【G検定対策】音声処理とは?|音声認識・音声データ・ディープラーニングとの関係を整理
seo-webmaster
G検定対策ブログ
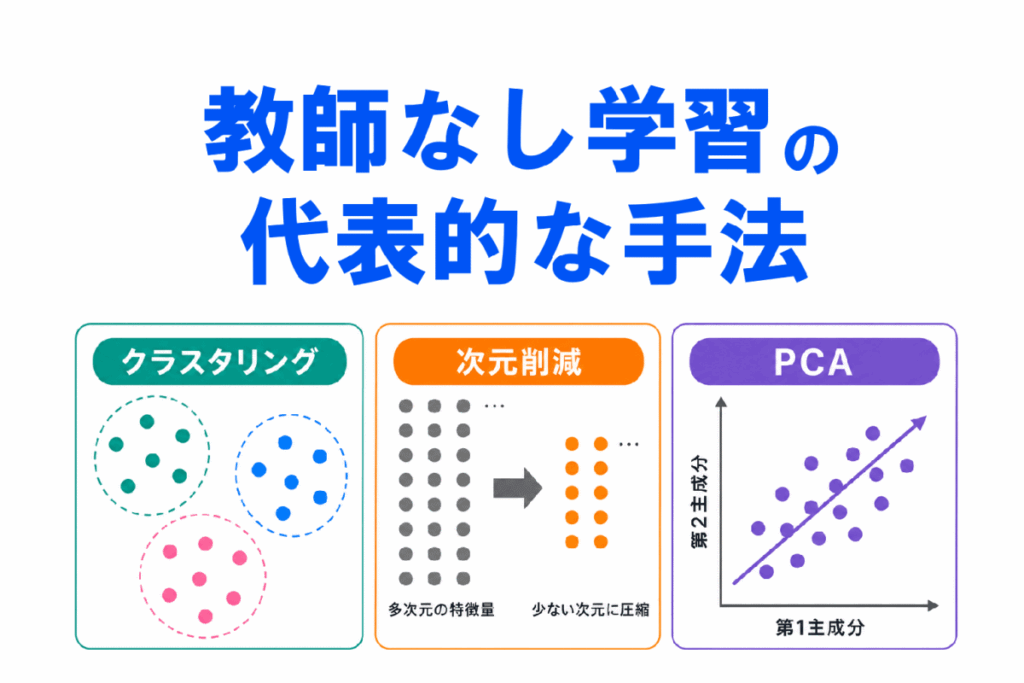
教師なし学習は、正解ラベル(答え)がないデータから、データの特徴やまとまりを見つける学習方法です。
教師あり学習では「犬か猫か」、「売上はいくらか」のように正解をもとに学習しますが、教師なし学習では、AIがデータの中にある似ている部分や構造を探します。
G検定では、教師あり学習との違いだけでなく、クラスタリング・次元削減・PCAの関係が問われやすいです。
この記事では、教師なし学習の代表的な手法を、AIの学習をはじめたばかりの人向けに整理します。
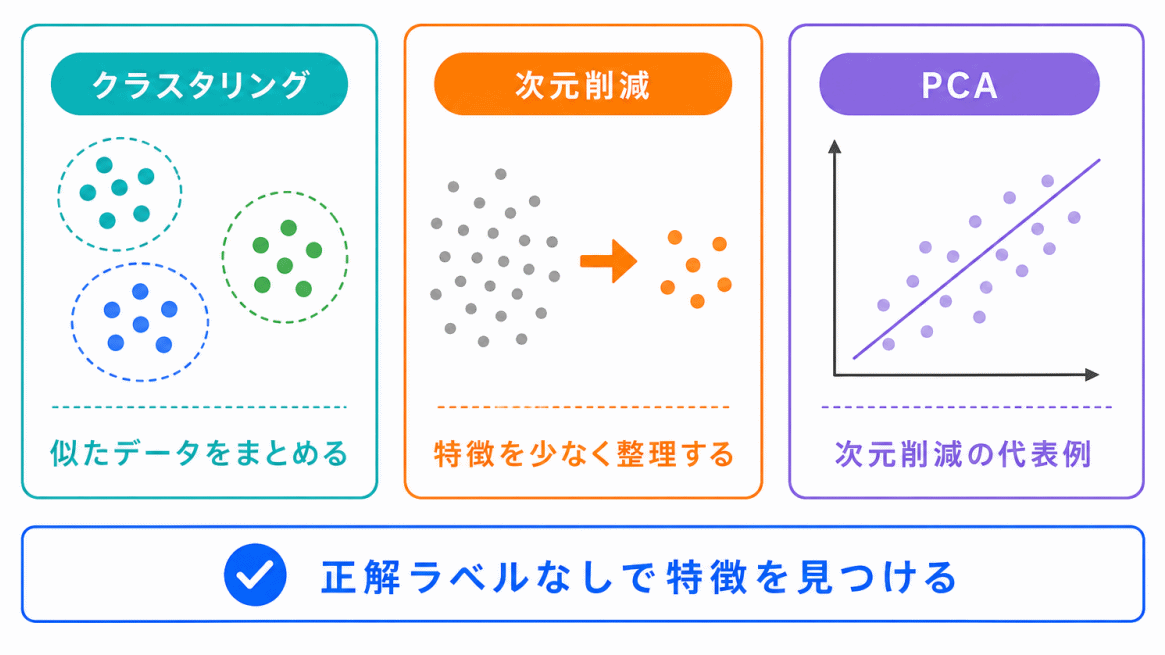
教師なし学習では、正解ラベルを使わずにデータの特徴を見つけます。
代表的な手法は、主に次の2つです。
| 手法 | 一言でいうと |
|---|---|
| クラスタリング | 似たデータをグループに分ける |
| 次元削減 | データの特徴を少ない情報に整理する |
さらに、次元削減の代表例として PCA(主成分分析) があります。
大事な整理は、次の通りです。
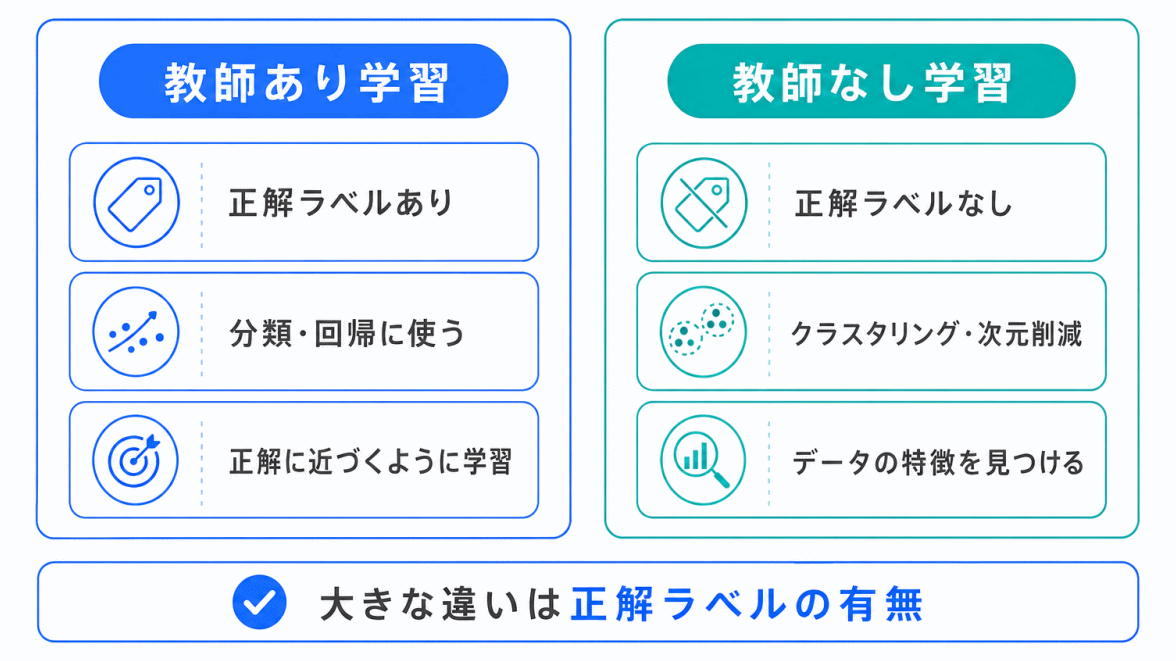
教師なし学習を理解するときは、教師あり学習との違いを先に押さえるとわかりやすいです。
| 学習方法 | 正解ラベル | 目的 |
|---|---|---|
| 教師あり学習 | ある | 正解に近い予測をする |
| 教師なし学習 | ない | データの構造や特徴を見つける |
たとえば、犬と猫の画像に「犬」、「猫」という正解ラベルがついていれば、教師あり学習です。
一方で、正解ラベルがない状態で、似た画像同士を自動でまとめる場合は、教師なし学習です。
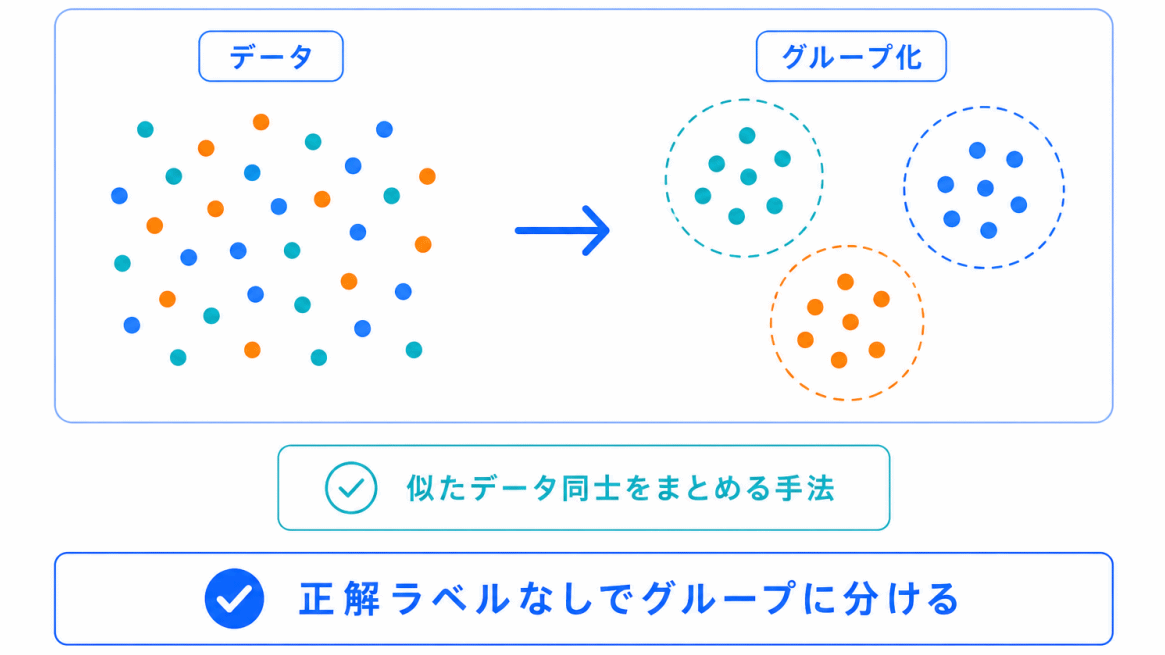
クラスタリングとは、似ているデータ同士をグループに分ける手法です。
たとえば、顧客データをもとに、購買傾向が似ている人をグループに分けるような場面で使われます。
| 観点 | 内容 |
|---|---|
| 目的 | 似たデータをまとめる |
| 正解ラベル | 使わない |
| 使われる例 | 顧客分類、画像の整理、文書の分類 |
ポイントは、最初から「この人はAグループ」と正解が決まっているわけではないことです。
データの特徴を見て、AIが似ているものをまとめます。
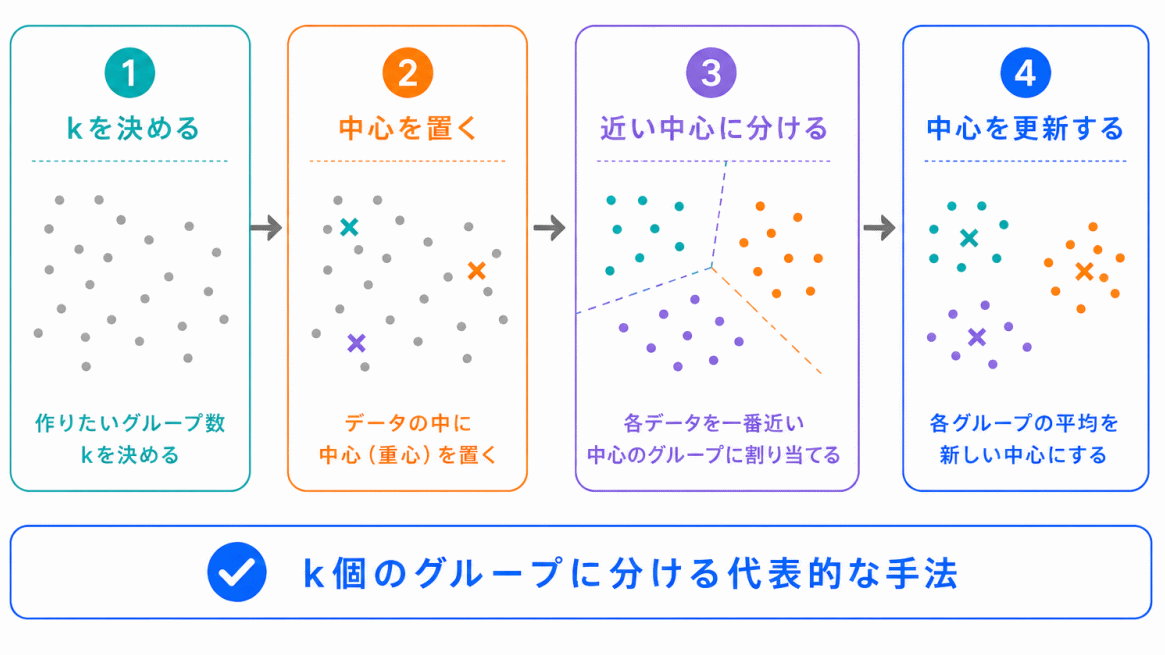
k-meansは、クラスタリングの代表的な手法です。
最初にグループ数を決めて、データを近いグループに分けていきます。
| 用語 | 一言でいうと |
|---|---|
| k | グループ数 |
| means | 平均 |
| k-means | 平均に近いデータを集める方法 |
たとえば、k=3と決めると、データを3つのグループに分けようとします。
G検定では、k-meansは クラスタリングの代表例 として整理しておくとよいです。
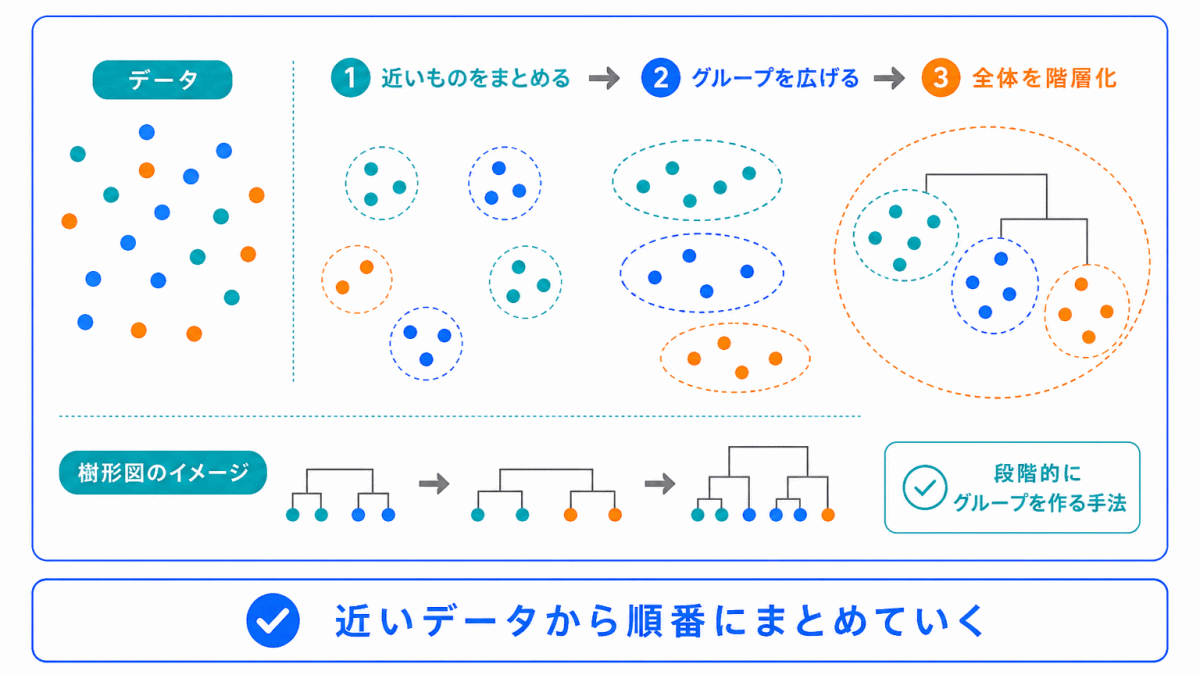
階層的クラスタリングは、データを段階的にまとめていく方法です。
最初はバラバラのデータを、似ているもの同士で少しずつまとめていきます。
| 手法 | イメージ |
|---|---|
| k-means | 最初にグループ数を決める |
| 階層的クラスタリング | 似ているものから段階的にまとめる |
階層的クラスタリングは、木の枝のような構造でグループの関係を表すことがあります。
細かい計算よりも、段階的にグループを作る方法 と覚えるとよいです。
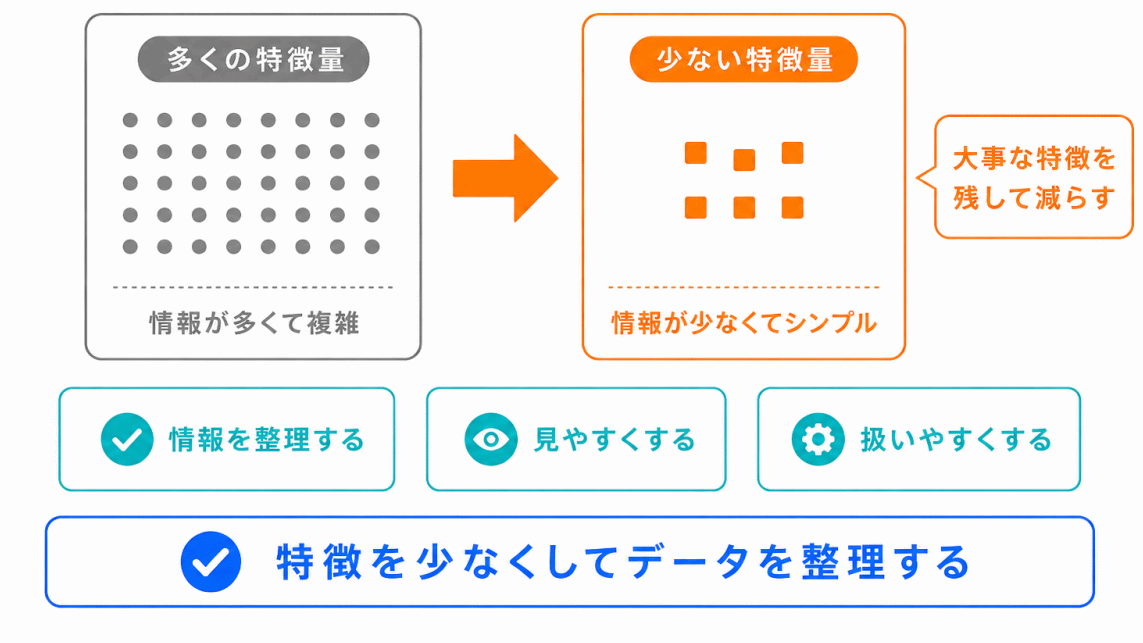
次元削減とは、データの特徴量を減らして、扱いやすくする手法です。
AIで扱うデータには、多くの特徴が含まれています。
たとえば、顧客データなら
のように、多くの情報があります。
特徴量が多すぎると、データの関係が見えにくくなることがあります。
そこで、重要な情報をなるべく残しながら、特徴量を少なく整理するのが次元削減です。
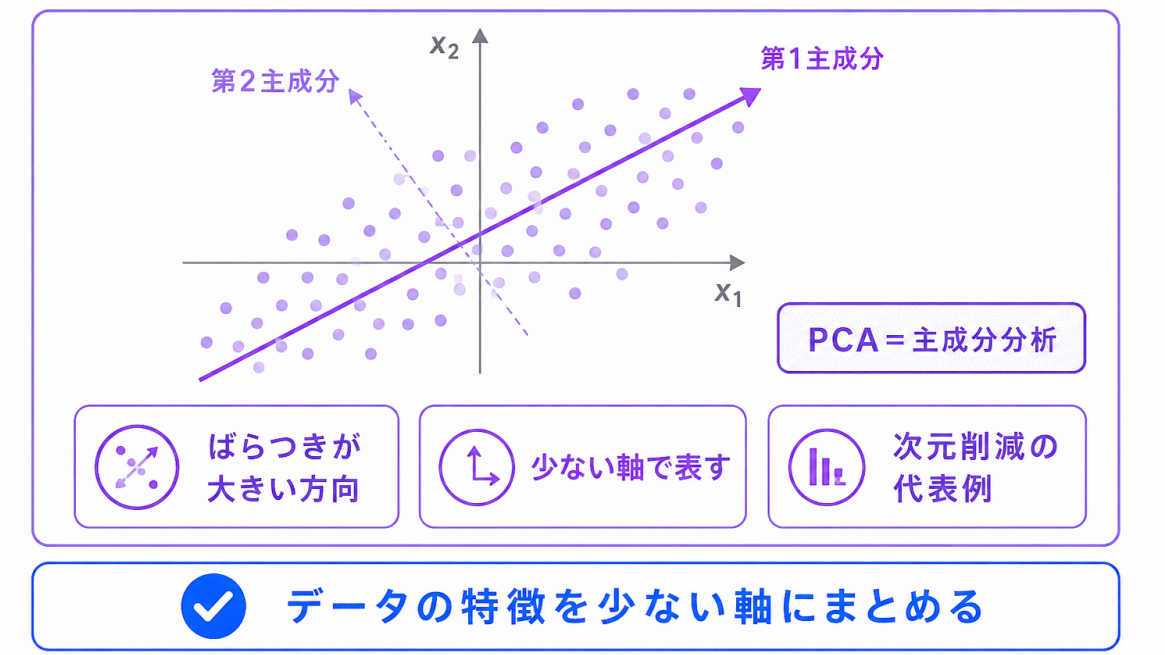
PCAは、次元削減の代表的な手法です。
日本語では 主成分分析 と呼ばれます。
| 用語 | 一言でいうと |
|---|---|
| PCA | 次元削減の代表的な方法 |
| 主成分分析 | データの特徴を少ない軸にまとめる方法 |
| 次元削減 | 特徴量を減らして整理する考え方 |
PCAでは、データのばらつきをよく表す方向を見つけて、少ない軸でデータを表します。
G検定対策では、数式よりも、次のように整理しておくと十分です。
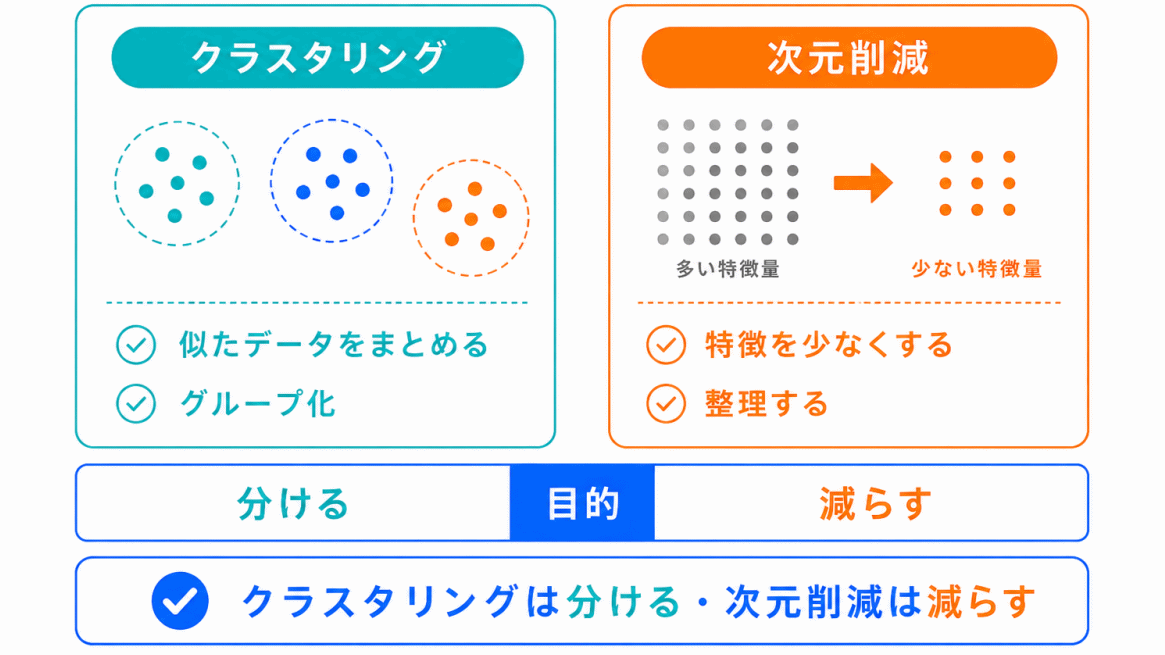
クラスタリングと次元削減は、どちらも教師なし学習に関係します。
ただし、目的が違います。
| 手法 | 目的 |
|---|---|
| クラスタリング | 似たデータをグループに分ける |
| 次元削減 | 特徴量を減らして整理する |
クラスタリングは「分ける」ことが目的です。
次元削減は「減らして見やすくする」ことが目的です。
この違いを押さえると、混同しにくくなります。
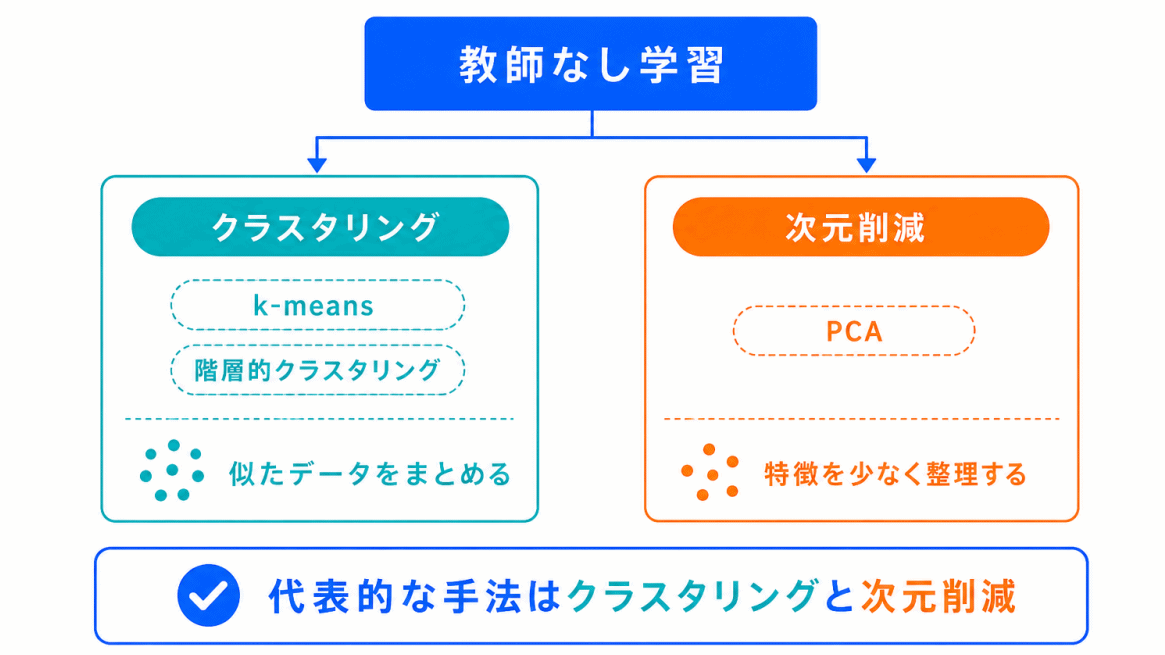
まとめると下の表になります。
| 用語 | 一言でいうと | 分類 |
|---|---|---|
| クラスタリング | 似たデータをグループに分ける | 教師なし学習 |
| k-means | 代表的なクラスタリング手法 | クラスタリング |
| 階層的クラスタリング | 段階的にグループを作る | クラスタリング |
| 次元削減 | 特徴量を減らして整理する | 教師なし学習 |
| PCA | 次元削減の代表的な方法 | 次元削減 |
| 主成分分析 | データを少ない軸で表す | PCA |
まずは、細かい手法をバラバラに覚えるよりも、次の関係を押さえることが大切です。
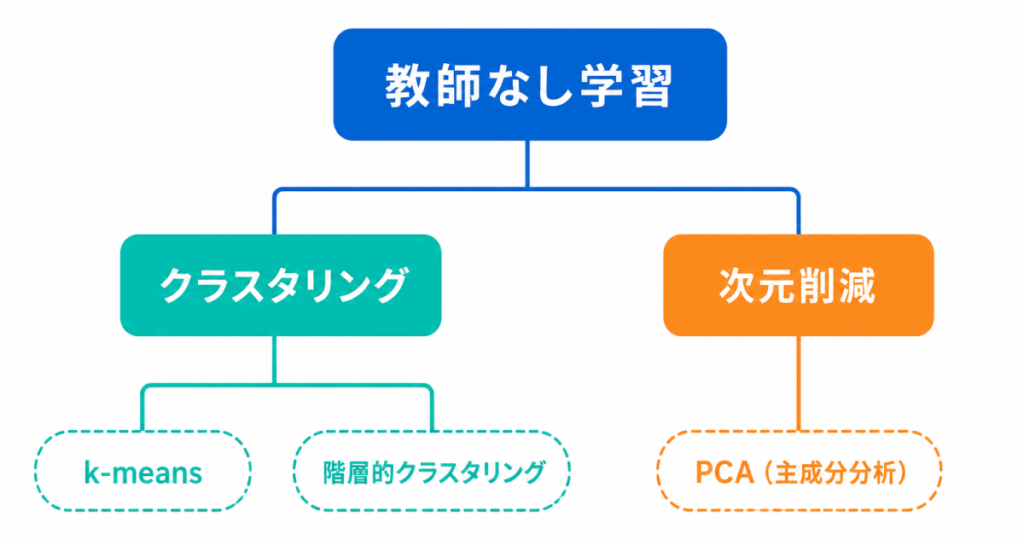
G検定では、教師なし学習の手法そのものよりも、どの用語が何をするものか が問われやすいです。
| 問われ方 | 選ぶ用語 |
|---|---|
| 正解ラベルなしで学習する | 教師なし学習 |
| 似たデータをグループに分ける | クラスタリング |
| クラスタリングの代表的な手法 | k-means |
| 特徴量を減らして整理する | 次元削減 |
| 次元削減の代表的な手法 | PCA |
| PCAの日本語名 | 主成分分析 |
特に混同しやすいのは、クラスタリングと分類です。
分類は、正解ラベルを使ってカテゴリを予測します。
クラスタリングは、正解ラベルなしで似たデータをまとめます。
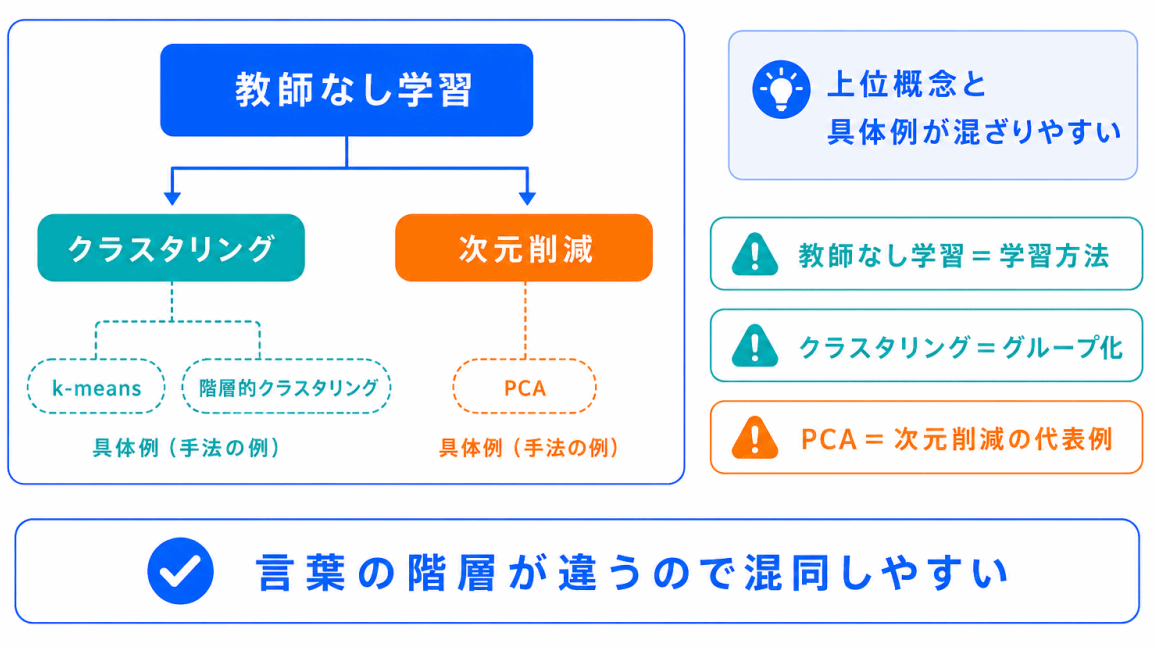
教師なし学習が混同しやすい理由は、似たような言葉が近くに出てくるからです。
| 混同しやすいもの | 違い |
|---|---|
| 分類 | 正解ラベルありでカテゴリを予測する |
| クラスタリング | 正解ラベルなしでグループに分ける |
| 次元削減 | 特徴量を減らして整理する |
| PCA | 次元削減の代表的な方法 |
特に、分類とクラスタリングはどちらも「分ける」ように見えるため、混同しやすいです。
大事なのは、正解ラベルがあるかどうかです。
この違いを押さえておくと、G検定でも判断しやすくなります。
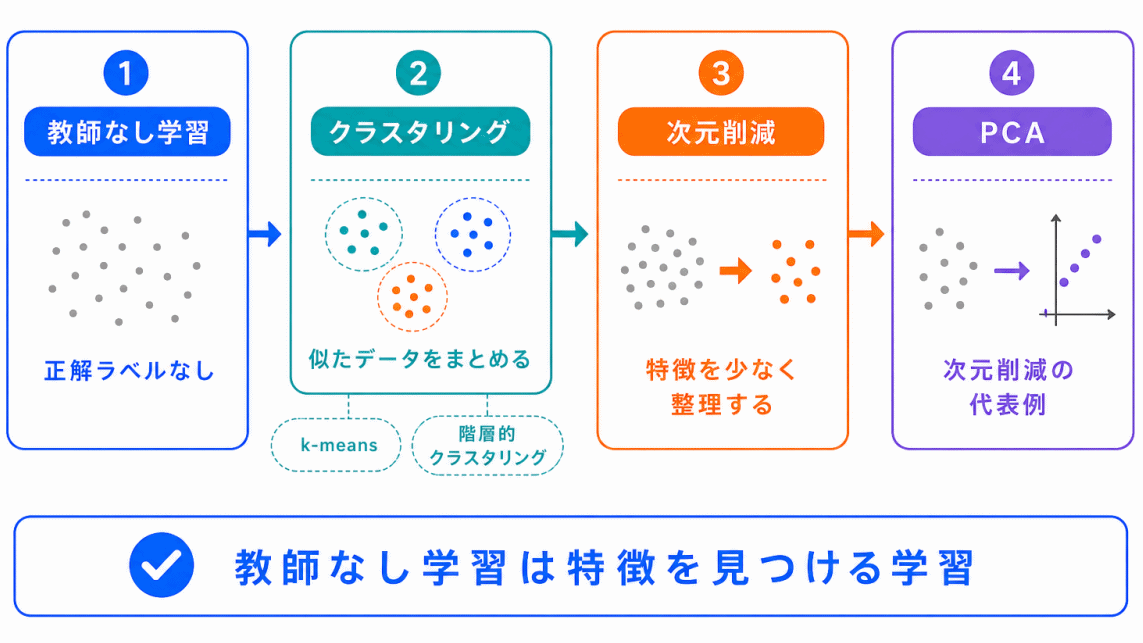
教師なし学習は、正解ラベルがないデータから、特徴や構造を見つける学習方法です。
代表的な手法には、クラスタリングと次元削減があります。
クラスタリングは、似たデータをグループに分ける方法です。
次元削減は、特徴量を減らしてデータを扱いやすくする方法です。
PCAは、次元削減の代表的な手法で、日本語では主成分分析と呼ばれます。
G検定では、細かい計算よりも、次の関係を整理しておくことが大切です。
分類・回帰・クラスタリングの違いをあわせて確認すると、教師あり学習と教師なし学習の関係がより整理しやすくなります。
教師なし学習は、正解ラベルなしでデータの特徴やまとまりを見つける学習方法です。
分類・回帰との違いや、教師あり学習側の代表手法もあわせて確認すると、クラスタリング・次元削減・PCAの位置づけが整理しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 教師あり学習と教師なし学習 | 正解データの有無/分類・回帰との関係/クラスタリングとの違い |
| 教師あり学習の代表アルゴリズム | 分類・回帰の考え方/代表的な手法/教師なし学習との違い |
| 機械学習とディープラーニングの違い | AI・機械学習・ディープラーニングの関係/特徴量設計/学習方法との違い |
| 8分野別の記事一覧 | G検定8分野の記事分類/苦手分野から読む記事/分野ごとの学習入口 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。