【G検定対策】CNNの畳み込み・プーリングとは?|画像認識で特徴を取り出す仕組みをわかりやすく整理
seo-webmaster
G検定対策ブログ

クラスタリングとは、正解ラベルがないデータを、似ているもの同士のグループに分ける考え方です。
たとえば、顧客データを似た購買傾向ごとに分けたり、画像や文章を似た特徴ごとに整理したりするときに使われます。
G検定では、クラスタリングを単独の手法名として暗記するよりも、「教師なし学習の代表例」「正解ラベルがない」「似ているデータをグループ化する」という関係で理解することが大切です。
また、k-means法、階層的クラスタリング、次元削減、特徴量とのつながりも問われやすいポイントです。
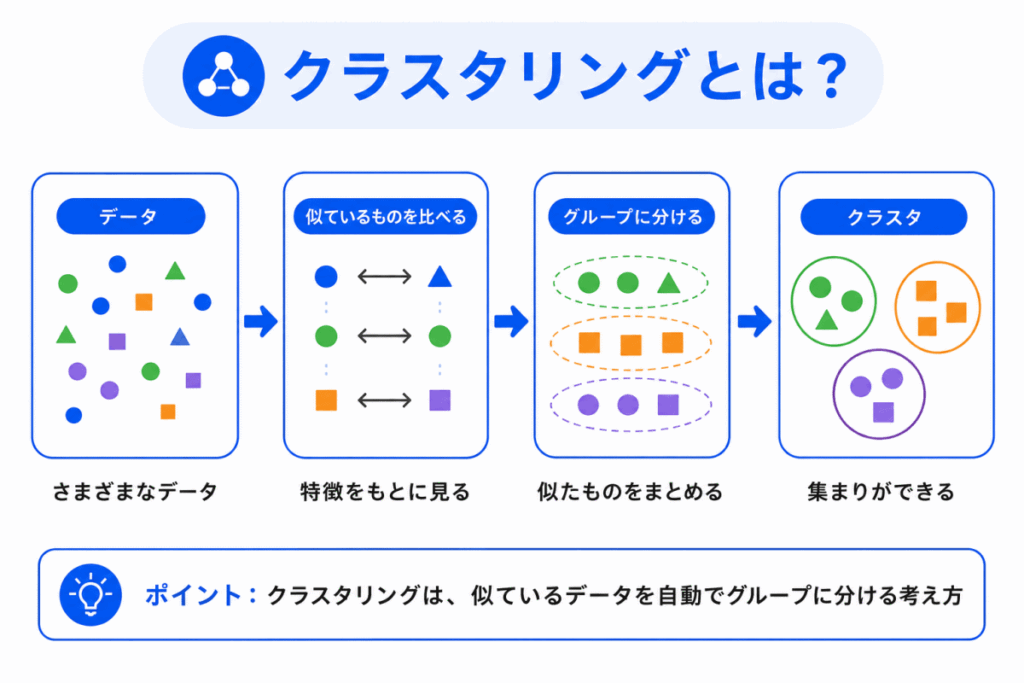
クラスタリングとは、データを似ているもの同士でグループに分ける手法です。
このグループのことを、クラスタと呼びます。
たとえば、次のようなイメージです。
| 用語 | 意味 |
|---|---|
| クラスタ | 似ているデータを集めたグループ |
| クラスタリング | データを似ているグループに分けること |
| 教師なし学習 | 正解ラベルがないデータから構造を見つける学習 |
クラスタリングでは、あらかじめ「このデータはAグループです」という正解は与えられません。
データの特徴をもとに、機械的に似ているものをまとめます。
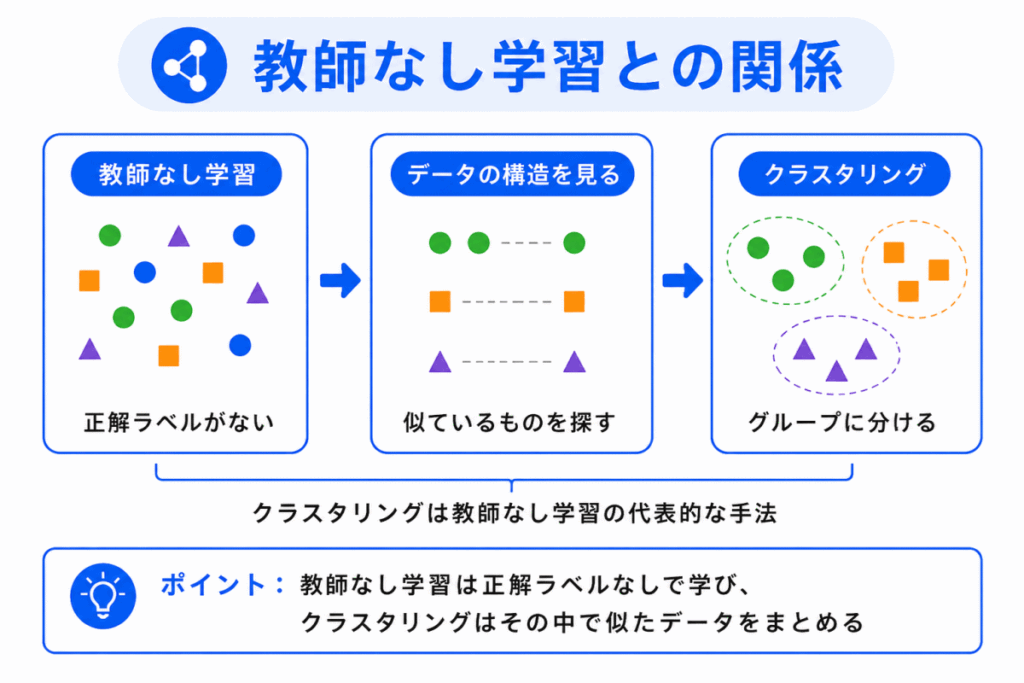
クラスタリングは、教師なし学習の代表的な手法です。
教師なし学習では、正解ラベルがないデータから、データの構造やパターンを見つけます。
クラスタリングの場合は、その構造を「グループ」として見つけます。
ポイントは、分類とは違って、最初から正解のクラスが決まっているわけではないことです。
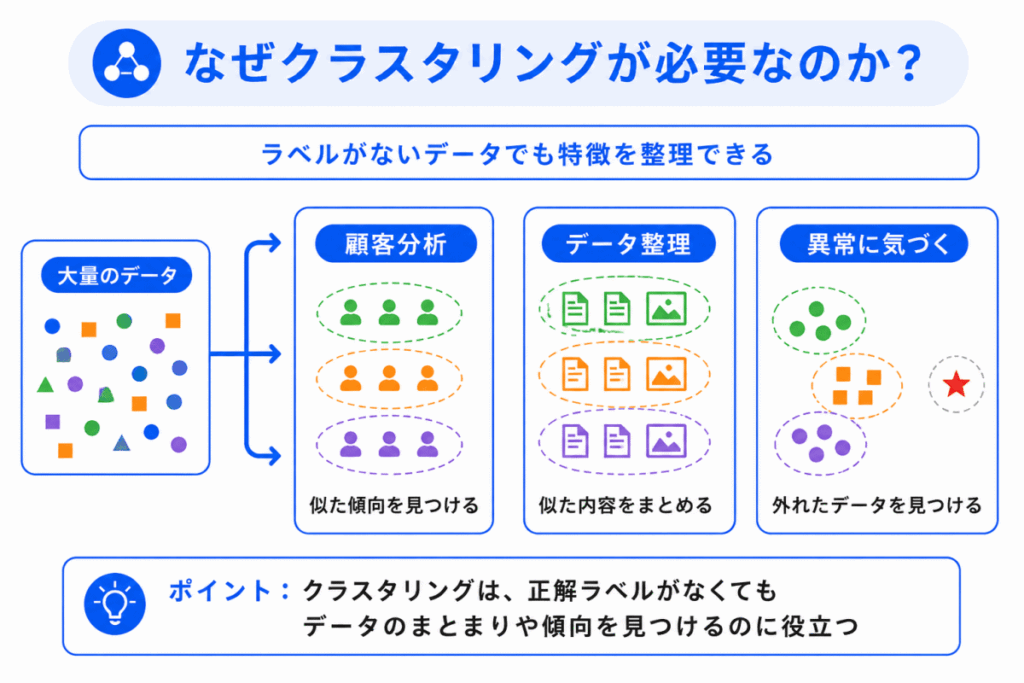
現実のデータには、正解ラベルが付いていないことが多くあります。
たとえば、顧客データはあっても、「この人はAタイプ」「この人はBタイプ」という正解が最初から付いているとは限りません。
そのようなときに、クラスタリングを使うと、データの中にあるまとまりを見つけやすくなります。
| 場面 | クラスタリングでできること |
|---|---|
| 顧客分析 | 似た購買傾向の顧客をグループに分ける |
| 文章データ | 似た内容の文章をまとめる |
| 画像データ | 似た特徴を持つ画像を整理する |
| 異常検知 | 通常のグループから外れたデータに注目する |
クラスタリングは、データを理解するための下準備として使われることもあります。
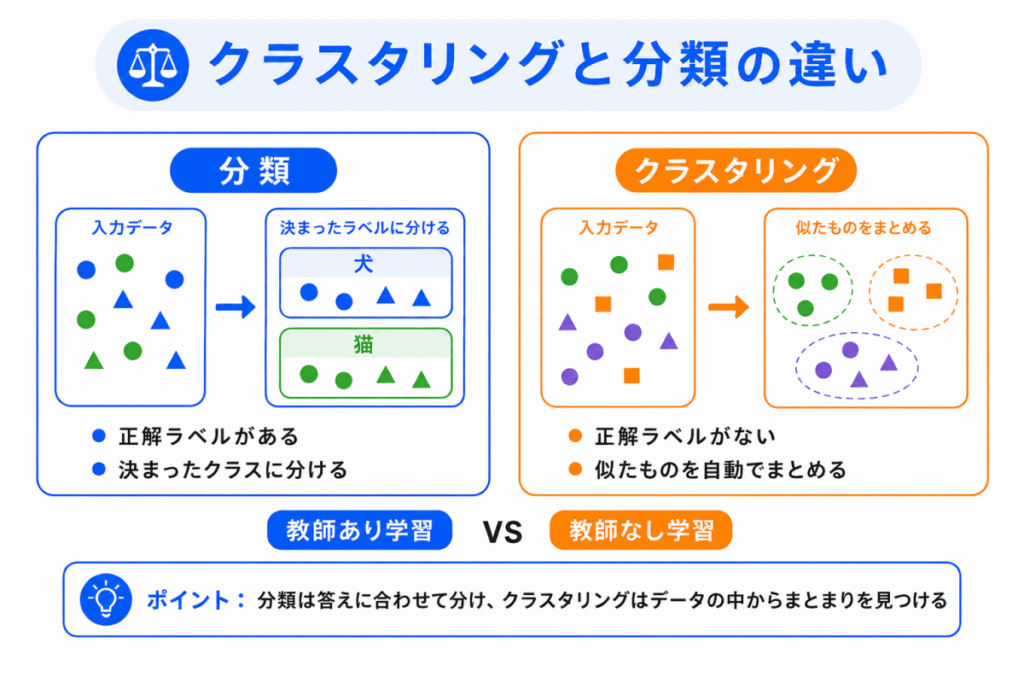
クラスタリングと混同しやすいのが、分類です。
どちらもデータを分ける考え方ですが、大きな違いは正解ラベルの有無です。
| 項目 | 分類 | クラスタリング |
|---|---|---|
| 学習の種類 | 教師あり学習 | 教師なし学習 |
| 正解ラベル | ある | ない |
| 目的 | 新しいデータを決まったクラスに分ける | 似ているデータのまとまりを見つける |
| 例 | 犬か猫かを判定する | 似た画像をグループに分ける |
分類は、すでに決まっている答えに近づける学習です。
クラスタリングは、データの中からまとまりを見つける学習です。
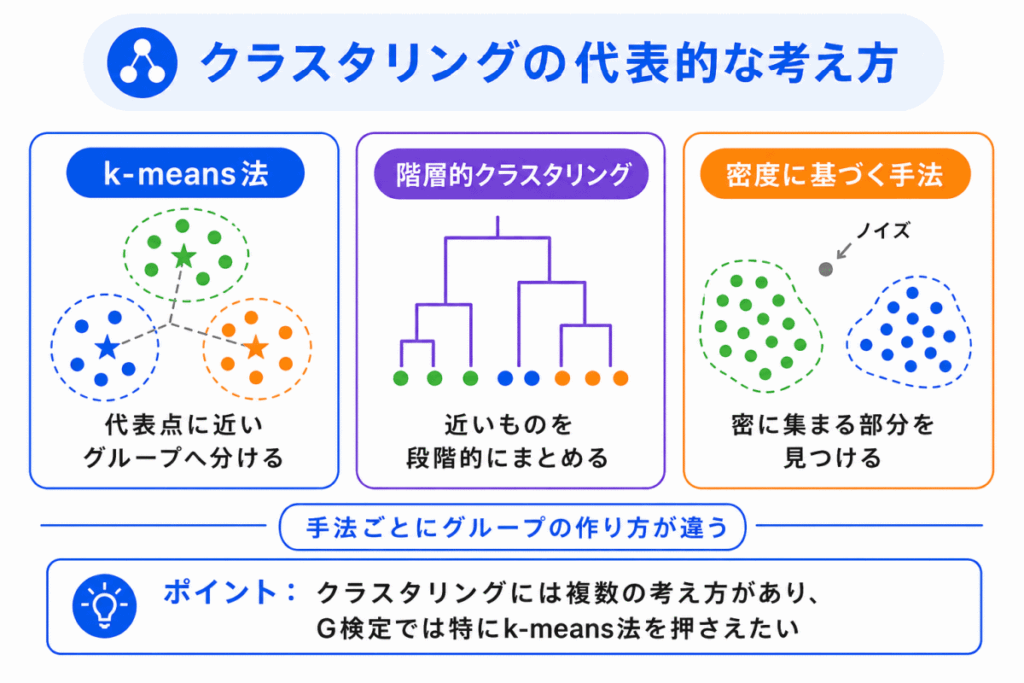
クラスタリングには、いくつかの代表的な考え方があります。
G検定では、特にk-means法を押さえておくと理解しやすくなります。
| 手法 | 考え方 | 押さえ方 |
|---|---|---|
| k-means法 | 代表点に近いデータを同じグループに分ける | クラスタリングの代表手法 |
| 階層的クラスタリング | 近いデータ同士を段階的にまとめる | 木のような構造で整理する |
| 密度に基づく手法 | データが密に集まっている部分をグループと見る | 形が複雑なまとまりにも対応しやすい |
この記事では、まずクラスタリング全体の意味を押さえます。
k-means法は、別記事で詳しく整理するとわかりやすくなります。
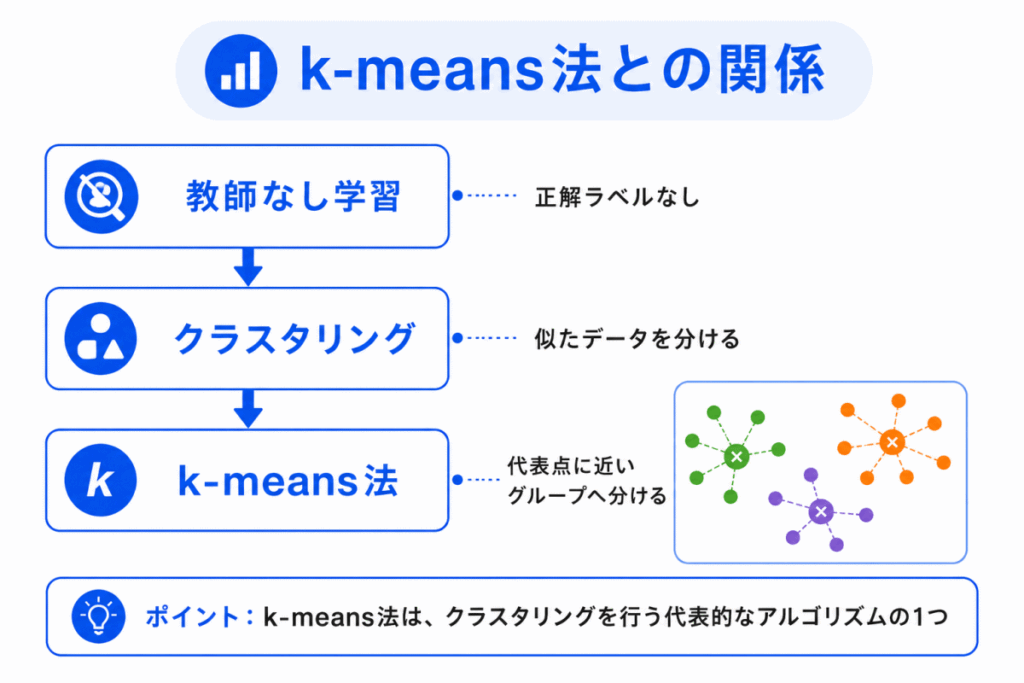
k-means法は、クラスタリングの代表的な手法です。
あらかじめクラスタの数を決め、各データを代表点に近いグループへ分けていきます。
たとえば、「3つのグループに分けたい」と決めてから、データを近いグループに割り当てます。
ここで大切なのは、k-means法はクラスタリングそのものではなく、クラスタリングを行うための具体的な手法の1つだということです。
関係を整理すると、次のようになります。
| 用語 | 位置づけ |
|---|---|
| 教師なし学習 | 正解ラベルなしでデータの構造を見つける学習 |
| クラスタリング | 教師なし学習の代表的な方法 |
| k-means法 | クラスタリングを行う代表的なアルゴリズム |
G検定では、この階層関係を押さえておくと混同しにくくなります。
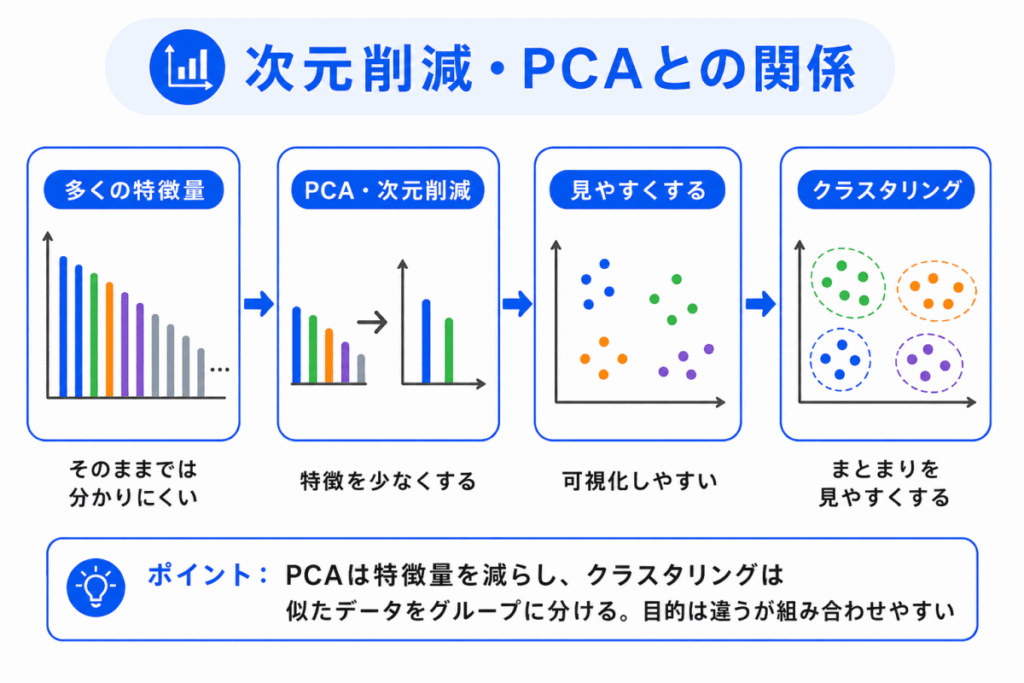
クラスタリングは、次元削減やPCAとも関係します。
データの特徴量が多すぎると、データ同士がどれくらい似ているのかを直感的に理解しにくくなります。
そこで、PCAなどの次元削減を使って特徴量を少なくすると、クラスタの様子を可視化しやすくなることがあります。
たとえば、多くの特徴量を持つ顧客データを2次元に圧縮すると、似ている顧客が近くに集まって見える場合があります。
ただし、PCAはデータを低次元に圧縮する手法です。
クラスタリングは、データをグループに分ける手法です。
目的が違う点に注意しましょう。
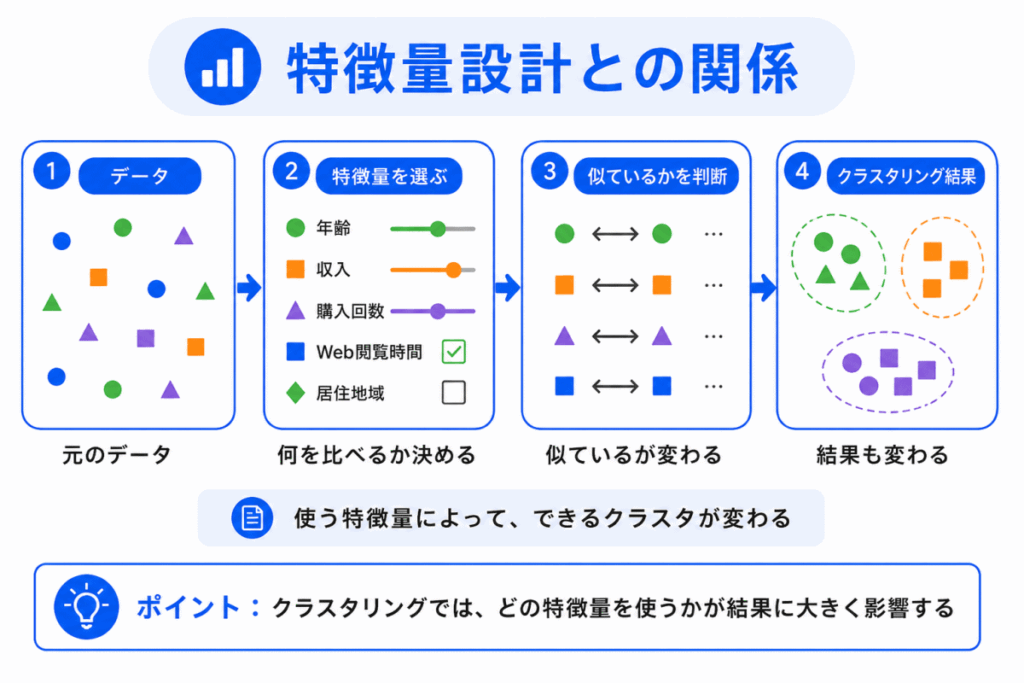
クラスタリングでは、どの特徴量を使うかが重要です。
なぜなら、クラスタリングはデータ同士の「似ている」をもとにグループを作るからです。
たとえば、顧客をグループに分ける場合、年齢、購入回数、購入金額、閲覧履歴など、どの特徴量を使うかによって結果が変わります。
関係のない特徴量が多いと、意味のあるクラスタが見えにくくなることもあります。
そのため、クラスタリングは特徴量設計やデータ前処理とも深く関係します。
クラスタリングは便利ですが、結果をそのまま正解と考えるのは危険です。
クラスタリングは、あくまでデータの特徴にもとづいて機械的にグループを作ります。
そのため、作られたクラスタに意味があるかどうかは、人間が確認する必要があります。
たとえば、顧客データを3つのグループに分けたとしても、それぞれが本当に意味のある顧客タイプになっているとは限りません。
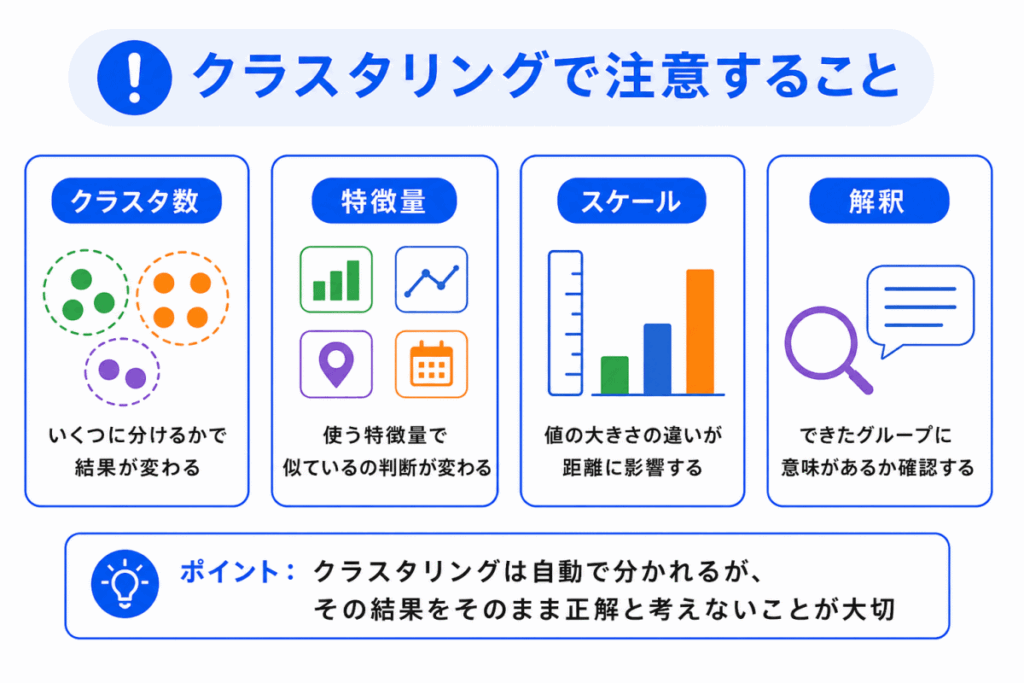
クラスタリングでは、次の点に注意します。
| 注意点 | 意味 |
|---|---|
| クラスタ数 | いくつのグループに分けるかで結果が変わる |
| 特徴量 | 使う特徴量によって似ているの判断が変わる |
| スケール | 値の大きさが違うと距離の計算に影響する |
| 解釈 | できたグループに意味があるか確認が必要 |
特に、数値のスケールが大きく違う場合は、正規化や標準化が関係します。
G検定では、クラスタリングについて細かい計算よりも、意味や位置づけが問われやすいです。
特に、教師あり学習の分類との違いを押さえることが大切です。
| 問われやすいポイント | 押さえ方 |
|---|---|
| クラスタリング | 似ているデータをグループに分ける |
| 教師なし学習 | 正解ラベルなしでデータの構造を見つける |
| 分類との違い | 分類は正解ラベルあり、クラスタリングは正解ラベルなし |
| k-means法 | クラスタリングの代表的な手法 |
| 特徴量との関係 | 何を似ていると見るかは特徴量に左右される |
「分類」と「クラスタリング」はどちらもデータを分けるため、混同しやすいです。
G検定では、正解ラベルがあるかどうかで判断すると整理しやすくなります。

まとめると次のような整理できます。
クラスタリングは、教師なし学習の代表的な考え方です。
正解ラベルがないデータから、似ているもの同士をグループに分けます。
分類との違いは、正解ラベルがあるかどうかです。
また、クラスタリングの結果は、特徴量、スケール、クラスタ数によって変わります。
G検定では、クラスタリングを「教師なし学習」、「正解ラベルなし」、「似たデータをグループ化」、「k-means法」とつなげて理解しておきましょう。
教師なし学習の全体像を確認するなら、こちらの記事がおすすめです。
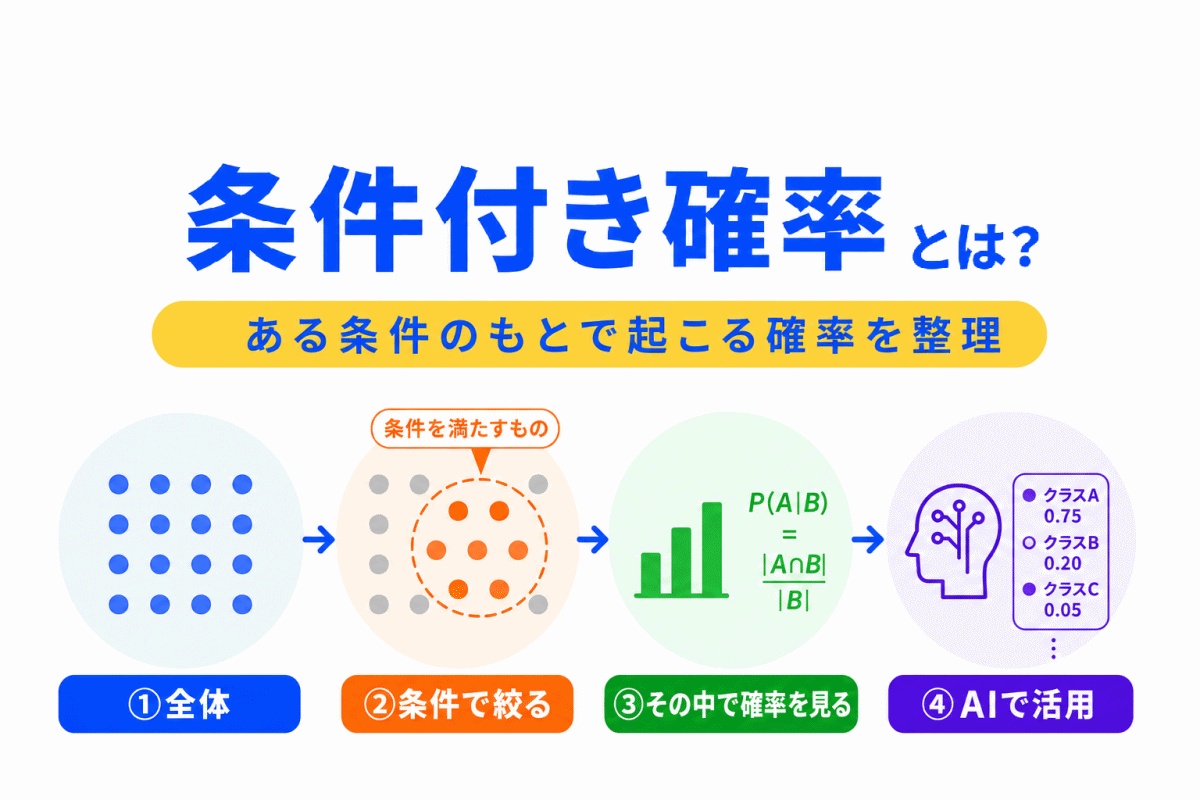
教師あり学習との違いを確認するなら、こちらの記事がおすすめです。
クラスタリングと一緒に出やすい次元削減を確認するなら、こちらの記事がおすすめです。
クラスタリングの結果に影響する特徴量を確認するなら、こちらの記事がおすすめです。

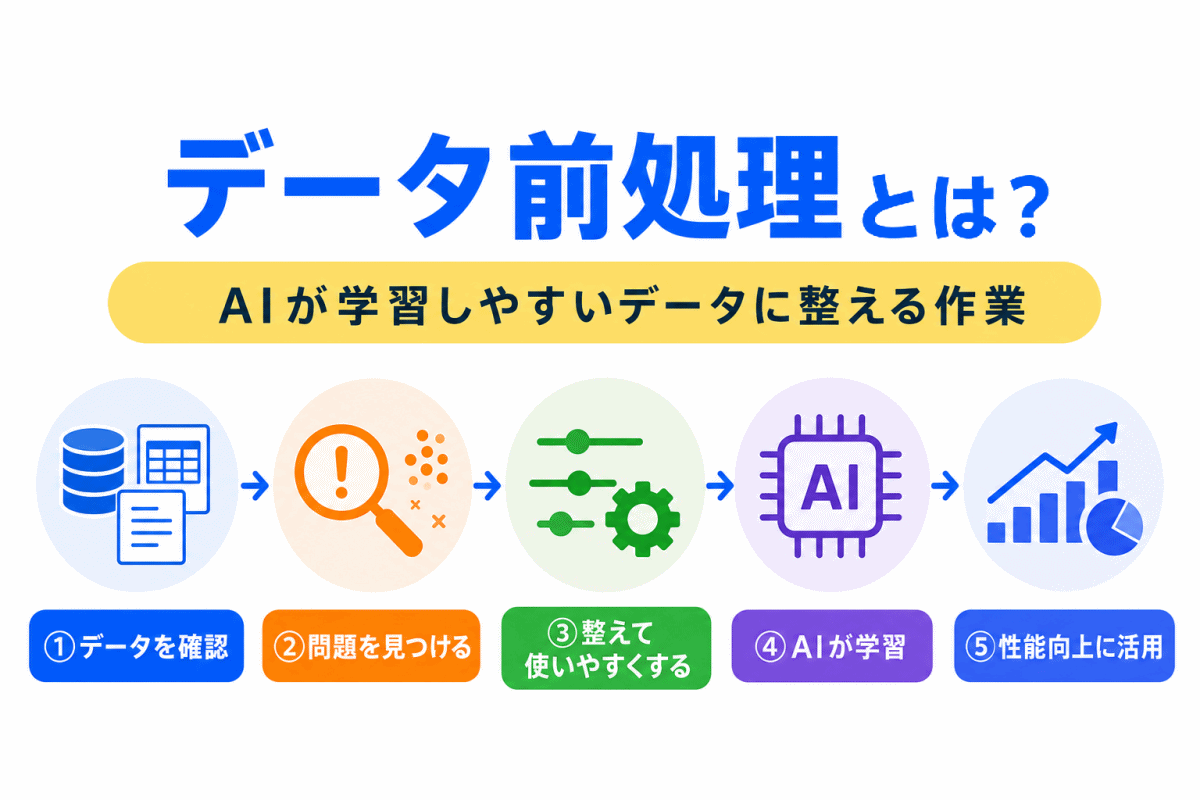
データを学習しやすく整える流れを確認するなら、こちらの記事がおすすめです。
スケール調整との関係を確認するなら、こちらの記事がおすすめです。
機械学習全体の中で位置づけを確認するなら、こちらの記事がおすすめです。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認