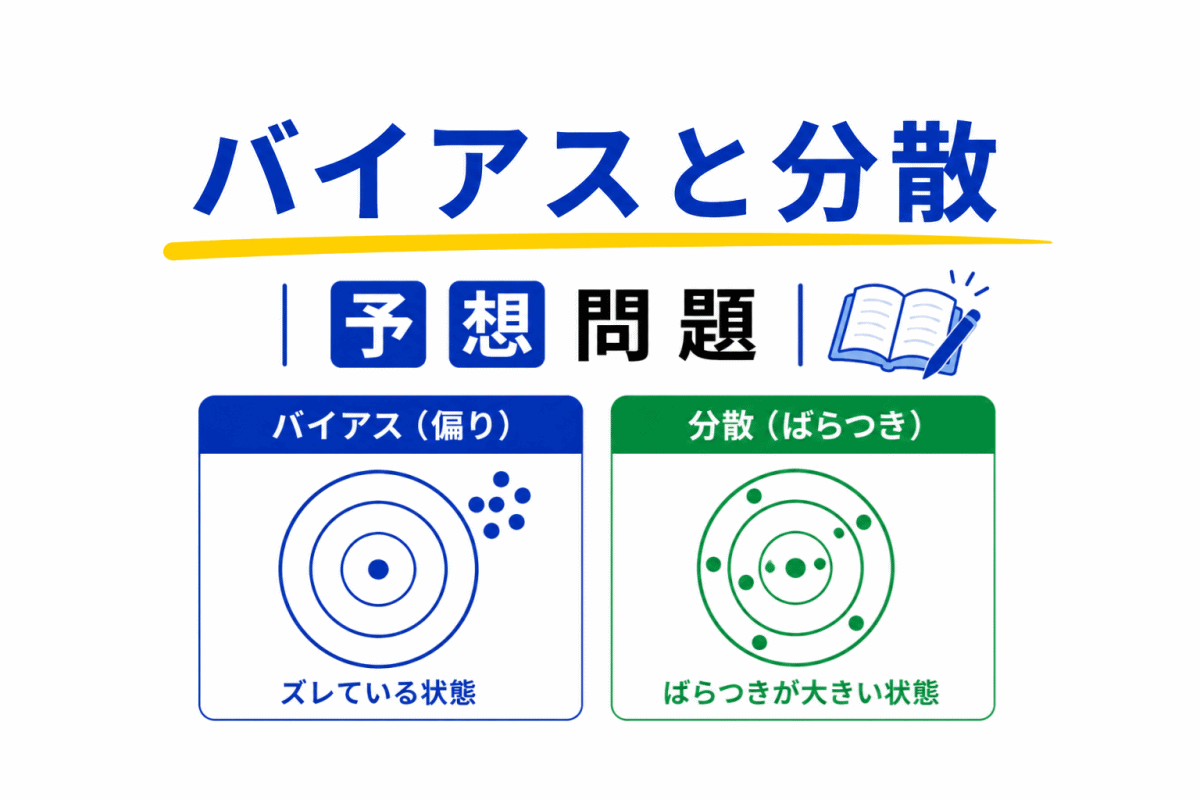
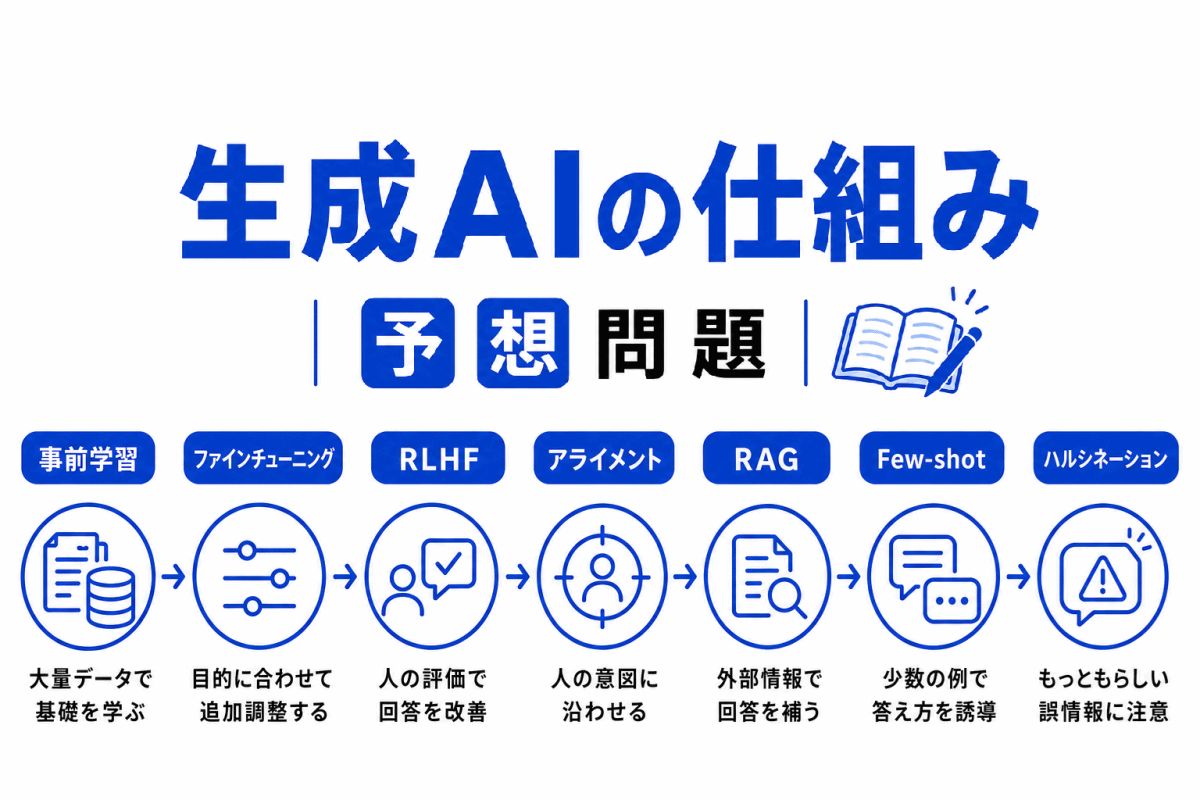
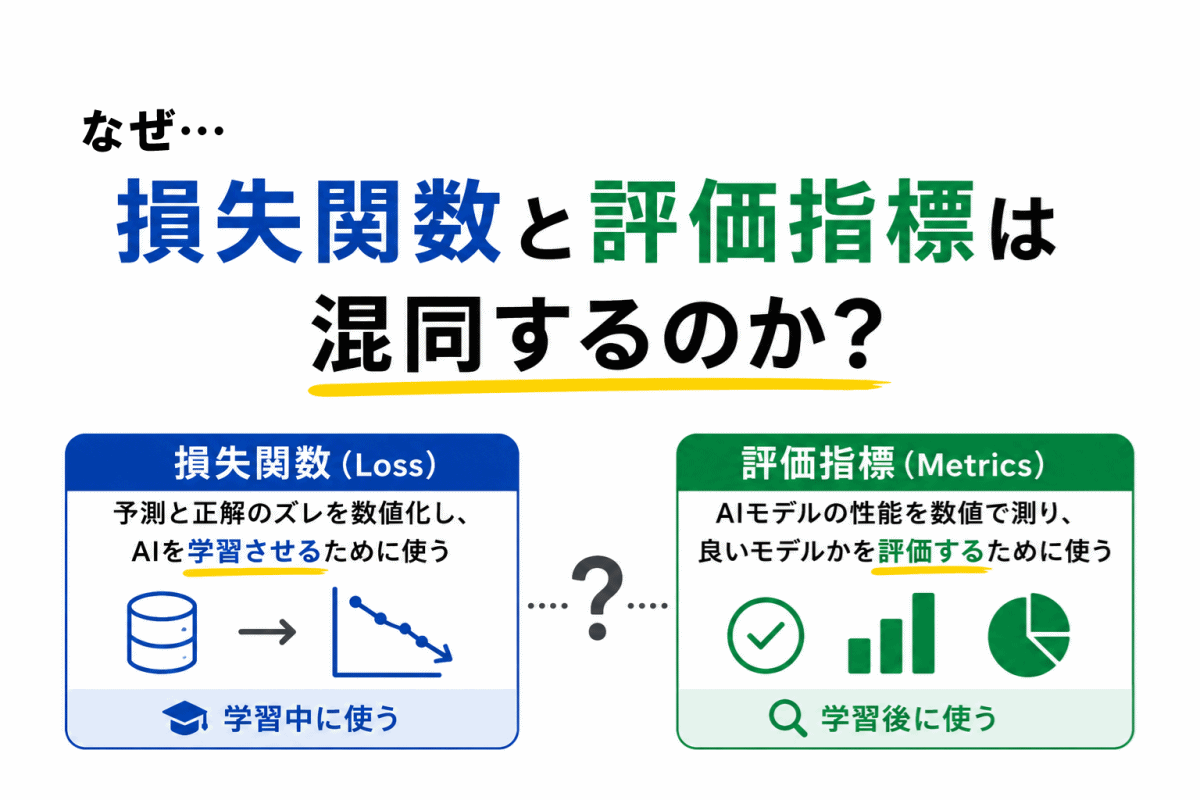
【G検定|理解型予想問題】過学習・正則化・ドロップアウト
seo-webmaster
G検定対策ブログ
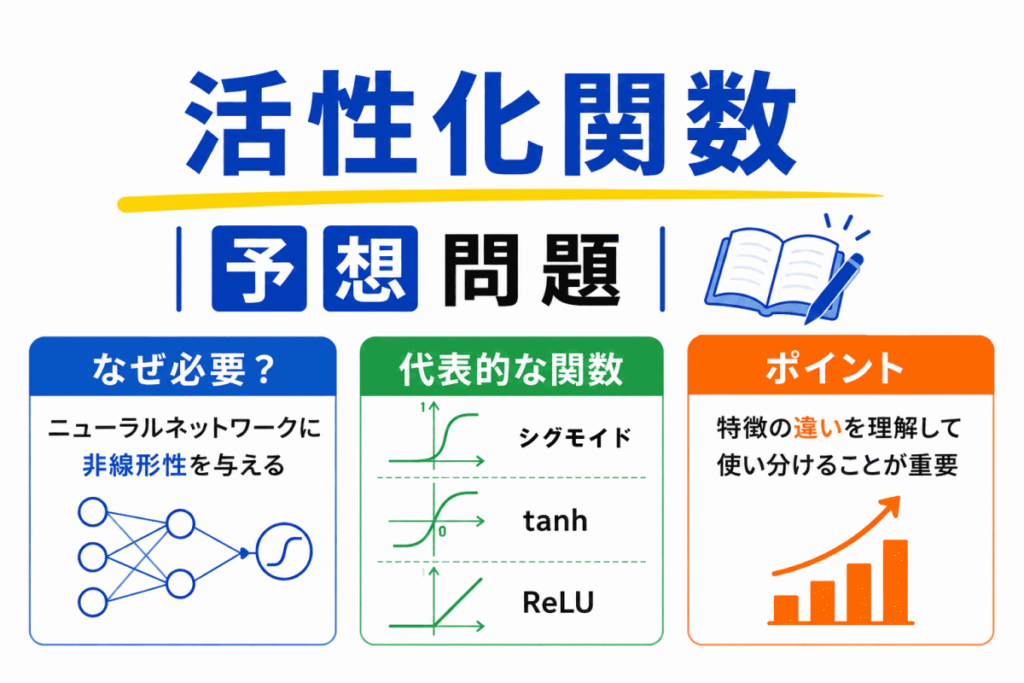
活性化関数 は重要テーマです。
ただし
を丸暗記しているだけでは、少し聞き方が変わると混乱しやすくなります。
この記事では、単なる暗記ではなく
まで含めて、理解型で整理していきます。
活性化関数の役割として最も適切なものはどれか?
B
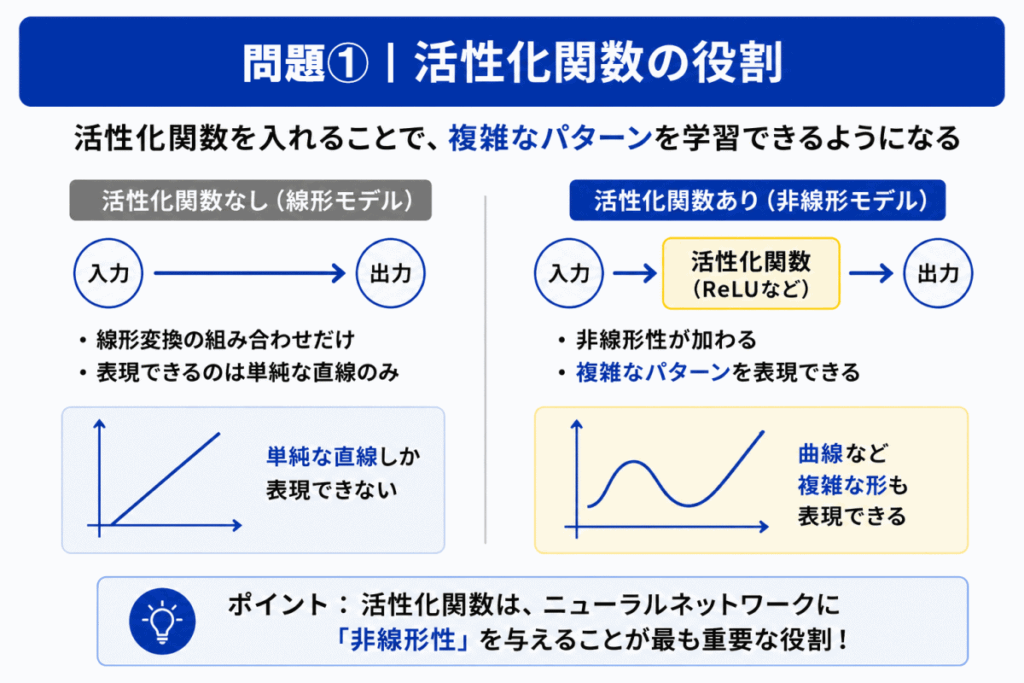
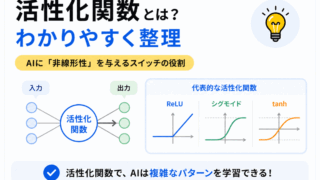
活性化関数の最も重要な役割は「非線形性」を与えること です。
ニューラルネットワークは、活性化関数を入れないと「ただの線形変換」の組み合わせになってしまいます。
すると複雑なパターンを学習できません。
そのため
などを使い、複雑な表現を可能にしています。
ここはG検定でかなり重要です。
初心者は「活性化関数 = 出力を変えるもの」とだけ覚えがちです。
しかし本質は「線形だけでは複雑な問題を解けない」にあります。
活性化関数を使わなかった場合に起きやすいこととして最も適切なものはどれか?
B
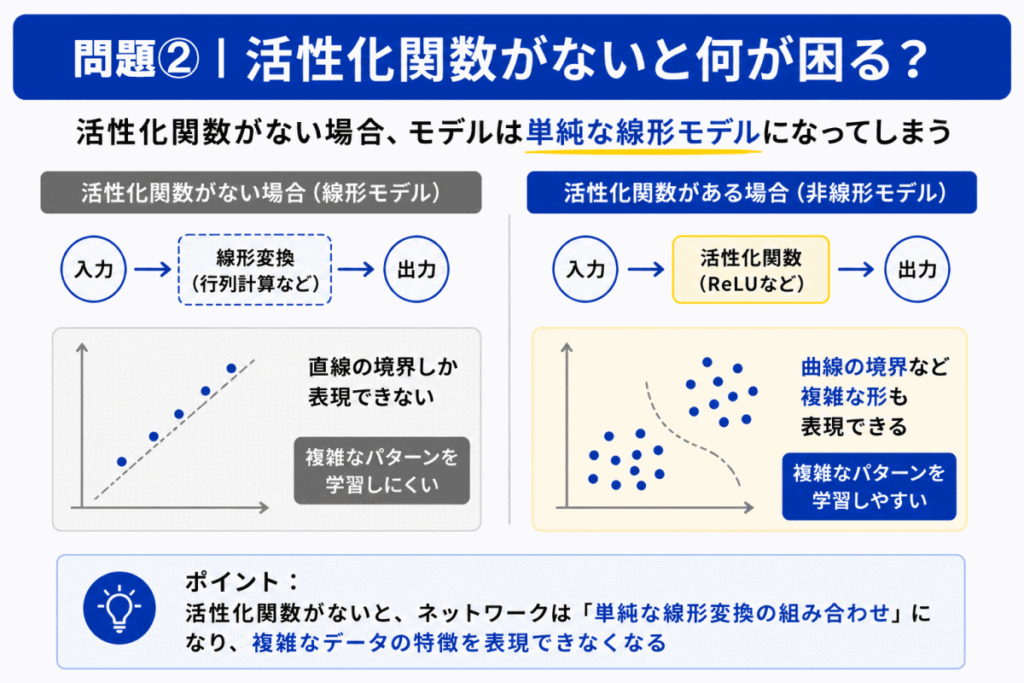
活性化関数を使わない場合、ニューラルネットワークは実質的に「単純な線形モデル」に近くなります。
すると
などへの対応が難しくなります。
つまり「複雑な特徴を学習できなくなる」ことが大きな問題です。
G検定では「活性化関数がないと何が困るのか」を問われることがあります。
単なる用語暗記ではなく「非線形性が失われる」まで理解しておくことが重要です。
ReLUの特徴として最も適切なものはどれか?
C
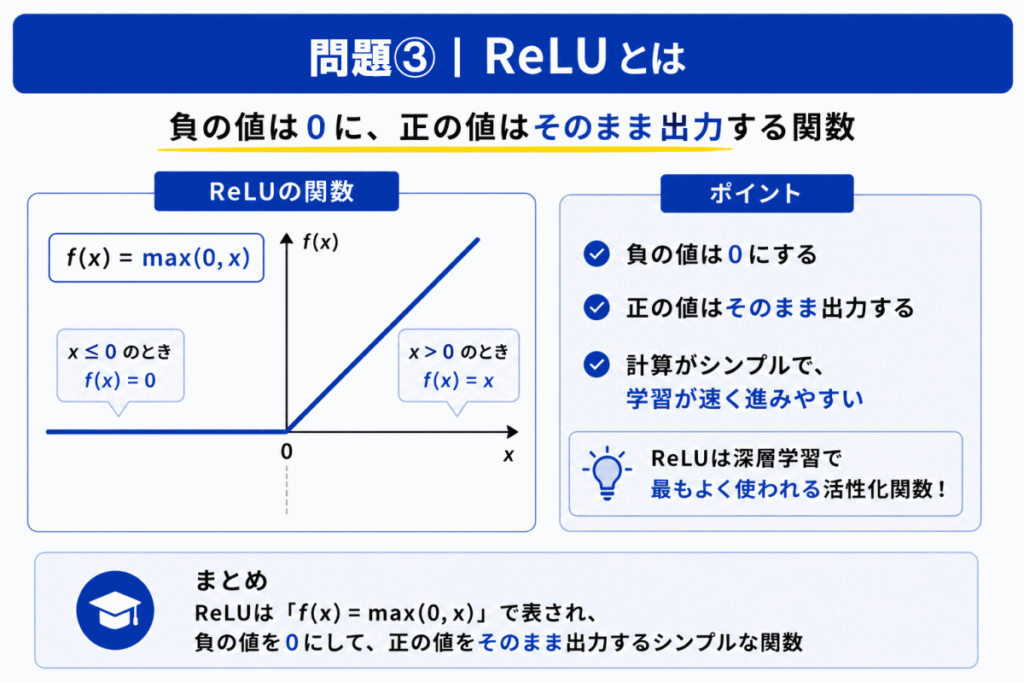
ReLU(Rectified Linear Unit)は
というシンプルな構造を持っています。
このシンプルさにより
というメリットがあります。
ここは
の違いを比較されやすいポイントです。
特に「0〜1に収まる」のはシグモイド。ReLUではありません。
シグモイド関数の特徴として最も適切なものはどれか?
A
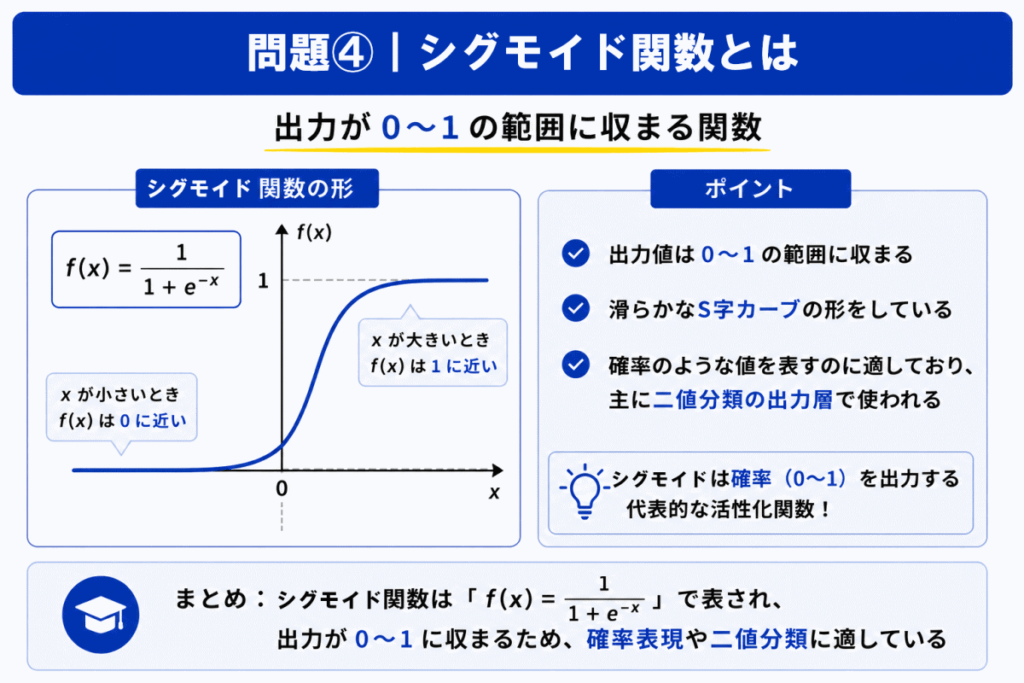
シグモイド関数は 出力が0〜1に収まる 特徴があります。
そのため
などで利用されます。
昔はシグモイドがよく使われていました。
しかし、現在は ReLUの方が主流 です。
理由は「勾配消失問題」が起きやすいためです。
勾配消失問題とは、AIが学習を重ねる途中で「どこを直せばいいか」の情報が弱くなり、学習が進みにくくなる問題です。
ReLUが現在広く使われている理由として最も適切なものはどれか?
C
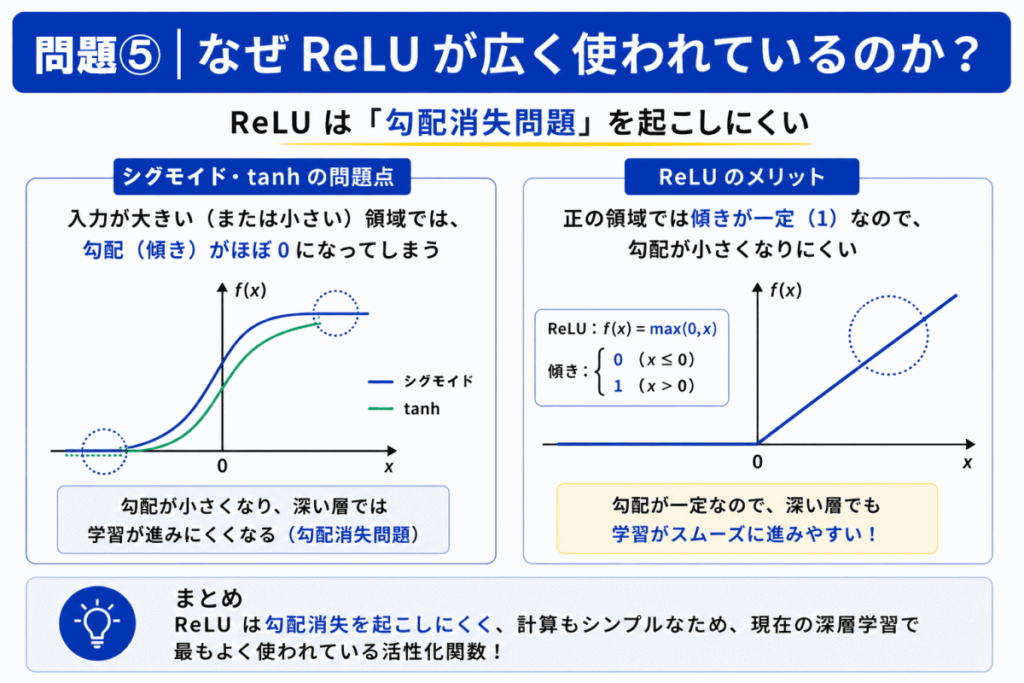
シグモイドやtanhでは
ことで「勾配消失問題」が発生しやすくなります。
勾配消失問題とは、AIが学習を重ねる途中で「どこを直せばいいか」の情報が弱くなり、学習が進みにくくなる問題です。
一方ReLUは 正の領域で勾配が一定 のため、勾配消失が起きにくい特徴があります。
その結果 深層学習で広く利用 されるようになりました。
G検定では「なぜReLUが普及したのか」はかなり重要です。
単なる「ReLUがよく使われる」ではなく「勾配消失を起こしにくい」までセットで理解しましょう。
画像認識などの深層学習で、現在最も広く使われている活性化関数として適切なものはどれか?
A
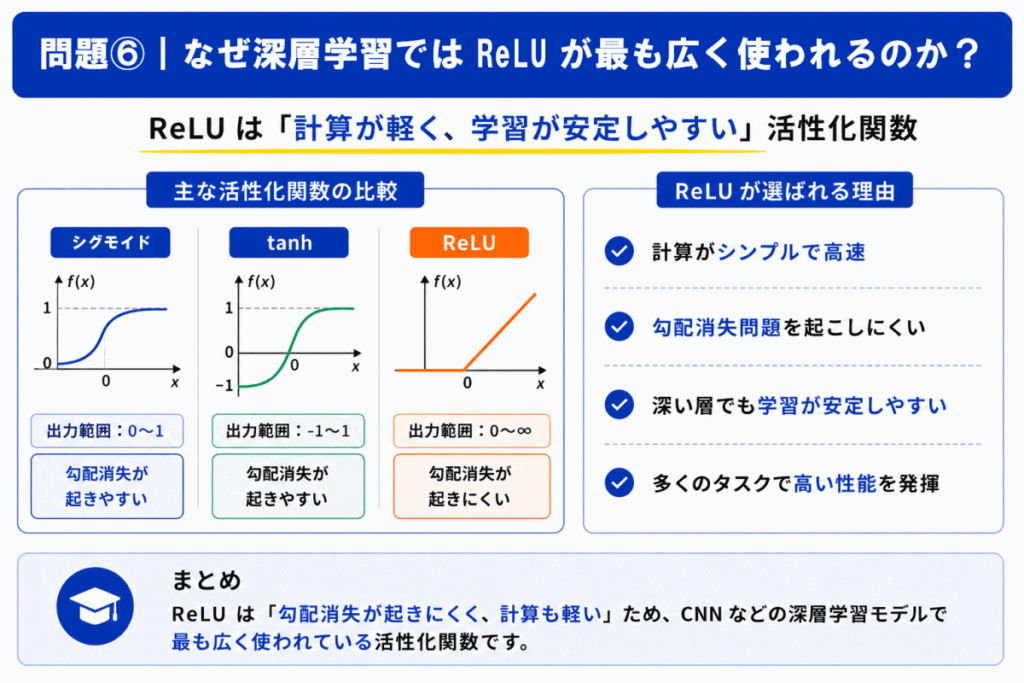
現在の深層学習(ディープラーニング)では ReLU系 の活性化関数が広く利用されています。
理由は
ためです。
特にCNNなどでは頻繁に利用されます。
ソフトマックスは活性化関数として扱われることもありますが、主に出力層 で使われます。
一方ReLUは、中間層で広く利用 されるのが特徴です。
次のうち、「活性化関数を利用する目的」として最も適切なものはどれか?
B
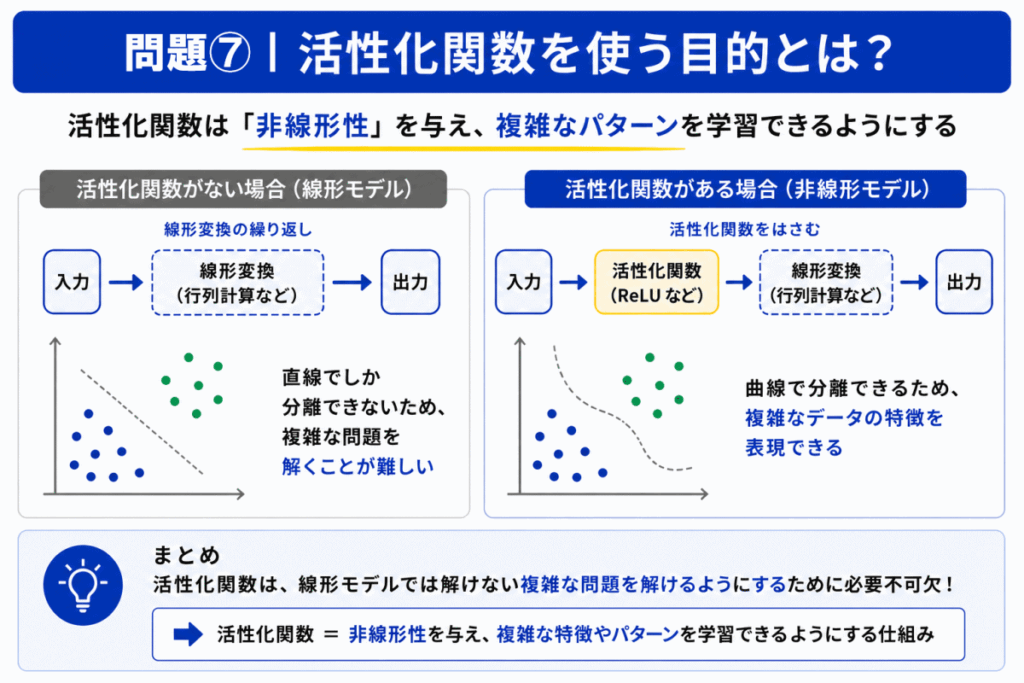
活性化関数の本質は「非線形な表現を可能にすること」です。
これによりニューラルネットワークは
などの複雑な特徴を学習できるようになります。
もし活性化関数がなければ「深いネットワークでも単純な線形変換」に近くなってしまいます。
ここは「なぜ必要なのか」を理解しているかが重要です。
G検定では
だけでは対応しにくい問題も出ます。
そのため「活性化関数がないと何が困るのか」まで整理して理解することが問い方変更への対応力につながります。
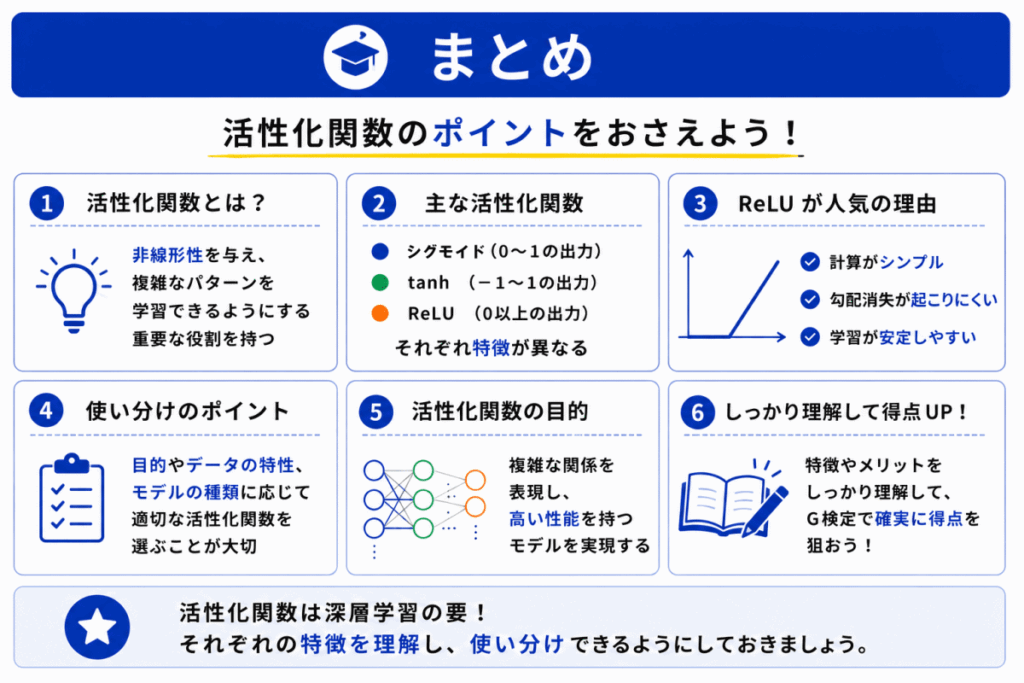
活性化関数は「非線形性を与える」ための重要な仕組みです。
特に
の違いはG検定重要ポイントです。
ただし「ReLUが主流」だけを暗記していると
で混乱しやすくなります。
重要なのは「なぜその関数が必要なのか?」を理解することです。
理解ベースで整理すると、問い方が変わっても対応しやすくなります。
この予想問題よりも活性化関数を詳しく整理しています。
もっと詳しく学習したい方はご覧ください。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。