【G検定対策】データ前処理とは?|AIが学習しやすいデータに整える作業をわかりやすく整理
seo-webmaster
G検定対策ブログ
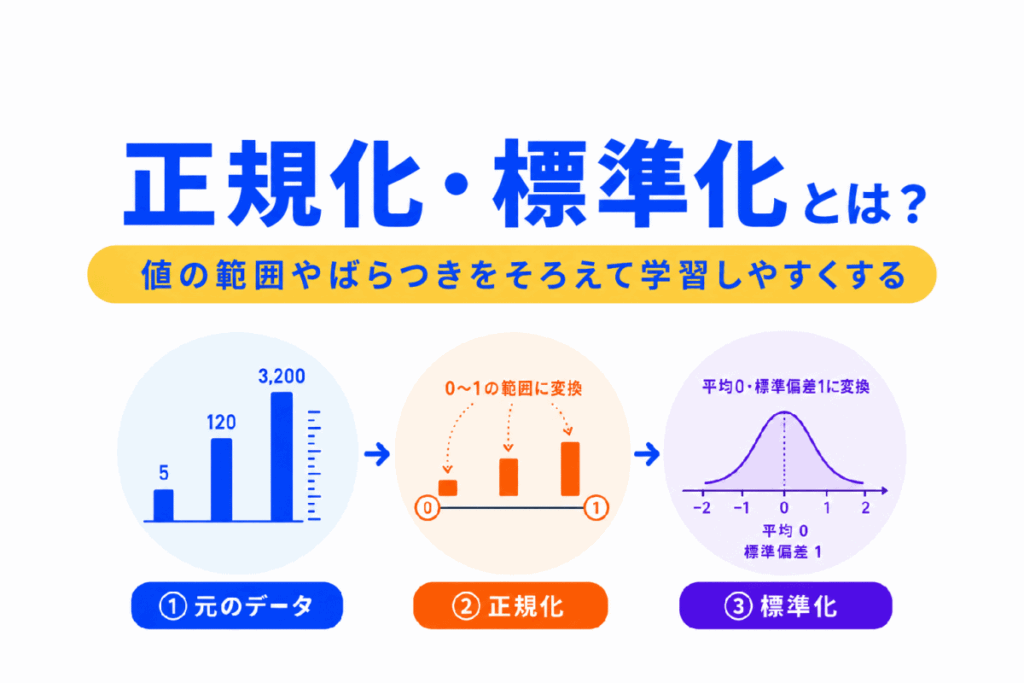
正規化・標準化は、データの値の大きさをそろえる前処理です。
AIや機械学習では、年齢、身長、年収、購入回数のように、単位や値の範囲が違うデータを同時に扱います。
そのまま学習すると、値が大きい特徴だけが強く影響してしまうことがあります。
そこで、正規化や標準化によって、特徴量のスケールを整えます。
この記事では、正規化と標準化の違い、正則化との違い、AIでなぜ重要なのかを、G検定向けにわかりやすく整理します。

正規化・標準化とは、データの値の大きさをそろえるための前処理です。
AIは、データを数値として扱います。
そのため、特徴量ごとの値の範囲が大きく違うと、学習が不安定になったり、一部の特徴だけが強く影響したりすることがあります。
たとえば、次のようなデータを考えます。
このように、特徴量によって値の範囲は大きく違います。
正規化・標準化は、このような数値のスケールをそろえるために使います。
| 用語 | 一言でいうと |
|---|---|
| 正規化 | 値の範囲をそろえる前処理 |
| 標準化 | 平均やばらつきを基準にそろえる前処理 |
| 目的 | AIが特徴量を扱いやすくする |
| 関係する分野 | データ前処理、特徴量設計、機械学習 |

正規化・標準化が必要になる理由は、特徴量ごとのスケールが違うからです。
たとえば、年齢と年収を同時に使う場合、年収の数値は年齢よりかなり大きくなります。
AIは数値をもとに計算するため、値が大きい特徴量を「重要そう」と扱ってしまうことがあります。
もちろん、値が大きいからといって、本当に重要とは限りません。
正規化・標準化は、特徴量を公平に扱いやすくするための準備です。
流れで見ると、次のようになります。

正規化とは、データの値の範囲をそろえる前処理です。
代表的な方法は、値を0〜1の範囲に変換する方法です。
たとえば、身長、年収、購入回数のように値の範囲が違う特徴量を、同じような範囲にそろえます。
イメージとしては、次のような変換です。
代表的な式は次の形です。
正規化後の値 = (元の値 – 最小値) / (最大値 – 最小値)
この式を覚えることよりも、G検定では「値の範囲をそろえる」という意味を押さえることが重要です。

標準化とは、データを平均0、標準偏差1に近づける前処理です。
平均からどれくらい離れているかを基準にして、値を変換します。
代表的な式は次の形です。
標準化後の値 = (元の値 – 平均) / 標準偏差
標準化では、単に0〜1に収めるのではなく、平均とばらつきを基準にします。
そのため、「平均より大きいか」「平均からどれくらい離れているか」を見やすくなります。
たとえば、テストの点数で考えると、単純な点数だけでなく、平均との差を見るイメージです。
このような位置関係を扱いやすくするのが標準化です。

正規化と標準化は、どちらもデータのスケールを整える前処理です。
ただし、そろえ方が違います。
| 項目 | 正規化 | 標準化 |
|---|---|---|
| 目的 | 値の範囲をそろえる | 平均とばらつきを基準にそろえる |
| 代表的な変換 | 0〜1の範囲に変換する | 平均0、標準偏差1に近づける |
| 基準 | 最小値・最大値 | 平均・標準偏差 |
| イメージ | 値の範囲をそろえる | 平均との差を見やすくする |
| 関係する考え方 | スケーリング | 平均、分散、標準偏差 |
ざっくり言うと、正規化は「範囲をそろえる」、標準化は「平均との差でそろえる」と考えるとわかりやすいです。

G検定では、正規化、標準化、正則化を混同しないことが重要です。
特に、正規化と正則化は名前が似ています。
しかし、意味はまったく違います。
正規化・標準化は、データを学習しやすくするための前処理です。
一方、正則化は、過学習を防ぐための工夫です。
| 用語 | 目的 | 一言でいうと |
|---|---|---|
| 正規化 | 値の範囲をそろえる | データのスケールを整える |
| 標準化 | 平均とばらつきを基準にそろえる | 平均との差を扱いやすくする |
| 正則化 | 過学習を防ぐ | モデルが複雑になりすぎないようにする |
正規化・標準化は「データ側」の調整です。
正則化は「モデル側」の調整です。
この違いを押さえると、混同しにくくなります。

正規化・標準化は、機械学習の前処理として使われます。
特に、距離や勾配を使う手法では重要です。
たとえば、k-means法 や k近傍法 では、データ同士の距離を使います。
特徴量のスケールが違うと、値の大きい特徴量が距離計算に強く影響します。
また、勾配降下法を使うモデルでは、特徴量のスケールがそろっている方が学習が安定しやすくなります。
ニューラルネットワークでも、入力データのスケールを整えることがあります。
ただし、すべての手法で同じように重要というわけではありません。
決定木やランダムフォレストのような木構造の手法では、正規化・標準化の影響が比較的小さい場合もあります。
G検定では、手法ごとの細かい使い分けよりも、「特徴量のスケールをそろえる前処理」として理解しておくことが大切です。

正規化・標準化は、データ前処理の一部です。
また、特徴量設計とも関係します。
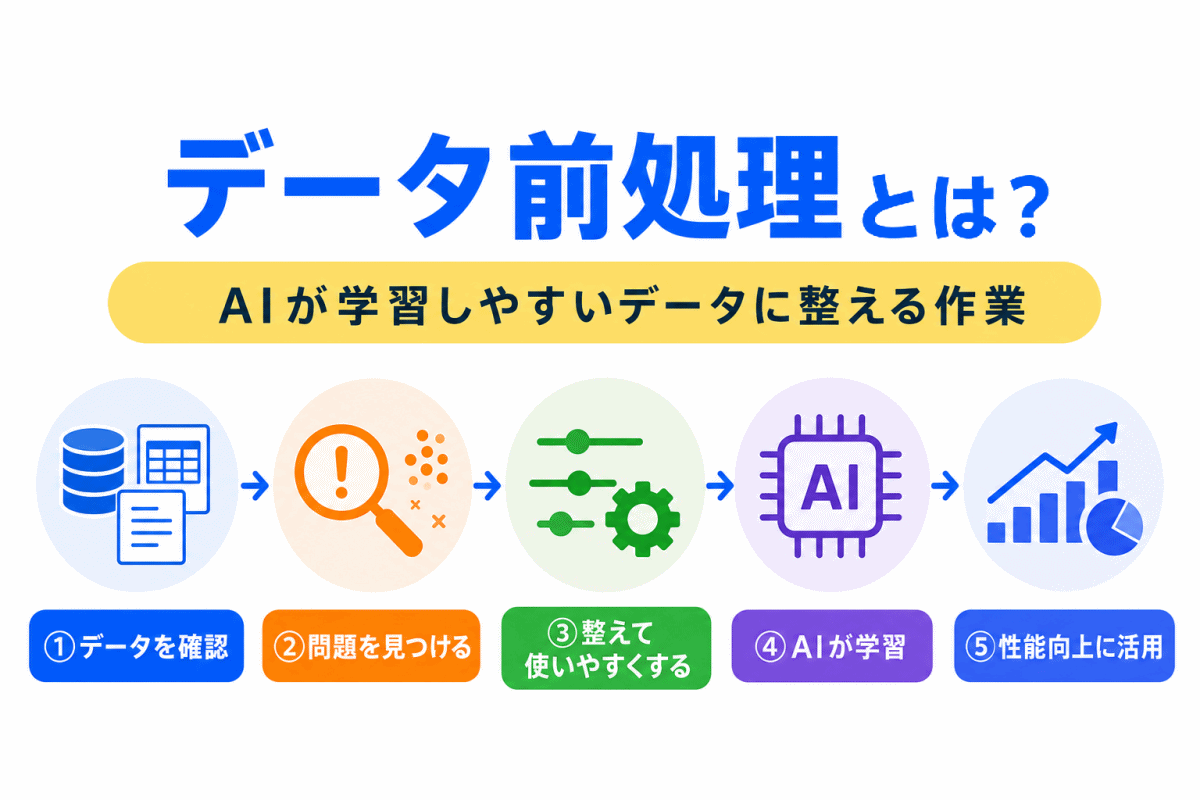
データ前処理は、AIが学習しやすいようにデータを整える作業です。
特徴量設計は、AIが学習しやすい特徴を作る作業です。
正規化・標準化は、その中で「数値のスケールを整える」役割を持ちます。
たとえば、欠損値を処理したあと、外れ値を確認し、必要に応じて正規化・標準化を行う流れが考えられます。

正規化・標準化では、学習データとテストデータの扱いに注意が必要です。
機械学習では、学習データで計算した最小値、最大値、平均、標準偏差を使って、検証データやテストデータも変換します。
テストデータまで含めて平均や標準偏差を計算してしまうと、本来は学習時に知らない情報を使うことになります。
これは、データリーケージにつながる可能性があります。
つまり、正規化・標準化は便利ですが、データの分け方と処理の順番にも注意が必要です。
正則化、正規化、標準化は名前が似ていますが、役割は違います。
正則化はモデル側の調整、正規化と標準化はデータ側の前処理として整理すると理解しやすくなります。
| 用語 | 意味 | 見分け方 |
|---|---|---|
| 正則化 | モデルが複雑になりすぎないようにして、過学習を防ぐ考え方 | モデル側を調整する |
| 正規化 | データの値の範囲を、0〜1など一定の範囲にそろえる前処理 | 値の範囲をそろえる |
| 標準化 | 平均や標準偏差を使って、データのスケールをそろえる前処理 | 平均0、標準偏差1に近づける |
G検定では、正規化・標準化の細かい計算よりも、意味や違いが問われやすいです。
特に、正則化との混同に注意が必要です。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 正規化の意味 | 値の範囲をそろえる前処理 |
| 標準化の意味 | 平均0、標準偏差1に近づける前処理 |
| 正則化との違い | 正則化は過学習を防ぐ工夫 |
| AIで使う理由 | 特徴量のスケールをそろえて学習しやすくする |
| 関係する分野 | データ前処理、特徴量設計、勾配降下法 |
AIの学習をはじめたばかりの人は、まず次の3つを区別すると理解しやすくなります。

正規化・標準化は、AIがデータを学習しやすくするための前処理 です。
正規化は、値の範囲をそろえる考え方 です。
標準化は、平均と標準偏差を基準に値をそろえる考え方 です。
どちらも、特徴量のスケールを整えるために使います。
一方、正則化は過学習を防ぐ工夫であり、正規化・標準化とは目的が違います。
| 用語 | 意味 | 覚え方 |
|---|---|---|
| 正規化 | 値の範囲をそろえる | 0〜1などにそろえる |
| 標準化 | 平均とばらつきを基準にそろえる | 平均0、標準偏差1に近づける |
| 正則化 | 過学習を防ぐ | モデルを複雑にしすぎない |
| G検定での重要点 | 意味と違いを理解する | 名前の似た用語を混同しない |
正規化・標準化は、数式を暗記するよりも、「AIがデータを公平に扱いやすくする準備」として理解すると、機械学習全体の流れとつながりやすくなります。
正規化・標準化は、データのスケールをそろえてAIが学習しやすい状態に整える考え方です。
前処理、特徴量設計、ベクトル・行列、平均・標準偏差、微分、正則化との違いまでつなげると整理しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| データ前処理とは? | AIが学習しやすいデータに整える作業/欠損・ノイズ・表記ゆれ/正規化・標準化の位置づけ |
| 特徴量設計とは? | AIが学習しやすい特徴を作る考え方/数値データの扱い/前処理との違い |
| ベクトル・行列とは? | AIがデータを数値で扱う考え方/数値のまとまり/スケール調整との関係 |
| 期待値・分散・標準偏差とは? | 平均的な値とばらつき/標準偏差の意味/標準化の理解に必要な基礎 |
| 微分とは? | 少し変えたときの変化/勾配降下法との関係/学習しやすさの理解 |
| 正則化とは? | モデルの複雑さを抑える考え方/過学習対策/正規化との違い |
| バッチ正規化・レイヤー正規化とは? | バッチ正規化/レイヤー正規化/正規化層/CNN/Transformer/正規化・標準化/正則化 |
| スキップ結合・ResNetとは? | スキップ結合/ResNet/残差学習/勾配消失問題/CNN・画像認識 |
| 正規化・正則化の違いを確認する | 正規化/正則化/過学習対策/正規化層 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。