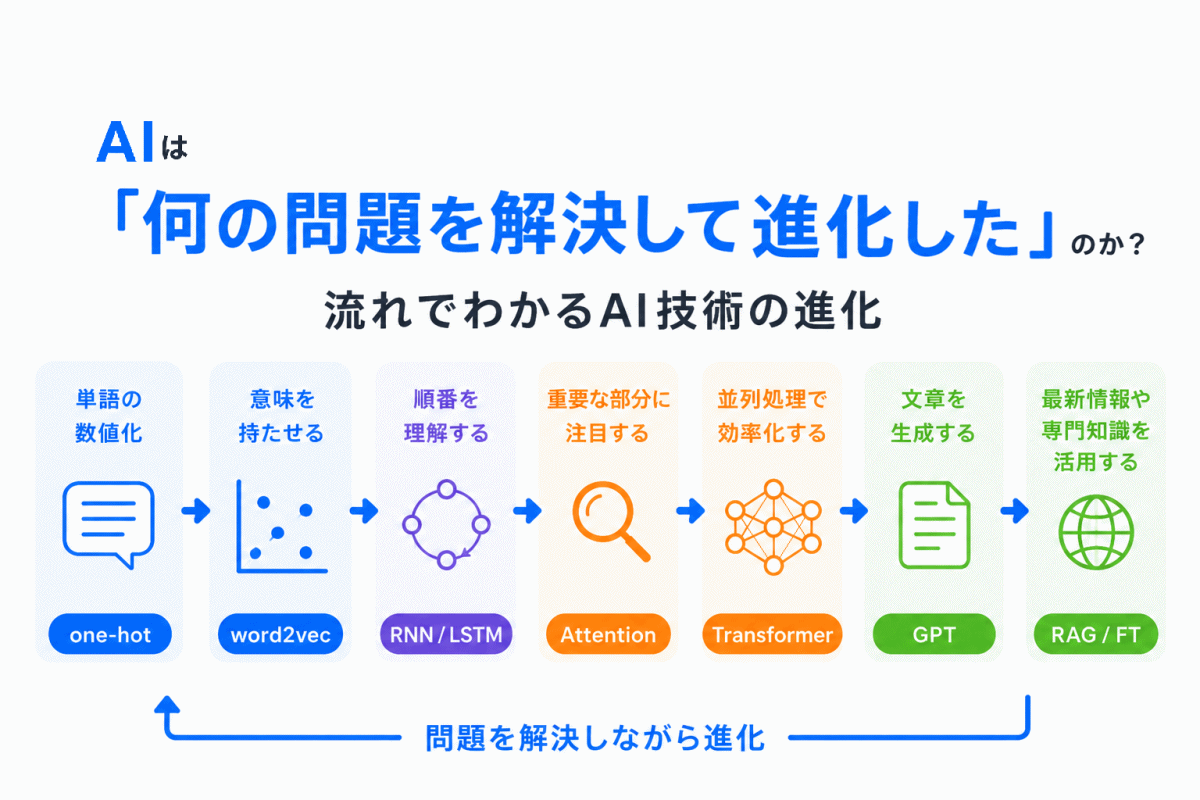
【G検定対策】CNN・RNN・Transformerの違いをわかりやすく整理
seo-webmaster
G検定対策ブログ
生成AIに関係する用語は、単語だけで覚えようとすると混同しやすくなります。
事前学習、ファインチューニング、RLHF、RAG、アライメントは、それぞれ別の意味を持つ言葉ですが、生成AIが「使える形」になるまでの流れ として見ると理解しやすくなります。
この記事では、生成AIがどのように基礎力を身につけ、人間にとって使いやすい形へ調整され、外部情報で補われるのかを整理します。
用語の意味だけでなく「どの段階の話なのか」を問われることがあるため、流れで理解しておくことが大切です。
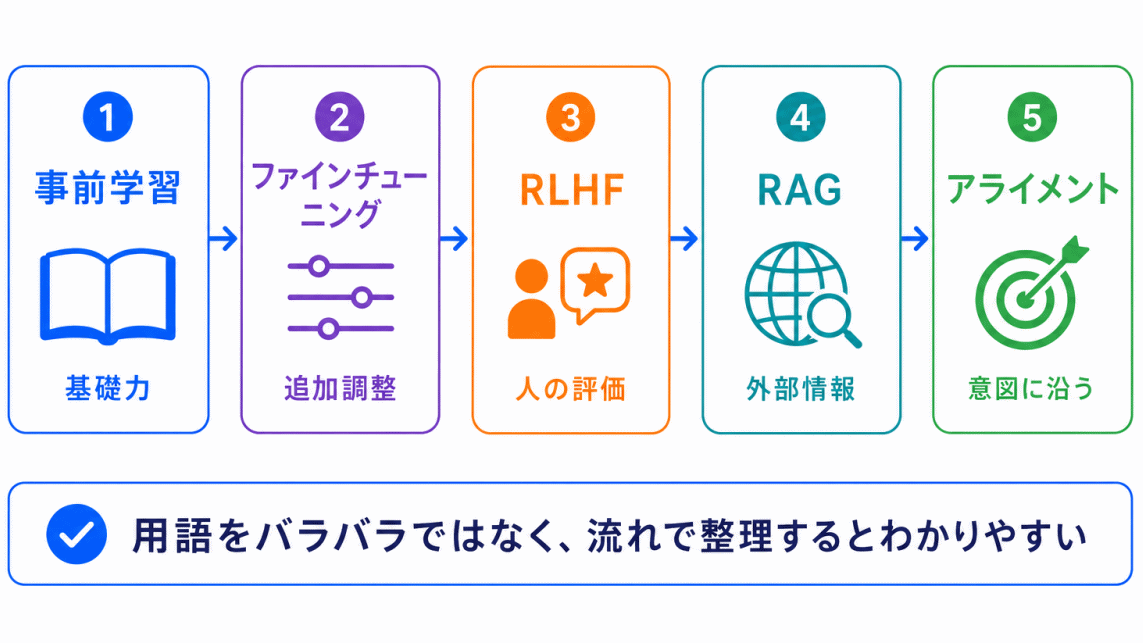
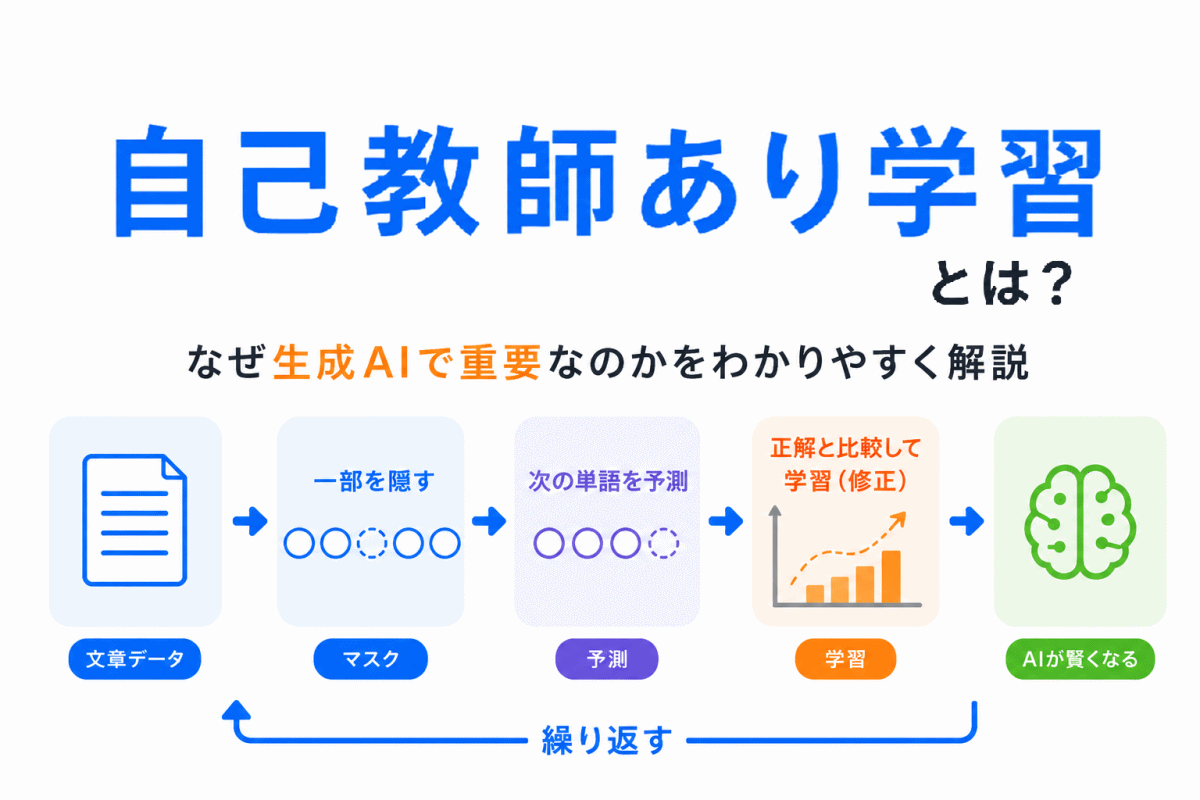
生成AIは、最初から人間にとって使いやすい回答ができるわけではありません。
大まかには、次のような流れで理解するとわかりやすいです。
この流れの中で登場するのが

という考え方です。
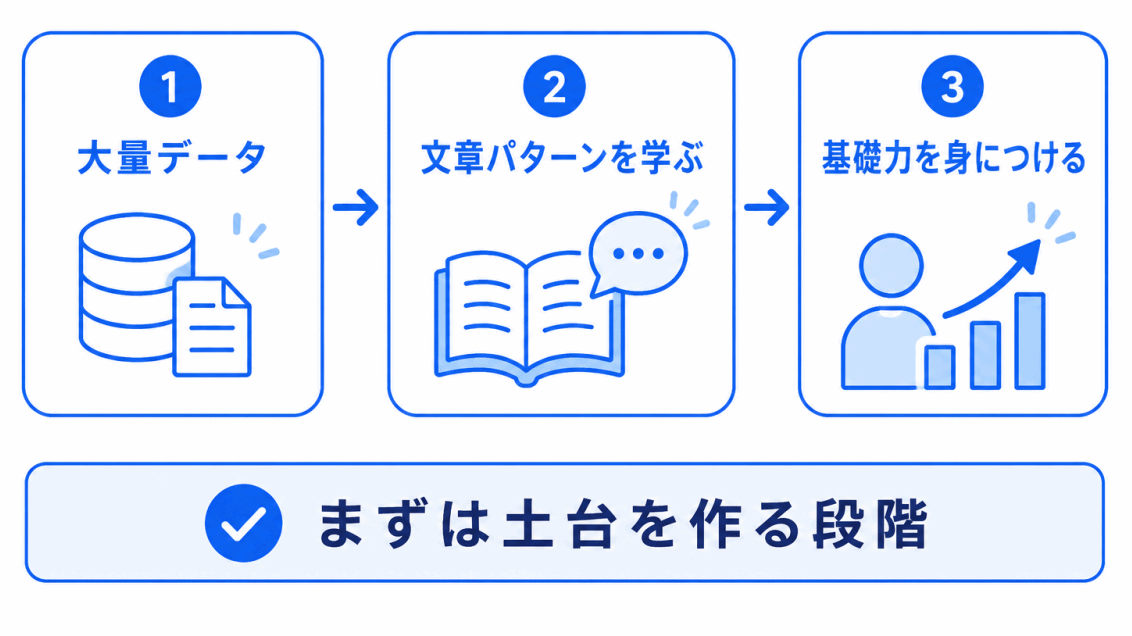
生成AIの土台になるのが、事前学習です。
事前学習では、大量の文章データを使って、言葉の使われ方や文脈、文章のパターンを学びます。
ここで重要なのは、事前学習は「特定の仕事だけを覚える段階」ではないということです。
たとえば
ような形で、広い意味での基礎力を身につけます。
つまり、事前学習は生成AIにとっての 土台作り です。
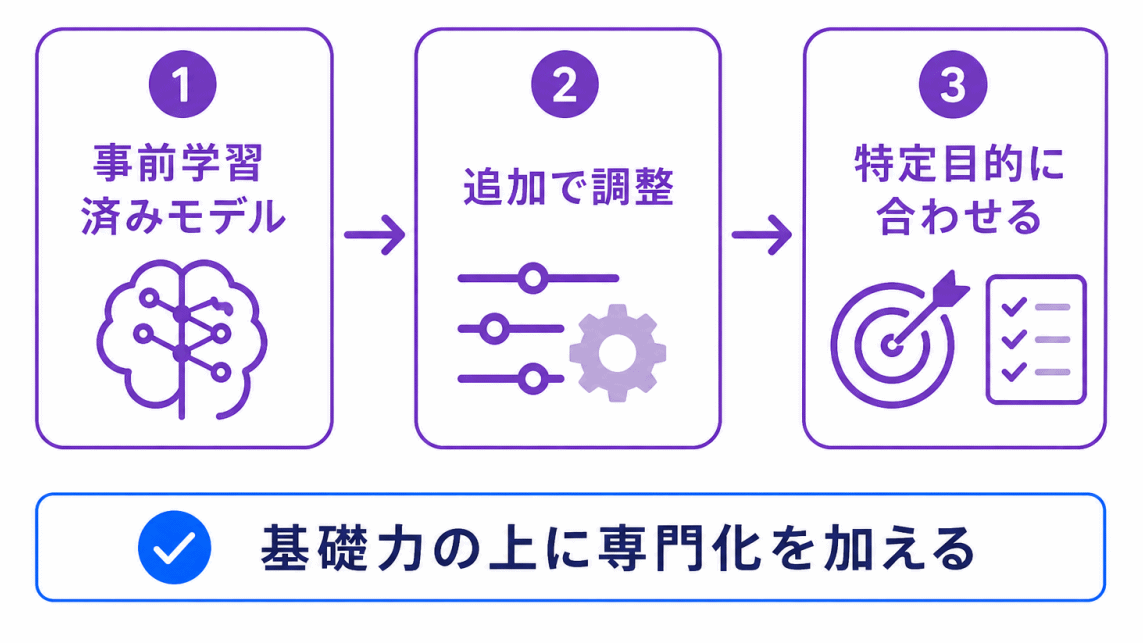
事前学習だけでは、特定の目的にぴったり合うとは限りません。
そこで使われるのが、ファインチューニングです。
ファインチューニングは、事前学習済みのモデルに対して、特定の目的に合わせて追加で学習させる方法です。
たとえば
| 目的 | 調整のイメージ |
|---|---|
| 医療文書に強くしたい | 医療系データで追加学習 |
| 法律文書に強くしたい | 法律系データで追加学習 |
| 社内用AIにしたい | 社内ルールや文体に合わせる |
事前学習が「基礎力」だとすると、ファインチューニングは 専門化 に近い考え方です。
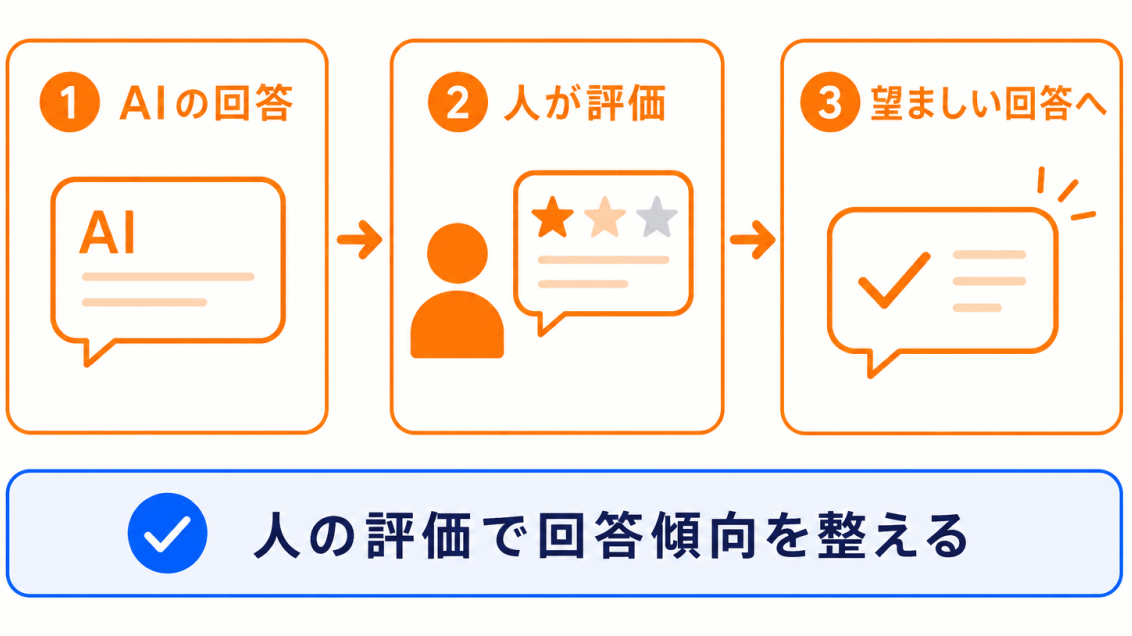
生成AIは、ただ文章を生成できるだけでは十分ではありません。
人間から見ると
といった問題が起こることがあります。
そこで使われる代表的な方法が、RLHFです。
RLHFは、人間のフィードバックを使って、より好ましい回答に近づける考え方です。
ここでのポイントは、RLHFは「知識を増やす方法」というより、回答の傾向を整える方法 だということです。
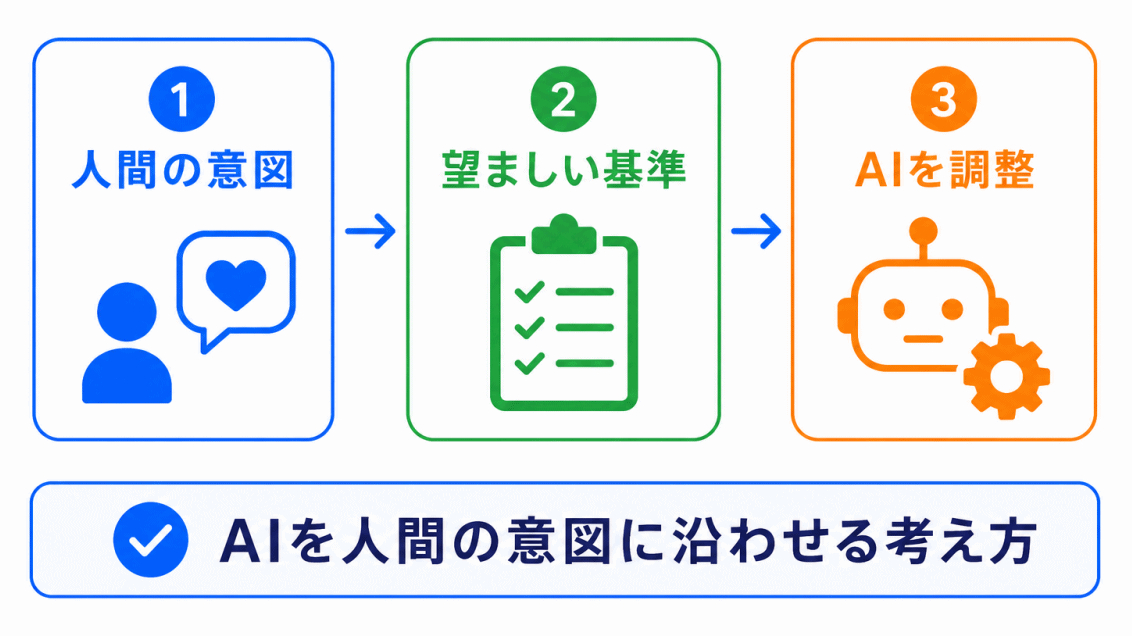
アライメントは、AIを人間の意図や価値観に沿わせる考え方です。
RLHFと混同しやすいですが、役割は少し違います。
| 用語 | 役割 |
|---|---|
| アライメント | 目標・考え方 |
| RLHF | その目標に近づける方法の一つ |
つまり
と整理するとわかりやすいです。
アライメントは、AI倫理や安全性、ハルシネーション対策とも関係します。
ただし、アライメントを行えばすべての問題が解決するわけではありません。
どの価値観に合わせるのか、誰の基準を反映するのか、という難しさもあります。
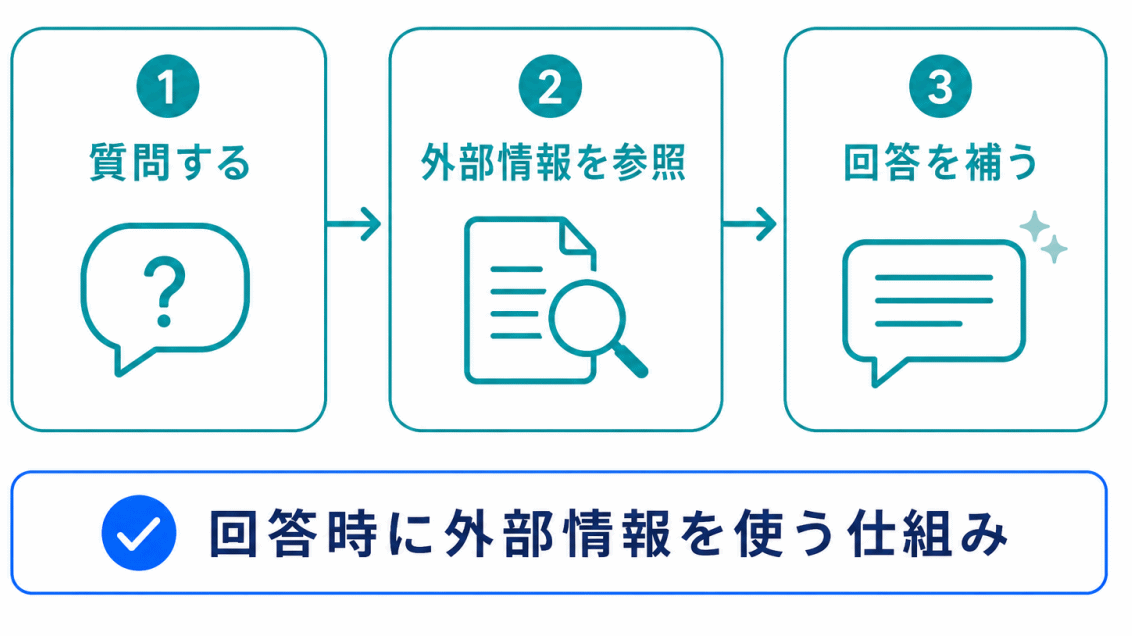
生成AIは、事前学習で得た知識をもとに回答します。
しかし、事前学習した時点より新しい情報や、社内文書のような個別情報には弱い場合があります。
そこで使われるのが、RAG です。
RAGは、外部情報を検索・参照しながら回答を生成する仕組みです。
| 比較 | 役割 |
|---|---|
| 事前学習 | モデル内部に知識の土台を作る |
| RAG | 外部情報を参照して回答を補う |
RAGは、モデルそのものを直接学習し直すというより、回答時に外部情報を使う仕組み です。
そのため、ファインチューニングやRLHFとは役割が違います。
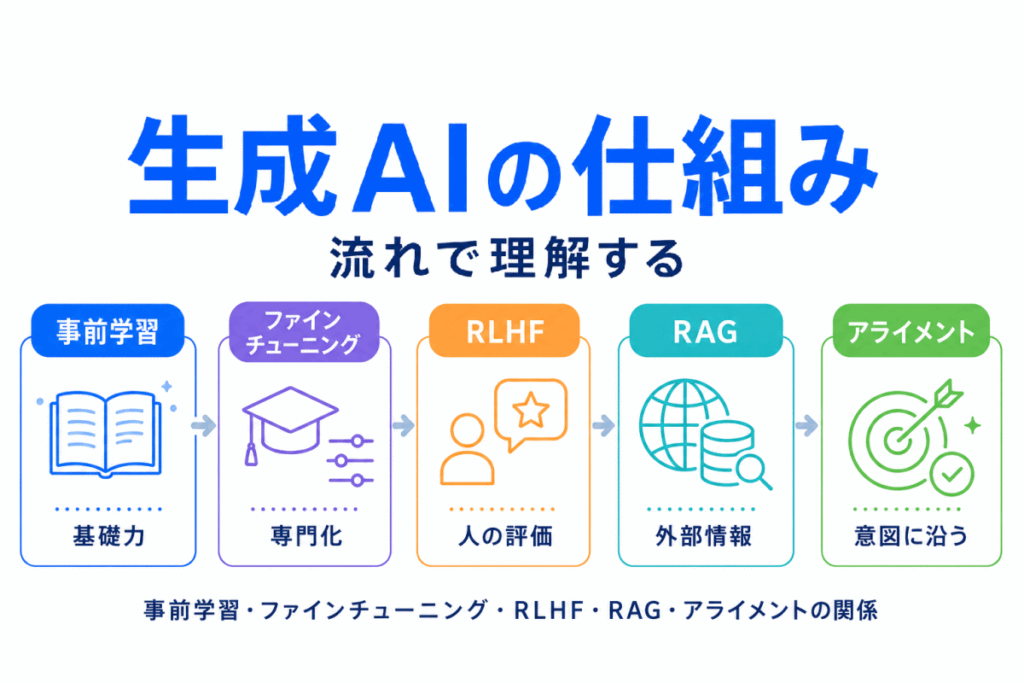
生成AIの仕組みは、用語を単独で覚えるより、流れの中で見ると整理しやすくなります。
| 段階 | 用語 | 役割 |
|---|---|---|
| 土台作り | 事前学習 | 大量データで基礎力を身につける |
| 目的調整 | ファインチューニング | 特定目的に合わせて追加調整する |
| 回答調整 | RLHF | 人間の評価で好ましい回答に近づける |
| 情報補完 | RAG | 外部情報を参照して回答を補う |
| 方向づけ | アライメント | 人間の意図や価値観に沿わせる |
特に混同しやすいのは、次の3つです。

G検定では、細かい実装手順よりも、それぞれの用語の役割の違いが問われやすいです。
たとえば、次のような整理が重要です。
| 問われ方 | 答え |
|---|---|
| 大量データで基礎力を身につける | 事前学習 |
| 特定目的に合わせて追加調整する | ファインチューニング |
| 人間の評価を使って回答を調整する | RLHF |
| 外部情報を参照して回答を補う | RAG |
| AIを人間の意図や価値観に沿わせる | アライメント |
単語だけで覚えると、RAGもファインチューニングも「AIをよくする方法」に見えてしまいます。
しかし、役割で見ると違います。
この違いを押さえると、選択肢の表現が変わっても判断しやすくなります。
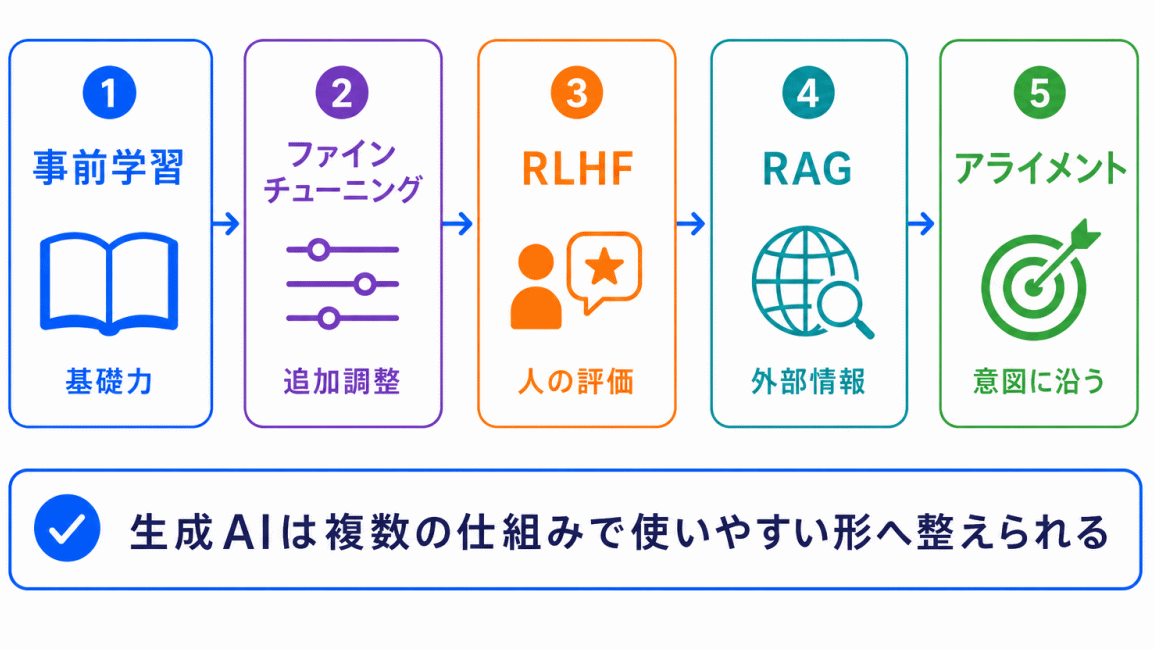
生成AIの仕組みは、用語をバラバラに覚えるよりも、流れで理解した方が整理しやすくなります。
まず、事前学習によって大量データから基礎力を身につけます。
その後、ファインチューニングによって目的に合わせて調整され、RLHFによって人間にとって好ましい回答へ近づけられます。
さらに、RAGによって外部情報を参照できるようになり、アライメントによって人間の意図や価値観に沿う方向へ整えられます。
つまり、生成AIは単に「大量データで学んだAI」ではなく、さまざまな調整や補助の仕組みによって、実際に使いやすい形へ近づけられていると考えるとわかりやすいです。
生成AIの仕組みは、事前学習、ファインチューニング、RLHF、RAG、アライメントを流れで見ると理解しやすくなります。
関連する用語をあわせて確認して、生成AIがどのように学習し、調整されるのか整理しておきましょう。
| 読む記事 | 確認できる内容 |
|---|---|
| 事前学習とは? | 大量データから知識を身につける流れ/LLMの土台作り/ファインチューニングとの違い |
| ファインチューニングとは? | 事前学習済みモデルの専門化/追加学習の考え方/転移学習との関係 |
| RLHFとは? | 人間の評価で回答を調整する仕組み/好ましい回答への調整/アライメントとの関係 |
| RAGとは? | 外部情報を参照する仕組み/生成AIの弱点補完/ハルシネーション対策との関係 |
| LLMとは? | 大規模言語モデルの意味/GPTとの違い/生成AIとの関係 |
| アライメントとは? | AIを人間の意図に沿わせる考え方/安全な生成AI利用/RLHFとの関係 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。