【G検定対策】クラスタリングとは?|教師なし学習で似たデータをグループに分ける考え方を整理
seo-webmaster
G検定対策ブログ
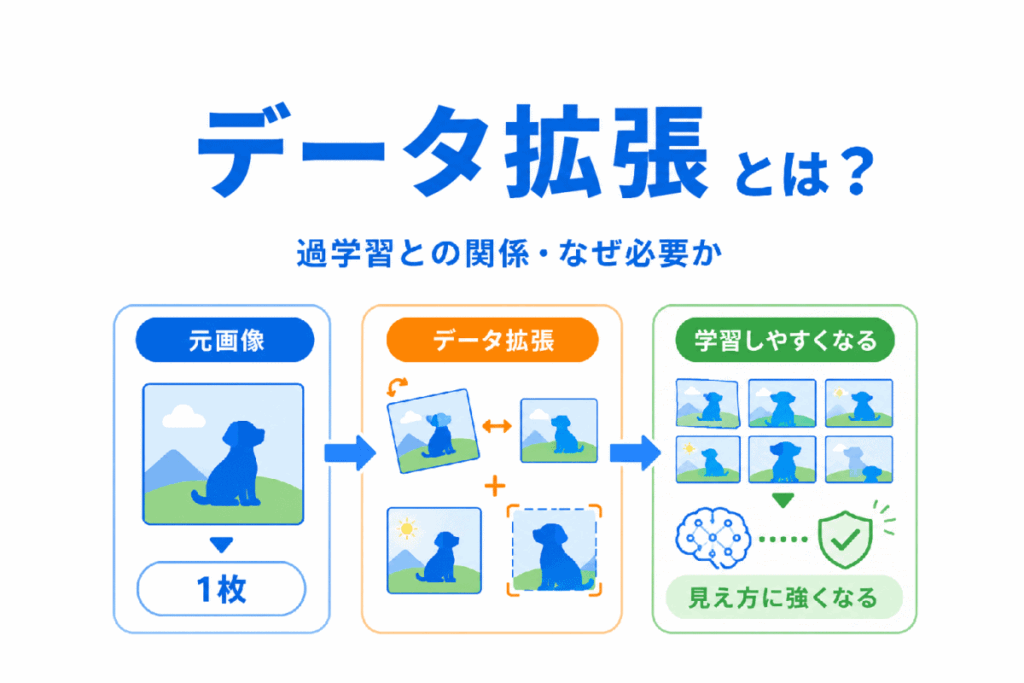
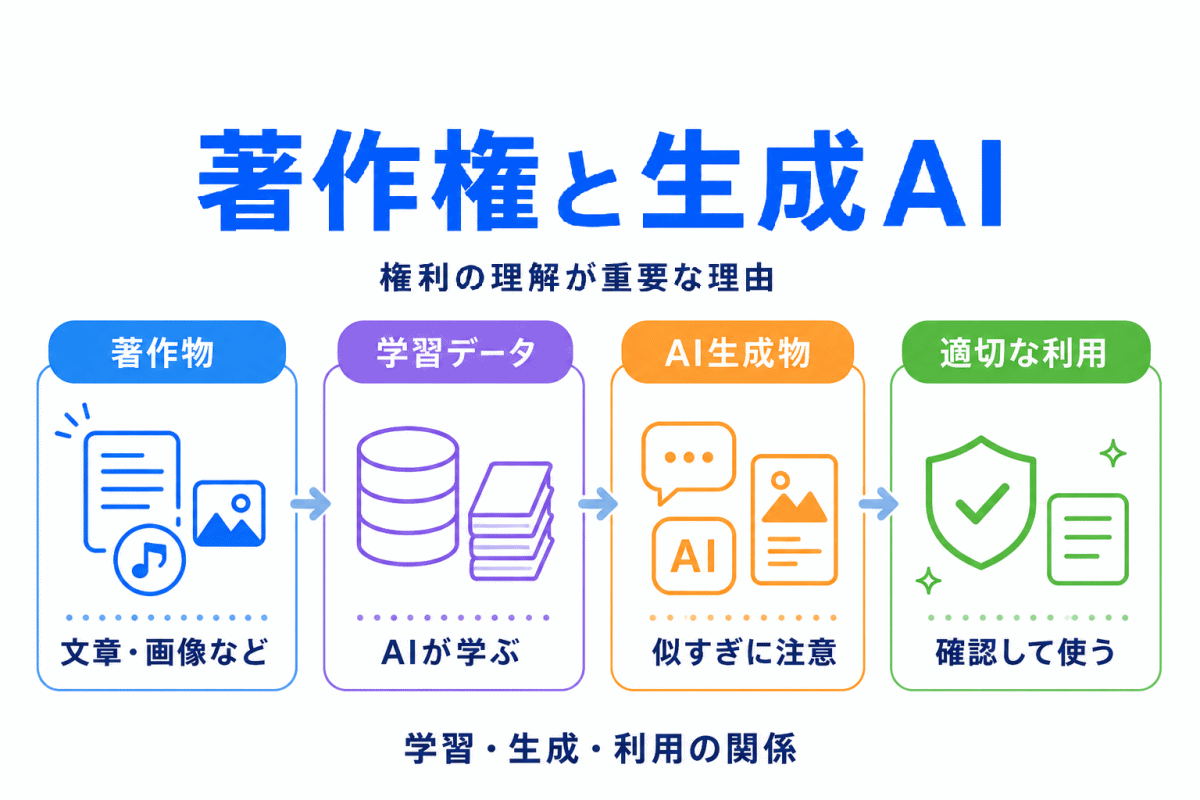
データ拡張とは、手元にある学習データをもとに、少し形を変えたデータを作り、AIに学習させる工夫です。
特に画像認識では、画像を回転させたり、反転させたり、明るさを変えたりすることで、見え方の違いに強いモデルを作りやすくなります。
AIは同じようなデータばかりで学習すると、そのデータには強くても、新しいデータに弱くなることがあります。
データ拡張は、AIが特定の見え方だけを覚えすぎないようにし、より幅広いパターンに対応できるようにするための考え方です。
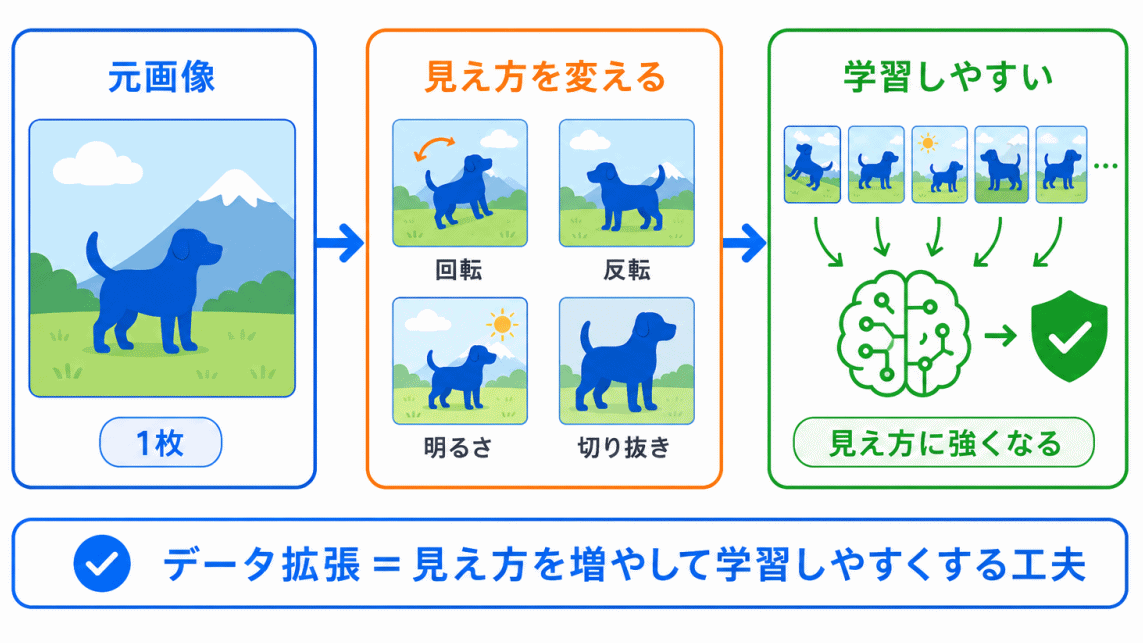
データ拡張は、まったく新しいデータを集めるのではなく、すでにあるデータの見え方を変える 方法です。
たとえば、犬の画像が1枚あるとします。
その画像を少し回転させたり、左右反転させたり、明るさを変えたりすると、AIから見ると違う画像のように扱えます。
| 元のデータ | 変え方 | AIにとっての意味 |
|---|---|---|
| 犬の画像 | 少し回転 | 角度が変わっても犬と判断する |
| 犬の画像 | 左右反転 | 向きが変わっても犬と判断する |
| 犬の画像 | 明るさ変更 | 明るさが違っても犬と判断する |
| 犬の画像 | 一部切り抜き | 少し見え方が違っても犬と判断する |
データ拡張 = 見え方のバリエーションを増やす工夫 と整理するとわかりやすいです。
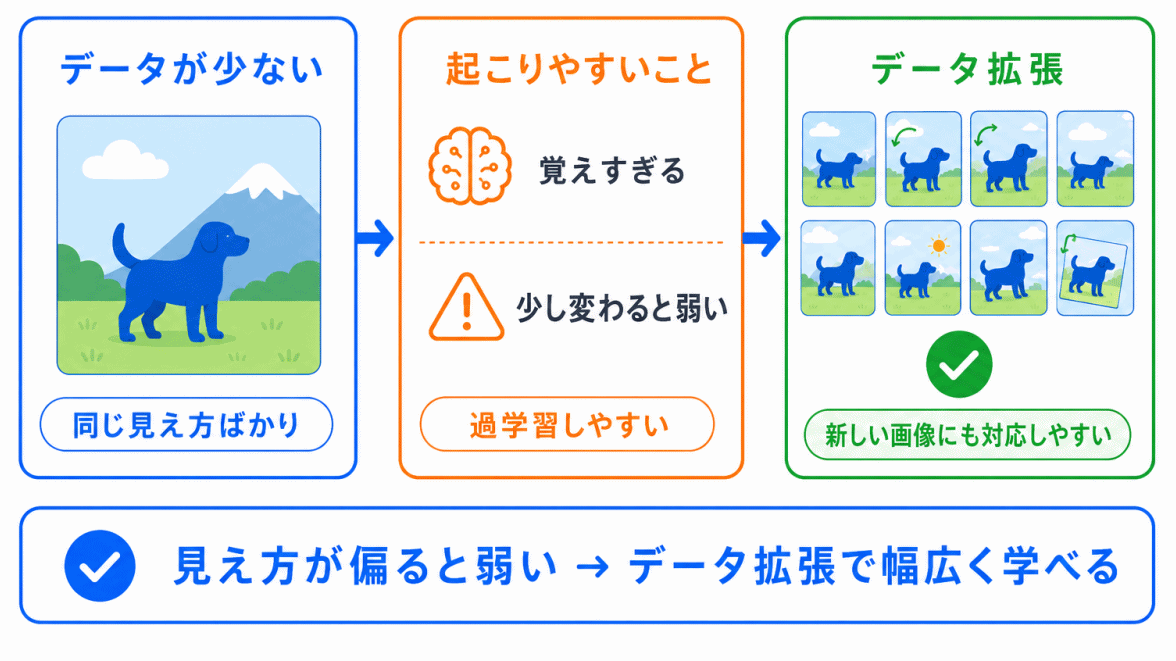
AIは、学習データからパターンを見つけます。
しかし、学習データが少なかったり、似たようなデータばかりだったりすると、AIはそのデータに合わせすぎてしまいます。
これが、過学習につながります。
| 状態 | 起きやすいこと |
|---|---|
| データが少ない | 特定の例を覚えすぎる |
| データが偏っている | 見たことのないパターンに弱い |
| 見え方が似ている | 少し変わると判断を間違えやすい |
データ拡張を使うと、AIは同じ対象をいろいろな見え方で学習できます。
その結果、新しいデータにも対応しやすくなることが期待できます。
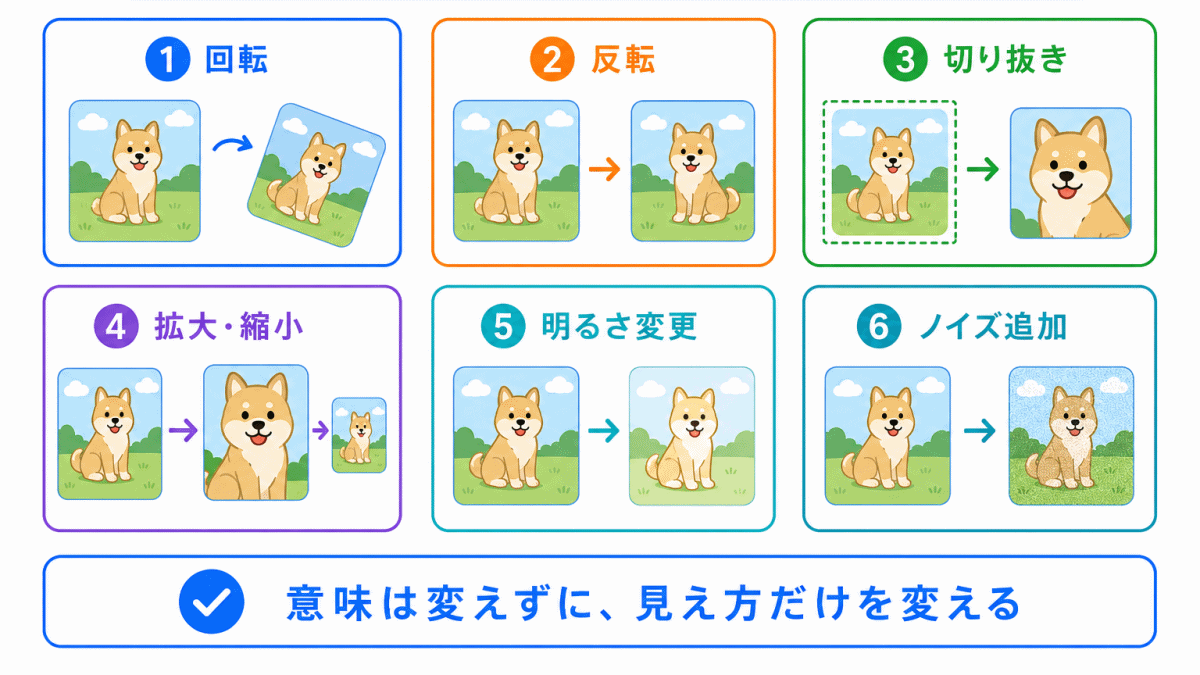
データ拡張は、特に画像認識でよく使われます。
| 方法 | 内容 |
|---|---|
| 回転 | 画像を少し傾ける |
| 反転 | 左右や上下を反転する |
| 切り抜き | 画像の一部を切り出す |
| 拡大・縮小 | 画像の大きさを変える |
| 明るさ変更 | 画像を明るくしたり暗くしたりする |
| ノイズ追加 | 少し乱れを加える |
たとえば、犬の画像を少し回転させても、犬であることは変わりません。
このように、意味は変えずに見た目だけを変えるのがポイントです。
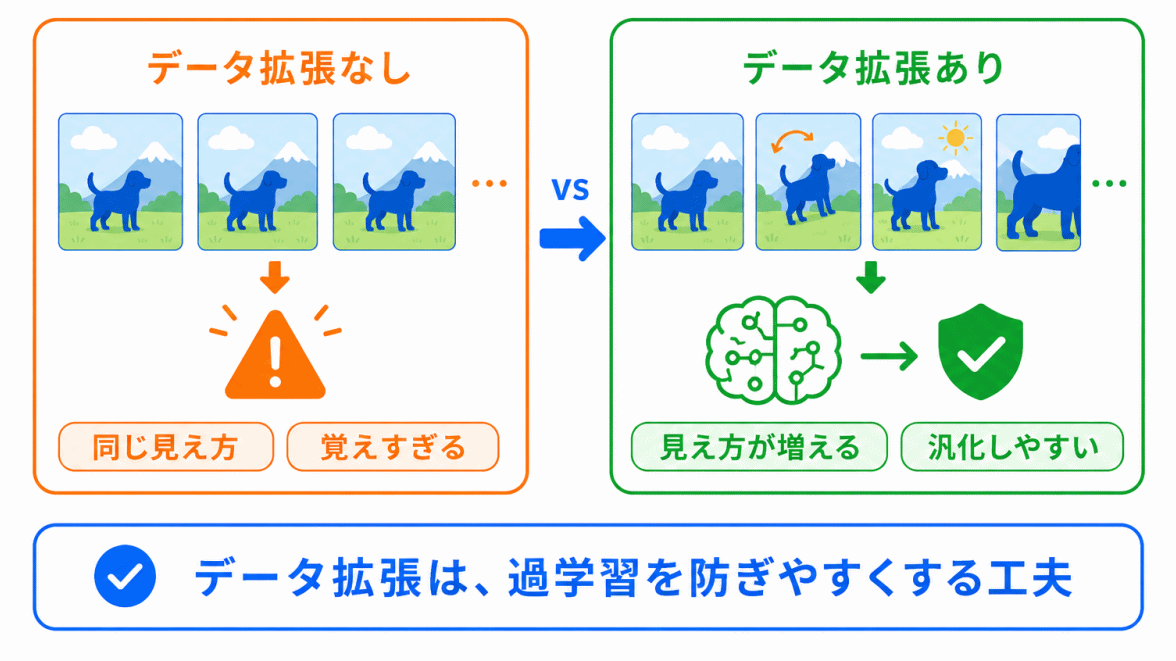
データ拡張は、過学習を防ぐための工夫として理解できます。
過学習とは、AIが学習データに合わせすぎて、新しいデータに弱くなる状態です。
| 用語 | 一言でいうと |
|---|---|
| 過学習 | 学習データを覚えすぎる |
| データ拡張 | 見え方を増やして覚えすぎを防ぐ |
| 汎化 | 新しいデータにも対応できること |
データ拡張によって、AIは同じものをいろいろな形で学習します。
そのため、特定の画像だけを丸暗記するのではなく、より本質的な特徴を見つけやすくなります。
データ拡張=過学習を防ぎ、汎化しやすくする工夫 と整理できます。
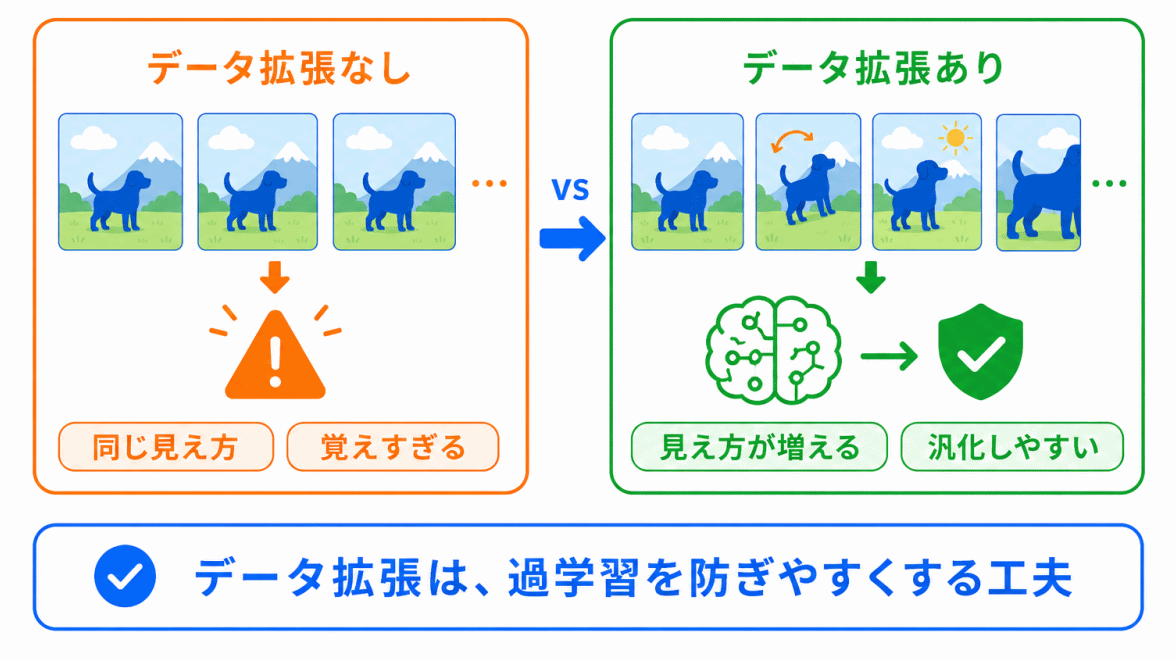
データ拡張は、正則化と同じように、過学習を抑える目的で使われます。
ただし、やっていることは少し違います。
| 用語 | 何をするか |
|---|---|
| 正則化 | モデルが複雑になりすぎないようにする |
| ドロップアウト | 一部のニューロンを使わずに学習する |
| データ拡張 | 学習データの見え方を増やす |
正則化やドロップアウトは、モデル側に工夫を入れる方法です。
一方、データ拡張は、データ側に工夫を入れる方法です。
ここを分けると混同しにくくなります。
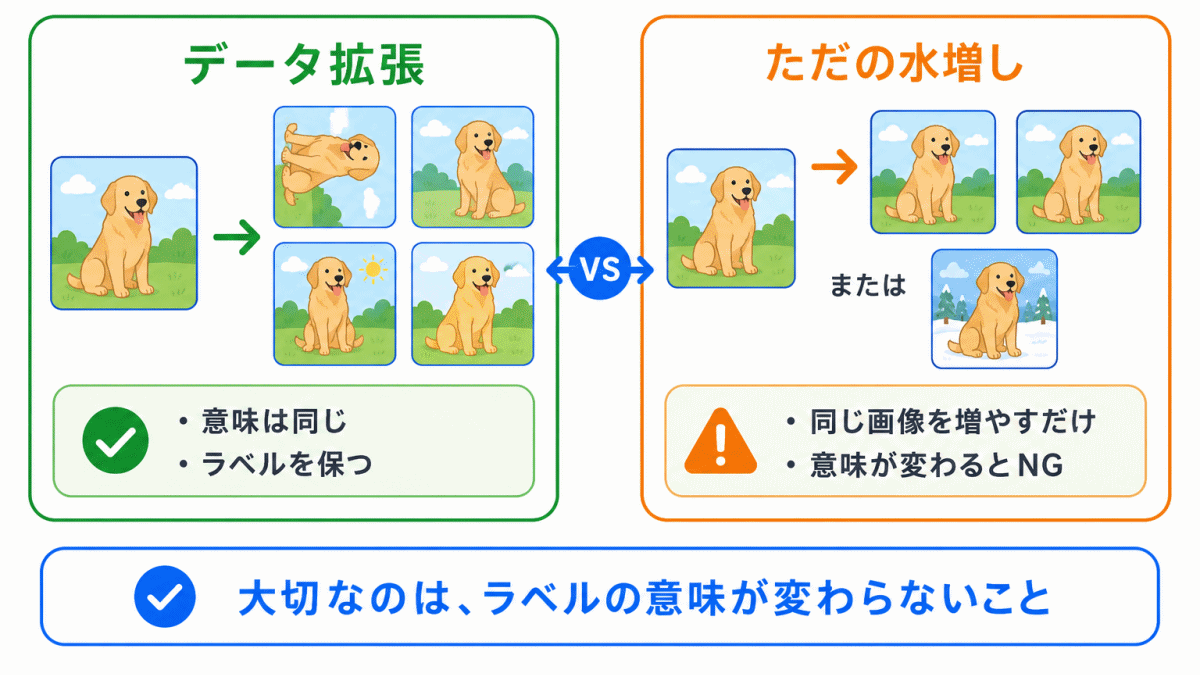
データ拡張は、単なる水増しではありません。
意味のない変化を加えると、逆に学習を邪魔することがあります。
たとえば、数字の「6」を上下反転すると「9」のように見える場合があります。
このような変換は、正しいラベルを保てない可能性があります。
| 変換 | 問題になりやすい例 |
|---|---|
| 上下反転 | 数字や文字の意味が変わる |
| 大きすぎる回転 | 対象が不自然になる |
| 強すぎるノイズ | 何の画像かわかりにくくなる |
| 過度な切り抜き | 重要な部分が消える |
データ拡張では、ラベルの意味が変わらない範囲で変換することが大切です。
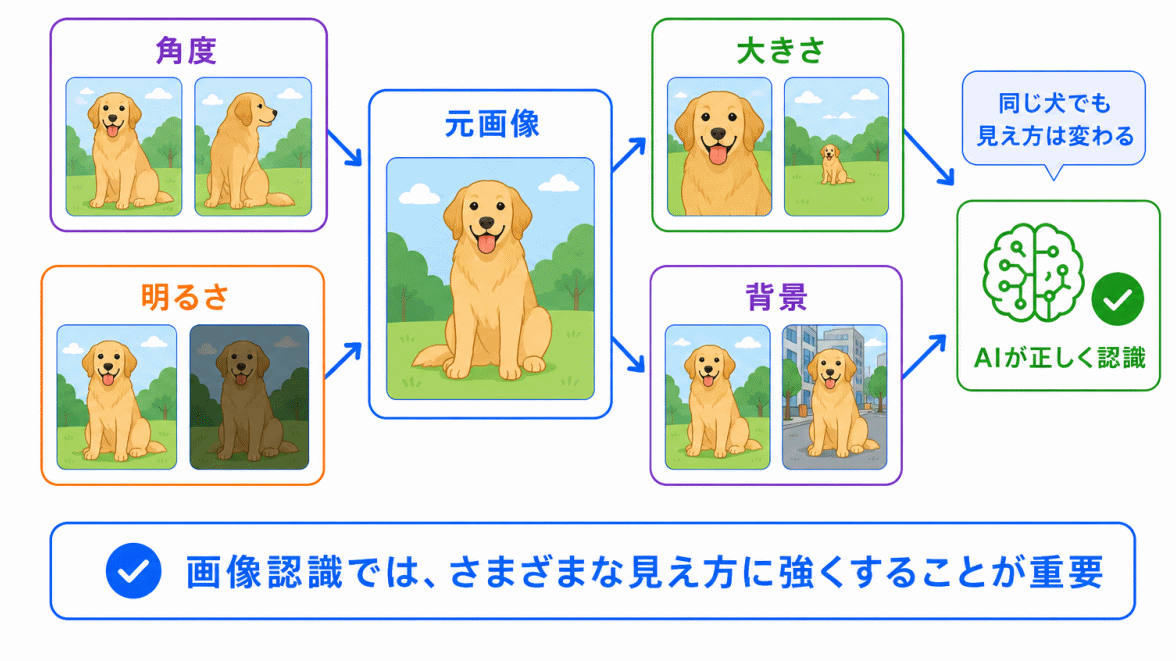
データ拡張は、画像認識と相性がよい考え方です。
画像認識では、同じ対象でも見え方が大きく変わります。
| 変化 | 例 |
|---|---|
| 角度 | 斜めから見た車 |
| 明るさ | 昼と夜の画像 |
| 大きさ | 近くの物体と遠くの物体 |
| 位置 | 画面の中央・端にある物体 |
| 背景 | 同じ犬でも背景が違う |
AIが実際に使われる場面では、学習データとまったく同じ画像が出てくるとは限りません。
そのため、データ拡張によって、いろいろな見え方に慣れさせることが重要になります。
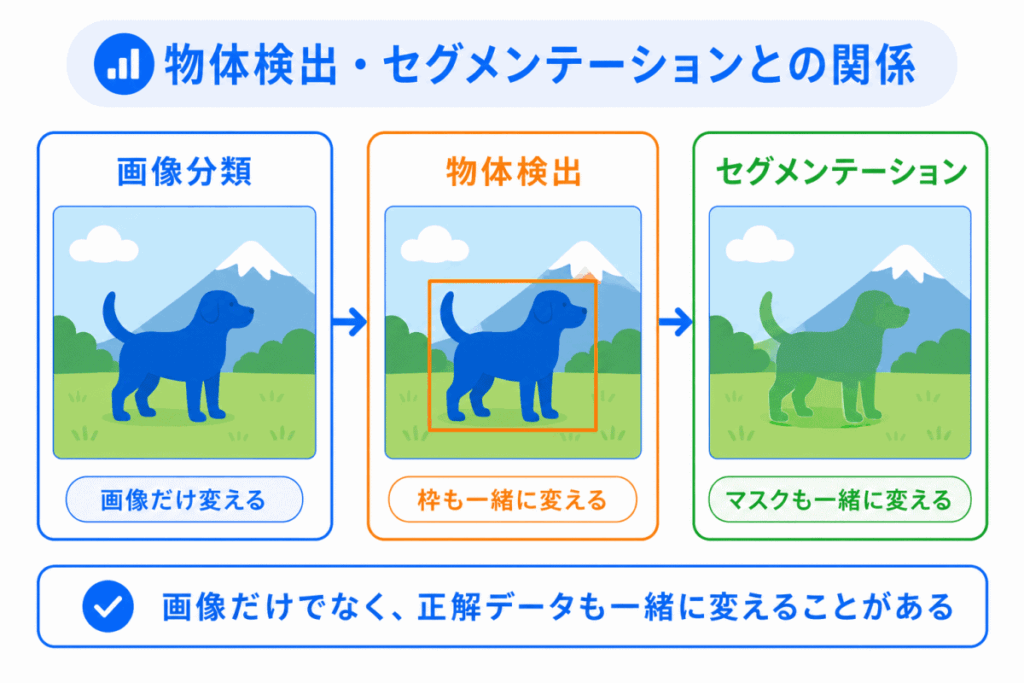
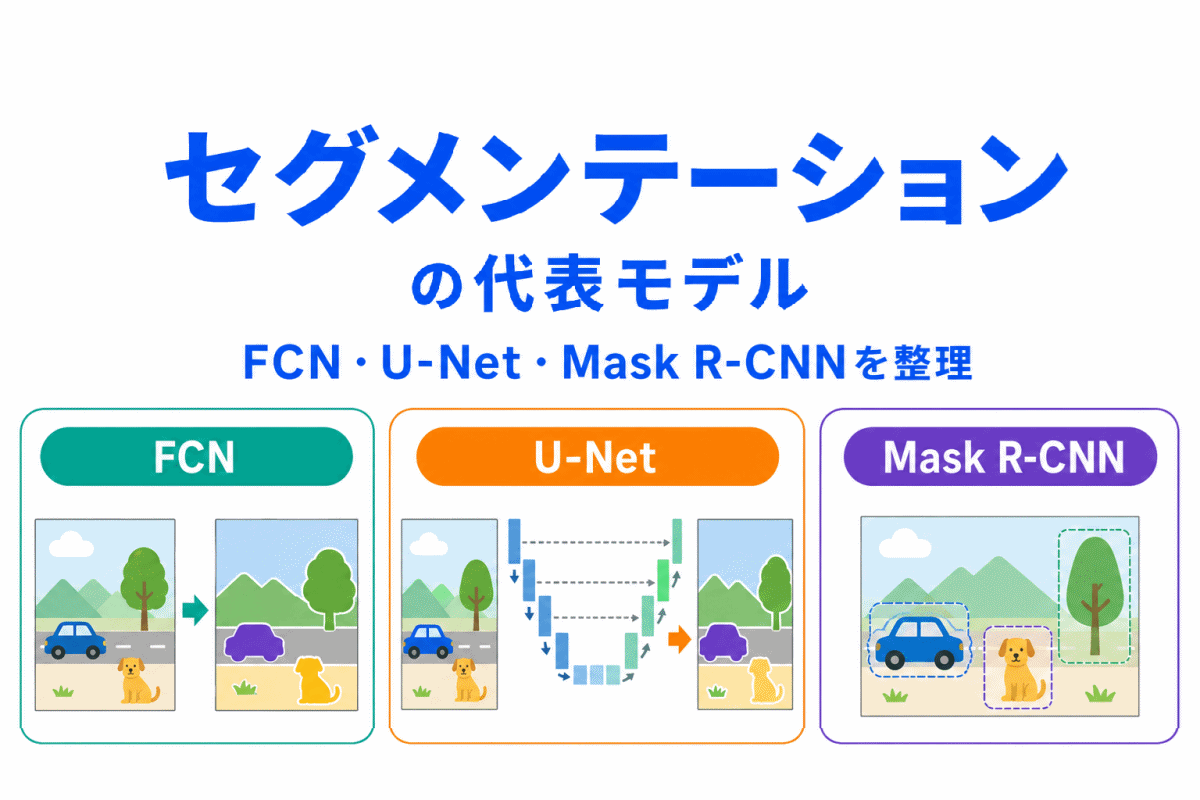
データ拡張は、画像分類だけでなく、物体検出やセグメンテーションでも使われます。
| 技術 | データ拡張で意識すること |
|---|---|
| 画像分類 | 画像全体のラベルが変わらないか |
| 物体検出 | 物体の位置情報も一緒に変える |
| セグメンテーション | 領域のマスクも一緒に変える |
画像分類では、画像全体のラベルが保たれればよい場合が多いです。
一方、物体検出では、画像を動かしたら、物体の位置を示す枠も一緒に動かす必要があります。
セグメンテーションでは、領域を示すマスクも同じように変える必要があります。
画像だけでなく、正解データも一緒に変える
という点が重要です。
G検定では、細かい実装よりも、データ拡張の目的を押さえることが大切です。
| 問われやすいポイント | 整理のしかた |
|---|---|
| データを増やす工夫 | データ拡張 |
| 過学習を抑える | 汎化性能を高めるため |
| 画像を回転・反転する | 代表的なデータ拡張 |
| 見え方を変える | ラベルの意味は変えない |
| 正則化との関係 | どちらも過学習対策 |
選択肢に
が並んだら、まず「何に工夫を加えているのか」を確認します。
データそのものを変えているなら、データ拡張です。
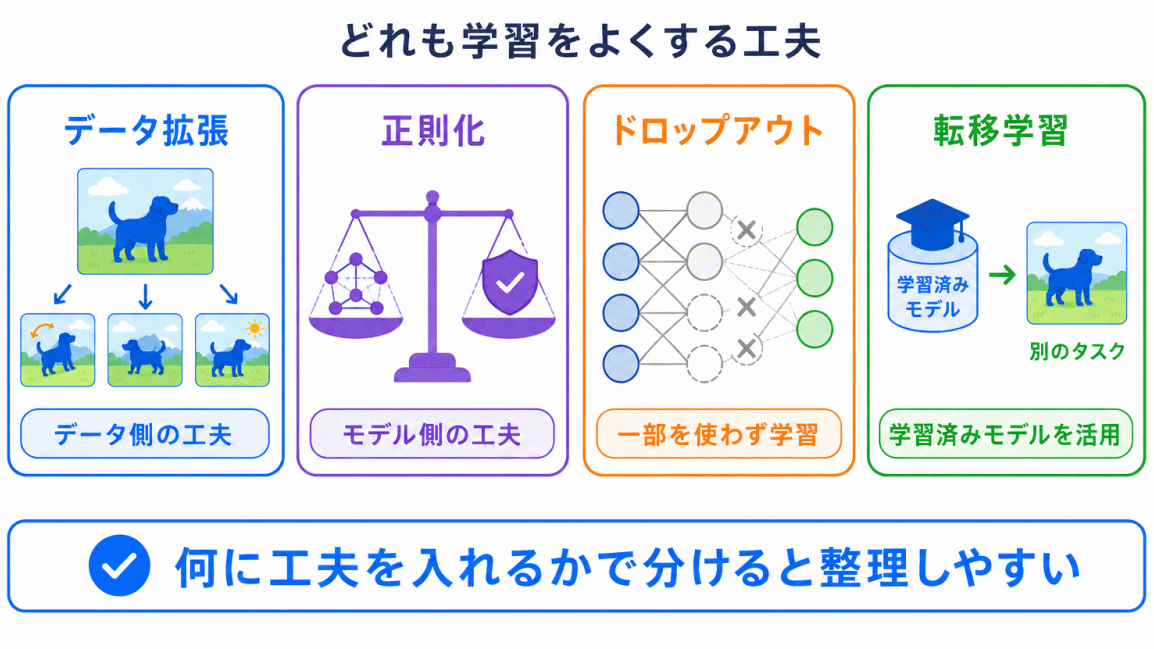
データ拡張は、過学習対策や正則化と一緒に出てくるため混同しやすいです。
| 混同しやすい理由 | 整理のしかた |
|---|---|
| 過学習対策として出てくる | 目的は似ている |
| 正則化と一緒に学ぶ | 方法が違う |
| データを増やすように見える | 意味を変えずに見え方を増やす |
| 転移学習と混ざる | データを増やすのか、学習済みモデルを使うのかで分ける |
整理すると、次のようになります。
| 用語 | 一言でいうと |
|---|---|
| データ拡張 | データの見え方を増やす |
| 正則化 | モデルを複雑にしすぎない |
| ドロップアウト | 一部を使わずに学習する |
| 転移学習 | 学習済みモデルを別の課題に活用する |
データ拡張 = データ側の工夫 と覚えると整理しやすいです。
データ拡張とは、すでにあるデータに少し変化を加えて、学習データの見え方を増やす工夫です。
画像認識では、回転・反転・切り抜き・明るさ変更などが代表的です。
データ拡張を使うことで、AIは特定のデータだけを覚えすぎるのではなく、いろいろな見え方に対応しやすくなります。
整理すると、次のようになります。
| 用語 | 一言でいうと |
|---|---|
| データ拡張 | 見え方を増やす |
| 過学習 | 覚えすぎる |
| 汎化 | 新しいデータにも対応する |
| 正則化 | 複雑になりすぎないようにする |
データ拡張 = 見え方を増やして、覚えすぎを防ぐ工夫 と押さえておきましょう。
データ拡張は、過学習を防ぎ、画像認識で汎化しやすいモデルを作るための工夫です。あわせて、過学習対策や画像認識の関連技術も確認しておくと理解しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| 過学習とは? | 学習データに合わせすぎる状態/汎化性能との関係/過学習を防ぐ工夫 |
| 正則化とは? | モデルの複雑さを抑える考え方/過学習対策/ドロップアウトとの関係 |
| ドロップアウトとは? | 一部のニューロンを使わない学習/過学習を抑える仕組み/正則化との関係 |
| 画像認識の歴史 | 画像認識の流れ/CNNとの関係/データ拡張が使われる場面 |
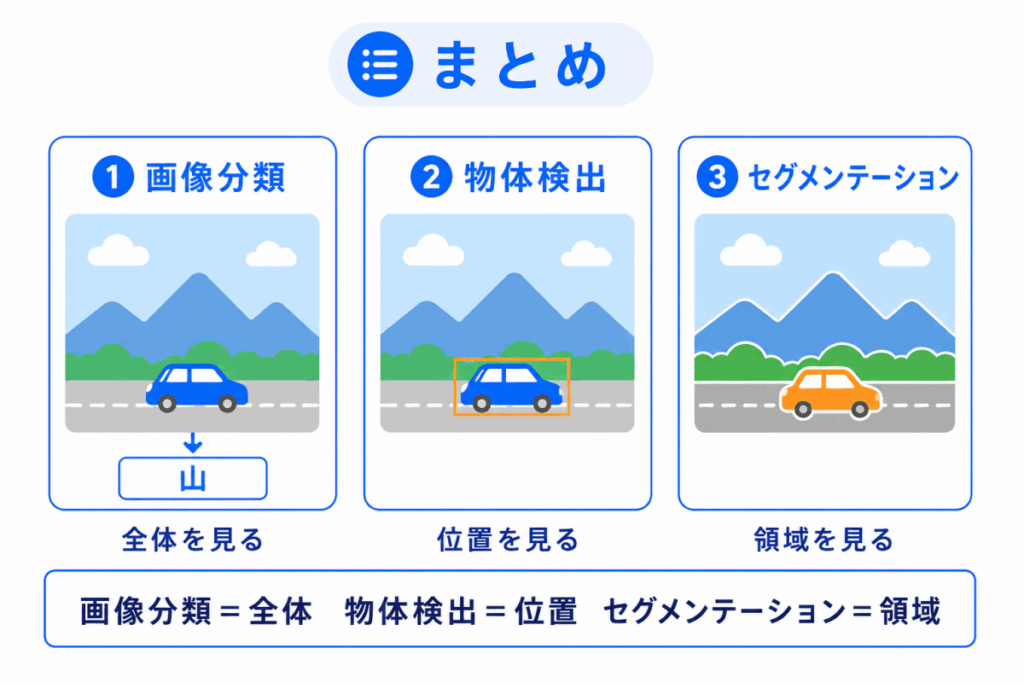
| 物体検出とは? | 画像分類との違い/物体の位置を見つける技術/セグメンテーションとの関係 |
| セグメンテーションとは? | 画像を領域ごとに分ける技術/マスク情報の扱い/物体検出との違い |
| ディープラーニングの応用例とは? | 画像認識・自然言語処理・生成AI/応用分野ごとの整理/技術と用途の対応 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。