【G検定対策】Attentionとは?|なぜTransformerで重要になったのかをわかりやすく整理
seo-webmaster
G検定対策ブログ
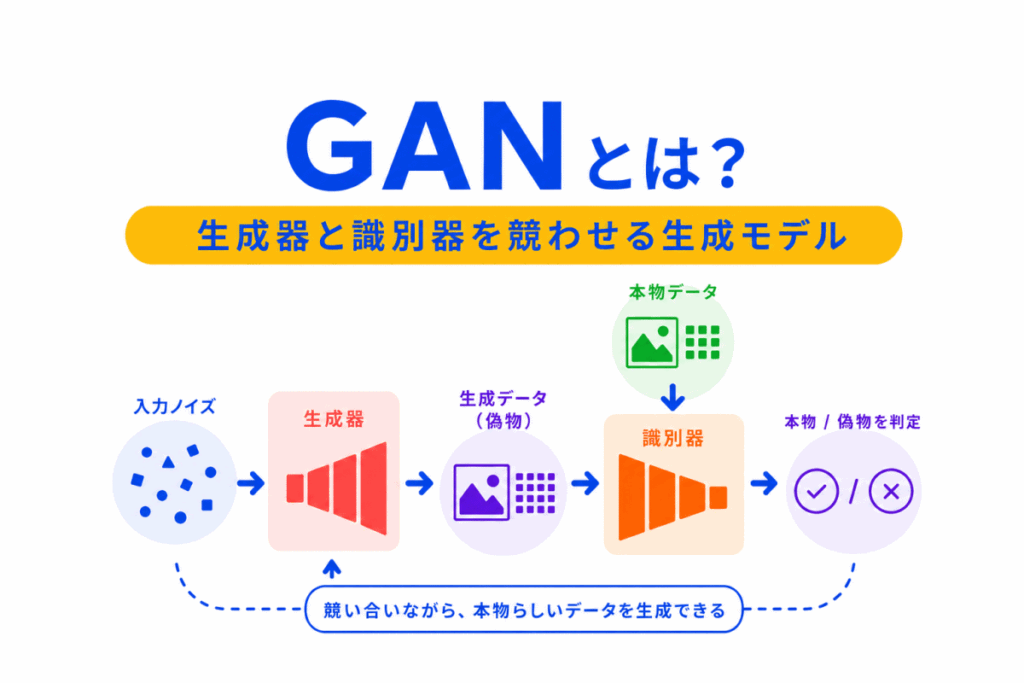
GAN は、生成器と識別器を競わせながら、本物らしいデータを作る生成モデルです。
G検定では、GAN の細かい数式よりも、「生成器がデータを作る」、「識別器が本物か偽物かを判定する」、「2つを競わせることで生成器が上達する」という流れを理解することが大切です。
この記事では、GAN の意味、生成器と識別器の役割、敵対的学習の考え方、VAEとの違い、ディープフェイクとの関係を、AIの学習をはじめたばかりの人にもわかりやすく整理します。
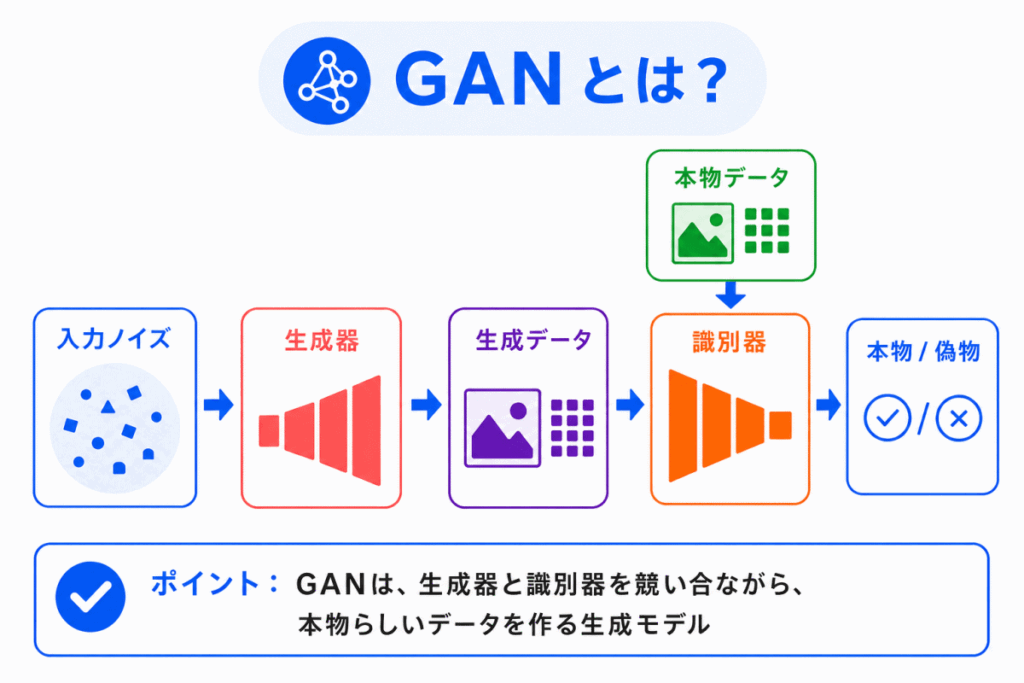
GAN とは、Generative Adversarial Networkの略です。
日本語では、敵対的生成ネットワークと呼ばれます。
GAN は、本物らしい画像やデータを作るための生成モデルです。
特徴は、1つのモデルだけで学習するのではなく、次の2つのモデルを使うことです。
| 要素 | 役割 | 一言でいうと |
|---|---|---|
| 生成器 | 本物らしい偽物のデータを作る | だます側 |
| 識別器 | 本物か偽物かを見分ける | 見破る側 |
生成器は、識別器をだませるようにデータを作ります。
識別器は、生成器が作ったデータを見破れるように学習します。
この2つが競い合うことで、生成器はだんだん本物らしいデータを作れるようになります。
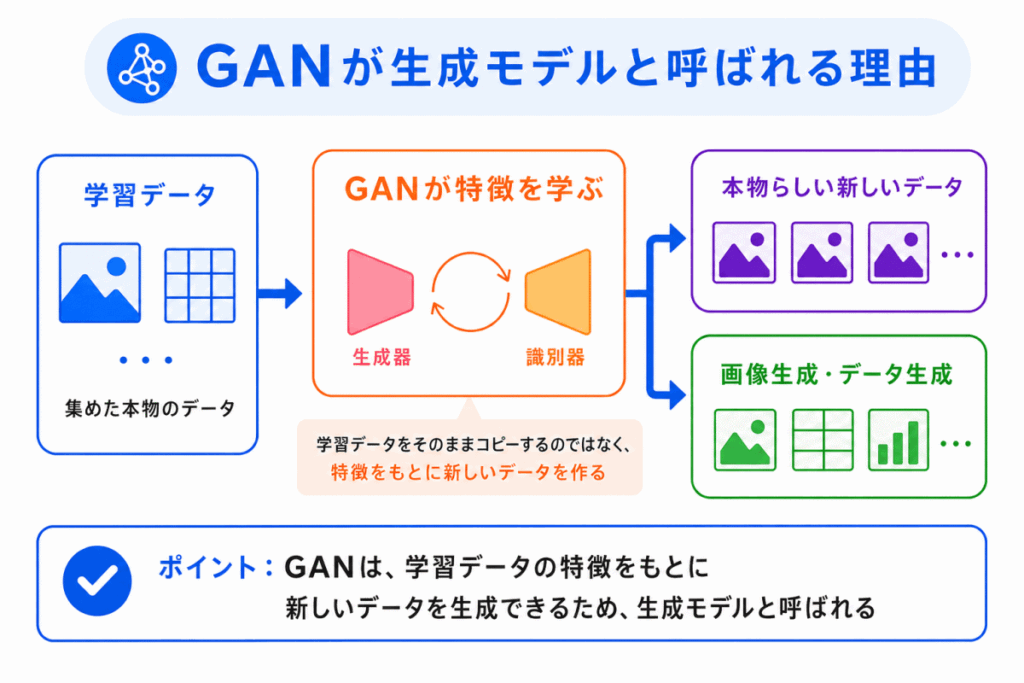
GAN は、新しいデータを作ることを目的にしたモデルです。
たとえば、画像を学習した GAN は、学習データに似た新しい画像を作ることができます。
ここで重要なのは、単に学習データをコピーしているわけではないという点です。
GAN は、学習データの特徴をもとに、本物らしく見える新しいデータを生成します。
そのため、画像生成、顔画像生成、データ拡張、ディープフェイクなどと関係します。
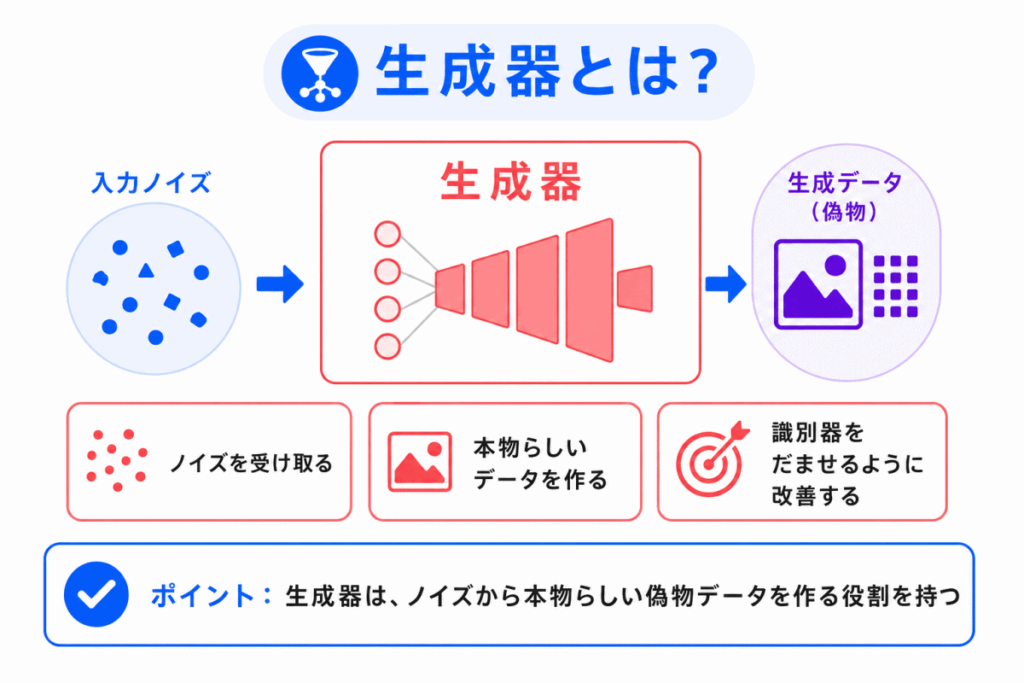
生成器は、偽物のデータを作る部分です。
英語では Generator と呼ばれます。
生成器は、最初から本物らしいデータを作れるわけではありません。
はじめは不自然なデータを作ります。
しかし、識別器に「偽物」と見破られることで、少しずつ改善されます。
つまり、生成器は識別器をだませるように学習していきます。
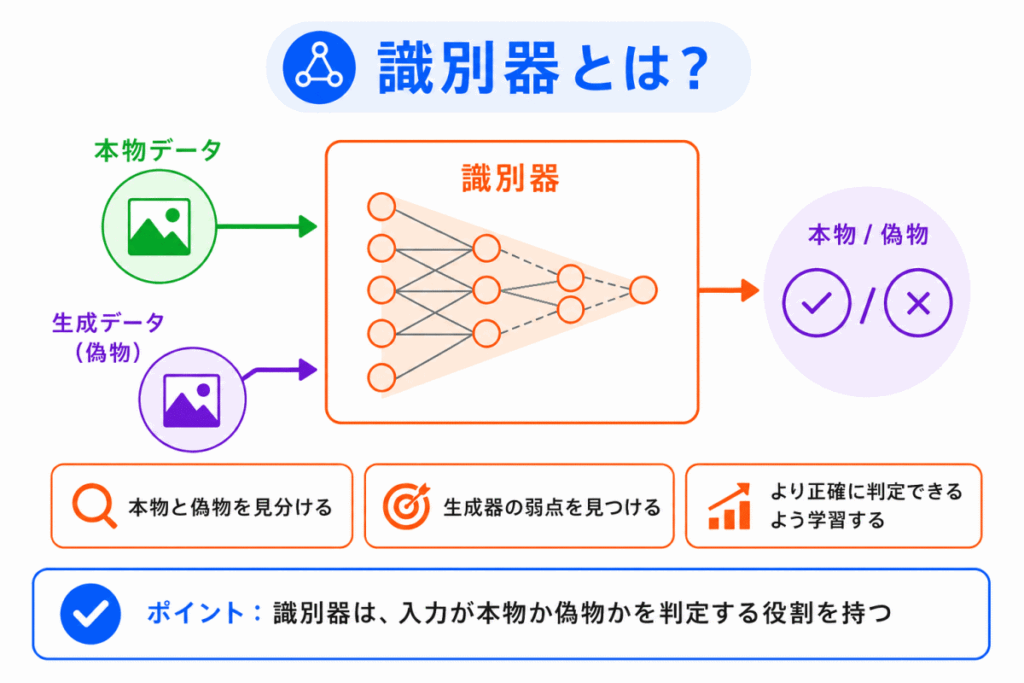
識別器は、入力されたデータが本物か偽物かを見分ける部分です。
英語では Discriminator と呼ばれます。
識別器には、本物のデータと、生成器が作った偽物のデータが入力されます。
識別器は、それらを見比べながら、本物と偽物を区別できるように学習します。
ただし、生成器も改善されるため、識別器も簡単には見破れなくなっていきます。
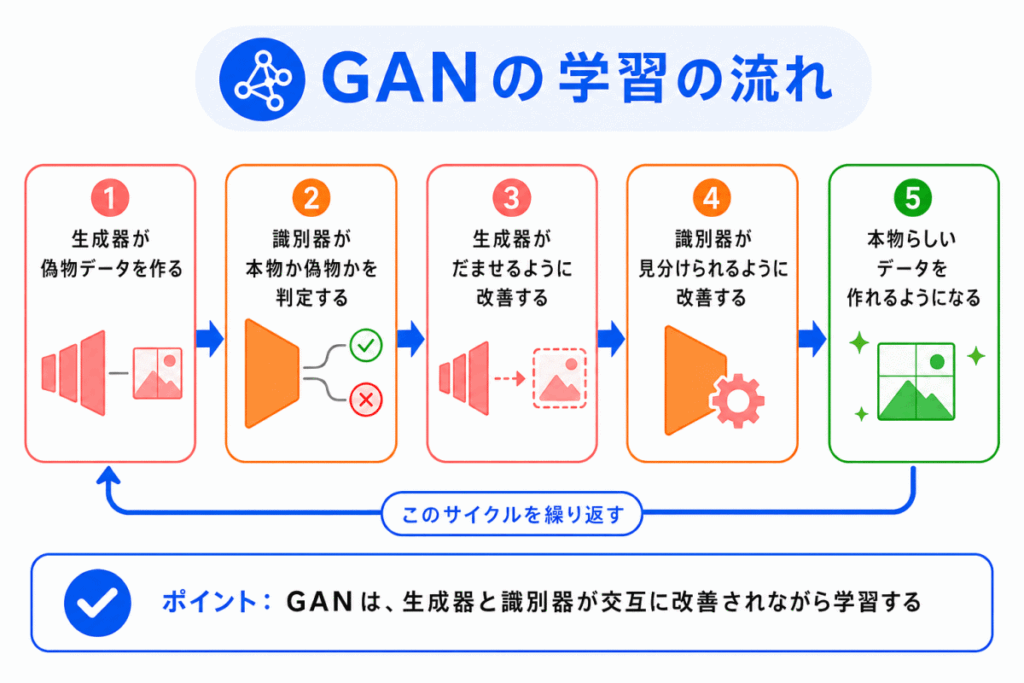
GAN の学習は、生成器と識別器が競い合う流れで理解するとわかりやすいです。
このように、GAN では生成器と識別器が同時に学習します。
片方だけが学習するのではなく、互いに影響しながら性能を高めていく点が特徴です。
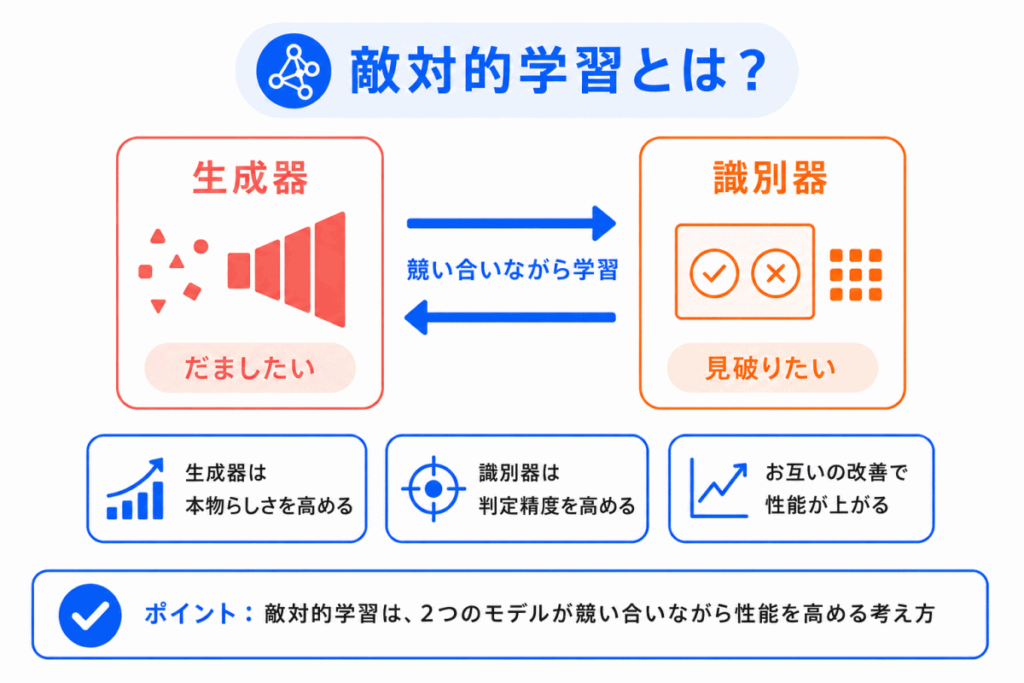
敵対的学習とは、2つのモデルが競い合いながら学習する考え方です。
GAN では、生成器と識別器が敵対的な関係になります。
生成器は、識別器をだましたい。
識別器は、生成器の偽物を見破りたい。
この関係があるため、GAN は敵対的生成ネットワークと呼ばれます。
ただし、「敵対」といっても、悪い意味ではありません。
学習の仕組みとして、お互いを高め合っていると考えると理解しやすくなります。
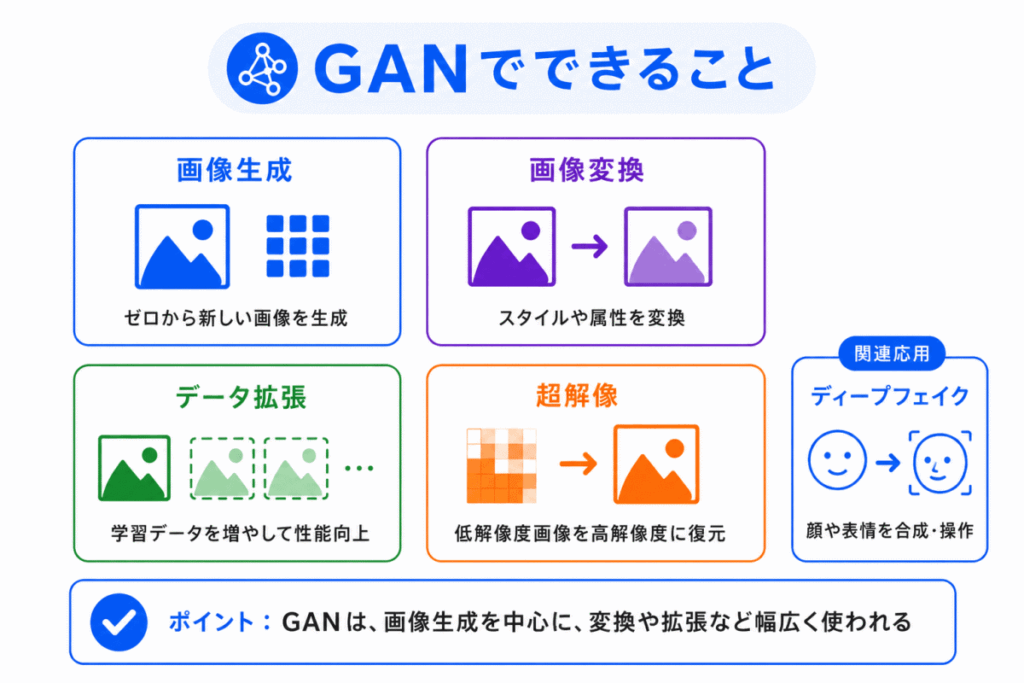
GAN は、特に画像生成の分野でよく使われてきました。
代表的な活用例は次の通りです。
| できること | 内容 |
|---|---|
| 画像生成 | 本物らしい画像を新しく作る |
| 画像変換 | 画像のスタイルや見た目を変える |
| データ拡張 | 学習データに似たデータを増やす |
| 超解像 | 低解像度の画像を高解像度に近づける |
| ディープフェイク | 人物の顔や映像を本物らしく生成・加工する |
G検定では、GAN の応用例として、画像生成やディープフェイクとの関係を押さえておくと理解しやすくなります。
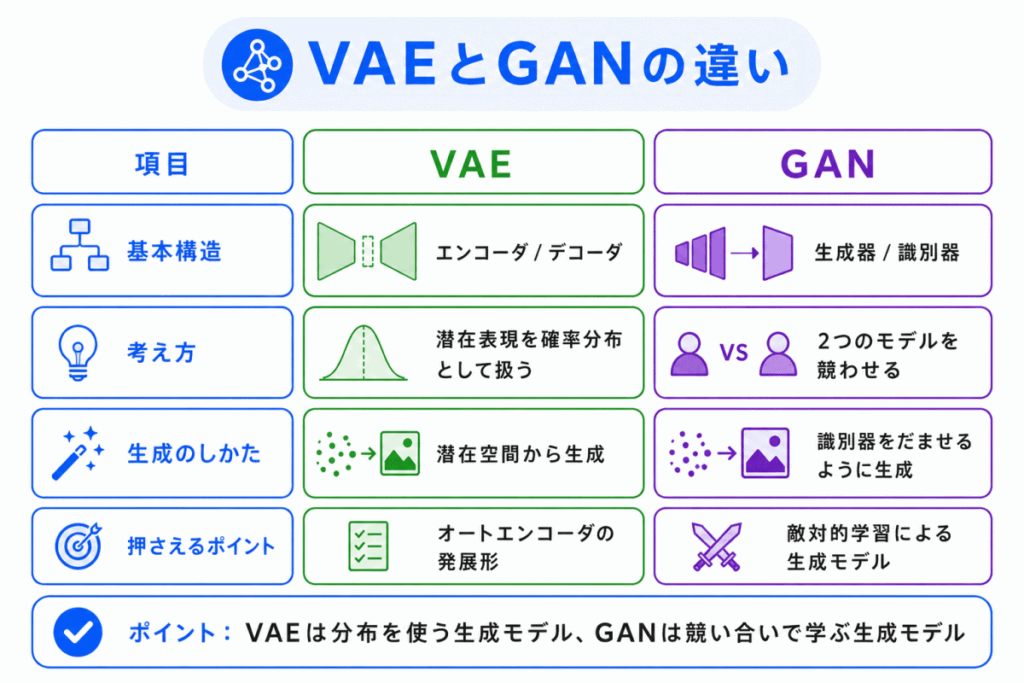
GAN と一緒に混同しやすいのが VAE です。
どちらも生成モデルですが、仕組みが違います。
| 項目 | VAE | GAN |
|---|---|---|
| 正式名称 | Variational Autoencoder | Generative Adversarial Network |
| 基本構造 | エンコーダとデコーダ | 生成器と識別器 |
| 考え方 | 潜在表現を確率分布として扱う | 2つのモデルを競わせる |
| 生成の方法 | 潜在空間から値を取り出して生成する | 生成器が識別器をだませるように生成する |
| 押さえるポイント | オートエンコーダの発展形 | 敵対的学習による生成モデル |
G検定では、この違いを整理しておくことが大切です。
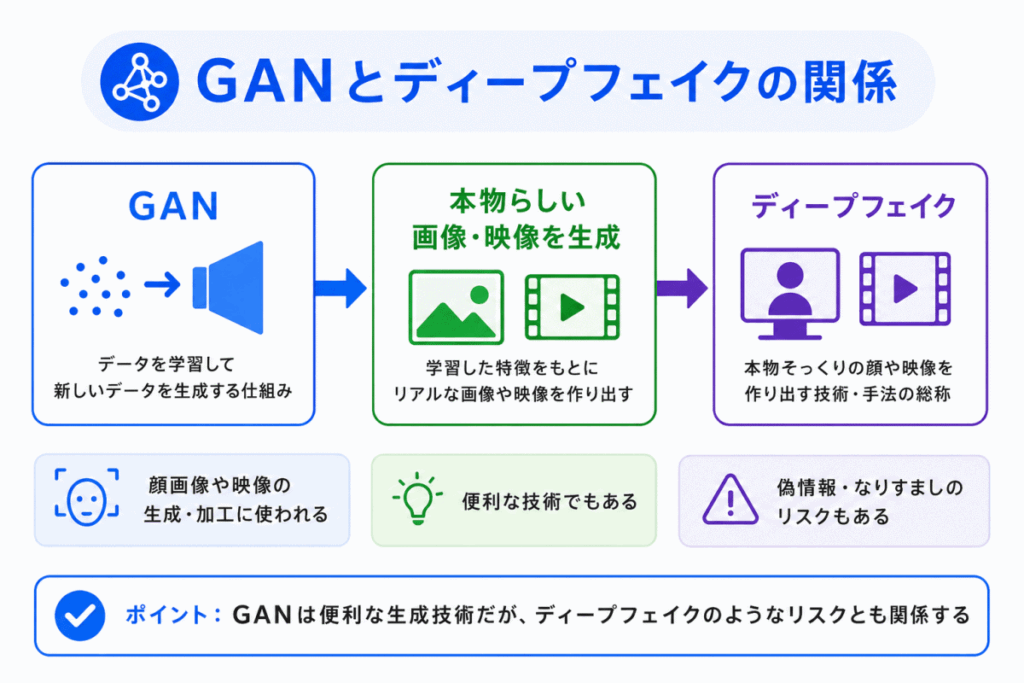
GAN は、ディープフェイクと関係の深い技術として説明されることがあります。
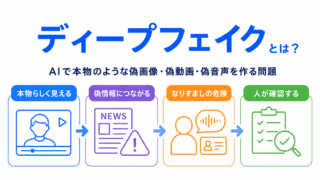
ディープフェイクとは、AIを使って、本物のように見える偽の画像、音声、動画などを作る技術や問題を指します。
GAN は、本物らしいデータを生成できるため、顔画像生成や映像加工と関係します。
そのため、GAN は技術として便利な一方で、偽情報、なりすまし、権利侵害などのリスクともつながります。
G検定では、GAN を技術面だけでなく、生成AIリスクやAI倫理の文脈でも理解しておくとよいです。
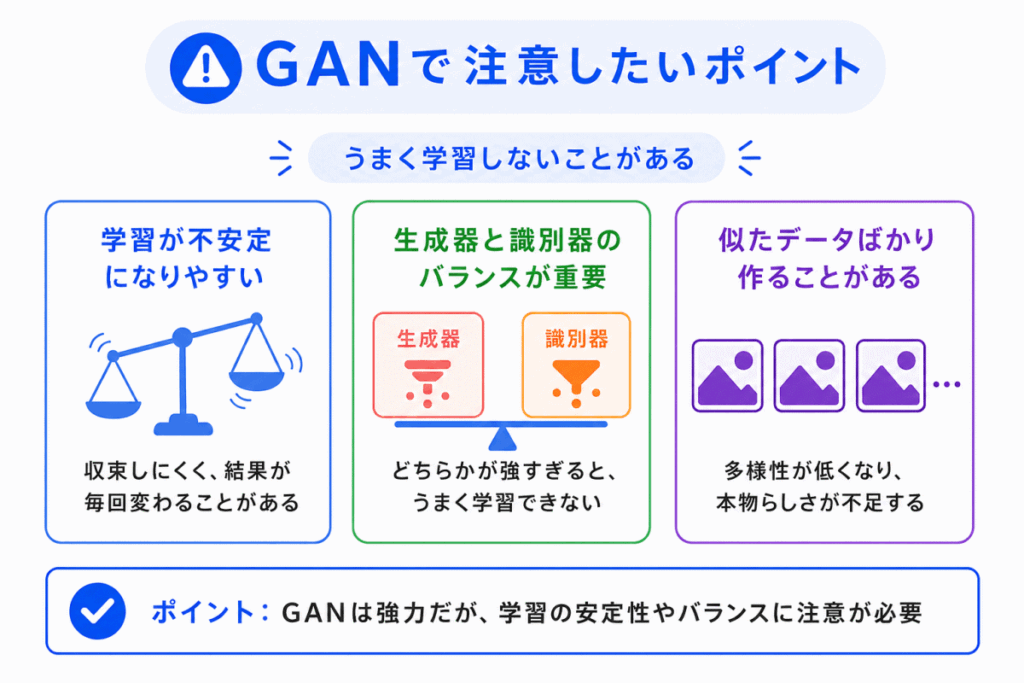
GAN は強力な生成モデルですが、学習が簡単なモデルではありません。
生成器と識別器のバランスが崩れると、うまく学習できないことがあります。
たとえば、識別器が強すぎると、生成器がなかなか改善できません。
逆に、生成器が一部の似たようなデータばかり作るようになることもあります。
G検定では、細かい学習上の問題まで深く覚える必要はありません。
ただし、GAN は生成器と識別器のバランスが重要なモデルだと理解しておくとよいです。
GAN は、生成モデル、ディープラーニングの要素技術、生成AIリスクとつながります。
G検定では、次のような観点で整理しておくと対応しやすくなります。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| GANの意味 | 生成器と識別器を競わせる生成モデル |
| 生成器の役割 | 本物らしい偽物のデータを作る |
| 識別器の役割 | 入力が本物か偽物かを判定する |
| 敵対的学習 | 2つのモデルが競い合いながら学習する考え方 |
| VAEとの違い | VAEは潜在表現を確率分布として扱い、GANは生成器と識別器を競わせる |
| 応用例 | 画像生成、画像変換、データ拡張、ディープフェイクなど |
特に、「生成器」、「識別器」、「敵対的学習」の3つは重要です。
GAN は、言葉だけを見ると難しく感じます。
しかし、試験対策では「作る側」と「見破る側」が競い合うモデルと考えると理解しやすくなります。
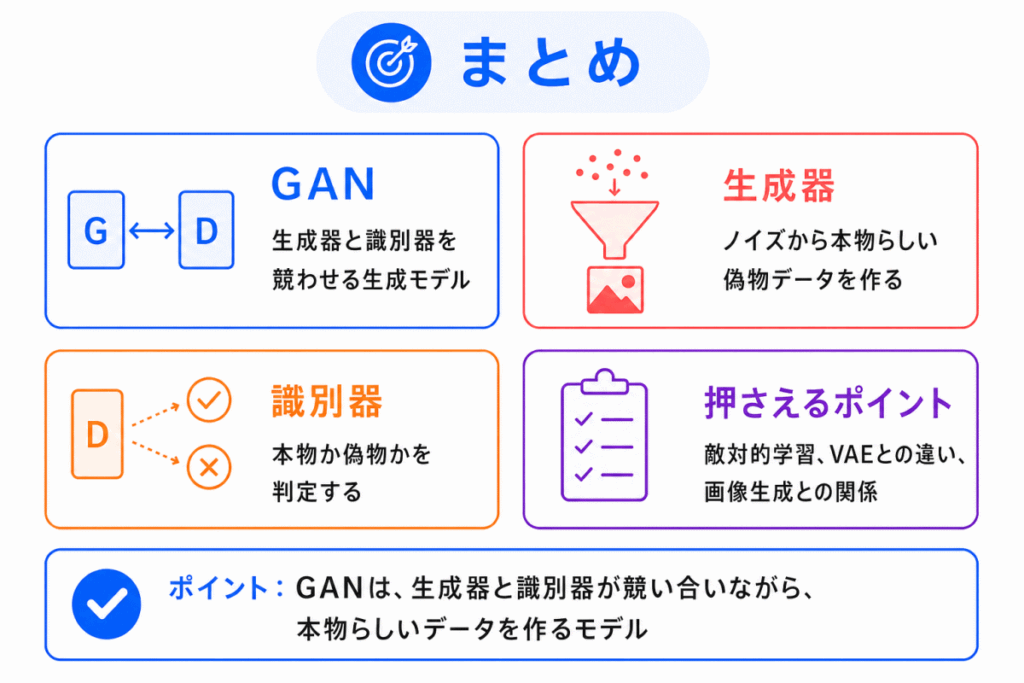
GAN は、生成器と識別器を競わせながら、本物らしいデータを作る生成モデルです。
最後に、重要ポイントを整理します。
GAN を理解すると、画像生成、ディープフェイク、生成AIリスクなどの話もつながりやすくなります。
G検定では、細かい数式よりも、生成器と識別器がどのように競い合うのかを押さえておきましょう。
VAEとの違いを確認するなら、こちらの記事がおすすめです。
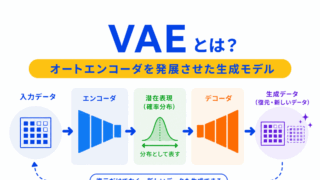
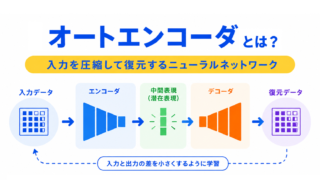
オートエンコーダの基本から確認するなら、こちらの記事がおすすめです。
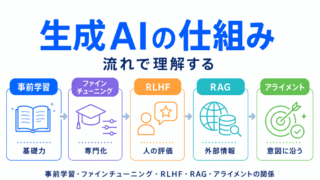
生成AI全体の流れを確認するなら、こちらの記事がおすすめです。
ディープフェイクとの関係を確認するなら、こちらの記事がおすすめです。
ディープラーニングの要素技術をまとめて確認するなら、こちらの記事がおすすめです。

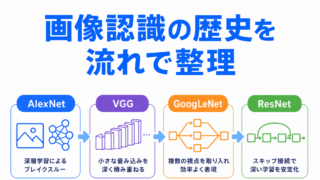
画像生成や画像認識とのつながりを確認するなら、こちらの記事がおすすめです。
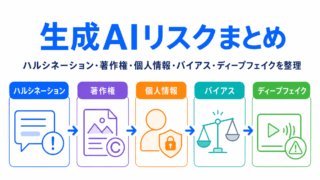
生成AIのリスク面も確認するなら、こちらの記事がおすすめです。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

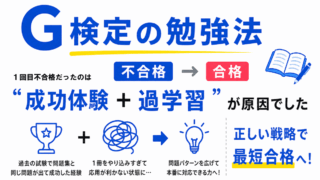
1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認