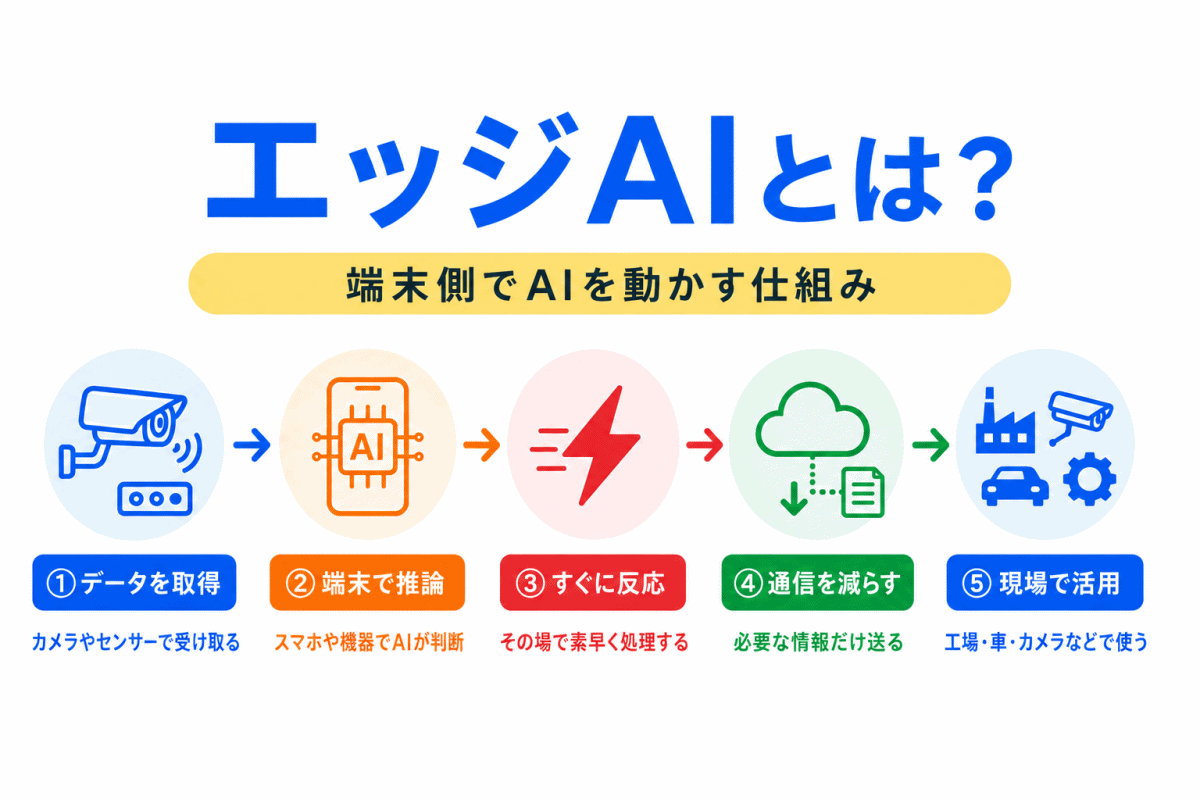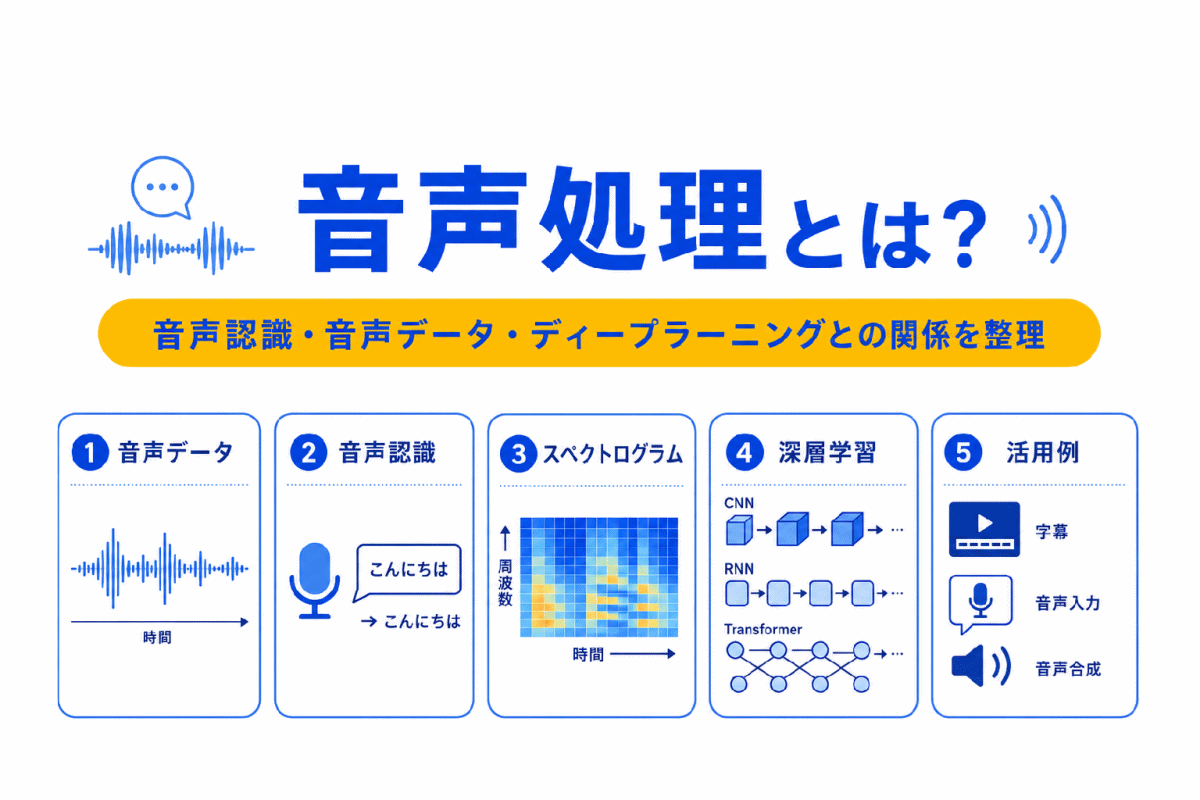
【G検定対策】音声処理とは?|音声認識・音声データ・ディープラーニングとの関係を整理
seo-webmaster
G検定対策ブログ
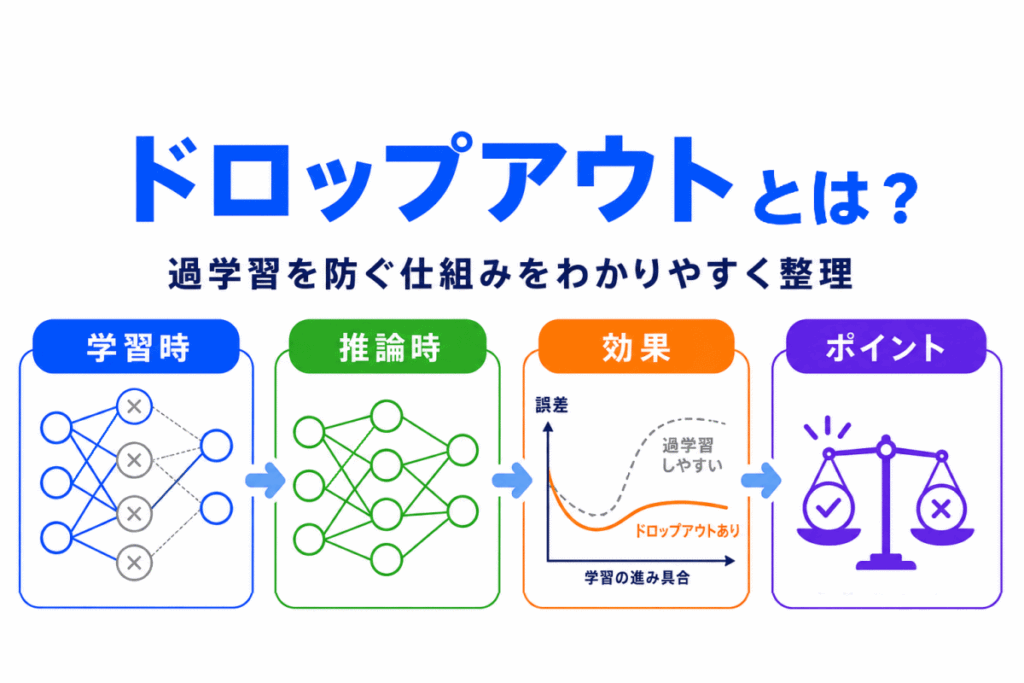
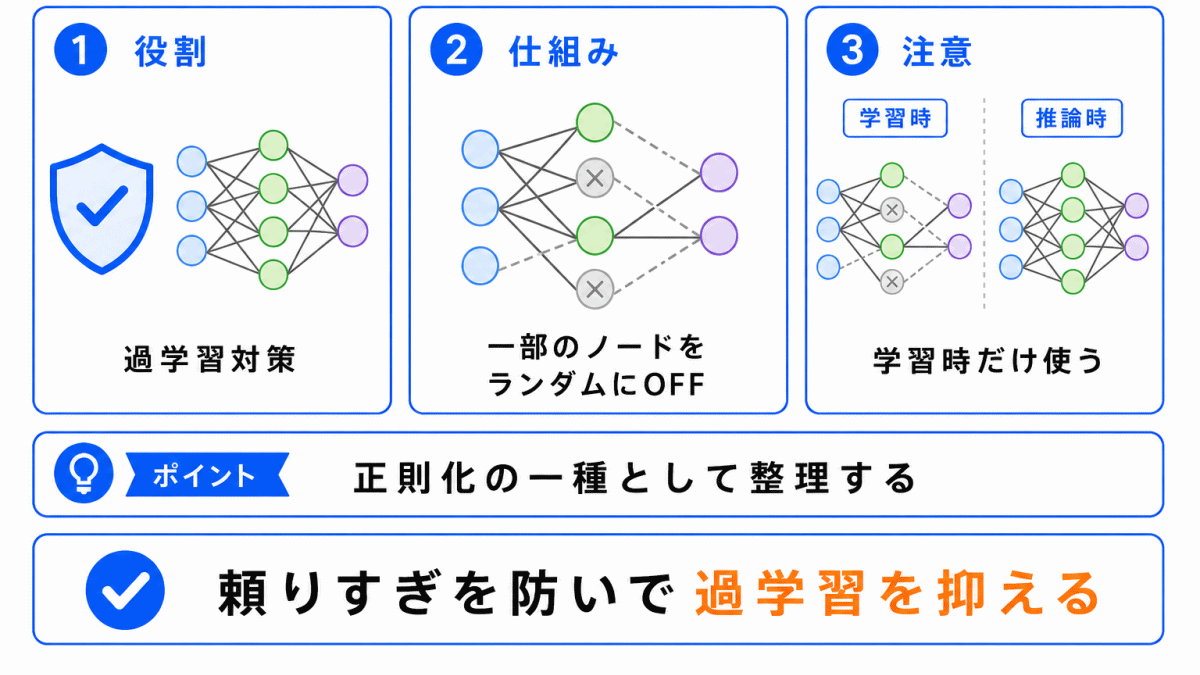
ドロップアウトとは、ニューラルネットワークの学習中に、一部のノードをランダムに無効化することで過学習を抑える手法です。
特定のノードに頼りすぎると、学習データには強くても未知のデータに弱いモデルになりやすくなります。
ドロップアウトは、毎回少し違う構成で学習させることで、依存を分散し、汎化しやすいモデルを目指します。
G検定では、正則化との関係や、学習時と推論時の違いを整理しておくことが大切です。
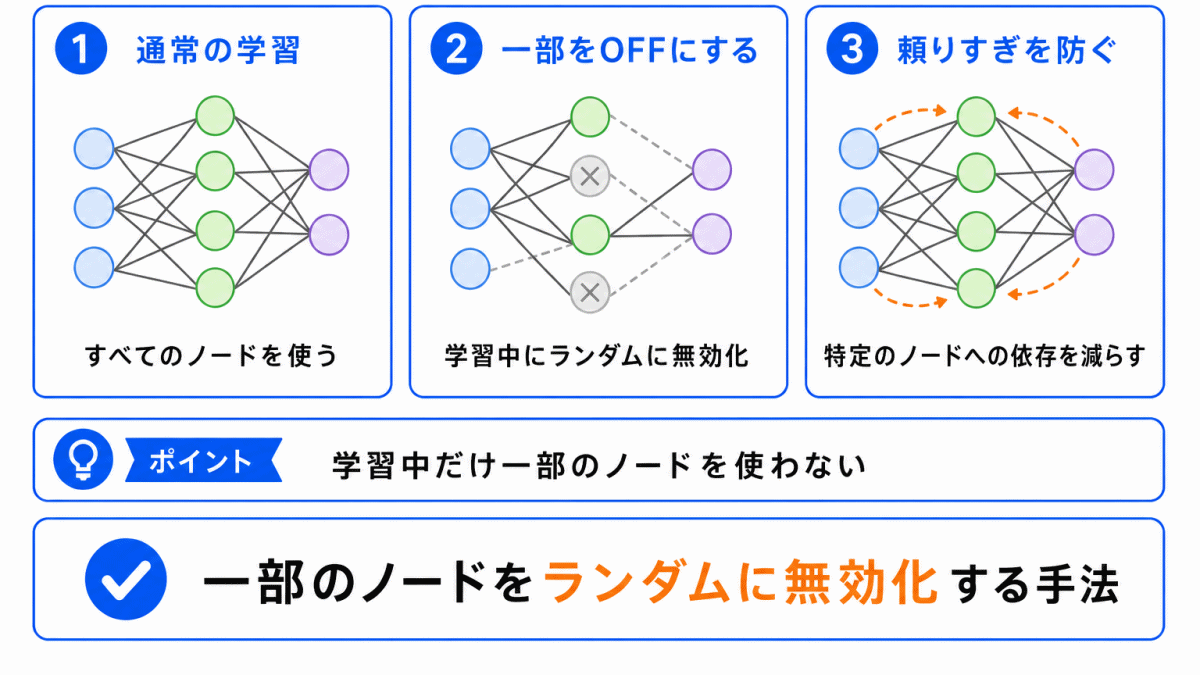
ドロップアウトとは、ニューラルネットワークの学習中に、一部のノードをランダムに無効化する方法です。
ここでいうノードとは、ニューラルネットワークの中で情報を受け取り、次の層へ渡す計算単位のことです。
通常の学習では、すべてのノードを使って予測します。
一方、ドロップアウトでは、学習のたびに一部のノードを一時的に使わないようにします。
| 方法 | 学習時のイメージ |
|---|---|
| ドロップアウトなし | すべてのノードを使う |
| ドロップアウトあり | 一部のノードをランダムに無効化する |
これにより、特定のノードだけに頼る学習を防ぎやすくなります。
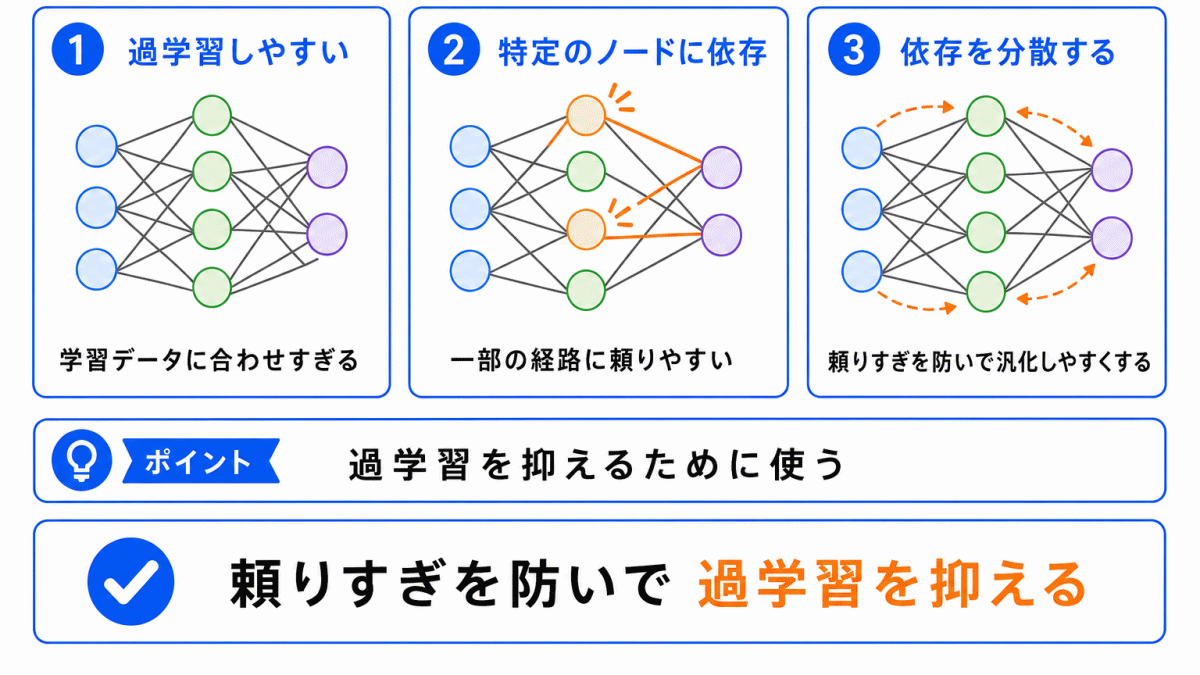
ドロップアウトが使われる理由は、過学習を防ぐためです。
過学習とは、学習データに合わせすぎて、未知のデータにうまく対応できなくなる状態です。
ニューラルネットワークでは、特定のノードや経路に強く依存して学習してしまうことがあります。
この状態になると、学習データにはよく当たっても、新しいデータでは性能が落ちやすくなります。
ドロップアウトを使うと、毎回一部のノードが使えなくなるため、モデルは特定のノードだけに頼りにくくなります。
| 問題 | ドロップアウトの役割 |
|---|---|
| 特定のノードに依存する | 依存を分散させる |
| 学習データに合わせすぎる | 過学習を抑えやすくする |
| 未知のデータに弱くなる | 汎化しやすい学習を目指す |
つまり、ドロップアウトは モデルを少し不便な状態で学習させることで、頼りすぎを防ぐ工夫 といえます。
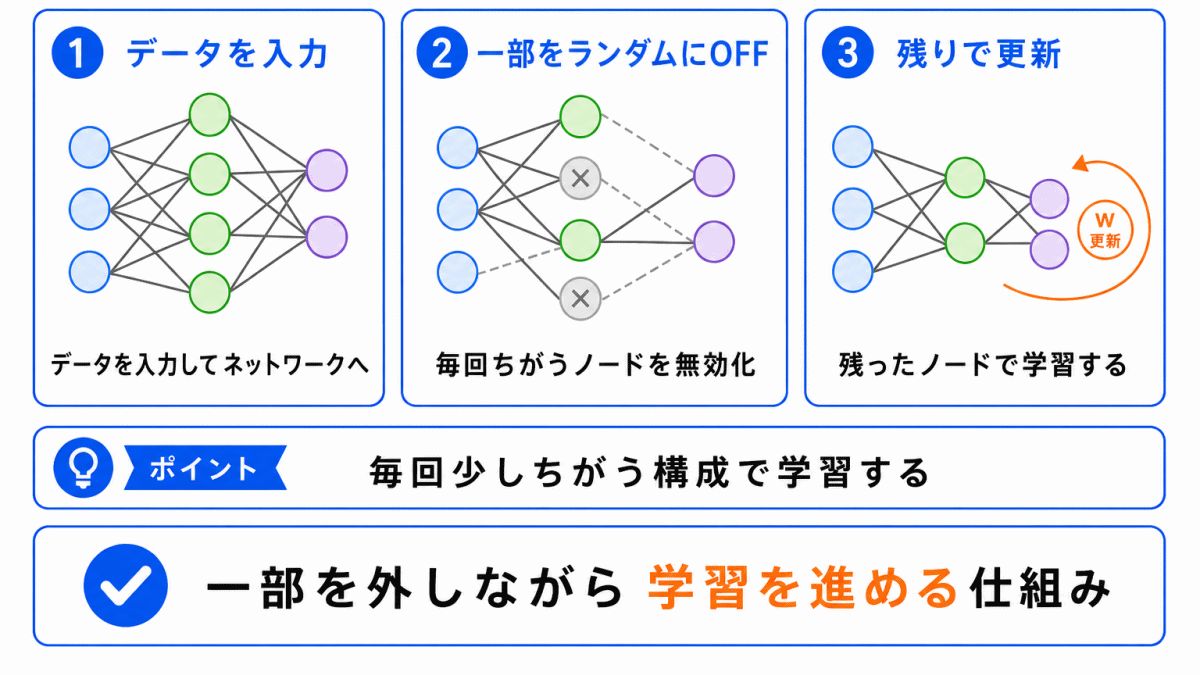
ドロップアウトでは、学習中に一部のノードをランダムに無効化します。
たとえば、ある層に10個のノードがある場合、そのうち数個を一時的に使わずに学習します。
次の学習では、別のノードが無効化されることもあります。
このように、毎回少し違うネットワークで学習しているような状態になります。
その結果、特定のノードだけに頼らず、複数のノードで特徴を分担しやすくなります。
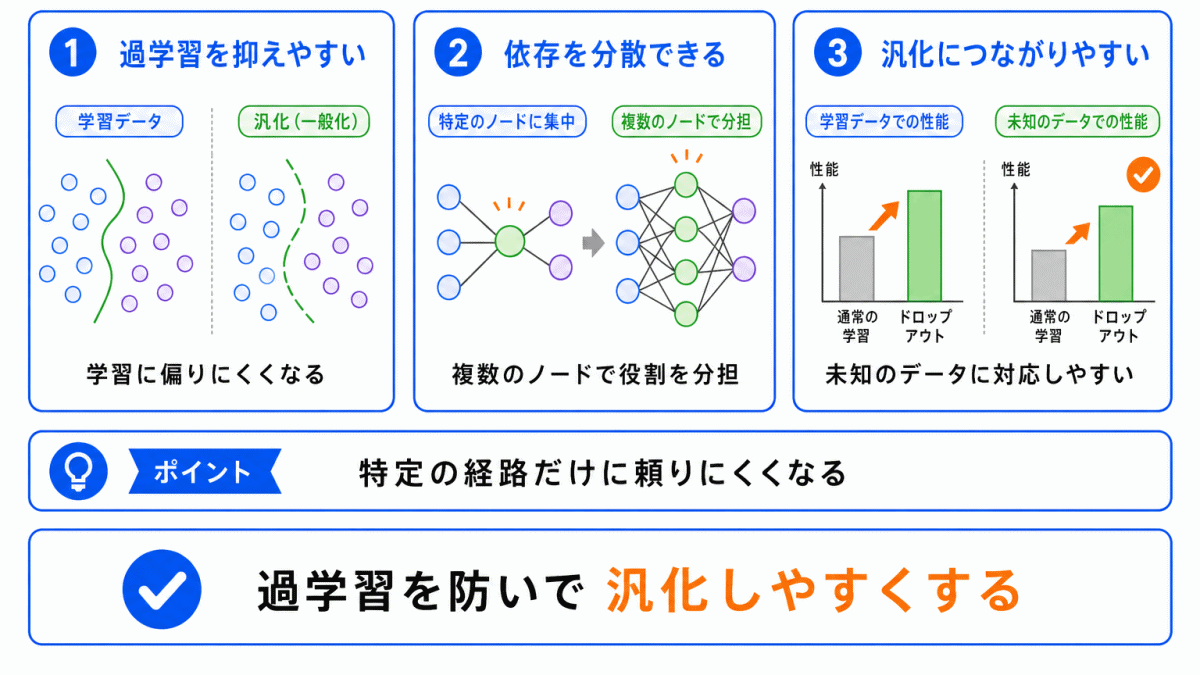
ドロップアウトのメリットは、過学習を抑えやすくなることです。
学習中に一部のノードを使えなくすることで、モデルは限られた経路だけに頼れなくなります。
| メリット | 内容 |
|---|---|
| 過学習を抑えやすい | 学習データへの合わせすぎを防ぐ |
| 依存を分散できる | 特定のノードに頼りにくくなる |
| 汎化につながりやすい | 未知のデータにも対応しやすくなることがある |
特に、ニューラルネットワークが複雑で、学習データに合わせすぎるおそれがある場合に使われます。
ただし、ドロップアウトを使えば必ず性能が上がるわけではありません。
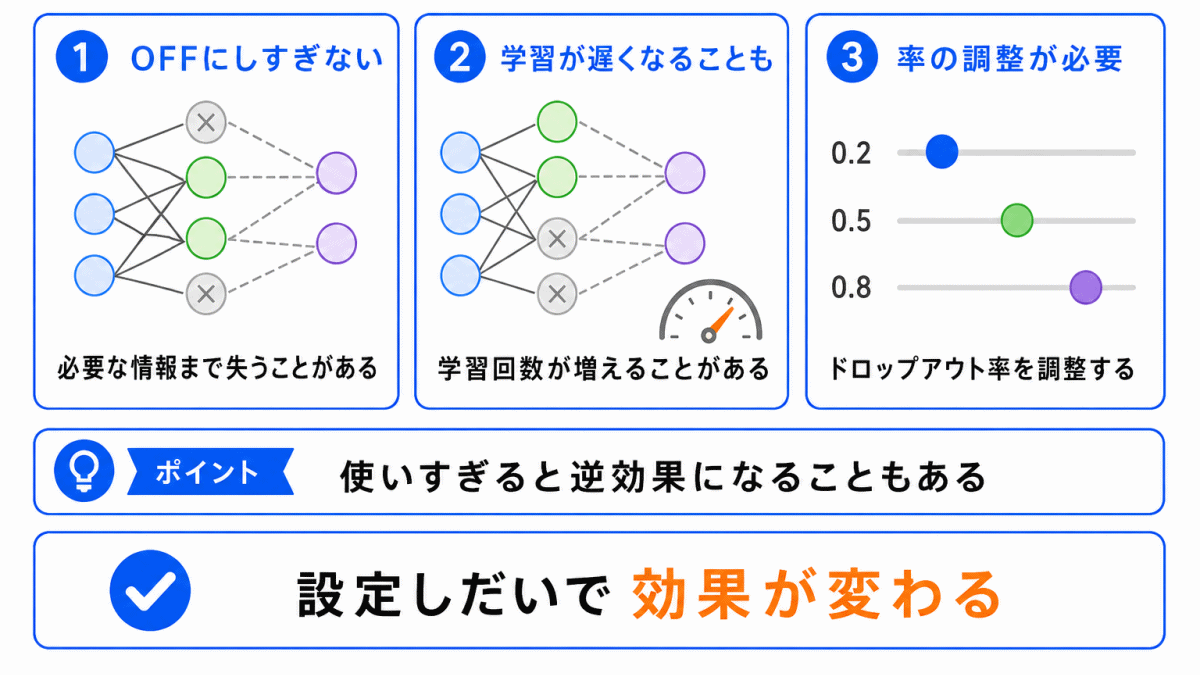
ドロップアウトは便利な手法ですが、使い方には注意が必要です。
ノードを無効化しすぎると、学習に必要な情報まで失われ、うまく学習できなくなることがあります。
また、ドロップアウトを使うと、学習に時間がかかる場合もあります。
| 注意点 | 内容 |
|---|---|
| 無効化しすぎに注意 | 必要な情報まで使えなくなる |
| 学習が遅くなることがある | 毎回一部のノードを外して学習するため |
| 設定が重要 | ドロップアウト率を調整する必要がある |
| 推論時は扱いが違う | 学習時と同じようには使わない |
ドロップアウト率とは、どれくらいの割合のノードを無効化するかを表す値です。
たとえば、ドロップアウト率が0.5なら、学習時に約半分のノードを無効化するイメージです。
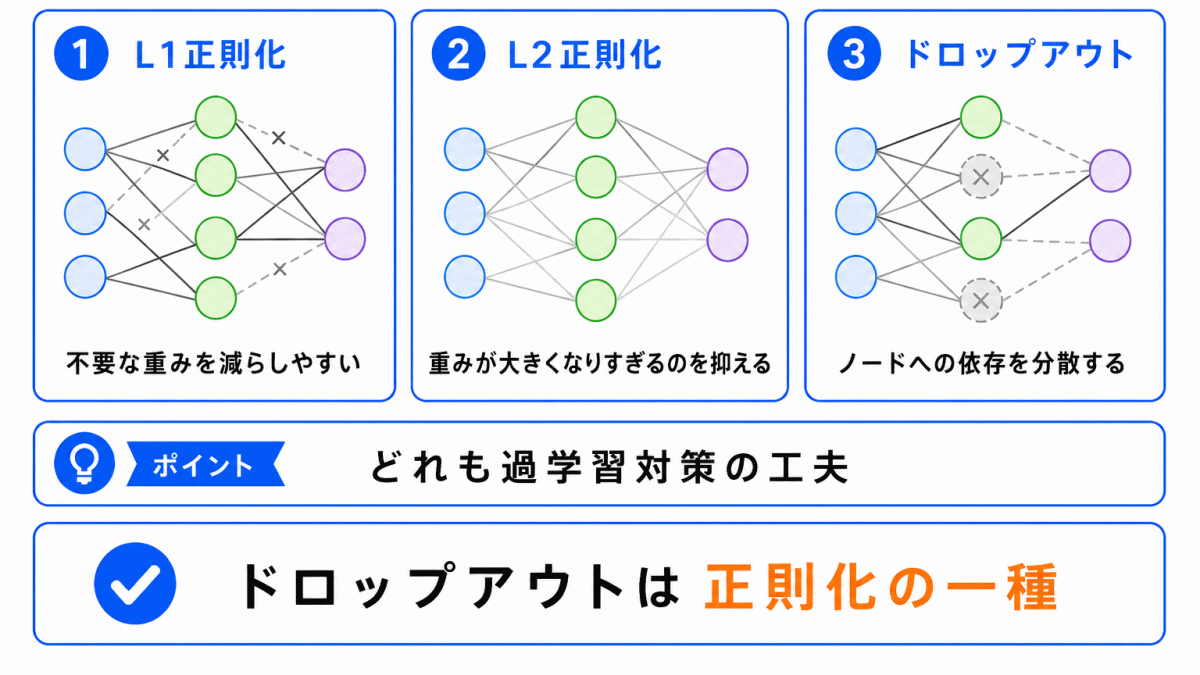
ドロップアウトは、過学習を抑えるための正則化手法の一つとして扱われます。
正則化とは、モデルが学習データに合わせすぎないようにする工夫です。
L1正則化やL2正則化は、重みに制約を加えることで過学習を抑えます。
一方、ドロップアウトは、ノードをランダムに無効化することで過学習を抑えます。
| 手法 | 何をするか | イメージ |
|---|---|---|
| L1正則化 | 不要な重みを小さくしやすい | 特徴を絞る |
| L2正則化 | 重みが大きくなりすぎるのを抑える | 全体をなめらかにする |
| ドロップアウト | 一部のノードを無効化する | 依存を分散する |
G検定では、ドロップアウトを単独で覚えるよりも、過学習を防ぐための正則化の一種 として整理しておくと理解しやすくなります。
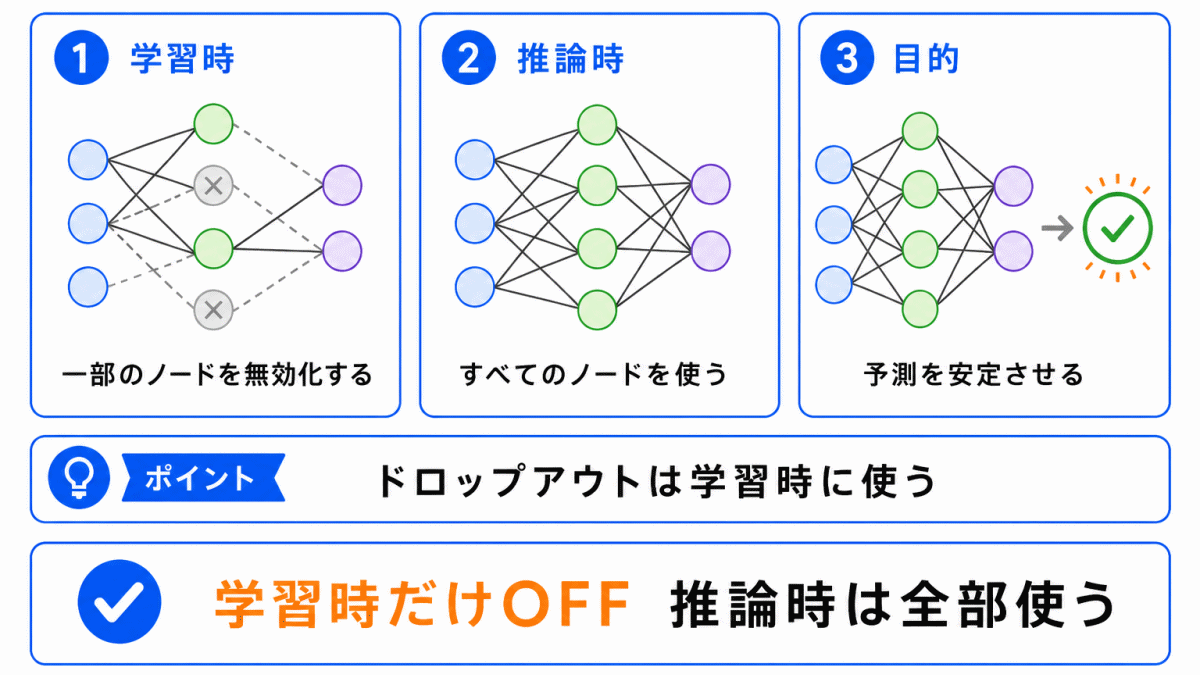
ドロップアウトで特に注意したいのが、学習時と推論時で扱いが違う ことです。
学習時は、一部のノードをランダムに無効化します。
しかし、推論時、つまり学習済みモデルを使って予測するときは、基本的にすべてのノードを使います。
| タイミング | ドロップアウトの扱い |
|---|---|
| 学習時 | 一部のノードをランダムに無効化する |
| 推論時 | 基本的にすべてのノードを使う |
推論時までノードをランダムに無効化してしまうと、予測結果が不安定になりやすくなります。
そのため、ドロップアウトは主に 学習時に過学習を抑えるための工夫 として使われます。
G検定では、ドロップアウトの細かい実装よりも、役割や目的が問われやすいです。
特に、過学習・正則化・学習時と推論時の違いをセットで整理しておくと判断しやすくなります。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| ドロップアウトの目的 | 過学習を抑える |
| 何を無効化するか | 学習中に一部のノードをランダムに無効化する |
| 正則化との関係 | 過学習対策の一種 |
| 学習時と推論時 | 学習時に使い、推論時は基本的にすべてのノードを使う |
| 注意点 | 使えば必ず性能が上がるわけではない |
「ドロップアウト=ノードを消す」とだけ覚えると、何のために使うのかがあいまいになります。
特定のノードへの依存を防ぎ、過学習を抑えるための手法 と整理しておくことが大切です。
ドロップアウトとは、ニューラルネットワークの学習中に、一部のノードをランダムに無効化する手法です。
特定のノードに頼りすぎることを防ぎ、過学習を抑えやすくする目的で使われます。
| 用語 | 一言でいうと |
|---|---|
| 過学習 | 学習データに合わせすぎること |
| 正則化 | 過学習を抑える工夫 |
| ドロップアウト | 一部のノードをランダムに無効化する手法 |
| ドロップアウト率 | 無効化するノードの割合 |
| 推論時 | 学習済みモデルで予測する段階 |
G検定では、ドロップアウトを数式で理解するよりも、過学習を防ぐために、学習中のノードを一部使わないようにする方法 と押さえておくと十分です。
また、ドロップアウトは学習時に使うものであり、推論時には基本的にすべてのノードを使う点も重要です。
ドロップアウトは、ニューラルネットワークの一部を使わずに学習することで、過学習を抑えるための手法です。
過学習、正則化、バイアスと分散までつなげて確認しておくと理解しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 過学習とは? | 学習データに合わせすぎる状態/汎化性能との関係/過学習を防ぐ工夫 |
| 正則化とは? | モデルの複雑さを抑える考え方/過学習対策/ドロップアウトとの関係 |
| ニューラルネットワークとは? | 入力から予測までの流れ/ノード・層の関係/ドロップアウトが使われる場所 |
| バイアスと分散とは? | 過学習・未学習の原因/モデルの複雑さとの関係/汎化性能の見方 |
| 過学習・正則化・ドロップアウト予想問題 | 混同しやすい用語の確認/引っかけポイント/理解型の問題演習 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。