【合格体験談】G検定は本当に簡単なの!?1回落ちた失敗を踏まえた体験談
seo-webmaster
G検定対策ブログ
G検定では、ディープラーニングの仕組みだけでなく、それが実際にどのような分野で使われているのかも問われます。
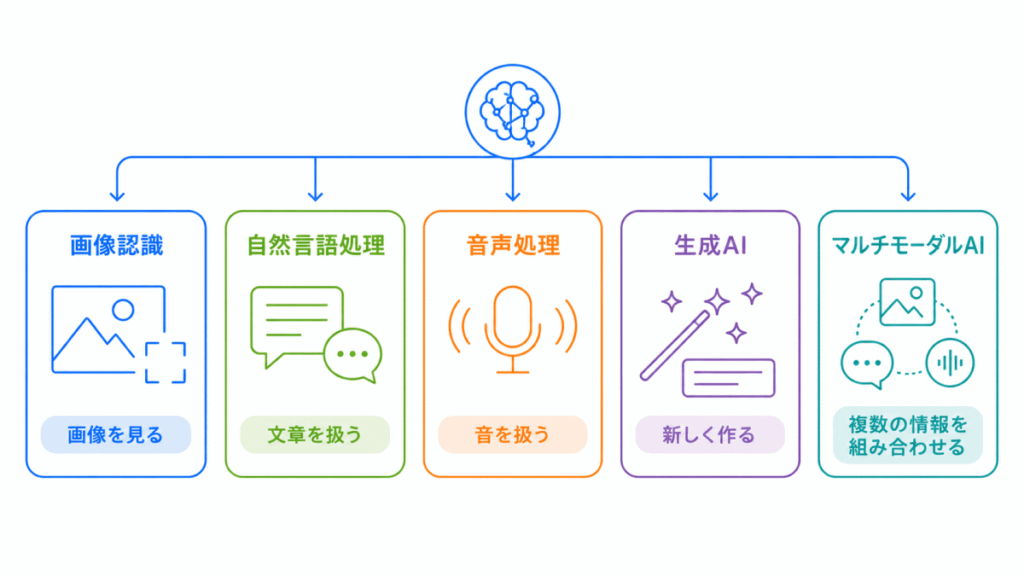
画像認識、物体検出、セグメンテーション、自然言語処理、音声認識、生成AI、転移学習、データ拡張、マルチモーダルAIは、それぞれ別々の用語に見えます。
しかし、流れで見ると、ディープラーニングが「画像」、「文章」、「音声」、「生成」、「複数の情報の組み合わせ」にどう応用されているかを理解するためのテーマです。
この記事では、ディープラーニングの応用例を、G検定で混同しやすい用語とつなげて整理します。
ディープラーニングの応用例とは、ニューラルネットワークを使って、画像、文章、音声、生成などの課題を解く技術や活用分野のことです。
G検定では、モデルの細かい実装よりも、「どの技術が、どの課題に使われるのか」を整理しておくことが大切です。
たとえば、画像を扱う場合でも、画像全体を分類するのか、画像内の物体を見つけるのか、領域ごとに分けるのかで、使う考え方が変わります。
整理すると、次のようになります。
| 応用分野 | 見るポイント | 一言でいうと |
|---|---|---|
| 画像認識 | 画像から特徴を取り出して判断する | 画像を見て何が写っているかを扱う分野 |
| 自然言語処理 | 文章や単語の意味・文脈を扱う | AIが文章を扱うための分野 |
| 音声処理 | 音声を認識・変換・生成する | 音をAIで扱う分野 |
| 生成AI | 文章・画像・音声などを新しく作る | 新しいコンテンツを生成するAI |
| マルチモーダルAI | 画像・文章・音声などを組み合わせる | 複数種類の情報を同時に扱うAI |
この分野は、用語を単独で覚えるよりも、「何を入力として、何を出力するのか」を意識すると整理しやすくなります。
G検定の得点率で表示される分野は8分野です。その8分野の5番目の分野のまとめ記事がこの記事です。そして、さらに詳細な記事へとつながります。
イメージ図で表すと次の図になります。

ディープラーニングの応用例で出てくる用語をまとめて確認したい場合は、こちらの記事も参考になります。
| 読む記事 | 確認できる内容 |
|---|---|
| ディープラーニング応用例の重要用語 | 画像認識/自然言語処理/音声処理/生成AI/推薦・異常検知/医療・自動運転/代表モデルとの対応関係 |
ディープラーニングの応用例では、AIが実際にどのような課題に使われるのかを学びます。
重要なテーマは、次のように整理できます。
| 項目 | 学ぶ内容 |
|---|---|
| 画像認識 | 画像を分類したり、画像内の対象を見つけたりする技術を理解する |
| 物体検出 | 画像の中のどこに何があるかを判断する技術を理解する |
| セグメンテーション | 画像をピクセル単位や領域単位で分ける技術を理解する |
| 自然言語処理 | 文章をAIが扱うための考え方を理解する |
| 音声処理 | 音声認識や音声生成など、音を扱うAIの応用を理解する |
| 生成AI | 文章・画像・音声などを生成する仕組みを理解する |
| 転移学習・データ拡張 | 少ないデータでも学習しやすくする工夫を理解する |
| マルチモーダルAI | 画像・文章・音声など複数の情報を組み合わせるAIを理解する |
この分野を理解すると、CNN、RNN、Transformer、生成モデルなどが、実際にどのような場面で使われるのかが見えやすくなります。
ディープラーニングの代表的なモデルとの関係を確認したい場合は、こちらの記事も参考になります。
| 読む記事 | 確認できる内容 |
|---|---|
| CNN・RNN・Transformerの違い | CNNは画像/RNNは時系列/Transformerは文章・生成AI/得意なデータと処理の考え方の違い |
画像認識とは、画像に写っているものをAIが判断する技術です。
たとえば、画像に犬が写っているのか、車が写っているのか、人が写っているのかを分類する場面で使われます。
ディープラーニングでは、特に CNN が画像認識で重要です。
CNN は、画像の中から特徴を取り出すのが得意なモデルです。
画像認識の基本的な流れは、次のように整理できます。
ここで大切なのは、AIが画像をそのまま人間のように見ているわけではないという点です。
AIは画像を数値のまとまりとして扱い、そこから特徴を取り出して判断しています。
画像認識がどのように発展してきたかを確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| 画像認識の歴史 | 画像認識の発展/CNN/AlexNet/VGG/GoogLeNet/ResNet/画像分類・物体検出・セグメンテーションの違い |
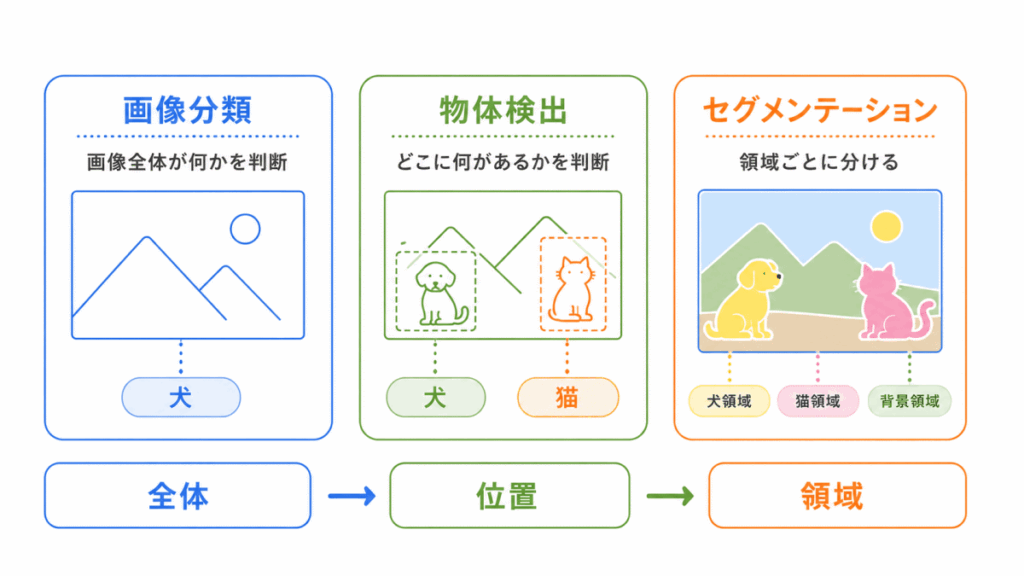
画像を扱う技術では、画像分類、物体検出、セグメンテーションが混同しやすいです。
それぞれの違いは、次のように整理できます。
| 技術 | 何をするか | 見るポイント |
|---|---|---|
| 画像分類 | 画像全体が何かを判断する | 画像全体を見る |
| 物体検出 | 画像の中のどこに何があるかを判断する | 位置と種類を見る |
| セグメンテーション | 画像をピクセル単位や領域単位で分ける | 領域を細かく分ける |
G検定では、この3つを区別できることが重要です。
たとえば、画像全体に「猫」とラベルを付けるのは画像分類です。
画像内の猫の位置を四角い枠で示すのは物体検出です。
猫の領域をピクセル単位で塗り分けるのはセグメンテーションです。
画像分類、物体検出、セグメンテーションの違いを詳しく確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| 物体検出とは? | 画像分類・物体検出・セグメンテーションの違い/画像の中の位置と種類を見つける考え方/CNNとの関係 |
| セグメンテーションとは? | 画像をピクセル単位・領域単位で分ける技術/画像分類・物体検出との違い/自動運転・医療画像での活用 |
物体検出とは、画像の中にある物体の位置と種類を見つける技術です。
画像分類では、画像全体に対して「犬」や「車」などのラベルを付けます。
一方、物体検出では、画像内のどこに犬がいるのか、どこに車があるのかまで判断します。
物体検出の代表的なモデルには、R-CNN系、YOLO、SSD などがあります。
| モデル | 特徴 | 押さえるポイント |
|---|---|---|
| R-CNN系 | 候補領域を使って物体を検出する流れ | 候補領域を使う考え方 |
| YOLO | 画像全体を一度に見て高速に検出する | 高速な物体検出 |
| SSD | 複数の特徴マップを使って検出する | YOLOと同じく高速な検出モデルとして整理する |
G検定では、細かい仕組みよりも、物体検出の目的と代表モデルの名前を整理しておくことが大切です。
物体検出の代表モデルを整理したい場合は、こちらの記事で詳しく解説しています。
| 読む記事 | 確認できる内容 |
|---|---|
| 物体検出の代表モデル | R-CNN/Fast R-CNN/Faster R-CNN/YOLO/SSD/バウンディングボックス/IoU/1段階型・2段階型の違い |
セグメンテーションとは、画像をピクセル単位や領域単位で分ける技術です。
画像分類や物体検出よりも、画像を細かく分ける点が特徴です。
たとえば、自動運転では、道路、歩行者、車、標識などを領域ごとに認識する必要があります。
医療画像では、臓器や病変部分を細かく分ける場面で使われます。
代表的なモデルには、FCN、U-Net、Mask R-CNN などがあります。
| モデル | 主な用途 | 押さえるポイント |
|---|---|---|
| FCN | 画像をピクセル単位で分類する | セグメンテーションの代表的な考え方 |
| U-Net | 医療画像などでよく使われる | エンコーダ・デコーダ構造と関連する |
| Mask R-CNN | 物体検出にマスク予測を加える | 物体検出とセグメンテーションのつながり |
画像をどのレベルで判断しているのかを意識すると、画像分類、物体検出、セグメンテーションの違いが整理しやすくなります。
セグメンテーションの代表モデルを整理したい場合は、こちらの記事で詳しく解説しています。
| 読む記事 | 確認できる内容 |
|---|---|
| セグメンテーション代表モデル | FCN/U-Net/Mask R-CNN/セマンティックセグメンテーション/インスタンスセグメンテーション/パノプティックセグメンテーション |
自然言語処理とは、人間が使う言葉をコンピュータで扱う技術です。
文章分類、翻訳、要約、質問応答、文章生成などが自然言語処理に含まれます。
ディープラーニングでは、RNN、LSTM・GRU、Seq2Seq、Attention、Transformer などが自然言語処理と深く関係します。
流れとしては、次のように整理できます。
文章をAIが扱うためには、文章をトークンに分け、単語や文の意味をベクトルで表す必要があります。
そのうえで、文の順番や単語同士の関係を扱います。
自然言語処理で出てくる基本用語を整理したい場合は、こちらの記事も参考になります。
| 読む記事 | 確認できる内容 |
|---|---|
| トークンとは? | 文章を細かく分ける単位/トークン化/次トークン予測/Attention・Transformer・GPT・RAGとの関係 |
| 単語埋め込みとは? | 単語を意味のある数値へ変換する技術/ベクトル化/分散表現/one-hot表現との違い/word2vec |
自然言語処理や生成AIでは、GPT、BERT、LLM が混同しやすいです。
違いは、次のように整理できます。
| 用語 | 意味 | 押さえるポイント |
|---|---|---|
| GPT | 文章生成に強いTransformer系モデル | 次の単語を予測する流れと関係する |
| BERT | 文脈理解に強いTransformer系モデル | 穴埋め学習やEncoder型として整理する |
| LLM | 大規模な言語モデル全般 | GPTはLLMの代表例として整理できる |
GPT は文章を生成する方向で理解すると整理しやすいです。
BERT は文章の意味や文脈を理解する方向で整理します。
LLM は、GPT などを含む大規模な言語モデル全般を指します。
GPT、LLM、BERTの違いを詳しく確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| GPTとは? | Transformerを使った文章生成AI/次単語予測/ChatGPTとの違い/LLMとの関係/ハルシネーション |
| LLMとは? | 大規模言語モデル/GPTとの違い/Transformerとの関係/次単語予測/RAGが必要になる理由 |
| BERTとは? | TransformerのEncoder型モデル/双方向の文脈理解/GPTとの違い/文章分類・意味理解 |
音声処理とは、音声を AI で扱う技術です。
音声認識、音声合成、話者識別などが関係します。
たとえば、音声認識では、人の声をテキストに変換します。
音声合成では、テキストから音声を生成します。
音声処理は、時系列データを扱う点で、RNN や LSTM・GRU などとも関係します。
また、現在では Transformer 系のモデルや、音声と言語を組み合わせるモデルとも関係します。
| 応用例 | 内容 |
|---|---|
| 音声認識 | 音声を文字に変換する |
| 音声合成 | 文字から音声を生成する |
| 話者識別 | 誰が話しているかを判断する |
G検定対策では、音声処理を単独で深掘りしすぎるよりも、画像、文章、音声の違いを整理しておくことが大切です。
生成AIとは、文章、画像、音声、動画などの新しいコンテンツを生成するAIです。
従来のAIは、分類や予測のイメージが強いかもしれません。
一方で、生成AIは、新しいデータを作る点が特徴です。
| 種類 | 内容 |
|---|---|
| 文章生成 | 質問への回答、要約、文章作成などを行う |
| 画像生成 | 指示に合わせて画像を生成する |
| 音声生成 | テキストから音声を作る |
| 動画生成 | 映像や動きのあるコンテンツを生成する |
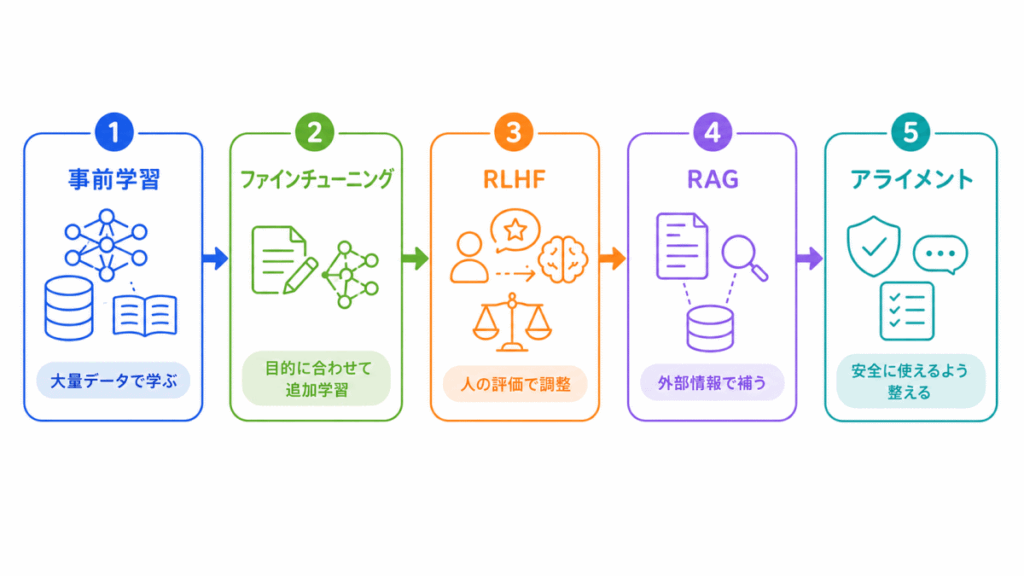
生成AIを理解するには、事前学習、ファインチューニング、RLHF、RAG、アライメントなどの関係も押さえておく必要があります。
生成AIの仕組みを流れで確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| 生成AIの仕組み | 事前学習/ファインチューニング/RLHF/RAG/アライメント/ハルシネーション/生成AIが使える形になるまでの流れ |
生成モデルとは、新しいデータを作るためのモデルです。
G検定では、GAN、VAE、拡散モデルが混同しやすいです。
違いは、次のように整理できます。
| 生成モデル | 仕組み | 押さえるポイント |
|---|---|---|
| GAN | 生成器と識別器を競わせる | 本物らしいデータを作る |
| VAE | 潜在表現を確率的に扱う | オートエンコーダから生成モデルにつながる |
| 拡散モデル | ノイズから復元する | 画像生成などで重要 |
生成モデルは、生成AIの仕組みを理解するうえでも重要です。
ただし、生成AIという言葉は、生成モデルそのものだけでなく、文章生成や画像生成などのサービスや応用も含んで使われます。
生成モデルの違いをまとめて確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| 生成モデルまとめ | 生成モデル/識別モデルとの違い/GAN・VAE・拡散モデル/生成AI・マルチモーダルAIとの関係 |
| GANとは? | 生成器と識別器を競わせる生成モデル/敵対的学習/本物らしいデータ生成/VAE・ディープフェイクとの関係 |
| VAEとは? | オートエンコーダを発展させた生成モデル/潜在表現/確率分布として扱う考え方/GANとの違い |
転移学習とは、ある課題で学習済みのモデルを、別の課題に活用する考え方です。
ディープラーニングでは、大量のデータと計算資源が必要になることがあります。
しかし、すでに学習済みのモデルを使えば、少ないデータでも学習を進めやすくなります。
転移学習は、画像認識や自然言語処理など、多くの分野で重要です。
ファインチューニングとも関係しますが、完全に同じ意味ではありません。
転移学習は、学習済みの知識を別の課題に活かす考え方です。
ファインチューニングは、そのモデルを特定の目的に合わせて追加学習する方法です。
転移学習とファインチューニングの関係を確認したい場合は、こちらの記事も参考になります。
| 読む記事 | 確認できる内容 |
|---|---|
| 転移学習とは? | 学習済みモデルを別の課題に活用する考え方/事前学習との違い/ファインチューニング・データ拡張との関係 |
| ファインチューニングとは? | 学習済みモデルを目的に合わせて追加調整する方法/転移学習との関係/生成AI・専門化とのつながり |
データ拡張とは、元のデータに加工を加えて、学習データを増やす工夫です。
特に画像認識では、画像の回転、反転、拡大縮小、明るさ変更などが使われます。
データ拡張を行うことで、モデルが特定のデータに合わせすぎることを防ぎやすくなります。
| データ拡張の例 | 目的 |
|---|---|
| 回転 | 角度が変わっても判断できるようにする |
| 反転 | 左右の違いに強くする |
| 明るさ変更 | 明るい画像や暗い画像にも対応しやすくする |
| 拡大・縮小 | 大きさの違いに強くする |
データ拡張は、過学習対策や汎化性能の改善とも関係します。
データ拡張の具体例を確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| データ拡張とは? | 学習データの見え方を増やす工夫/回転・反転・切り抜き・明るさ変更/過学習対策/正則化・転移学習との違い |
マルチモーダルAI とは、画像、文章、音声など、複数の種類の情報を組み合わせて扱う AI です。
たとえば、画像を見ながら文章で説明するAIや、音声とテキストを組み合わせて理解するAIが関係します。
モーダルとは、情報の種類のことです。
画像、文章、音声、動画などは、それぞれ異なるモーダルとして扱えます。
| 情報の種類 | 例 |
|---|---|
| 画像 | 写真、図、映像の一部 |
| 文章 | 質問文、説明文、会話文 |
| 音声 | 話し声、会話、音声入力 |
| 動画 | 画像の連続と音声の組み合わせ |
生成AI時代では、文章だけでなく、画像や音声も組み合わせて扱うAIが重要になっています。
G検定では、マルチモーダルAI を「複数の情報を組み合わせるAI」として押さえておくと整理しやすいです。
マルチモーダルAI の意味や生成AIとの関係を確認したい場合は、こちらの記事で整理しています。
| 読む記事 | 確認できる内容 |
|---|---|
| マルチモーダルAIとは? | 文章・画像・音声・動画を組み合わせて扱うAI/モダリティ/シングルモーダルAIとの違い/生成AI・画像認識・Transformerとの関係 |
ディープラーニングの応用例では、似た用語が多く出てきます。
特に、次の違いは試験直前に確認しておくと安心です。
| 混同しやすい用語 | 違い・確認ポイント |
|---|---|
| 画像分類・物体検出・セグメンテーション | 画像全体を分類する/位置と種類を見つける/領域単位で分ける |
| R-CNN・YOLO・SSD | 候補領域を使う流れ/高速な物体検出で使われる代表モデル |
| FCN・U-Net・Mask R-CNN | セグメンテーションで使われるモデル/Mask R-CNNは物体検出にマスク予測を加える |
| GPT・BERT・LLM | 文章生成に強い/文脈理解に強い/大規模言語モデル全般 |
| RAG・ファインチューニング・RLHF | 外部情報を使う/モデルを追加学習する/人間の評価で調整する |
| GAN・VAE・拡散モデル | 生成器と識別器を競わせる/潜在表現を確率的に扱う/ノイズから復元する |
| 転移学習・ファインチューニング | 学習済みモデルを別課題に活用する考え方/特定目的に合わせて追加学習する方法 |
| 生成AI・生成モデル・マルチモーダルAI | コンテンツを作るAI/データを生成するモデル/複数の情報を組み合わせるAI |
この表は、試験直前に見直すと効果的です。
用語を個別に覚えるよりも、「何を入力にして、何を出力するのか」、「どの課題に使うのか」を意識すると混同しにくくなります。
G検定では、ディープラーニングの応用例について、技術名と使われる場面の対応が問われやすいです。
細かい実装よりも、代表的な技術の役割と違いを整理しておくことが大切です。
| 問われやすい内容 | 確認ポイント | 注意点 |
|---|---|---|
| 画像分類・物体検出・セグメンテーション | 画像全体・位置・領域の違い | 画像をどの粒度で判断するかを見る |
| 物体検出モデル | R-CNN、YOLO、SSD | 代表モデルの名前と用途を整理する |
| セグメンテーションモデル | FCN、U-Net、Mask R-CNN | 領域分割と物体検出の関係に注意する |
| 自然言語処理 | トークン、Embedding、Transformer、GPT、BERT | 文章生成と文脈理解の違いを整理する |
| 生成AI | 事前学習、ファインチューニング、RLHF、RAG、アライメント | それぞれの役割を流れで理解する |
| 生成モデル | GAN、VAE、拡散モデル | 生成の仕組みの違いを押さえる |
| 転移学習・データ拡張 | 少ないデータで学習しやすくする工夫 | 過学習対策や汎化性能との関係を見る |
| マルチモーダルAI | 画像・文章・音声など複数の情報を扱うAI | 単一の情報だけを扱うAIとの違いを意識する |
G検定では、用語の名前だけでなく、「どの分野の応用例なのか」を判断できることが重要です。
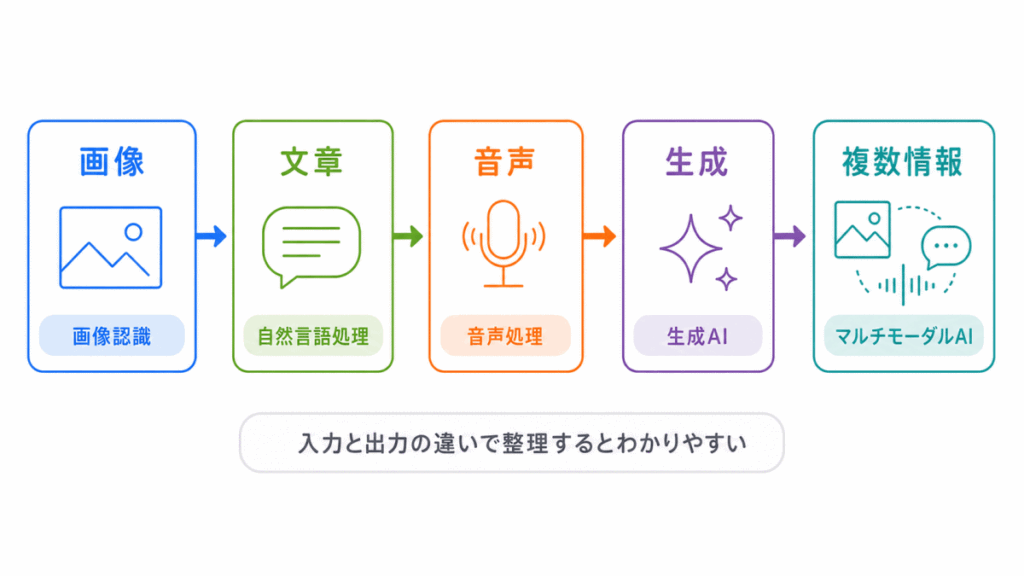
ディープラーニングの応用例は、AIが実際にどのような場面で使われるのかを理解する分野です。
画像認識、自然言語処理、音声処理、生成AI、マルチモーダルAIなど、扱う対象は幅広いです。
ただし、整理の軸はシンプルです。
G検定対策では、細かい技術をすべて暗記するよりも、「どの技術が、どの課題に使われるのか」を理解することが大切です。
特に、画像分類、物体検出、セグメンテーション、GPT、BERT、LLM、GAN、VAE、拡散モデル、RAG、ファインチューニング、RLHF は混同しやすいため、違いを表で確認しておきましょう。
ディープラーニングの応用例をさらに整理したい方は、次の記事も参考になります。
| 読む記事 | 確認できる内容 |
|---|---|
| ディープラーニング応用例の重要用語 | 画像認識/自然言語処理/音声処理/生成AI/推薦・異常検知/医療・自動運転 |
| ディープラーニングの応用例まとめ | 画像認識/自然言語処理/音声認識/生成AI/CNN・RNN・Transformerの対応関係 |
| 生成モデルまとめ | 生成モデル/識別モデルとの違い/GAN・VAE・拡散モデル/生成AI・マルチモーダルAIとの関係 |
| 物体検出とは? | 画像分類・物体検出・セグメンテーションの違い/位置と種類を見つける考え方 |
| セグメンテーションとは? | 画像をピクセル単位・領域単位で分ける技術/画像分類・物体検出との違い |
| 生成AIの仕組み | 事前学習/ファインチューニング/RLHF/RAG/アライメントを流れで整理 |
| マルチモーダルAIとは? | 画像・文章・音声など複数の情報を組み合わせて扱うAI/生成AI・基盤モデルとの関係 |
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認