【G検定対策】著作権と生成AIとは?|AI活用でなぜ権利の理解が重要になるのか
seo-webmaster
G検定対策ブログ
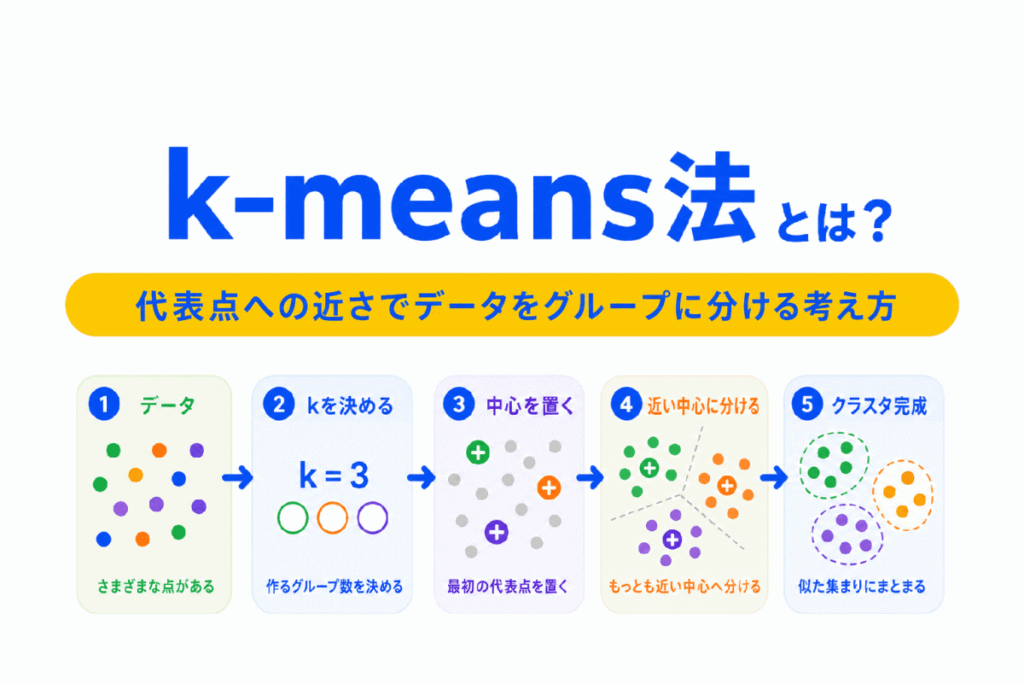
k-means法とは、似ているデータをいくつかのグループに分けるクラスタリング手法です。教師なし学習の代表的な方法であり、G検定でもよく出てくる考え方です。
クラスタリングは、正解ラベルがないデータを、似ているもの同士のグループに分ける方法でした。その中でk-means法は、あらかじめクラスタ数 k を決め、各データを代表点に近いグループへ割り当てていきます。
この記事では、k-means法の意味、クラスタリングとの関係、基本的な流れ、注意点、G検定で押さえたいポイントを整理します。
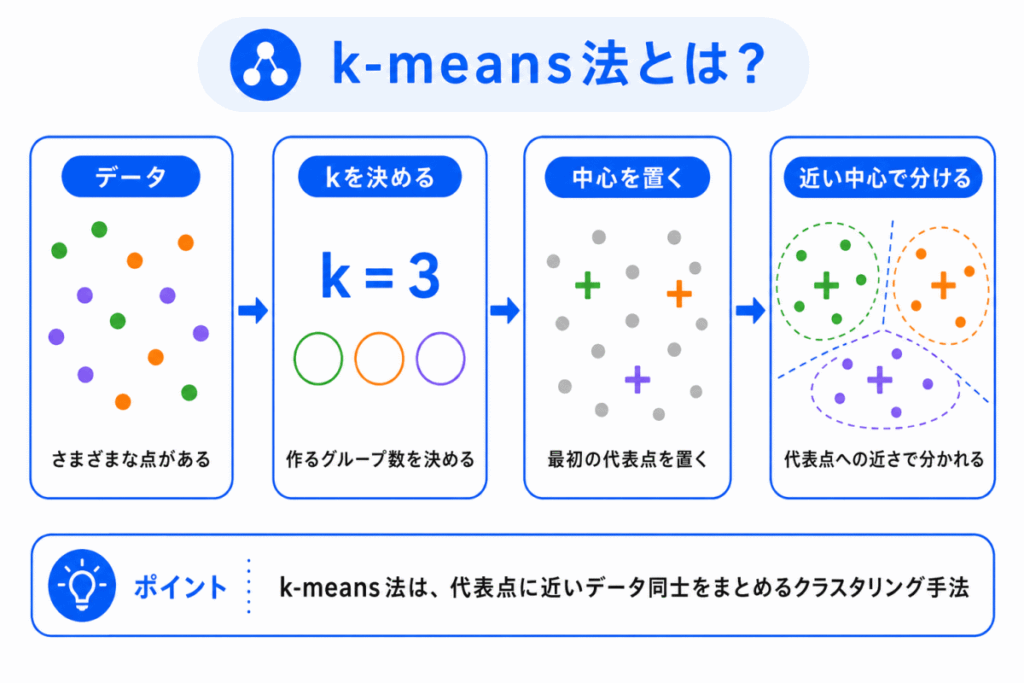
k-means法とは、データを k 個のクラスタに分ける代表的なクラスタリング手法です。
ここでいう k は、作りたいグループの数を表します。
たとえば、データを3つのグループに分けたい場合は、k=3 と考えます。
k-means法では、各クラスタの中心を考えます。
そして、それぞれのデータを、近い中心のグループへ割り当てます。
つまり、k-means法は、次のように考えるとわかりやすいです。
| 用語 | 意味 |
|---|---|
| k-means法 | データを k 個のクラスタに分ける代表的な手法 |
| k | 作りたいクラスタの数 |
| クラスタ | 似ているデータを集めたグループ |
| クラスタ中心 | 各クラスタを代表する中心点 |
k-means法では、データとクラスタ中心の距離を見ながら、どのグループに入れるかを決めます。
そのため、k-means法は「代表点に近いデータ同士をまとめる方法」と考えると理解しやすいです。
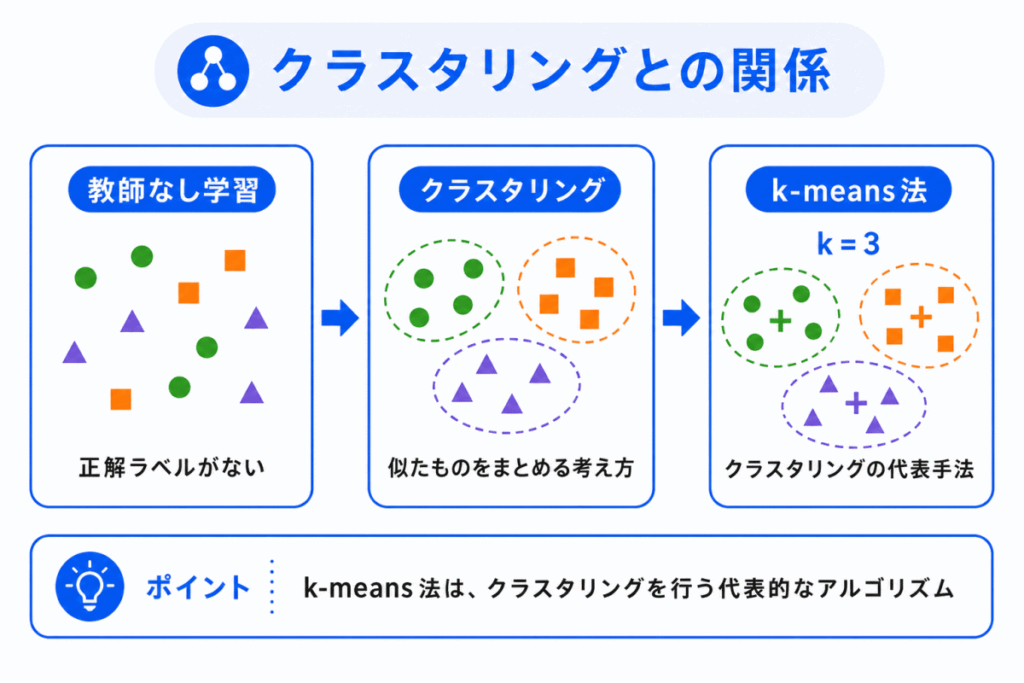
k-means法は、クラスタリングの代表的なアルゴリズムです。
クラスタリングは、似ているデータをグループに分ける考え方です。
k-means法は、そのクラスタリングを実際に行うための具体的な方法です。
関係を整理すると、次のようになります。
つまり、k-means法を単独で覚えるのではなく、教師なし学習、クラスタリング、k-means法の順番で理解すると整理しやすくなります。
| 項目 | 位置づけ |
|---|---|
| 教師なし学習 | 正解ラベルなしでデータの構造を見つける学習 |
| クラスタリング | 似ているデータをグループに分ける考え方 |
| k-means法 | クラスタリングを行う代表的な手法 |
G検定では、k-means法は教師なし学習の代表例として押さえることが大切です。
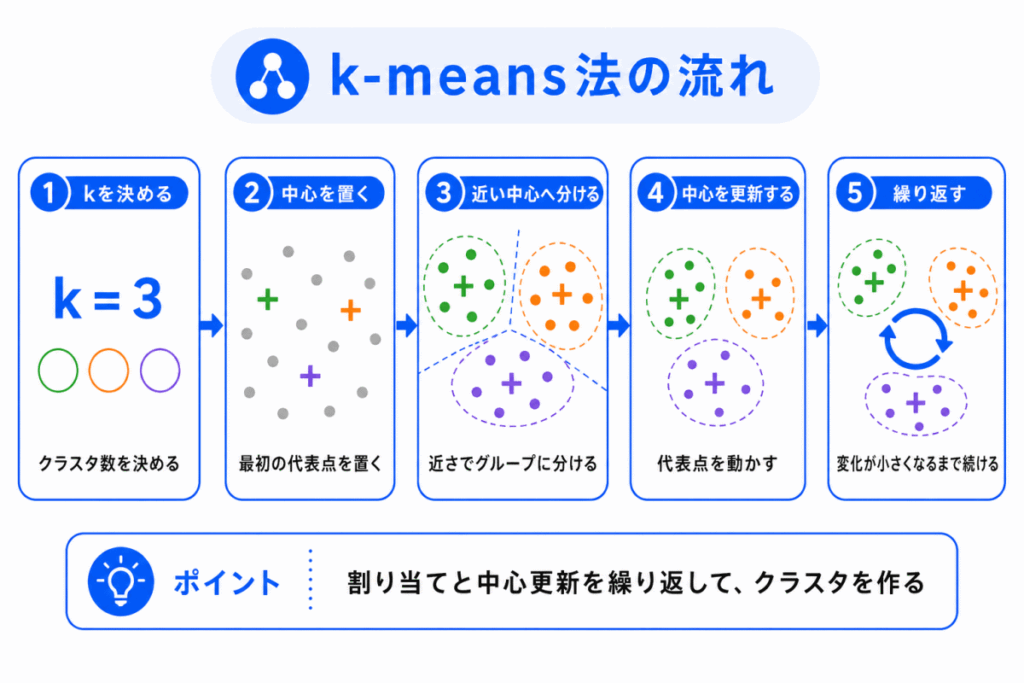
k-means法は、データを一度で完全に分けるのではありません。
クラスタ中心を置き、データを割り当て、中心を更新する作業を繰り返します。
流れは次の通りです。
ポイントは、データと中心の距離です。
各データは、もっとも近いクラスタ中心に割り当てられます。
その後、割り当てられたデータの平均をもとに、新しい中心が計算されます。
この作業を繰り返すことで、似ているデータ同士が同じクラスタに集まりやすくなります。
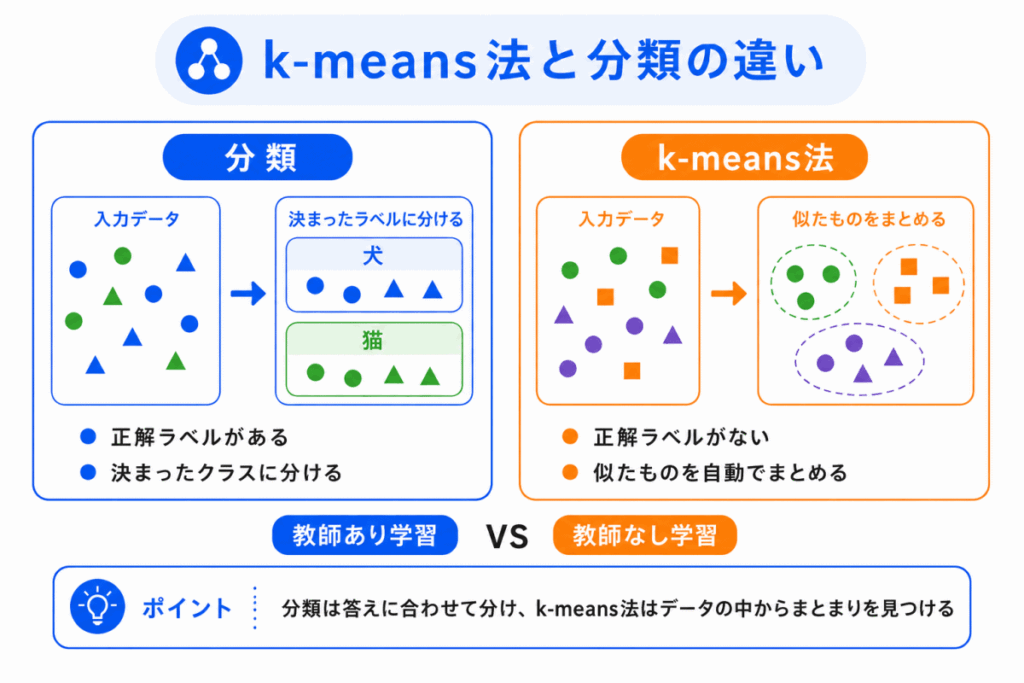
k-means法は、データをグループに分けるため、分類と似て見えることがあります。
しかし、分類とk-means法は、正解ラベルの有無が違います。
分類は、正解ラベルがある教師あり学習です。
一方、k-means法は、正解ラベルがない教師なし学習です。
違いを整理すると、次のようになります。
| 項目 | 分類 | k-means法 |
|---|---|---|
| 学習の種類 | 教師あり学習 | 教師なし学習 |
| 正解ラベル | ある | ない |
| 目的 | 既知のラベルに分ける | 似ているデータをまとめる |
| 分け方 | 学習したルールで分ける | クラスタ中心への近さで分ける |
G検定では、分類とクラスタリングを混同しないことが大切です。
この違いを押さえておくと、問題文を読みやすくなります。
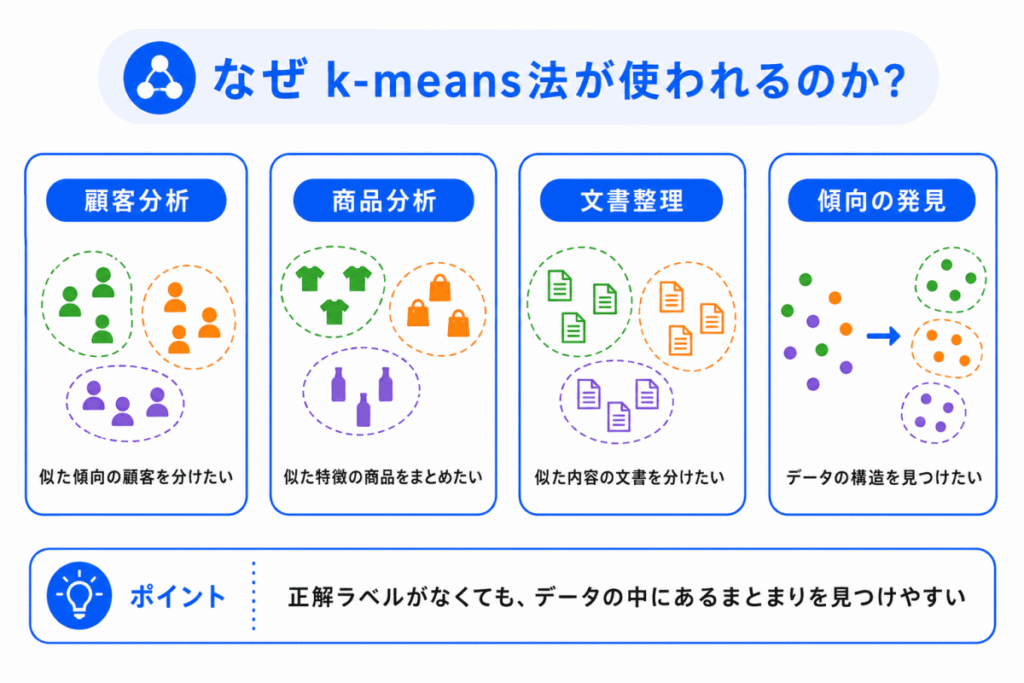
k-means法は、データの中にあるまとまりを見つけたいときに使われます。
たとえば、次のような場面です。
| 場面 | 見たいこと |
|---|---|
| 顧客分析 | 似た購買傾向の人をグループに分けたい |
| 商品分析 | 似た特徴を持つ商品をまとめたい |
| 文書整理 | 似た内容の文書をグループ化したい |
| データ分析 | データ全体の傾向をつかみたい |
正解ラベルがない場合でも、k-means法を使うと、データの中にある傾向を見つけやすくなります。
ただし、k-means法が作ったクラスタに意味があるかどうかは、人間が確認する必要があります。
AIがグループを作っても、そのグループが実際に意味のあるまとまりとは限らないからです。
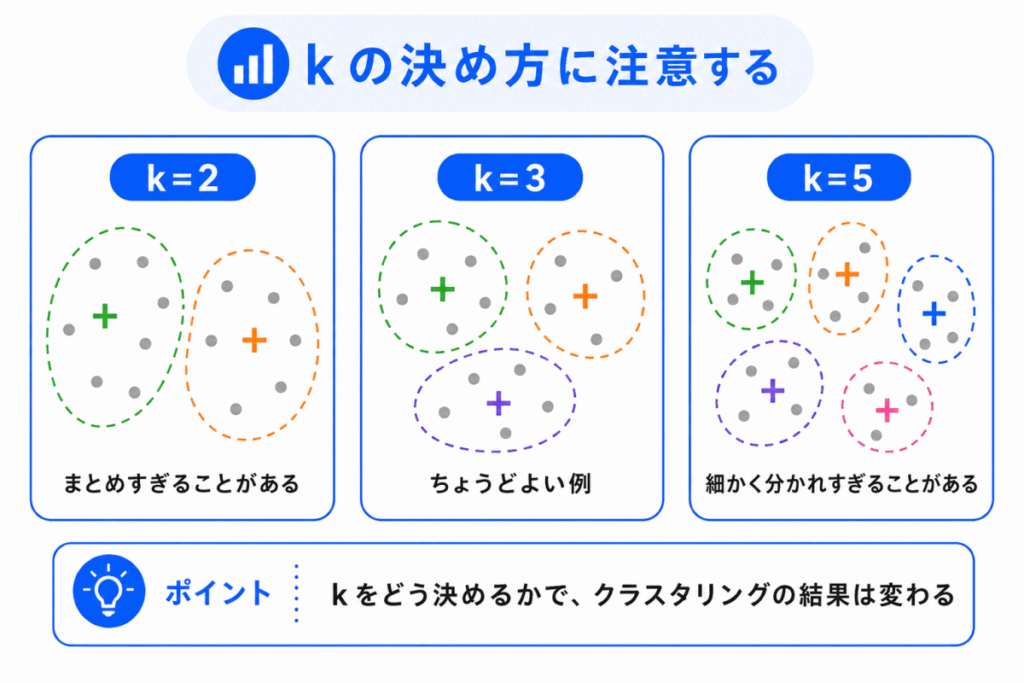
k-means法では、クラスタ数 k を先に決める必要があります。
ここが重要な注意点です。
k が小さすぎると、本当は違う種類のデータが同じクラスタに入ってしまうことがあります。
反対に、k が大きすぎると、本来は同じまとまりとして見たいデータが細かく分かれすぎることがあります。
たとえば、顧客を2つに分けるのか、3つに分けるのか、5つに分けるのかで、結果の見え方は変わります。
そのため、k-means法では、k の値をどう決めるかが大切です。
G検定では、細かい決め方の計算よりも、k は自分で決める必要がある という点を押さえておきましょう。
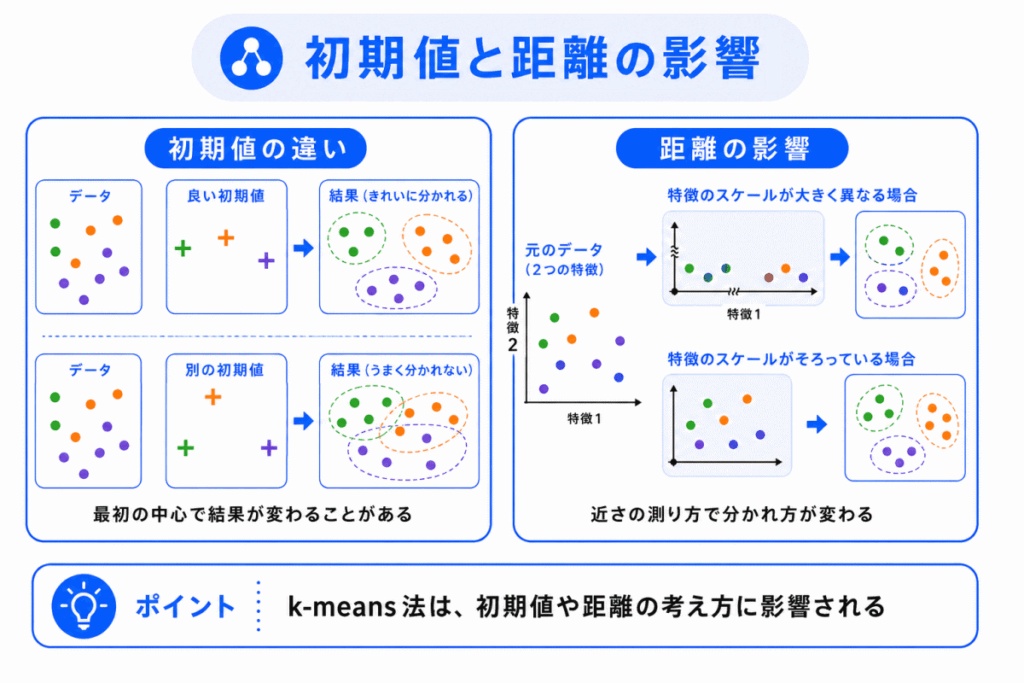
k-means法では、最初に置くクラスタ中心の位置によって、結果が変わることがあります。
この最初の中心を、初期値と考えるとわかりやすいです。
また、k-means法は距離を使うため、特徴量のスケールにも影響されます。
たとえば、年齢と年収を使って顧客を分ける場合を考えます。
年齢は数十程度の値です。
一方、年収は数百万のように大きな値になりやすいです。
このまま距離を計算すると、年収の影響が大きくなりすぎることがあります。
そのため、k-means法を使う前に、正規化や標準化でスケールをそろえることがあります。
| 注意点 | 内容 |
|---|---|
| k を決める必要がある | クラスタ数を事前に決める必要がある |
| 初期値に影響される | 最初の中心の置き方で結果が変わることがある |
| スケールに影響される | 値の大きい特徴量が距離計算に強く影響することがある |
| 外れ値に影響される | 極端な値がクラスタ中心をずらすことがある |
| 解釈が必要 | できたクラスタに意味があるかは人間が確認する必要がある |
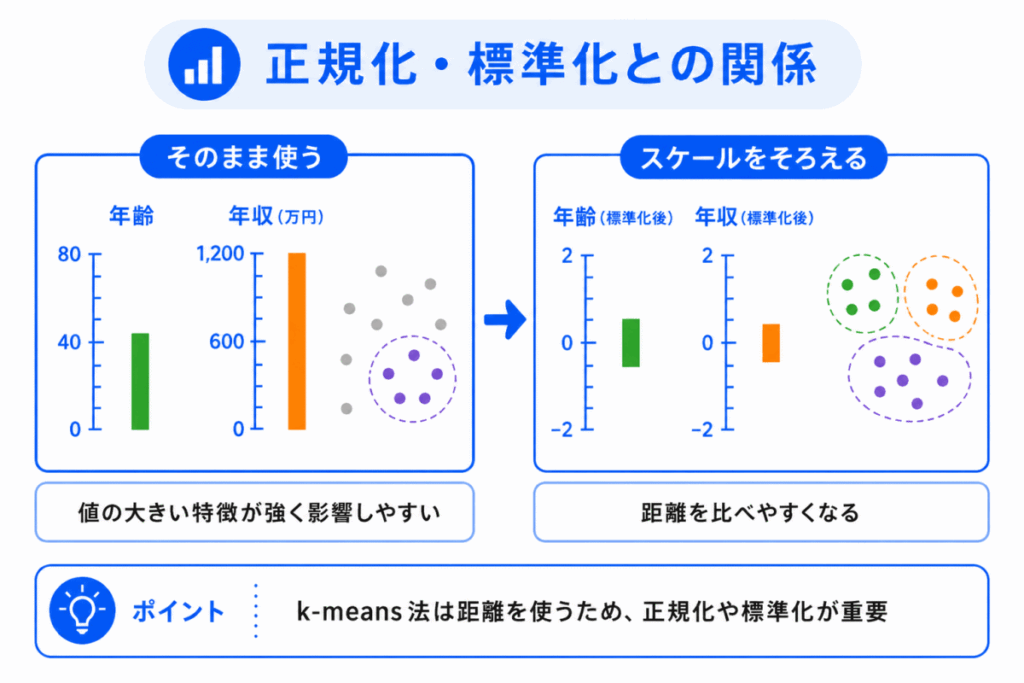
k-means法は、距離を使ってデータを分けます。
そのため、特徴量のスケールがそろっていないと、結果が偏ることがあります。
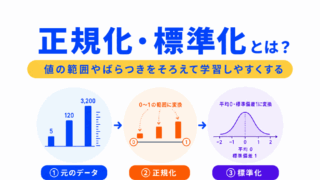
このとき重要になるのが、正規化や標準化です。
正規化は、値の範囲をそろえる考え方です。
標準化は、平均や標準偏差をもとに値のスケールをそろえる考え方です。
k-means法では、どの特徴量を使うかだけでなく、それぞれの特徴量のスケールも大切です。
つまり、k-means法は、データ前処理とセットで理解するとわかりやすくなります。
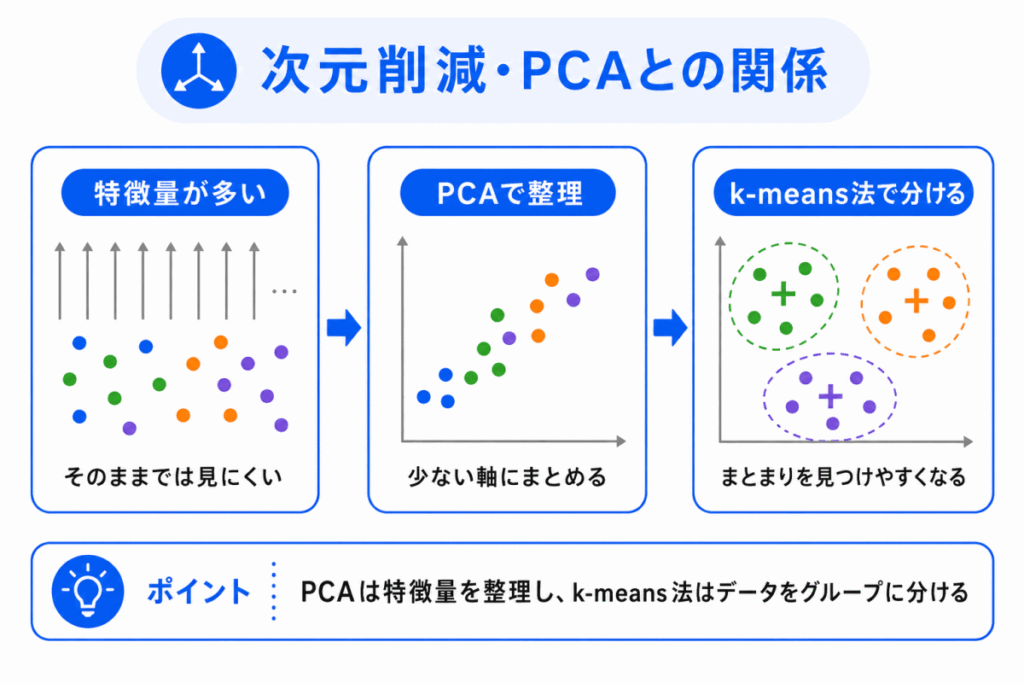
k-means法は、次元削減やPCAとも関係します。
特徴量が多すぎると、データ同士の距離の意味がわかりにくくなることがあります。
また、人間が結果を見ても、どのように分かれているのかを確認しにくくなります。
そこで、PCAなどを使って特徴量を少ない軸に整理してから、クラスタリングの結果を見ることがあります。
ただし、PCAとk-means法は目的が違います。
PCAは、特徴量を減らしたり、見やすくしたりするための方法です。
k-means法は、データをクラスタに分けるための方法です。
この違いも押さえておきましょう。
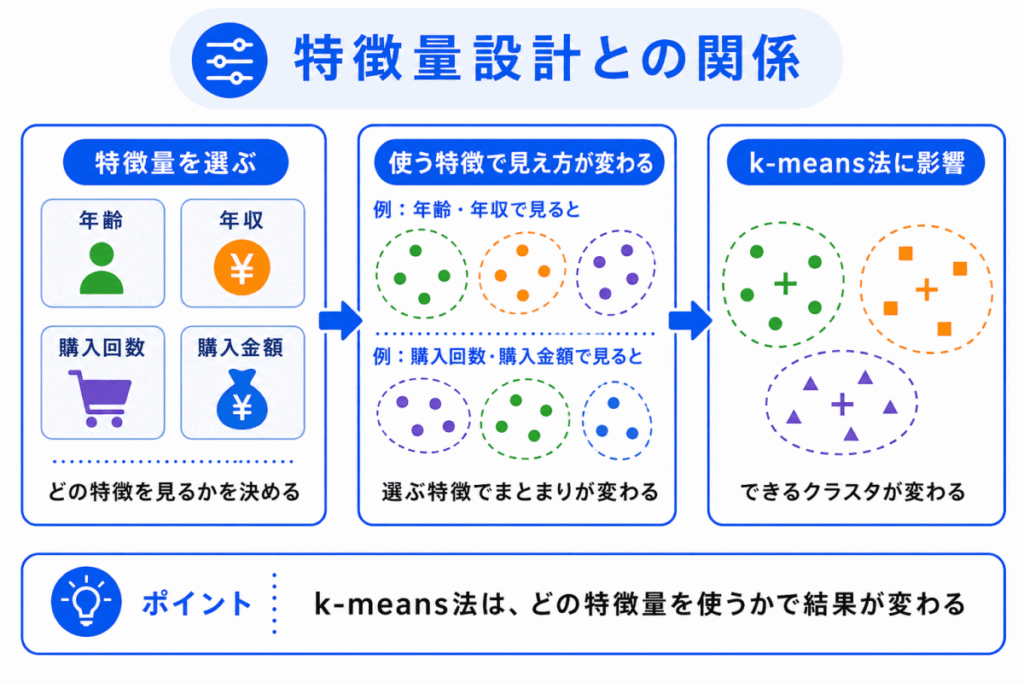
k-means法では、どの特徴量を使うかによって、できるクラスタが変わります。
たとえば、顧客を分ける場合でも、年齢や年収を使うのか、購入回数や購入金額を使うのかで、分かれ方は変わります。
つまり、k-means法は、データを入れれば必ず意味のあるクラスタができる方法ではありません。
このあたりを考える必要があります。
そのため、k-means法は特徴量設計とも深く関係します。
G検定では、k-means法の細かい計算よりも、意味と位置づけが重要です。
特に、次の点を押さえておくとよいです。
| 押さえたい点 | 内容 |
|---|---|
| 学習の種類 | k-means法は教師なし学習の代表的な手法 |
| 何をするか | 似たデータを k 個のクラスタに分ける |
| 分け方 | クラスタ中心への近さをもとに分ける |
| 注意点 | k、初期値、スケール、外れ値で結果が変わることがある |
| 関連テーマ | クラスタリング、正規化・標準化、PCA、特徴量設計 |
特に、k-means法はクラスタリングの代表手法であり、教師なし学習に含まれる点を押さえましょう。
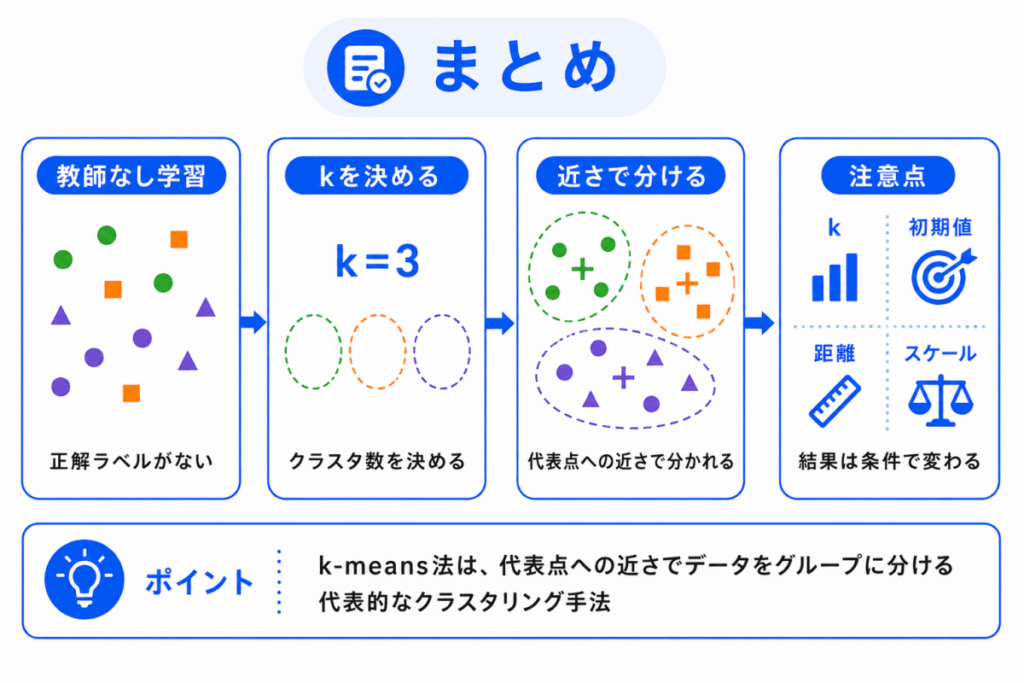
k-means法は、似ているデータを k 個のクラスタに分ける代表的なクラスタリング手法です。
教師なし学習の一種であり、正解ラベルがないデータから、似ているもの同士のまとまりを見つけるときに使われます。
ただし、k-means法では、クラスタ数 k を自分で決める必要があります。
また、初期値、距離、特徴量のスケール、外れ値によって結果が変わることがあります。
そのため、k-means法は、クラスタリングだけでなく、正規化・標準化、PCA、特徴量設計、データ前処理ともつなげて理解することが大切です。
クラスタリングの全体像を確認するなら、こちらの記事がおすすめです。
教師なし学習の代表手法を整理するなら、こちらの記事がおすすめです。
教師あり学習との違いを確認するなら、こちらの記事がおすすめです。
k-means法と一緒に出やすい次元削減を確認するなら、こちらの記事がおすすめです。
クラスタリングの結果に影響する特徴量を確認するなら、こちらの記事がおすすめです。

スケール調整との関係を確認するなら、こちらの記事がおすすめです。
機械学習全体の中で位置づけを確認するなら、こちらの記事がおすすめです。
【G検定対策】機械学習の概要まとめ|教師あり・教師なし・強化学習をつなげて理解する
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認