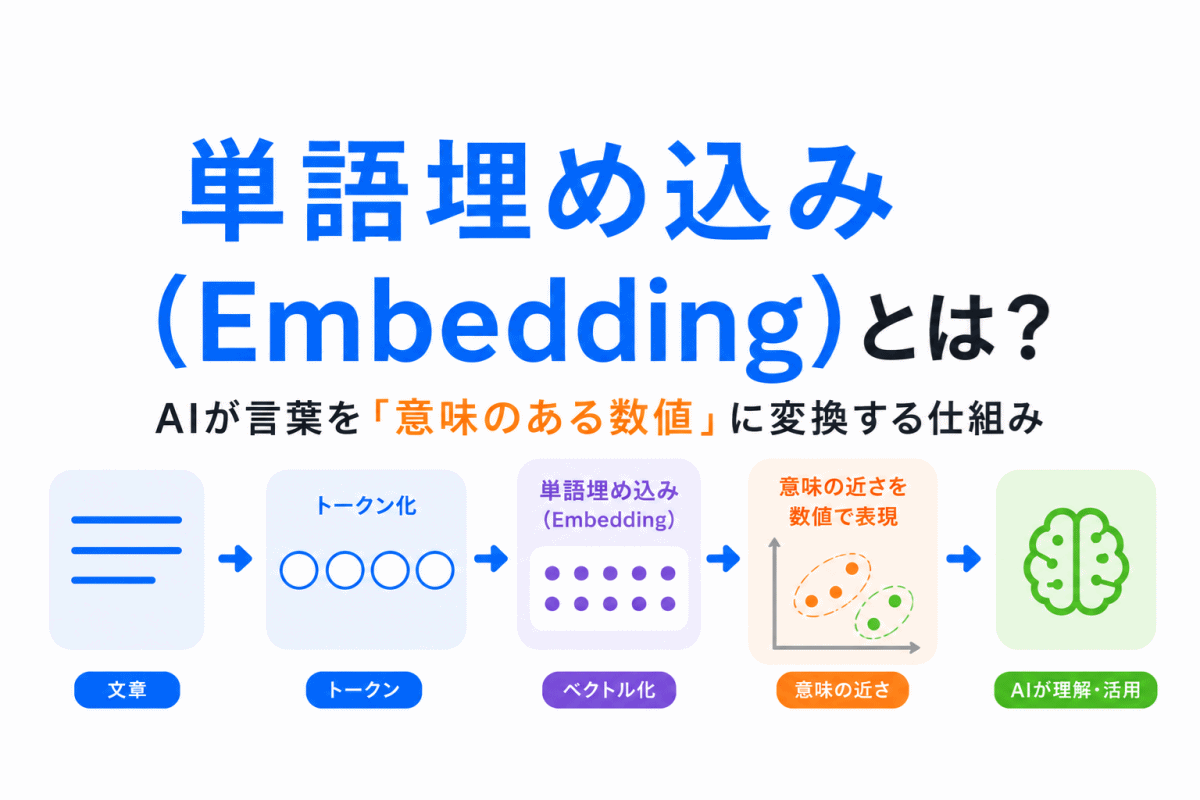
【G検定対策】単語埋め込み(Embedding)とは?
seo-webmaster
SEO・ウェブマスターブログ
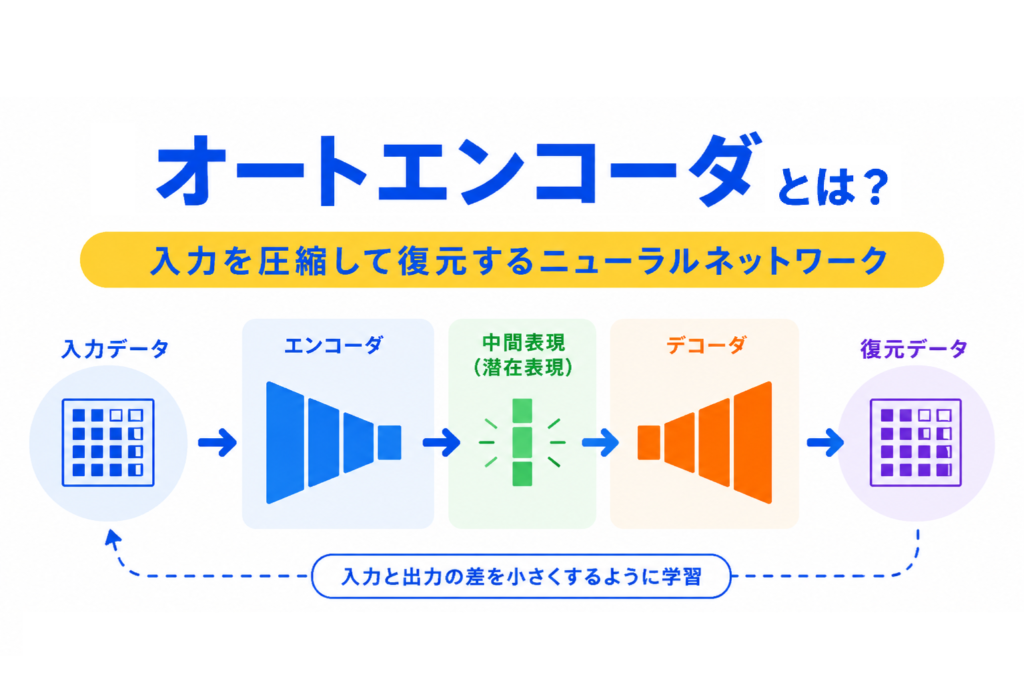
オートエンコーダとは、入力データを一度小さな表現に圧縮し、そこから元のデータを復元するニューラルネットワークです。
分類のように正解ラベルを当てるのではなく、入力と出力をできるだけ近づけることで、データの特徴を学習します。
G検定では、エンコーダ、デコーダ、潜在表現、次元削減、特徴抽出、異常検知、VAEとの関係を押さえておくと理解しやすくなります。
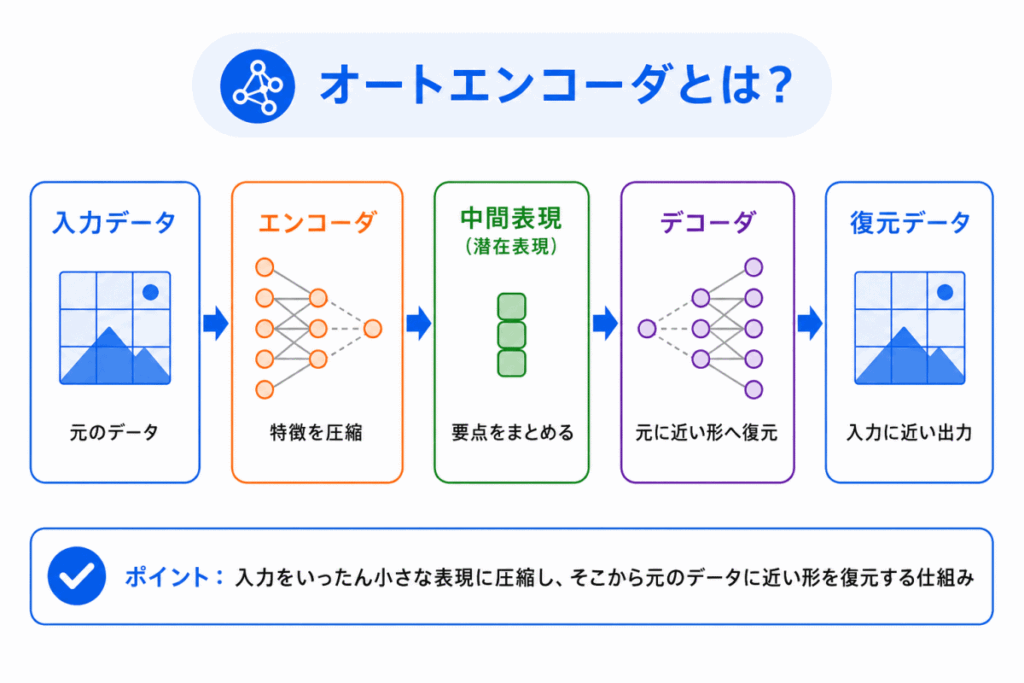
オートエンコーダとは、入力データを圧縮してから復元するニューラルネットワーク です。
英語では Autoencoder と呼ばれます。
名前だけ見ると難しく感じますが、考え方はシンプルです。
入力されたデータをそのまま覚えるのではなく、いったん重要な特徴だけに絞ります。
そのうえで、絞った情報から元のデータを再現しようとします。
流れで見ると、次のようになります。
ポイントは、入力と出力を近づけるように学習する ことです。
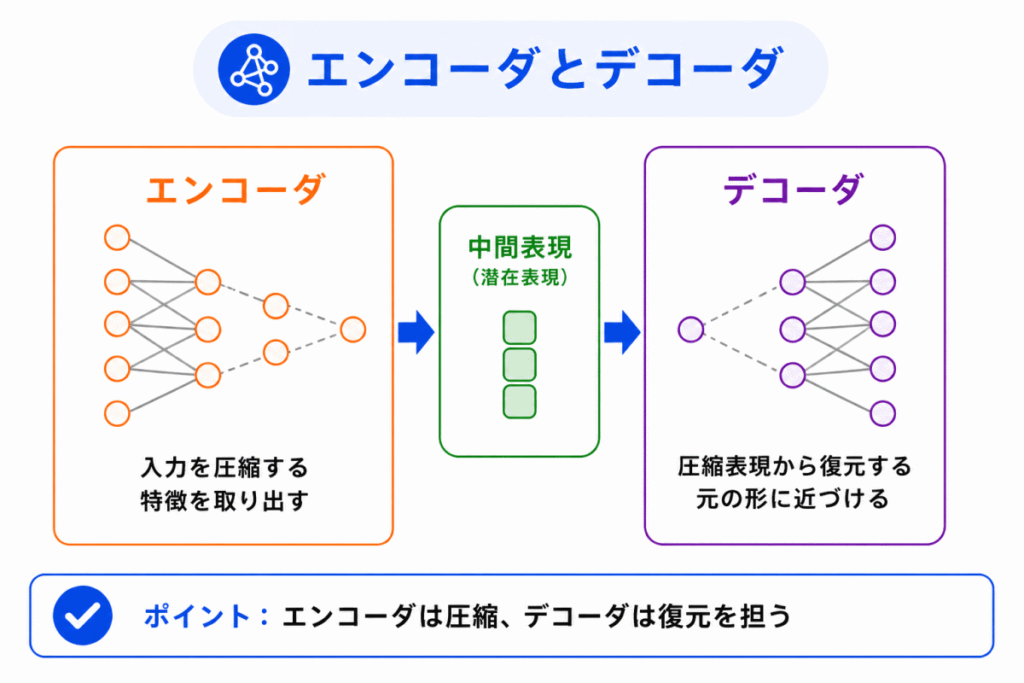
オートエンコーダは、主に エンコーダ と デコーダ で構成されます。
役割は次のように整理できます。
| 部分 | 役割 | イメージ |
|---|---|---|
| エンコーダ | 入力データを小さな表現に圧縮する | 重要な特徴だけを取り出す |
| 中間表現 | 圧縮された特徴を表す | データの要点をまとめたもの |
| デコーダ | 圧縮された表現から元のデータを復元する | 要点から元の形に戻す |
この中間にある圧縮された表現を、潜在表現や特徴表現 と呼ぶことがあります。
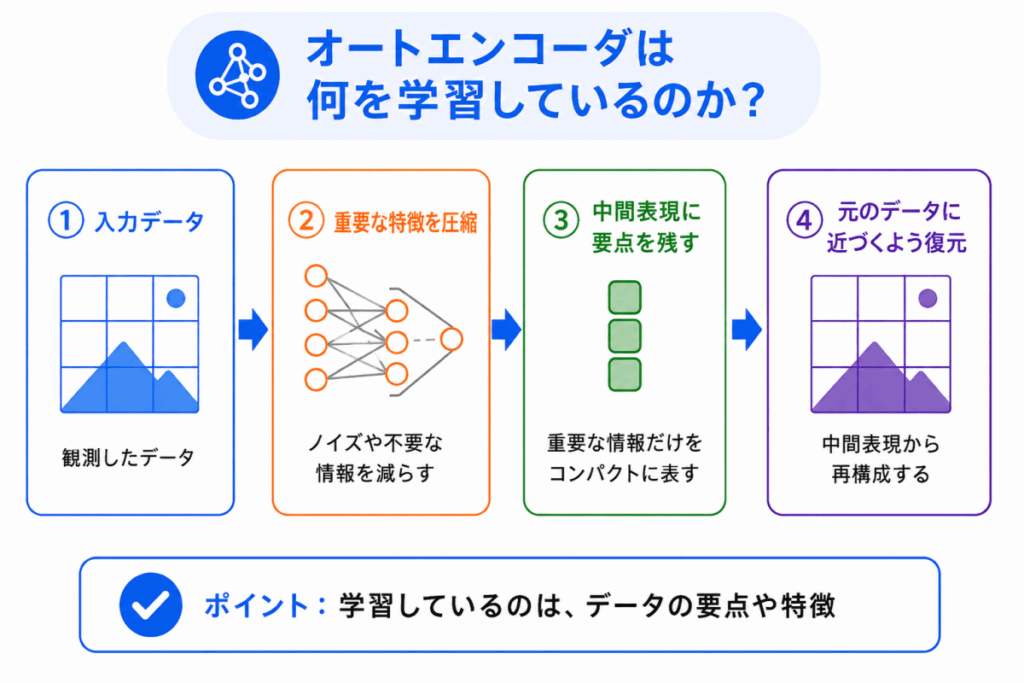
オートエンコーダが学習しているのは、データの中にある 重要な特徴 です。
たとえば、画像データには多くの画素があります。
そのすべてが同じくらい重要とは限りません。
オートエンコーダは、元のデータを復元するために必要な情報を、中間表現に残そうとします。
つまり、入力を圧縮し、復元する過程で、データの要点を内部に持つようになります。
分類のように「犬」や「猫」といった正解ラベルを直接当てるわけではありません。
入力データそのものを使って、特徴を学習する点が特徴です。
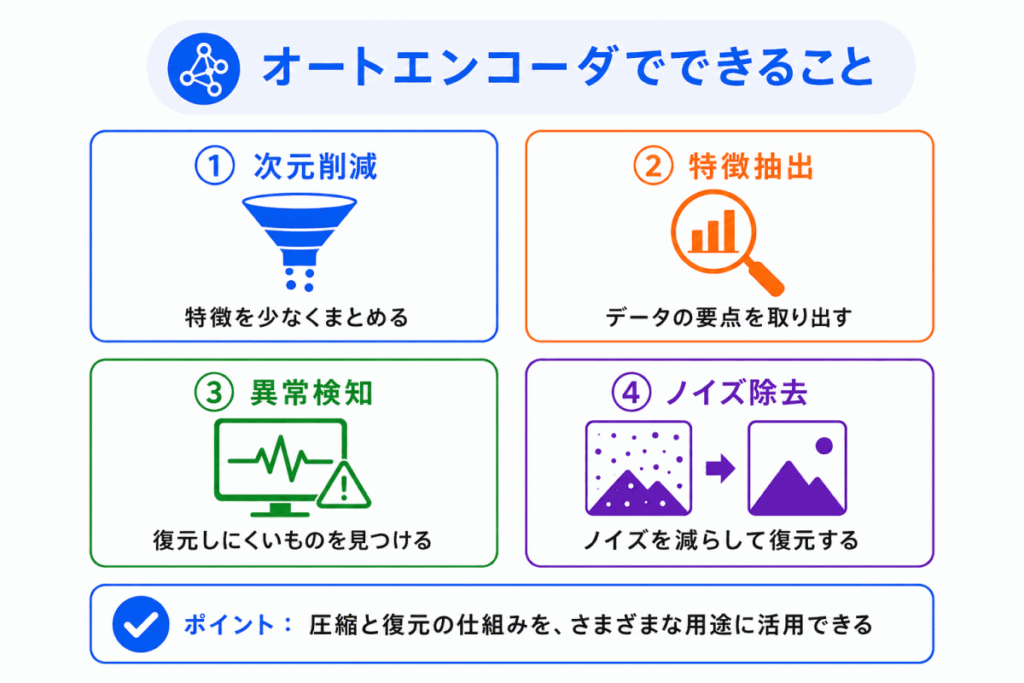
オートエンコーダは、入力データを圧縮して復元する仕組みを使って、さまざまな用途に使われます。
代表的な用途は次の通りです。
| 用途 | 考え方 | ポイント |
|---|---|---|
| 次元削減 | データを少ない特徴に圧縮する | PCAと関連して問われやすい |
| 特徴抽出 | データの重要な特徴を取り出す | 中間表現が重要になる |
| 異常検知 | 正常データを復元できるように学習する | 復元誤差が大きいものを異常と見る |
| ノイズ除去 | ノイズを含む入力から元のデータを復元する | デノイジングオートエンコーダと関係する |
G検定では、特に 次元削減、特徴抽出、異常検知 との関係を押さえておくと理解しやすくなります。
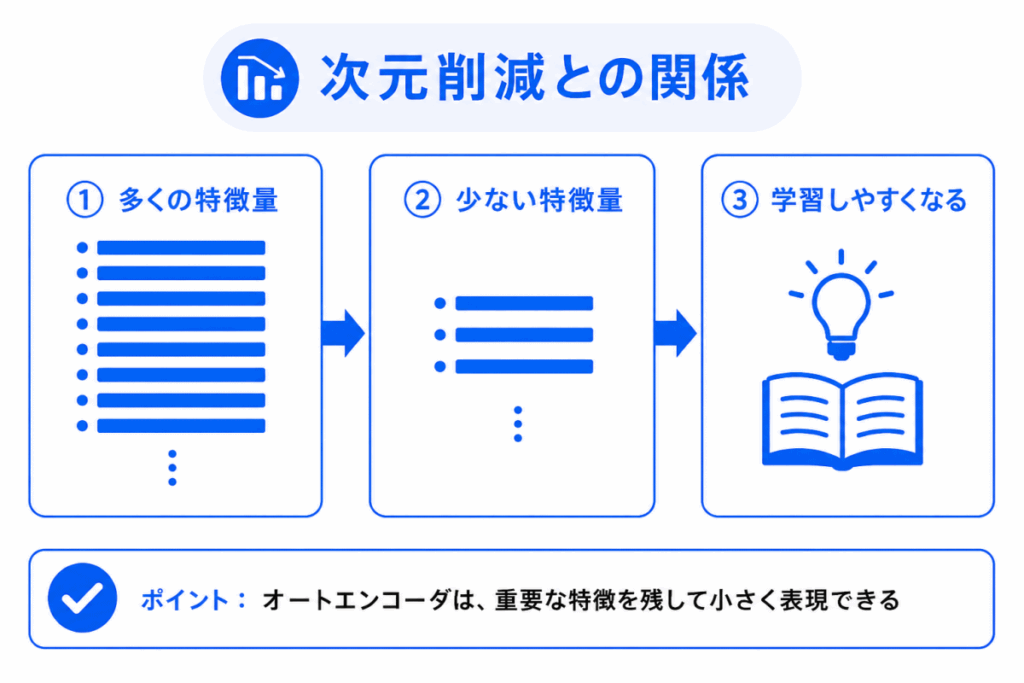
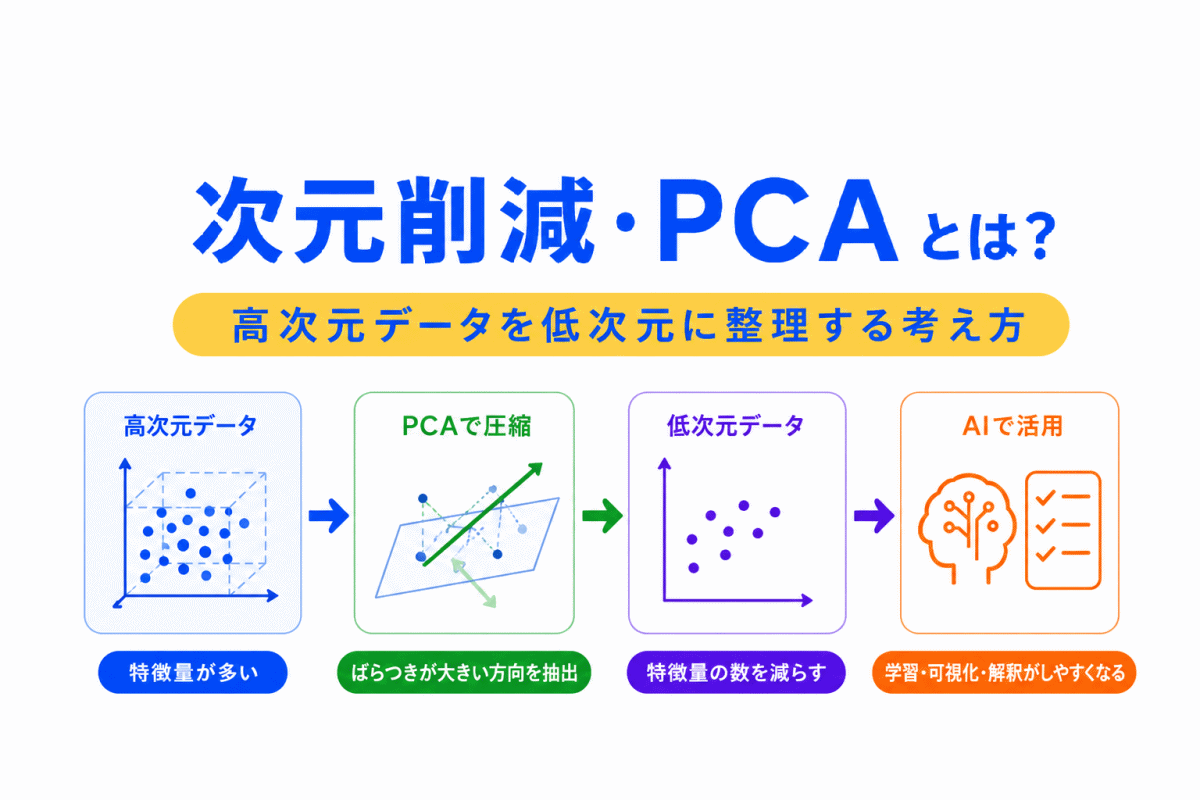
オートエンコーダは、次元削減の考え方と深く関係します。
次元削減とは、データの特徴量を減らして、扱いやすい形にすることです。
たとえば、画像や文章のように多くの情報を持つデータは、そのままだと複雑です。
そこで、重要な特徴だけを残して小さく表現できれば、学習や分析がしやすくなります。
オートエンコーダでは、エンコーダによってデータを小さな表現に圧縮します。
この部分が、次元削減と似た役割を持ちます。
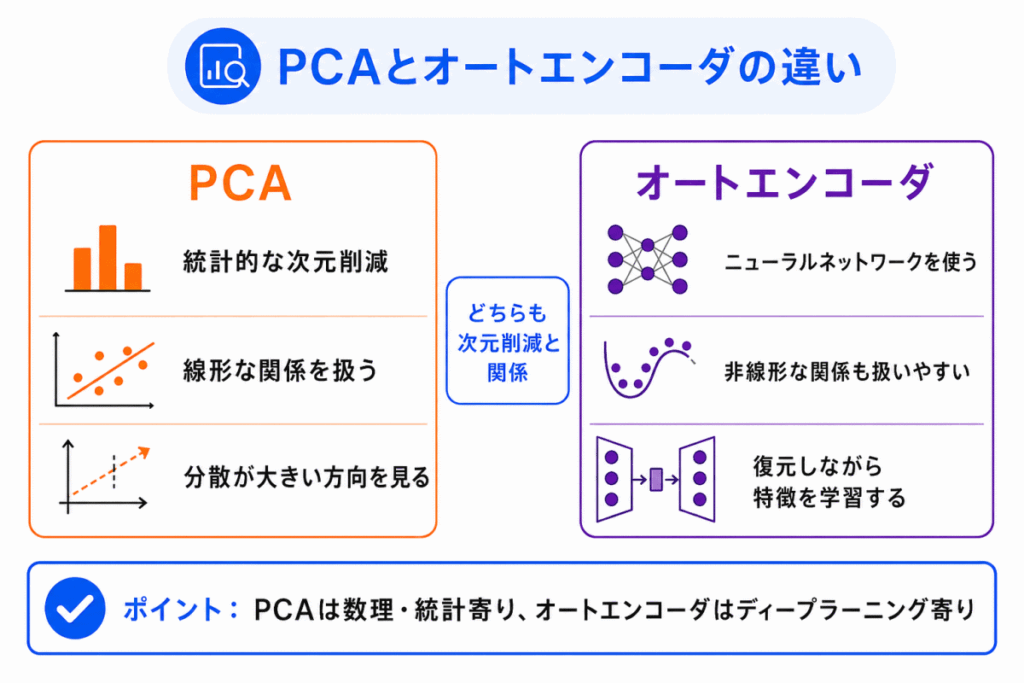
次元削減では、PCAもよく出てきます。
PCAとオートエンコーダは、どちらもデータを小さく表現する考え方と関係します。
ただし、同じものではありません。
違いは次のように整理できます。
| 項目 | PCA | オートエンコーダ |
|---|---|---|
| 種類 | 統計的な次元削減手法 | ニューラルネットワークを使う手法 |
| 見ているもの | データの分散が大きい方向 | 入力を復元するために必要な特徴 |
| 表現力 | 主に線形な関係を扱う | 非線形な関係も扱いやすい |
| G検定での見方 | 数理・統計寄りの次元削減 | ディープラーニング寄りの特徴抽出 |
PCAは、数理・統計寄りの次元削減です。
オートエンコーダは、ニューラルネットワークを使った次元削減・特徴抽出として整理できます。
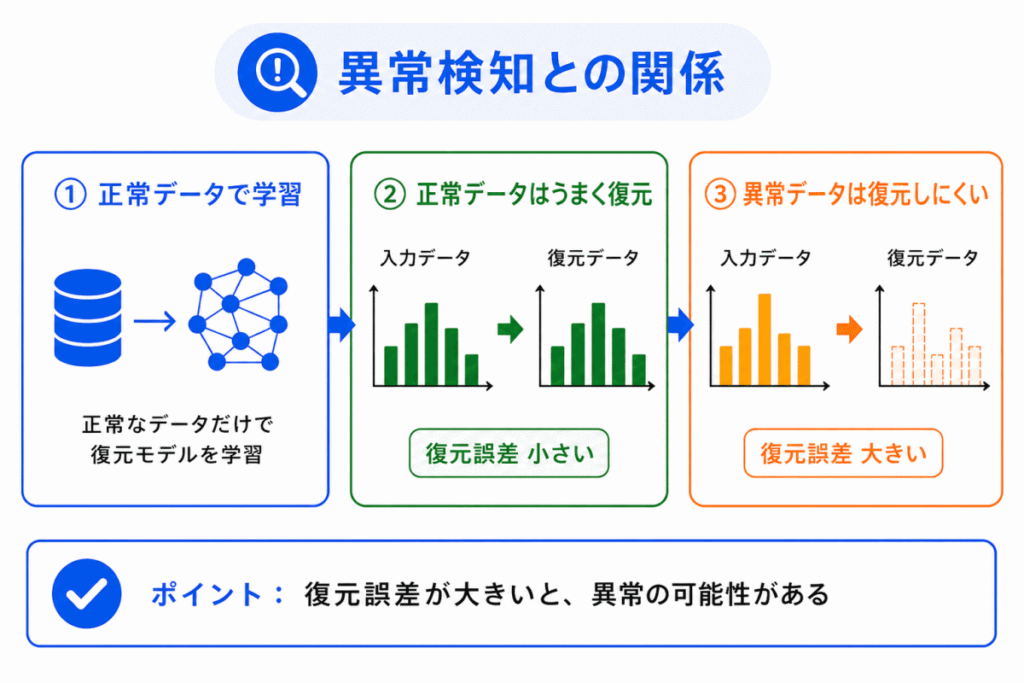
オートエンコーダは、異常検知にも使われます。
考え方は、正常なデータをうまく復元できるように学習することです。
正常なデータで学習したオートエンコーダは、正常な入力ならうまく復元できます。
しかし、学習していない異常な入力が来ると、うまく復元できないことがあります。
このとき、入力と出力の差が大きくなります。
この差を 復元誤差 と呼びます。
復元誤差が大きい場合、通常とは違うデータである可能性があるため、異常と判断する手がかりになります。
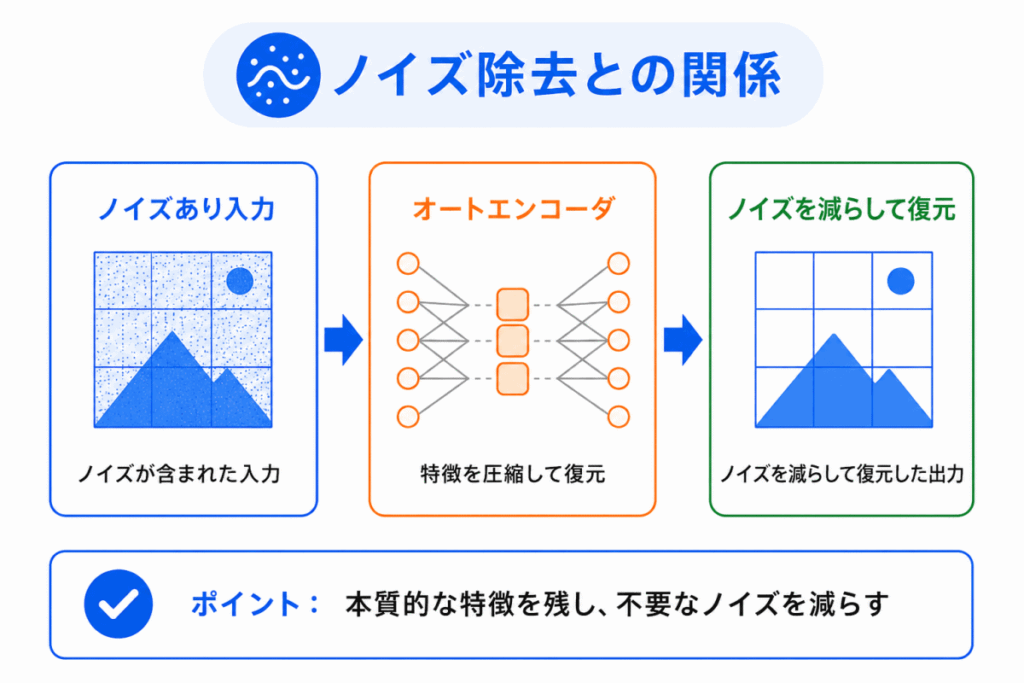
オートエンコーダは、ノイズ除去にも使われます。
たとえば、ノイズを含む画像を入力し、元のきれいな画像に近づけて復元するように学習します。
このような考え方を使うものに、デノイジングオートエンコーダ があります。
デノイジングとは、ノイズを取り除くという意味です。
G検定では、細かい実装よりも、ノイズを含む入力から本質的な特徴を取り出す考え方 として押さえるとよいです。
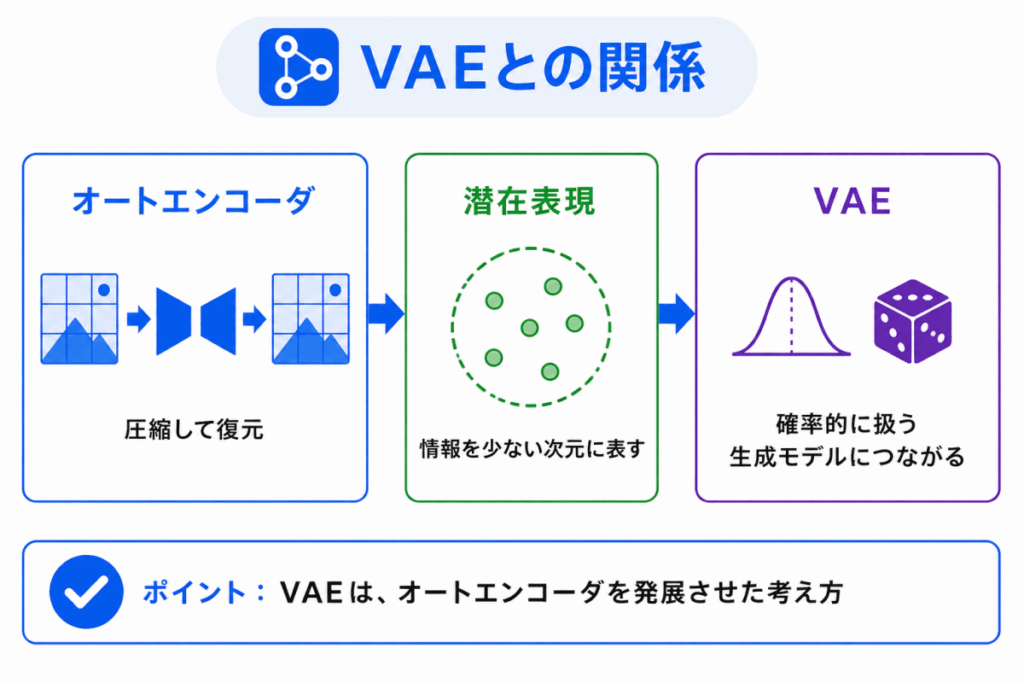
オートエンコーダを理解すると、VAEも理解しやすくなります。
VAEは、Variational Autoencoder の略です。
日本語では、変分オートエンコーダと呼ばれます。
VAEは、オートエンコーダの考え方をもとにしながら、潜在表現を確率的に扱うモデルです。
通常のオートエンコーダは、入力を圧縮して復元することが中心です。
一方、VAEは、潜在表現を確率分布として扱うことで、新しいデータの生成にもつながります。
ここでは、まず次のように押さえるとよいです。
細かい違いは、VAEやGANの記事で整理すると理解しやすくなります。
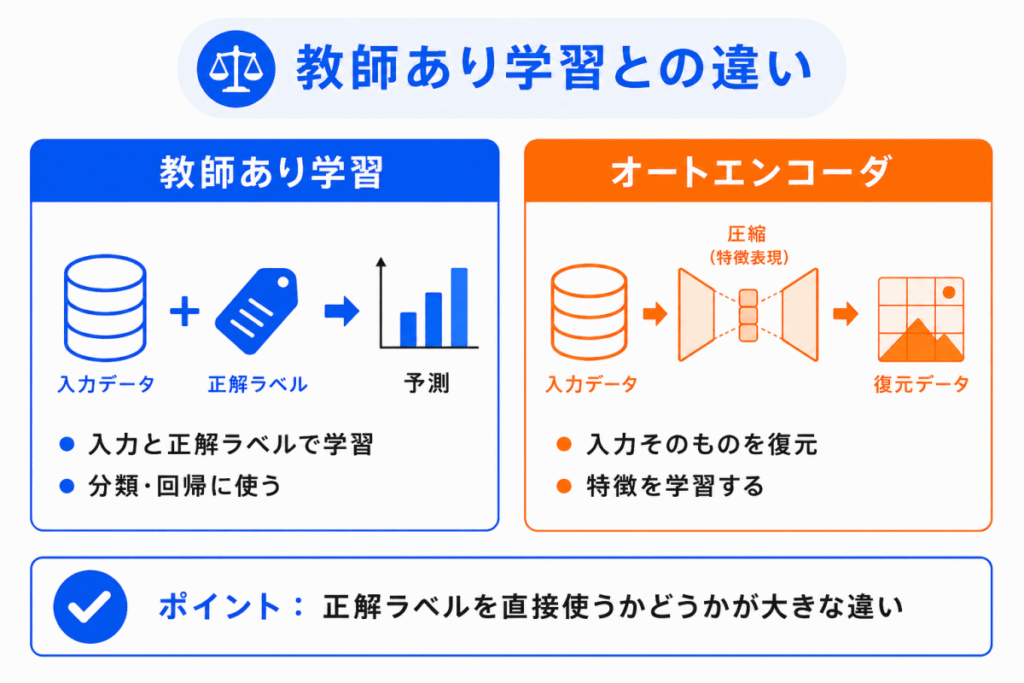
オートエンコーダは、教師あり学習の分類問題とは少し違います。
教師あり学習では、入力データと正解ラベルの組み合わせを使います。
たとえば、画像を入力して「犬」や「猫」という正解を当てるように学習します。
一方、オートエンコーダでは、入力データを復元するように学習します。
入力そのものが、目標に近い役割を持ちます。
そのため、オートエンコーダは、正解ラベルがなくても特徴を学習しやすいモデルとして整理されることがあります。
G検定では、分類名を細かく覚えるよりも、入力を圧縮して復元することで特徴を学習する という仕組みを優先して理解するとよいです。
G検定では、オートエンコーダの数式よりも、仕組みや関連用語が問われやすいです。
押さえるポイントは次の通りです。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 基本構造 | エンコーダで圧縮し、デコーダで復元する |
| 学習の目的 | 入力と出力の差を小さくする |
| 中間表現 | 圧縮された特徴表現を学習する |
| 次元削減 | 特徴を少ない次元にまとめる考え方と関係する |
| 異常検知 | 復元誤差が大きいデータを異常と見ることがある |
| VAEとの関係 | VAEはオートエンコーダを発展させた生成モデルとして整理できる |
特に、入力を復元する、特徴を圧縮する、VAEにつながる という3点は重要です。
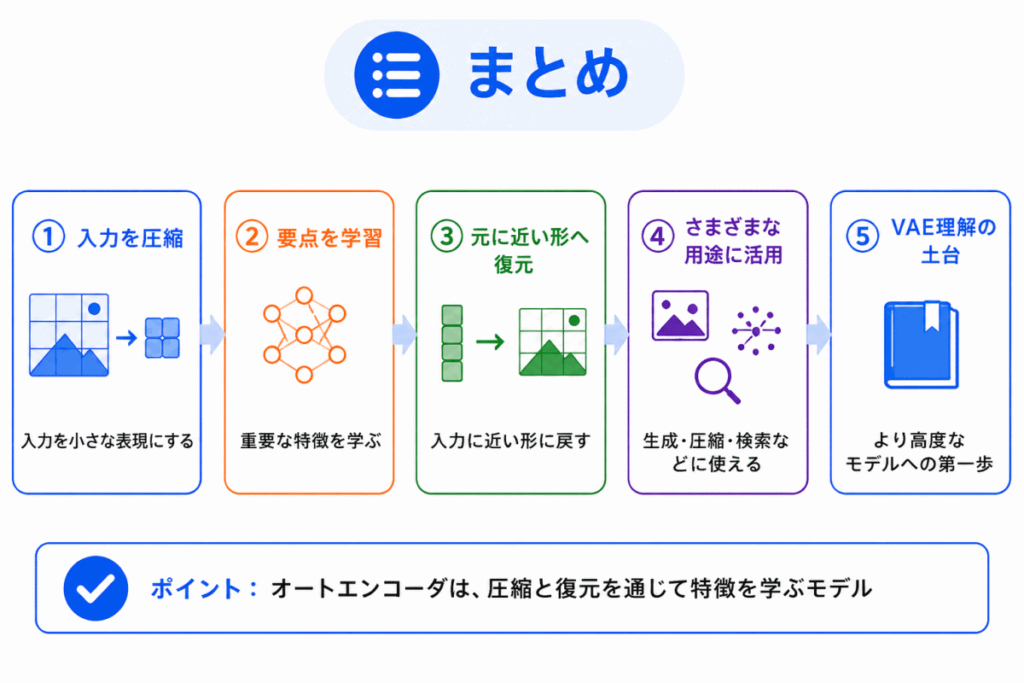
オートエンコーダは、入力データを一度圧縮し、そこから元のデータを復元するニューラルネットワークです。
エンコーダで特徴を小さくまとめ、デコーダで元の形に戻します。
その過程で、データの重要な特徴を学習します。
G検定では、細かい数式よりも、次のように整理すると理解しやすくなります。
オートエンコーダは、入力を圧縮して復元するモデルです。
中間表現には、復元に必要な特徴がまとめられます。
次元削減、特徴抽出、異常検知、ノイズ除去と関係します。
VAEや生成モデルを理解する前段階としても重要です。
単独で暗記するよりも、次元削減、PCA、VAE、生成モデル とのつながりで理解すると整理しやすくなります。
次元削減との関係を理解するなら、こちらの記事がおすすめです。
データを数字のまとまりとして扱う前提を確認するなら、こちらの記事がおすすめです。
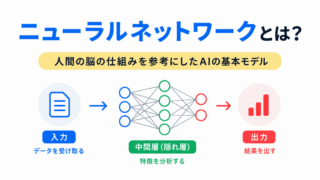
ニューラルネットワークの基本から確認するなら、こちらの記事がおすすめです。
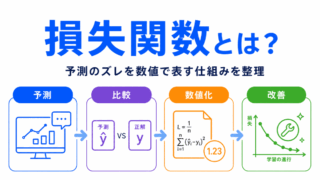
損失を小さくしながら学習する流れを確認するなら、こちらの記事がおすすめです。
ディープラーニングの要素技術をまとめて確認するなら、こちらの記事がおすすめです。

数理・統計とのつながりを確認するなら、こちらの記事がおすすめです。

重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

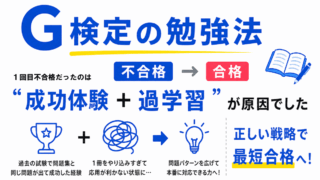
1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認