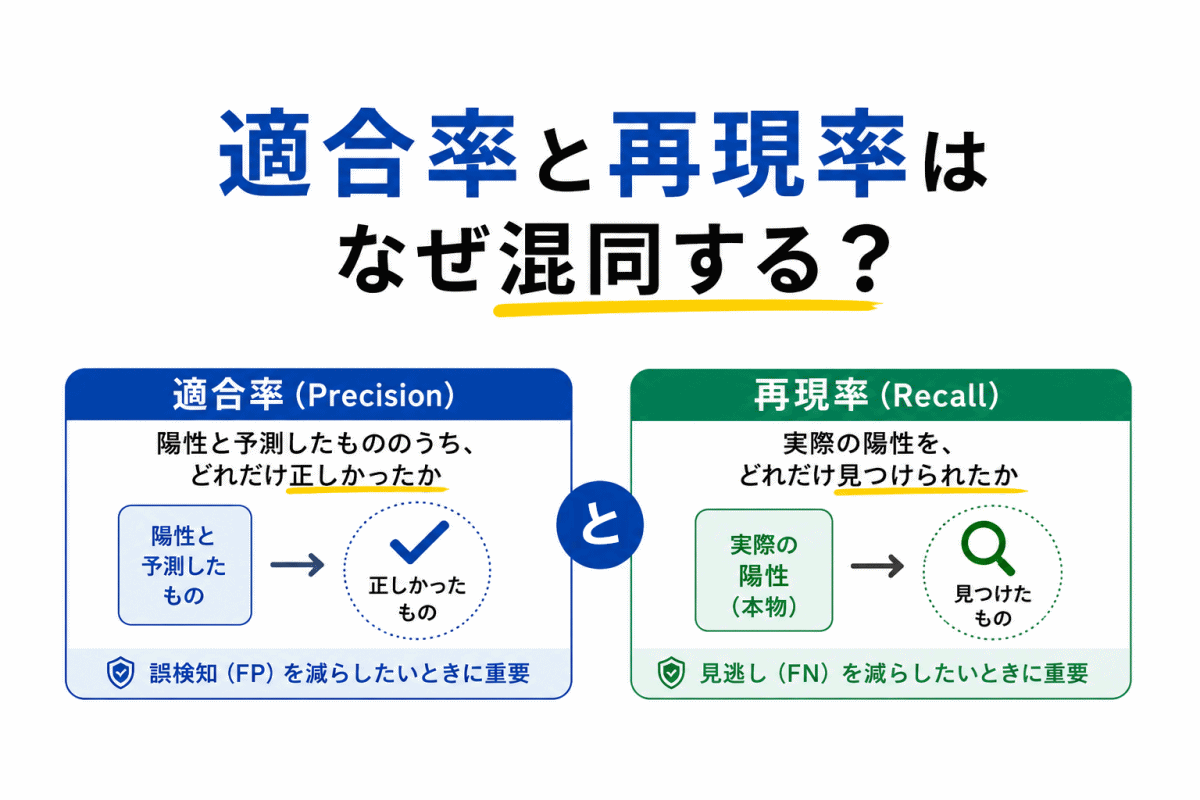
【G検定|理解型予想問題】適合率と再現率はなぜ混同する?
seo-webmaster
G検定対策ブログ
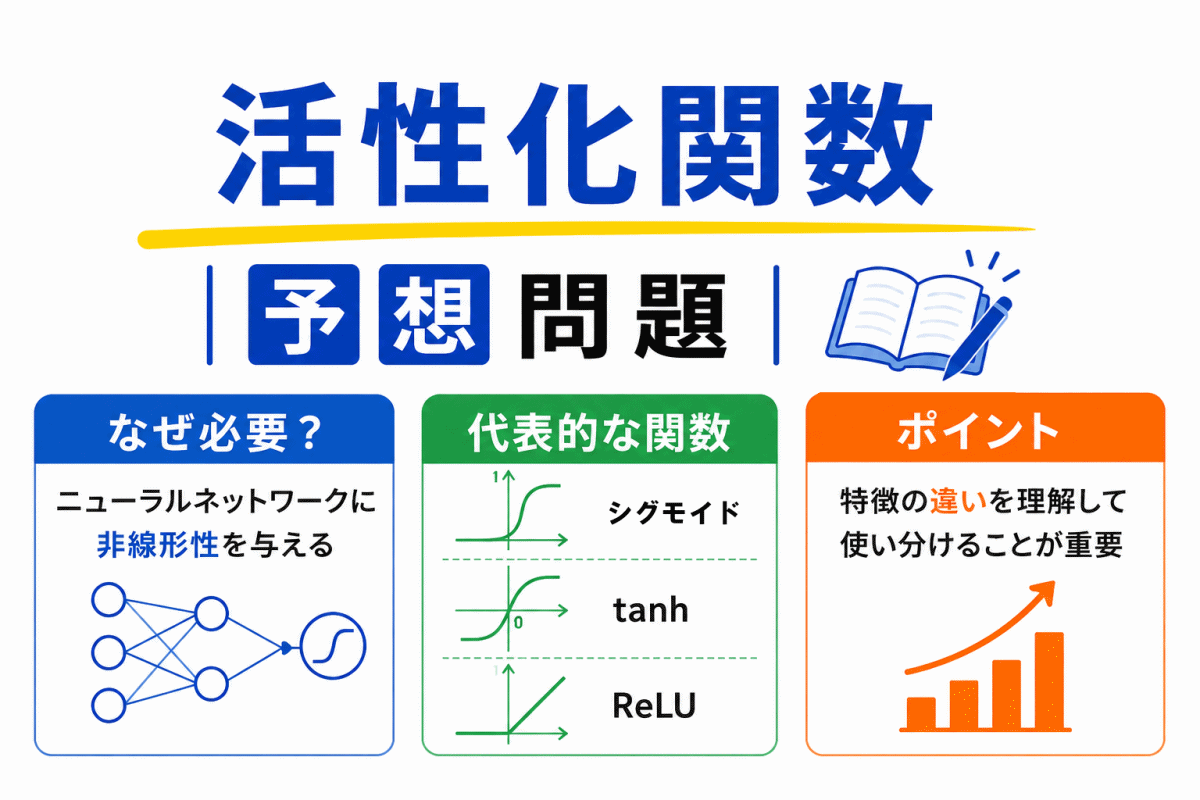
AI関連の用語は、1つずつ覚えようとすると混乱しやすくなります。
しかし、本来は
などは、すべて「AIが間違いを修正し続ける流れ」の中に存在しています。
この記事では、AI学習の流れを“線”で理解できるように、理解型の予想問題を通して整理していきます。
損失関数の役割として最も適切なものはどれか?
B
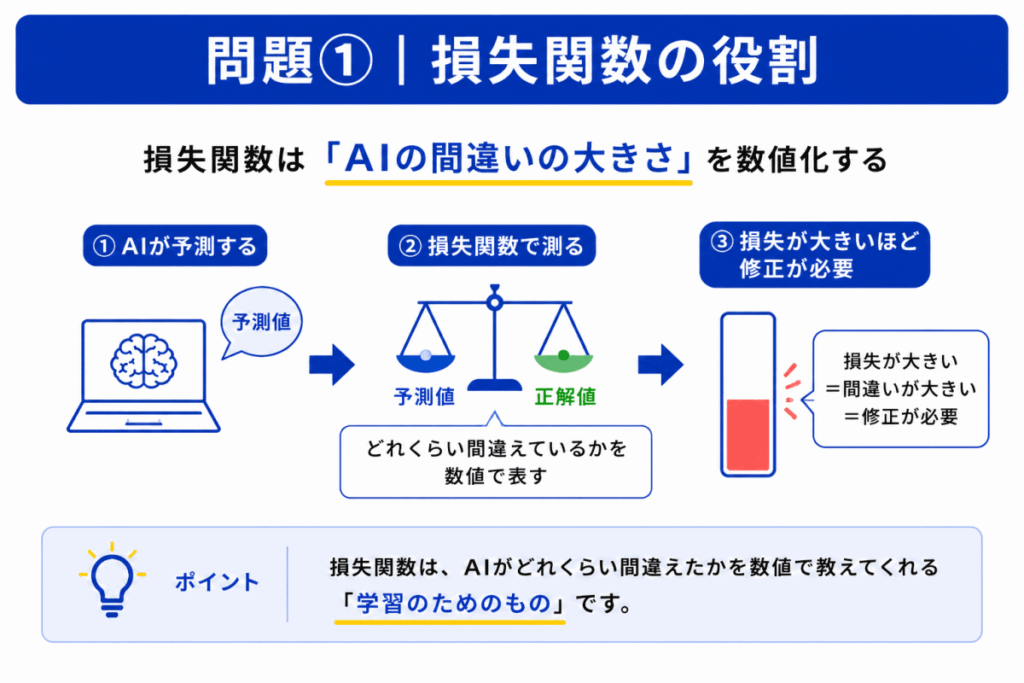
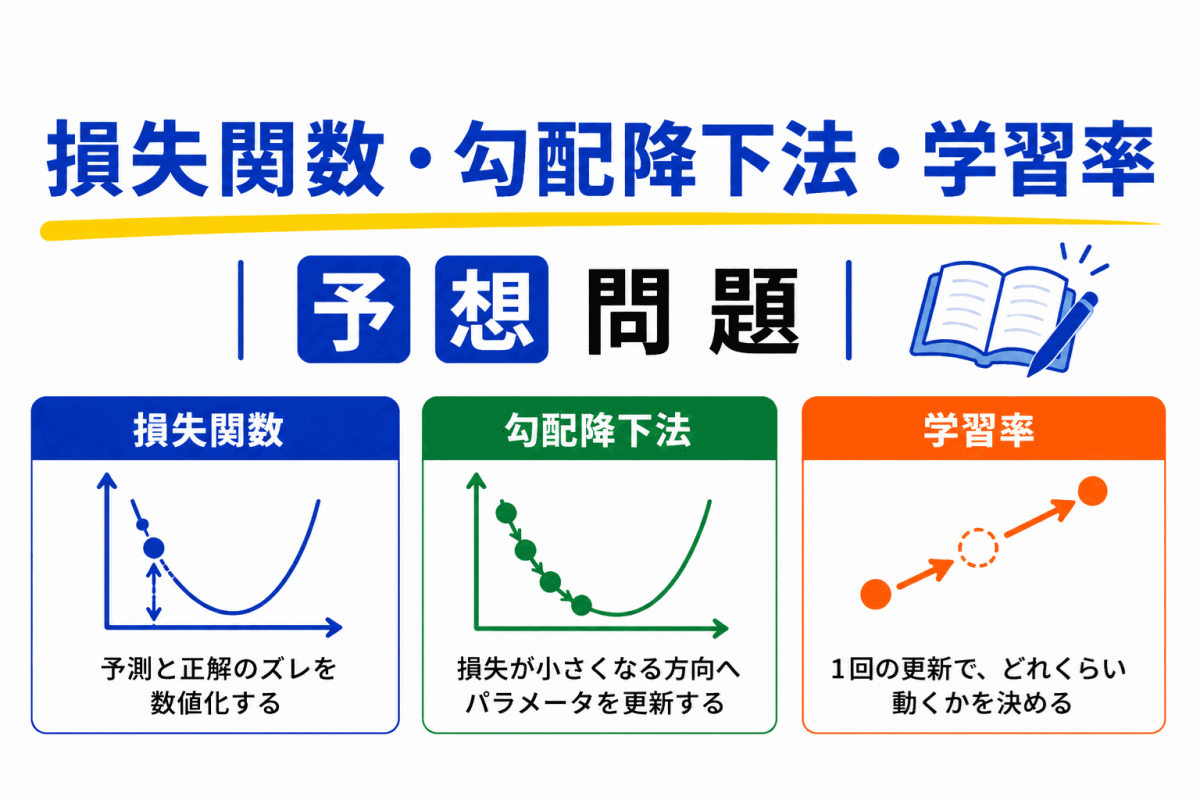
損失関数は「AIがどれくらい間違えたか」を数値化するものです。
AIはまず予測を行い、その予測と正解との差を損失関数で測定します。
損失が大きいほど
という意味になります。
AIの学習をはじめたばかりの人は
を混同しやすいです。
理由はどちらも「数値で性能を見る」からです。
しかし、本当は下の表の役割があります。
| 用語 | 役割 |
|---|---|
| 損失関数 | 学習用 |
| 評価指標 | 確認用 |
勾配降下法の説明として最も適切なものはどれか?
B
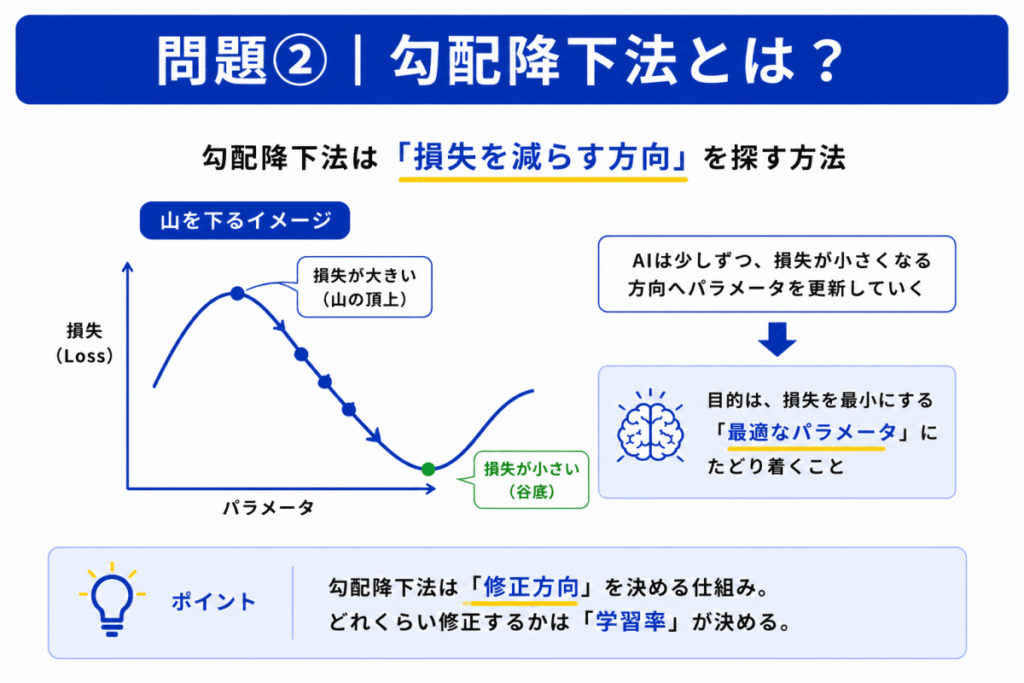
勾配降下法は「どちらに修正すれば損失が減るか」を探す方法です。
よく
でイメージされます。
AIは
修正を繰り返します。
勾配降下法は「修正する仕組み」です。
一方で「どれくらい修正するか」を決めるのは学習率です。
ここは非常に混同しやすいポイントです。
学習率が大きすぎる場合に起きやすいことはどれか?
A. 修正が小さすぎて進まない
B. 損失関数が不要になる
C. 最適解を飛び越えやすくなる
D. データ量が不足する
C
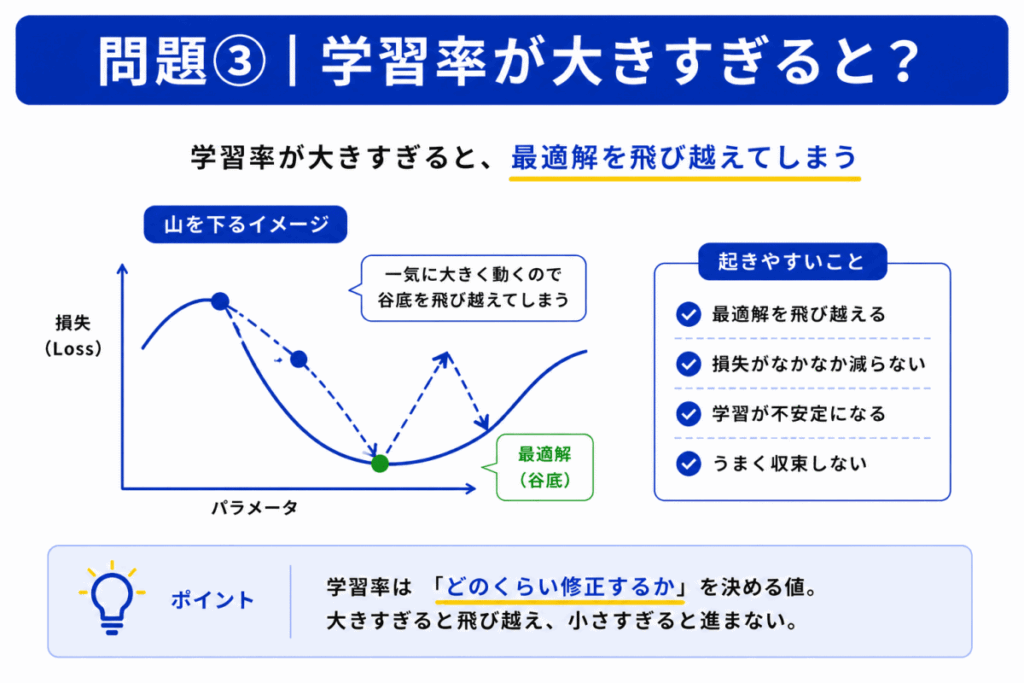
学習率は「どのくらい修正するか」を決める値です。
大きすぎると
という問題が起きます。
逆に小さすぎると
状態になります。
AIの学習をはじめたばかりの人は
をセットで覚えがちです。
しかし、本当は下の表の役割になります。
| 用語 | 役割 |
|---|---|
| 勾配降下法 | 修正方向 |
| 学習率 | 修正量 |
ミニバッチ学習の説明として最も適切なものはどれか?
C
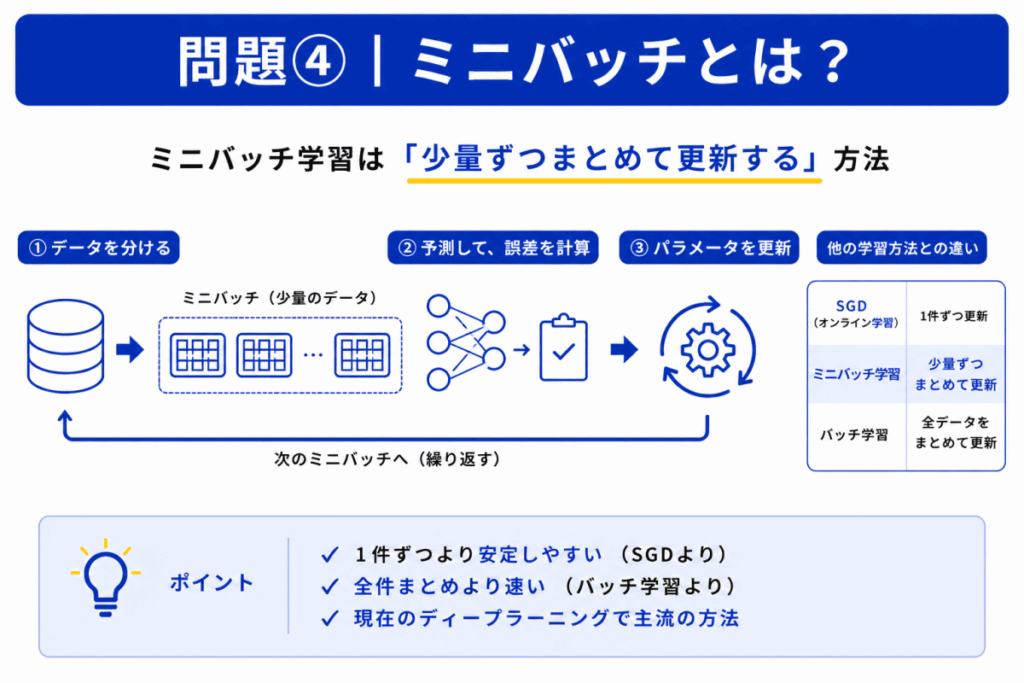
ミニバッチ学習は「少量ずつまとめて更新する」方法です。
特徴
という特徴があります。
整理すると下の表のようになります。
| 用語 | 更新方法 |
|---|---|
| SGD | 1件ずつ |
| ミニバッチ | 少量まとめて |
| バッチ学習 | 全件まとめて |
Adamの特徴として最も適切なものはどれか?
A
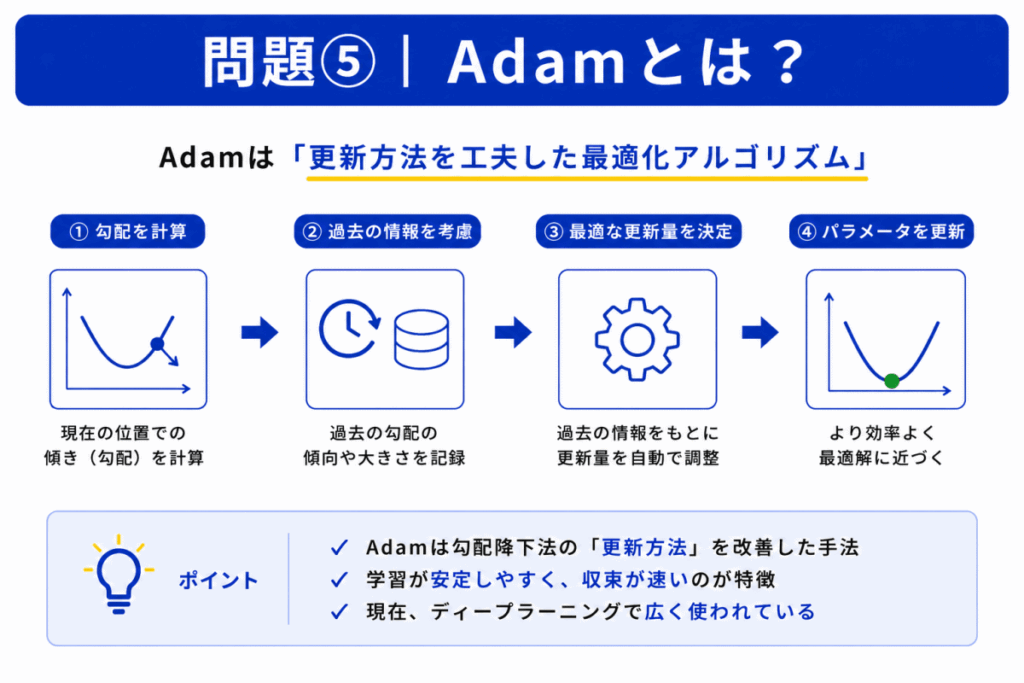
Adamは「更新方法を賢く改善した手法」です。
特徴
という特徴があります。
つまり「どう更新するかを改善したもの」です。
Adamは
とは別カテゴリです。
役割としては「更新の工夫」に近いです。
過学習の説明として最も適切なものはどれか?
B
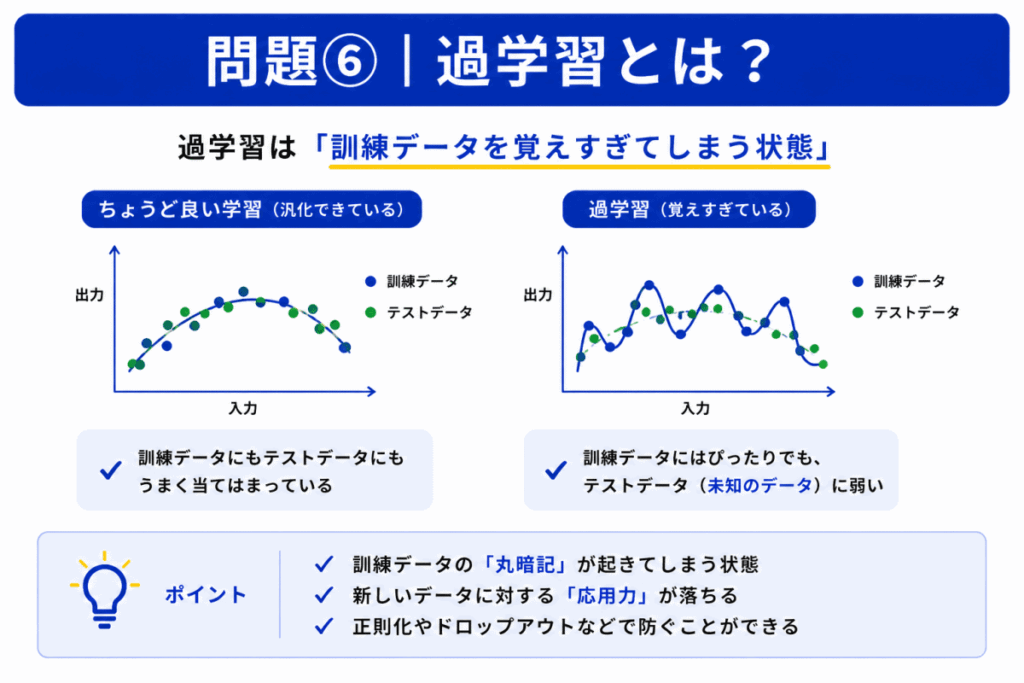
過学習とは「AIの丸暗記」に近い状態です。
訓練データには強いのに
に弱くなります。
つまり「応用力がない状態」です。
これはG検定の学習にも似ています。
という状態は「人間の過学習」とも言えます。
正則化やドロップアウトの役割として最も適切なものはどれか?
A
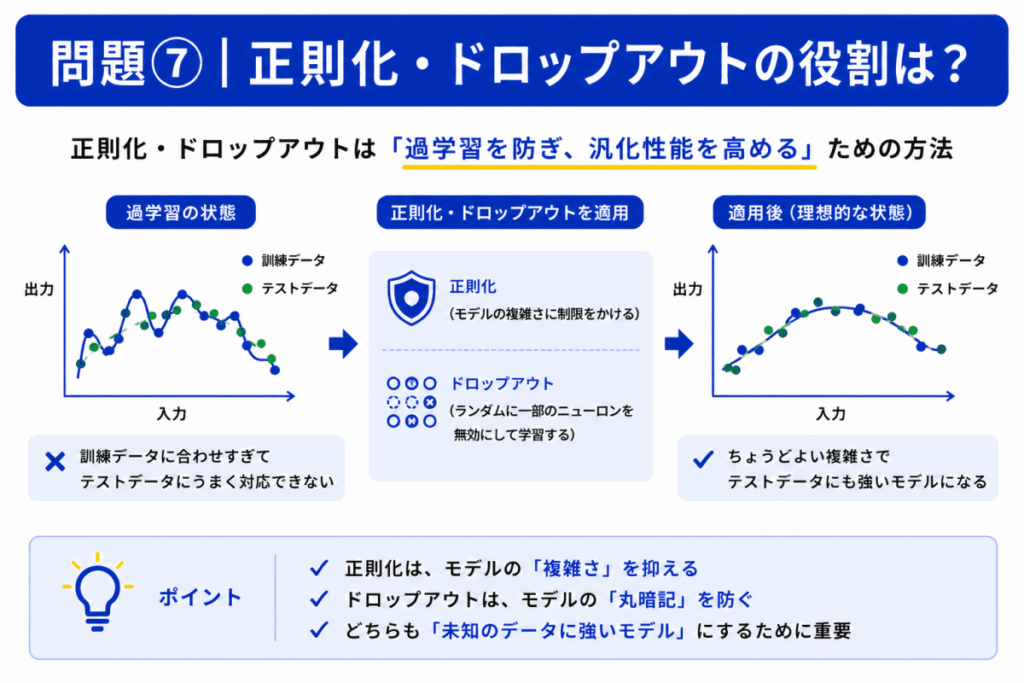
正則化やドロップアウトは「過学習対策」です。
目的は
です。
重要なのは「過学習対策は学習の一部」ということです。
単独用語ではなく、下記のイメージの流れで理解するとわかりやすいです。
という流れで理解すると整理しやすくなります。
評価指標の役割として最も適切なものはどれか?
C
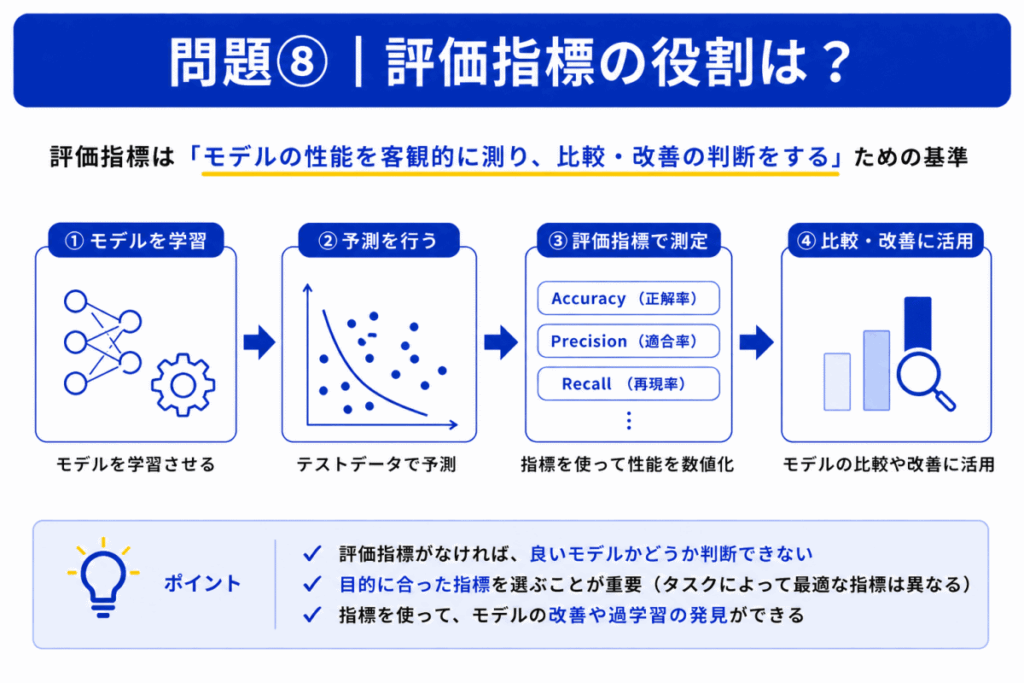
評価指標は「最終的な性能確認」に使います。
例:
などがあります。
ここは超重要です。
| 用語 | 役割 |
|---|---|
| 損失関数 | 学習中に使う |
| 評価指標 | 学習後に確認する |
この違いを整理できると、AI学習全体がかなり理解しやすくなります。
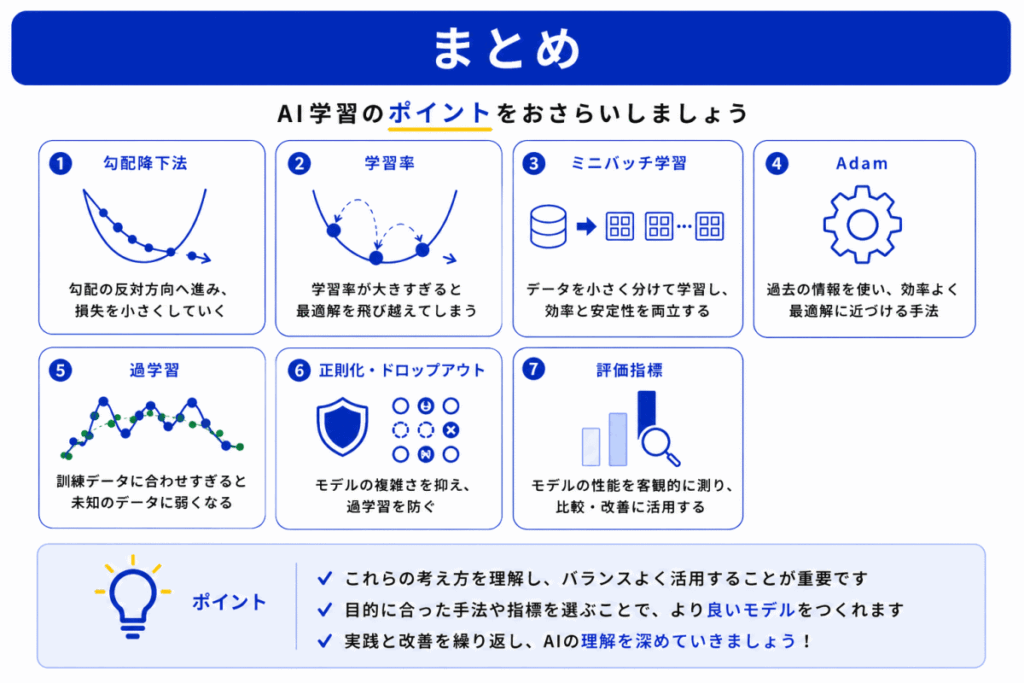
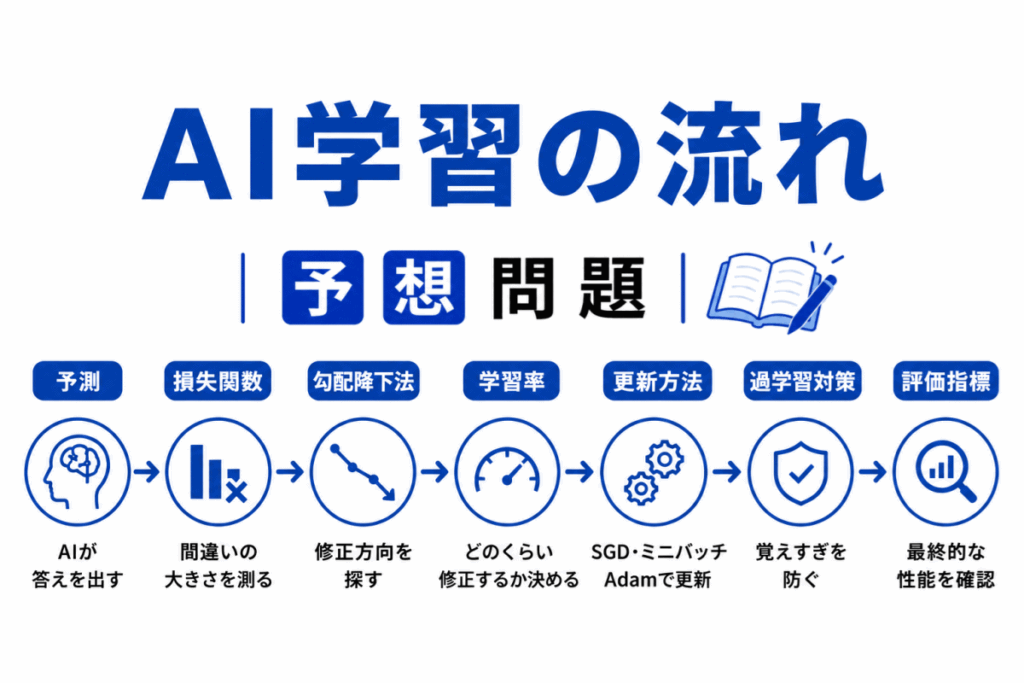
AI学習は「間違いを修正し続ける流れ」です。
流れで見ると下の表になります。
| 流れ | 役割 |
|---|---|
| 予測 | AIが答えを出す |
| 損失関数 | 間違いを測る |
| 勾配降下法 | 修正方向を探す |
| 学習率 | 修正量を決める |
| SGD / Adam | 更新方法を工夫する |
| 過学習対策 | 覚えすぎを防ぐ |
| 評価指標 | 最終確認する |
重要なのは「全部バラバラの用語ではない」ことです。
本当は「AIが学習する流れ」の中で、それぞれ役割分担しているだけです。
重要なのは「単語暗記で終わらせない」ことです。
例えば
のように「役割の違い」を理解できると、問い方が変わっても崩れにくくなります。
これはG検定で非常に重要なことです。
問題文や選択肢の表現が変わっても「AI内部で何が起きているか?」を理解できていれば対応しやすくなります。
AI用語を「点」ではなく「学習の流れ」という「線」で整理できるようになると、AI全体の理解が一気につながりやすくなります。
「AIはどのように学習しているのか?」もっと詳しく整理しています。
どの分野から出題されるか予想しました。
G検定 合格体験談です。2回目の受験で何とか合格できました。