【G検定対策】AIの社会実装に向けてまとめ|PoC・MLOps・データ品質・運用までつなげて理解する
seo-webmaster
G検定対策ブログ
このページにあるリンク(青字のリンク)はサイト内のリンクです。
G検定では、用語をただ暗記するだけでは対応しにくい問題が出ます。
理由は、AIの仕組み、機械学習、ディープラーニング、生成AI、社会実装、法律・倫理、数理・統計など、広い範囲の知識がつながって問われるためです。
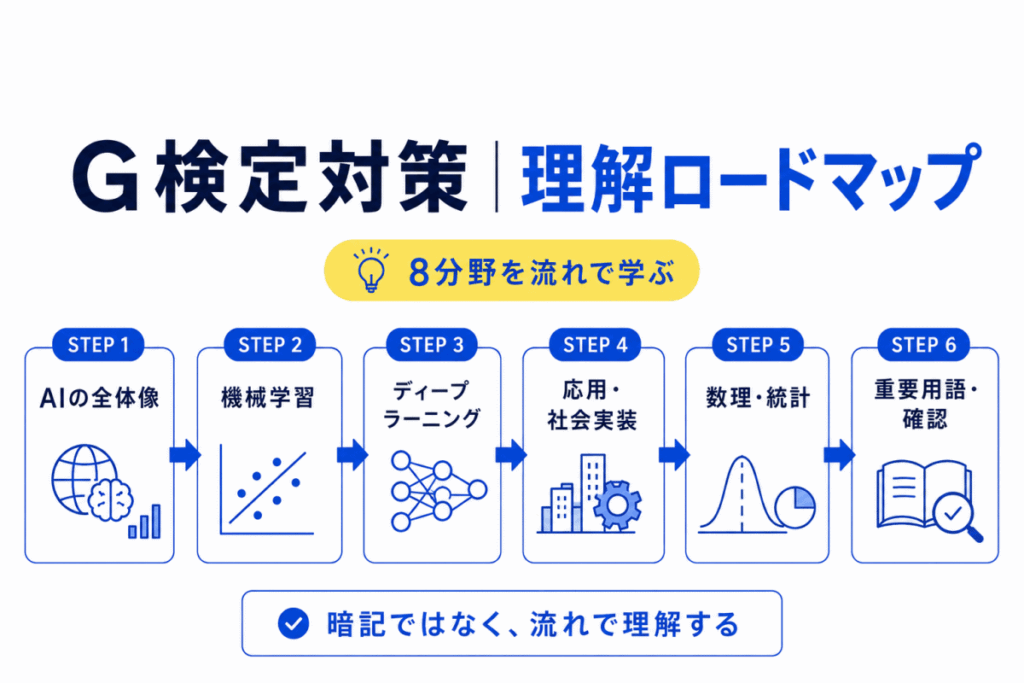
このページでは、G検定の学習を「何から読めばよいか?」という視点で整理します。
AIの学習をはじめたばかりの人は、最初から細かい用語を覚えるよりも、まず全体の流れをつかむことが大切です。
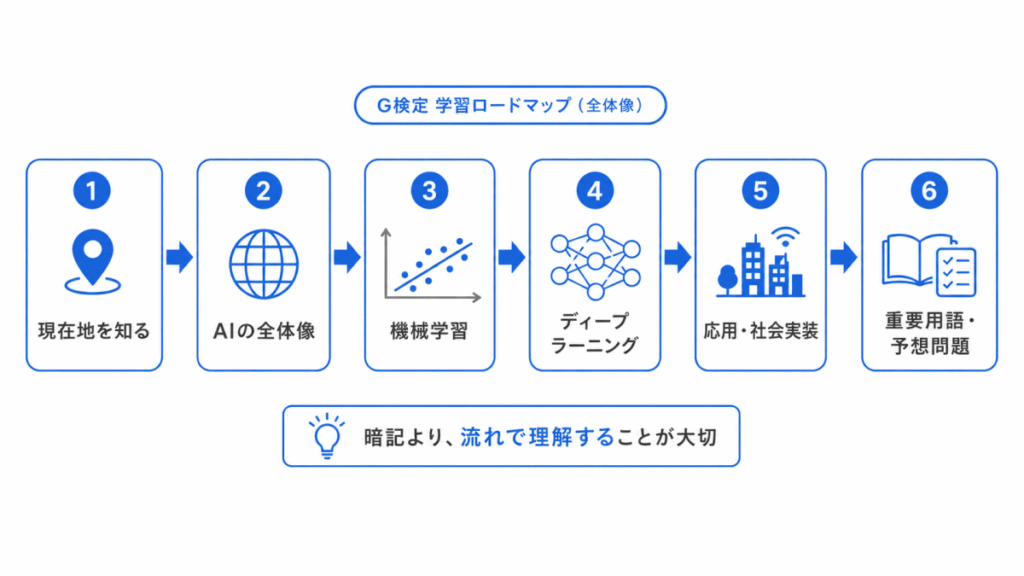
このロードマップでは
という順番で、G検定対策の記事を整理しています。
「何から読めばよいかわからない」、「用語がバラバラに感じる」、「試験前にどの記事を確認すべきか迷う」という方は、このページを入口にして学習を進めてみてください。
G検定の学習で大切なのは、最初から細かい用語を暗記しようとしすぎないことです。
もちろん用語の暗記も必要ですが、先に用語だけを詰め込むと
という状態になりやすいです。
そのため、G検定の学習では、まず「全体像」を見てから、個別の用語を理解していくのがおすすめです。
G検定対策では、次の順番で学ぶと知識がつながりやすくなります。
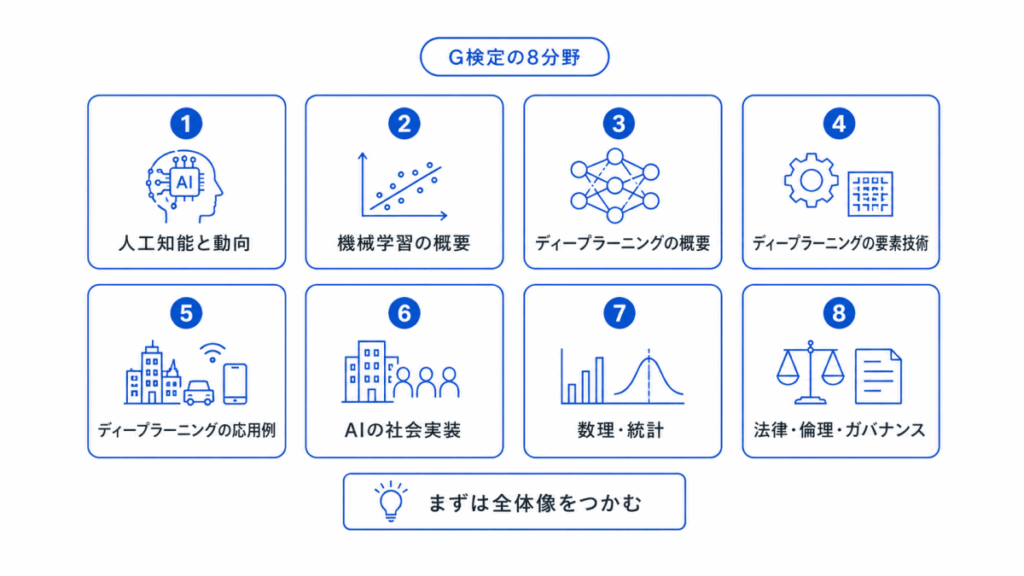
G検定は、AIの仕組みだけでなく、社会実装、法律、倫理、数理・統計まで幅広く問われます。
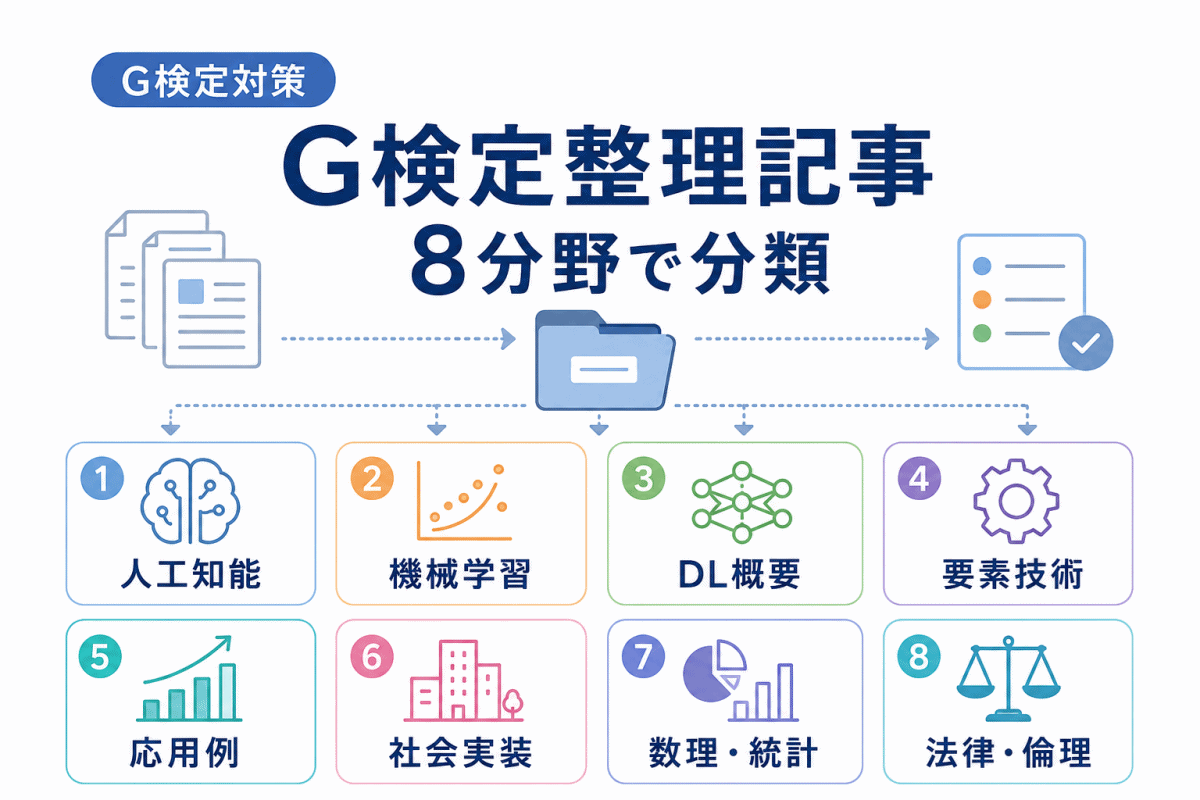
そのため、1つの記事だけで完璧に理解しようとするよりも、8分野ごとに入口記事を決めておくと学習しやすくなります。
G検定の学習範囲を大きく整理すると、次のようになります。
| 分野 | まず押さえること | おすすめ記事 |
|---|---|---|
| 人工知能とは・動向 | AIの定義、AIブーム、探索・推論、知識表現 | 人工知能とは・人工知能をめぐる動向まとめ |
| 機械学習の概要 | 教師あり学習、教師なし学習、強化学習、評価 | 機械学習の概要まとめ |
| ディープラーニングの概要 | ニューラルネットワーク、損失関数、最適化、過学習 | ディープラーニングの概要まとめ |
| ディープラーニングの要素技術 | CNN、RNN、Transformer、Attention、オートエンコーダ | ディープラーニングの要素技術まとめ |
| ディープラーニングの応用例 | 画像認識、自然言語処理、生成AI、マルチモーダル | ディープラーニングの応用例まとめ |
| AIの社会実装 | PoC、MLOps、データ品質、特徴量設計、運用 | AIの社会実装に向けてまとめ |
| 数理・統計 | 確率、統計、微分、ベクトル・行列、情報量 | AIに必要な数理・統計知識まとめ |
| 法律・倫理・ガバナンス | 個人情報、著作権、バイアス、XAI、AIガバナンス | AIに関する法律・契約・倫理・ガバナンスまとめ |
この8分野をすべて同じ深さで学ぼうとすると大変です。
まずは全体像をつかみ、苦手な分野を重点的に補う形で進めるのがおすすめです。
AIの学習をはじめたばかりの人は、いきなり細かい用語に入るよりも、次の順番で読むと理解しやすくなります。
| 順番 | 学ぶ内容 | 読む記事 |
|---|---|---|
| STEP0 | まず問題を解いて現在地を知る | 重要用語チェックシート、不合格体験談、合格体験談 |
| STEP1 | AI、機械学習、ディープラーニングの関係を知る | 機械学習とディープラーニングの違いをわかりやすく整理 |
| STEP2 | 教師あり学習、教師なし学習、強化学習を整理する | 教師あり学習・教師なし学習・強化学習の違いをわかりやすく整理 |
| STEP3 | ニューラルネットワークの学習の流れを理解する | ニューラルネットワークとは? |
| STEP4 | 損失関数、勾配降下法、学習率を理解する | 損失関数、勾配降下法、学習率 |
| STEP5 | 過学習、正則化、ドロップアウトを理解する | 過学習、正則化、ドロップアウト |
この順番で読むと、AIがどのように学習し、どこで失敗し、どのように改善し、どう評価されるのかが流れで理解しやすくなります。
G検定では、単語の意味だけでなく、似た用語の違いや、技術同士の関係が問われます。
そのため、1記事ずつバラバラに読むよりも、流れで読むことが大切です。
G検定の学習では、最初に少しだけ問題を解いてみるのがおすすめです。
理由は、自分がどこを理解できていて、どこを理解できていないのかを知るためです。
最初はほとんど解けなくても問題ありません。
むしろ、最初に問題を見ておくことで、
が見えやすくなります。
私自身も、1回目のG検定では「問題を覚えた = 理解した」と思い込んでしまい、不合格になりました。
その経験から、G検定では問題集をただ暗記するよりも、「なぜその選択肢が正しいのか?」、「他の選択肢と何が違うのか?」を理解することが重要だと感じています。
この段階でおすすめの記事は、次の通りです。
| 目的 | 読む記事 |
|---|---|
| G検定の失敗例を知る | 【不合格体験談】G検定に落ちた原因|「成功体験」と「過学習」が落とし穴 |
| 合格までの感覚を知る | 【合格体験談】G検定は本当に簡単なの!?1回落ちた失敗を踏まえた体験談 |
| 重要用語をざっと確認する | 【G検定対策】重要用語チェックシート |
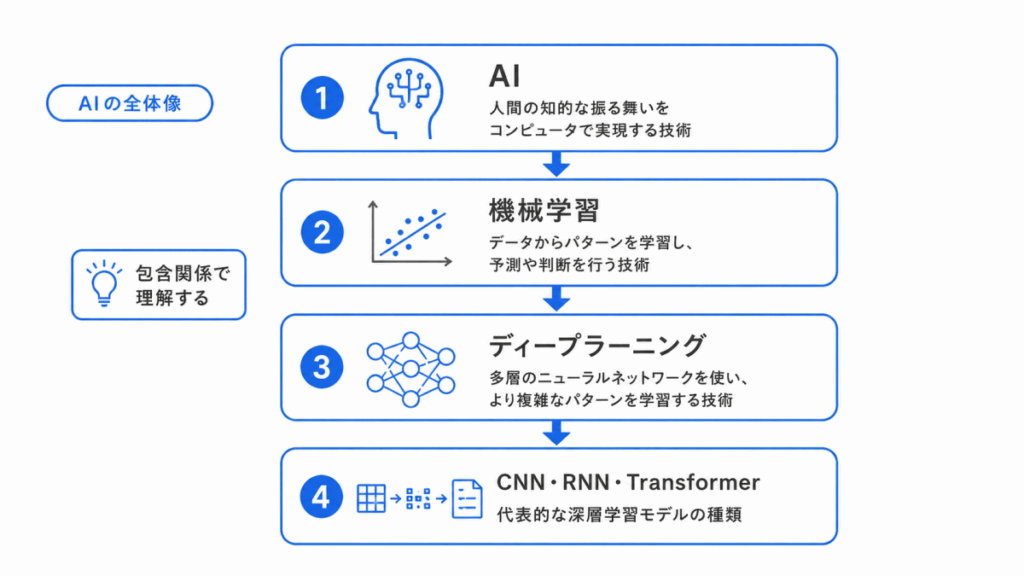
最初に押さえたいのは、AI、機械学習、ディープラーニングの関係です。
この関係が曖昧なままだと、あとから出てくる CNN、RNN、Transformer、生成AI、LLM などの位置づけがわかりにくくなります。
AIの全体像は、次のように整理すると理解しやすいです。
ここで重要なのは、AI、機械学習、ディープラーニングを別々のものとして覚えるのではなく、包含関係で理解することです。
この段階でおすすめの記事は、次の通りです。
| 学ぶ内容 | 読む記事 |
|---|---|
| AIの定義を知る | 【G検定対策】人工知能とは?|AIの定義・強いAI・弱いAIをわかりやすく整理 |
| AIの歴史を流れで知る | 【G検定対策】AIブームの歴史とは?|第一次・第二次・第三次AIブームを流れで整理 |
| 機械学習とディープラーニングの違いを知る | 【G検定対策】機械学習とディープラーニングの違いをわかりやすく整理|教師あり・教師なしも解説 |
| 学習方法の分類を知る | 【G検定対策】教師あり学習・教師なし学習・強化学習の違いをわかりやすく整理 |
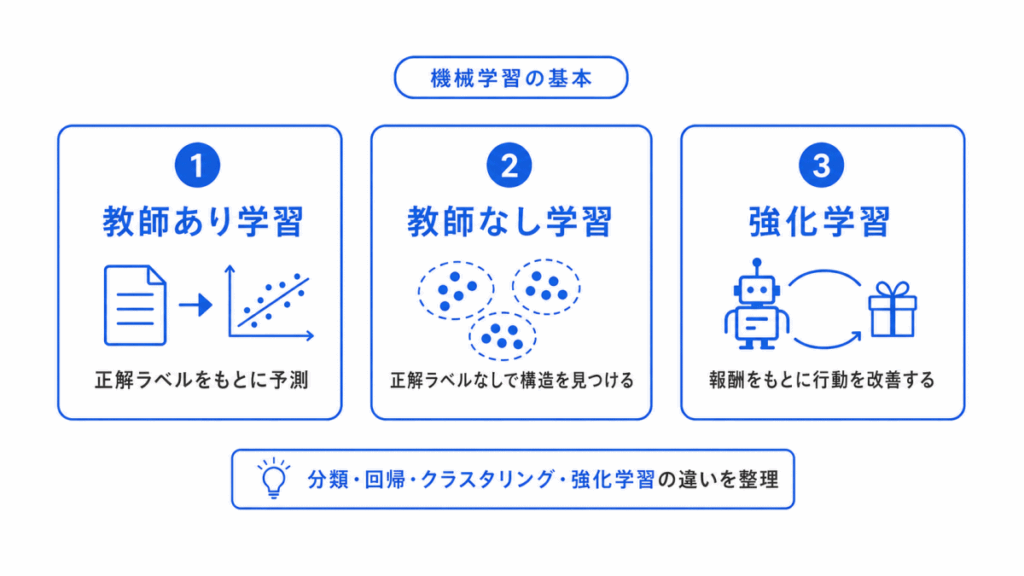
AIの全体像をつかんだら、次に機械学習の基本を整理します。
G検定では、教師あり学習、教師なし学習、強化学習の違いがよく問われます。
特に、分類、回帰、クラスタリング、強化学習の違いは混同しやすいポイントです。
| 学習方法 | 何をするか | 代表例 |
|---|---|---|
| 教師あり学習 | 正解ラベルをもとに予測する | 分類、回帰 |
| 教師なし学習 | 正解ラベルなしで構造を見つける | クラスタリング、次元削減 |
| 強化学習 | 報酬をもとに行動を改善する | ゲーム、ロボット制御 |
この段階でおすすめの記事は、次の通りです。
| 学ぶ内容 | 読む記事 |
|---|---|
| 機械学習の全体像 | 【G検定対策】機械学習の概要まとめ|教師あり・教師なし・強化学習をつなげて理解する |
| 教師あり学習の代表手法 | 【G検定対策】教師あり学習の代表的なアルゴリズムを整理 |
| 教師なし学習の代表手法 | 【G検定対策】教師なし学習の代表的な手法を整理 |
| 強化学習 | 【G検定対策】強化学習とは?|報酬をもとに行動を改善する考え方を整理 |
| 分類手法 | 【G検定対策】SVMとは?|境界線とマージンでデータを分ける分類手法をわかりやすく整理 |
| 木構造の手法 | 【G検定対策】決定木・ランダムフォレストとは?|木構造で判断し、複数の木で予測を安定させる考え方を整理 |
| クラスタリング | 【G検定対策】クラスタリングとは?|教師なし学習で似たデータをグループに分ける考え方を整理 |
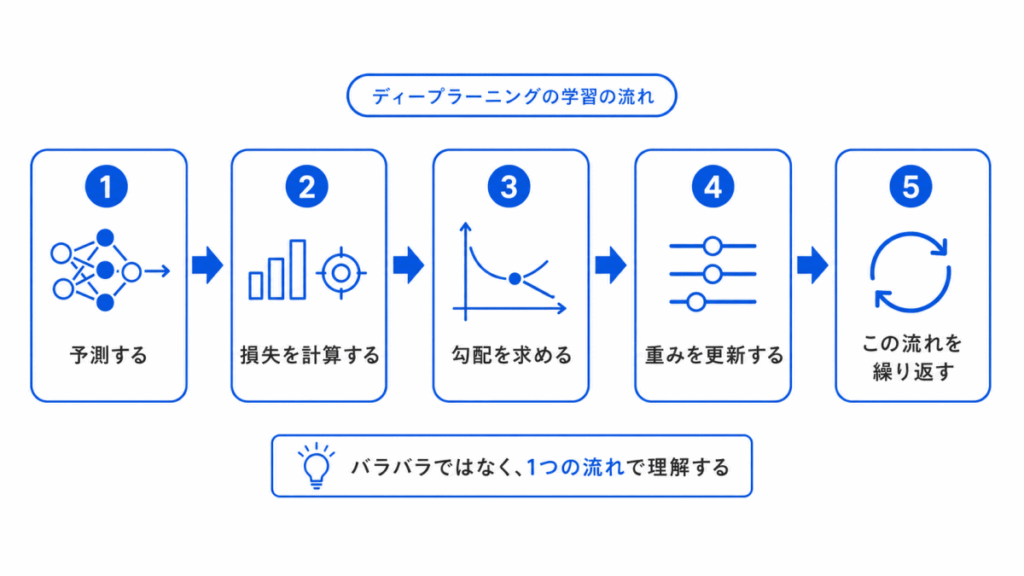
機械学習の基本を理解したら、次にディープラーニングの学習の流れを整理します。
ディープラーニングは、ニューラルネットワークを使って、データから特徴を学習する仕組みです。
ここでは、損失関数、勾配降下法、学習率、誤差逆伝播法、最適化手法などがつながって出てきます。
この流れを理解すると、損失関数、勾配降下法、学習率、SGD、ミニバッチ、Adam がバラバラの用語ではなく、1つの学習プロセスとして見えてきます。
この段階でおすすめの記事は、次の通りです。
| 学ぶ内容 | 読む記事 |
|---|---|
| ニューラルネットワーク | 【G検定対策】ニューラルネットワークとは? |
| 重み | 【G検定対策】重みとは?|AIが「どこを重要視するか?」を決める仕組みをわかりやすく整理 |
| 損失関数 | 【G検定対策】損失関数とは?わかりやすく整理 |
| 勾配降下法 | 【G検定対策】勾配降下法とは?わかりやすく整理 |
| 学習率 | 【G検定対策】学習率とは?わかりやすく整理 |
| SGD・ミニバッチ・Adam | SGD、ミニバッチ、Adam |
| 誤差逆伝播法 | 【G検定対策】誤差逆伝播法とは?AIの反省会… |
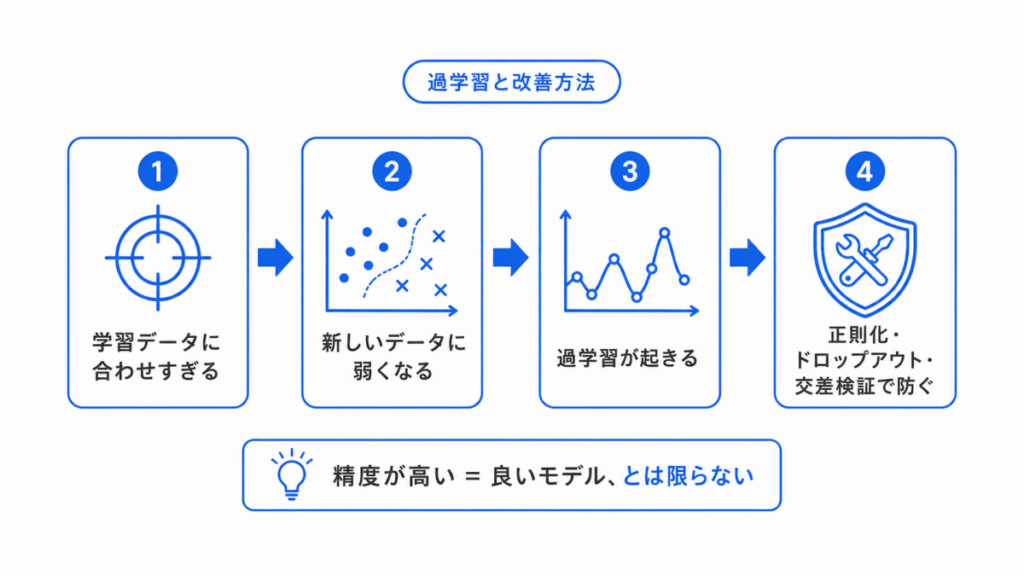
AIモデルは、学習データにうまく合わせるだけでは不十分です。
学習データでは高い精度が出ても、新しいデータでうまく予測できない場合があります。
この状態が、過学習 です。
G検定では、過学習、正則化、ドロップアウト、バイアスと分散、交差検証などの関係を理解しておくことが大切です。
この段階でおすすめの記事は、次の通りです。
| 学ぶ内容 | 読む記事 |
|---|---|
| 過学習 | 【G検定対策】過学習とは?わかりやすく整理 |
| 正則化 | 【G検定対策】正則化とは?わかりやすく整理 |
| ドロップアウト | 【G検定対策】ドロップアウト(Dropout)とは?わかりやすく整理 |
| バイアスと分散 | 【G検定対策】バイアスと分散とは?過学習・未学習の原因をわかりやすく整理 |
| 交差検証 | 【G検定対策】交差検証(クロスバリデーション)とは?わかりやすく整理 |
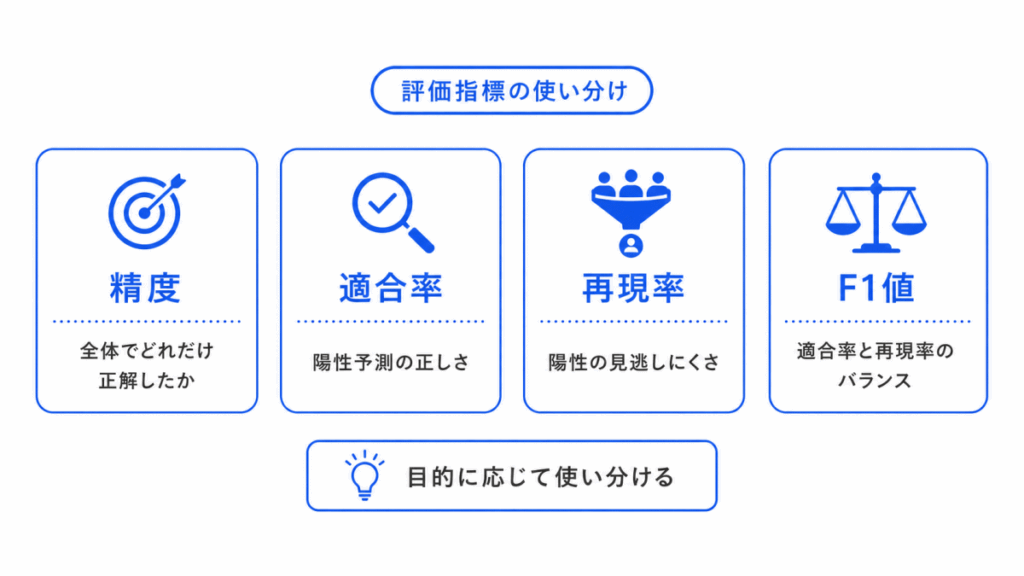
モデルを作ったら、最後に評価が必要です。
ただし、評価指標は1つだけ覚えればよいわけではありません。
分類問題では、精度、適合率、再現率、F1値などが使われます。
ここで大切なのは、「どの指標が一番良いか」ではなく、「目的によって使い分ける」という考え方です。
| 指標 | 見ること | 注意点 |
|---|---|---|
| 精度 | 全体のうち正しく予測できた割合 | データの偏りに弱い場合がある |
| 適合率 | 陽性と予測した中で本当に陽性だった割合 | 誤検出を減らしたいときに重要 |
| 再現率 | 本当の陽性をどれだけ見つけられたか | 見逃しを減らしたいときに重要 |
| F1値 | 適合率と再現率のバランス | 片方だけ高い状態を避けたいときに使う |
この段階でおすすめの記事は、次の通りです。
| 学ぶ内容 | 読む記事 |
|---|---|
| 評価指標の基本 | 【G検定対策】精度・再現率・適合率とは?わかりやすく整理 |
| 評価指標の使い分け | 【G検定対策】評価指標の使い分け方は?わかりやすく整理 |
| 損失関数との違い | 【G検定|理解型予想問題】損失関数と評価指標はなぜ混同する? |
| 適合率と再現率の違い | 【G検定|理解型予想問題】適合率と再現率はなぜ混同する? |
ここからは、G検定の8分野ごとに、読む順番を整理します。
苦手な分野がある場合は、該当する分野から読み進めてください。
この分野では、AIの定義、AIブームの歴史、探索・推論、知識表現、エキスパートシステム、AIの限界と議論などを整理します。
単語だけを見ると古典的な内容に見えるかもしれませんが、G検定では今のAIと昔のAIの違いを理解するうえで重要です。
おすすめの読む順番は、次の通りです。
この分野でおすすめの記事は、次の通りです。
この分野では、教師あり学習、教師なし学習、強化学習、代表的なアルゴリズム、評価方法を整理します。
G検定の土台になる分野なので、最初にしっかり理解しておきたいところです。
特に、分類、回帰、クラスタリング、強化学習の違いは重要です。
おすすめの記事は、次の通りです。
この分野では、ニューラルネットワーク、損失関数、活性化関数、誤差逆伝播法、最適化手法、正則化などを整理します。
用語が多く見えますが、中心にある流れはシンプルです。
おすすめの記事は、次の通りです。
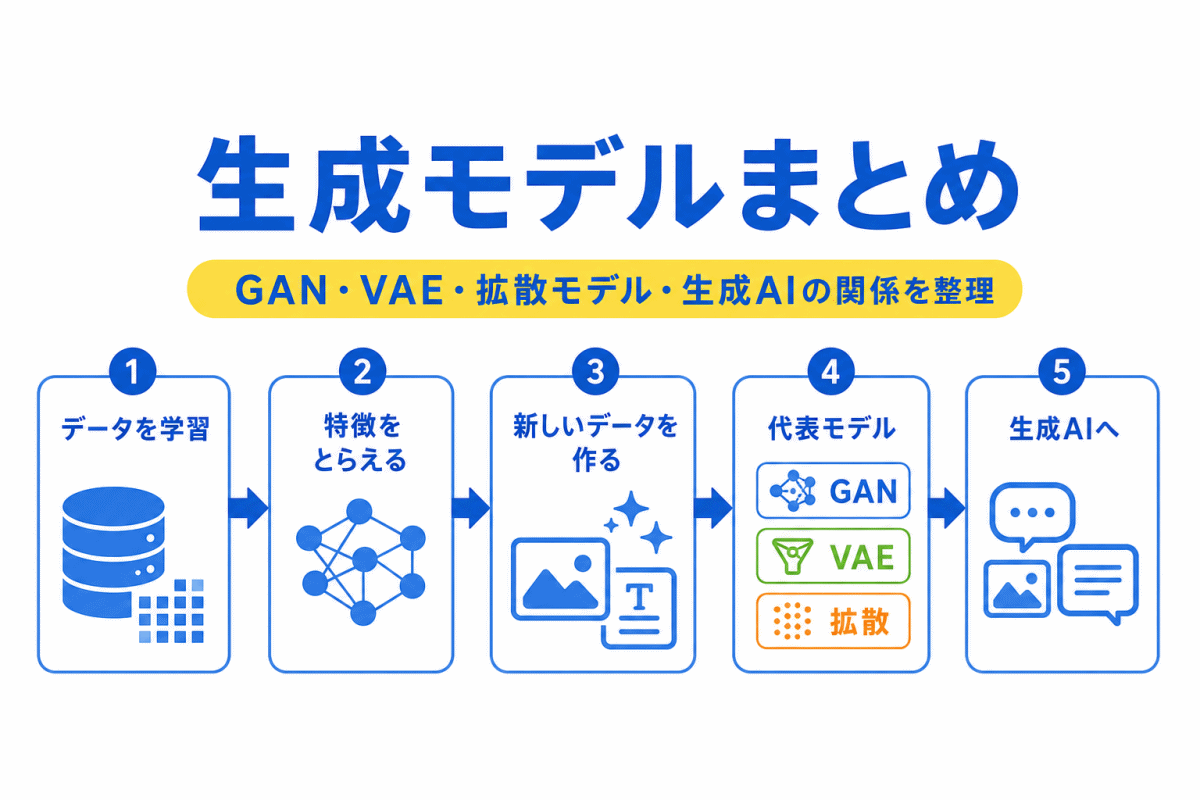
この分野では、CNN、RNN、Transformer、Attention、オートエンコーダ、GAN、VAEなどを整理します。
それぞれの技術を別々に暗記するよりも、「何が得意なのか」で整理すると理解しやすくなります。
| 技術 | 得意なこと | 関連する記事 |
|---|---|---|
| CNN | 画像の特徴を取り出す | CNNの畳み込み・プーリング |
| RNN・LSTM・GRU | 時系列や順番のあるデータを扱う | LSTM・GRU |
| Transformer | Attentionを使って重要な情報に注目する | Transformer、Attention |
| オートエンコーダ | 入力を圧縮して復元する | オートエンコーダ、VAE |
| GAN | 生成器と識別器を競わせる | GAN、生成モデルまとめ |
おすすめの記事は、次の通りです。
この分野では、画像認識、自然言語処理、生成AI、マルチモーダルAIなどを整理します。
応用例は、単に技術名を覚えるのではなく、「何に使われる技術なのか?」を意識すると理解しやすくなります。
おすすめの記事は、次の通りです。
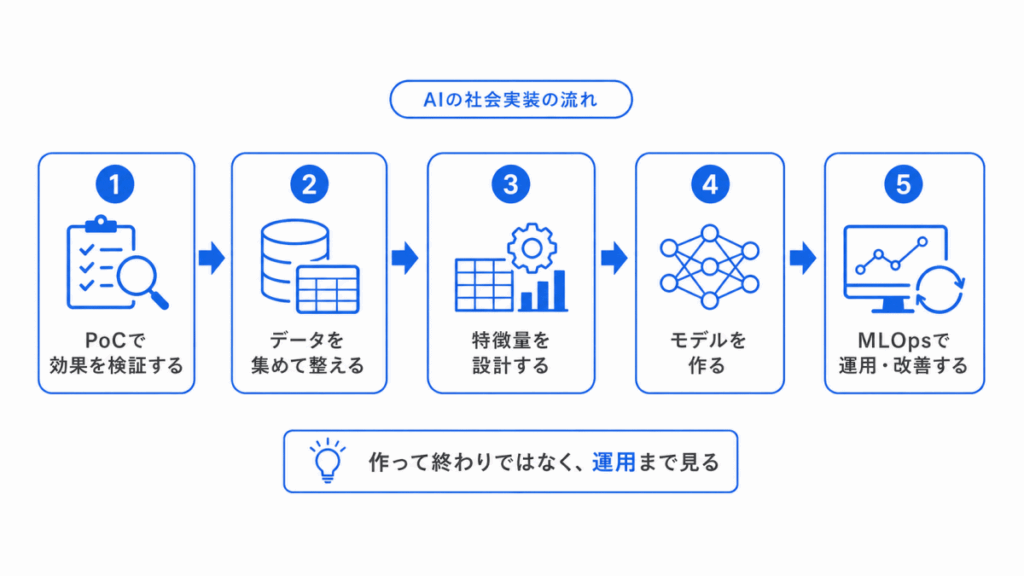
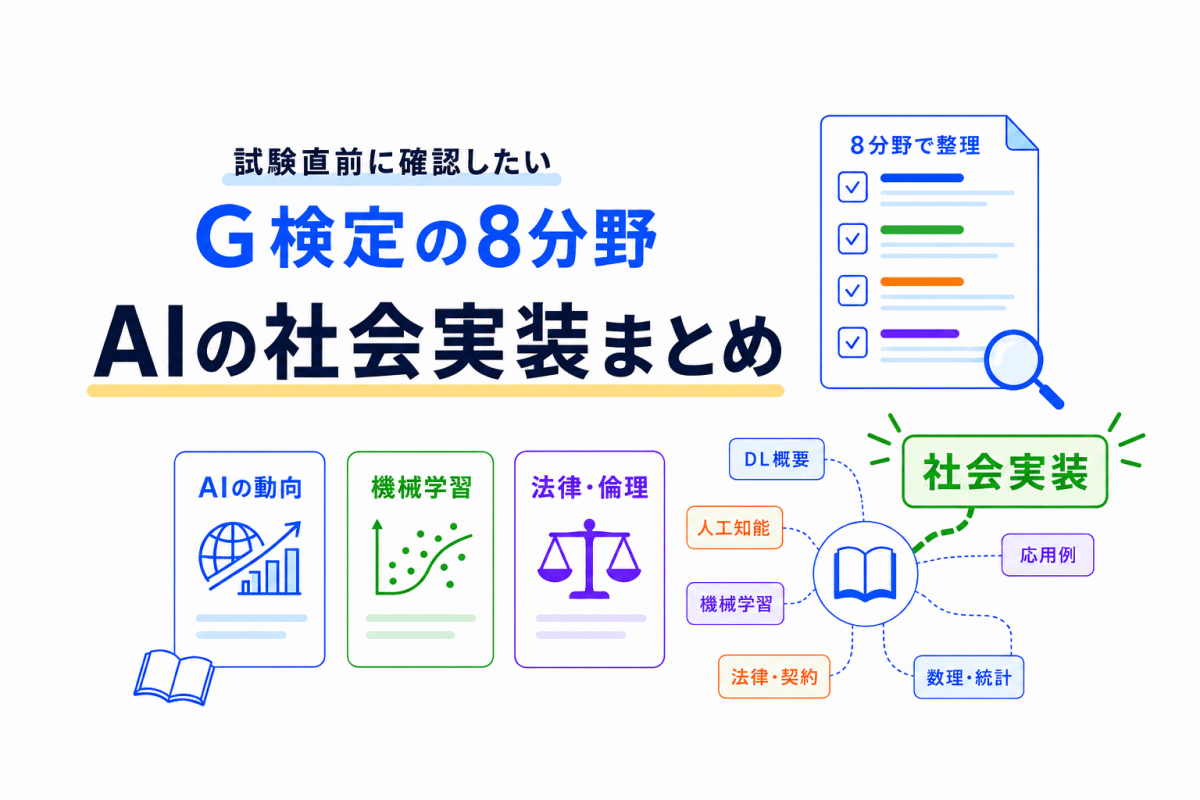
この分野では、AIを作るだけでなく、実際に使える形にするための知識を整理します。
PoC、MLOps、データ品質、データ前処理、特徴量設計、データリーケージなどは、AI開発の流れで理解するとつながりやすくなります。
おすすめの記事は、次の通りです。
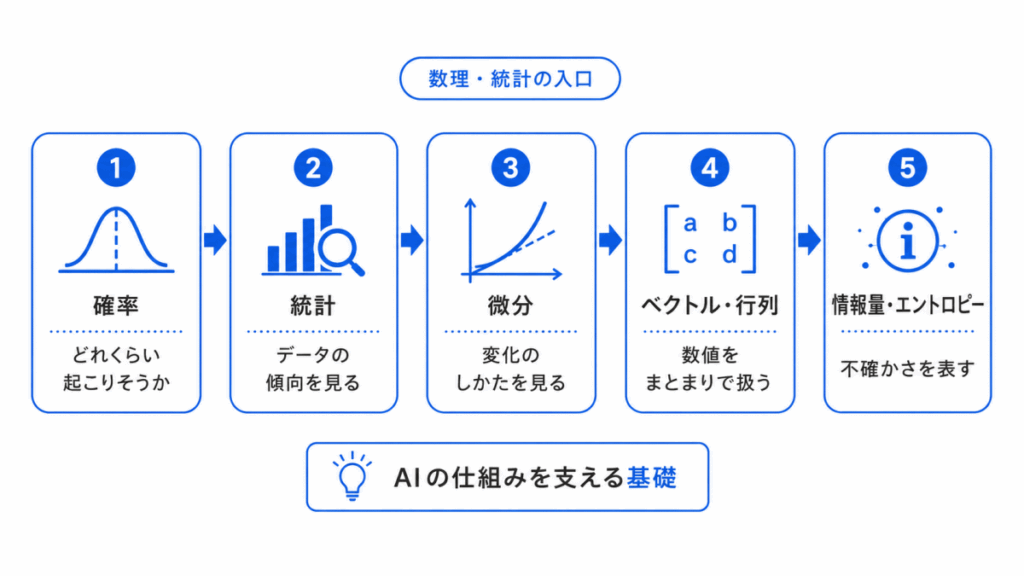
数理・統計は苦手意識を持ちやすい分野です。
ただし、G検定対策では、いきなり難しい計算を完璧にするよりも、「AIのどこで使われる考え方なのか」を理解することが大切です。
| 用語 | ざっくりした意味 | AIとの関係 |
|---|---|---|
| 確率 | どれくらい起こりそうか | 分類や予測の不確かさに関係する |
| 統計 | データの傾向を見る | データ理解や評価に関係する |
| 微分 | 少し変えたときの変化を見る | 勾配降下法に関係する |
| ベクトル・行列 | 数値をまとまりとして扱う | データや重みの表現に関係する |
| 情報量・エントロピー | 不確かさを表す | 分類や決定木の考え方に関係する |
おすすめの記事は、次の通りです。
法律・倫理・ガバナンスは、生成AI時代のG検定で特に重要になっている分野です。
技術用語とは違い、個人情報、著作権、バイアス、説明可能性、ガバナンスなど、社会との関係で理解する必要があります。
| テーマ | 重要な考え方 | 関連する記事 |
|---|---|---|
| 個人情報 | AIが扱うデータとプライバシー | 個人情報保護とAI |
| 著作権 | 学習データや生成物の権利 | 著作権と生成AI |
| バイアス | AIの不公平な判断 | アルゴリズムバイアス |
| XAI | 判断理由を説明できること | 説明可能AI |
| AIガバナンス | 安全に使うためのルール作り | AIガバナンス |
おすすめの記事は、次の通りです。
ここからは、読者の状態に合わせて、どの記事から読むべきかを整理します。
すべての記事を上から順番に読む時間がない場合は、目的別に読む記事を選んでください。
| 読者の状態 | 最初に読む記事 | 次に読む記事 |
|---|---|---|
| AIの学習をはじめたばかり | AIはどうやって学習する? | 機械学習とディープラーニングの違い |
| 用語がバラバラに感じる | 重要用語まとめ8分野 | G検定整理記事を8分野で分類 |
| 機械学習が苦手 | 機械学習の概要まとめ | 教師あり学習・教師なし学習・強化学習の違い |
| ディープラーニングが苦手 | ディープラーニングの概要まとめ | ニューラルネットワーク、損失関数、勾配降下法 |
| 生成AIが苦手 | 生成AIの仕組み | GPT、LLM、RAG、RLHF、アライメント |
| 数理・統計が苦手 | AIに必要な数理・統計知識まとめ | 微分、ベクトル・行列、確率分布 |
| 法律・倫理が苦手 | AIに関する法律・倫理まとめ | 個人情報、著作権、XAI、AIガバナンス |
| 試験直前 | 重要用語チェックシート | 重要用語チェックシート |
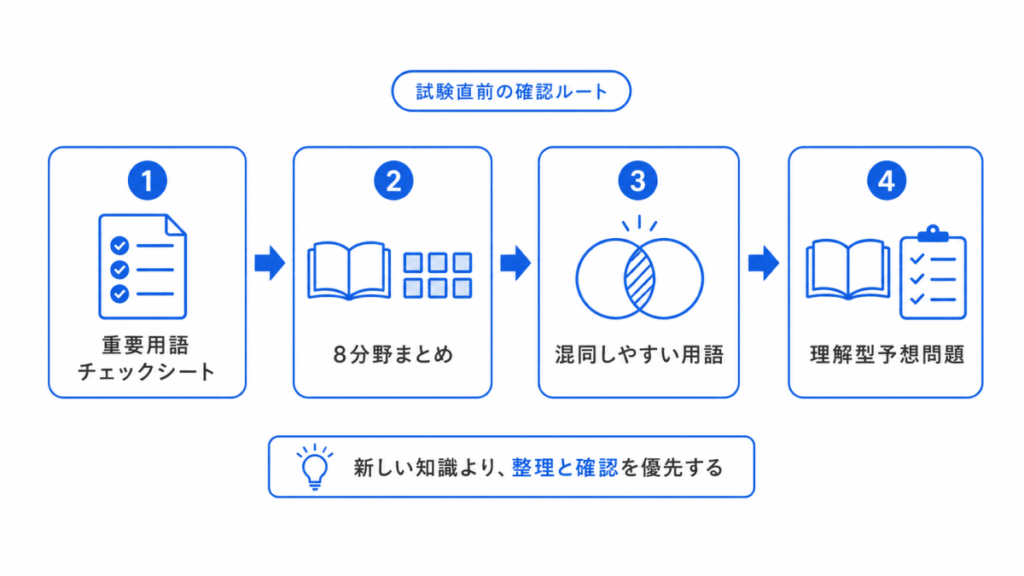
試験直前は、新しい知識を大量に増やすよりも、混同しやすい用語を整理することが大切です。
特に、G検定では似た用語の違いを問われることがあります。
直前期は、次の記事を優先して確認するのがおすすめです。
| 確認したい内容 | おすすめ記事 |
|---|---|
| 全体の重要用語 | 【G検定対策】重要用語チェックシート |
| 8分野の整理 | 【G検定対策】重要用語まとめ8分野|試験前に確認したいAI用語を体系的に整理 |
| 分野別の記事一覧 | 【G検定対策】G検定整理記事を8分野で分類|苦手分野から学べる記事一覧 |
| AI学習の流れ | 【G検定|理解型予想問題】AI学習の流れ |
| 教師あり・教師なし・強化学習 | 【G検定|理解型予想問題】教師あり学習・教師なし学習・強化学習はなぜ混同する? |
| 損失関数・勾配降下法・学習率 | 【G検定|理解型予想問題】損失関数・勾配降下法・学習率 |
| CNN・RNN・Transformer | 【G検定|理解型予想問題】CNN・RNN・Transformer |
| 生成AIの仕組み | 【G検定|理解型予想問題】生成AIの仕組み|事前学習・ファインチューニング・RLHF・RAG・アライメントはなぜ混同する? |
| 法律・倫理・ガバナンス | 【G検定|理解型予想問題】AI倫理・法律・ガバナンス|生成AIリスクはなぜ混同する? |
G検定では、似た用語の違いを理解しているかが重要です。
特に、次の用語は混同しやすいため、セットで整理しておくのがおすすめです。
| 混同しやすい用語 | 整理のポイント | おすすめ記事 |
|---|---|---|
| 損失関数と評価指標 | 学習中に使うものか、性能確認に使うものか | 損失関数と評価指標はなぜ混同する? |
| 適合率と再現率 | 誤検出を減らすか、見逃しを減らすか | 適合率と再現率はなぜ混同する? |
| 教師あり学習と教師なし学習 | 正解ラベルがあるかどうか | 教師あり学習・教師なし学習・強化学習はなぜ混同する? |
| 正則化と正規化 | 過学習対策か、データのスケール調整か | 正則化、正規化・標準化 |
| CNN・RNN・Transformer | 画像、順番、重要な部分への注目 | CNN・RNN・Transformerの違い |
| GPTとBERT | 生成が得意か、文脈理解が得意か | BERTとは?|GPTとの違いからわかりやすく整理 |
| RAG・ファインチューニング・RLHF | 外部情報を使うか、モデルを調整するか、人間の評価を使うか | 生成AIの仕組み、RAG、RLHF |
| 個人情報・著作権・バイアス | 守る対象や問題の種類が違う | 生成AIリスクまとめ |
G検定は、用語をたくさん覚える試験に見えます。
しかし、実際には、用語同士の関係や、技術が使われる理由を理解しているかが重要です。
そのため、最初から細かい暗記に入るよりも
という順番で学ぶのがおすすめです。
このサイトでは、G検定の用語をただ暗記するのではなく、「なぜ必要なのか?」、「他の用語と何が違うのか?」、「AI開発の流れのどこで使われるのか?」を重視して整理しています。
試験直前の方は、まず重要用語チェックシートと理解型予想問題を確認してください。
これから学習を始める方は、このロードマップを入口にして、AIの全体像から順番に学んでいくのがおすすめです。
G検定の学習範囲を8分野で整理したい方は、こちらの記事もおすすめです。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認