【G検定対策】データリーケージとは?|本番で使えない情報が混ざる問題をわかりやすく整理
seo-webmaster
G検定対策ブログ
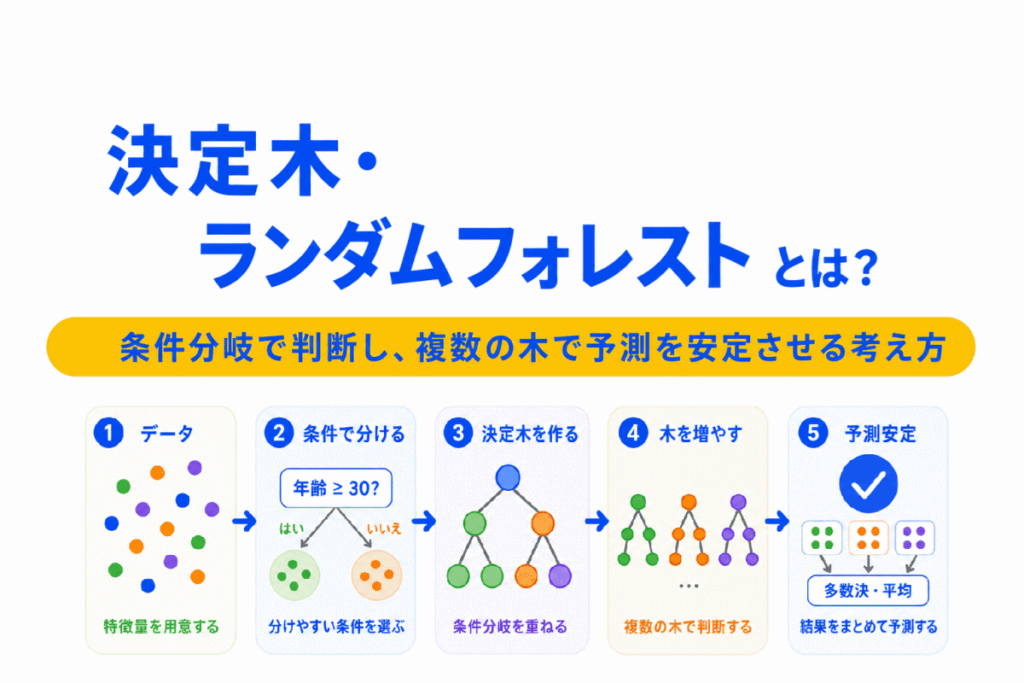
決定木は、条件分岐を使ってデータを分けていく機械学習の手法です。
「気温が高いか」、「購入回数が多いか」、「画像の特徴があるか」のように、条件を順番にたどりながら判断します。
一方、ランダムフォレストは、複数の決定木を組み合わせて予測を安定させる手法です。
G検定では、決定木を単独で覚えるだけでなく、教師あり学習、分類、回帰、過学習、アンサンブル学習とのつながりで理解しておくことが大切です。
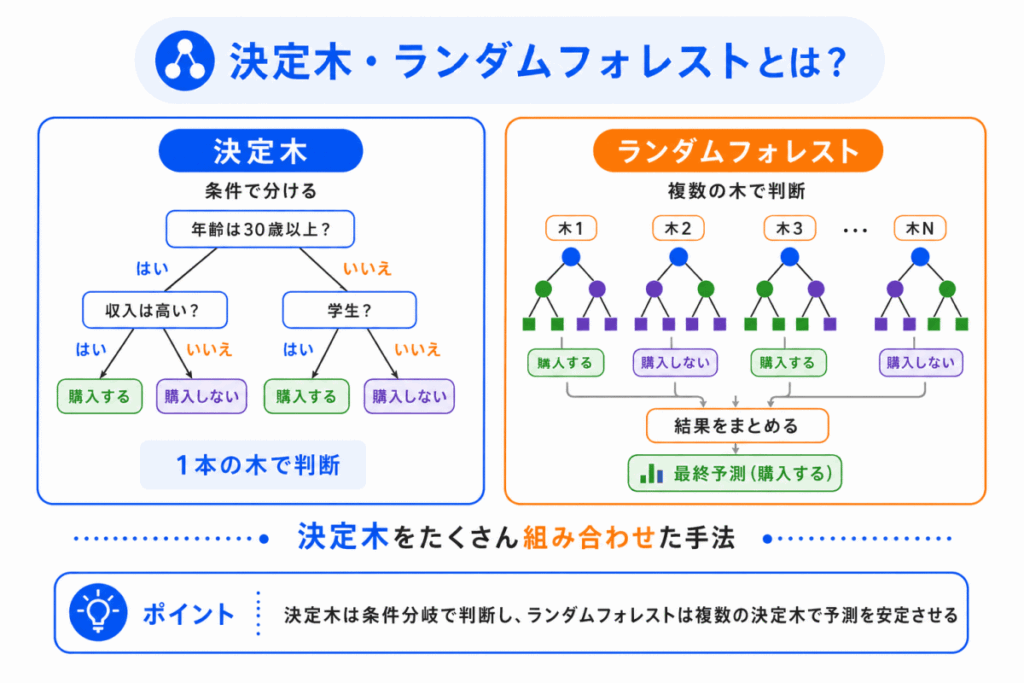
決定木とは、条件分岐を木のようにつなげて、分類や回帰を行う手法です。
たとえば、ある人が商品を買うかどうかを予測する場合、次のように条件をたどって判断します。
ランダムフォレストは、この決定木をたくさん作り、それぞれの予測結果を組み合わせる手法です。
1本の決定木だけに頼るよりも、複数の木で判断した方が、予測が安定しやすくなります。
決定木とランダムフォレストの関係は、次のように整理できます。
| 用語 | 意味 | ポイント |
|---|---|---|
| 決定木 | 条件分岐を使って予測する手法 | 判断の流れが見えやすい |
| ランダムフォレスト | 複数の決定木を組み合わせる手法 | 予測を安定させやすい |
| アンサンブル学習 | 複数のモデルを組み合わせる考え方 | ランダムフォレストの土台になる |
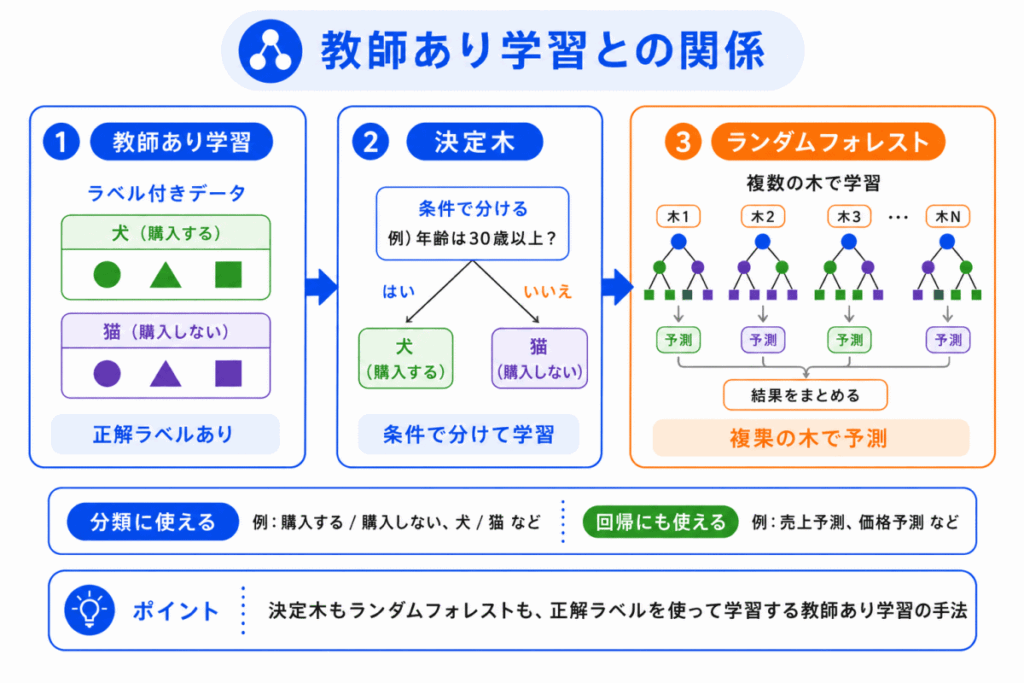
決定木とランダムフォレストは、教師あり学習で使われる代表的な手法です。
たとえば、次のような使い方があります。
| 目的 | 例 | 決定木で行うこと |
|---|---|---|
| 分類 | 購入する / 購入しない | どちらのクラスに入るかを判断する |
| 分類 | 迷惑メール / 通常メール | メールの特徴から種類を分ける |
| 回帰 | 売上金額の予測 | 数値を予測する |
| 回帰 | 住宅価格の予測 | 条件から価格を予測する |
ここで大切なのは、決定木は分類だけでなく、回帰にも使えるという点です。
G検定では、分類手法として出てくることが多いですが、数値予測にも使えることを押さえておくと理解しやすくなります。
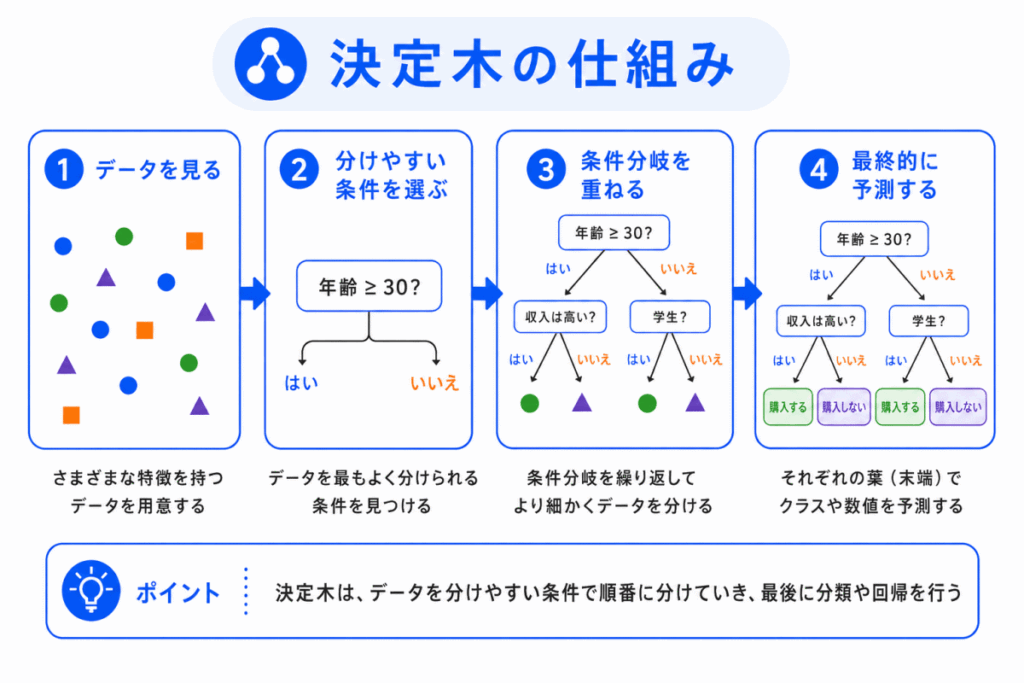
決定木は、データを条件で分けながら、最終的な予測へ進みます。
木構造で考えると、上から下へ条件をたどるイメージです。
たとえば、商品を買うかどうかを予測する場合、決定木は次のような条件を作ります。
このような条件をたどりながら、最終的に「購入しそう」、「購入しなさそう」のように予測します。
決定木は、人間にとって判断の流れが見えやすいことが特徴です。
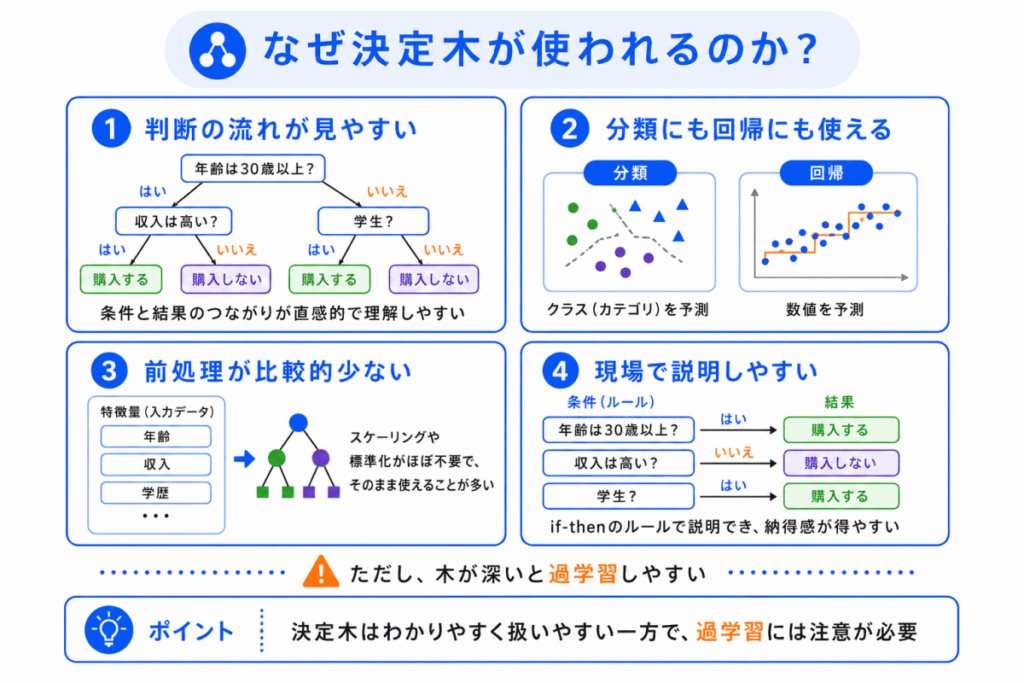
決定木が使われる理由は、判断の流れを理解しやすいからです。
ニューラルネットワークのように内部の判断が見えにくいモデルと比べると、決定木は「どの条件で分けたのか」が比較的わかりやすいです。
主な特徴は、次の通りです。
| 特徴 | 内容 | 注意点 |
|---|---|---|
| 解釈しやすい | 条件分岐で判断の流れを見やすい | 木が深くなると複雑になる |
| 分類と回帰に使える | クラス分類にも数値予測にも使える | 目的に応じて使い分ける |
| 前処理が比較的少ない | 特徴量のスケール差に強い場合がある | データ品質の影響は受ける |
| 過学習しやすい | 学習データに合わせすぎることがある | 木の深さなどを調整する |
決定木はわかりやすい一方で、学習データに細かく合わせすぎると、過学習が起きやすくなります。
その弱点を補う考え方として、ランダムフォレストが登場します。
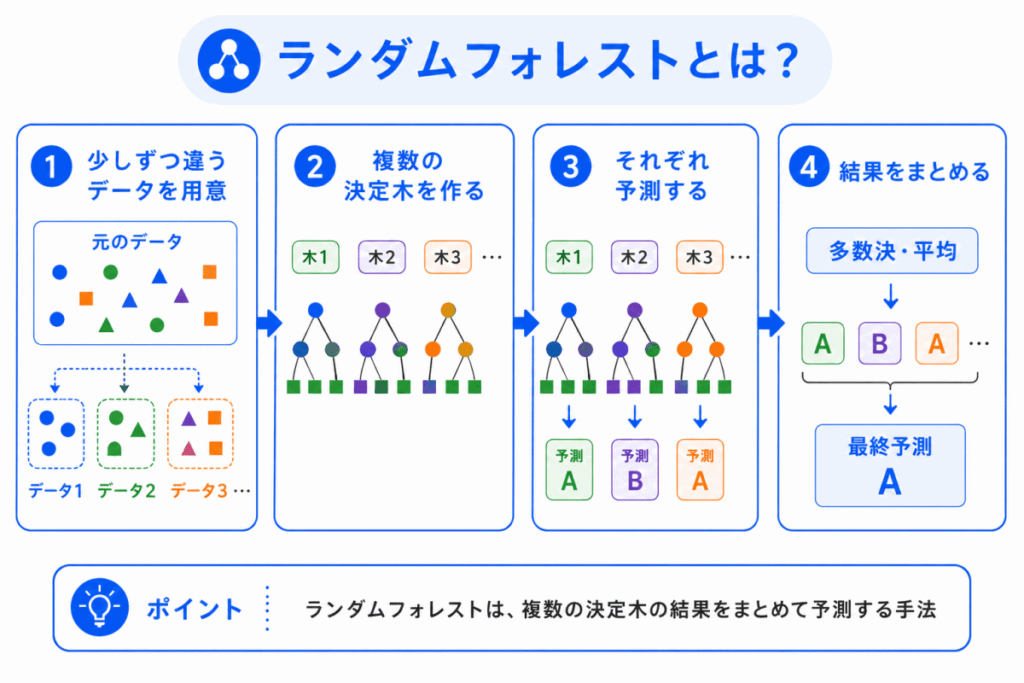
ランダムフォレストは、複数の決定木を作り、それらの予測を組み合わせる手法です。
名前の通り、たくさんの木を集めた森のようなイメージです。
1本の決定木だけで判断すると、学習データの偏りに引っ張られやすくなります。
そこで、ランダムフォレストでは、少しずつ異なるデータや特徴量を使って、複数の決定木を作ります。
そのうえで、分類なら多数決、回帰なら平均のようにして、最終的な予測を決めます。
| 項目 | 決定木 | ランダムフォレスト |
|---|---|---|
| モデルの数 | 1本の木 | 複数の木 |
| 判断の安定性 | データに左右されやすい | 安定しやすい |
| 過学習 | 起きやすい | 抑えやすい |
| 解釈しやすさ | 比較的わかりやすい | 単体の木よりは見えにくい |
ランダムフォレストは、決定木のわかりやすさを活かしつつ、複数の木で予測を安定させる手法です。
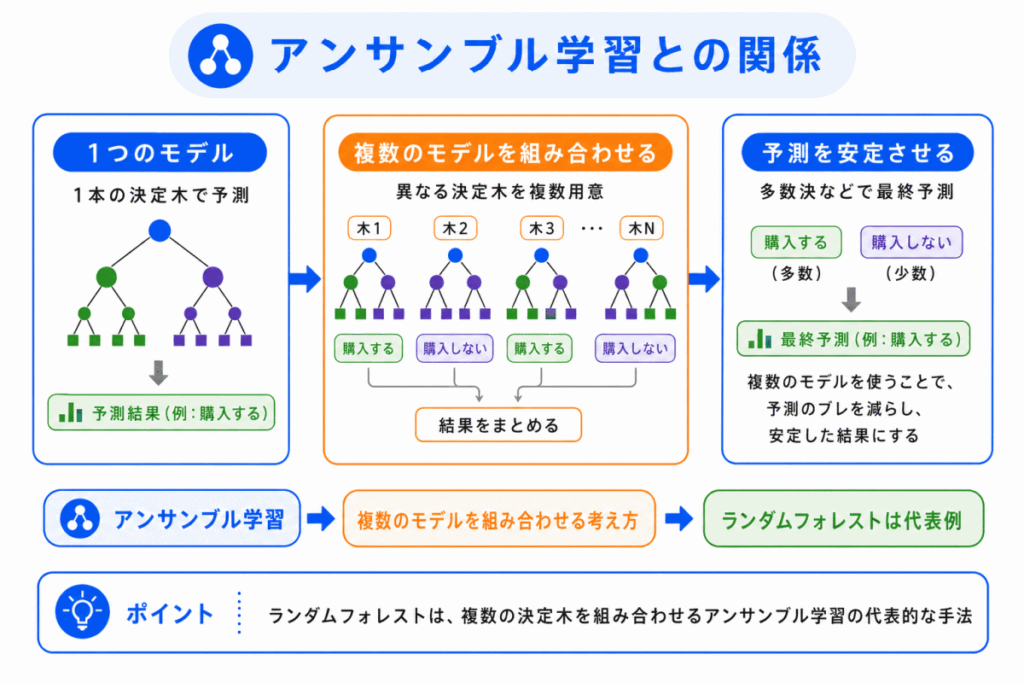
ランダムフォレストは、アンサンブル学習の代表例です。
アンサンブル学習とは、複数のモデルを組み合わせて、単独のモデルよりもよい予測を目指す考え方です。
1人だけの意見で判断するより、複数人の意見を集めた方が安定することがあります。
ランダムフォレストも同じで、1本の決定木ではなく、複数の決定木の結果を組み合わせて予測します。
特に、ランダムフォレストはバギングの考え方と関係します。
バギングとは、学習データから少しずつ違うデータを取り出して、複数のモデルを作る方法です。
G検定では、次の関係で整理しておくと覚えやすくなります。
| 用語 | 押さえ方 |
|---|---|
| アンサンブル学習 | 複数のモデルを組み合わせる考え方 |
| バギング | データを少しずつ変えて複数のモデルを作る方法 |
| ランダムフォレスト | 複数の決定木を組み合わせる代表的な手法 |
「ランダムフォレスト=アンサンブル学習の一種」と押さえておくと、他の手法との関係も理解しやすくなります。
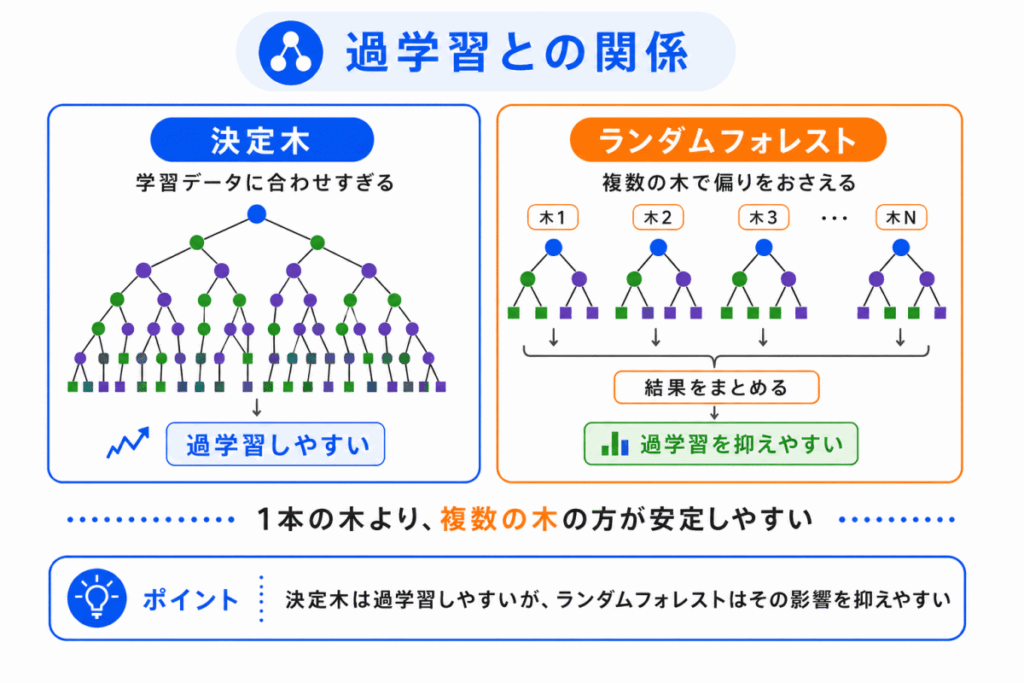
決定木は、条件分岐を細かく増やしていくと、学習データにぴったり合いやすくなります。
一見すると性能が高く見えますが、本番データではうまく予測できないことがあります。
これが過学習です。
決定木では、木が深くなりすぎると、細かい例外まで覚えてしまいやすくなります。
そのため、木の深さを制限したり、分岐を増やしすぎないようにしたりすることが重要です。
ランダムフォレストは、複数の決定木を組み合わせることで、1本の木に依存しすぎる問題を抑えます。
ただし、ランダムフォレストを使えば必ず過学習しない、というわけではありません。
データの質、特徴量、モデル設定によって結果は変わります。
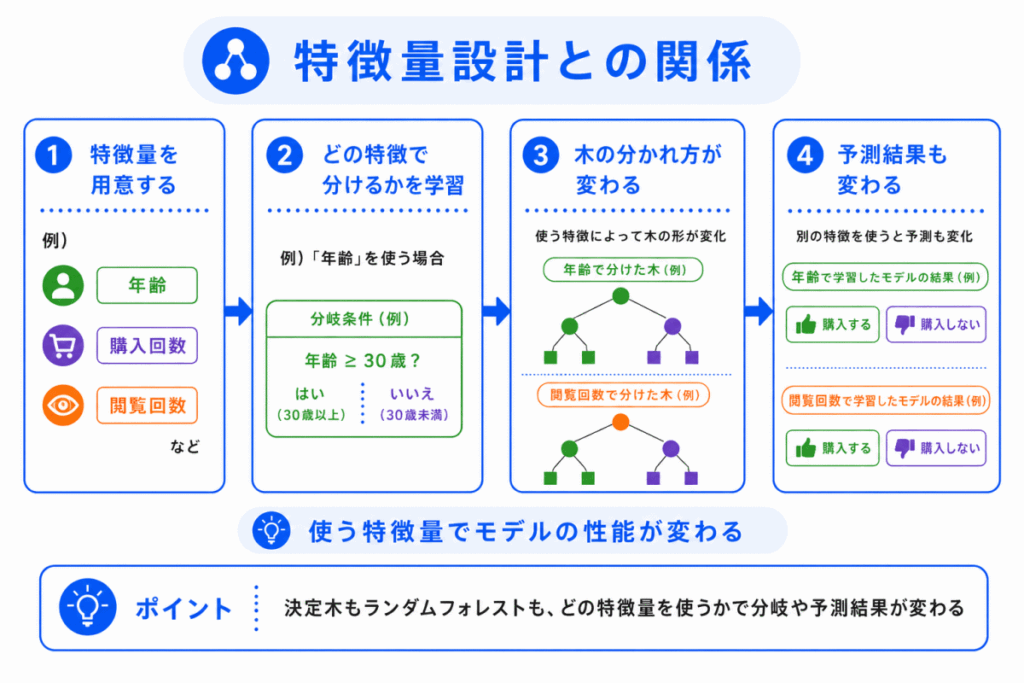
決定木やランダムフォレストは、特徴量の影響を受けます。
特徴量とは、AIが判断に使うデータの項目です。
たとえば、購入予測であれば、年齢、購入回数、閲覧回数、滞在時間などが特徴量になります。
どの特徴量を使うかによって、決定木の分岐も変わります。
つまり、決定木は「どの条件で分けるか」を学習しますが、その条件の材料になるのは特徴量です。
そのため、特徴量設計が悪いと、決定木やランダムフォレストでも良い予測はできません。
G検定では、アルゴリズムだけでなく、データ前処理や特徴量設計との関係も意識しておくと理解が深まります。
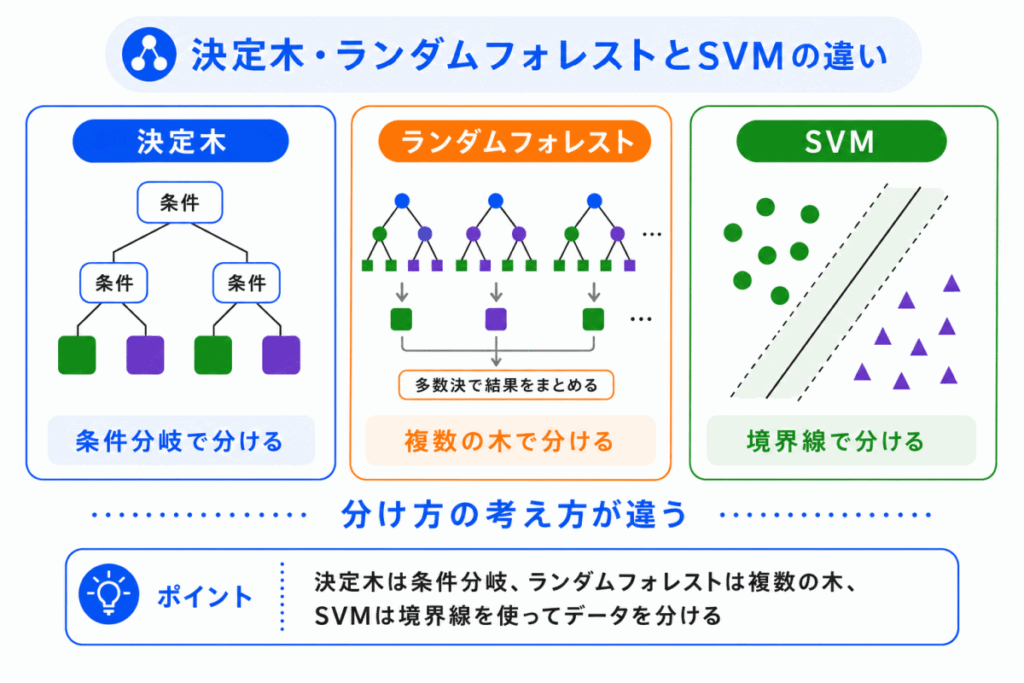
決定木やランダムフォレストと一緒に、SVMが出てくることがあります。
どちらも教師あり学習の代表的な手法ですが、考え方は違います。
決定木は、条件分岐でデータを分けます。
SVMは、境界線や境界面を使ってデータを分けます。
細かい数式よりも、まずは分け方のイメージの違いを押さえることが大切です。
| 手法 | 分け方のイメージ | 押さえるポイント |
|---|---|---|
| 決定木 | 条件分岐で分ける | 判断の流れが木構造になる |
| ランダムフォレスト | 複数の決定木で分ける | 予測を安定させやすい |
| SVM | 境界線や境界面で分ける | マージンを意識する |
この違いを押さえておくと、次にSVMを学ぶときにも理解しやすくなります。
G検定では、決定木やランダムフォレストについて、細かい計算よりも意味と関係が問われやすいです。
特に、次のポイントを押さえておきましょう。
ランダムフォレストは、アンサンブル学習の代表例です。
決定木は解釈しやすい一方で、過学習しやすい特徴があります。
ランダムフォレストは、複数の木を使うことで予測を安定させやすくします。
分類だけでなく、回帰にも使える点も押さえておくと安心です。
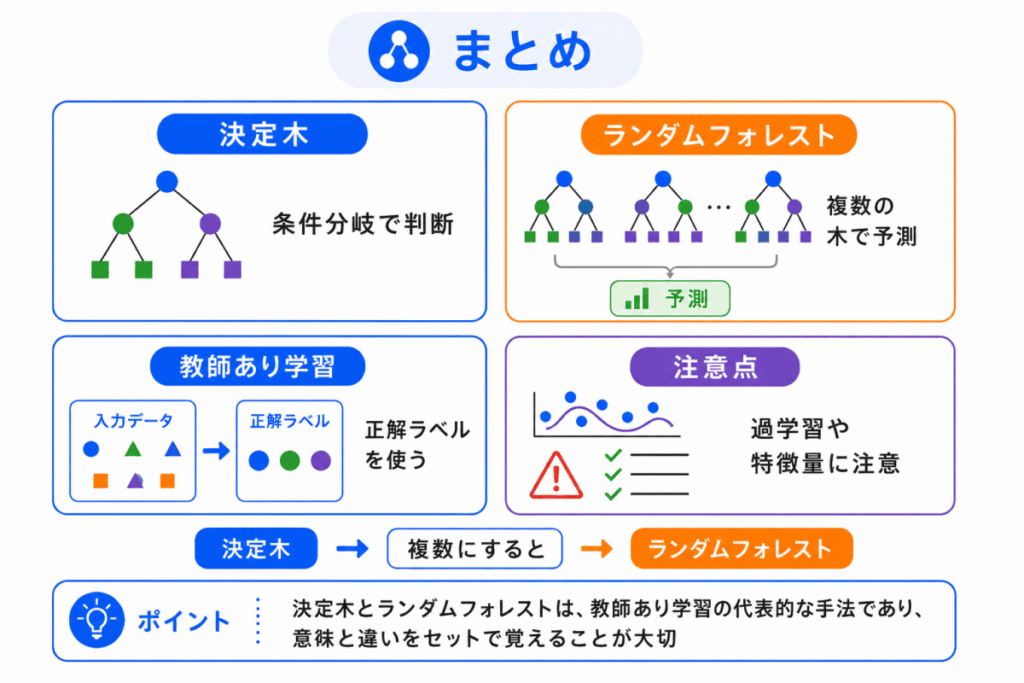
最後に、決定木とランダムフォレストの要点を整理します。
決定木は、条件で分けながら予測するわかりやすい手法です。
ランダムフォレストは、その決定木を複数組み合わせて、予測を安定させる手法です。
G検定では、「決定木」、「ランダムフォレスト」、「アンサンブル学習」、「過学習」の関係をセットで理解しておきましょう。
教師あり学習全体の中で位置づけを確認するなら、こちらの記事がおすすめです。
分類、回帰、教師なし学習との違いを整理するなら、こちらの記事がおすすめです。
複数のモデルを組み合わせる考え方を確認するなら、こちらの記事がおすすめです。
過学習との関係を確認するなら、こちらの記事がおすすめです。
特徴量との関係を確認するなら、こちらの記事がおすすめです。

データを整える流れを確認するなら、こちらの記事がおすすめです。
機械学習全体の流れを確認するなら、こちらの記事がおすすめです。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認