【G検定対策】説明可能AI(XAI)とは?|AIの判断理由がなぜ重要なのか
seo-webmaster
SEO・ウェブマスターブログ
AIはデータから学習しますが、集めたデータをそのまま使えるとは限りません。
欠損値があったり、表記がばらばらだったり、外れ値やノイズが含まれていたりすると、AIは正しいパターンを学びにくくなります。
そこで重要になるのが、データ前処理です。
この記事では、データ前処理の意味、データ品質との関係、主な作業内容、G検定で問われやすいポイントを、AIの学習をはじめたばかりの人向けに整理します。
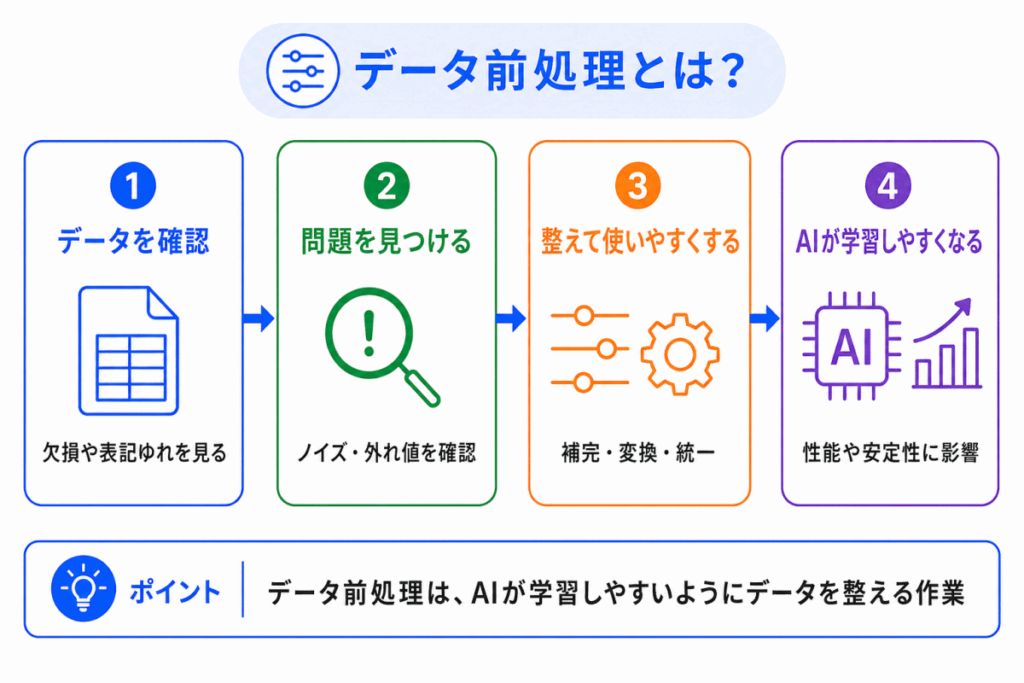
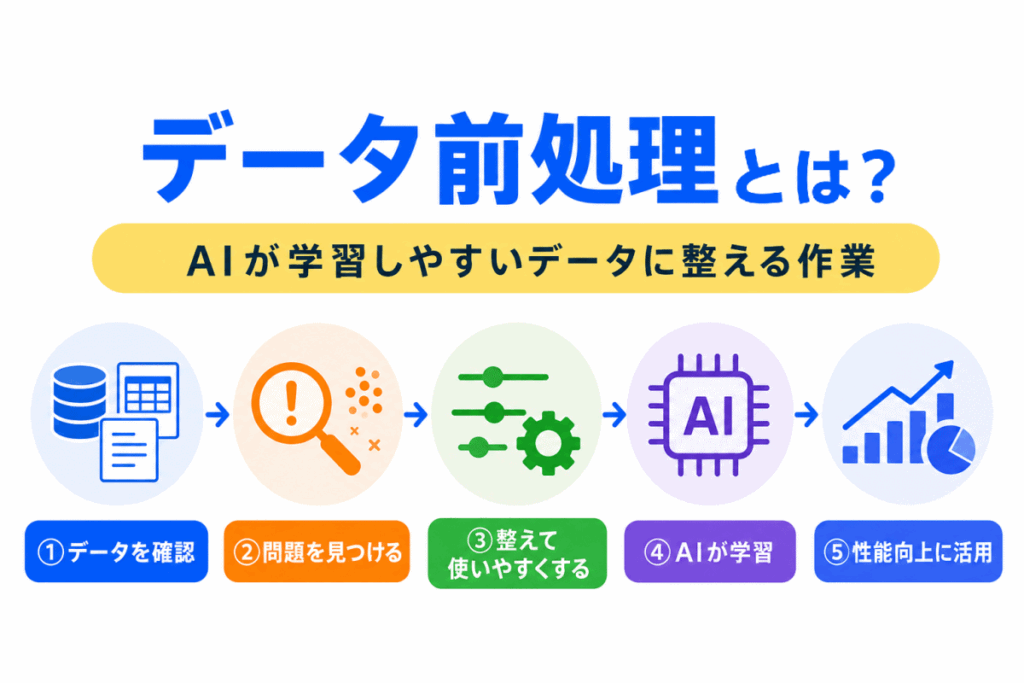
データ前処理とは、AIが学習しやすいように、データを整える作業です。
AI開発では、データを集めたあと、そのままモデルに入力するのではなく、欠損値、ノイズ、外れ値、表記ゆれ、データ形式の違いなどを確認し、必要に応じて修正します。
一言でいうと、データ前処理は次のように整理できます。
たとえば、次のようなデータは、そのままだとAIが学習しにくくなります。
つまり、データ前処理は、AIにデータを渡す前の準備作業です。
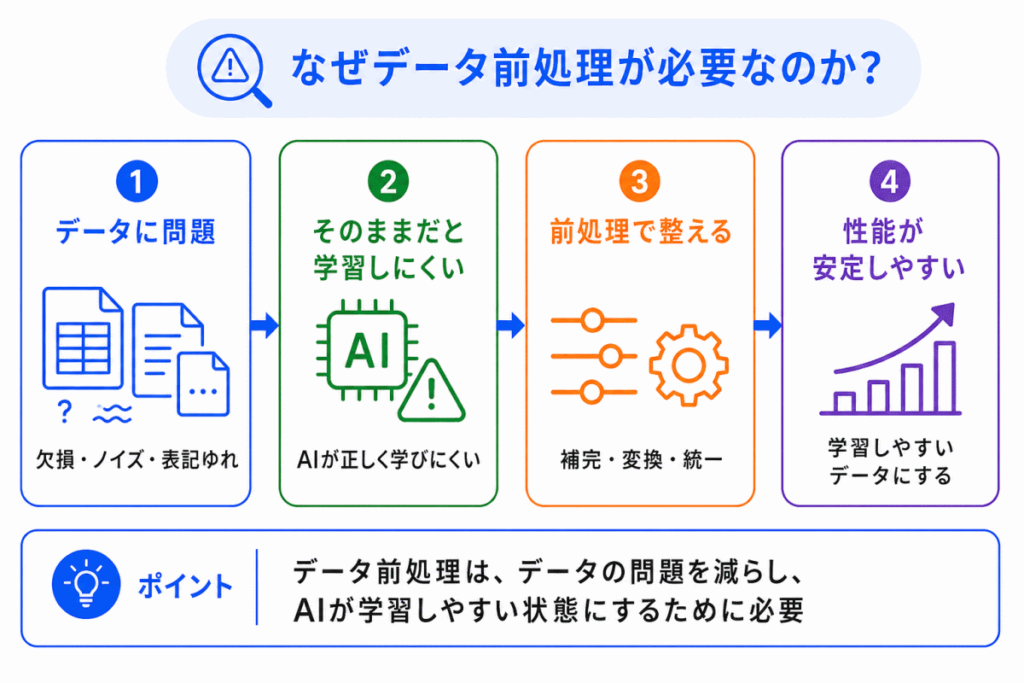
データ前処理が必要な理由は、AIの性能がデータの状態に大きく左右されるからです。
AIは与えられたデータからパターンを学びます。
そのため、データに問題が残っていると、AIは本来学ぶべき特徴ではなく、欠損、ノイズ、偏り、表記ゆれなどの影響を受けてしまうことがあります。
主な理由は次の通りです。
G検定では、データ前処理を「モデルを作る前にデータを整える工程」として押さえておくと理解しやすいです。
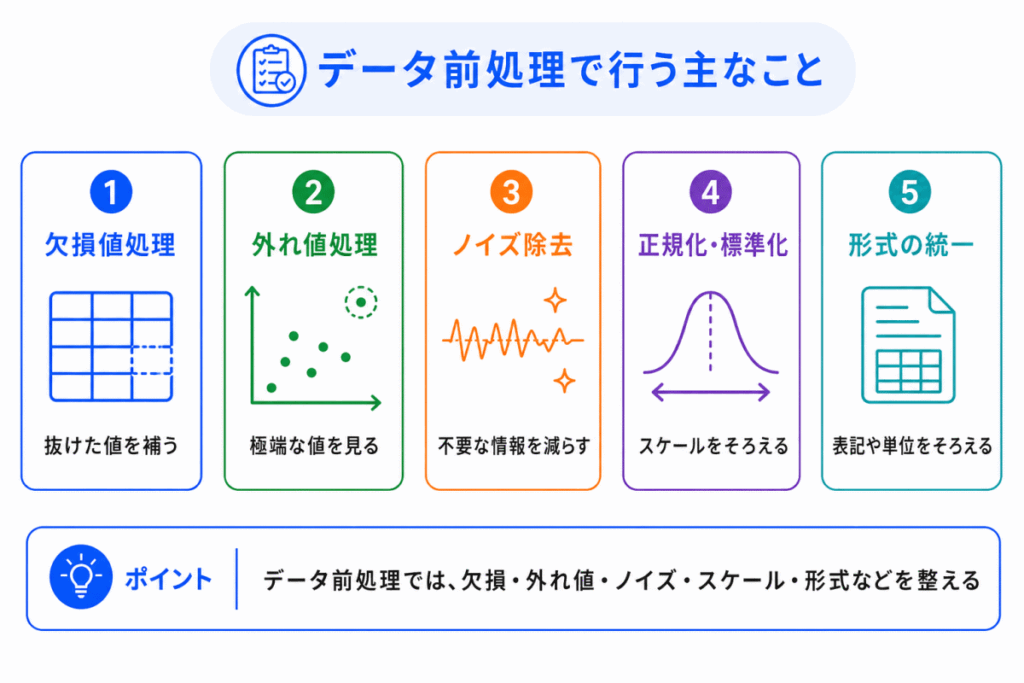
データ前処理では、データの種類や目的に応じて、さまざまな作業を行います。
すべてを細かく覚える必要はありませんが、G検定では「どのような問題を、どのように整えるのか」を大まかに理解しておくことが大切です。
主な作業は次のように整理できます。
たとえば、身長のデータが「170cm」、「1.70m」、「170センチ」のようにばらばらだと、コンピュータは同じ意味として扱いにくくなります。
このような表記をそろえることも、データ前処理の一部です。
データ品質とデータ前処理は、かなり近い関係にあります。
データ品質は、AIに使うデータが目的に合っていて信頼できるかを見る考え方です。一方、データ前処理は、そのデータをAIが学習しやすい状態に整える作業です。
関係は次のように整理できます。
つまり、データ品質で問題を見つけ、データ前処理で整えるイメージです。
G検定向けには、データ品質とデータ前処理を別々に暗記するよりも、「品質を確認し、問題があれば前処理で整える」とつなげて理解すると覚えやすくなります。
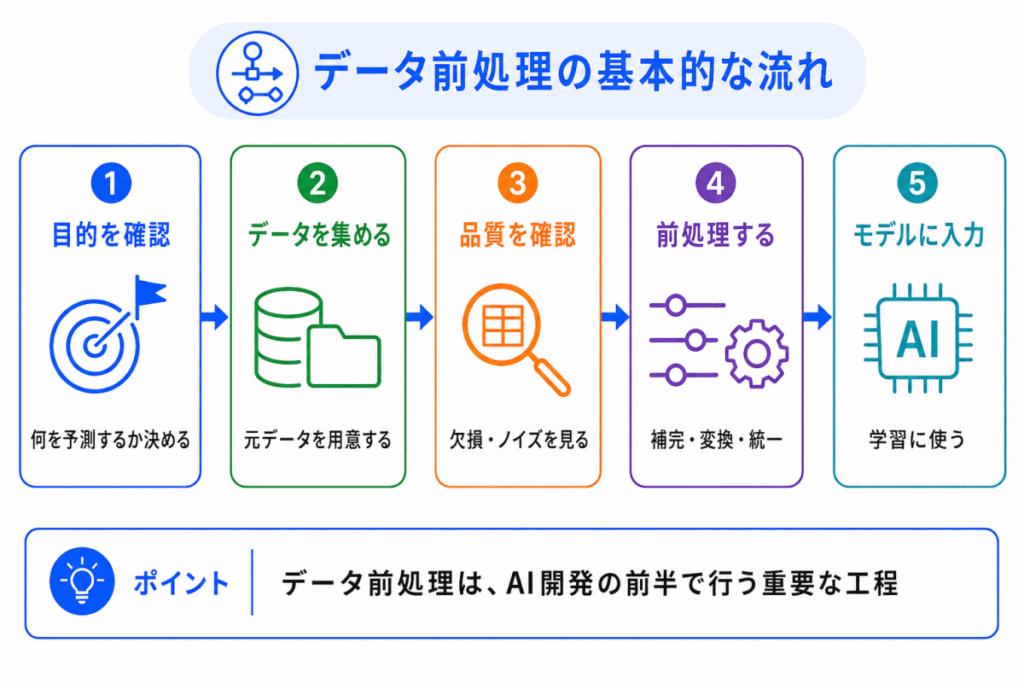
データ前処理は、AI開発の前半で行われる重要な工程です。
細かい手順はデータや目的によって変わりますが、基本的には次の流れで押さえると理解しやすいです。
重要なのは、前処理は「とりあえず機械的に行う作業」ではないということです。
何を予測したいのか、どのデータが必要なのか、どの問題を残すと危険なのかを考えながら行う必要があります。
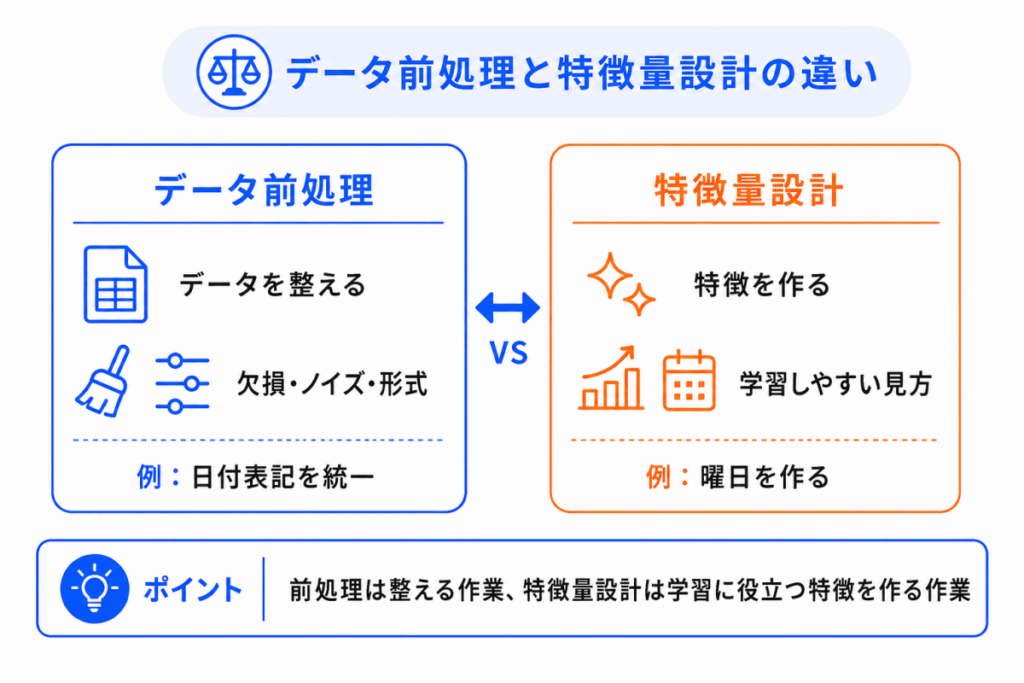
データ前処理と特徴量設計は、どちらもAIに使うデータを準備する作業なので混同しやすいです。
違いは次のように整理できます。
たとえば、日付データがある場合を考えます。
日付の表記を「2026/06/11」のようにそろえるのは、データ前処理です。
一方で、その日付から「曜日」、「月」、「祝日かどうか」などの新しい情報を作るのは、特徴量設計に近い作業です。
G検定では、この違いをざっくり押さえておくと十分です。
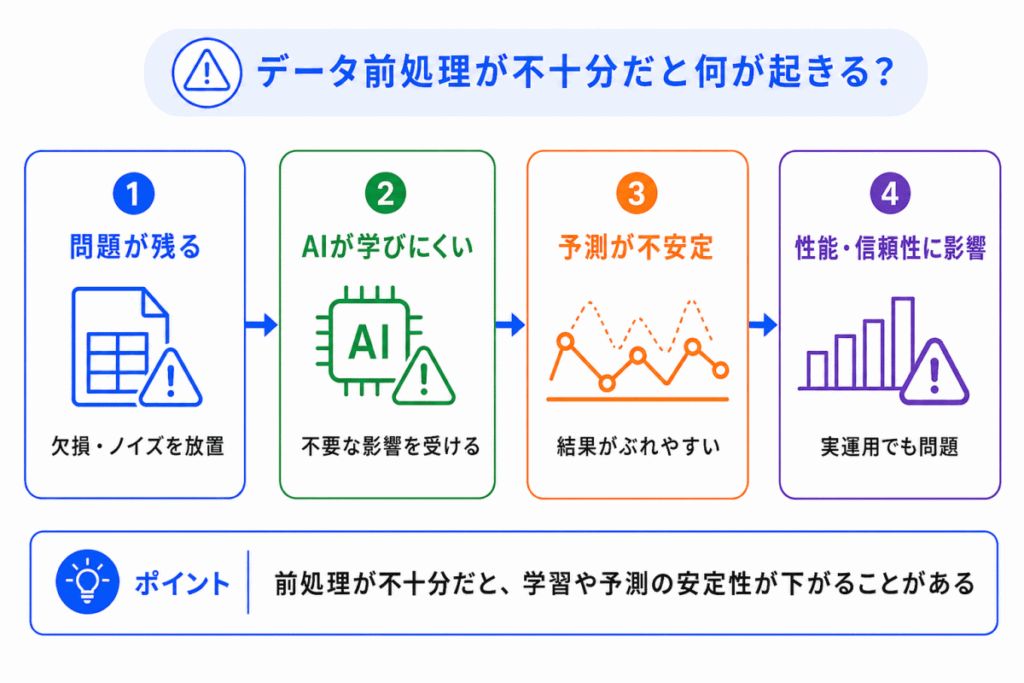
データ前処理が不十分だと、モデルの性能や安定性に影響することがあります。
前処理が不十分な場合に起きやすい問題は、次の表のように整理できます。
ただし、前処理をすれば必ず性能が上がるわけではありません。
必要以上にデータを削ったり、本来重要な情報まで消してしまったりすると、逆にAIが学ぶための情報が減ってしまうこともあります。
そのため、データ前処理では「何を残し、何を整えるか」を目的に合わせて考えることが大切です。
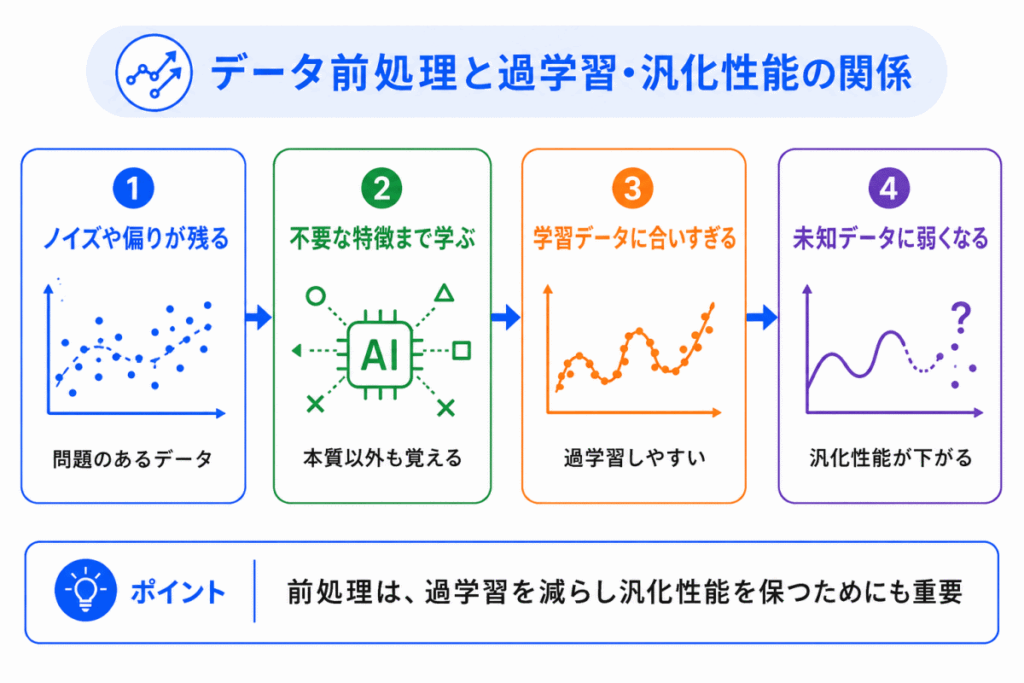
データ前処理は、過学習や汎化性能とも関係します。
過学習とは、学習データにはよく合っているのに、未知のデータには弱くなる状態です。
データにノイズや偏りが多いと、AIが本来の傾向ではなく、学習データだけに含まれる不要な特徴まで覚えてしまうことがあります。
G検定向けには、次のように押さえておくと理解しやすいです。
データ前処理は、こうした問題を減らし、AIがより一般的なパターンを学びやすくするためにも重要です。
ただし、過学習を防ぐ方法は前処理だけではありません。正則化、ドロップアウト、交差検証、データ拡張なども関係します。
G検定では、データ前処理そのものの細かい手順よりも、「なぜ必要なのか」、「何を整えるのか」、「AIの学習にどう影響するのか」が問われやすいです。
特に、次の表のように整理しておくと理解しやすいです。
暗記だけで覚えるよりも、次の流れで理解すると整理しやすくなります。
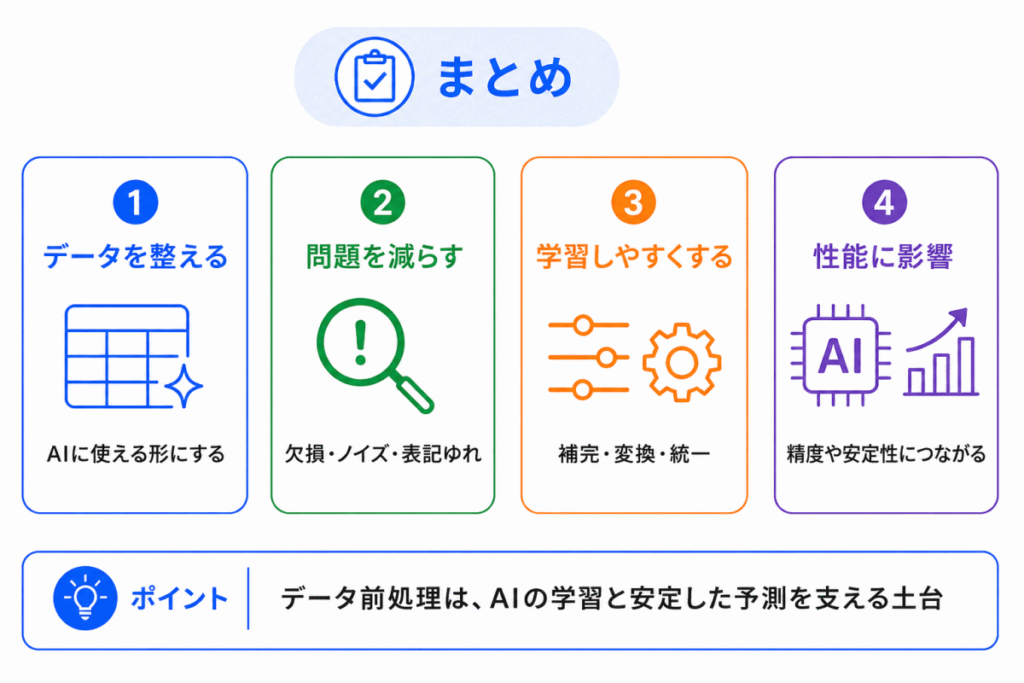
データ前処理は、AIが学習しやすいようにデータを整える作業です。
AIはデータから学ぶため、欠損値、ノイズ、外れ値、表記ゆれ、スケールの違いなどが残っていると、学習や予測に影響することがあります。
最後に、この記事のポイントを整理します。
データ前処理は、AI開発の中では地味に見えますが、モデルの性能や信頼性を支える重要な土台です。
「よいAIを作るには、よいデータが必要。そのために、データを整える作業がデータ前処理」と押さえておきましょう。
データ前処理は、データ品質の問題を整える作業です。先にデータの良し悪しを整理すると、前処理の必要性が理解しやすくなります。

アノテーションの質は、教師データの品質に影響します。正解ラベルを付ける作業から確認すると、データ準備の流れがつながります。
教師あり学習では、正解データを使ってAIを学習させます。前処理したデータがどのように使われるかを確認しておきましょう。
データにノイズや偏りがあると、AIが不要な特徴まで覚えることがあります。過学習との関係もあわせて整理しておくと理解しやすいです。
データの偏りは、AIの判断の偏りにもつながることがあります。公平性やAI倫理の観点からも確認しておきたいテーマです。

AI導入前の検証では、使うデータの質や前処理の必要性も確認します。PoCとの関係を押さえると、社会実装の流れが見えやすくなります。
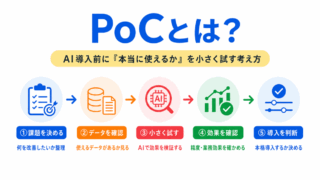
AIモデルは作って終わりではなく、運用後もデータの変化に対応する必要があります。MLOpsとつなげると、前処理の重要性がより理解しやすくなります。
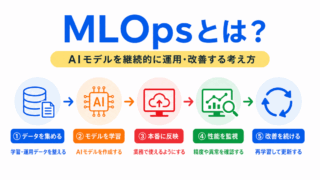
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認