【G検定対策】個人情報保護とAIとは?|AI活用でなぜプライバシーが重要になるのか
seo-webmaster
G検定対策ブログ
生成AIは、文章・画像・音声・動画などを作れる便利な技術です。
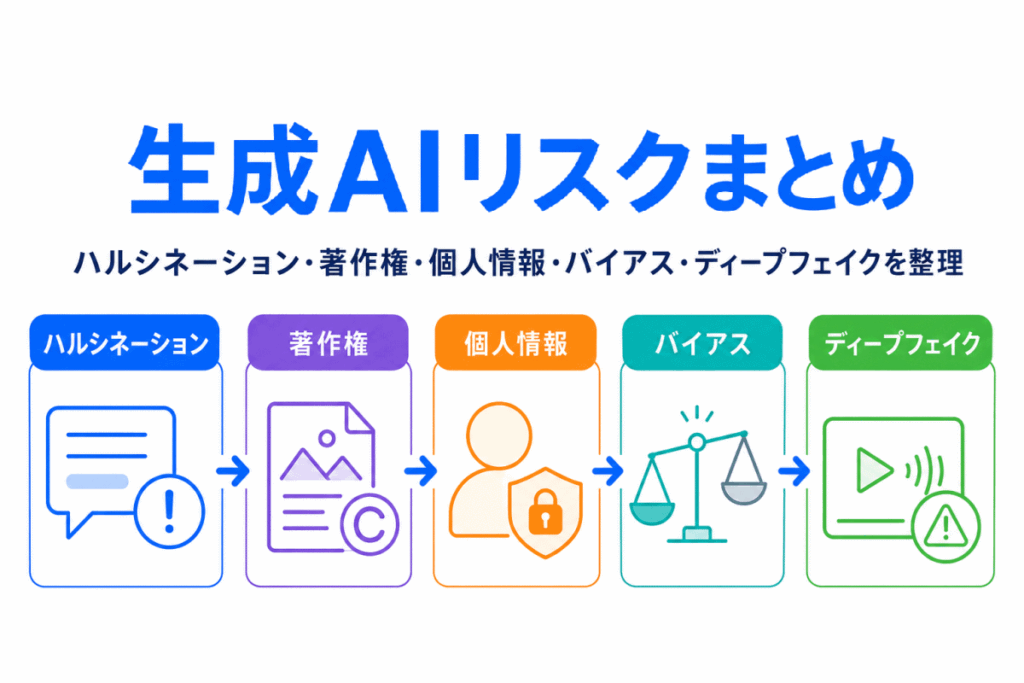
一方で、便利さが広がるほど、誤情報、権利侵害、個人情報の扱い、不公平な判断、偽コンテンツといったリスクも目立つようになります。
G検定では、生成AIそのものの仕組みだけでなく、社会で安全に使うための考え方も問われます。
この記事では、生成AIに関係する代表的なリスクをバラバラに覚えるのではなく「何が問題になり、どのテーマとつながるのか」という流れで整理します。
生成AIは、文章を作る、画像を作る、要約する、質問に答える、アイデアを出すなど、さまざまな場面で使われます。
しかし、生成AIは万能ではありません。
生成AIのリスクは、AIが使えないから起こるのではなく、便利に使えるからこそ起こる問題 です。
たとえば、もっともらしい文章を作れるからハルシネーションが問題になります。自然な画像や音声を作れるからディープフェイクが問題になります。
大量のデータを使うから著作権や個人情報保護が問題になります。
つまり、生成AIのリスクは次のように整理できます。
| 観点 | 主なリスク |
|---|---|
| 内容の正しさ | ハルシネーション |
| 権利 | 著作権 |
| 情報の扱い | 個人情報保護 |
| 公平性 | アルゴリズムバイアス |
| 偽コンテンツ | ディープフェイク |
| 説明責任 | XAI |
| 管理体制 | AIガバナンス |
生成AIを理解するときは、技術だけでなく、社会でどう使うか まで含めて考えることが重要です。
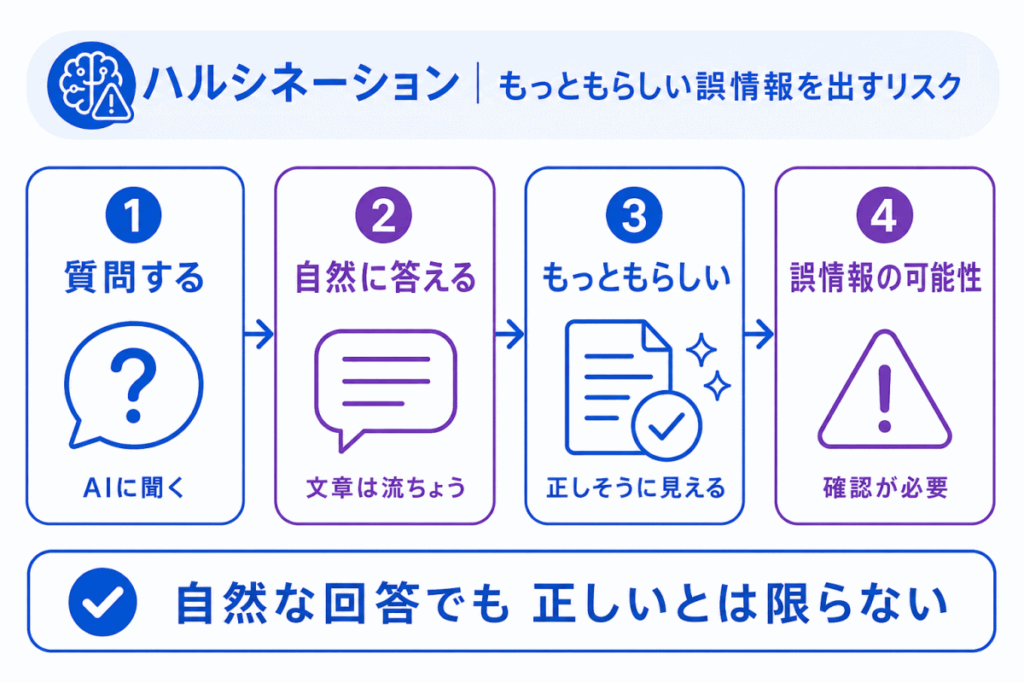
ハルシネーションとは、AIが もっともらしく間違った内容を出してしまう現象 です。
生成AIは、質問に対して自然な文章で答えることができます。しかし、その回答が常に正しいとは限りません。
存在しない情報を本当のように説明したり、事実と異なる内容を自信ありげに出したりすることがあります。
ここで重要なのは、生成AIが「正解を知っている」のではなく、学習したパターンをもとに それらしい回答を生成している という点です。
そのため、次のような場面では注意が必要です。
| 場面 | 注意点 |
|---|---|
| 調べもの | 回答をそのまま信じない |
| 医療・法律・金融 | 専門家や公的情報で確認する |
| 引用・出典 | 存在しない出典の可能性がある |
| 数値・日付 | 最新情報と一致するとは限らない |
G検定では、ハルシネーションを「AIが意図的に嘘をつくこと」ではなく、「もっともらしい誤情報を生成する問題」として押さえると理解しやすいです。
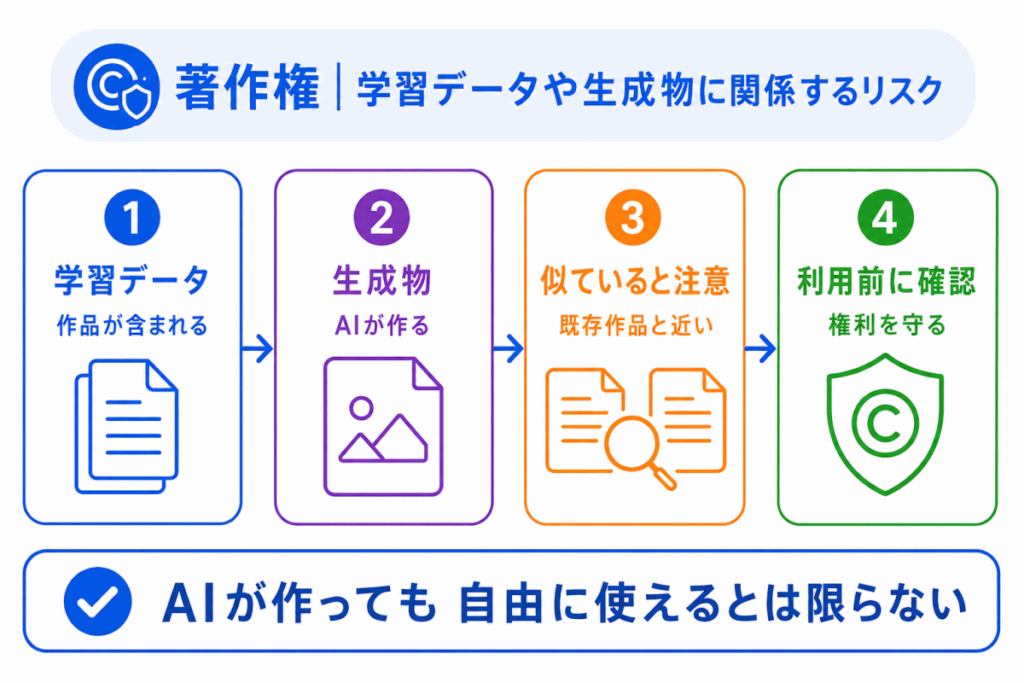
生成AIでは、著作権の問題も重要です。
生成AIは、大量の文章・画像・音声などのデータからパターンを学習します。そのため、学習データに著作物が含まれている場合や、生成された内容が既存作品に似ている場合に、著作権上の問題が生じる可能性があります。
著作権のリスクは、主に次の3つで整理できます。
| 観点 | 内容 |
|---|---|
| 学習データ | 著作物が使われている可能性がある |
| 生成物 | 既存作品に似る可能性がある |
| 利用方法 | 商用利用や公開で問題になる場合がある |
ここで大切なのは、AIが作ったから自由に使えるとは限らない という点です。
生成AIで作成した文章や画像であっても、既存作品と似ている場合や、他人の権利を侵害する使い方をした場合には問題になる可能性があります。
G検定では、著作権を単なる法律問題としてではなく、生成AIの学習データ・生成物・利用方法に関係するリスク として整理するとよいです。
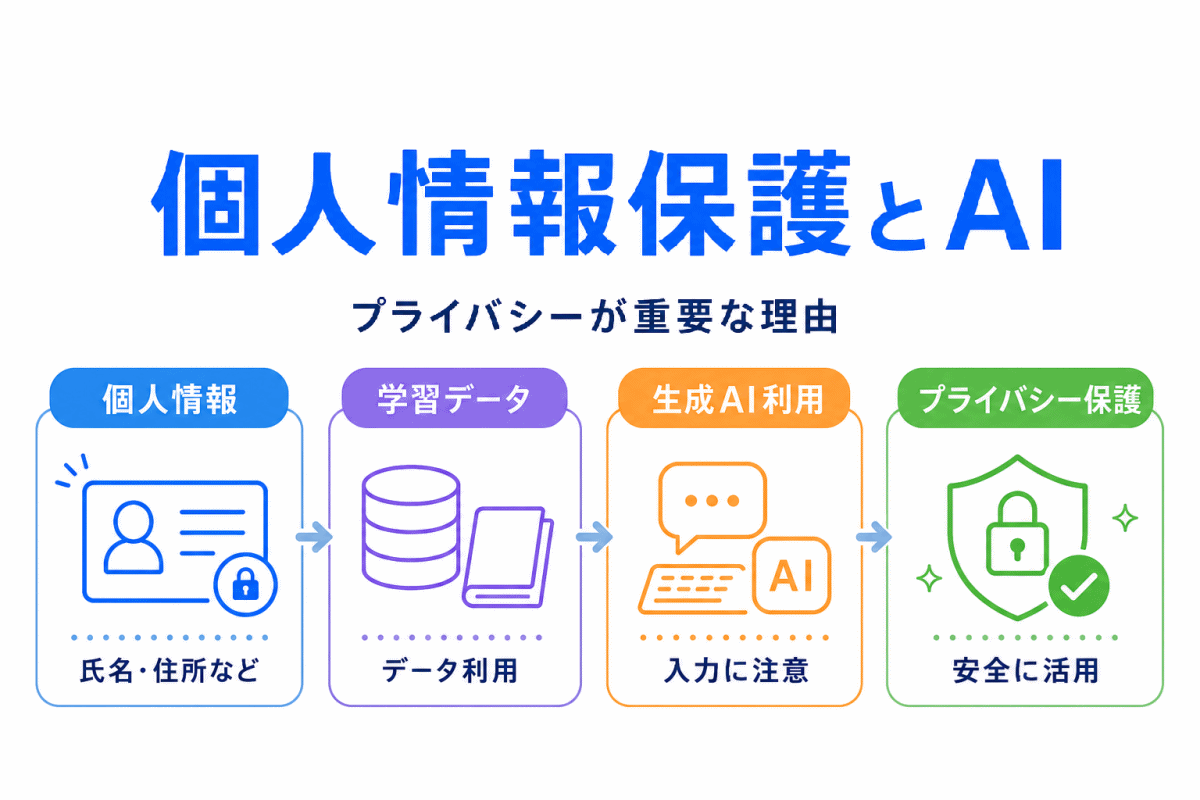
生成AIでは、個人情報保護も重要なテーマです。
たとえば、氏名、住所、電話番号、メールアドレス、顔写真、音声、職歴、病歴など、個人を識別できる情報をAIに入力すると、プライバシー上の問題が生じる可能性があります。
特に注意したいのは、入力した情報がどのように扱われるのかを理解しないまま使ってしまうこと です。
| 例 | リスク |
|---|---|
| 顧客情報を入力する | 個人情報の漏えいにつながる可能性 |
| 社内情報を入力する | 機密情報が外部に出る可能性 |
| 顔写真を使う | 本人の同意や肖像に関係する可能性 |
| 音声を使う | なりすましやディープフェイクに関係する可能性 |
個人情報保護では、AIの性能よりも、何を入力してよいのか、どこまで使ってよいのかを考える必要があります。
G検定では、個人情報保護を「AIが個人情報を覚えるかどうか」だけでなく、入力・保存・利用・共有の管理が重要なテーマ として押さえると理解しやすいです。
アルゴリズムバイアスとは、AIの判断に偏りが生じ、特定の人や集団にとって不公平な結果になる問題です。
AIは、学習データからパターンを学びます。そのため、学習データに偏りがあると、AIの判断にも偏りが反映されることがあります。
たとえば、採用、融資、広告配信、医療判断などの場面では、AIの判断が人に大きな影響を与えることがあります。
| 原因 | 起こりうる問題 |
|---|---|
| 学習データが偏っている | 特定の集団に不利な判断をする |
| 過去の判断が偏っている | 過去の不公平を再現する |
| 評価方法が不十分 | 偏りに気づきにくい |
| 人間が確認しない | 不公平な結果がそのまま使われる |
重要なのは、AIは自動的に公平さを理解しているわけではないという点です。
AIが出した結果であっても、その判断が公平かどうかは、人間が確認する必要があります。
試験では、アルゴリズムバイアスを「データの偏りがAIの判断に影響する問題」として押さえるとよいです。
ディープフェイクとは、AIを使って、本物のように見える偽画像・偽動画・偽音声を作る技術や、その悪用による問題です。
生成AIによって、存在しない人物の画像を作ったり、実在人物が話しているような動画や音声を作ったりすることが可能になっています。
ディープフェイクの問題は、見た人が本物だと信じてしまいやすいこと です。
| 種類 | 例 |
|---|---|
| 偽画像 | 存在しない人物や場面を作る |
| 偽動画 | 実在人物が発言したように見せる |
| 偽音声 | 本人の声に似せて話したように聞かせる |
| なりすまし | 本人のふりをして信用させる |
ディープフェイクは、偽情報、なりすまし、信用低下、社会的混乱につながる可能性があります。
試験では、ディープフェイクをハルシネーションと混同しないことが重要です。
ハルシネーションは、主に もっともらしい誤情報の回答 です。
ディープフェイクは、主に 本物らしい偽画像・偽動画・偽音声 です。
XAIとは、Explainable AI の略で、日本語では説明可能AIと呼ばれます。
AIの判断結果が出ても、なぜその結果になったのかがわからないと、利用者は安心して使えません。特に、医療、金融、採用、行政などの分野では、AIの判断理由が重要になります。
XAIは、AIの判断を完全に人間と同じように説明するというより、AIの判断を人間が理解・確認しやすくするための考え方 です。
| 観点 | 内容 |
|---|---|
| 透明性 | 判断の流れを見えやすくする |
| 説明責任 | なぜその判断になったか説明できるようにする |
| 信頼性 | 利用者が安心して使えるようにする |
| 改善 | 誤りや偏りを見つけやすくする |
XAIは、ハルシネーション、バイアス、個人情報保護などのリスクと直接つながります。
なぜなら、AIの判断理由が見えなければ、間違い・偏り・不適切な利用に気づきにくいからです。
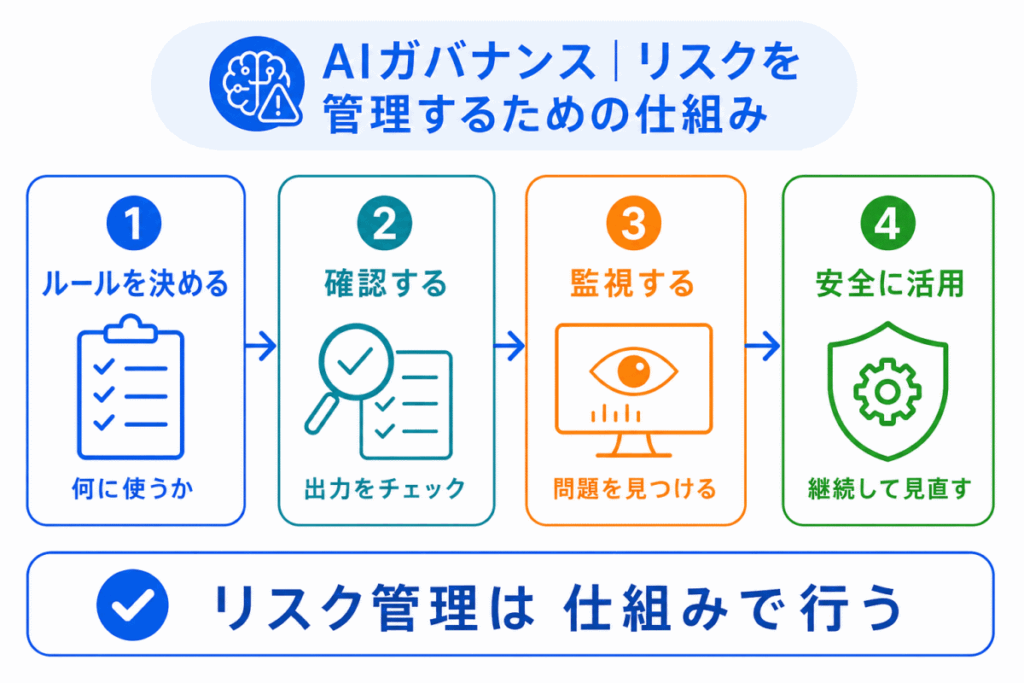
AIガバナンスとは、AIを安全に活用するためのルールや管理体制のことです。
生成AIにはさまざまなリスクがありますが、リスクをゼロにすることは簡単ではありません。そのため、組織や社会として、AIをどのように使うかを決め、継続的に管理する必要があります。
AIガバナンスでは、次のような取り組みが重要になります。
| 取り組み | 内容 |
|---|---|
| 利用ルール | 何に使ってよいかを決める |
| 入力管理 | 個人情報や機密情報を守る |
| 出力確認 | AIの回答を人間が確認する |
| 表示 | AI生成物であることを示す |
| 教育 | 利用者がリスクを理解する |
| 監視 | 問題が起きていないか確認する |
AIガバナンスは、単なる規制ではありません。
生成AIを使わないための考え方ではなく、安全に使うための仕組み です。
試験では、AIガバナンスを「AIの利用を止めるもの」ではなく、AIのリスクを管理し、信頼できる形で活用するための考え方 として押さえるとよいです。

ここまでの内容を整理すると、生成AIのリスクは次のように関係しています。
| テーマ | 主な問題 | 押さえるポイント |
|---|---|---|
| ハルシネーション | 誤情報 | もっともらしい間違いに注意 |
| 著作権 | 権利侵害 | 学習データ・生成物・利用方法が関係 |
| 個人情報保護 | プライバシー | 入力情報や顔・声の扱いに注意 |
| アルゴリズムバイアス | 不公平な判断 | データの偏りが判断に影響 |
| ディープフェイク | 偽コンテンツ | 本物らしい画像・動画・音声に注意 |
| XAI | 判断理由の不透明さ | 説明可能性が信頼につながる |
| AIガバナンス | 管理不足 | ルール・確認・監視が重要 |
生成AIのリスクを覚えるときは、用語だけを暗記するよりも、「何に対するリスクなのか」で整理すると理解しやすくなります。
ハルシネーション、ディープフェイク、生成AIリスクは、生成AIを使うときの注意点としてまとめて出てきやすい用語です。
どのリスクを指しているのかを分けて理解することが大切です。
| 用語 | 意味 | 見分け方 |
|---|---|---|
| ハルシネーション | AIがもっともらしい誤情報を出してしまう現象 | 文章や回答の間違い |
| ディープフェイク | AIで本物らしい偽画像・偽動画・偽音声を作る技術や問題 | 偽の画像・動画・音声 |
| 生成AIリスク | 著作権、個人情報、偽情報、バイアスなど、生成AI利用時の幅広いリスク | リスク全体をまとめた言葉 |
G検定では、生成AIのリスクについて、単独の用語だけでなく、関連するテーマとの違いや関係が問われる可能性があります。
特に押さえたいのは、次のような観点です。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| ハルシネーション | もっともらしい誤情報を生成する問題 |
| ディープフェイク | 本物らしい偽画像・偽動画・偽音声の問題 |
| 著作権 | 学習データや生成物の権利に関係 |
| 個人情報保護 | 入力情報や顔・声などの扱いに関係 |
| アルゴリズムバイアス | データの偏りが不公平な判断につながる |
| XAI | 判断理由を説明しやすくする考え方 |
| AIガバナンス | AIを安全に使うためのルールや管理体制 |
たとえば、次のような選択肢には注意が必要です。
これらは、用語の意味を少しずらした誤りです。
試験では、似たテーマを混同しないこと が重要です。
特に、ハルシネーションとディープフェイク、AI倫理とAIガバナンス、著作権と個人情報保護は混同しやすいので注意しましょう。
生成AIは、文章・画像・音声・動画などを作れる便利な技術です。
しかし、その便利さの裏側には、ハルシネーション、著作権、個人情報保護、アルゴリズムバイアス、ディープフェイクなどのリスクがあります。
大切なのは、生成AIを「危険だから使わない」と考えることではありません。
生成AIのリスクを理解したうえで、安全に使うためのルールや確認方法を持つこと です。
ハルシネーションは、もっともらしい誤情報の問題です。
ディープフェイクは、本物らしい偽コンテンツの問題です。
著作権や個人情報保護は、データや生成物の扱いに関係します。アルゴリズムバイアスは、不公平な判断につながる問題です。
そして、XAIやAIガバナンスは、これらのリスクを確認し、管理するための考え方です。
試験では、個別用語を暗記するだけでなく、それぞれのリスクが何と関係しているのか を整理しておくと、問い方が変わっても対応しやすくなります。
生成AIのリスクは、ハルシネーション、著作権、個人情報、バイアス、ディープフェイクなどを別々に覚えるより、AIを安全に使うための注意点としてまとめて整理すると理解しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| ハルシネーションとは? | AIが誤情報を出す理由/自信満々に間違える仕組み/生成AI利用時の注意点 |
| ディープフェイクとは? | 画像・動画・音声の偽コンテンツ/なりすまし・偽情報のリスク/生成AI時代の注意点 |
| 著作権と生成AI | 学習データと著作権/生成物の扱い/AI活用時の権利理解 |
| 個人情報保護とAI | 入力情報の扱い/プライバシー保護/AI利用時に注意する情報 |
| アルゴリズムバイアスとは? | AIの不公平な判断/データの偏り/AI倫理との関係 |
| 説明可能AI(XAI)とは? | AIの判断理由を説明する考え方/ブラックボックス問題/信頼性との関係 |
| AIガバナンスとは? | AIを安全に使うルール作り/リスク管理/組織でのAI活用 |
| 国内外のAIガイドラインとは? | AIガイドライン/AI規制/AIガバナンス/リスク管理 |
| 生成AIリスク予想問題 | ハルシネーション/著作権/個人情報/バイアス/理解型予想問題 |
| 理解型予想問題まとめ | 混同しやすい用語/予想問題/分野別チェック |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。