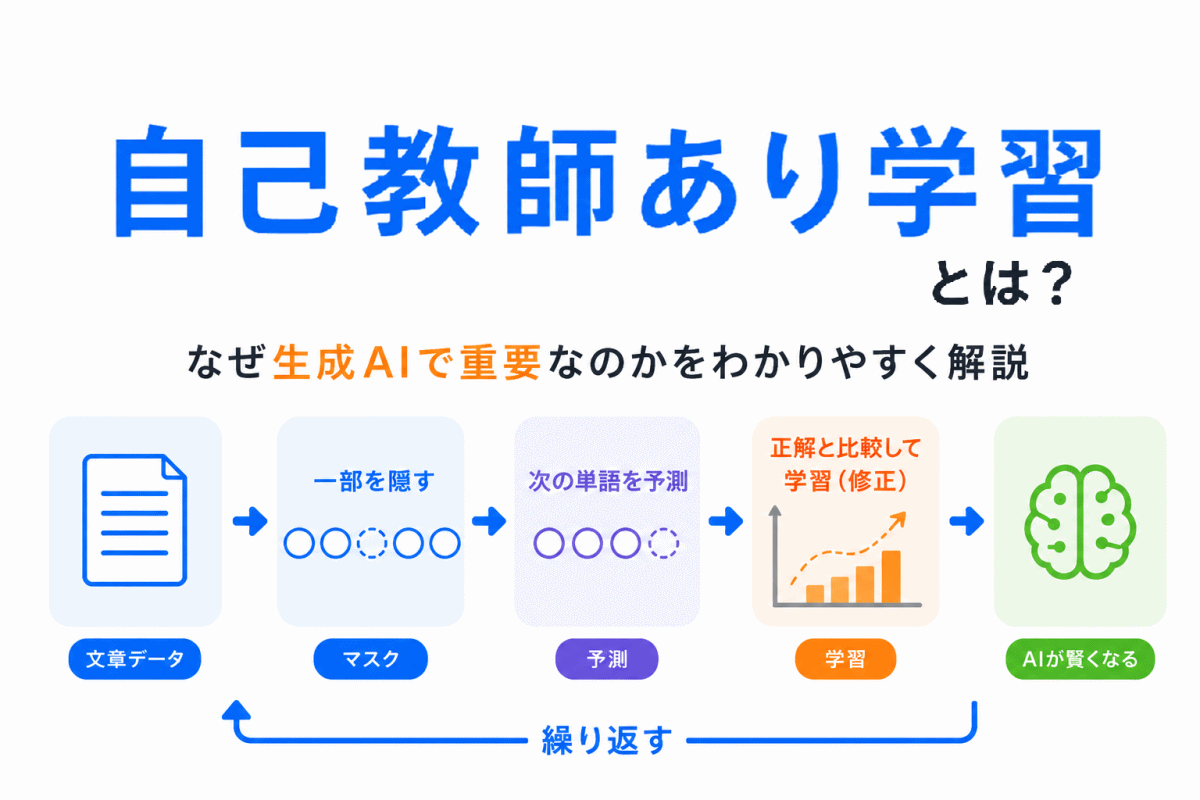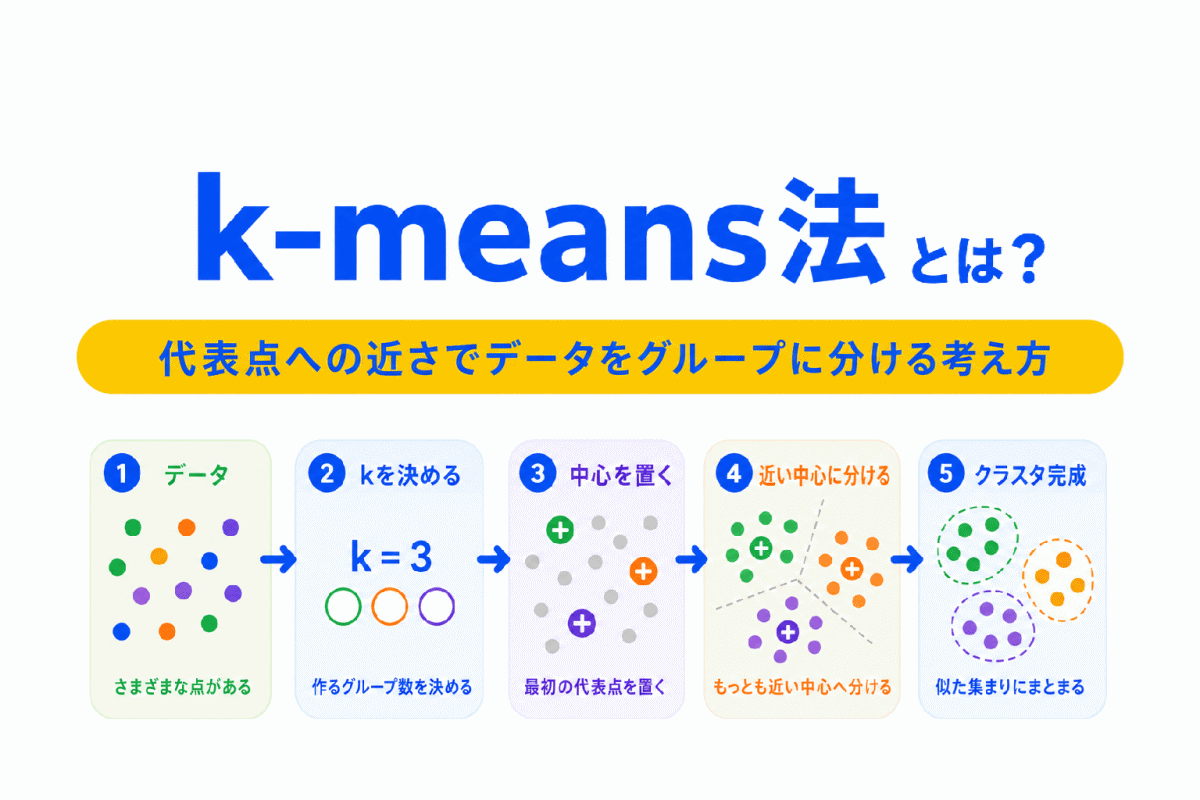
【G検定対策】k-means法とは?|似たデータを代表点に近いグループへ分ける考え方を整理
seo-webmaster
G検定対策ブログ
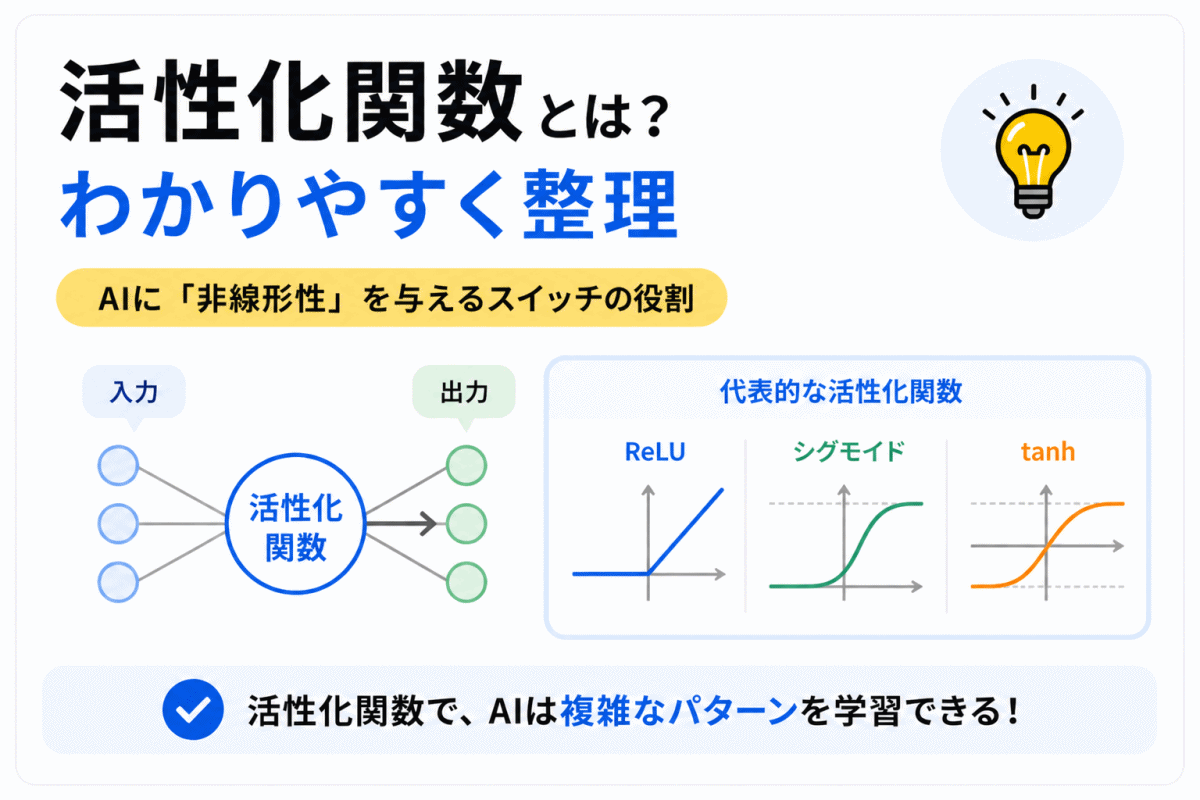
活性化関数とは、ニューラルネットワークの中で、入力された値を変換して次の層へ渡すための関数です。
活性化関数がないと、層を何枚重ねても単純な計算に近くなり、画像や文章のような複雑な特徴を表現しにくくなります。
G検定では、活性化関数の細かい数式よりも、なぜ必要なのか、ReLUやシグモイド、ソフトマックスがどこで使われるのか、損失関数と何が違うのかを整理しておくことが大切です。
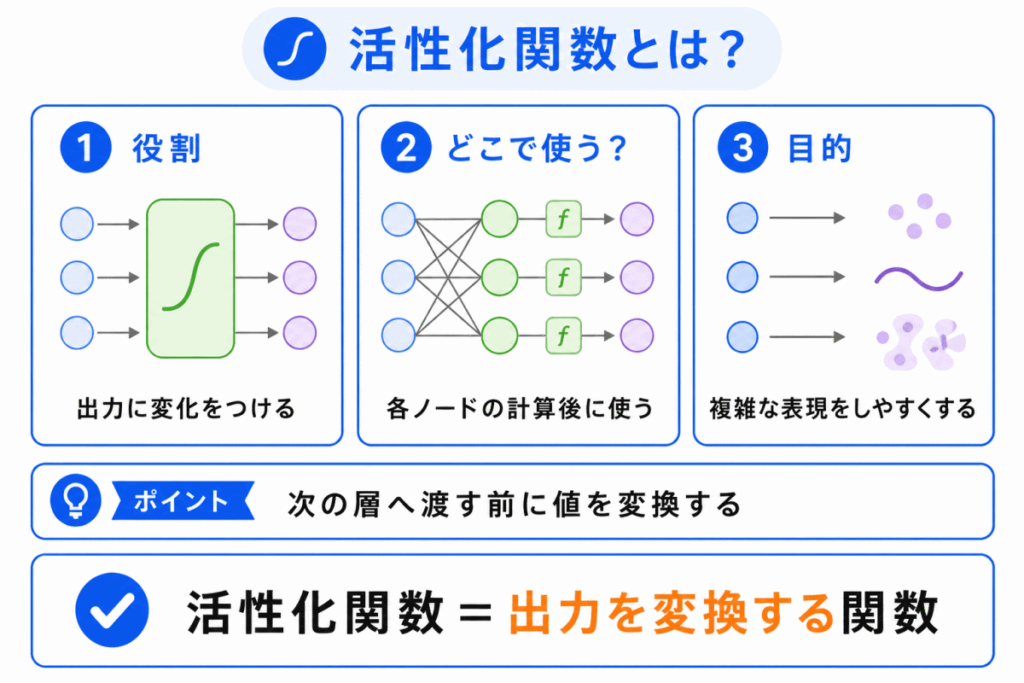
活性化関数とは、ニューラルネットワークの各層で、入力された値を変換して出力する関数です。
ニューラルネットワークでは、入力されたデータに重みをかけて計算し、その結果を次の層へ渡します。
このとき、ただ計算結果をそのまま渡すのではなく、活性化関数を通して値を変換します。
| 用語 | 一言でいうと |
|---|---|
| 重み | 入力の重要度を調整する値 |
| 活性化関数 | 出力に変化をつける関数 |
| 出力 | 次の層へ渡す値 |
活性化関数は、ニューラルネットワークに 複雑な表現力を持たせるための仕組み と考えるとわかりやすいです。
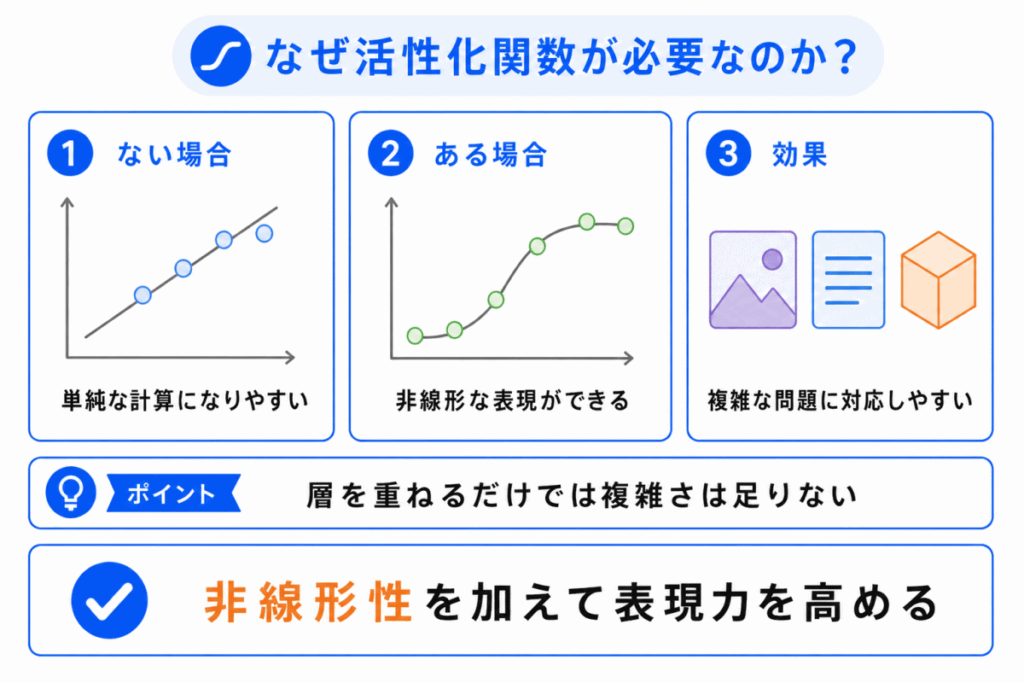
活性化関数が必要な理由は、ニューラルネットワークに 非線形性 を加えるためです。
非線形性とは、簡単にいうと、入力と出力の関係が単純な直線では表せない性質のことです。
画像認識や自然言語処理では、入力と答えの関係は単純ではありません。
たとえば、画像の中に猫がいるかどうかを判断する場合、明るさ、形、模様、位置など、さまざまな特徴を組み合わせて判断する必要があります。
活性化関数がないと、層を重ねても単純な計算の組み合わせになり、複雑な特徴を表現しにくくなります。
| 活性化関数 | 表現できること |
|---|---|
| なし | 単純な関係になりやすい |
| あり | 複雑な関係を表現しやすい |
つまり、活性化関数は ニューラルネットワークを複雑な問題に対応させるための重要な部品 です。
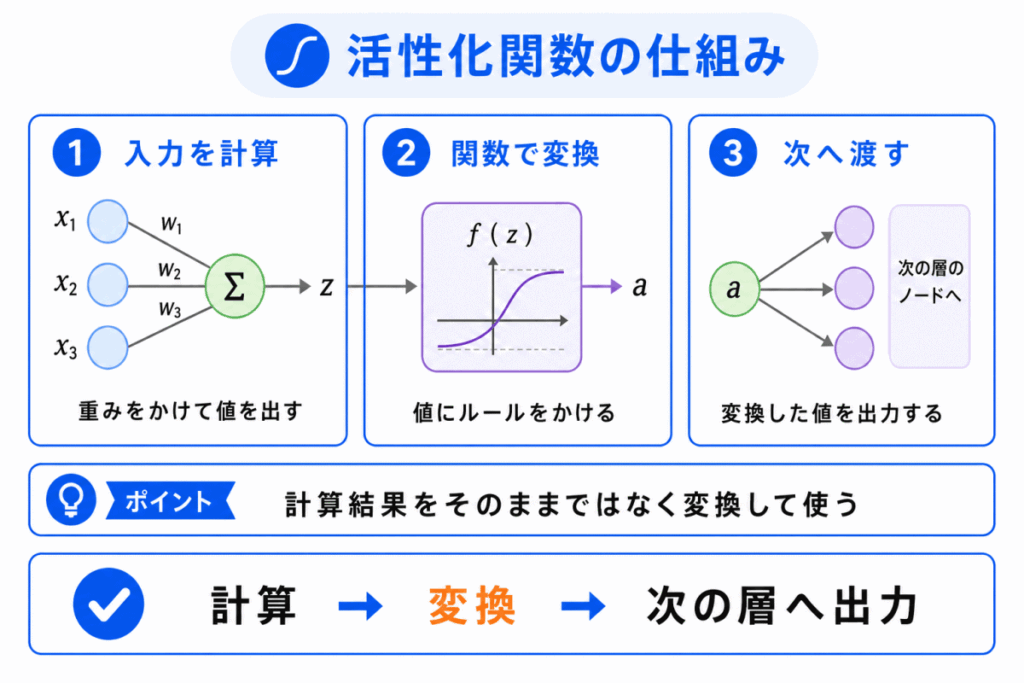
活性化関数は、各ノードの計算結果を受け取り、一定のルールにしたがって値を変換します。
たとえば、入力値が大きければそのまま通し、入力値が小さければ0にする、といった変換を行います。
この変換によって、ニューラルネットワークは「どの情報を強く反応させるか」、「どの情報を弱めるか」を調整しやすくなります。
| 流れ | 内容 |
|---|---|
| 1 | 入力を受け取る |
| 2 | 重みをかけて計算する |
| 3 | 活性化関数で変換する |
| 4 | 次の層へ渡す |
活性化関数は、入力された値に対して 反応の仕方を決める関数 と整理できます。
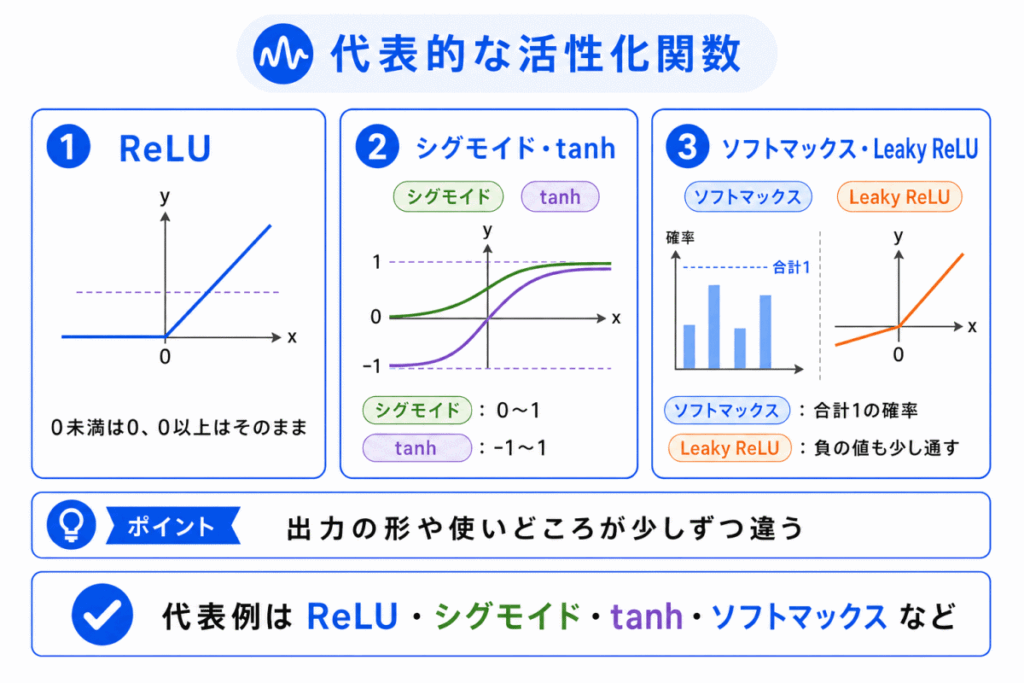
代表的な活性化関数には、ReLU、シグモイド、tanh、Leaky ReLU、ソフトマックスなどがあります。
それぞれ役割や使われる場面が少しずつ異なります。
| 活性化関数 | 一言でいうと | 押さえるポイント |
|---|---|---|
| ReLU | 0未満は0、0以上はそのまま | ディープラーニングでよく使われる |
| シグモイド | 0〜1に変換 | 確率のように扱いやすい |
| tanh | -1〜1に変換 | 0を中心にした出力 |
| Leaky ReLU | 負の値も少し通す | ReLUの弱点対策 |
| ソフトマックス | 合計1の確率に変換 | 多クラス分類の出力層で使われる |
G検定では、すべての数式を細かく覚えるよりも、どの活性化関数がどんな役割を持つか を整理しておくと判断しやすくなります。
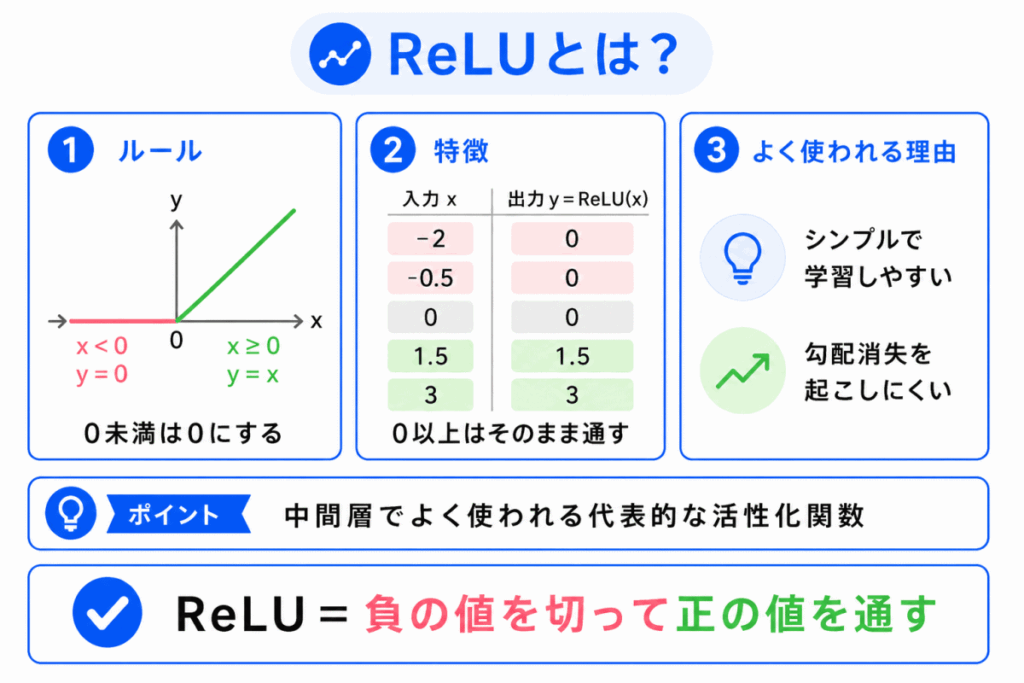
ReLUは、ディープラーニングでよく使われる代表的な活性化関数です。
ReLUは、入力が0より小さい場合は0を出力し、0以上の場合はそのまま出力します。
| 入力 | ReLUの出力 |
|---|---|
| -3 | 0 |
| -1 | 0 |
| 0 | 0 |
| 2 | 2 |
| 5 | 5 |
ReLUは仕組みがシンプルで、計算しやすいという特徴があります。
また、シグモイド関数などで起きやすい勾配消失問題を起こしにくいため、深いニューラルネットワークでよく使われます。
ただし、ReLUにも弱点があります。
入力が負の値になり続けると、そのノードがほとんど学習に使われなくなることがあります。
この弱点を補うために、Leaky ReLUのような派生形もあります。
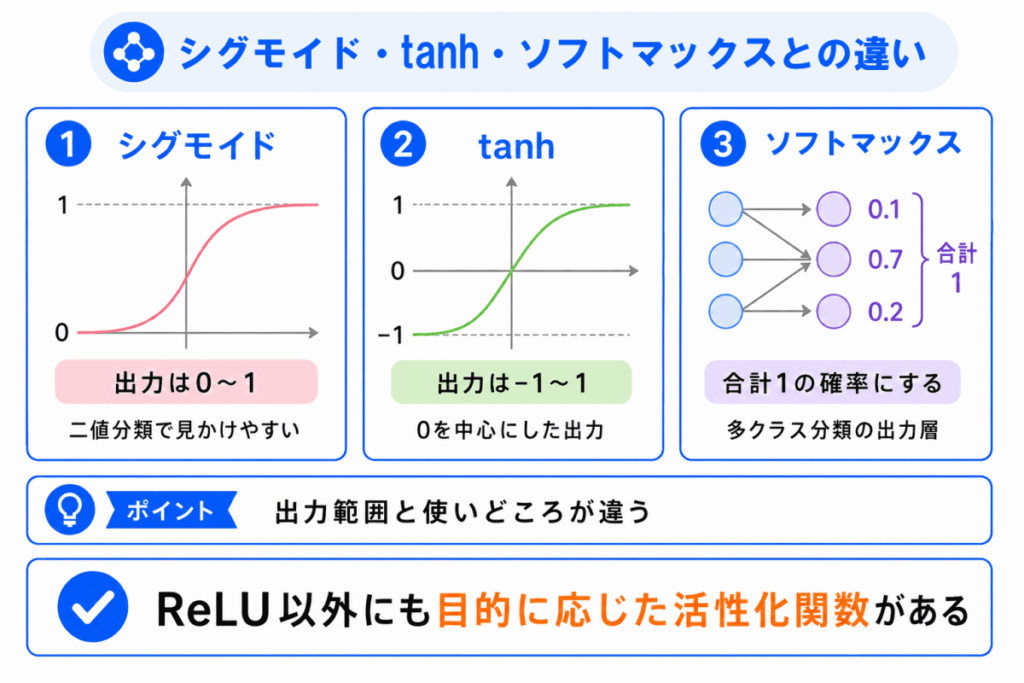
活性化関数は、出力の形によって使い分けられます。
シグモイドは0〜1の値に変換するため、確率のように扱いやすい特徴があります。
tanhは-1〜1の値に変換します。
シグモイドよりも0を中心にした出力になるため、学習で扱いやすい場合があります。
ソフトマックスは、複数の出力を合計1になるように変換します。
そのため、複数のクラスからどれに当てはまるかを判断する多クラス分類で使われます。
| 活性化関数 | 出力の範囲 | よく使われる場面 |
|---|---|---|
| シグモイド | 0〜1 | 二値分類など |
| tanh | -1〜1 | 中間層など |
| ReLU | 0以上 | 中間層でよく使われる |
| ソフトマックス | 合計1 | 多クラス分類の出力層 |
ざっくり言うと、ReLUは中間層、ソフトマックスは多クラス分類の出力層 で見かけやすいです。
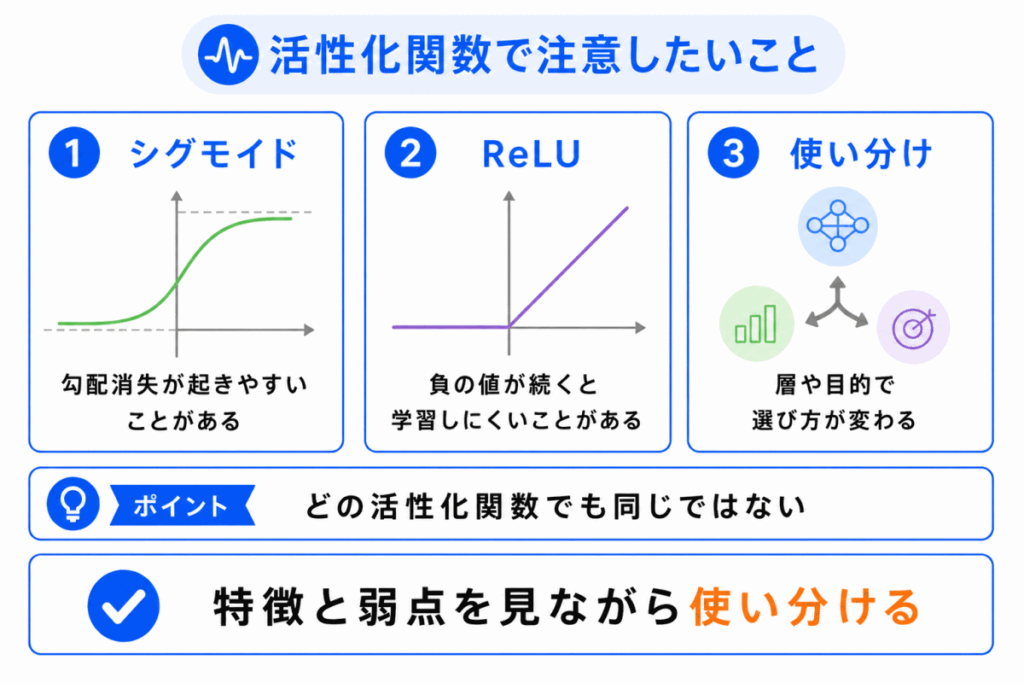
活性化関数は重要ですが、どれを使ってもよいわけではありません。
種類によって、学習のしやすさや出力の意味が変わります。
特に、シグモイド関数では勾配消失問題が起きやすいことがあります。
勾配消失問題とは、ニューラルネットワークが深くなるほど、誤差の情報が前の層へ伝わりにくくなり、学習が進みにくくなる問題です。
| 注意点 | 内容 |
|---|---|
| シグモイド | 勾配消失が起きやすいことがある |
| ReLU | 負の値が続くと学習しにくいノードが出ることがある |
| ソフトマックス | 多クラス分類の出力層で使われることが多い |
| 使い分け | 層や目的によって変わる |
G検定では、「活性化関数=どれも同じ」と考えるのではなく、代表的な種類と役割の違い を押さえることが大切です。
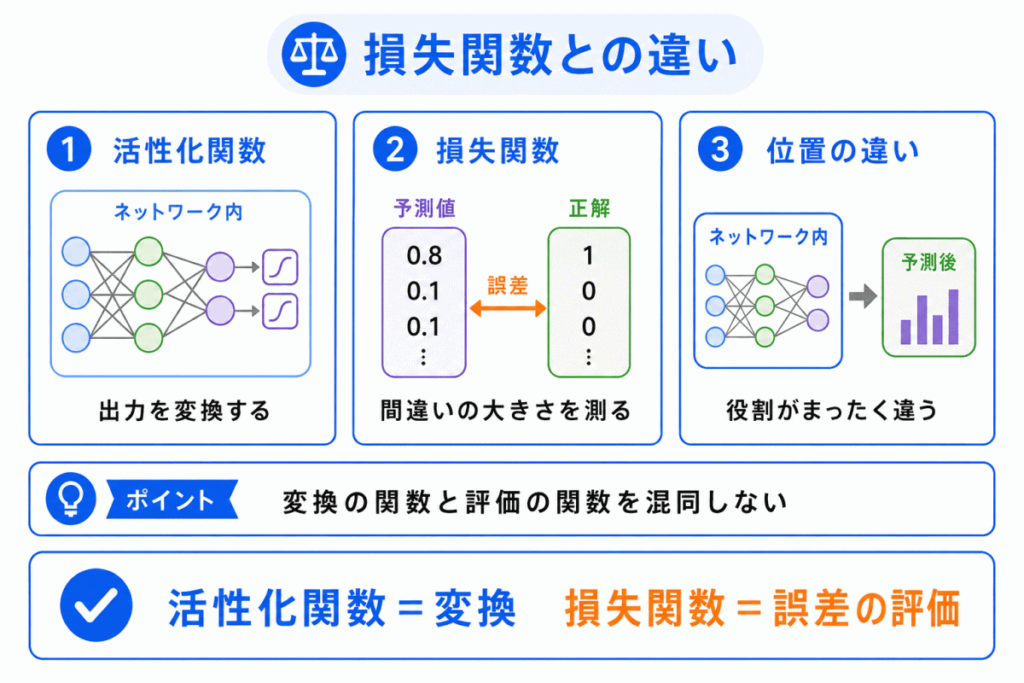
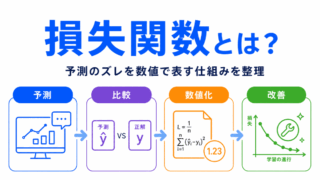
活性化関数と損失関数は、名前は似ていませんが、役割を混同しやすい用語です。
活性化関数は、ニューラルネットワークの中で出力を変換するために使います。
一方、損失関数は、予測と正解のズレを測るために使います。
| 用語 | 役割 | 使う場所 |
|---|---|---|
| 活性化関数 | 出力を変換する | ニューラルネットワークの各層 |
| 損失関数 | 間違いの大きさを測る | 予測後の評価 |
たとえば、活性化関数は「次の層へどのような値を渡すか」を決めます。
損失関数は「その予測がどれくらい間違っていたか」を測ります。
つまり
と分けて覚えると混同しにくくなります。
G検定では、活性化関数の数式よりも、役割や代表例が問われやすいです。
特に、ReLU、シグモイド、ソフトマックス、勾配消失問題との関係を整理しておくと理解しやすくなります。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| 活性化関数の役割 | 非線形性を加える |
| 活性化関数がない場合 | 複雑な表現がしにくい |
| ReLU | ディープラーニングでよく使われる |
| シグモイド | 0〜1に変換するが、勾配消失に注意 |
| ソフトマックス | 多クラス分類の出力層で使われる |
| 損失関数との違い | 活性化関数は変換、損失関数は誤差を測る |
「活性化関数=ニューラルネットワークに非線形性を加えるもの」と押さえたうえで、代表的な種類の違いを整理しておくと、選択肢を判断しやすくなります。
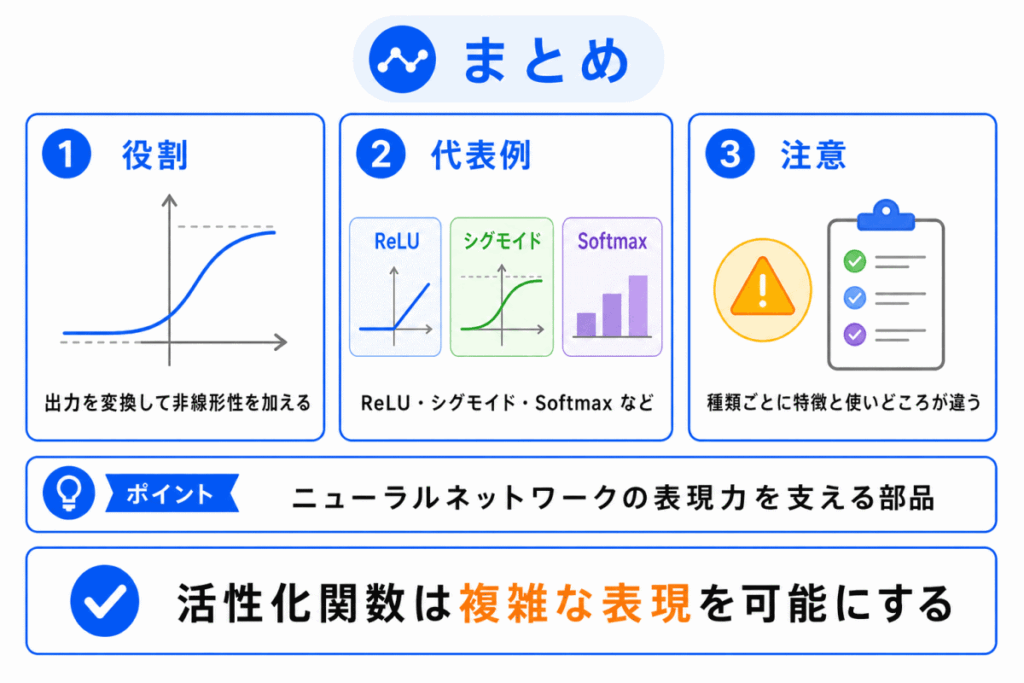
活性化関数とは、ニューラルネットワークの中で、入力された値を変換して次の層へ渡す関数です。
活性化関数によって非線形性が加わるため、ニューラルネットワークは複雑な問題を表現しやすくなります。
| 用語 | 一言でいうと |
|---|---|
| 活性化関数 | 出力に変化をつける関数 |
| 非線形性 | 単純な直線では表せない性質 |
| ReLU | 0未満を0、0以上をそのまま出す |
| シグモイド | 0〜1に変換する |
| ソフトマックス | 合計1の確率に変換する |
| 損失関数 | 間違いの大きさを測る関数 |
G検定では、活性化関数を数式で細かく覚えるよりも、なぜ必要なのか、どこで使われるのか、損失関数と何が違うのか を整理しておくことが大切です。
特に、ReLUは中間層、ソフトマックスは多クラス分類の出力層で使われることが多い、と押さえておくと理解しやすくなります。
活性化関数を理解するには、ニューラルネットワークや損失関数、勾配消失問題とのつながりもあわせて整理しておくと理解しやすくなります。
活性化関数の選び方は、勾配消失問題とも関係します。
活性化関数と損失関数は役割が異なるため、違いを整理しておくと混同しにくくなります。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認