【G検定対策】モデル軽量化とは?|AIを小さく速く動かすための工夫をわかりやすく整理
seo-webmaster
G検定対策ブログ
Transformerを学んでいると
という似た言葉が次々に出てきて、混乱した経験がある人も多いのではないでしょうか。
実際、これらはまったく別の技術というより「Attention」が進化してTransformerの中で使われる形になったもの です。
しかし、名前が似ているため、「何が違うのか?」が分かりにくくなっています。
特にAIの学習をはじめたばかりの人は、「Transformer=Attentionがすごいらしい」という理解で止まりがちですが、Transformerの本質を理解するには
という流れ、を整理しておくことが重要です。
この記事では、それぞれの役割と違いを、流れでわかりやすく整理していきます。
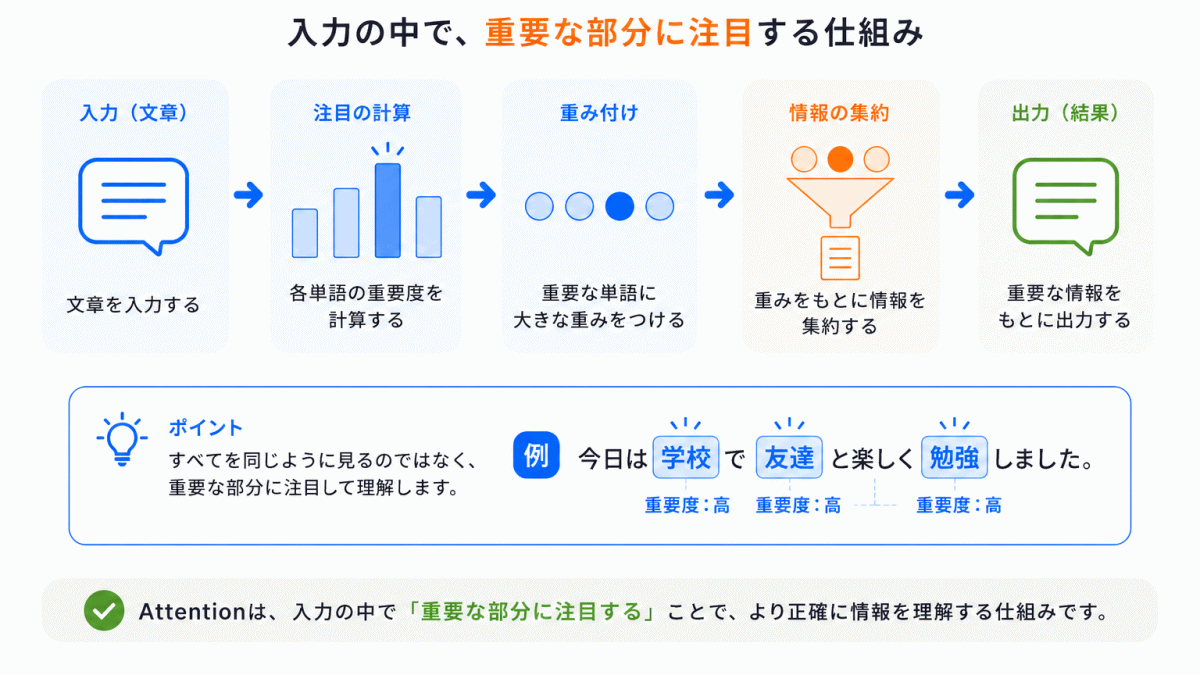
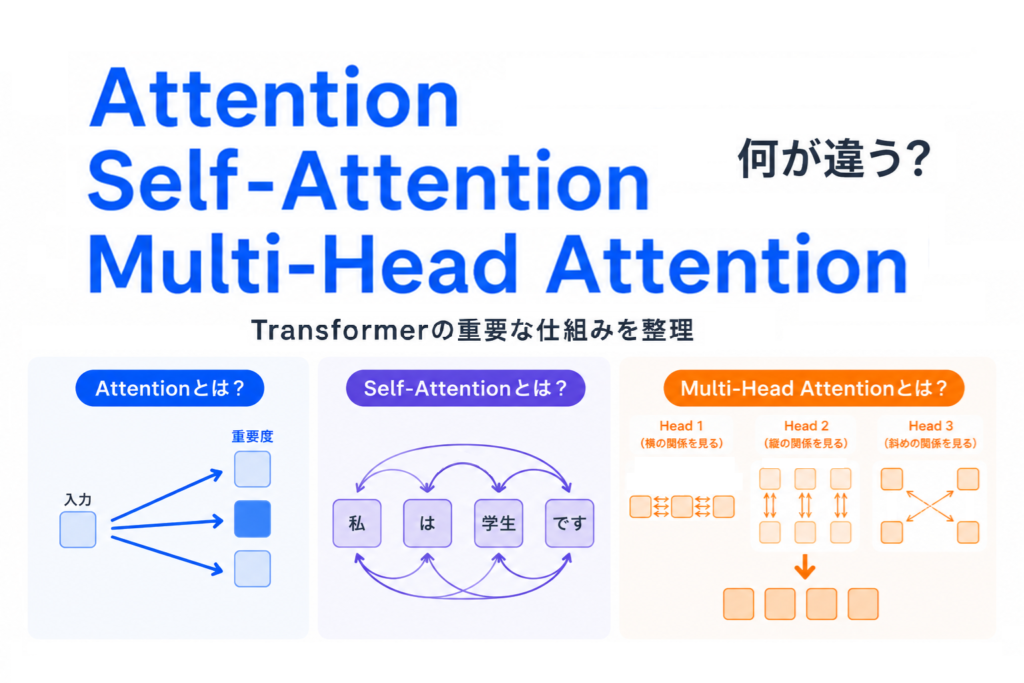
Attentionとは、簡単に言うと「重要な部分に注目する仕組み」です。
従来のAIでは、入力全体を同じように扱うことが多かったのですが、実際の文章では「特に重要な単語」があります。
例えば
「私は昨日、友人と映画を見に行った」
という文章なら
などが重要な情報になるかもしれません。
Attentionは 入力の中で重要な部分に重みをつけて注目する という考え方です。
これによってAIは「全部を同じように見る」のではなく「ここが重要そうだ」と重点的に見る ことができるようになりました。
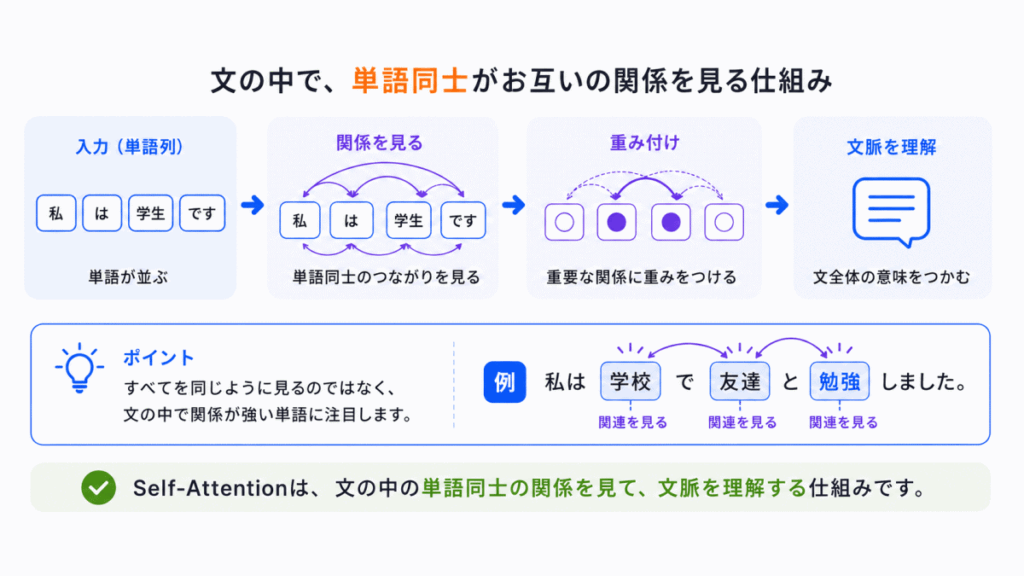
Attentionの考え方をさらに進化させたのが Self-Attention です。
普通のAttentionは「ある入力が、別の情報を見て重要度を決める」という仕組みでした。
一方、Self-Attentionは「文章の中の単語同士がお互いを見て関係を判断する」仕組みです。
例えば
「私は学校に行った。そこで勉強した。」
この文章で「そこで」は何を指しているのか?Self-Attentionは、文章全体を見て
という関係を判断します。
つまり
というように、文の中の単語同士が相互に関連を見る のがSelf-Attentionです。
これがTransformerの中心技術です。
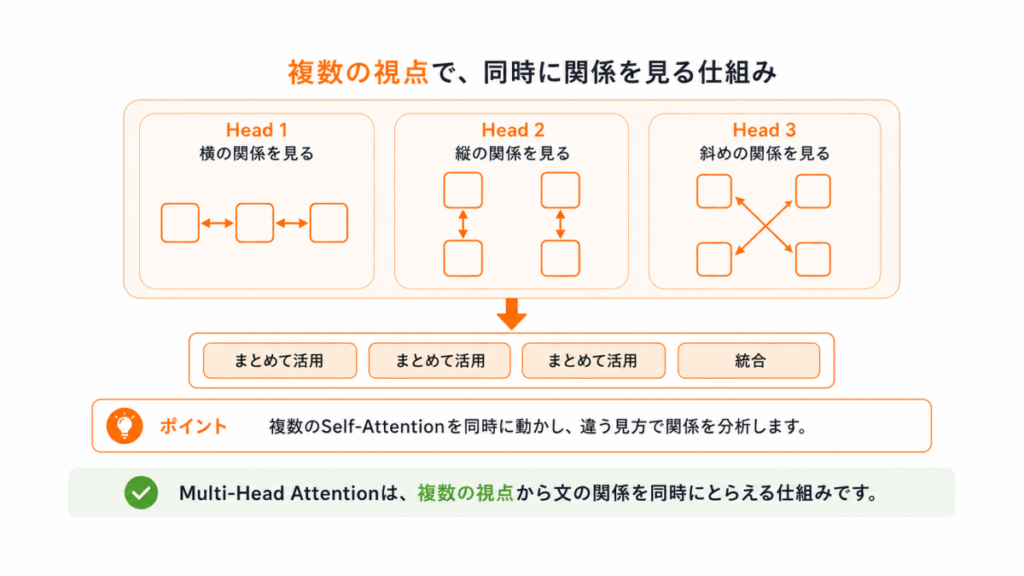
Self-Attentionだけでも便利ですが、問題があります。
それは
1つの見方しかできない
ということです。
例えば文章には
など、複数の見方があります。
そこで登場したのが
Multi-Head Attention
です。
これは
複数のSelf-Attentionを同時に動かして、違う視点で見る
仕組みです。
イメージとしては
のように
複数の視点で同時に関連を分析する
ことができます。
これによって、1つの見方だけでは見えない複雑な関係も理解しやすくなりました。
シンプルに言うと
という関係です。
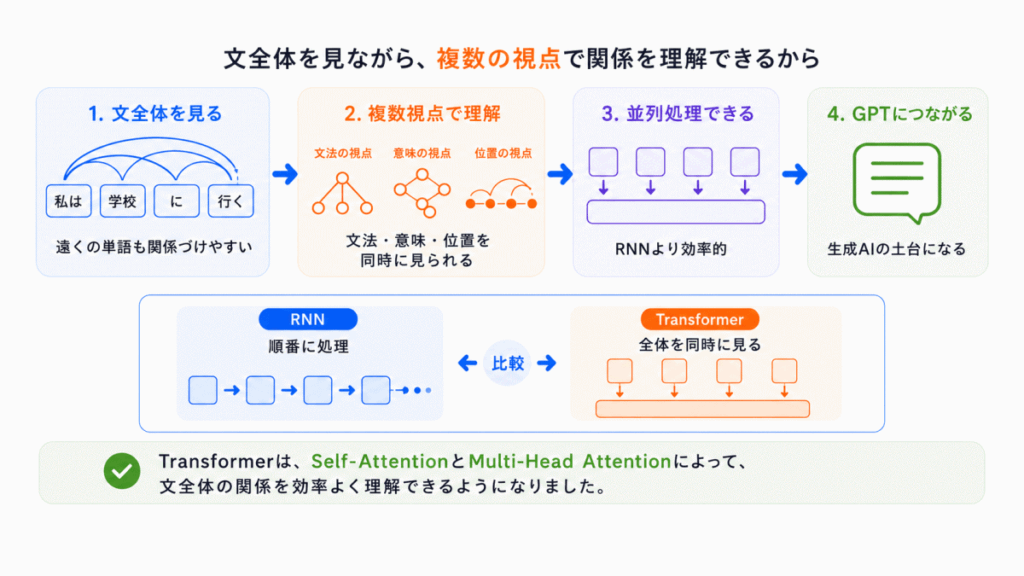
RNNは 1文字ずつ順番に処理していました。
そのため
という問題がありました。
Transformerは、Self-Attentionを使うことで
文章全体を一気に見て、単語同士の関係を判断する
ことができるようになりました。
さらに、Multi-Head Attentionによって
複数の視点で同時に理解する
ことができるようになりました。
これが、Transformerが革命的だった理由の1つです。
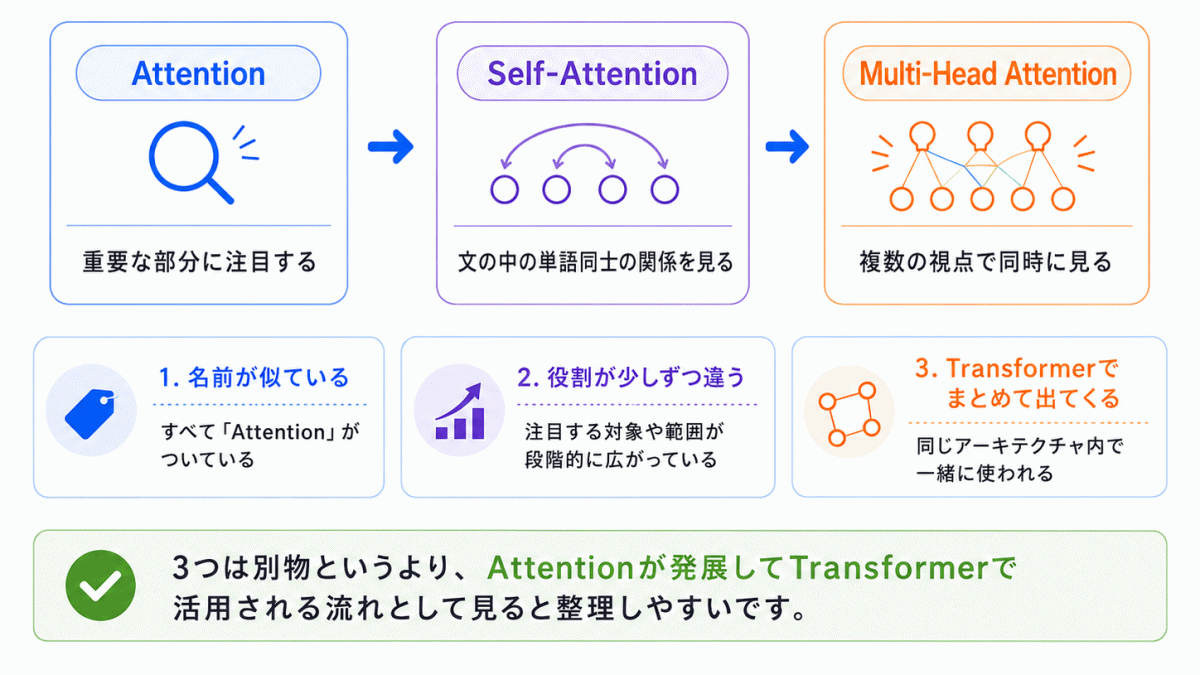
この3つが混同しやすい理由は、
「名前が似ていて、進化した関係にある」
からです。
つまり、別々の技術というより
発展していく流れ
なのです。
そのため、名前だけ見ると違いが分かりにくくなります。
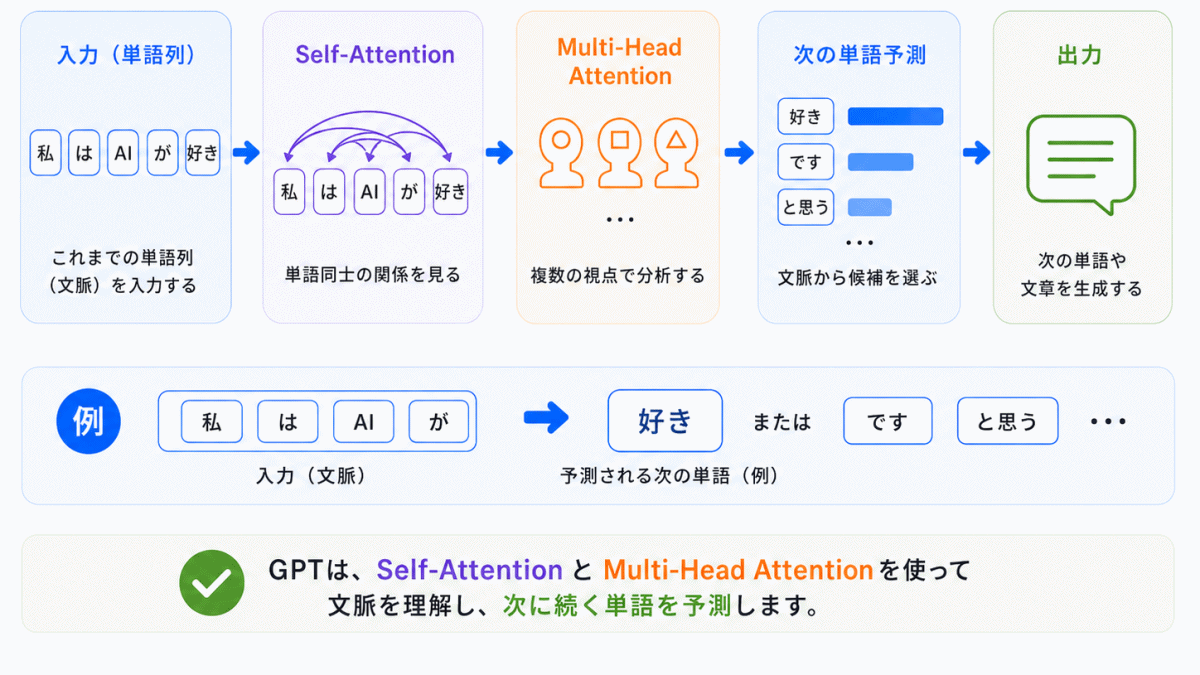
GPTはTransformerをベースにしています。
GPT内部では
という流れが起きています。
つまり、GPTが「文脈を読む」ために重要なのが、
Self-AttentionとMulti-Head Attention
なのです。
これがなければ、GPTは文章全体の関係を理解しにくくなります。
G検定では「Transformerの特徴」として問われることが多いです。
例えば
といった形で出題される可能性があります。
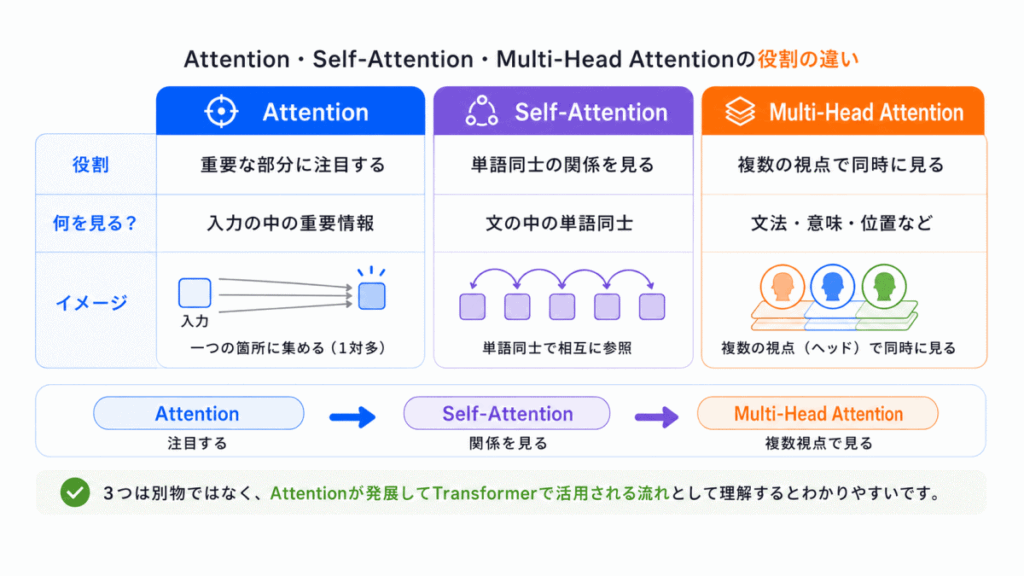
特に注意したいのは、Attention = Transformerそのもの ではない ことです。
Attentionは考え方であり、Transformerでは Self-AttentionやMulti-Head Attentionとして実装されている という理解が重要です。
Attention・Self-Attention・Multi-Head Attentionは、名前が似ているため混同しやすいですが、役割は少しずつ違います。
Attentionは 重要な部分に注目する考え方 です。
Self-Attentionは 文章の中の単語同士がお互いを見て関係を判断する仕組み です。
Multi-Head Attentionは それを複数の視点で同時に行う仕組み です。
この流れを理解すると
というつながりが見えてきます。
AIは単語を暗記して理解するのではなく
「どことどこが関係しているか」を見て理解している
その中心にあるのが、この技術たちです。
TransformerやGPTを本当に理解するためにも、この3つの違いは整理しておくことが重要です。
Attention・Self-Attention・Multi-Head Attentionの違いを理解するには、GPT、Attention、位置エンコーディングとの関係をあわせて整理しておくと理解しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| GPTとは? | Transformerとの関係/次トークン予測/文章生成の仕組み |
| Attentionとは? | 重要な部分への注目/Self-Attentionとの関係/Transformerでの役割 |
| 位置エンコーディングとは? | 語順の情報/Transformerの弱点補完/Attentionとの関係 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。