【G検定対策】単語埋め込み(Embedding)とは?
seo-webmaster
SEO・ウェブマスターブログ
画像認識の分野では、画像に何が写っているかを判断するだけでなく、どこに何があるのか を見つける技術も重要です。
これが物体検出です。G検定では、画像分類・物体検出・セグメンテーションの違いに加えて、R-CNN 、YOLO、SSD などの代表的なモデル名が登場することがあります。
この記事では、物体検出の代表モデルを細かい仕組みまで深掘りしすぎず、AIの学習をはじめたばかりの人でも混同しにくいように整理します。
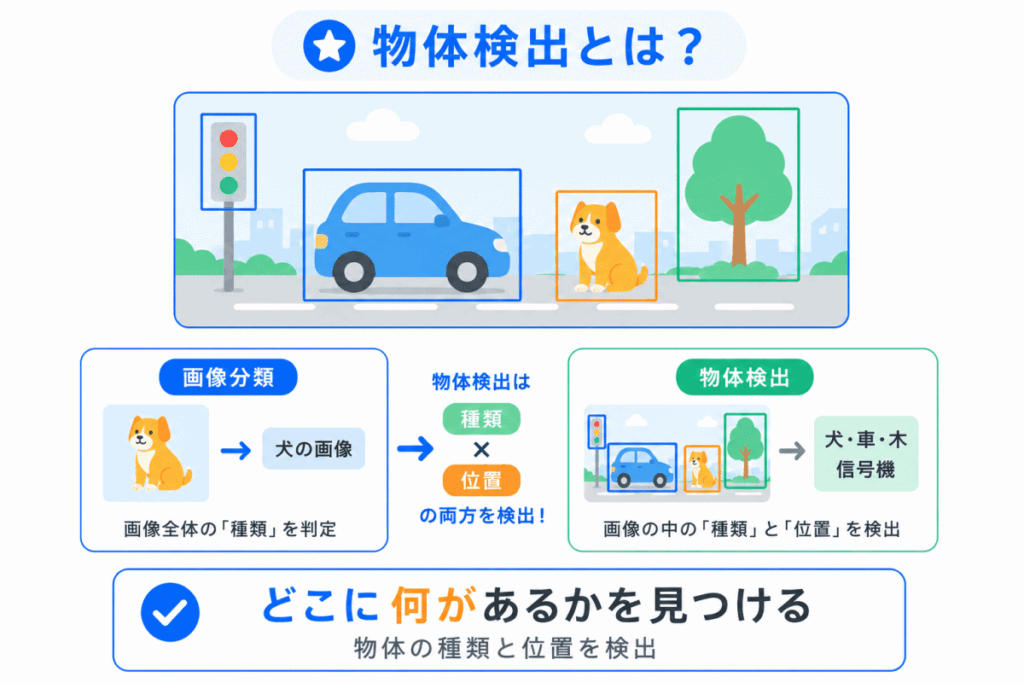
物体検出とは、画像の中にある物体の「種類」と「位置」を見つける技術 です。
たとえば、1枚の画像の中に車や犬や木が写っていたときに、「何があるか」だけでなく、「どこにあるか」まで判断します。
ここが、画像分類との大きな違いです。
画像分類は画像全体を見て「この画像は犬の画像」と判断しますが、物体検出は「画像の中のどこに犬がいるか」「ほかに何があるか」まで見ます。
| 技術 | 何を見るか |
|---|---|
| 画像分類 | 画像全体が何の画像かを判断する |
| 物体検出 | 画像の中の物体の種類と位置を見つける |
| セグメンテーション | 画像を領域ごとに細かく分ける |
物体検出では、位置を表すためにバウンディングボックスという四角い枠を使います。
たとえば、車のまわりを四角で囲めば、「ここに車がある」と表せます。
つまり、物体検出は次のように整理できます。
この2つを同時に扱うのが、物体検出のポイントです。
たとえば自動運転では、道路の画像から
などを見つけて、それぞれの位置を把握する必要があります。
そのため、物体検出は画像認識の中でもとても重要な技術です。
物体検出 = 画像の中 の「どこに何があるか」を見つける技術 と押さえると、全体像がつかみやすくなります。
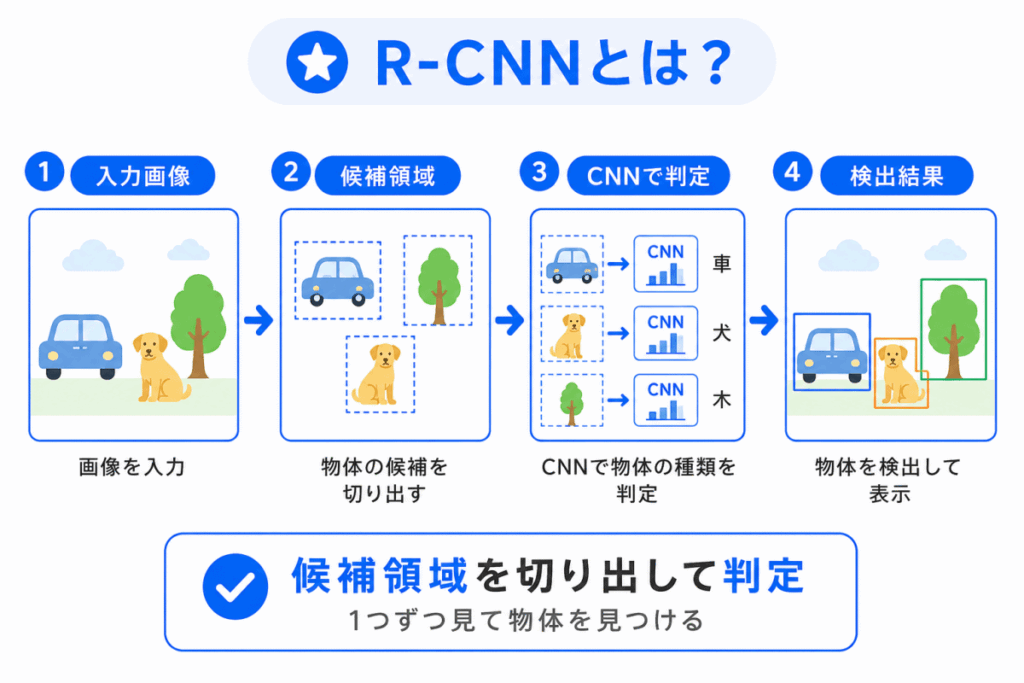
R-CNNは、物体検出の代表的なモデルのひとつです。
大まかには、画像の中から「物体がありそうな場所」を探し、その候補領域をCNNで判定する方法です。
流れで見ると、次のようになります。
R-CNNは、物体検出にCNNを活用した重要な流れの出発点として押さえると理解しやすいです。
ただし、候補領域ごとに処理するため、計算に時間がかかりやすいという弱点があります。
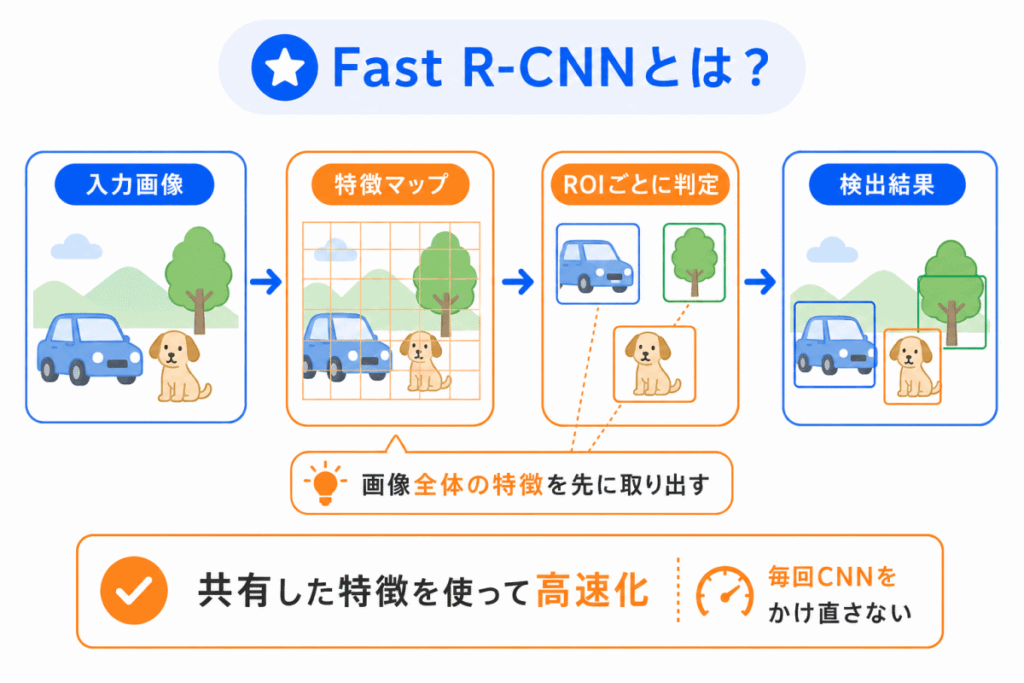
Fast R-CNNは、R-CNNを高速化したモデルです。
R-CNNでは、候補領域ごとにCNNの処理を行うため、時間がかかりやすいという問題がありました。
Fast R-CNNでは、画像全体から特徴を取り出してから、候補領域ごとに判断します。
つまり、処理の重複を減らして、より効率よく物体検出を行うモデルです。
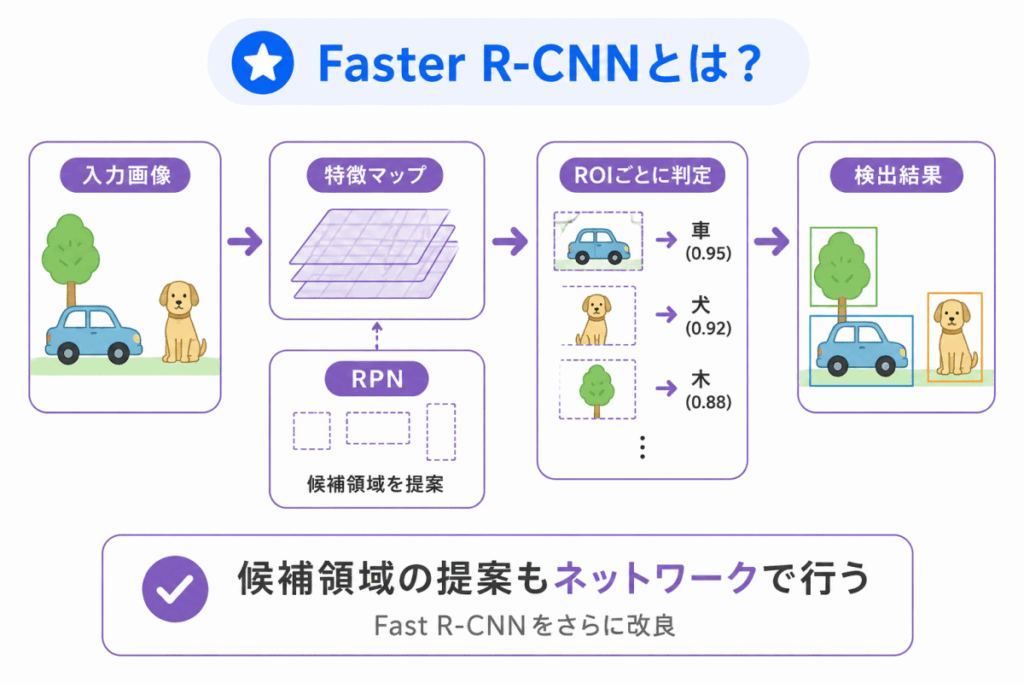
Faster R-CNNは、Fast R-CNNをさらに高速化したモデルです。
大きなポイントは、物体がありそうな領域を探す処理もニューラルネットワークで行うことです。
Fast R-CNNまでは、候補領域を探す部分が別の処理として残っていました。
Faster R-CNNでは、RPNという仕組みを使って、候補領域の提案もネットワーク内で行います。
| モデル | 特徴 |
|---|---|
| R-CNN | 候補領域を取り出してCNNで判定 |
| Fast R-CNN | 画像全体から特徴を取り出して高速化 |
| Faster R-CNN | 候補領域の提案もネットワークで行う |
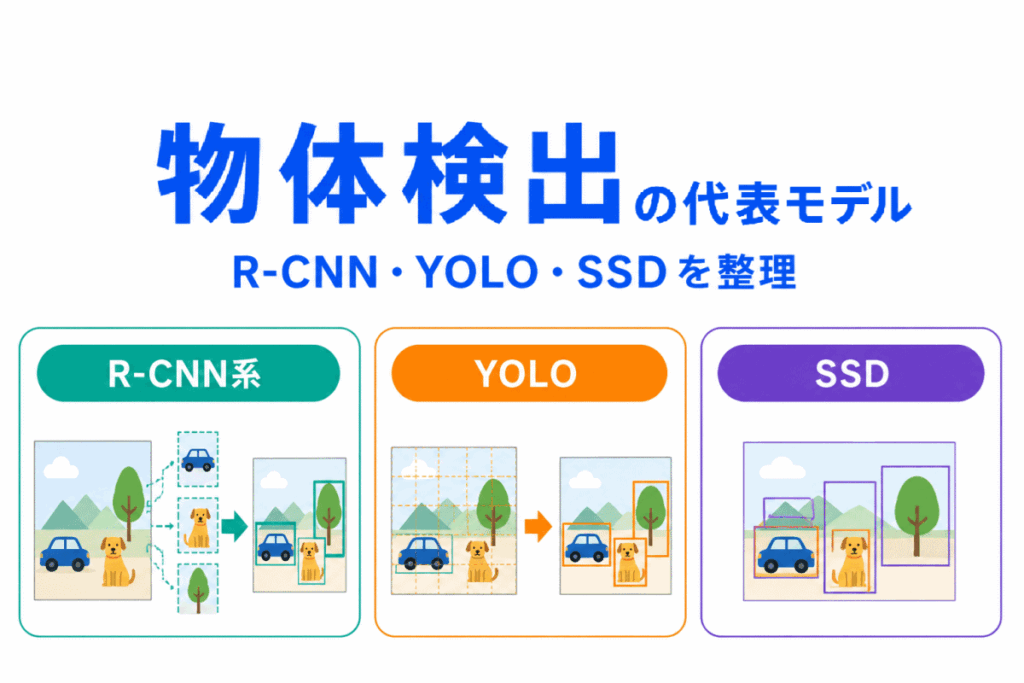
名前は似ていますが、流れとしては R-CNN → Fast R-CNN → Faster R-CNN の順に高速化されたと押さえると整理しやすいです。
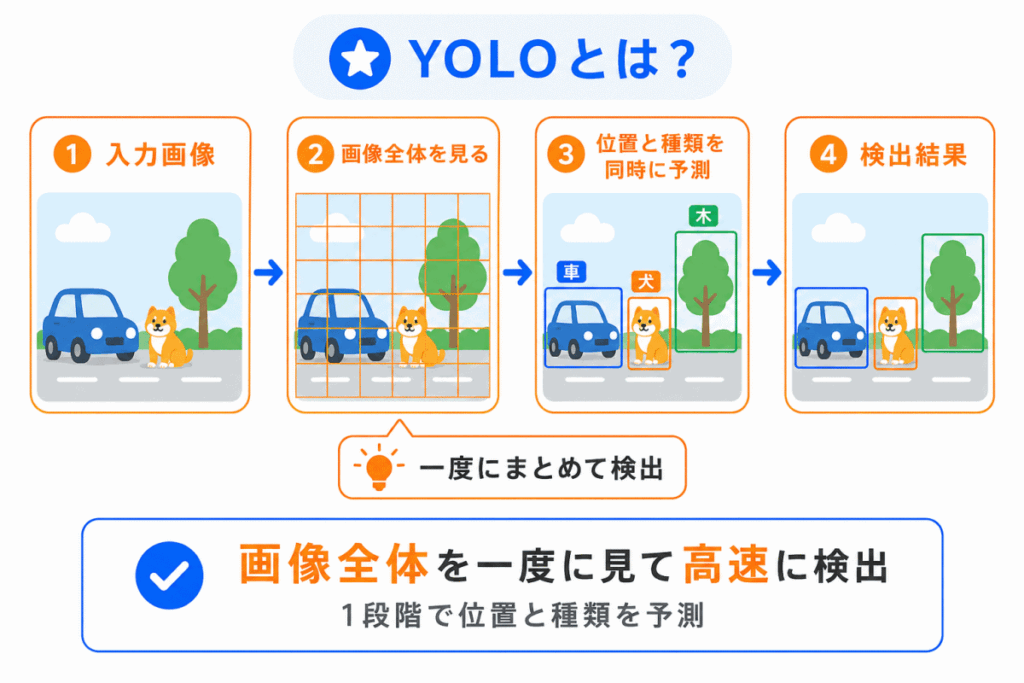
YOLOは、物体検出の代表的なモデルです。
YOLOは You Only Look Once の略で、画像を一度見るだけで、物体の種類と位置をまとめて予測する考え方です。
R-CNN系は、物体がありそうな場所を探してから分類する流れです。
R-CNN系
一方で、YOLOは画像全体を一度に見て、物体の位置と種類を同時に予測します。
YOLO
YOLOは高速に処理しやすいため、リアルタイムの物体検出と結びつけて覚えるとよいです。
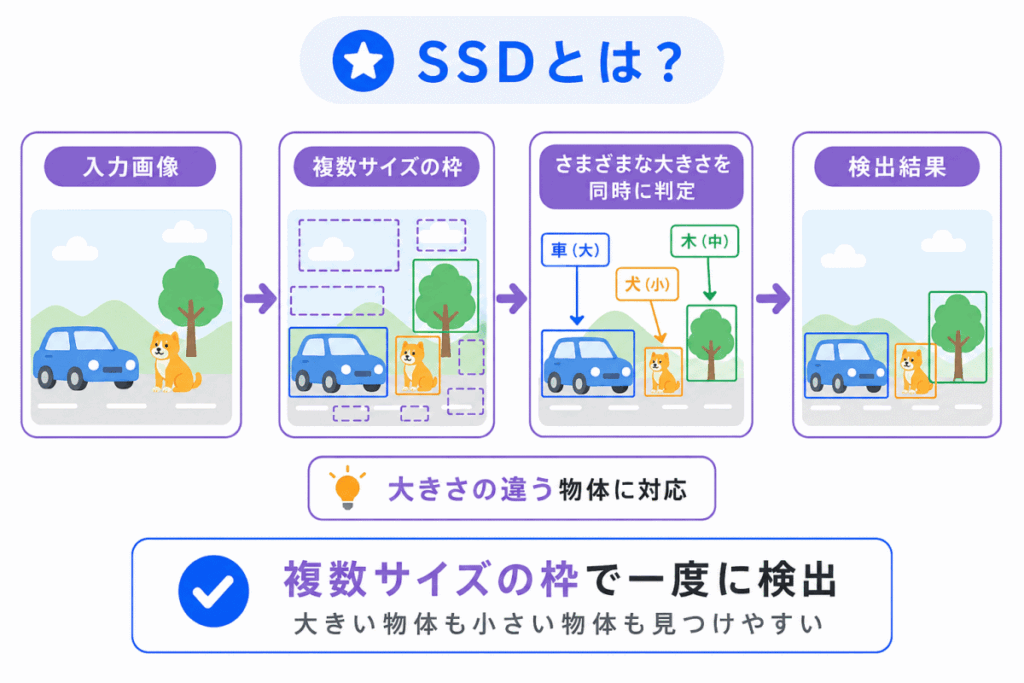
SSDは、Single Shot MultiBox Detector の略です。
YOLOと同じく、画像を一度に処理して物体を検出するタイプのモデルです。
SSDでは、複数の大きさの枠を使って、さまざまなサイズの物体を検出しようとします。
| モデル | 覚え方 |
|---|---|
| YOLO | 画像を一度に見て高速に検出する |
| SSD | 複数サイズの枠で物体を検出する |
SSDも、R-CNN系のように候補領域を段階的に処理するのではなく、1回の処理で物体の位置と種類を予測するモデルとして整理できます。
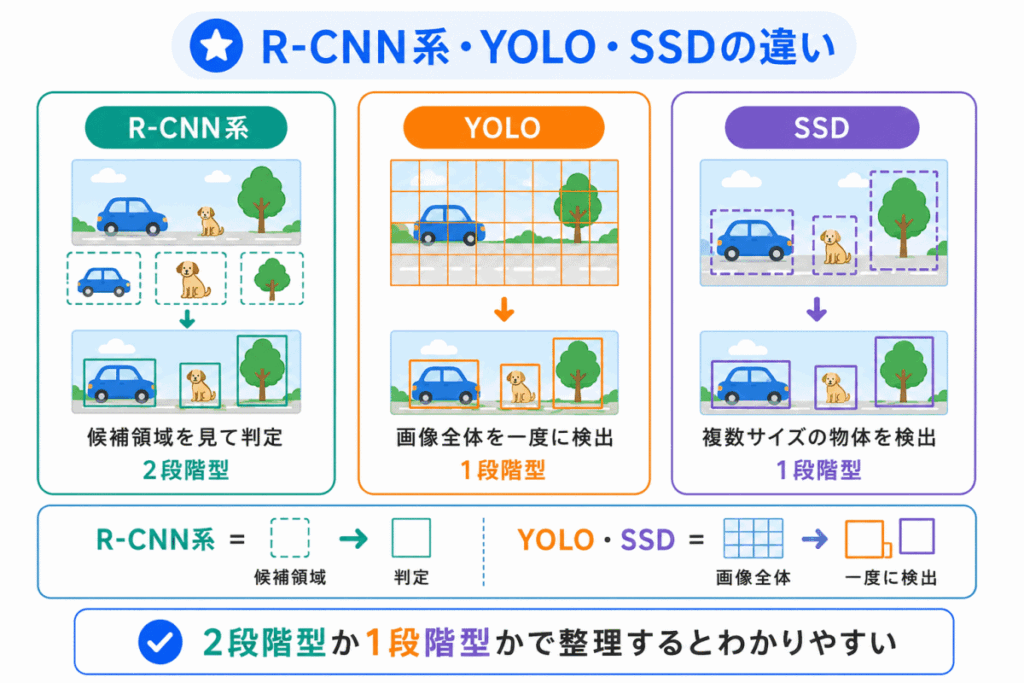
物体検出モデルは、細かい構造を覚えるよりも、まずは 1段階型か2段階型か で整理すると理解しやすいです。
| モデル | タイプ | 覚え方 |
|---|---|---|
| YOLO | 1段階型 | 画像全体を一度に見て高速に検出する |
| SSD | 1段階型 | 複数サイズの枠で一度に検出する |
| R-CNN | 2段階型 | 候補領域を取り出してから判定する |
| Fast R-CNN | 2段階型 | R-CNNを高速化したモデル |
| Faster R-CNN | 2段階型 | 候補領域の提案もネットワークで行う |
ざっくり整理すると、次のようになります。
G検定では、細かい数式よりも、この大きな違いを問われる可能性があります。
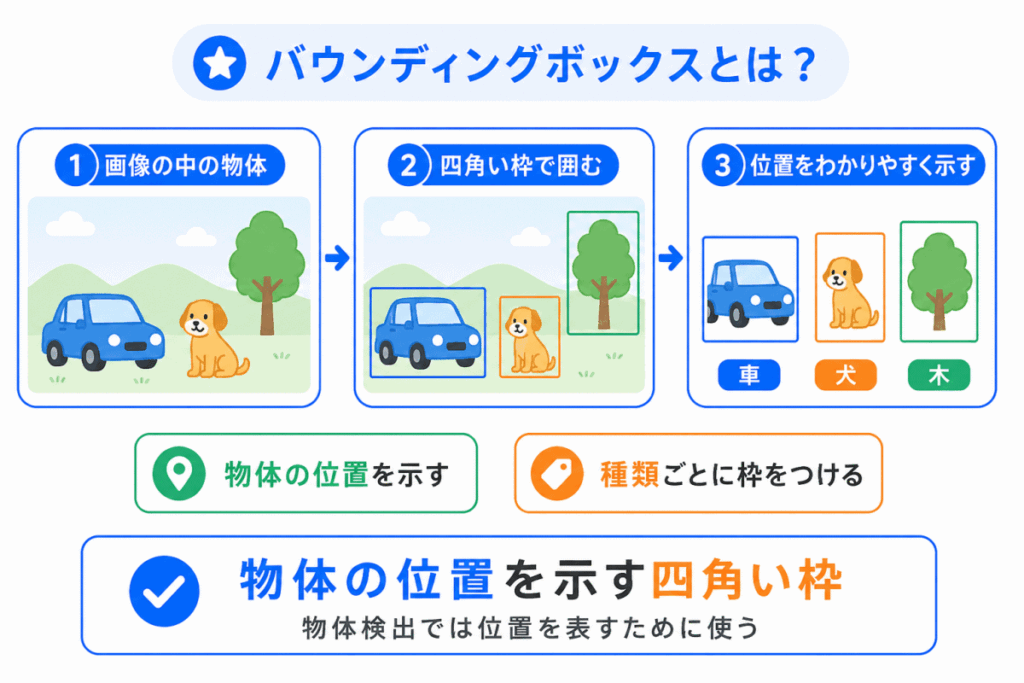
バウンディングボックスとは、画像の中の物体を囲む四角い枠のことです。
物体検出では、物体が「何か」だけでなく、「どこにあるか」も重要です。
その位置を表すために、四角い枠を使います。
この四角い枠が、バウンディングボックスです。
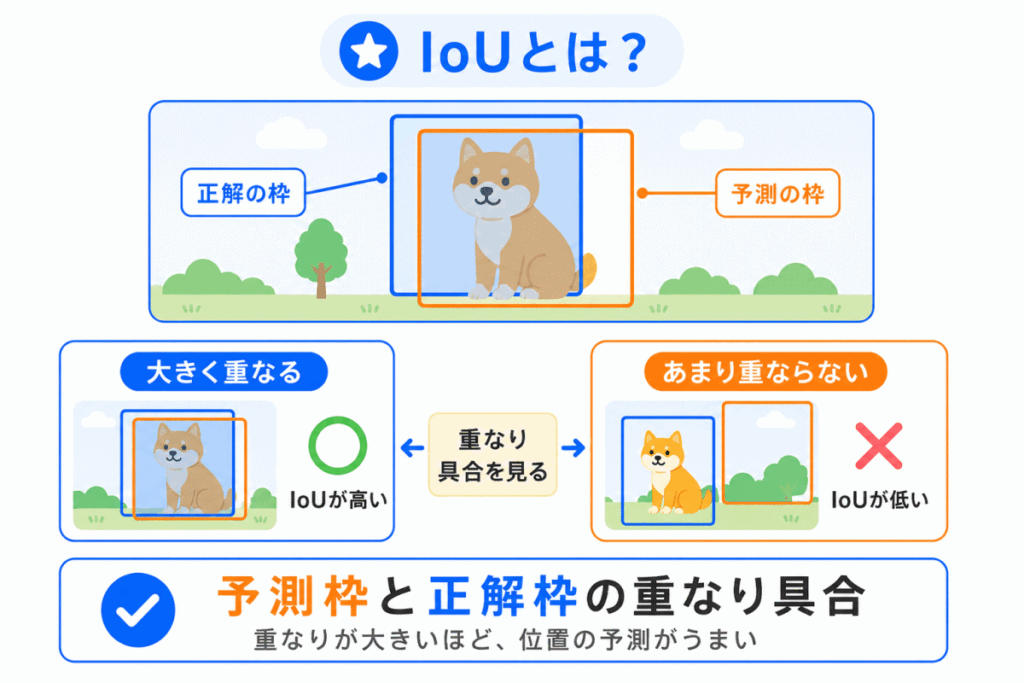
IoUは、物体検出で使われる評価の考え方です。
予測したバウンディングボックスと、正解のバウンディングボックスがどれくらい重なっているかを見ます。
重なりが大きければ、位置をうまく予測できていると考えられます。
| 状態 | 評価のイメージ |
|---|---|
| 枠が大きく重なる | よく検出できている |
| 枠が少ししか重ならない | 位置がずれている |
| 枠がほとんど重ならない | 検出がうまくいっていない |
G検定対策では、IoUを難しい数式で覚えるより、予測した枠と正解の枠の重なり具合 と押さえるとよいです。
G検定では、物体検出モデルの細かい実装よりも、用語の対応関係や違いを問われる可能性があります。
| 問われ方 | 選ぶ用語 |
|---|---|
| 物体の位置を四角い枠で示す | バウンディングボックス |
| 予測枠と正解枠の重なりを見る | IoU |
| 候補領域を使う物体検出モデル | R-CNN系 |
| R-CNNを高速化したモデル | Fast R-CNN |
| 候補領域の提案もネットワークで行う | Faster R-CNN |
| 画像を一度に見て高速に検出する | YOLO |
| 1回の処理で複数サイズの物体を検出する | SSD |
特に混同しやすいのは、R-CNN、Fast R-CNN、Faster R-CNNの違いです。
もうひとつ混同しやすいのは、YOLOとSSDです。
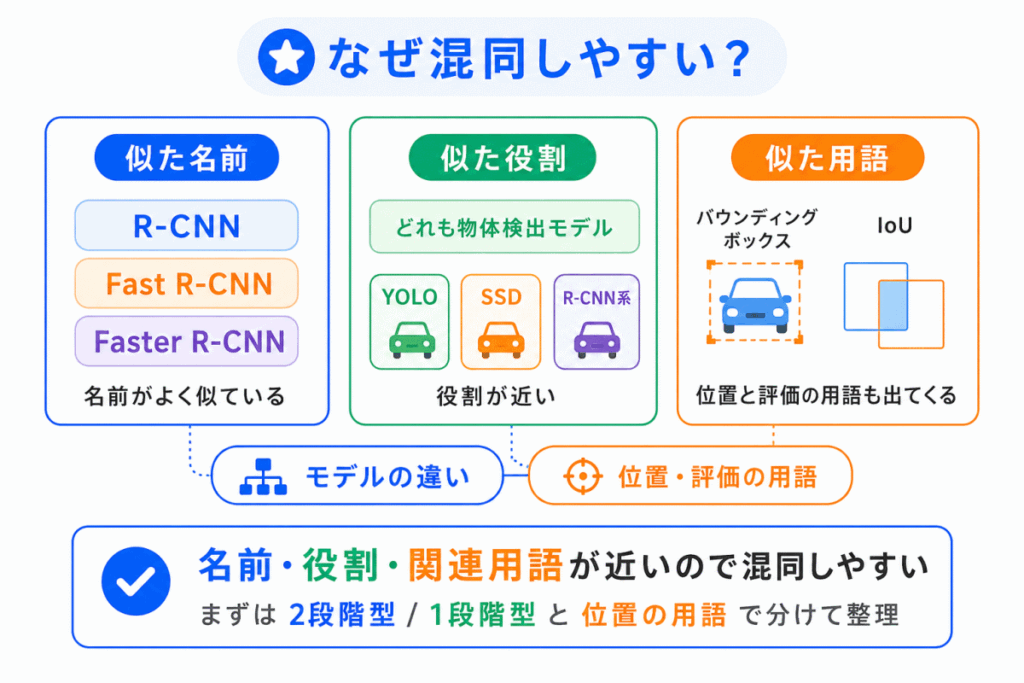
物体検出のモデルが混同しやすい理由は、名前が似ているうえに、どれも「画像の中から物体を見つけるモデル」だからです。
R-CNN、Fast R-CNN、Faster R-CNNは名前だけ見ると違いがわかりにくいです。
しかし、流れで見ると整理しやすくなります。
YOLOとSSDは、どちらも1段階型として整理できます。
つまり、まずは YOLO・SSDは1段階型、R-CNN系は2段階型 と分けるのがポイントです。
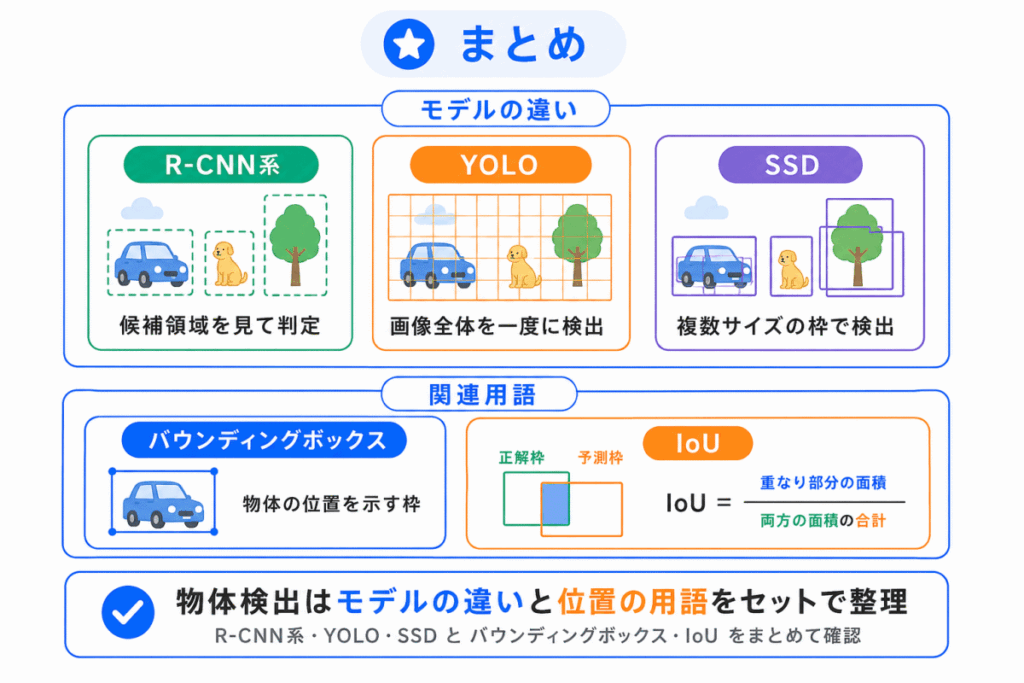
物体検出は、画像の中から物体の種類と位置を見つける技術です。
画像分類は「画像全体が何か」を判断しますが、物体検出は「どこに何があるか」まで判断します。
代表的なモデルは、R-CNN系、YOLO、SSD です。
物体検出をまとめると下の表になります。
| 用語 | 一言でいうと | 検出タイプ |
|---|---|---|
| R-CNN | 候補領域を取り出してCNNで判定するモデル | 2段階検出 |
| Fast R-CNN | R-CNNを高速化したモデル | 2段階検出 |
| Faster R-CNN | 候補領域の提案もネットワークで行うモデル | 2段階検出 |
| YOLO | 画像を一度に見て高速に検出するモデル | 1段階検出 |
| SSD | 複数サイズの枠で一度に検出するモデル | 1段階検出 |
物体検出で登場する用語まとめると下の表になります。
| 用語 | 一言でいうと |
|---|---|
| バウンディングボックス | 物体の位置を示す四角い枠 |
| IoU | 予測枠と正解枠の重なり具合 |
まずは、次のように整理しておくと混同しにくくなります。
物体検出の基本を先に確認したい方は、こちらの記事も参考になります。
物体検出そのものの意味を先に確認したい方は、こちらの記事も参考になります。
物体検出とセグメンテーションの違いを整理したい方は、こちらの記事もあわせて確認すると理解しやすくなります。
画像認識モデルの流れを確認したい方は、こちらの記事も参考になります。
画像認識がディープラーニングの応用例の中でどこに位置づくかを確認したい方は、こちらの記事も参考になります。
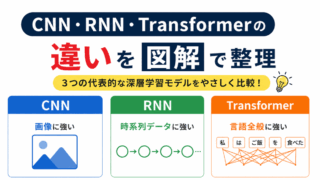
CNNとの関係を整理したい方は、こちらの記事もあわせて読むと理解しやすくなります。
用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認