【G検定対策】データ前処理とは?|AIが学習しやすいデータに整える作業をわかりやすく整理
seo-webmaster
G検定対策ブログ
そこで使われる考え方が、次元削減です。
次元削減は、データが持つ情報をできるだけ残しながら、特徴量の数を減らす考え方です。
その代表的な手法がPCA、つまり主成分分析です。
この記事では、G検定対策として、次元削減とPCAの意味、使われる理由、正規化・標準化や特徴量設計との関係を、数式に偏りすぎずに整理します。

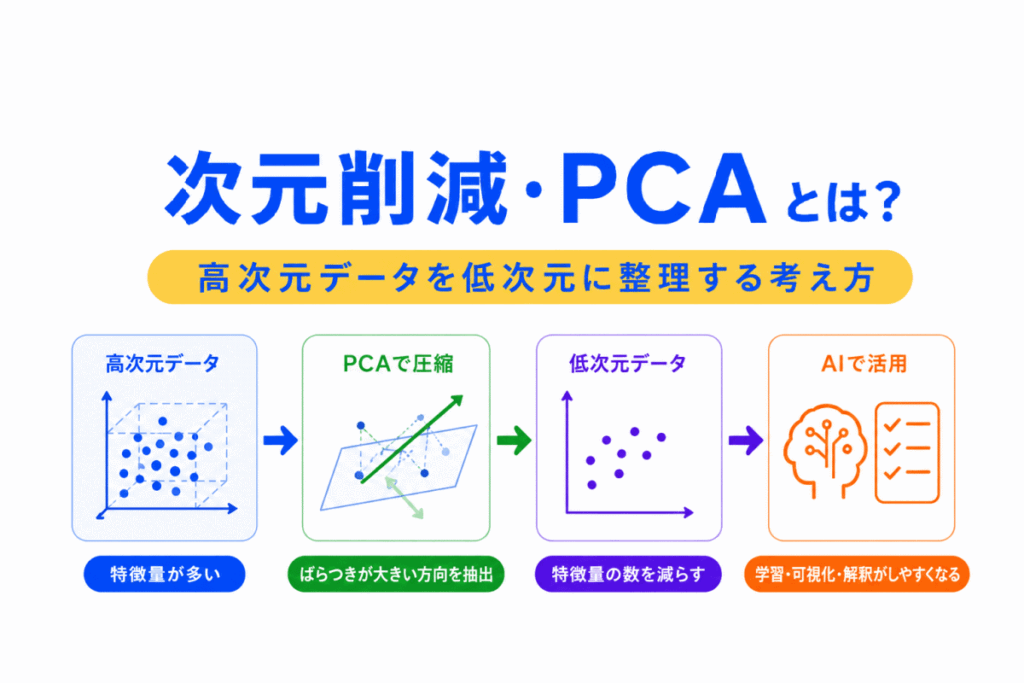
次元削減とは、特徴量の数を減らしながら、重要な情報をできるだけ残す考え方です。
たとえば、あるデータに年齢、身長、体重、購入回数、閲覧回数、滞在時間など、たくさんの特徴量があるとします。
特徴量が多いほど情報は増えますが、その分、AIが扱うデータは複雑になります。
次元削減では、このような多くの特徴量を、より少ない特徴量にまとめます。
PCAは、次元削減の代表的な手法です。
PCAは、データのばらつきが大きい方向を見つけ、その方向に沿ってデータを表し直します。
| 用語 | 意味 |
|---|---|
| 次元削減 | 特徴量の数を減らしながら、重要な情報を残す考え方 |
| PCA | データのばらつきが大きい方向を使って、低次元に表し直す手法 |
| 主成分 | データの特徴をよく表す新しい軸 |
ポイントは、単に特徴量を捨てるのではなく、できるだけ情報を残しながら整理することです。

特徴量が多いことは、一見よいことのように見えます。
しかし、特徴量が多すぎると、AIにとって扱いにくいデータになることがあります。
たとえば、不要な特徴量や似たような特徴量が多いと、学習が複雑になります。
また、データの数に対して特徴量が多すぎると、学習データには合っているのに、新しいデータではうまく予測できないことがあります。
これが、過学習につながる場合があります。
次元削減が必要になる流れは、次のように整理できます。
次元削減は、AIが学習しやすい状態にデータを整理するための考え方です。

機械学習でいう次元とは、特徴量の数を指すことが多いです。
たとえば、年齢だけで人を表すなら1次元です。
年齢と身長で表すなら2次元です。
年齢、身長、体重、年収、購入回数などで表すなら、さらに高い次元になります。
| データの表し方 | 次元のイメージ |
|---|---|
| 年齢だけで表す | 1次元 |
| 年齢と身長で表す | 2次元 |
| 年齢・身長・体重で表す | 3次元 |
| 数十個、数百個の特徴量で表す | 高次元データ |
AIでは、画像、文章、音声などを大量の数値で表します。
そのため、実際のデータはかなり高次元になることがあります。
高次元データをそのまま扱うと、計算が重くなったり、データ同士の関係が見えにくくなったりします。

PCAは、Principal Component Analysisの略で、日本語では主成分分析と呼ばれます。
PCAは、元の特徴量をそのまま使うのではなく、データの特徴をよく表す新しい軸を作ります。
この新しい軸を主成分といいます。
PCAでは、データのばらつきが大きい方向を重視します。
ばらつきが大きい方向には、データの違いを説明する情報が多く含まれていると考えるためです。
たとえば、2つの特徴量で表されているデータを、1つの主成分にまとめることがあります。
このとき、データの広がりをできるだけ保つ方向に圧縮します。
PCAを一言でいうと、次のようになります。
| 観点 | PCAの考え方 |
|---|---|
| 目的 | 高次元データを低次元に圧縮する |
| 重視するもの | データのばらつきが大きい方向 |
| 作るもの | 主成分という新しい軸 |
| 使いどころ | 可視化、ノイズ低減、計算量削減、前処理 |
G検定では、PCAの細かい計算よりも、データを低次元に圧縮する代表的な手法として理解することが重要です。

次元削減と似た言葉に、特徴選択があります。
どちらも特徴量を減らす考え方ですが、やっていることは少し違います。
特徴選択は、元の特徴量の中から重要なものを選びます。
一方、PCAのような次元削減では、元の特徴量を組み合わせて、新しい特徴量に変換します。
| 項目 | 特徴選択 | 次元削減 |
|---|---|---|
| 考え方 | 重要な特徴量を選ぶ | 特徴量を新しい軸に変換する |
| 元の特徴量 | 残る | そのままでは残らないことが多い |
| 代表例 | 不要な列を削除する | PCAで主成分に変換する |
| 解釈のしやすさ | 比較的わかりやすい | やや解釈しにくくなることがある |
特徴選択は、元の列を選ぶイメージです。
次元削減は、元の列をまとめて、新しい表し方に変えるイメージです。

PCAは、さまざまな目的で使われます。
代表的なのは、可視化です。
高次元データは、そのままでは人間が見ても理解しにくいです。
PCAで2次元や3次元に圧縮すると、データの分布を図で確認しやすくなります。
また、特徴量の数を減らすことで、計算量を減らせる場合があります。
不要なばらつきやノイズの影響を小さくする目的で使われることもあります。
ただし、PCAを使えば必ず性能が上がるわけではありません。
重要な情報まで失われると、かえって予測性能が下がることもあります。
PCAは、データを扱いやすくするための手段であり、万能な方法ではありません。

PCAでは、特徴量のスケールが結果に影響することがあります。
たとえば、年齢は20〜80くらい、年収は200万〜1000万くらいの範囲を取るとします。
このままPCAを行うと、値の大きい特徴量の影響が強く出ることがあります。
そのため、PCAの前に標準化を行うことがよくあります。
標準化は、平均0、標準偏差1に近づける前処理です。
特徴量ごとのスケールをそろえることで、PCAが特定の特徴量に引っ張られすぎるのを防ぎやすくなります。
ここで重要なのは、正規化・標準化とPCAは役割が違うという点です。
正規化・標準化は、値のスケールを整える前処理です。
PCAは、特徴量の数を減らす次元削減の手法です。

次元削減は、データ前処理や特徴量設計と深く関係します。
データ前処理は、欠損値、外れ値、ノイズ、スケールなどを整える作業です。
特徴量設計は、AIが学習しやすい特徴を作る作業です。
次元削減は、多すぎる特徴量を整理して、扱いやすくする作業です。
| 用語 | 主な役割 | 例 |
|---|---|---|
| データ前処理 | データを学習しやすく整える | 欠損値処理、標準化、ノイズ除去 |
| 特徴量設計 | 学習に役立つ特徴量を作る | 比率、回数、曜日、カテゴリ変換 |
| 次元削減 | 特徴量を減らして扱いやすくする | PCA、主成分への変換 |
この3つは別々の言葉ですが、AIが学習しやすいデータを作るという意味ではつながっています。

次元削減と関係するディープラーニングの手法に、オートエンコーダがあります。
オートエンコーダは、入力データをいったん小さな表現に圧縮し、そこから元のデータを復元するように学習するニューラルネットワークです。
PCAもオートエンコーダも、データを低次元に表すという点では似ています。
ただし、PCAは主に線形な変換を使う代表的な次元削減手法です。
オートエンコーダは、ニューラルネットワークを使って、より複雑な表現を学習できる場合があります。
G検定では、PCAは古典的な次元削減、オートエンコーダはディープラーニングを使った表現学習とつなげて理解すると整理しやすくなります。

次元削減は便利ですが、注意点もあります。
まず、情報を減らす処理なので、必要な情報まで失われる可能性があります。
次元を減らしすぎると、データの特徴を十分に表せなくなることがあります。
また、PCAで作られる主成分は、元の特徴量そのものではありません。
そのため、元の特徴量と比べると、意味を解釈しにくくなる場合があります。
さらに、PCAの前に標準化が必要になることがあります。
特徴量のスケールが大きく違う場合、そのままPCAを行うと、値の大きい特徴量の影響が強くなりやすいためです。
データリーケージにも注意が必要です。
標準化やPCAを行うときは、学習データで求めた平均、標準偏差、主成分を使って、検証データやテストデータを変換する必要があります。
テストデータ全体を使って変換方法を決めてしまうと、本番では使えない情報が混ざる可能性があります。
G検定では、PCAの細かい計算よりも、次元削減の意味や目的が問われやすいです。
特に、次の点を押さえておくと整理しやすくなります。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 次元削減の意味 | 特徴量の数を減らしながら、重要な情報を残す |
| PCAの意味 | データのばらつきが大きい方向を使って低次元に表す |
| 目的 | 可視化、計算量削減、ノイズ低減、過学習の抑制 |
| 注意点 | 情報が失われることがある |
| 標準化との関係 | PCAの前処理として標準化が使われることがある |
PCAは、数式だけで覚えるよりも、高次元データを低次元に圧縮する代表的な方法として理解することが大切です。

次元削減は、特徴量の数を減らしながら、重要な情報をできるだけ残す考え方です。
PCAは、その代表的な手法です。
データのばらつきが大きい方向を見つけ、その方向に沿ってデータを表し直します。
特徴量が多すぎると、計算量が増えたり、ノイズの影響を受けたり、過学習につながったりすることがあります。
次元削減は、そのような高次元データを扱いやすくするために使われます。
| 用語 | 押さえるポイント |
|---|---|
| 次元削減 | 特徴量の数を減らし、データを扱いやすくする考え方 |
| PCA | ばらつきが大きい方向を使って、低次元に表す手法 |
| 主成分 | データの特徴をよく表す新しい軸 |
| 標準化との関係 | PCAの前処理として使われることがある |
| 注意点 | 情報が失われたり、解釈しにくくなったりすることがある |
G検定では、PCAの計算手順よりも、次元削減の目的、PCAの役割、標準化との関係を押さえることが重要です。
次元削減・PCAは、特徴量を減らしてデータを扱いやすくする考え方です。
ベクトル・行列、分散、正規化・標準化、前処理、特徴量設計とあわせて確認すると、AIでなぜ次元を減らすのか理解しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| ベクトル・行列とは? | AIがデータを数値で扱う考え方/数値のまとまり/次元削減の前提 |
| 期待値・分散・標準偏差とは? | 平均的な値とばらつき/分散の意味/PCAで重要になる考え方 |
| 正規化・標準化とは? | 値のスケールをそろえる考え方/前処理との関係/PCA前に確認したい基礎 |
| データ前処理とは? | AIが学習しやすいデータに整える作業/次元削減の位置づけ/学習前の準備 |
| 特徴量設計とは? | AIが学習しやすい特徴を作る考え方/特徴を作る作業/特徴を減らす作業との違い |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。