【G検定|理解型予想問題】AI学習の流れ
seo-webmaster
G検定対策ブログ
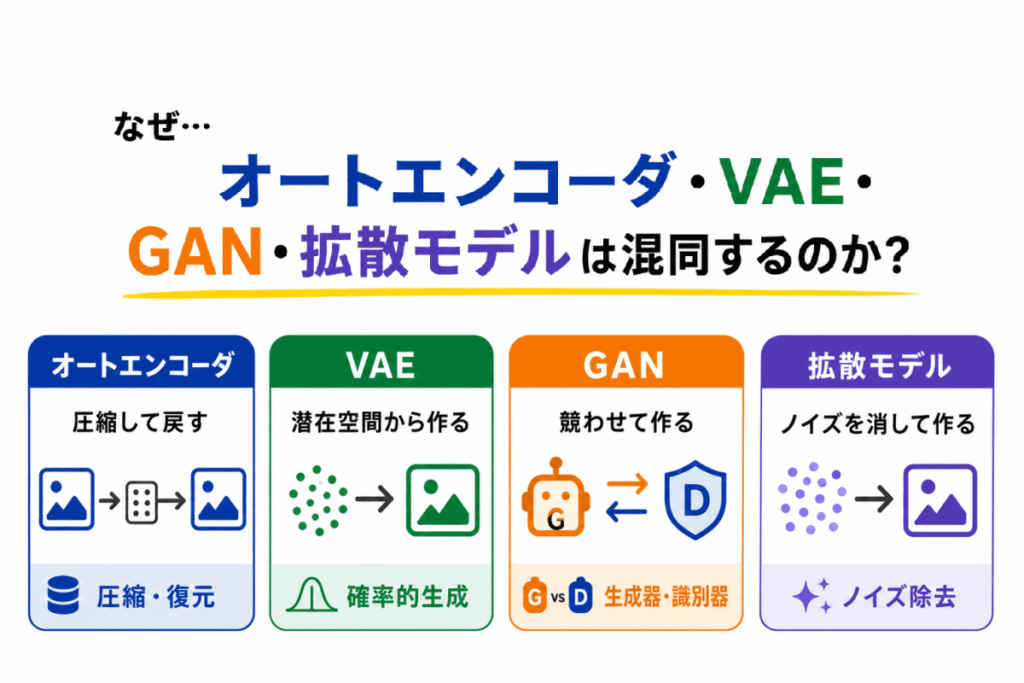
生成モデルは、G検定で「どのモデルが、どのようにデータを生成するのか」を問われやすい分野です。
特に「オートエンコーダ」、「VAE」、「GAN」、「拡散モデル」は、どれも生成AIや画像生成AIと関係するため、名前だけで覚えると混同しやすくなります。
この記事では、生成モデル系の用語を、暗記ではなく「圧縮するのか」、「潜在空間から作るのか」、「競わせるのか」、「ノイズを消すのか」という見分け方で整理します。
生成モデル系の用語は、まず「何を使ってデータを作るのか」で整理すると理解しやすくなります。
| 用語 | 一言でいうと |
|---|---|
| 生成モデル | 新しいデータを作るモデル |
| オートエンコーダ | 入力を圧縮して復元するモデル |
| VAE | 潜在空間からデータを作る生成モデル |
| GAN | 生成器と識別器を競わせて作る生成モデル |
| 拡散モデル | ノイズを取り除きながら作る生成モデル |
| DDPM | ノイズ除去を使う代表的な拡散モデル |
| 画像生成AI | 条件に合う画像を生成するAI |
生成モデル系の用語は、どれも「新しいデータを作る」という方向につながります。
そのため、G検定では次のような混同が起きやすくなります。
| 混同しやすい用語 | 混同する理由 | 見分け方 |
|---|---|---|
| オートエンコーダとVAE | どちらも入力を圧縮する考え方と関係する | VAEは潜在空間を確率的に扱う |
| VAEとGAN | どちらも生成モデルとして扱われる | VAEは潜在空間、GANは競争で整理する |
| GANと拡散モデル | どちらも画像生成AIと関係が深い | GANは競わせる、拡散モデルはノイズを消す |
| 拡散モデルとDDPM | どちらもノイズ除去と関係する | DDPMは代表的な拡散モデルとして押さえる |
| 生成モデルと画像生成AI | どちらもデータ生成と関係する | 生成モデルは仕組み、画像生成AIは応用例として整理する |
次のうち、生成モデルの説明として最も適切なものはどれか?
B
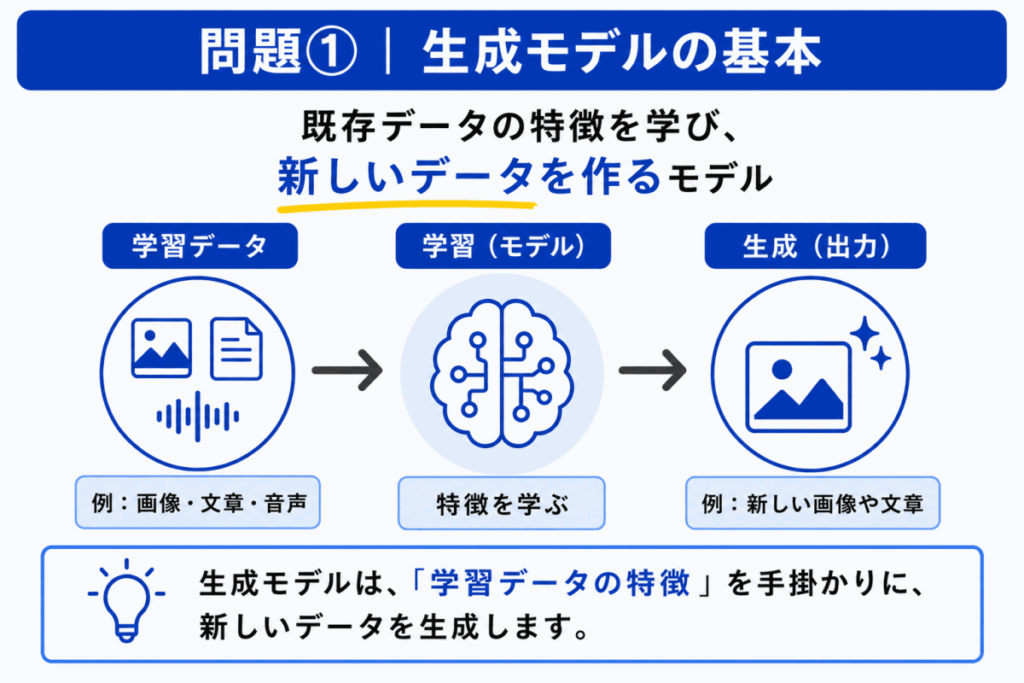
生成モデルは、学習したデータの特徴をもとに、新しいデータを生成するモデルです。
たとえば、画像、文章、音声などを生成するAIの背景には、生成モデルの考え方があります。
Aは分類モデルの説明に近く、Cはアノテーションなどの人手作業に近い説明です。Dは画像圧縮の説明に近く、生成モデルそのものの説明ではありません。
次のうち、オートエンコーダの説明として最も適切なものはどれか?
A
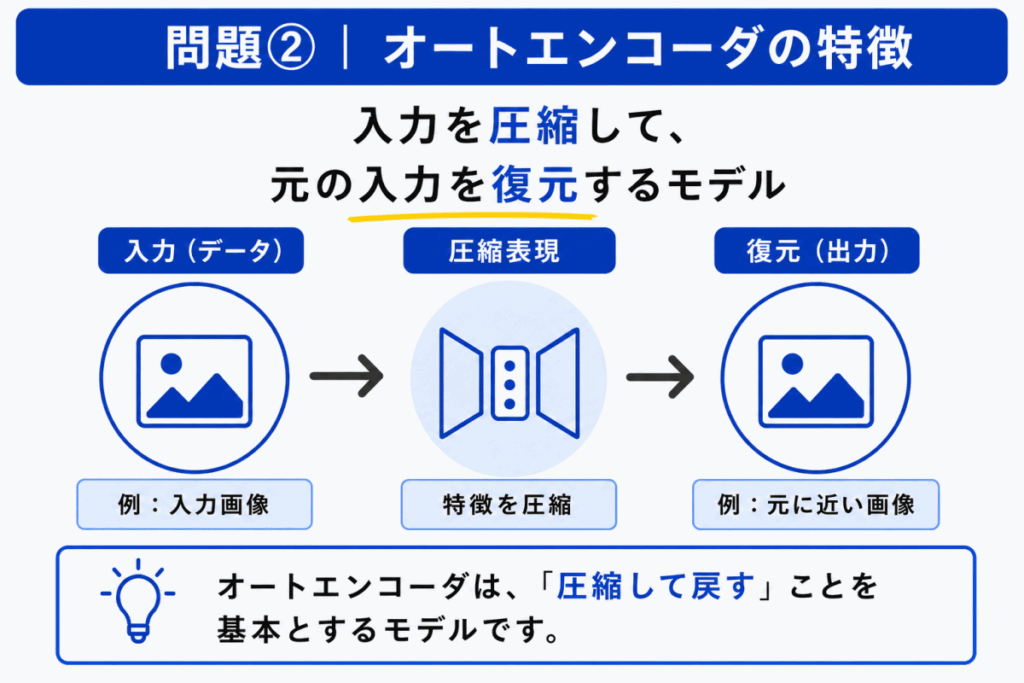
オートエンコーダは、入力データをいったん低次元の表現に圧縮し、そこから元の入力に近い形へ復元するニューラルネットワークです。
ポイントは、圧縮して戻すことです。
Bは GAN、Cは拡散モデル、Dは強化学習の説明です。
次のうち、VAE の説明として最も適切なものはどれか?
A
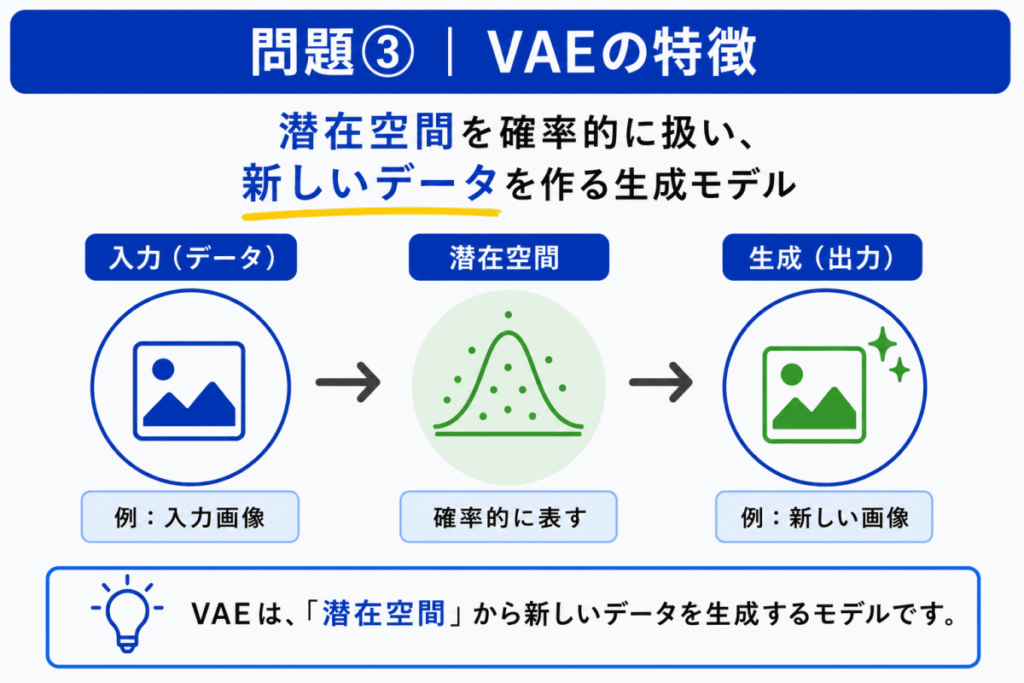
VAE は、オートエンコーダの考え方と関係する生成モデルです。
通常のオートエンコーダが「圧縮して復元する」ことを重視するのに対し、VAE は潜在空間を確率的に扱い、そこから新しいデータを生成する方向につながります。
Bは分類モデル、Cは強化学習、Dはセグメンテーションの説明です。
次のうち、GANの説明として最も適切なものはどれか?
A
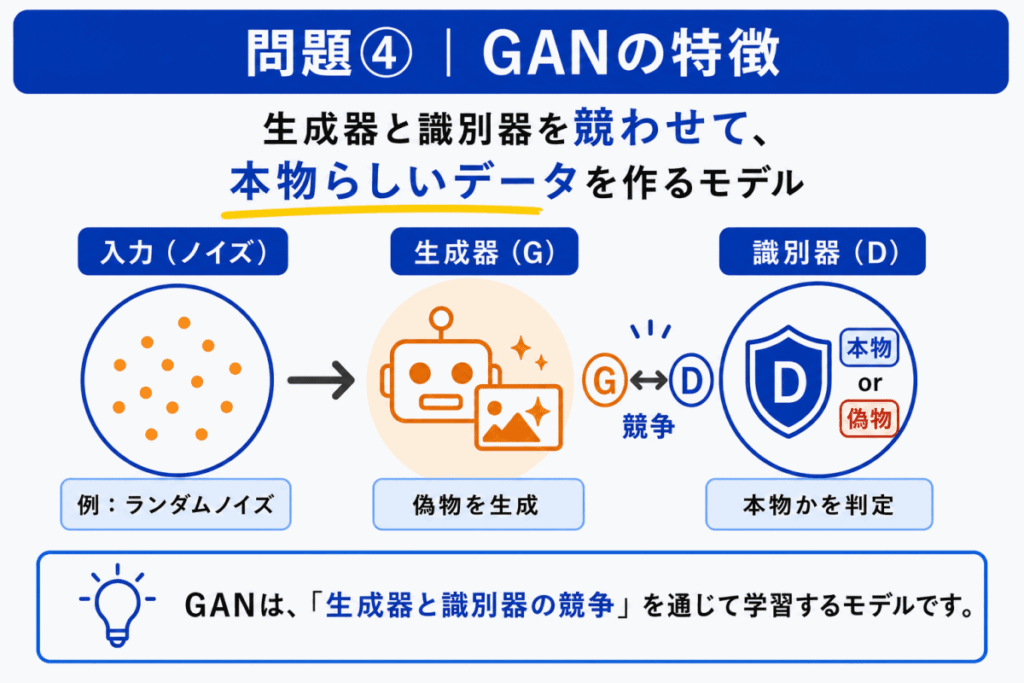
GAN は、生成器と識別器を競わせながら、本物らしいデータを生成するモデルです。
生成器は本物らしいデータを作ろうとし、識別器は本物と偽物を見分けようとします。この競争によって、生成器がより自然なデータを作れるようになります。
Bはオートエンコーダ、Dは標準化に近い説明です。Cは拡散モデルと混同しやすいですが、GAN の説明ではありません。
次のうち、拡散モデルの説明として最も適切なものはどれか?
A
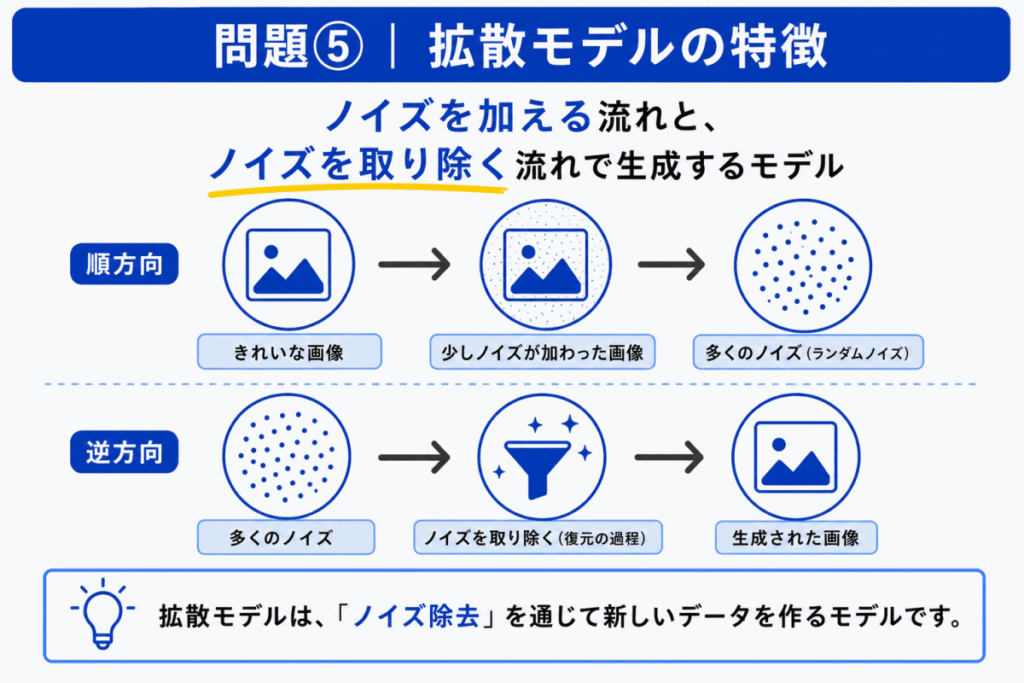
拡散モデルは、元のデータに少しずつノイズを加える流れと、その逆向きにノイズを取り除く流れを使って、新しいデータを生成するモデルです。
見分けるキーワードは、ノイズを加える、ノイズを取り除く、逆拡散です。
Bは GAN、Cはオートエンコーダ、Dは教師あり学習の分類問題に近い説明です。
次のうち、DDPM の説明として最も適切なものはどれか?
A
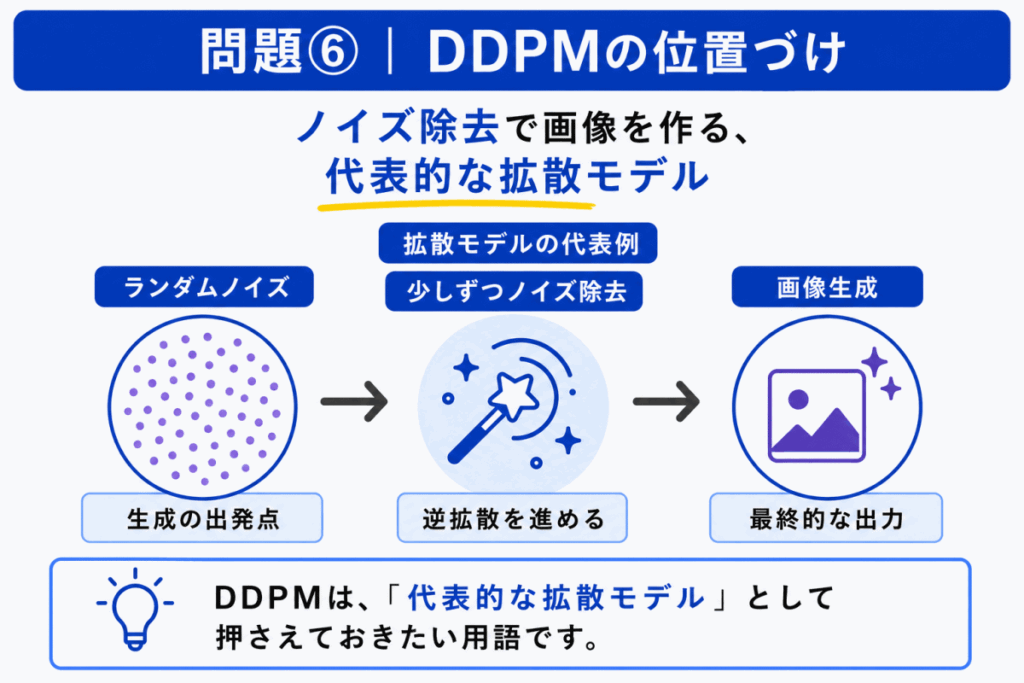
DDPM は、拡散モデルの代表例として押さえておきたいモデルです。
G検定対策では、DDPM を細かい数式で覚えるよりも、ノイズを加える過程と、ノイズを取り除く過程を使う生成モデルとして整理する方が重要です。
Bはランダムフォレスト、Cは単語埋め込み、Dは強化学習系の説明に近いです。
次のうち、GAN と拡散モデルの違いとして最も適切なものはどれか?
A
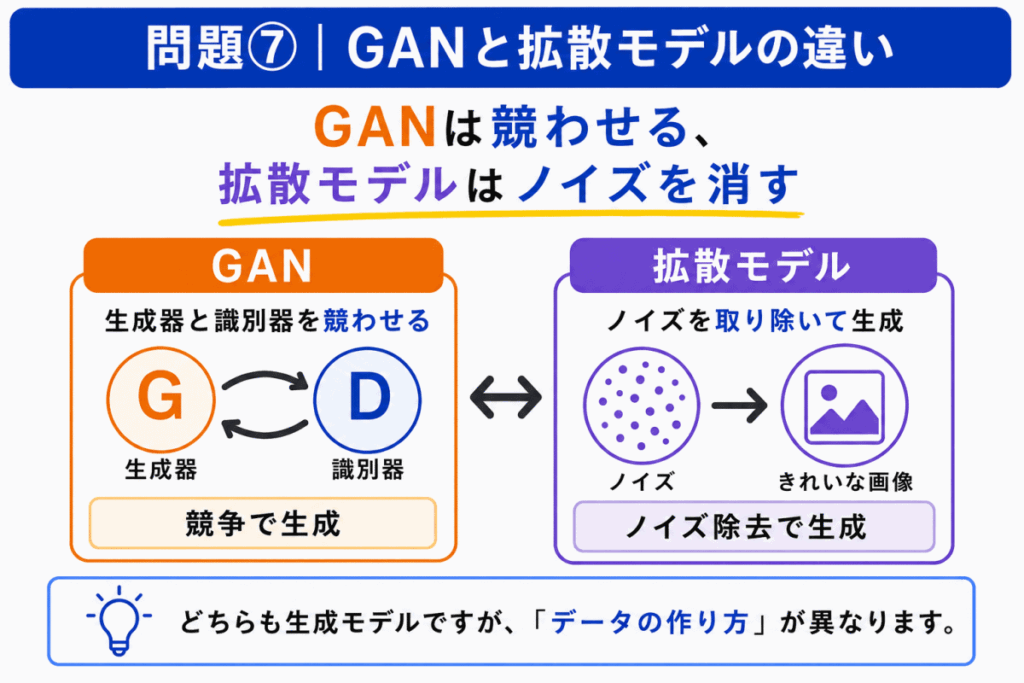
GAN は、生成器と識別器を競わせてデータを生成します。
一方、拡散モデルは、ノイズを加える過程と、ノイズを取り除く過程を使ってデータを生成します。
G検定で迷った場合は、次のように見分けます。
次のうち、オートエンコーダとVAEの違いとして最も適切なものはどれか?
A
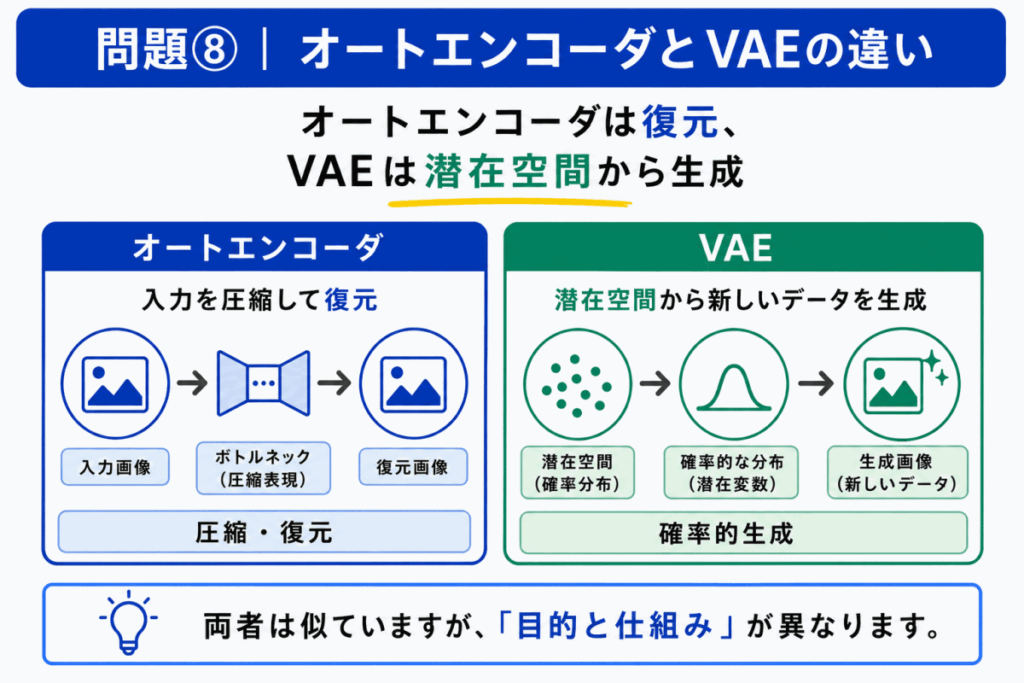
オートエンコーダは、入力を圧縮して復元するモデルです。
VAE は、その考え方をもとにしながら、潜在空間を確率的に扱い、新しいデータを生成する方向に発展したモデルとして整理できます。
Dは GAN の説明に近いです。
次のうち、生成モデルと画像生成AIの関係として最も適切なものはどれか?
A
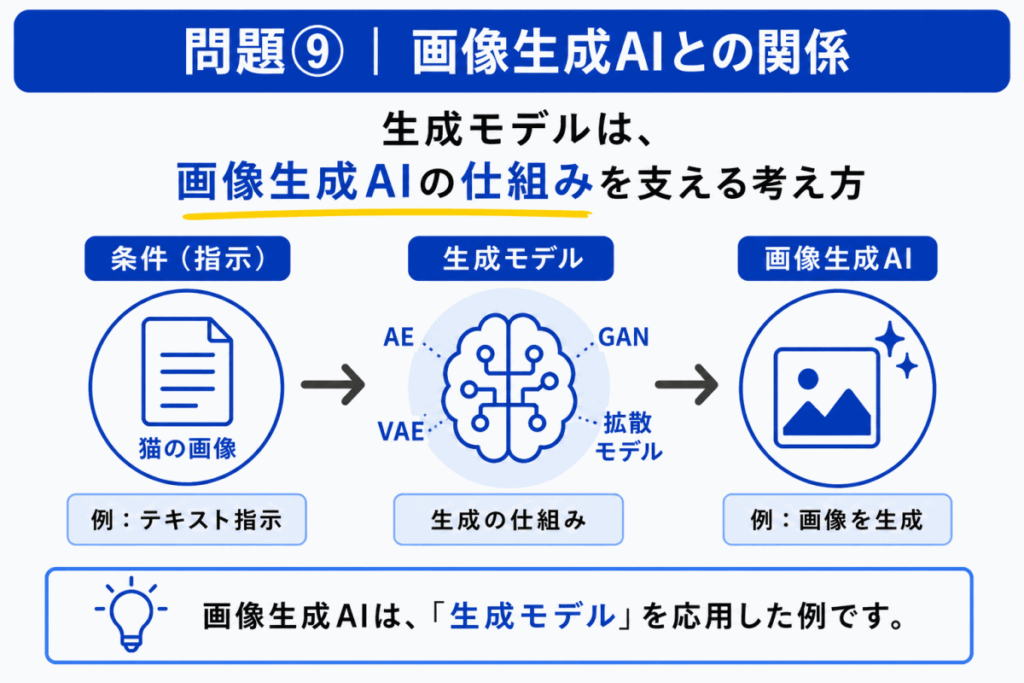
画像生成AIを理解するうえで、生成モデルの考え方は重要です。
GAN、VAE、拡散モデルなどは、データを生成する仕組みとして整理されます。特に拡散モデルは、画像生成AIとの関係で押さえておきたい用語です。
B、C、Dはいずれも不適切です。
次のうち、用語と説明の組み合わせとして最も適切なものはどれか?
B
GAN は、生成器と識別器を競わせながらデータを生成するモデルです。
Aは拡散モデルの説明に近いです。Cは強化学習の説明に近く、Dはランダムフォレストの説明に近いです。
この問題では、用語のキーワードを対応させることが重要です。
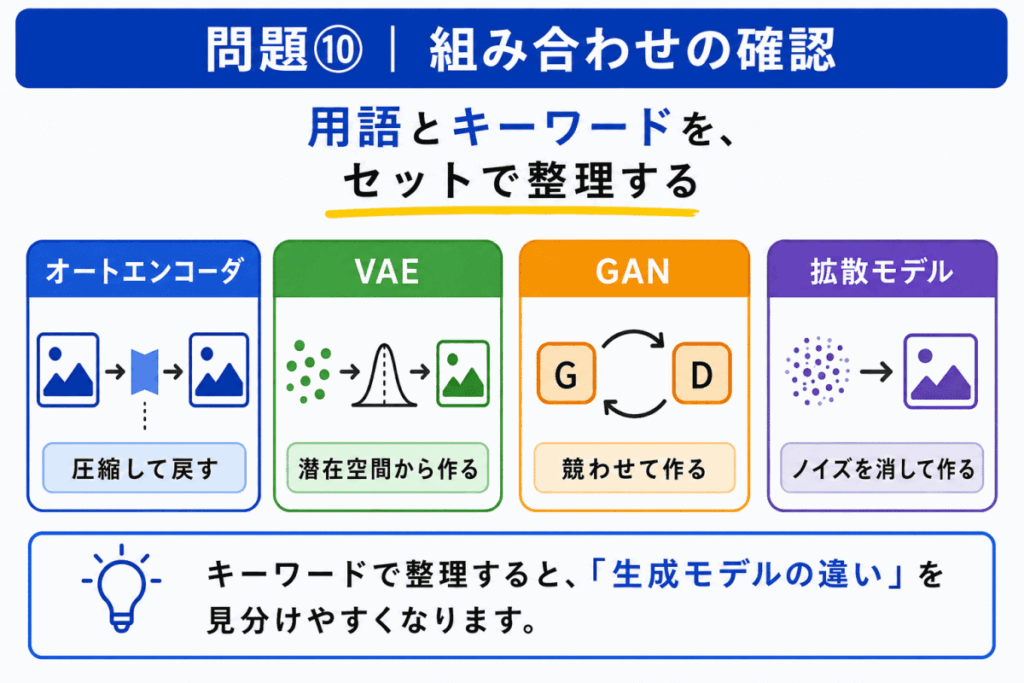
生成モデル系の問題で迷ったときは、次のキーワードで整理します。
| 用語 | 見分けるキーワード |
|---|---|
| オートエンコーダ | 圧縮して戻す |
| VAE | 潜在空間から作る |
| GAN | 生成器と識別器を競わせる |
| 拡散モデル | ノイズを取り除きながら作る |
| DDPM | 代表的な拡散モデル |
| 画像生成AI | 生成モデルの応用例 |
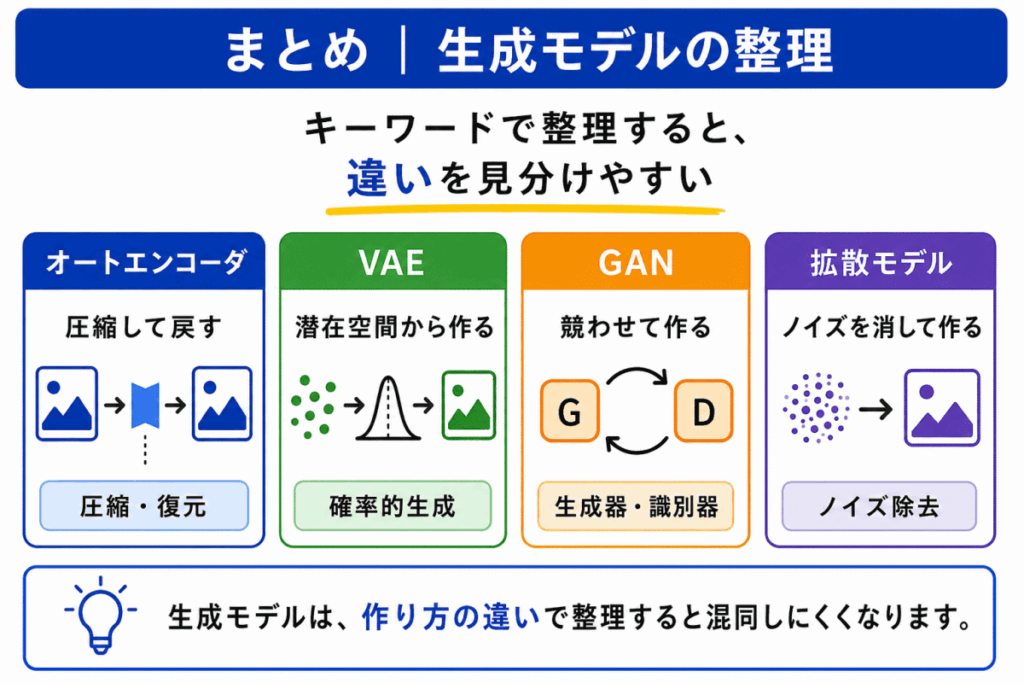
生成モデル系の用語は、すべてを「データを作る仕組み」としてまとめてしまうと混同しやすくなります。
G検定対策では、次のように整理しておくと見分けやすくなります。
生成モデルは、画像生成AIや生成AIの仕組みを理解するうえでも重要です。暗記だけで覚えるのではなく、「圧縮」、「潜在空間」、「競争」、「ノイズ除去」というキーワードで整理しておくと、選択肢で迷いにくくなります。
生成モデル系の用語は、個別記事とまとめ記事を行き来しながら確認すると理解しやすくなります。
| リンク先 | 確認できる内容 |
|---|---|
| 生成モデルまとめ | GAN/VAE/拡散モデル/生成AIの関係 |
| オートエンコーダとは? | 圧縮/復元/潜在表現 |
| VAEとは? | 潜在空間/確率的な生成/オートエンコーダとの関係 |
| GANとは? | 生成器/識別器/競争による生成 |
| 拡散モデルとは? | ノイズを加える過程/逆拡散/DDPM |
| 生成AIの仕組み | 事前学習/ファインチューニング/RLHF/RAG |
| マルチモーダルAIとは? | 画像/文章/音声/複数モダリティ |