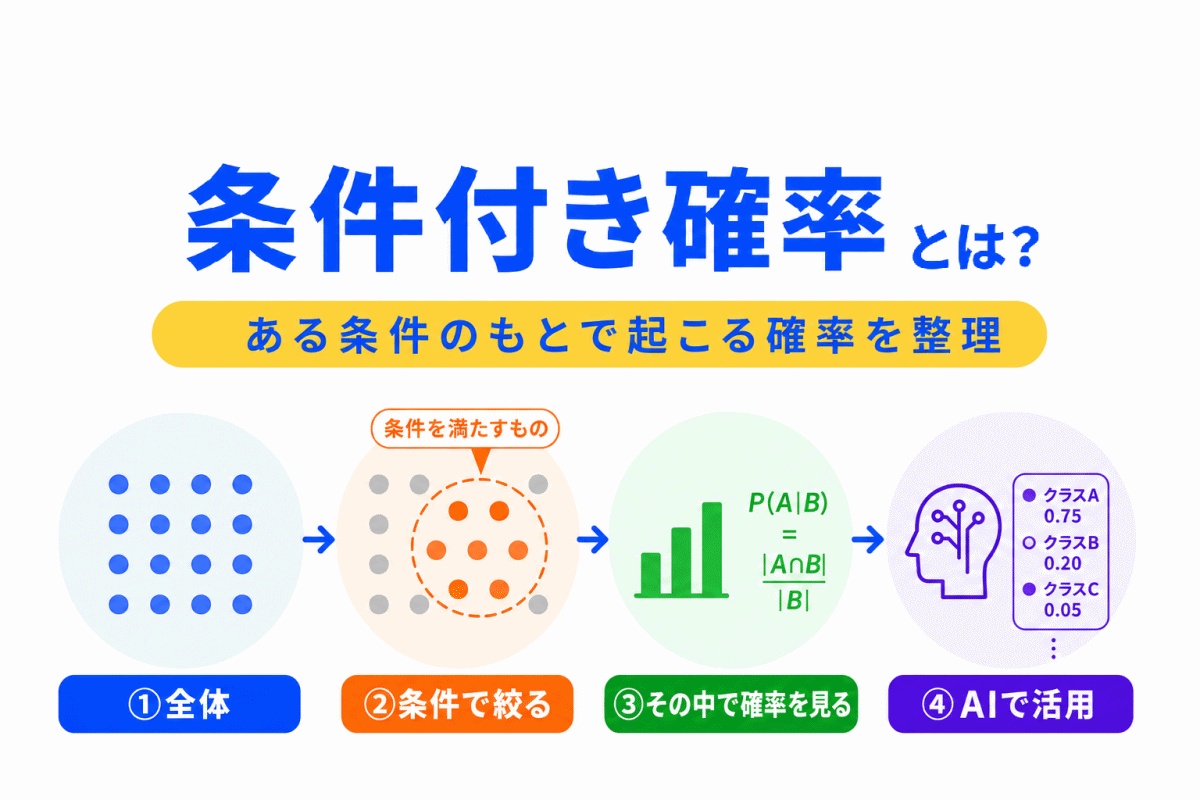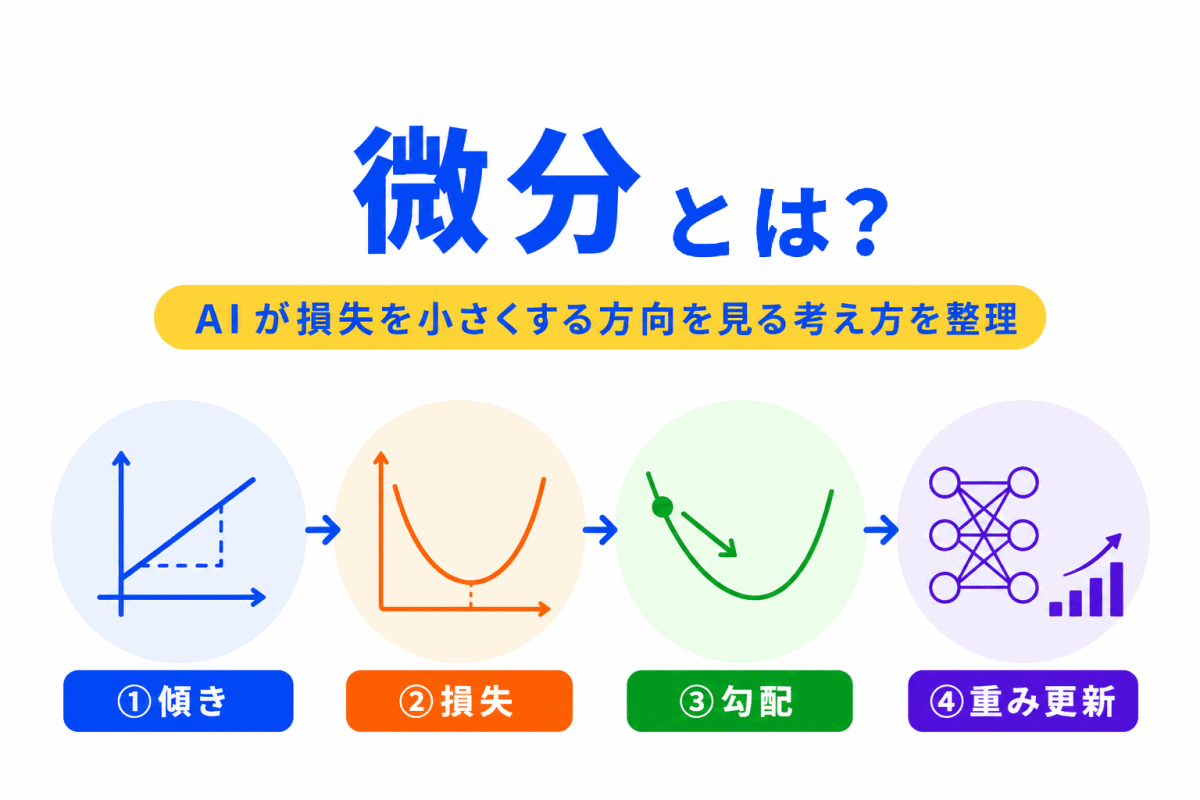
【G検定対策】微分とは?|勾配降下法と重みの更新につながる考え方を整理
seo-webmaster
G検定対策ブログ
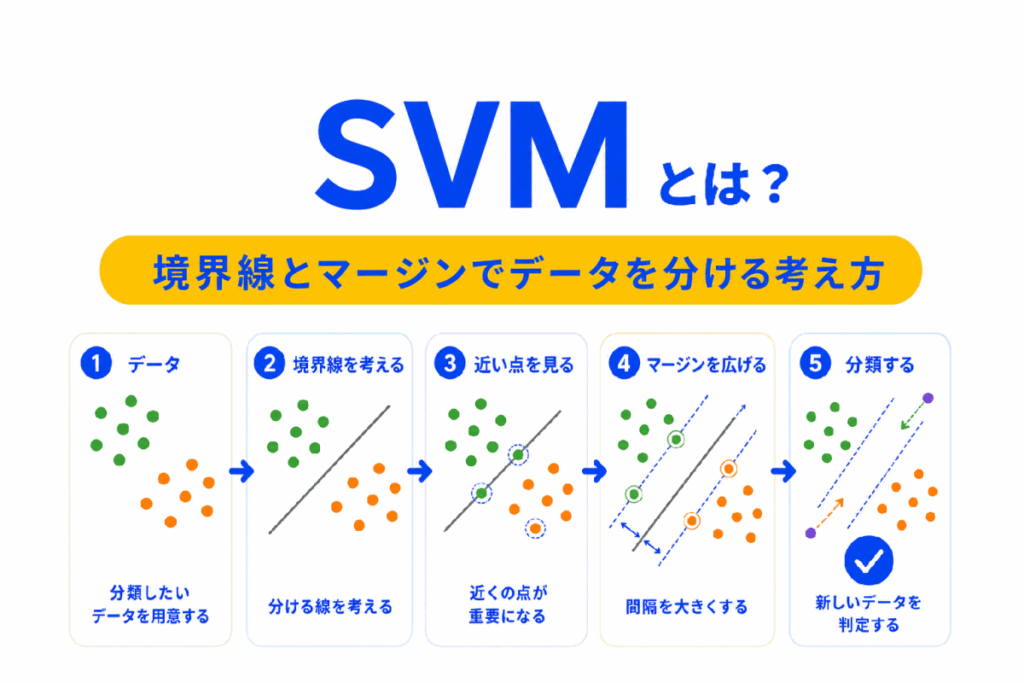
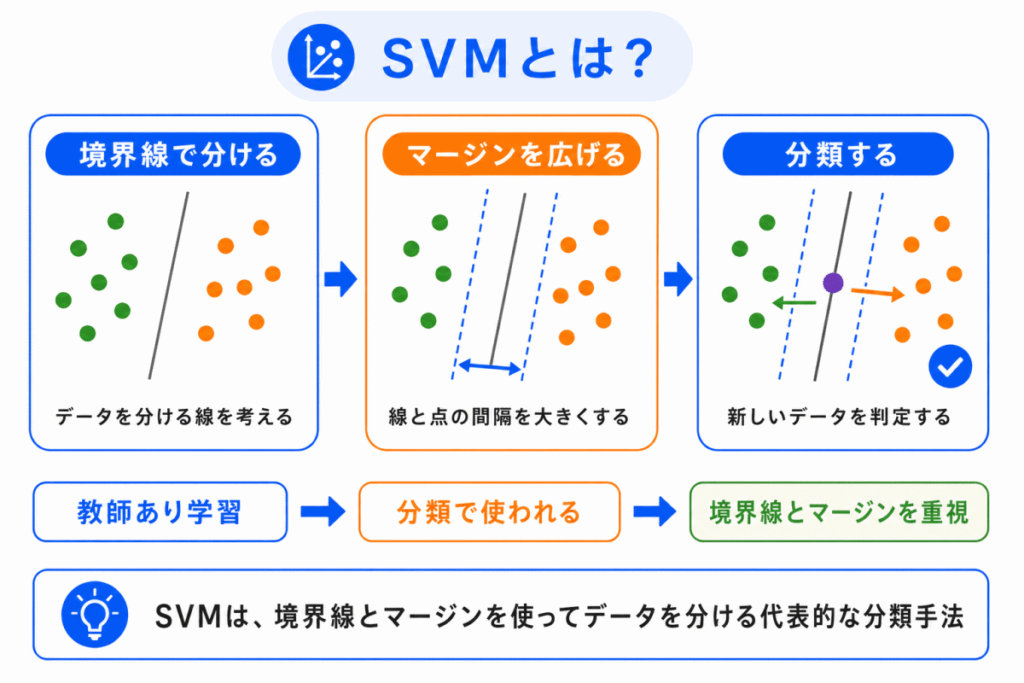
SVM とは、データを分ける境界線を考える教師あり学習の手法です。
特に分類でよく使われます。
単にデータを分けるだけでなく、境界線とデータの間隔であるマージンをできるだけ大きくすることを重視します。
G検定では、SVM を難しい数式で覚えるよりも、「境界線」、「マージン」、「サポートベクター」、「カーネル法」の関係で整理することが大切です。
SVM は、Support Vector Machineの略です。
日本語では、サポートベクターマシン と呼ばれます。
SVM は、データを2つのグループに分ける境界線を考える手法です。
たとえば、メールを迷惑メールか通常メールかに分ける場合を考えます。
SVM は、どこに線を引けばうまく分けられるかを考えます。
ただし、SVM は「分けられればよい」と考えるだけではありません。
境界線の近くにあるデータとの距離をできるだけ広く取ろうとします。
この距離が、マージンです。
| 用語 | 意味 | G検定での押さえ方 |
|---|---|---|
| SVM | 境界線を使ってデータを分ける手法 | 教師あり学習の代表的な分類手法 |
| マージン | 境界線と近くのデータとの間隔 | できるだけ大きくする |
| サポートベクター | 境界線に近い重要なデータ | 境界線を決める手がかりになる |
| カーネル法 | 線形では分けにくいデータを扱う工夫 | 非線形分類とセットで押さえる |
SVM は、次のように覚えると理解しやすいです。
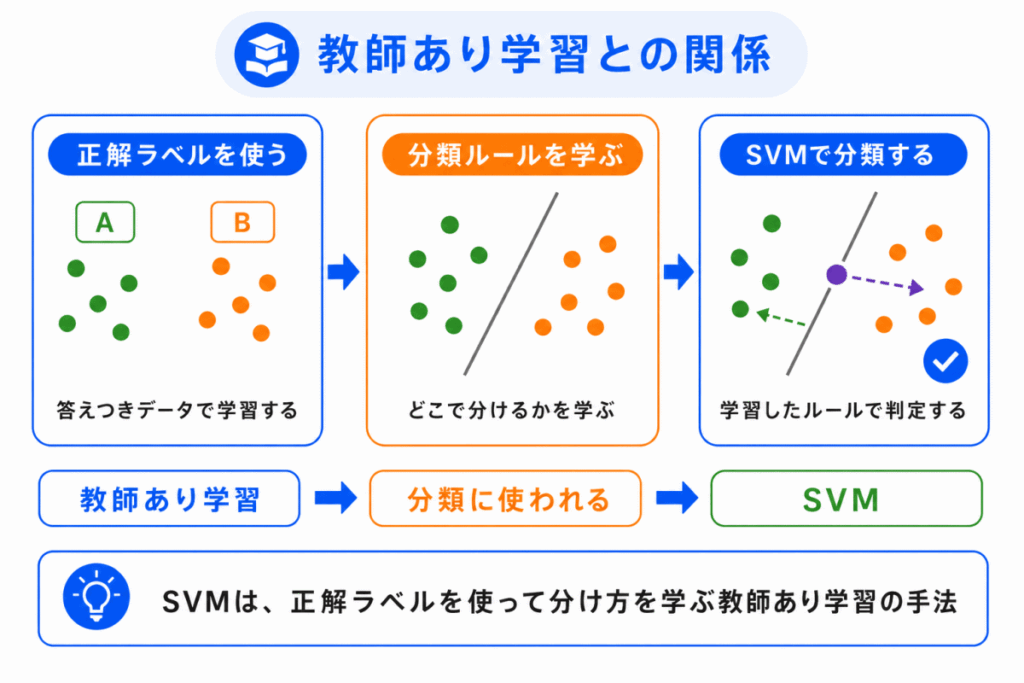
SVM は、教師あり学習で使われる代表的な手法です。
教師あり学習では、入力データと正解ラベルを使って学習します。
SVM の場合も、あらかじめ正解ラベルがあるデータを使います。
たとえば、次のようなデータです。
この正解ラベルをもとに、SVM は境界線を学習します。
G検定では、SVM を次の流れで押さえると整理しやすいです。
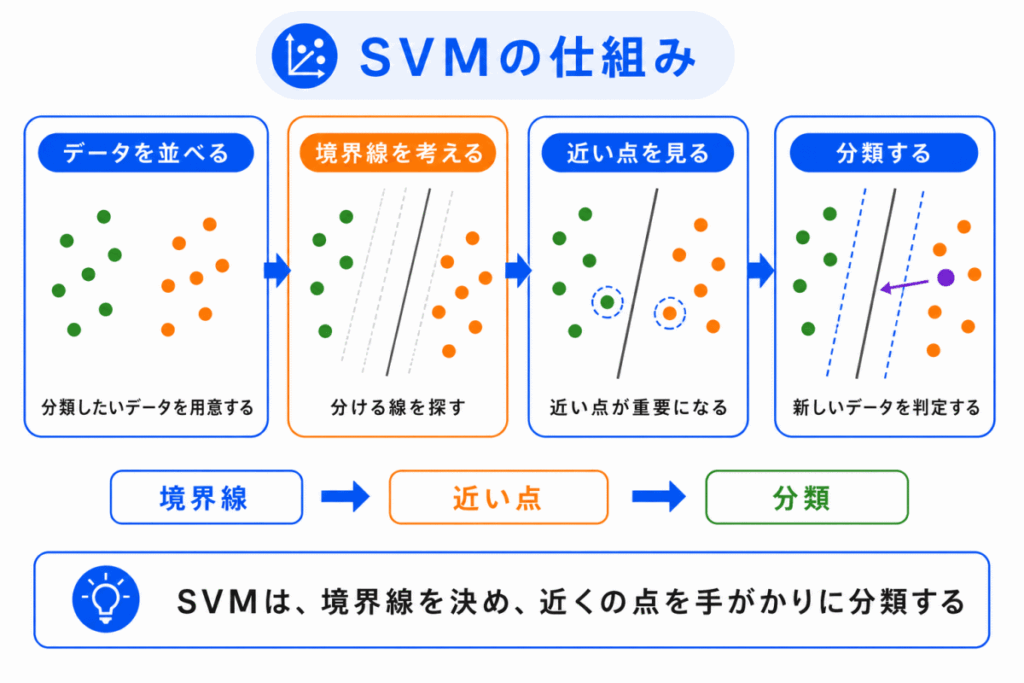
SVM の考え方は、境界線を引いてデータを分けることです。
ただし、同じように分けられる境界線は複数あります。
その中で、SVM はマージンが大きい境界線を選びます。
マージンが大きいと、新しいデータが少しずれても分類しやすくなります。
逆に、境界線がデータに近すぎると、新しいデータに弱くなりやすいです。
SVM は、境界線そのものだけではなく、境界線の近くにあるデータを重視します。
この近くにあるデータが、サポートベクターです。
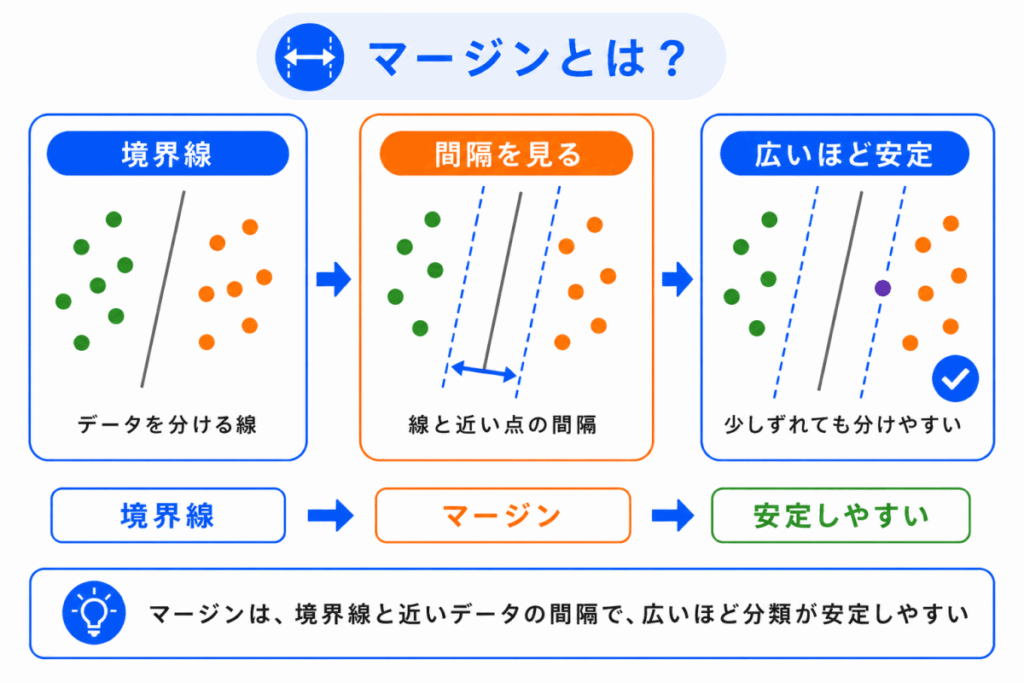
マージンとは、境界線とデータの間隔 です。
SVM では、このマージンをできるだけ大きくすることを目指します。
イメージとしては、2つのグループの間にできるだけ広い道を作るような考え方です。
道が狭いと、少し位置がずれただけで判断が変わってしまいます。
道が広いと、多少の違いがあっても安定して分類しやすくなります。
そのため、SVM ではマージン最大化が重要です。
G検定では、次のように押さえると十分です。
SVM = マージンを最大化する分類手法
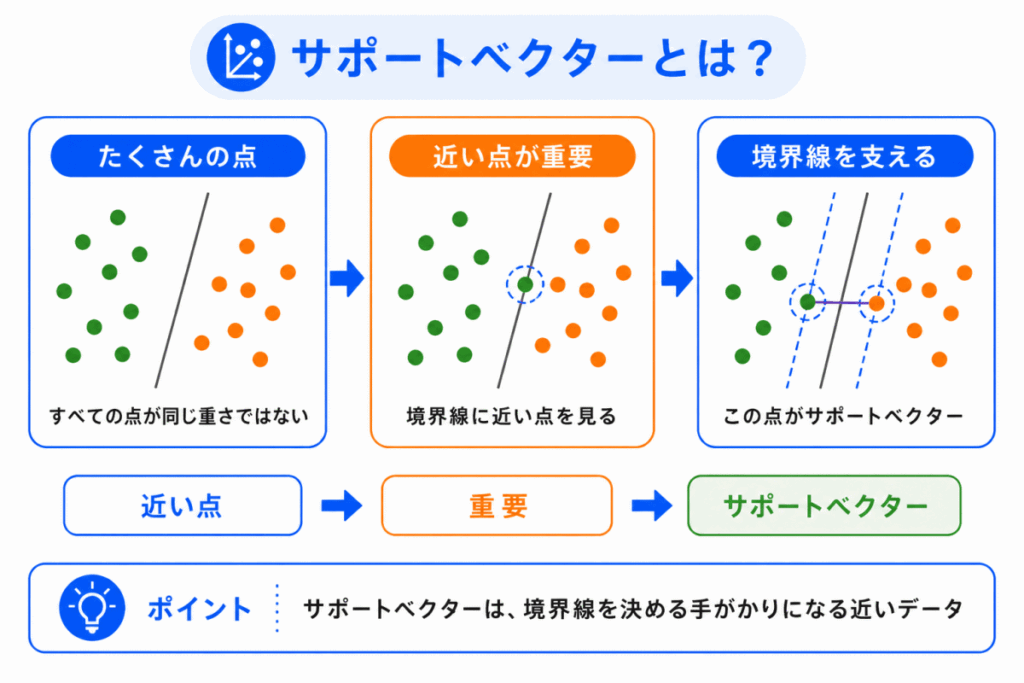
サポートベクターとは、境界線に近いデータのことです。
すべてのデータが境界線を決めるわけではありません。
SVM では、境界線の近くにある一部のデータが特に重要になります。
このデータが、分類の境界を支えます。
そのため、サポートベクターと呼ばれます。
AIの学習をはじめたばかりの人は、次のように理解するとよいです。
サポートベクター=境界線を決めるうえで重要な、近くのデータ
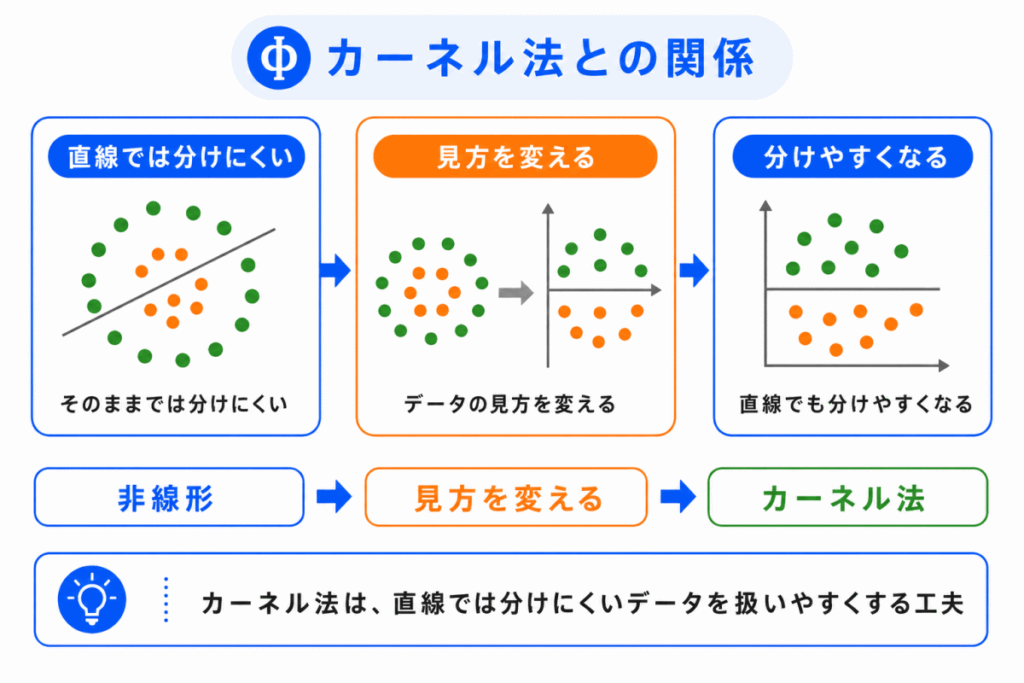
SVM は、直線や平面で分けられるデータに対して使いやすい手法です。
しかし、現実のデータは単純な直線で分けられないことがあります。
たとえば、内側と外側に分かれたようなデータは、一本の直線では分けにくいです。
このようなときに出てくるのが、カーネル法です。
カーネル法は、データの見方を変えて、複雑な分け方をしやすくする考え方です。
| 分類の形 | 意味 | SVMとの関係 |
|---|---|---|
| 線形分類 | 直線や平面で分ける | 基本的なSVMのイメージ |
| 非線形分類 | 曲線のような複雑な形で分ける | 単純な直線では難しい場合がある |
| カーネル法 | データの見方を変える工夫 | 非線形分類を扱いやすくする |
G検定では、カーネル法を数式で深く追う必要はありません。
SVM とカーネル法は、非線形な分類を扱うために関係する、と押さえるのが大切です。
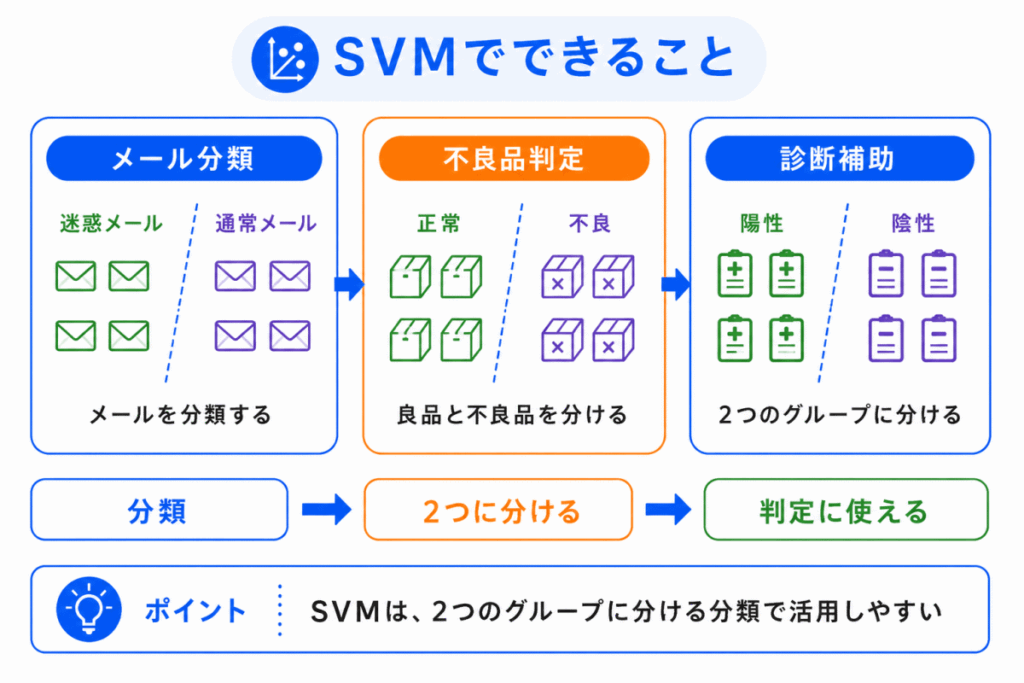
SVM は、分類でよく使われます。
代表的には、2つのグループに分ける二値分類です。
たとえば、次のような使い方があります。
また、SVM の考え方は回帰にも応用されます。
ただし、G検定では、まず分類手法としての SVM を押さえるのが重要です。
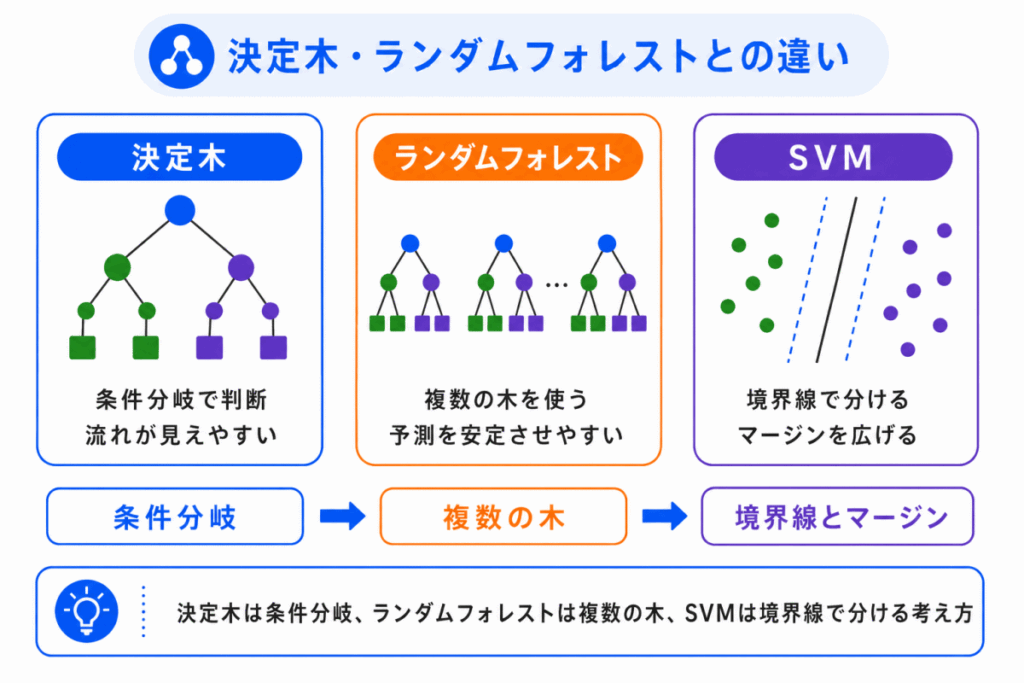
SVM は、決定木やランダムフォレストと同じく、教師あり学習で使われる手法です。
ただし、分け方の考え方が違います。
決定木は、条件分岐をたどって判断します。
ランダムフォレストは、複数の決定木を組み合わせて予測を安定させます。
SVM は、境界線とマージンを考えて分類します。
| 手法 | 分け方の考え方 | 押さえるポイント |
|---|---|---|
| 決定木 | 条件分岐で分ける | 判断の流れが見えやすい |
| ランダムフォレスト | 複数の決定木を組み合わせる | 予測を安定させやすい |
| SVM | 境界線とマージンで分ける | マージン最大化が重要 |
この違いを押さえると、教師あり学習の代表的な手法を混同しにくくなります。
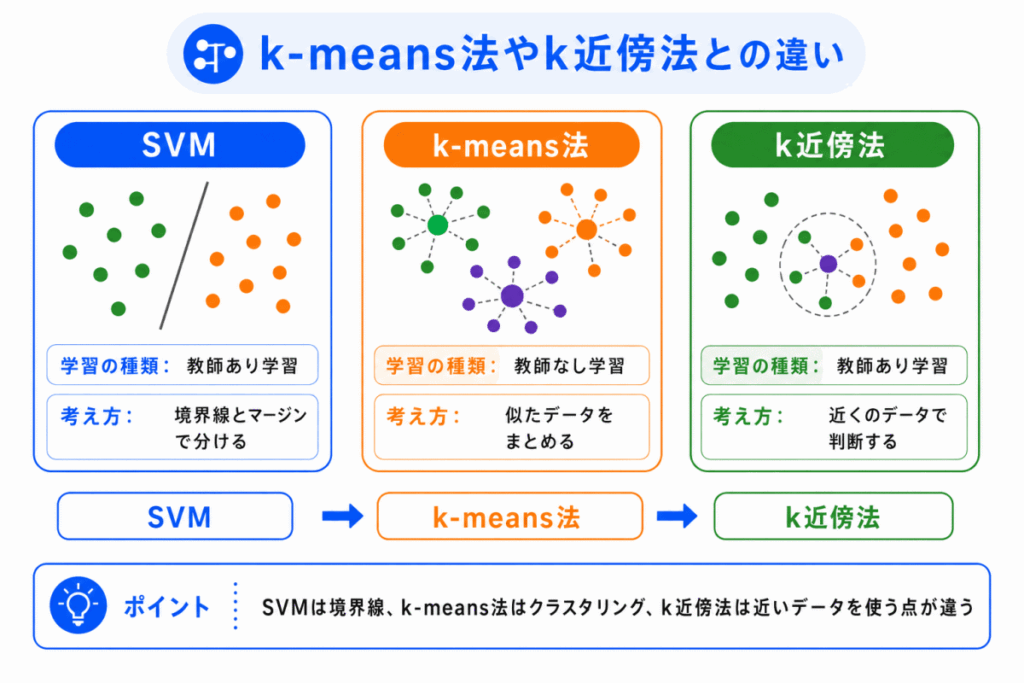
SVM は、k-means法やk近傍法とも混同しやすいです。
名前の印象ではなく、学習の種類と判断方法で整理するとわかりやすくなります。
| 手法 | 学習の種類 | 判断の考え方 |
|---|---|---|
| SVM | 教師あり学習 | 境界線とマージンで分ける |
| k-means法 | 教師なし学習 | 似たデータを代表点に近いグループへ分ける |
| k近傍法 | 教師あり学習 | 近くにあるデータをもとに判断する |
G検定では、SVM とk-means法を同じものとして覚えないように注意します。
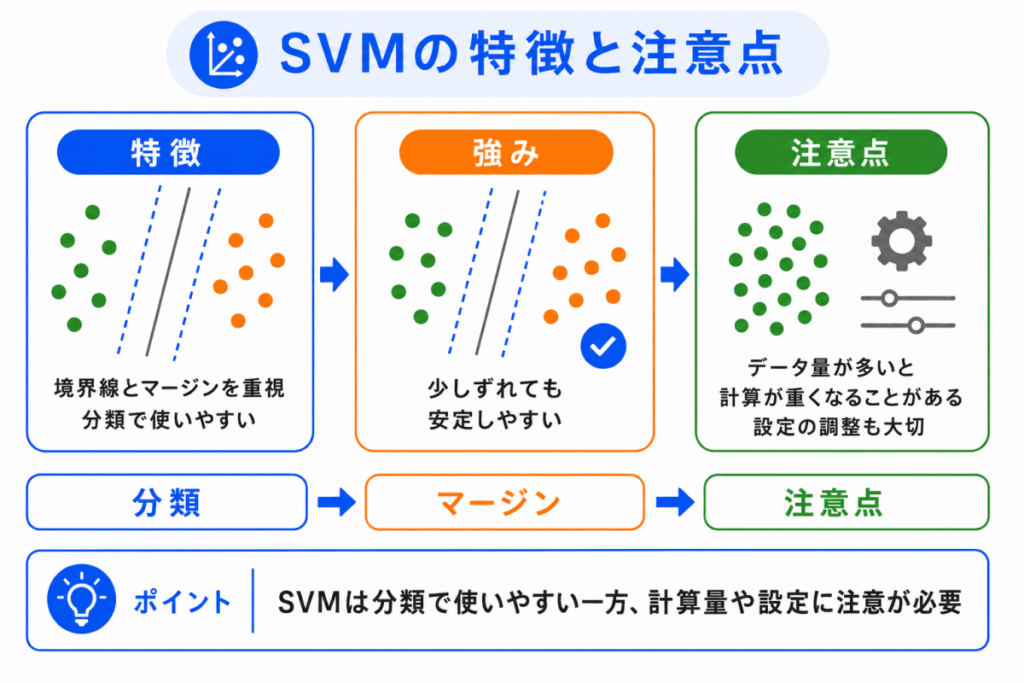
SVM には、マージンを大きくすることで、分類を安定させやすいという特徴があります。
一方で、データ量が多い場合や、特徴量が多い場合には、計算が重くなることがあります。
また、カーネルやパラメータの選び方によって結果が変わります。
そのため、SVMも万能ではありません。
| 項目 | 内容 |
|---|---|
| 特徴 | マージンを大きくして分類する |
| 強み | 境界がはっきりした分類で使いやすい |
| 注意点 | データ量や特徴量によって計算が重くなることがある |
| 関連用語 | マージン、サポートベクター、カーネル法 |
G検定では、細かい計算よりも、SVM が何を重視して分類するのかを押さえます。
G検定では、SVM について、数式を細かく解くよりも意味理解が重要です。
特に、次のような問われ方に注意します。
特に重要なのは、次の整理です。
この流れで押さえると、SVM の位置づけがわかりやすくなります。
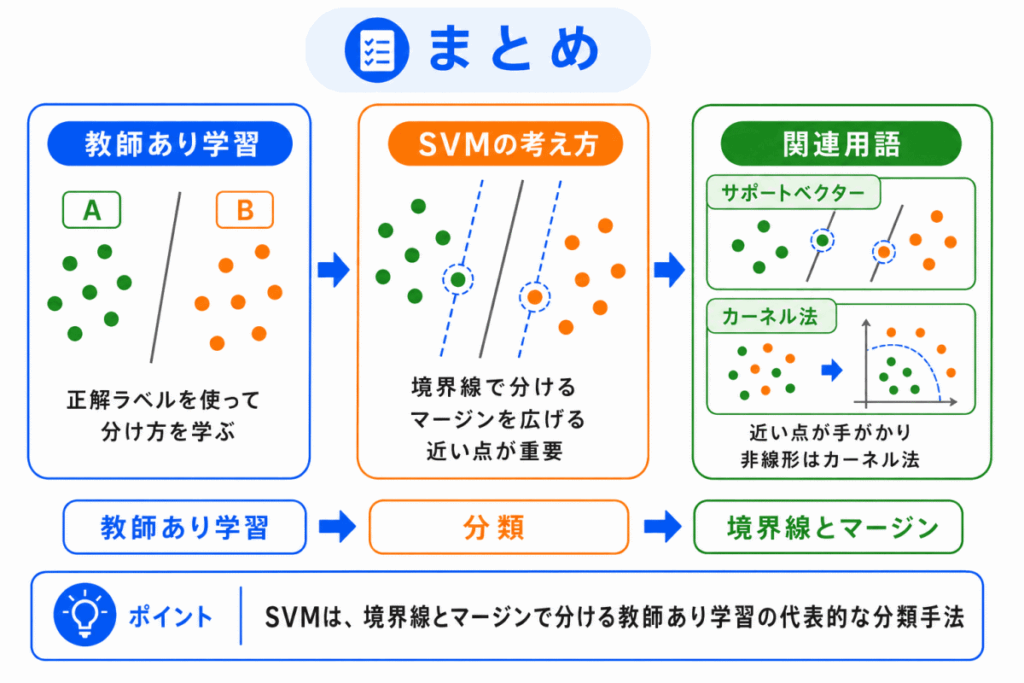
SVM は、教師あり学習の代表的な分類手法です。
データを分ける境界線を考え、その境界線とデータの間隔であるマージンをできるだけ大きくしようとします。
境界線に近い重要なデータは、サポートベクターと呼ばれます。
また、直線では分けにくいデータを扱う考え方として、カーネル法とも関係します。
G検定では、SVM を数式で覚えるよりも、境界線、マージン、サポートベクター、カーネル法の関係で理解することが大切です。
教師あり学習の代表的な手法を整理するなら、こちらの記事がおすすめです。
教師あり学習、教師なし学習、強化学習の違いを確認するなら、こちらの記事がおすすめです。
条件分岐で分ける手法と比較するなら、こちらの記事がおすすめです。

教師なし学習との違いを確認するなら、こちらの記事がおすすめです。
データを学習しやすく整える流れを確認するなら、こちらの記事がおすすめです。
特徴量と分類結果の関係を確認するなら、こちらの記事がおすすめです。

機械学習全体の中で位置づけを確認するなら、こちらの記事がおすすめです。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認