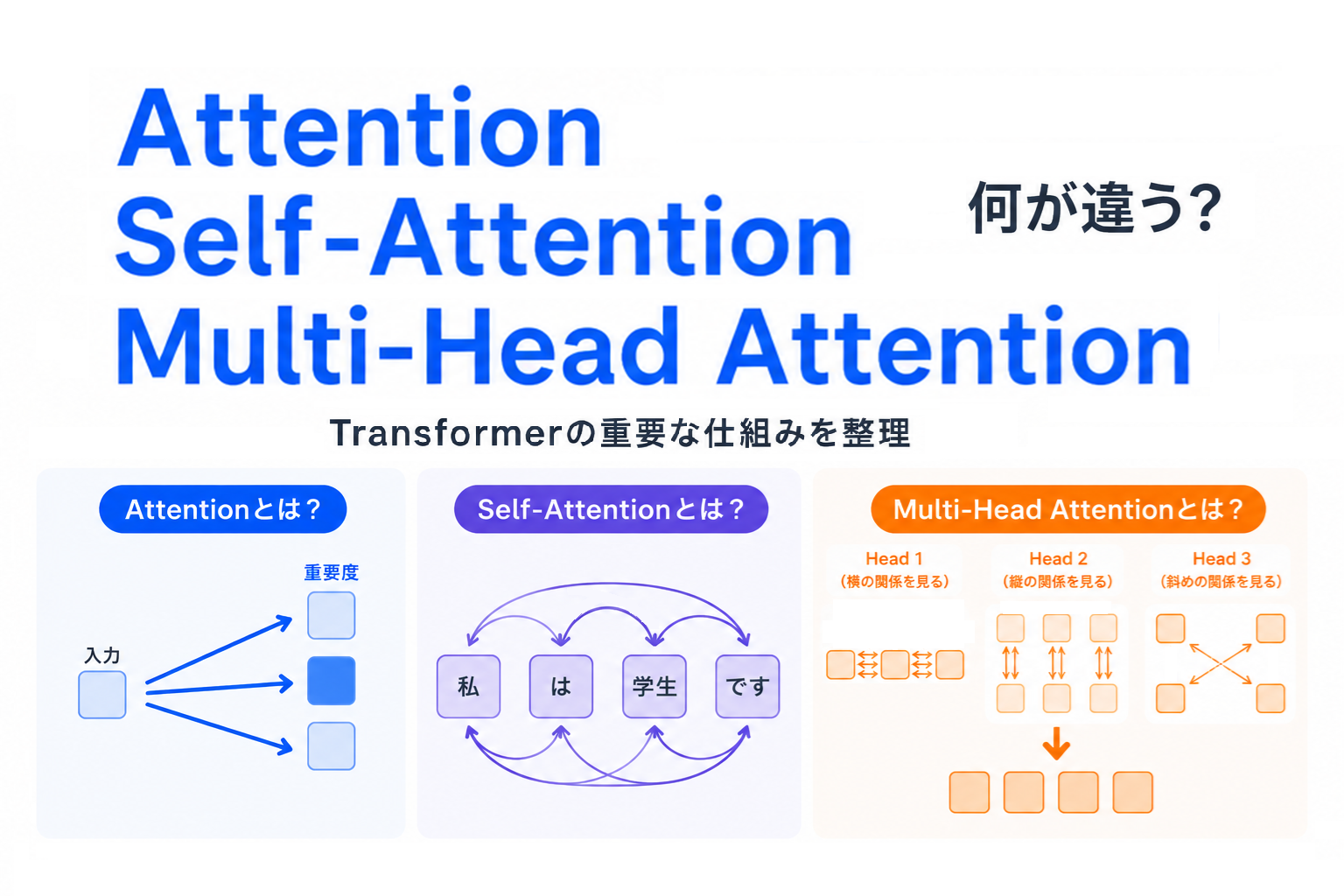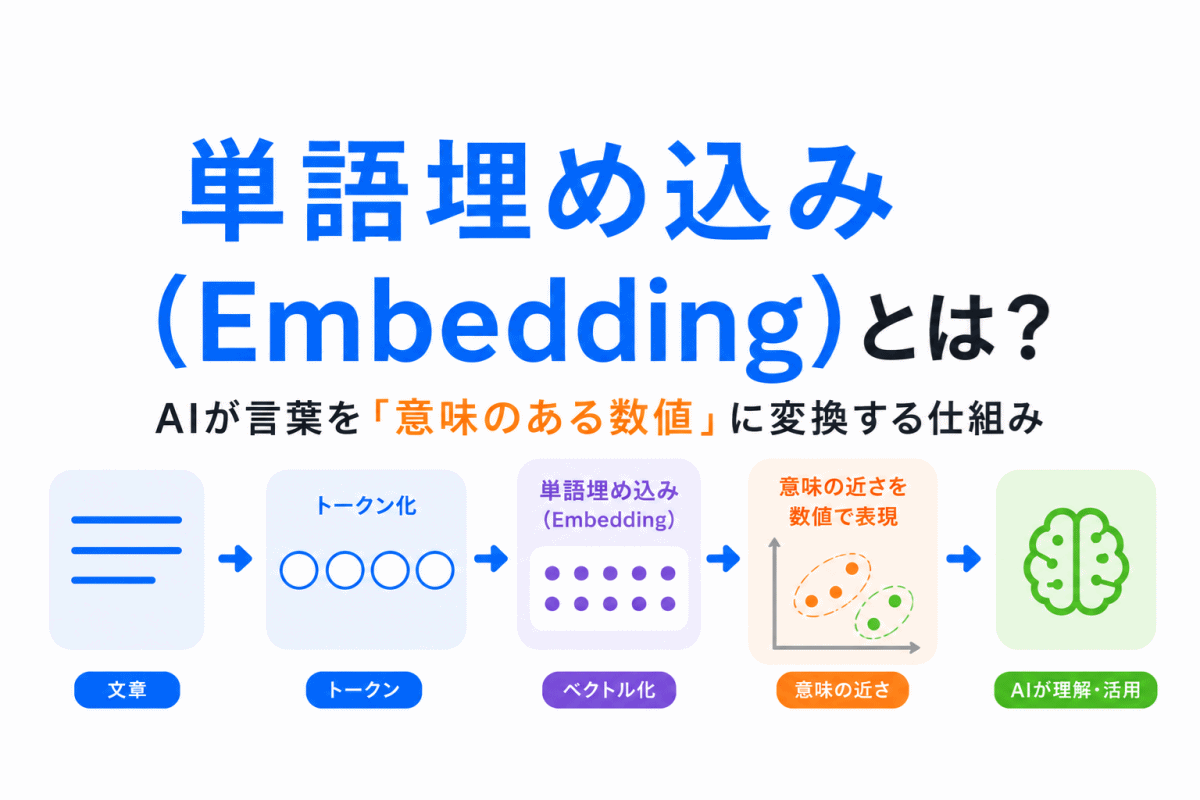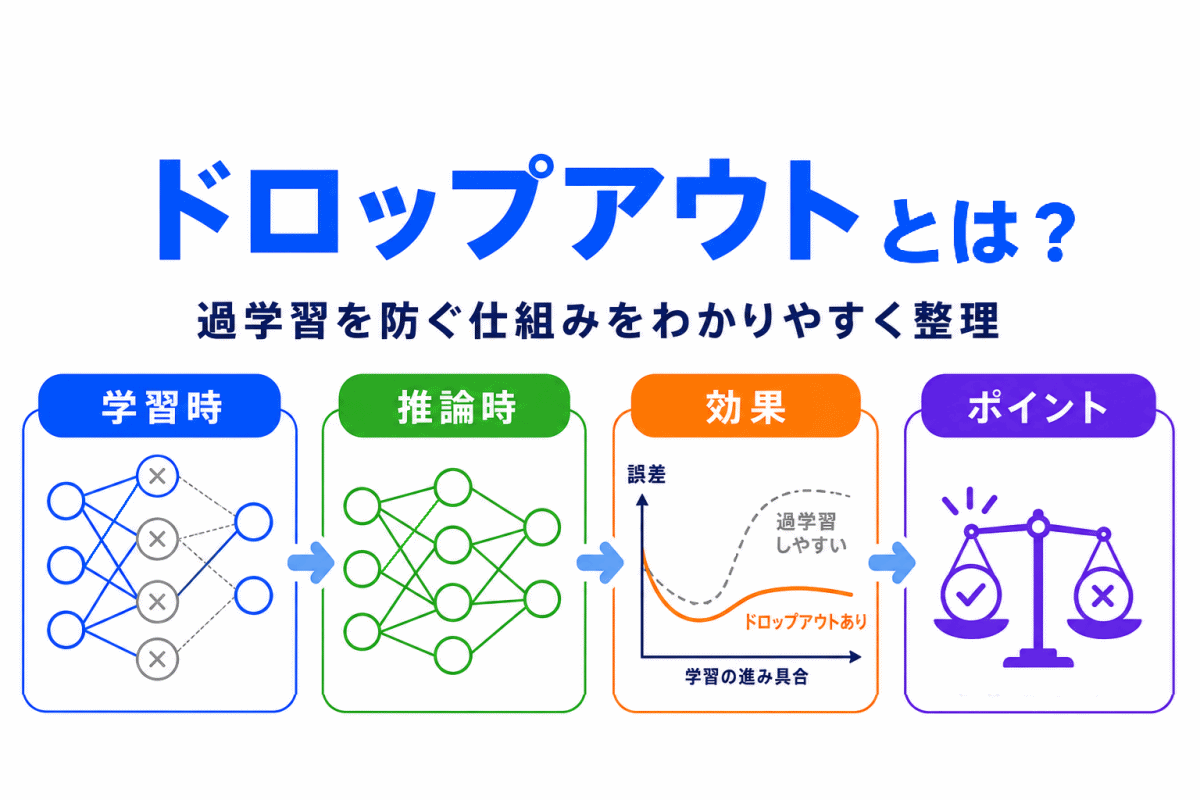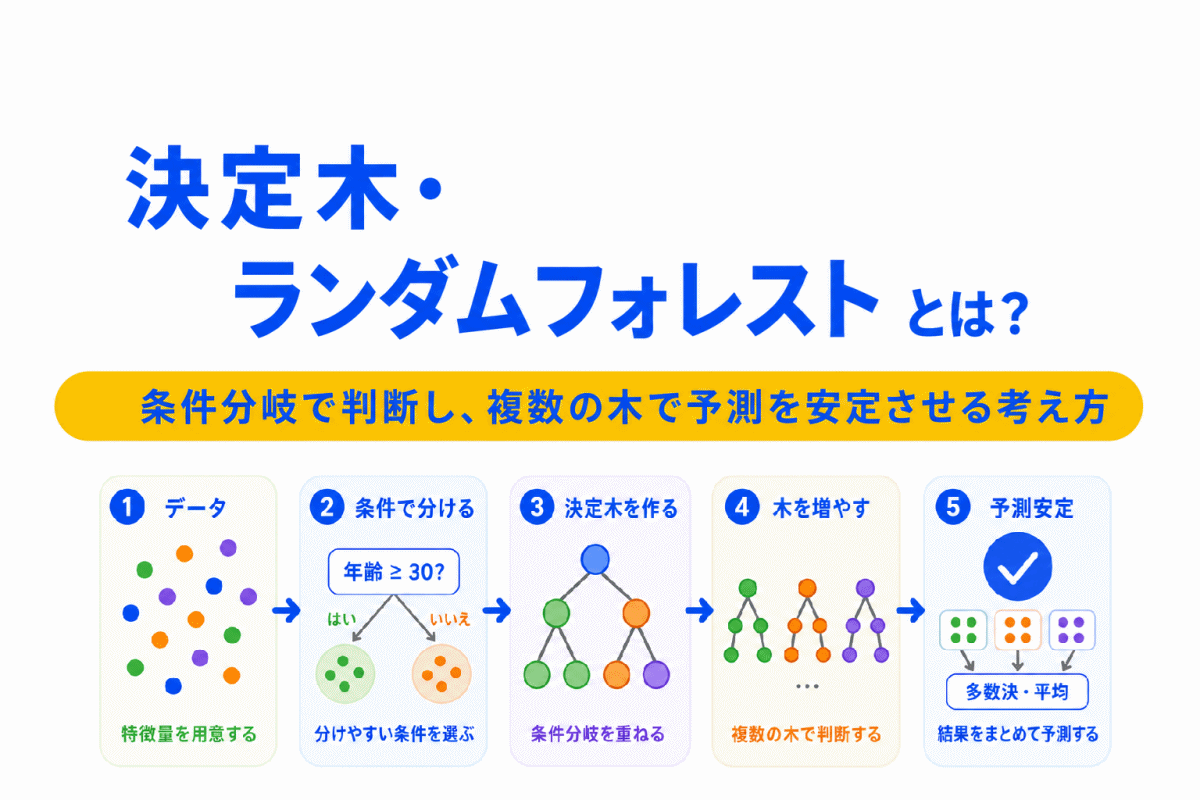
【G検定対策】決定木・ランダムフォレストとは?|木構造で判断し、複数の木で予測を安定させる考え方を整理
seo-webmaster
G検定対策ブログ
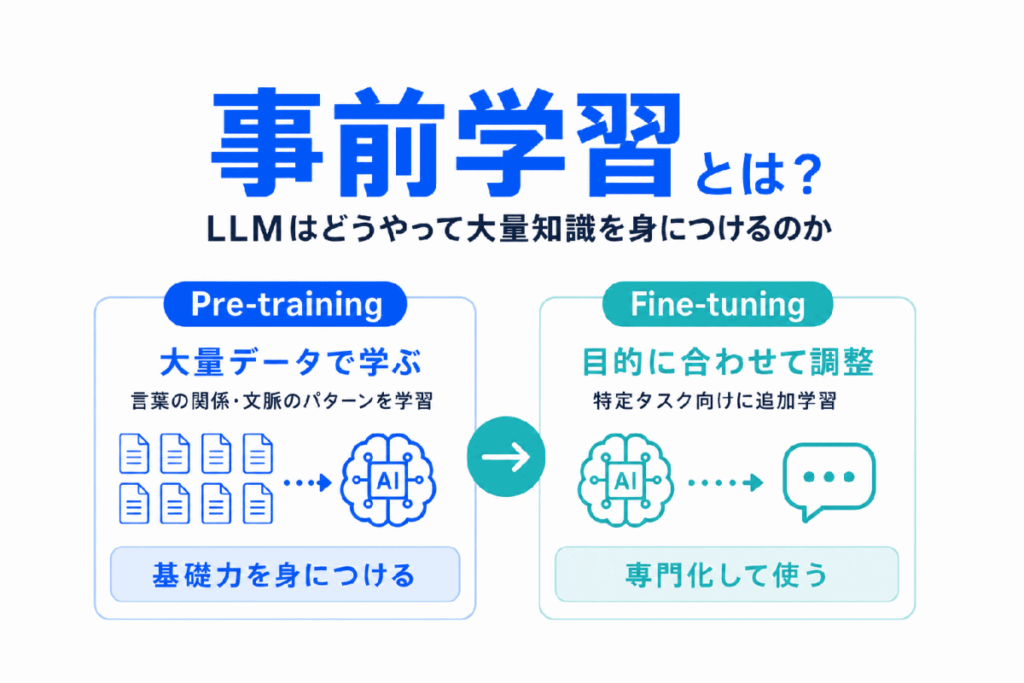
事前学習とは、AIが特定の仕事をする前に、大量のデータから言葉の使われ方や文脈のパターンを学んでおく段階のことです。
LLMやBERT、GPTのようなモデルは、いきなり質問応答や文章生成だけを学ぶのではなく、まず大量の文章を通して「言葉と言葉の関係」を身につけます。
この記事では、事前学習が何をしているのか、自己教師あり学習やファインチューニングとどう違うのかを、AIの学習をはじめたばかりの人にもわかりやすく整理します。
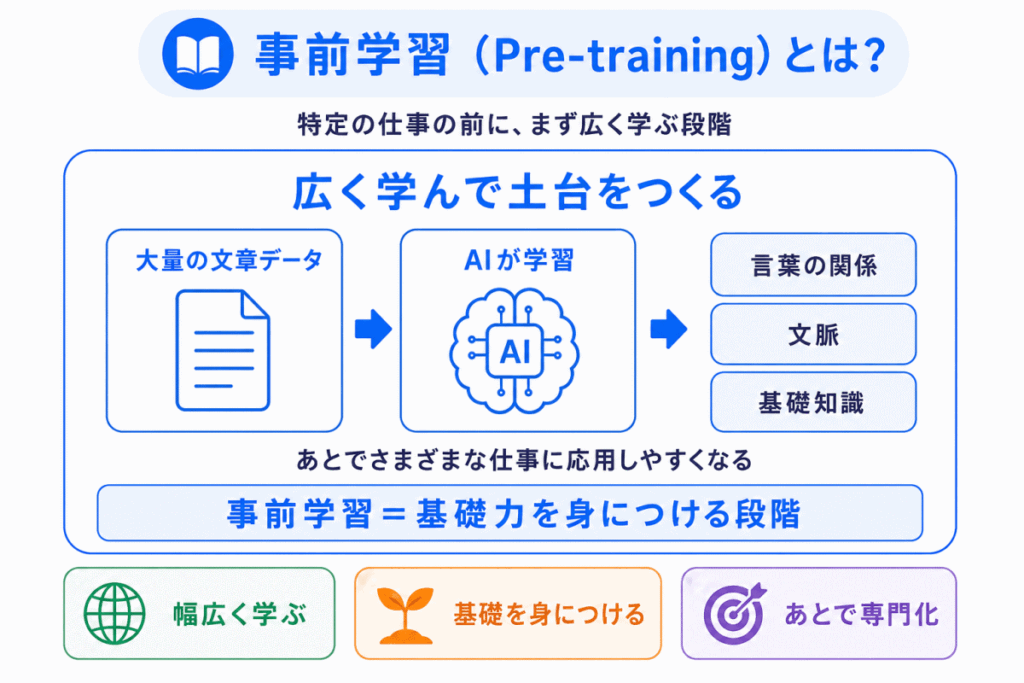
事前学習は、AIにとっての 基礎学習 のようなものです。
人間でたとえると、いきなり専門試験の問題を解く前に、文章を読む力、言葉の意味を理解する力、文脈をつかむ力を身につける段階に近いです。
AIも同じで、最初から「法律相談に答える」、「医療文書を分類する」、「チャットで自然に返答する」といった個別の仕事だけを学ぶわけではありません。
まずは大量の文章を使って
といった、言語の基本的なパターンを学びます。
この段階が 事前学習 です。
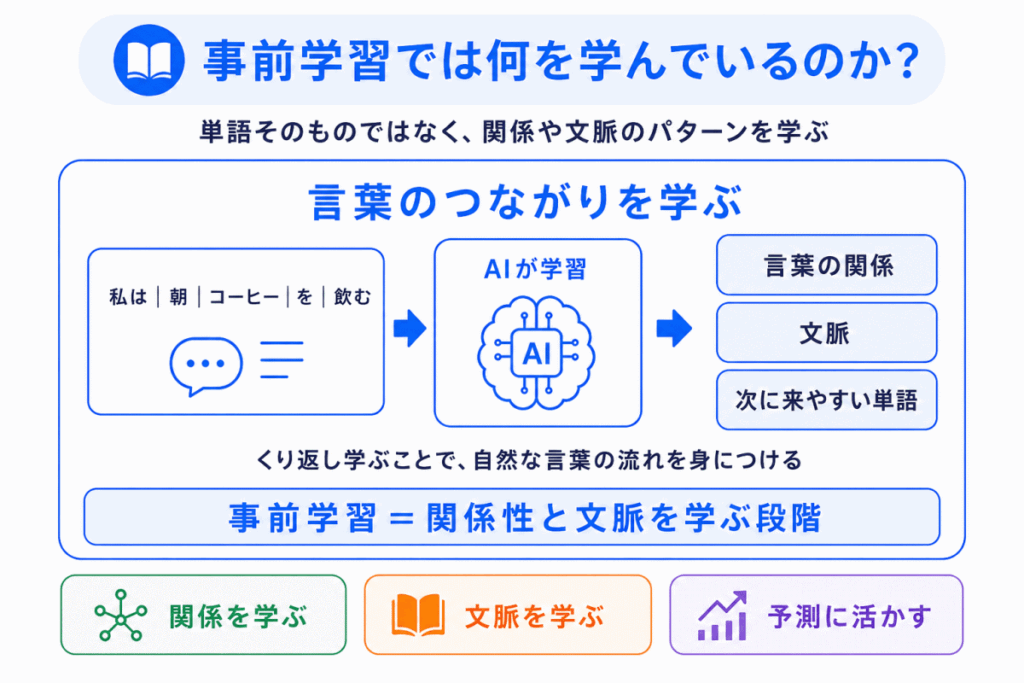
事前学習でAIが学んでいるのは、単なる単語の暗記ではありません。
重要なのは、言葉の関係性 や 文脈のパターン です。
たとえば、次のような文章があるとします。
「私は朝、コーヒーを飲んで会社へ行った」
この文章を大量のデータの中で学ぶことで、AIは次のような関係を少しずつ身につけます。
つまり、事前学習とは、AIが文章を丸暗記することではなく、言葉の使われ方の傾向を学ぶこと です。
ここを理解すると、LLMがなぜ自然な文章を生成できるのかも見えやすくなります。
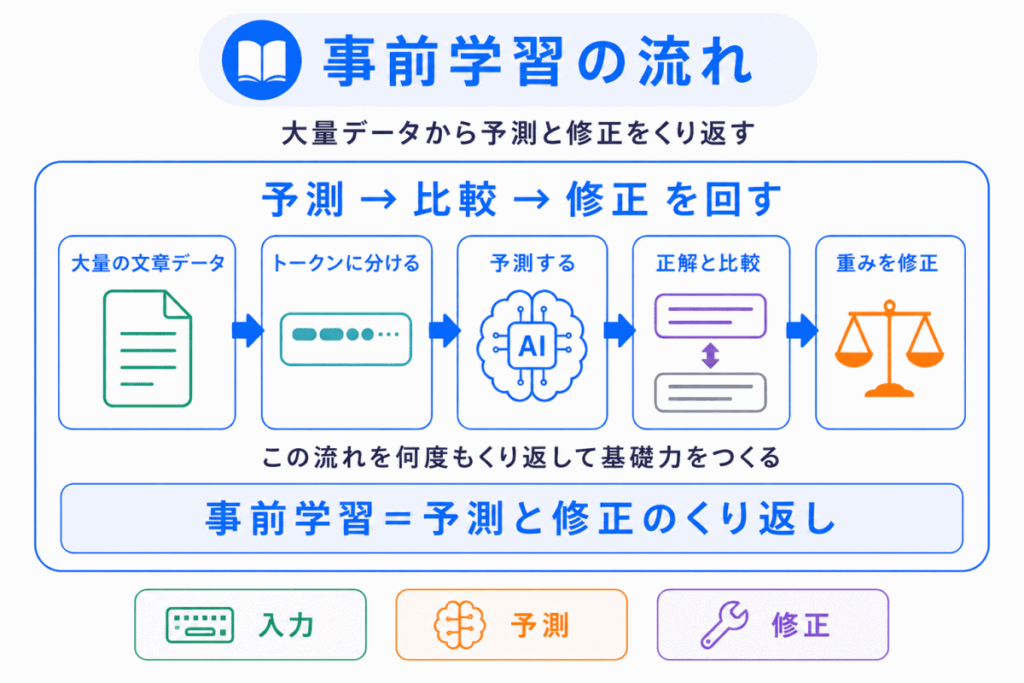
事前学習の流れは、シンプルに整理すると次のようになります。
ここで重要なのは、事前学習もAIの基本的な学習の流れと同じだという点です。
つまり
という流れを大量に繰り返しています。
LLMが賢く見えるのは、最初から知識を持っているからではありません。大量のデータから、何度も予測と修正を繰り返しているからです。
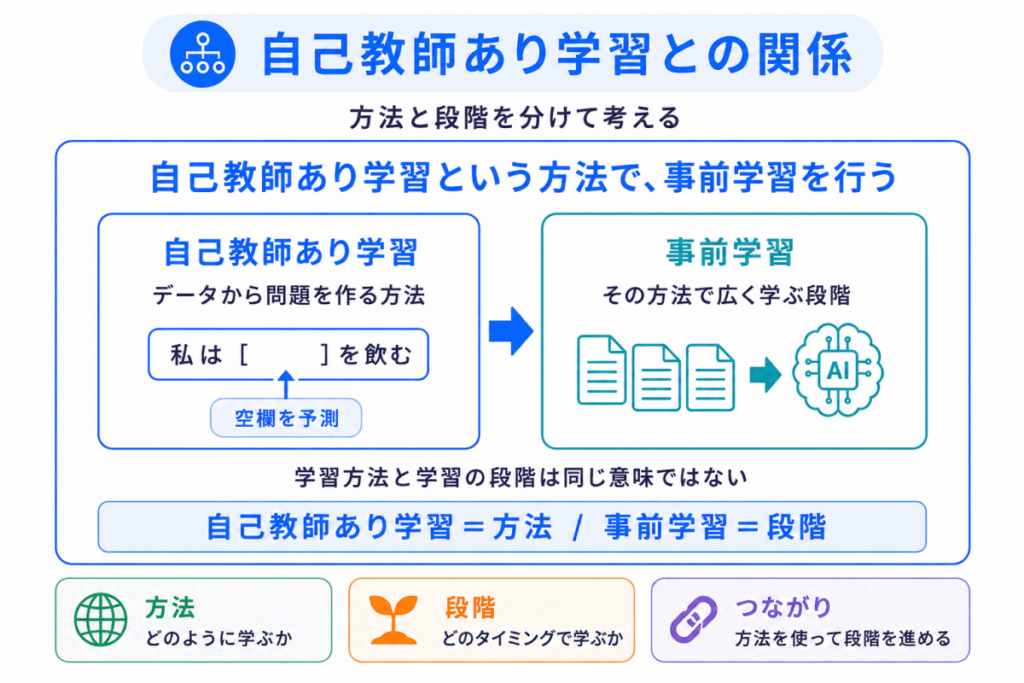
事前学習を理解するときに、よく一緒に出てくるのが 自己教師あり学習 です。
この2つは混同しやすいですが、役割が少し違います。
つまり、自己教師あり学習という方法を使って、事前学習を行う と考えるとわかりやすいです。
たとえば、文章の一部を隠して、その隠れた単語を予測する学習があります。
「私は朝、____を飲んだ」
この空欄に入る言葉を予測することで、AIは文脈を学びます。
このように、データそのものから問題と正解のような形を作り出して学習する方法が、自己教師あり学習です。
そして、その自己教師あり学習を使って、大量の文章から基礎的な言語能力を身につける段階が、事前学習です。
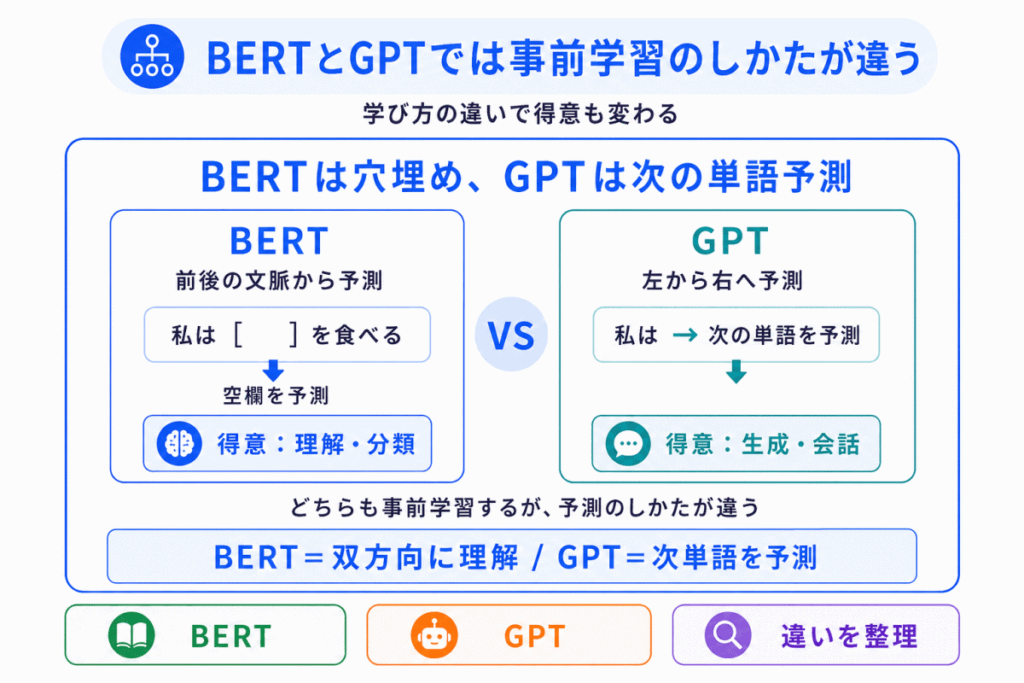
BERTとGPTは、どちらも事前学習を行います。
ただし、学び方が違います。
BERTは、文章の一部を隠して、その単語を予測するような学習をします。
そのため、前後両方の文脈を見ながら意味を理解することに向いています。
一方、GPTは、左から右へ文章を読み、次に来る単語を予測するような学習をします。
そのため、文章を自然に続けて生成することに向いています。
整理すると、次のようになります。
| モデル | 事前学習のイメージ | 得意なこと |
|---|---|---|
| BERT | 隠れた単語を前後の文脈から予測する | 文章理解・分類 |
| GPT | 次に来る単語を予測する | 文章生成 |
| LLM | 大量の文章から言語パターンを学ぶ | 文章理解・生成 |
ここで大切なのは、BERTもGPTも、いきなり特定の仕事だけを覚えているわけではないという点です。
まず、事前学習によって、言葉や文脈の基本パターンを学んでいます。
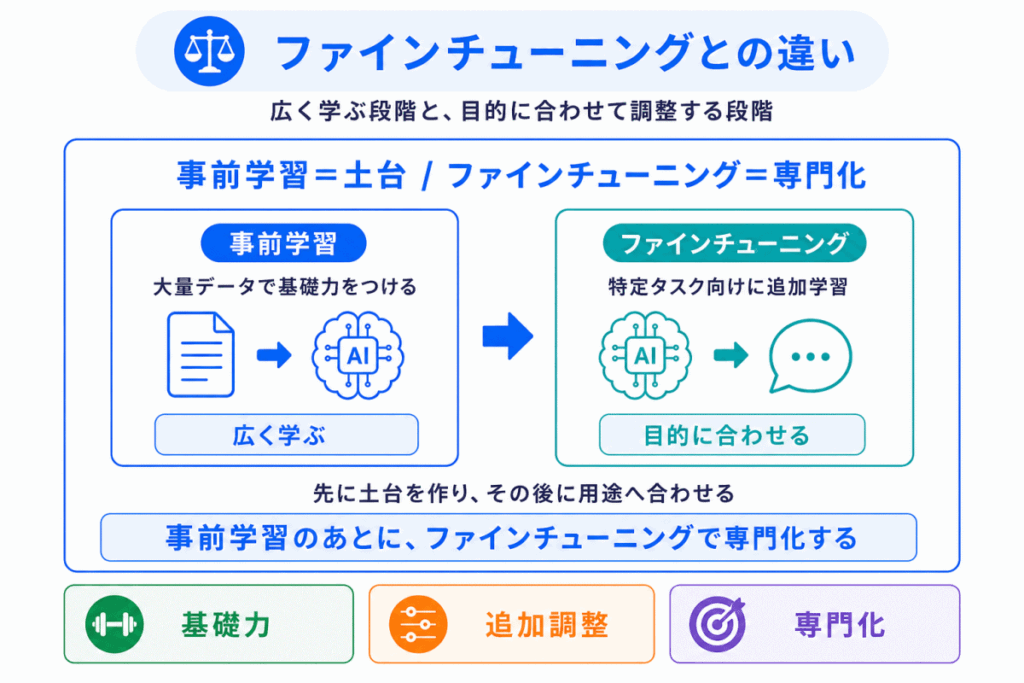
事前学習とファインチューニングも、非常に混同しやすい用語です。
違いは、次のように整理できます。
| 用語 | 役割 | イメージ |
|---|---|---|
| 事前学習 | 基礎力を身につける | 大量の文章で広く学ぶ |
| ファインチューニング | 特定の目的に合わせる | 用途に合わせて追加調整する |
たとえば、事前学習によってAIは文章の読み方や言葉の関係を広く学びます。
しかし、それだけでは「法律文書を分類する」、「医療系の質問に答える」、「カスタマーサポート向けに返答する」といった特定の用途に最適化されているとは限りません。
そこで、特定の目的に合わせて追加で学習させるのがファインチューニングです。
つまり
という関係です。
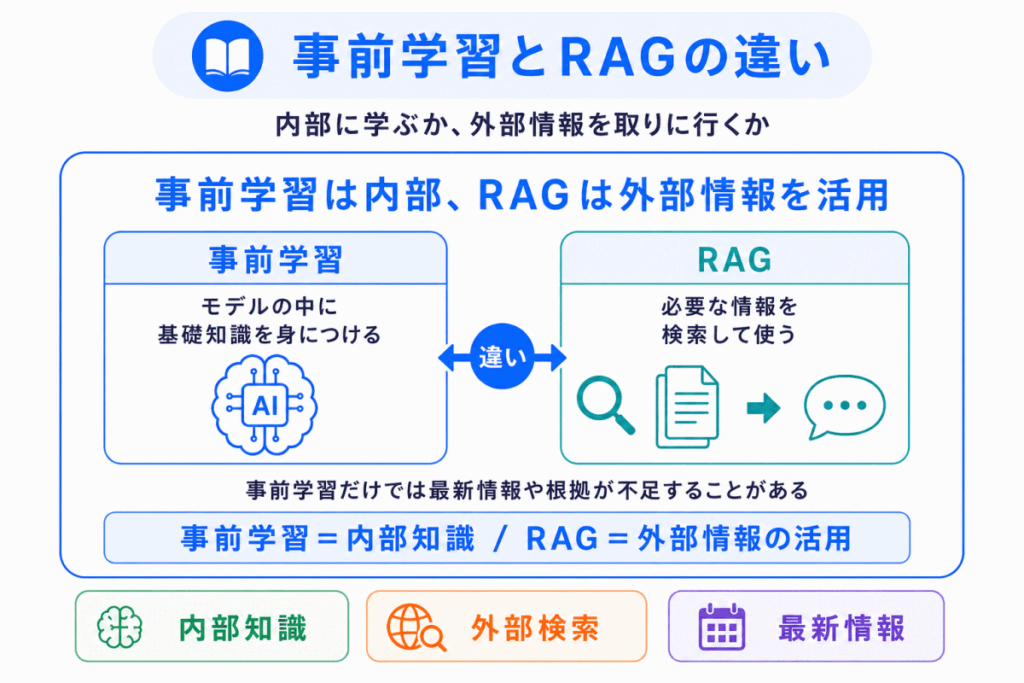
事前学習とRAGも、生成AIの文脈では混同されやすいです。
事前学習は、モデルの中に言語パターンや一般的な知識を身につける段階です。
一方、RAGは、必要に応じて外部情報を検索し、その情報を使って回答する仕組みです。
つまり
| 用語 | 何をする? | ポイント |
|---|---|---|
| 事前学習 | モデル自体を学習させる | 内部に基礎力を作る |
| RAG | 外部情報を参照して回答する | 最新情報や根拠を補う |
事前学習だけでは、学習後に出てきた新しい情報には対応しにくいです。
そこで、RAGのように外部情報を参照する仕組みが重要になります。
ここを理解すると、次の関係が見えてきます。
この流れで整理すると、生成AI関連の用語がかなりつながりやすくなります。
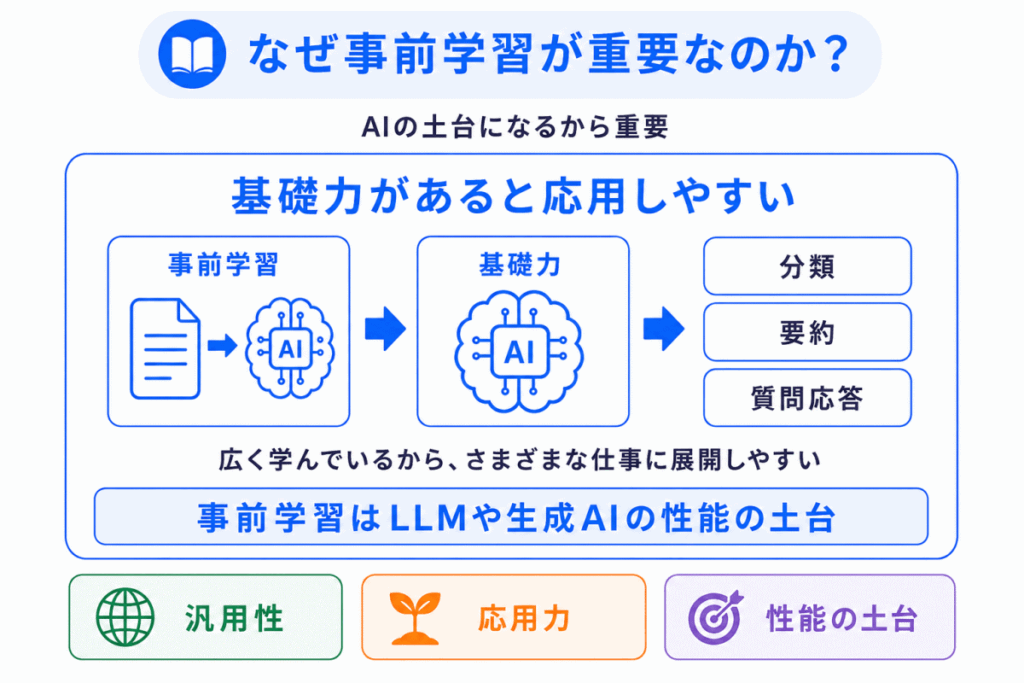
事前学習が重要なのは、AIの性能の土台になるからです。
事前学習が不十分だと、AIは言葉の意味や文脈を十分に理解できません。
逆に、大量のデータでしっかり事前学習されたモデルは、さまざまなタスクに応用しやすくなります。
たとえば、文章分類、要約、翻訳、質問応答、文章生成など、さまざまな処理に展開できます。
これは、事前学習によって汎用的な言語能力を身につけているからです。
そのため、事前学習はLLMを理解するうえで非常に重要です。
GPTやBERTを個別に覚えるだけではなく、どちらも事前学習によって基礎力を身につけたモデルである と理解すると、生成AI全体の構造が見えやすくなります。
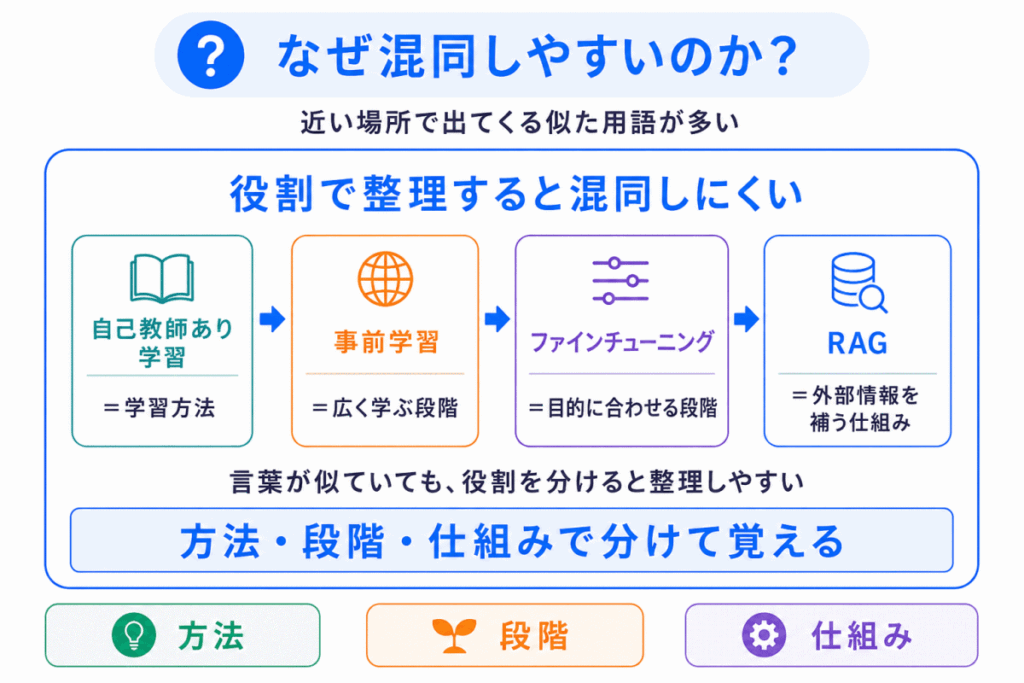
事前学習が混同されやすい理由は、似た用語が近くにたくさん出てくるからです。
特に混同しやすいのは、次の4つです。
| 用語 | 混同しやすい理由 |
|---|---|
| 自己教師あり学習 | 事前学習でよく使われる学習方法だから |
| ファインチューニング | どちらもモデルを学習させる段階だから |
| LLM | 事前学習された大規模モデルとして登場するから |
| RAG | 生成AIの改善方法として一緒に語られやすいから |
ここで大切なのは、用語を単独で覚えないことです。
次のように流れで見ると、混同しにくくなります。
このように整理すると、それぞれの役割がはっきりします。
事前学習、ファインチューニング、RAG、RLHFは、生成AIやLLMの理解で混同しやすい用語です。
どれもAIの性能や使いやすさに関係しますが、役割は異なります。
| 用語 | 意味 | 見分け方 |
|---|---|---|
| 事前学習 | 大量のデータから、言葉や知識のパターンを広く学ぶ段階 | 土台を作る |
| ファインチューニング | 事前学習済みモデルを、特定の目的に合わせて追加調整する方法 | 目的に合わせて専門化する |
| RAG | 外部情報を参照しながら回答を生成する仕組み | 外部情報を使って補う |
| RLHF | 人間の評価を使って、好ましい回答に近づける調整方法 | 人間の評価で調整する |
G検定では、事前学習という用語そのものだけでなく、関連する用語との違いが問われる可能性があります。
特に注意したいのは、次のような聞かれ方です。
選択肢では、次のような混同が起こりやすいです。
G検定では、細かい数式よりも、どの段階で何をしているのか が重要です。
つまり、事前学習は、モデルが広い基礎力を身につける段階 と理解しておくと、選択肢に惑わされにくくなります。
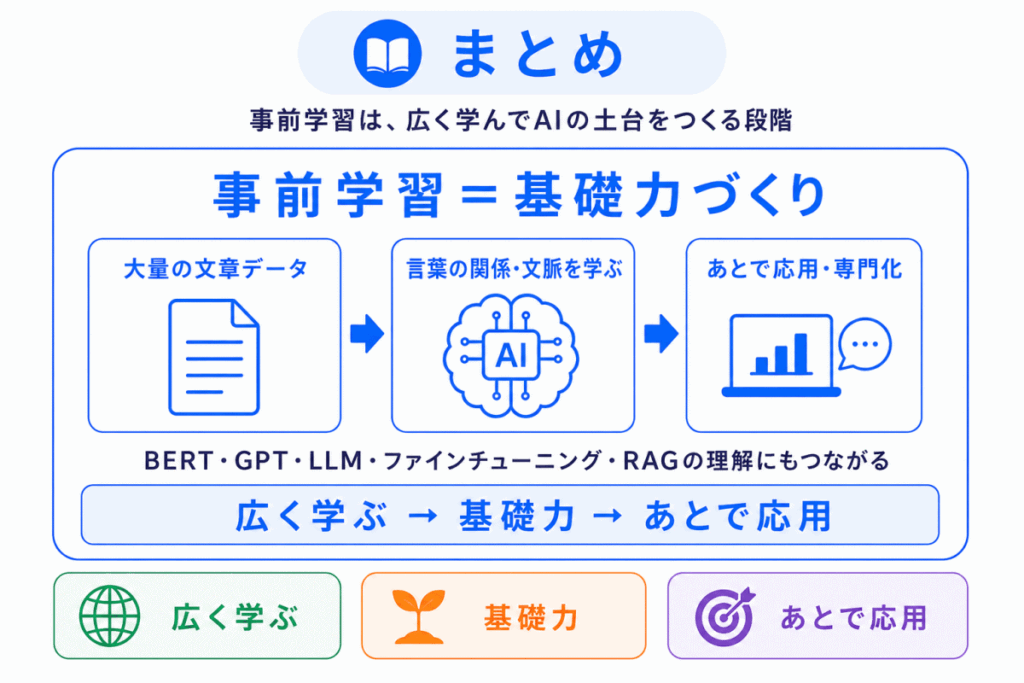
事前学習(Pre-training)とは、AIが特定の仕事をする前に、大量の文章データから言葉の使われ方や文脈のパターンを学ぶ段階です。
BERTやGPT、LLMは、いきなり文章理解や文章生成だけを学んでいるわけではありません。
まず事前学習によって、言葉と言葉の関係、文脈、次に来やすい単語、文章全体の意味の傾向などを広く学びます。
ここで重要なのは、事前学習を単なる「知識の暗記」と考えないことです。
事前学習は、大量の文章から言語のパターンを学び、さまざまなタスクに応用できる基礎力を作る段階です。
また、事前学習は自己教師あり学習、ファインチューニング、RAGと混同されやすい用語です。
整理すると
です。
G検定では、用語を単独で覚えるよりも、AIがどの順番で学習し、どの段階で何をしているのかを理解することが大切です。
事前学習を理解すると、BERT、GPT、LLM、ファインチューニング、RAGの関係が一気につながりやすくなります。
事前学習は、AIが特定の仕事をする前に、大量データから基礎的なパターンを学ぶ段階です。
自己教師あり学習、ファインチューニング、LLM、GPT、BERT、RAGとあわせて確認すると、生成AIや言語モデルの学習の流れを整理しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| 自己教師あり学習とは? | データから予測問題を作る学習/生成AIで使われる考え方/事前学習との関係 |
| ファインチューニングとは? | 事前学習済みモデルの専門化/追加学習の考え方/事前学習との違い |
| LLMとは? | 大規模言語モデルの意味/GPTとの違い/生成AIとの関係 |
| GPTとは? | 文章生成に向いたモデル/Transformerとの関係/事前学習とのつながり |
| BERTとは? | 文章理解に向いたモデル/GPTとの違い/事前学習の違い |
| RAGとは? | 外部情報を参照する仕組み/事前学習だけでは補いにくい情報/生成AIの弱点補完 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。