【G検定対策】活性化関数とは?わかりやすく整理
seo-webmaster
SEO・ウェブマスターブログ
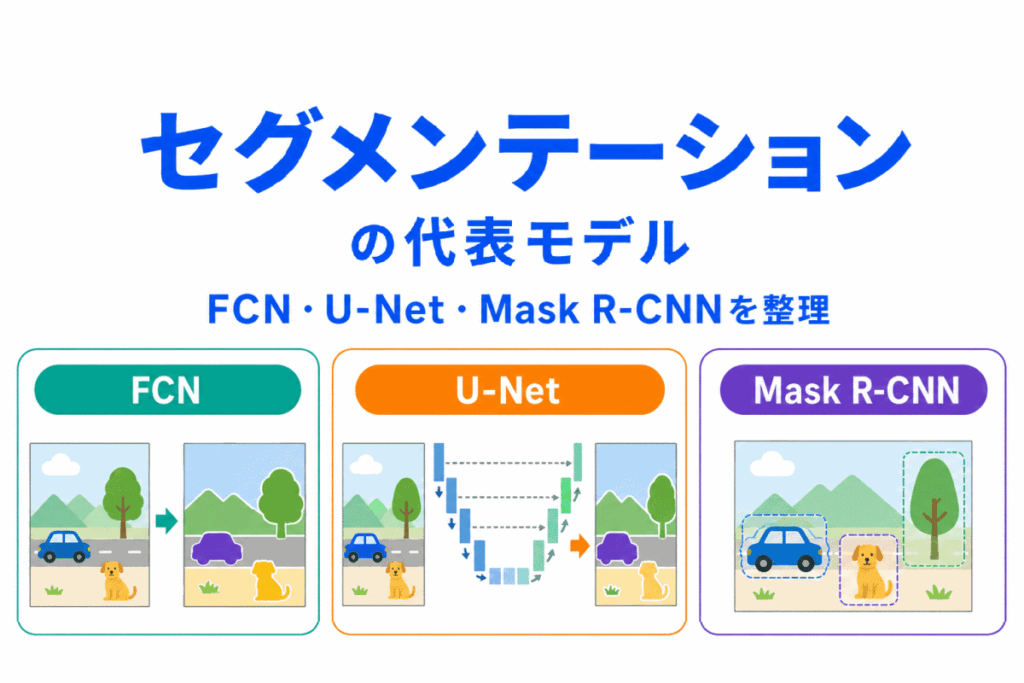
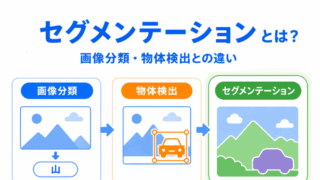
セグメンテーションは、画像を「領域ごとに分ける」技術です。
ただ、G検定対策で学習していると、FCN、U-Net、Mask R-CNN など、似たようなモデル名が出てきて混乱しやすくなります。
特に、画像分類や物体検出と違い、セグメンテーションは「画像全体を見る」のではなく、画素単位でどの領域に属するかを考える点が重要です。
この記事では、FCN・U-Net・Mask R-CNNの役割を、細かい数式ではなく「何を分けるモデルなのか」という流れで整理します。
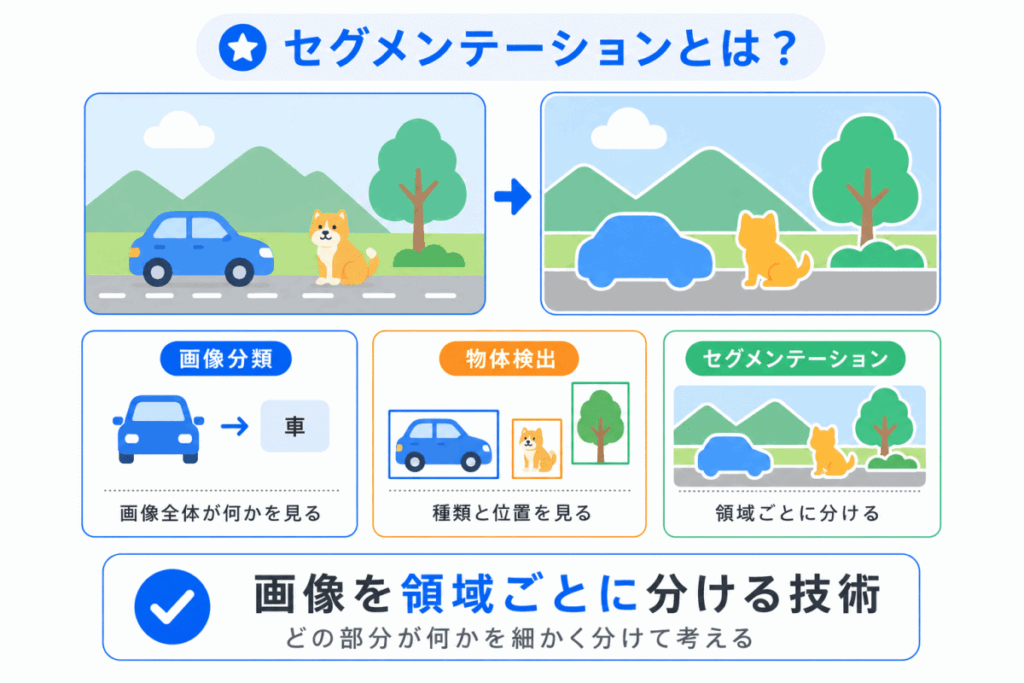
セグメンテーションとは、画像を領域ごとに分ける技術 です。
画像分類では、画像全体を見て「犬の画像」「車の画像」のように判断します。
物体検出では、画像の中の物体を四角い枠で囲み、「どこに何があるか」を見つけます。
一方、セグメンテーションでは、画像の中のどの部分が犬で、どの部分が背景なのかを、より細かく分けます。
つまり、セグメンテーションは次のように整理できます。
| 技術 | 何を見るか |
|---|---|
| 画像分類 | 画像全体が何かを見る |
| 物体検出 | 物体の種類と位置を見る |
| セグメンテーション | 画像を領域ごとに分ける |
セグメンテーション = 画像を「どの領域に分けるか」を考える技術 と押さえると、全体像がつかみやすくなります。
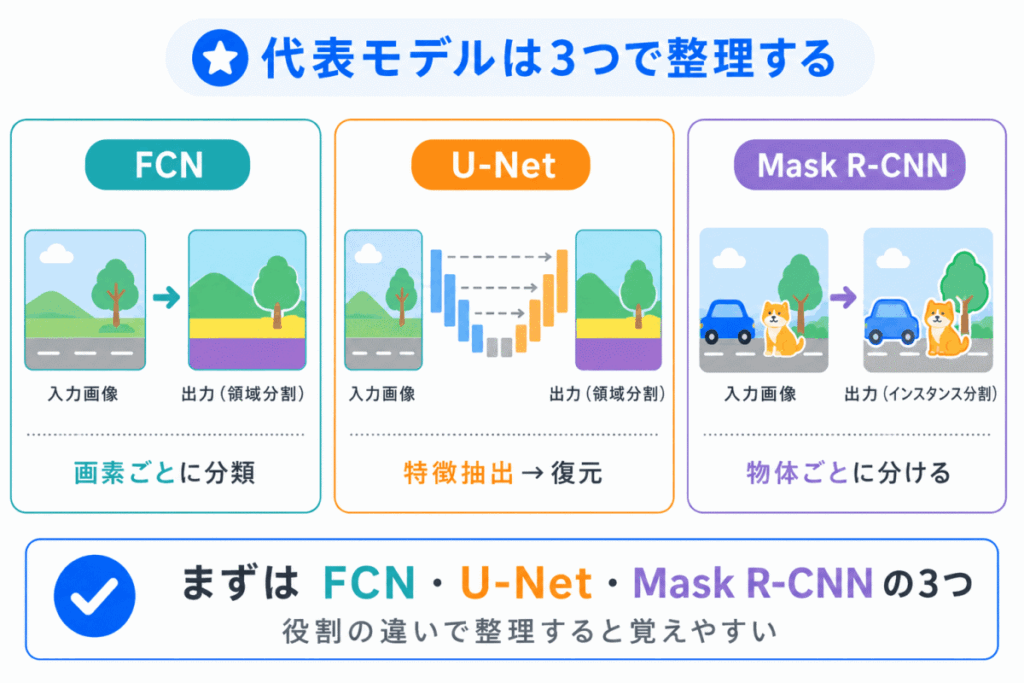
セグメンテーションの代表モデルは、まず次の3つで整理するとわかりやすいです。
| モデル | 一言でいうと |
|---|---|
| FCN | 画像を画素ごとに分類する基本的なモデル |
| U-Net | 細かい位置情報を復元しやすいモデル |
| Mask R-CNN | 物体ごとに領域を分けるモデル |
ここで大事なのは、すべてを同じものとして覚えないことです。
FCNとU-Netは、画像を領域ごとに分ける考え方と関係が深いモデルです。
Mask R-CNNは、物体検出のR-CNN系を発展させて、物体ごとのマスクも予測するモデルです。
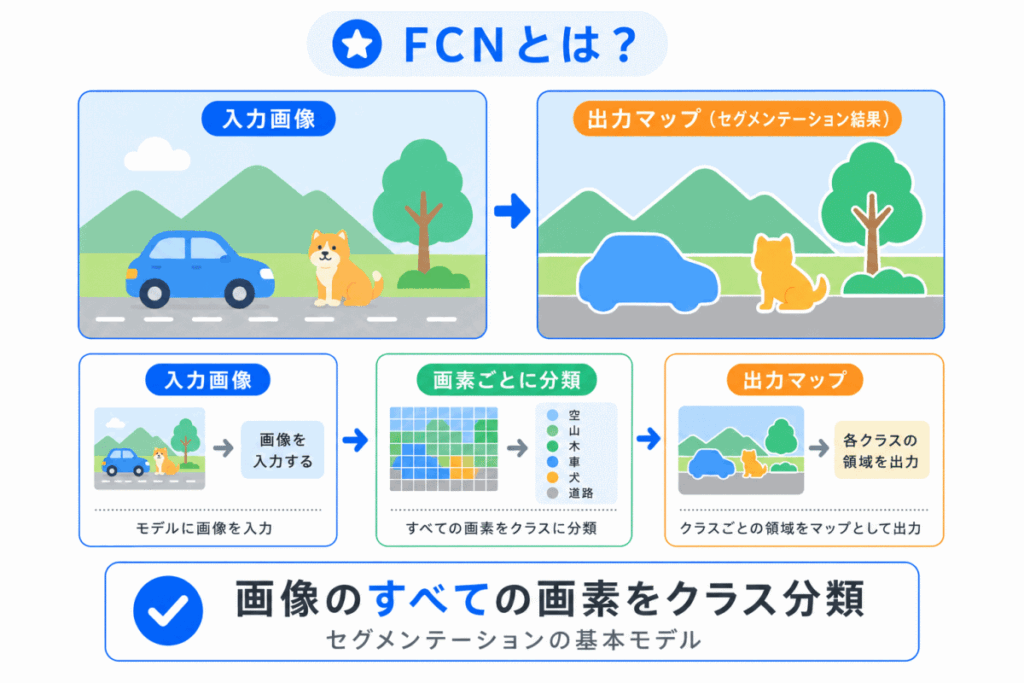
FCNとは、Fully Convolutional Network の略です。
日本語では、全畳み込みネットワークと呼ばれることがあります。
通常のCNNは、画像分類で使われることが多く、最後に「この画像は何か」を判断します。
一方、FCNは画像全体を1つのラベルで分類するのではなく、画像の各位置に対して「ここは何の領域か」を予測します。
たとえば、道路の画像であれば
| 画像の部分 | 予測する内容 |
|---|---|
| 道路の部分 | 道路 |
| 車の部分 | 車 |
| 空の部分 | 空 |
| 建物の部分 | 建物 |
のように、領域ごとに分類します。
FCNは、セグメンテーションを深層学習で行う基本的な考え方として重要です。
FCN = 画像を画素ごとに分類するセグメンテーションの基本モデル と整理しておくとよいです。
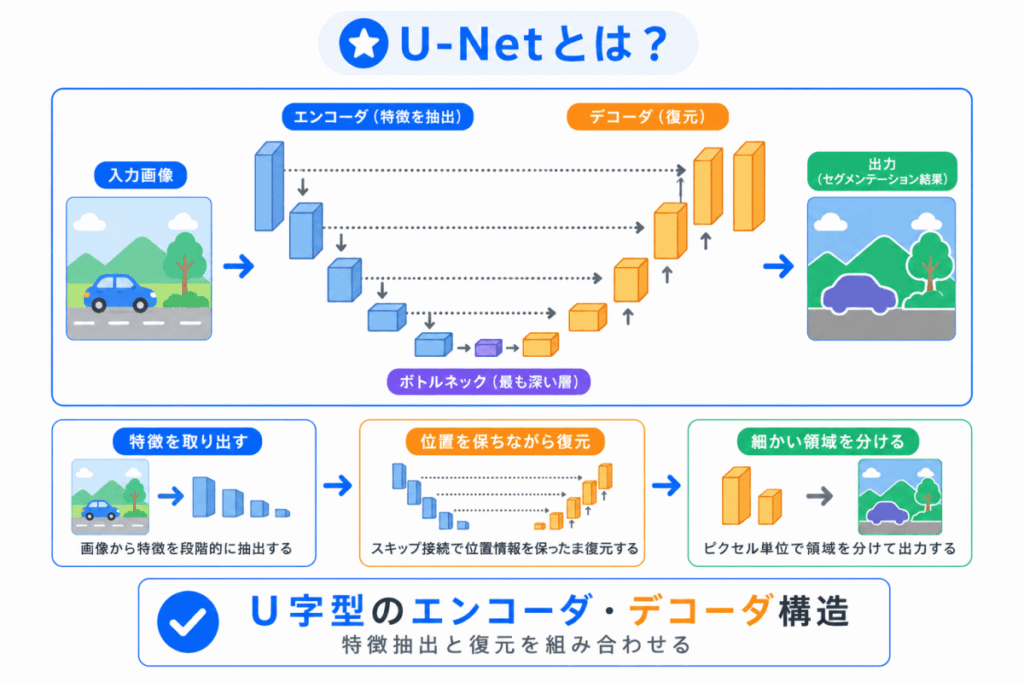
U-Netは、画像を細かく分けるセグメンテーションでよく使われるモデルです。
名前の通り、構造がU字型に見えることからU-Netと呼ばれます。
U-Netでは、まず画像を小さくしながら特徴を取り出します。
その後、取り出した特徴をもとに、画像の細かい位置情報を復元していきます。
流れで見ると、次のようになります。
U-Netがわかりやすいのは、「特徴を取り出すだけでなく、元の位置に戻す」イメージで理解できるところです。
セグメンテーションでは、何が写っているかだけでなく、どこからどこまでがその領域なのかも大切です。
そのため、位置を復元しやすいU-Netは、医療画像などの細かい領域分けでよく使われます。
U-Net = 特徴を取り出してから、位置を復元して領域を分けるモデル と押さえると理解しやすいです。
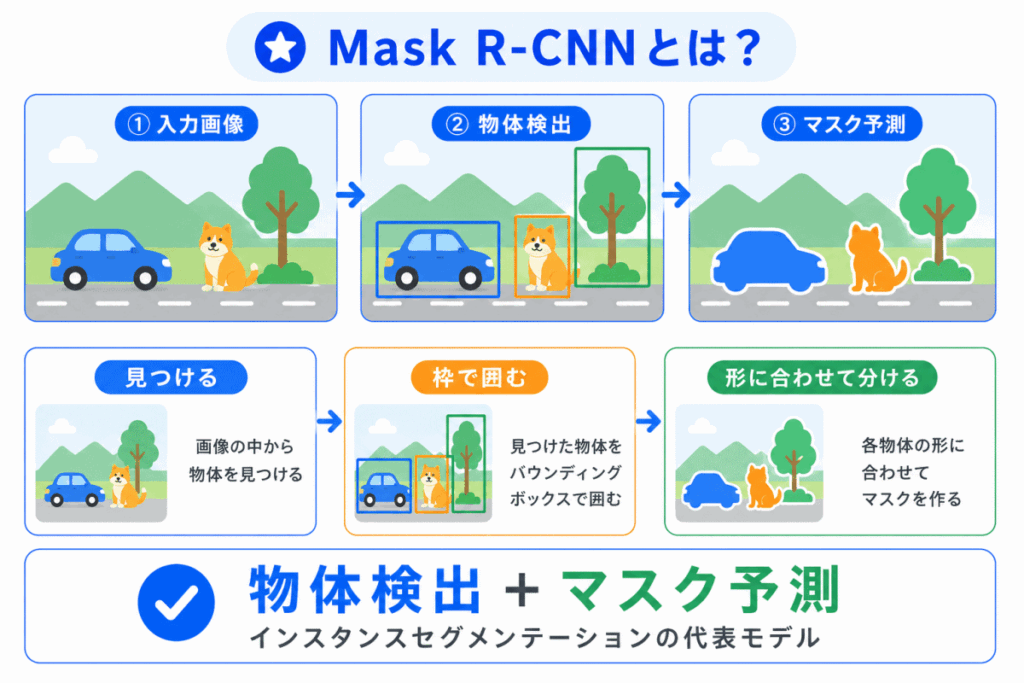
Mask R-CNN は、物体検出で使われるFaster R-CNNを発展させたモデルです。
Faster R-CNN は、画像の中から物体を見つけ、四角い枠で囲むモデルでした。
Mask R-CNN では、それに加えて、物体ごとの領域も予測します。
つまり、次のように整理できます。
| モデル | 何を出力するか |
|---|---|
| Faster R-CNN | 物体の種類と四角い枠 |
| Mask R-CNN | 物体の種類、四角い枠、物体ごとの領域 |
ここでいう「物体ごとの領域」は、マスクと呼ばれます。
たとえば、画像の中に犬が2匹いる場合、単に「犬の領域」とまとめるのではなく、1匹目の犬と2匹目の犬を分けて扱います。
このように、物体ごとに領域を分けるセグメンテーションを、インスタンスセグメンテーションといいます。
Mask R-CNN = 物体検出にマスク予測を加えたモデル と整理すると、Faster R-CNNとの関係が見えやすくなります。
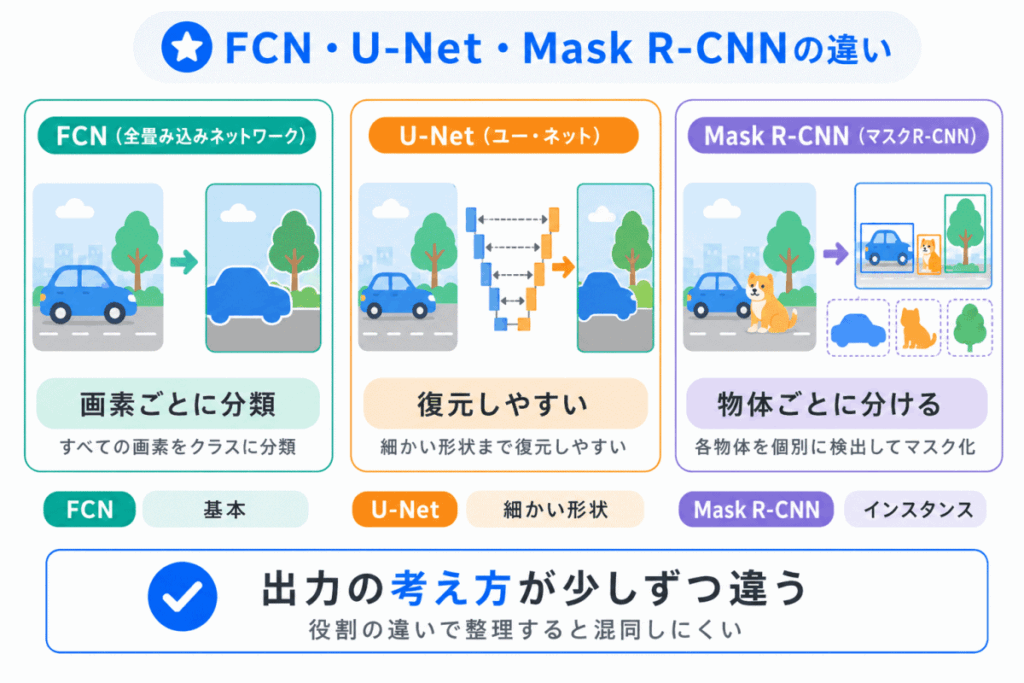
FCN・U-Net・Mask R-CNNは、どれもセグメンテーションに関係するモデルですが、役割は少しずつ違います。
| モデル | 特徴 | 覚え方 |
|---|---|---|
| FCN | 画像を画素ごとに分類する | セグメンテーションの基本 |
| U-Net | 特徴を取り出して位置を復元する | 細かい領域分けに強い |
| Mask R-CNN | 物体ごとの領域を分ける | 物体検出+マスク |
特に混同しやすいのは、U-NetとMask R-CNNです。
U-Netは、画像全体を領域ごとに分けるイメージです。
Mask R-CNNは、物体を検出したうえで、物体ごとの領域を分けるイメージです。
ざっくり整理すると、次のようになります。
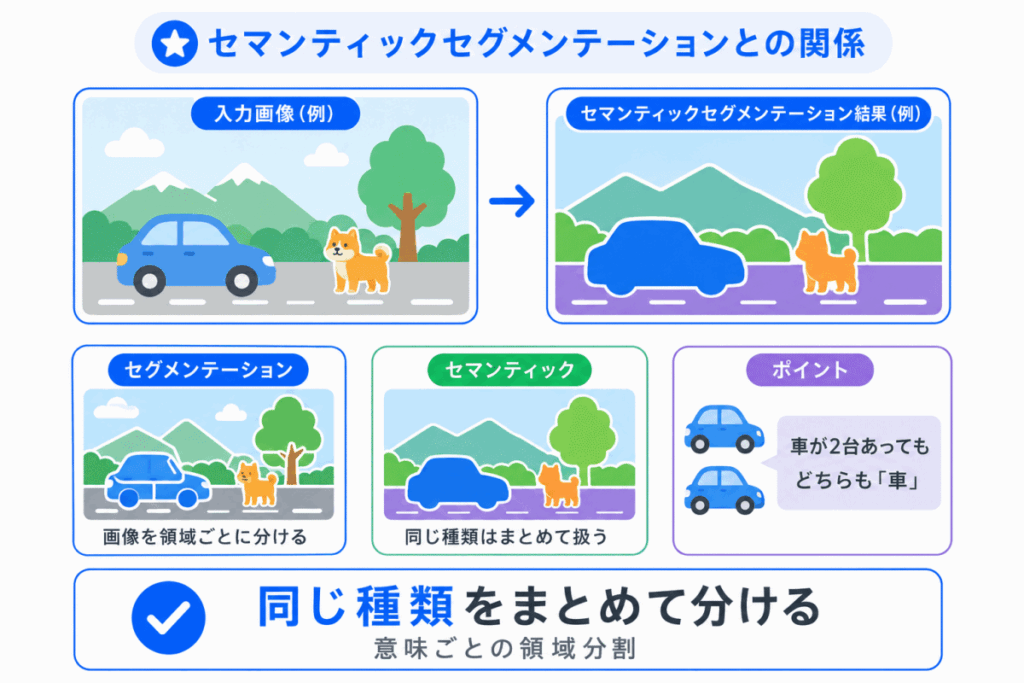
セマンティックセグメンテーションとは、画像の各領域を意味ごとに分ける方法です。
たとえば、画像の中に車が複数台あっても、すべて同じ「車」として扱います。
| 対象 | 分け方 |
|---|---|
| 車A | 車 |
| 車B | 車 |
| 道路 | 道路 |
| 空 | 空 |
このように、同じ種類のものは同じラベルとして扱います。
FCNやU-Netは、セマンティックセグメンテーションの文脈で理解するとわかりやすいモデルです。
セマンティックセグメンテーション = 同じ種類の領域を同じラベルで分ける と整理できます。
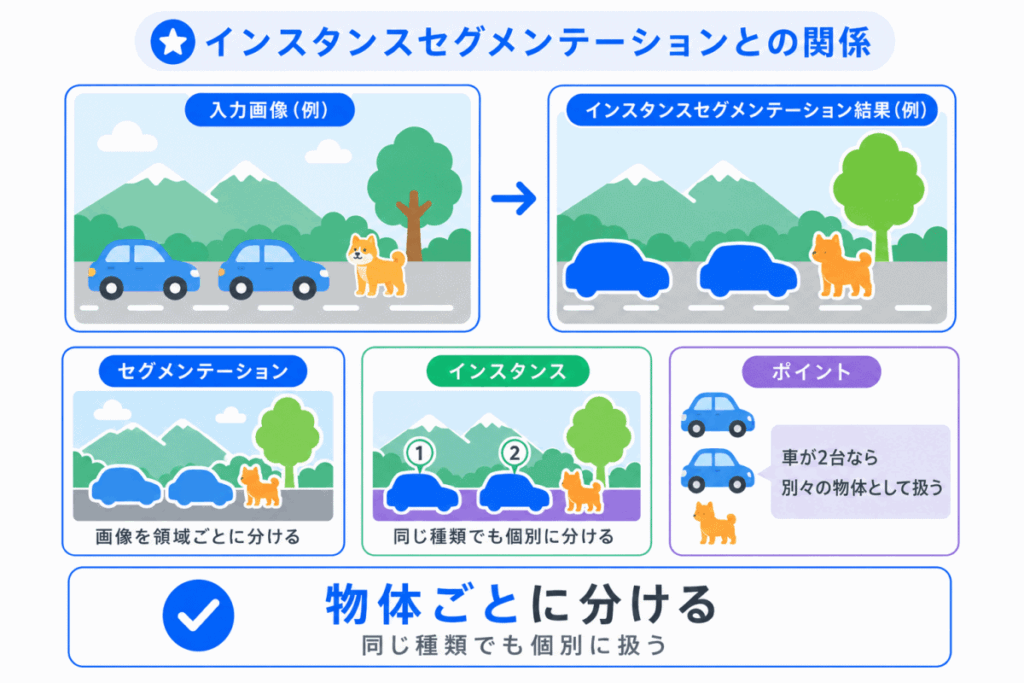
インスタンスセグメンテーションとは、同じ種類の物体でも、1つ1つの個体を分ける方法です。
たとえば、画像の中に犬が2匹いる場合、どちらも「犬」ですが、別々の物体として扱います。
| 対象 | 分け方 |
|---|---|
| 犬A | 犬Aの領域 |
| 犬B | 犬Bの領域 |
| 背景 | 背景 |
この考え方と関係が深いのが、Mask R-CNNです。
Mask R-CNNは、物体を検出するだけでなく、それぞれの物体ごとにマスクを作ります。
インスタンスセグメンテーション = 同じ種類でも、物体ごとに分ける と押さえるとよいです。
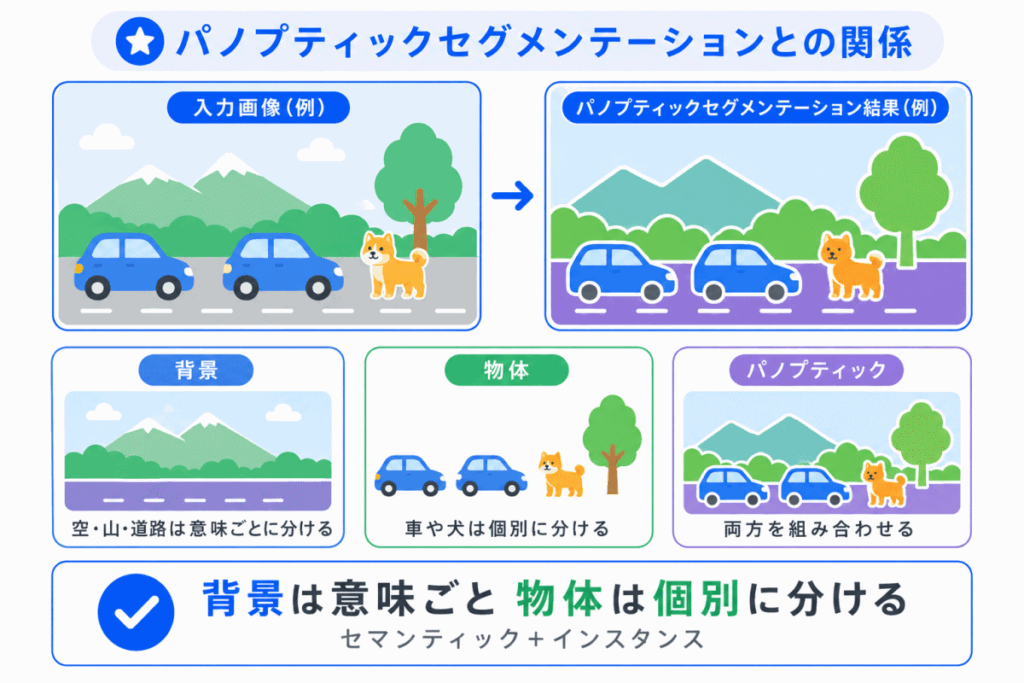
パノプティックセグメンテーションは、セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせた考え方です。
背景のような領域は意味ごとに分け、車や人のような物体は個体ごとに分けます。
| 種類 | 分け方 |
|---|---|
| 道路・空・建物 | 意味ごとに分ける |
| 人・車・犬 | 個体ごとに分ける |
G検定対策では、まずは次の関係を押さえると十分です。
パノプティックセグメンテーションは細かい用語ですが、セグメンテーションの発展形として軽く押さえておくと安心です。
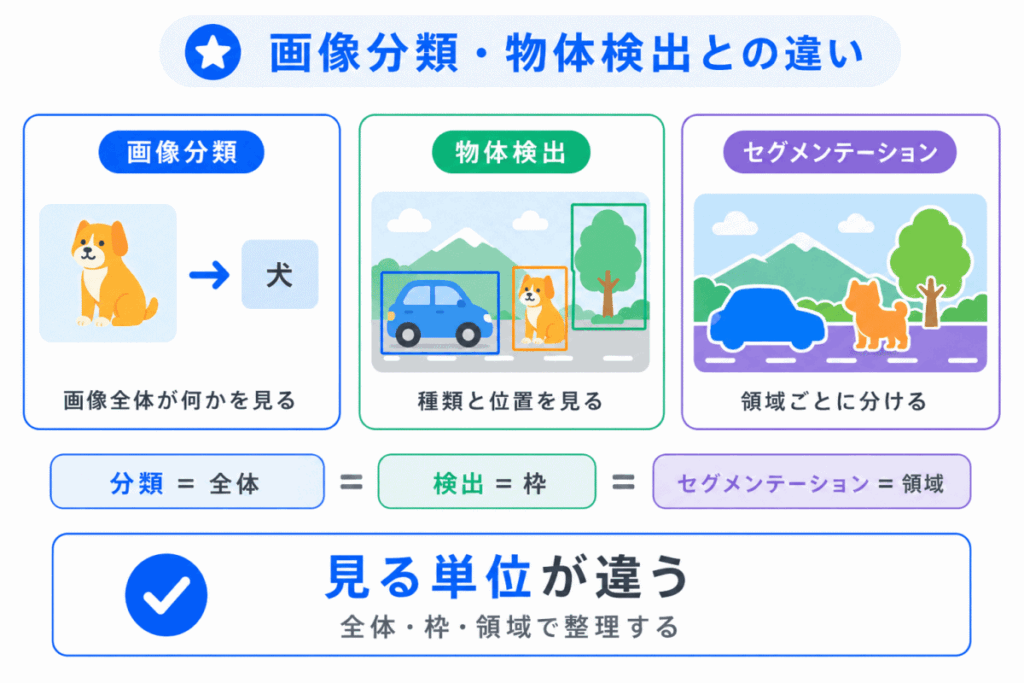
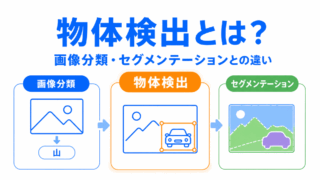
セグメンテーションは、画像分類や物体検出と混同しやすいです。
違いは、出力される結果を見るとわかりやすくなります。
| 技術 | 出力されるもの |
|---|---|
| 画像分類 | 画像全体のラベル |
| 物体検出 | 物体の種類と四角い枠 |
| セグメンテーション | 領域ごとのラベル |
| インスタンスセグメンテーション | 物体ごとの領域 |
画像分類は「何の画像か」を見ます。
物体検出は「どこに何があるか」を見ます。
セグメンテーションは「どの領域が何か」を見ます。
この違いを先に整理しておくと、FCN・U-Net・Mask R-CNN も理解しやすくなります。
G検定では、細かい実装方法よりも、モデル名と役割の対応が問われやすいです。
たとえば、次のような形で整理しておくと対応しやすくなります。
| 問われやすいポイント | 押さえ方 |
|---|---|
| FCNとは何か | 画素ごとに分類するセグメンテーションの基本モデル |
| U-Netとは何か | 特徴抽出と位置復元を行うU字型のモデル |
| Mask R-CNNとは何か | Faster R-CNNにマスク予測を加えたモデル |
| セマンティックセグメンテーション | 同じ種類をまとめて分ける |
| インスタンスセグメンテーション | 同じ種類でも個体ごとに分ける |
特に、Mask R-CNNは物体検出の記事とつなげて理解すると覚えやすくなります。
このように、既に学んだ物体検出とつなげると、暗記ではなく理解で整理できます。
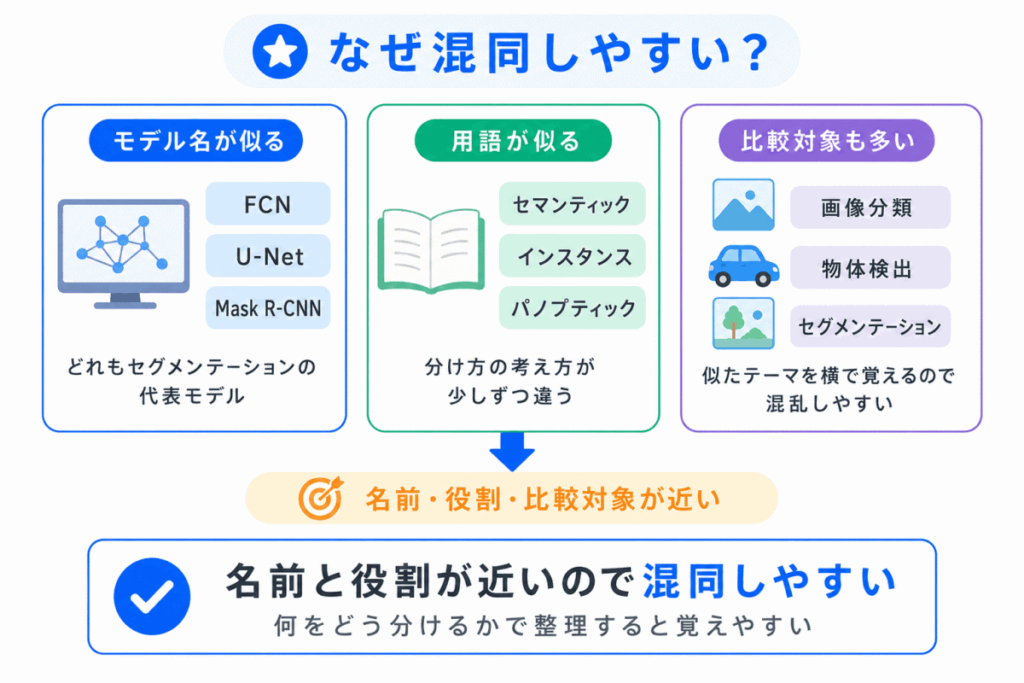
セグメンテーションの代表モデルが混同しやすい理由は、どれも「画像を分ける」技術に見えるからです。
ただし、見るポイントは少し違います。
| 混同しやすい理由 | 整理のコツ |
|---|---|
| どれも画像を分ける技術に見える | 何を出力するかで見る |
| FCNとU-Netの違いが見えにくい | U-Netは位置を復元する構造で考える |
| Mask R-CNNが物体検出なのか セグメンテーションなのか迷う |
物体検出+マスクと考える |
| セマンティックとインスタンスが似ている | 同じ種類をまとめるか、個体ごとに分けるかで見る |
つまり、モデル名を単独で覚えるよりも
で整理すると混同しにくくなります。
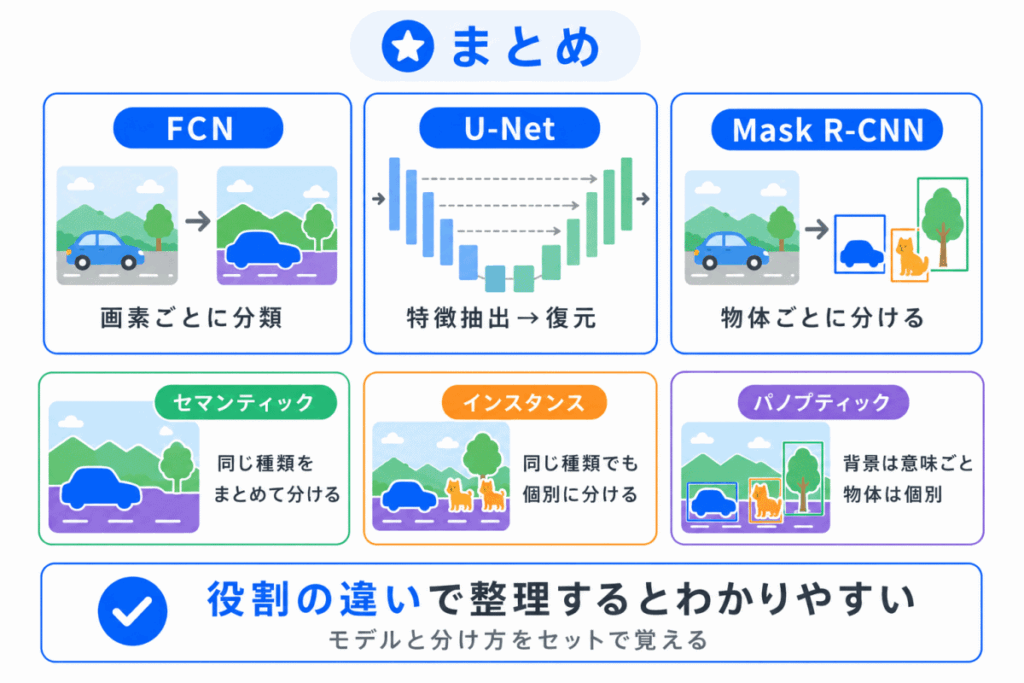
セグメンテーションは、画像を領域ごとに分ける技術です。
代表モデルは、FCN・U-Net・Mask R-CNN の3つで整理すると理解しやすくなります。
| 用語 | 一言でいうと | 関係する考え方 |
|---|---|---|
| FCN | 画素ごとに分類する基本モデル | セマンティックセグメンテーション |
| U-Net | 特徴を取り出して位置を復元するモデル | 細かい領域分け |
| Mask R-CNN | 物体ごとのマスクを予測するモデル | インスタンスセグメンテーション |
| セマンティックセグメンテーション | 同じ種類をまとめて分ける | 意味ごとの領域分け |
| インスタンスセグメンテーション | 同じ種類でも個体ごとに分ける | 物体ごとの領域分け |
| パノプティックセグメンテーション | 意味ごとの分割と個体ごとの分割を組み合わせる | 発展的な領域分け |
まずは
と整理しておくと、G検定対策でも混同しにくくなります。
セグメンテーションは、画像分類や物体検出と並ぶ画像認識の重要な応用例です。モデル名だけを暗記するのではなく、「画像をどう分けるのか」という視点で理解しておくことが大切です。
セグメンテーションの理解を深めるには、画像分類・物体検出との違いもあわせて整理しておくと理解しやすくなります。
用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認