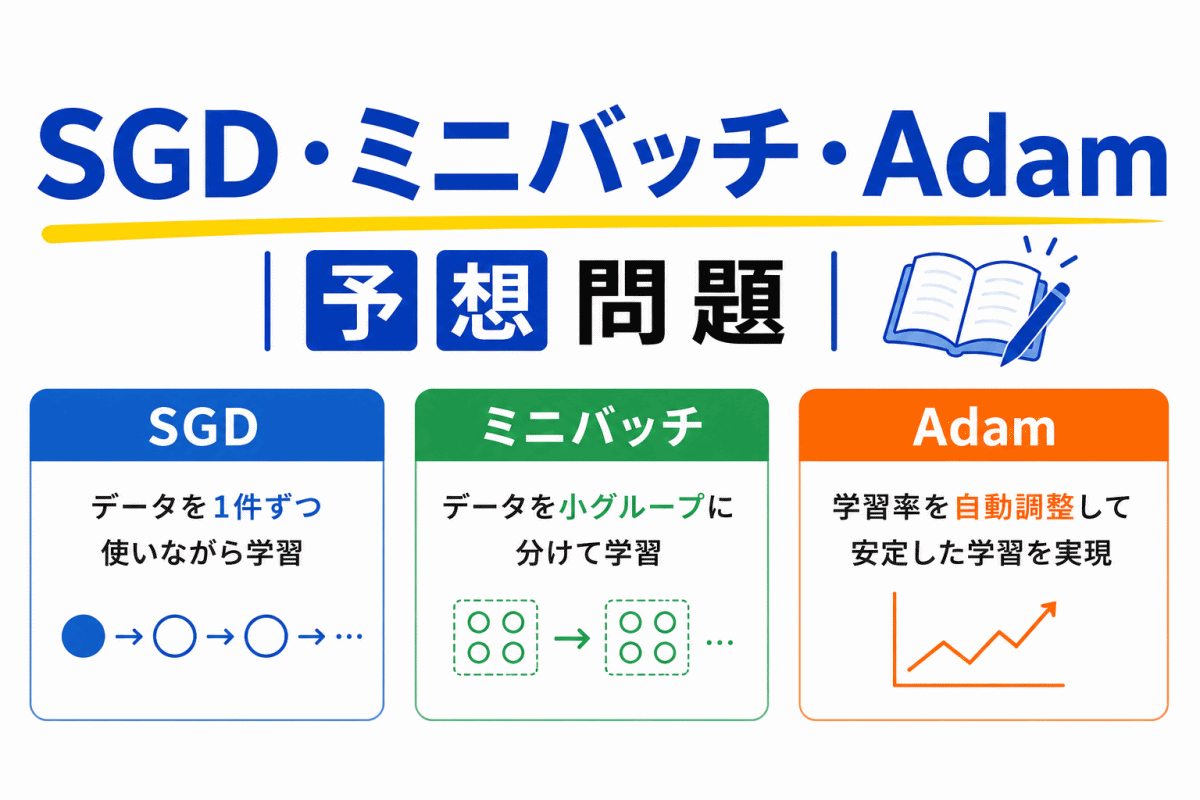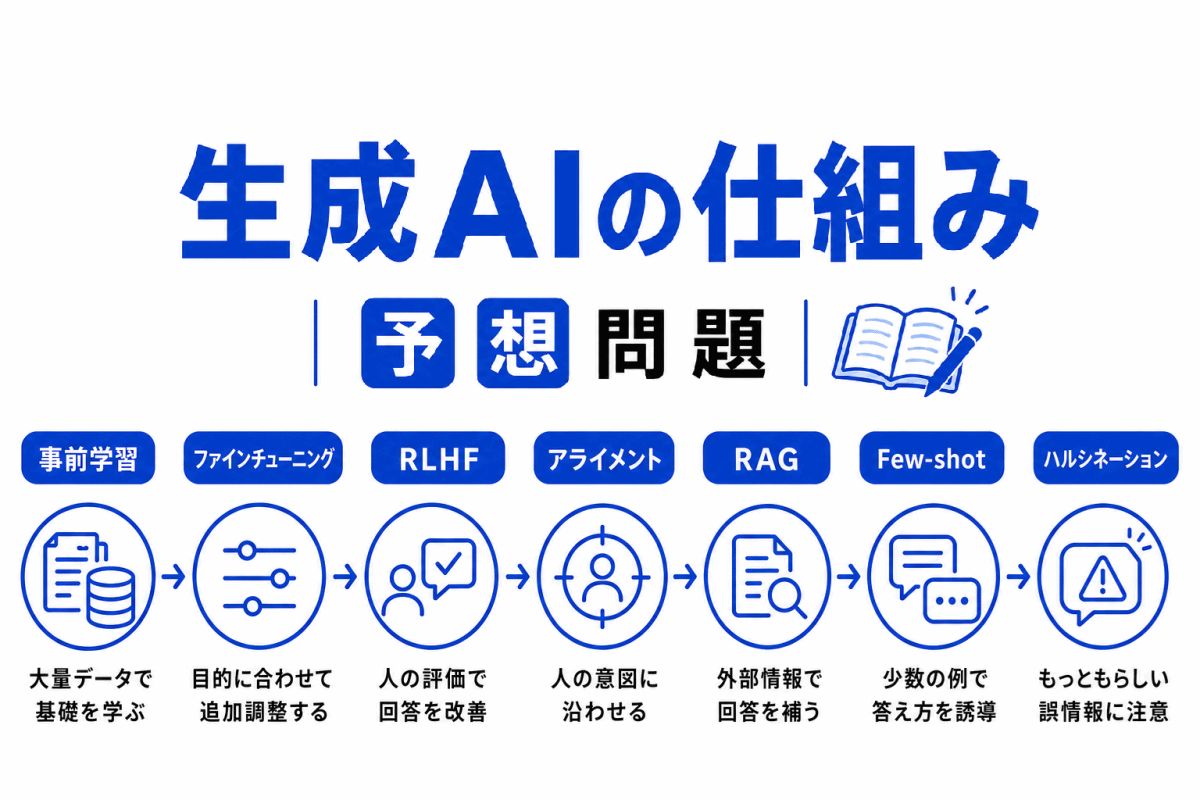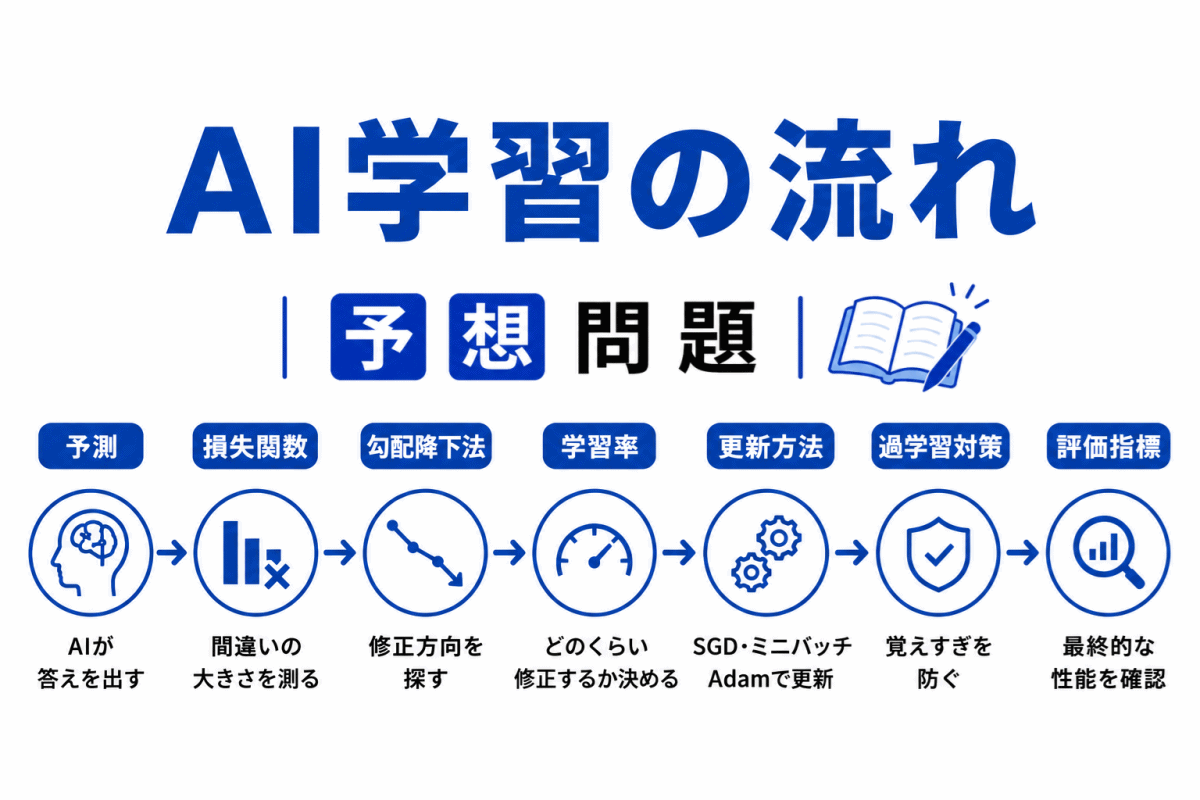
【G検定|理解型予想問題】AI学習の流れ
seo-webmaster
G検定対策ブログ

過学習・正則化・ドロップアウト は重要なテーマです。
ただし、「過学習を防ぐ」、「精度を上げる」と丸暗記しているだけでは、少し聞き方が変わると混乱しやすくなります。
この記事では単なる暗記ではなく
まで含めて整理していきます。
過学習(Overfitting)の説明として最も適切なものはどれか?
B
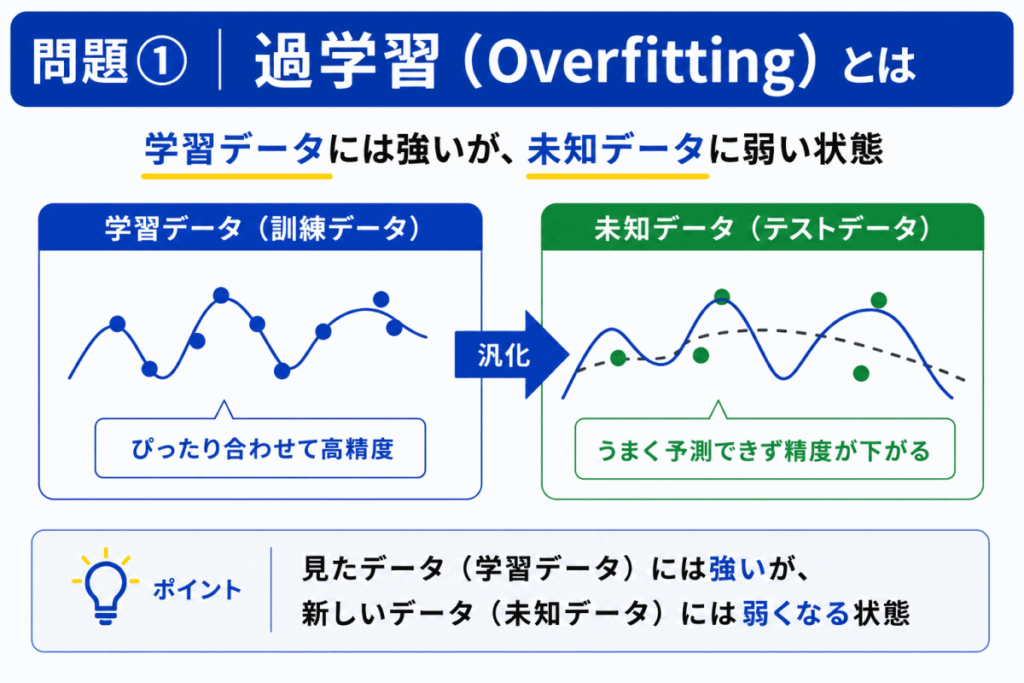
過学習とは、「訓練データに合わせすぎた状態」です。
その結果
が発生します。
つまり「丸暗記して応用できない状態」に近いです。
これは人間の勉強でも起こります。
「精度が高い = 良いモデル」とは限りません。
重要なのは「未知データでも通用するか」です。
AIにおける「過学習」に最も近い人間の勉強法はどれか?
C
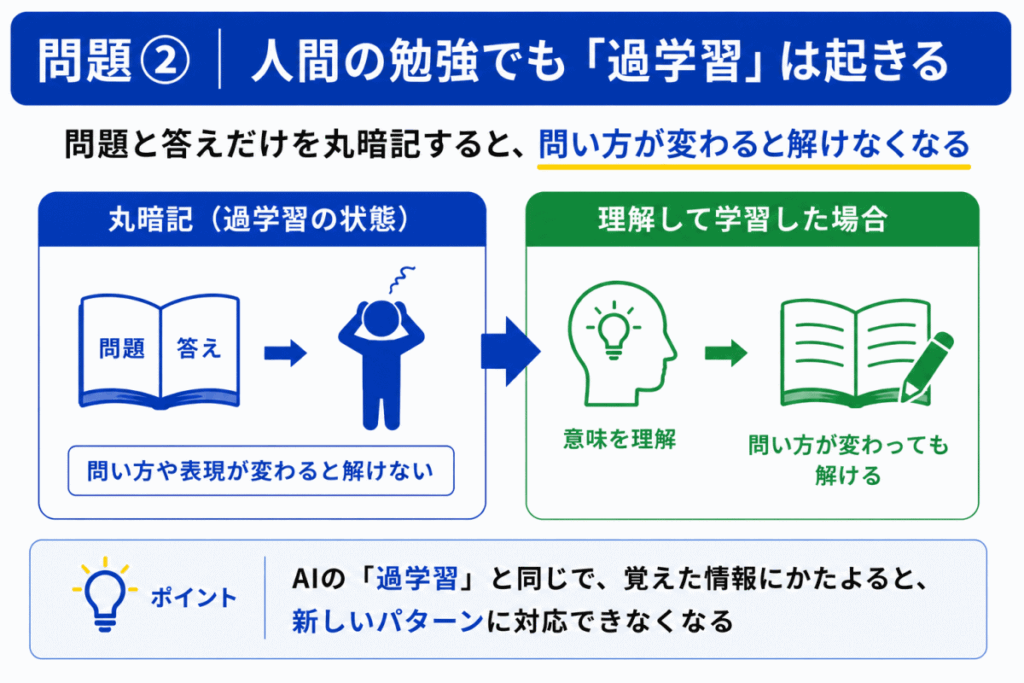
問題と答えだけを覚えると
で崩れやすくなります。
これはAIでいう「訓練データに適応しすぎた状態」に近いです。
G検定では「見たことあるのに解けない」が起こります。
これは「理解不足型の過学習」です。
正則化(Regularization)の目的として最も適切なものはどれか?
C
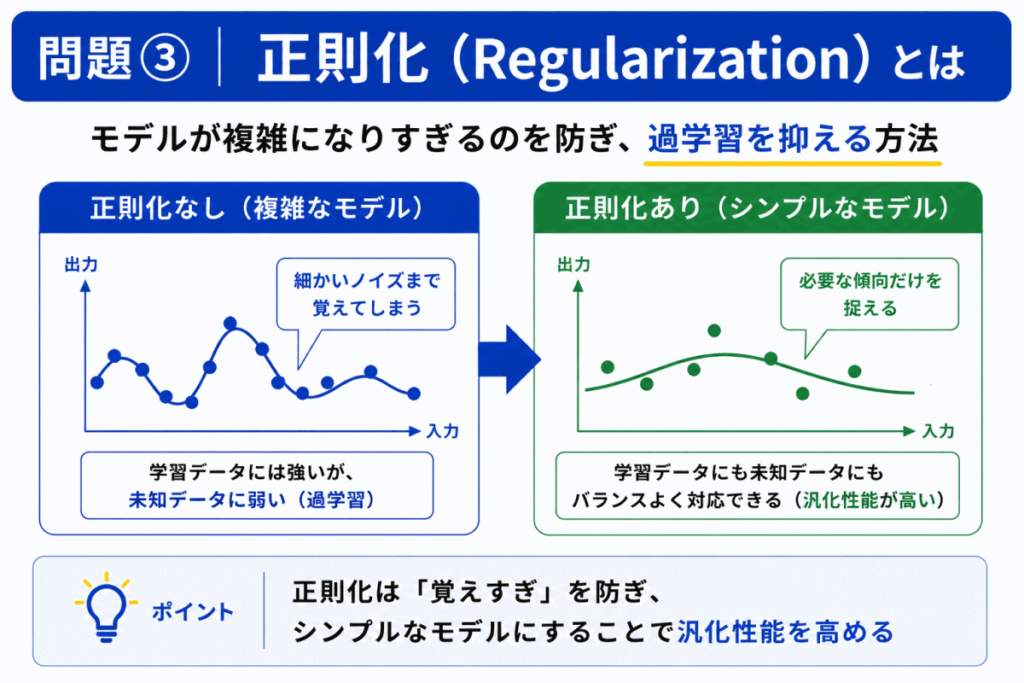
正則化は「モデルが複雑になりすぎるのを防ぐ技術」です。
モデルが複雑すぎると
まで覚えてしまいます。
そこで「シンプルな学習」へ誘導します。
一言でいうと、正則化は「覚えすぎ防止」です。
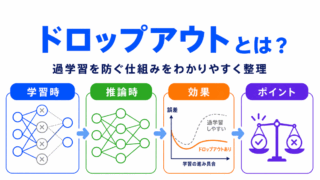
ドロップアウト(Dropout)の説明として正しいものはどれか?
A
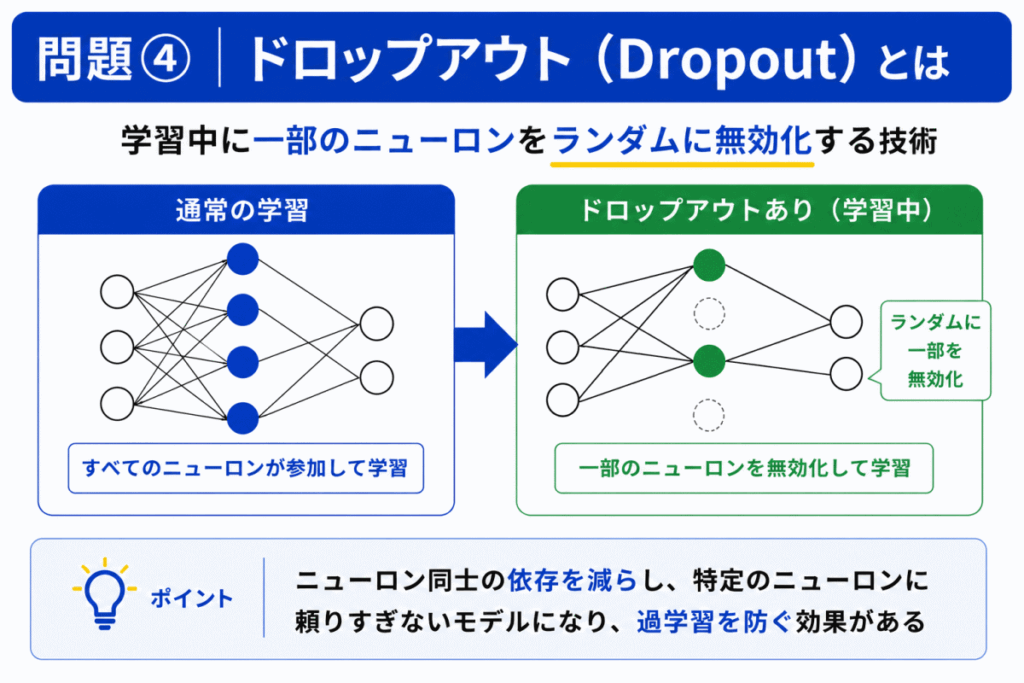
ドロップアウトは、学習時に「一部のニューロンをランダムにOFF」にします。
これにより
を防ぎます。
イメージとしては、毎回メンバーが少し変わるチームで仕事するイメージです。
その結果「どのニューロンにも依存しすぎない」状態になります。
正則化とドロップアウトの共通目的として最も適切なものはどれか?
C
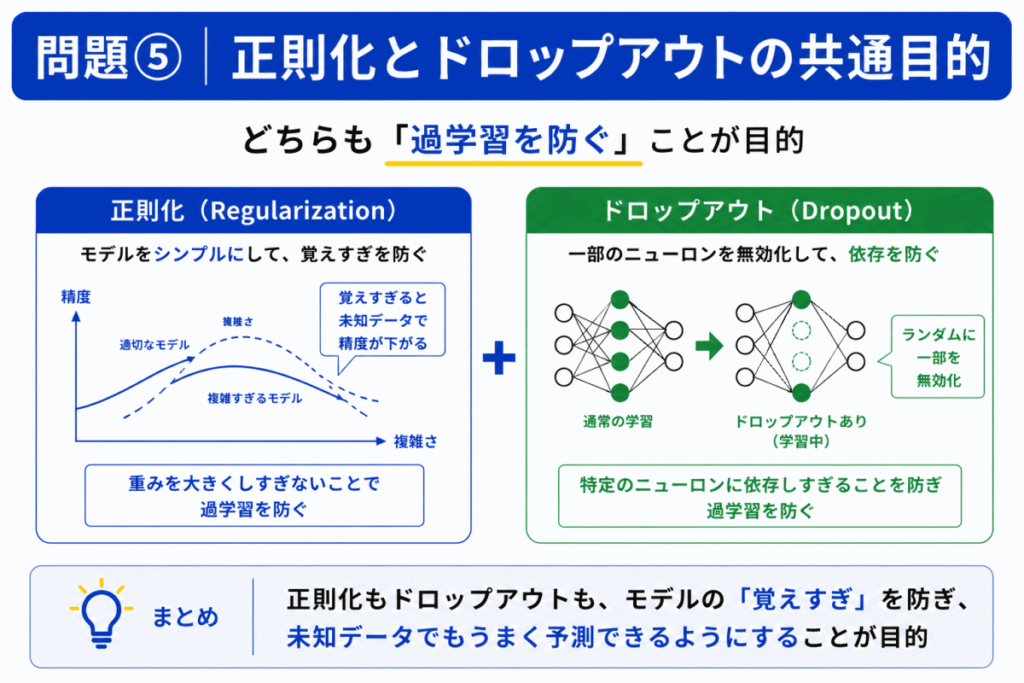
両者とも「過学習対策」です。ただし方法が違います。
正則化
→ 重みを大きくしすぎない
ドロップアウト
→ 一部ニューロンを無効化
G検定では「目的は同じ、手法が違う」といった問題が出ます。
次のうち、過学習が起きている可能性が高い状態はどれか?
C
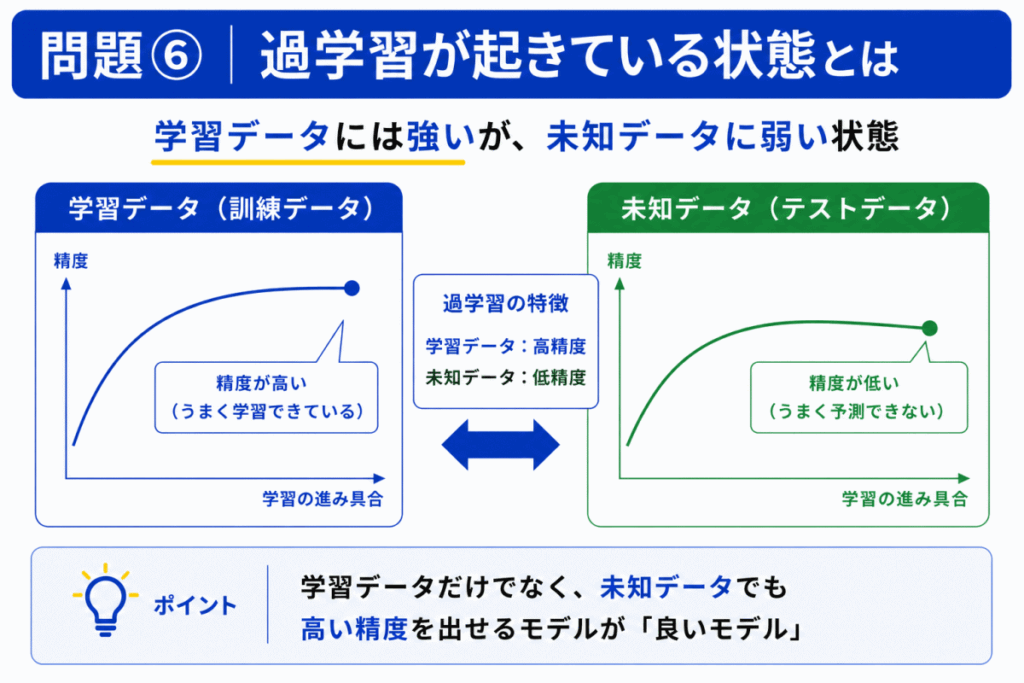
過学習では
状態になります。つまり「覚えたが応用できない」です。
「訓練精度が高いから良い」と思いやすい。
しかし、重要なのは「未知データへの強さ」です。
次のうち、「過学習を防ぐための考え方」として最も適切なものはどれか?
C
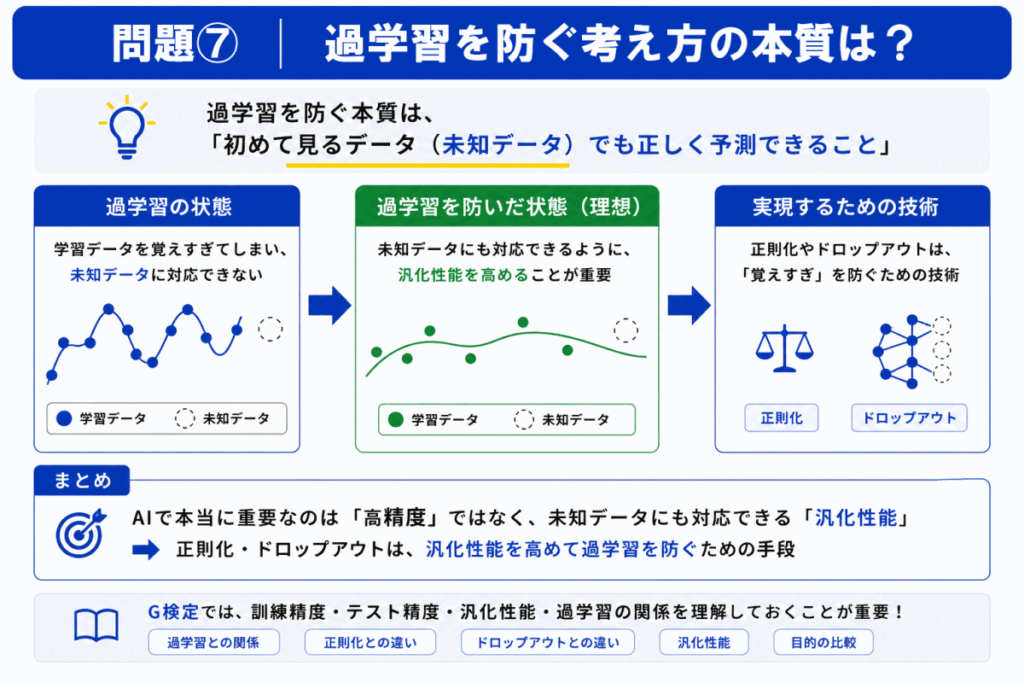
過学習を防ぐ目的は「未知データでも正しく予測できるようにすること」です。
AIは、訓練データだけを覚えすぎると
に弱くなります。
これが「過学習(Overfitting)」です。
AIで本当に重要なのは「覚えること」ではなく「初見データにも対応できること」です。
これを「汎化性能(Generalization)」といいます。
正則化やドロップアウトは「覚えすぎ」を防ぎ、未知データにも対応しやすくするための技術です。
つまり
はどちらも「汎化性能を高める」ことが目的です。
G検定では
の関係がよく問われます。
そのため「高精度 = 良いAI」ではない点に注意が必要です。
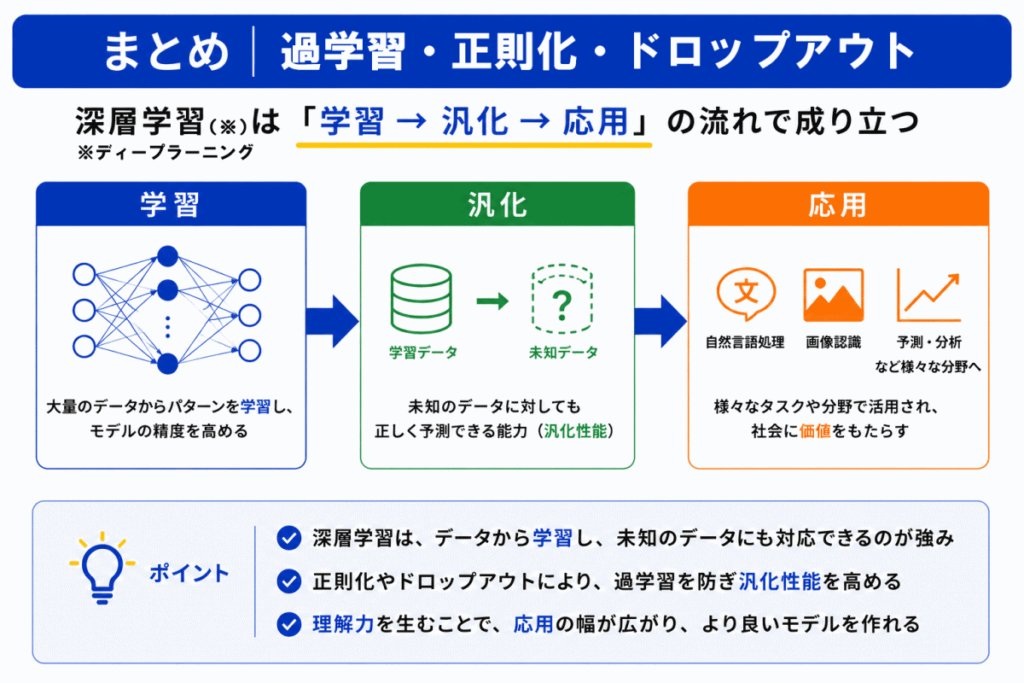
過学習・正則化・ドロップアウトは単なる用語暗記ではなく
まで理解することが重要です。
特にG検定では「見たことあるのに解けない」状態を防ぐためにも「答え」ではなく「意味」を理解することが重要になります。
この予想問題よりも過学習・正則化・ドロップアウトを詳しく整理しています。
もっと詳しく学習したい方はご覧ください。

公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認