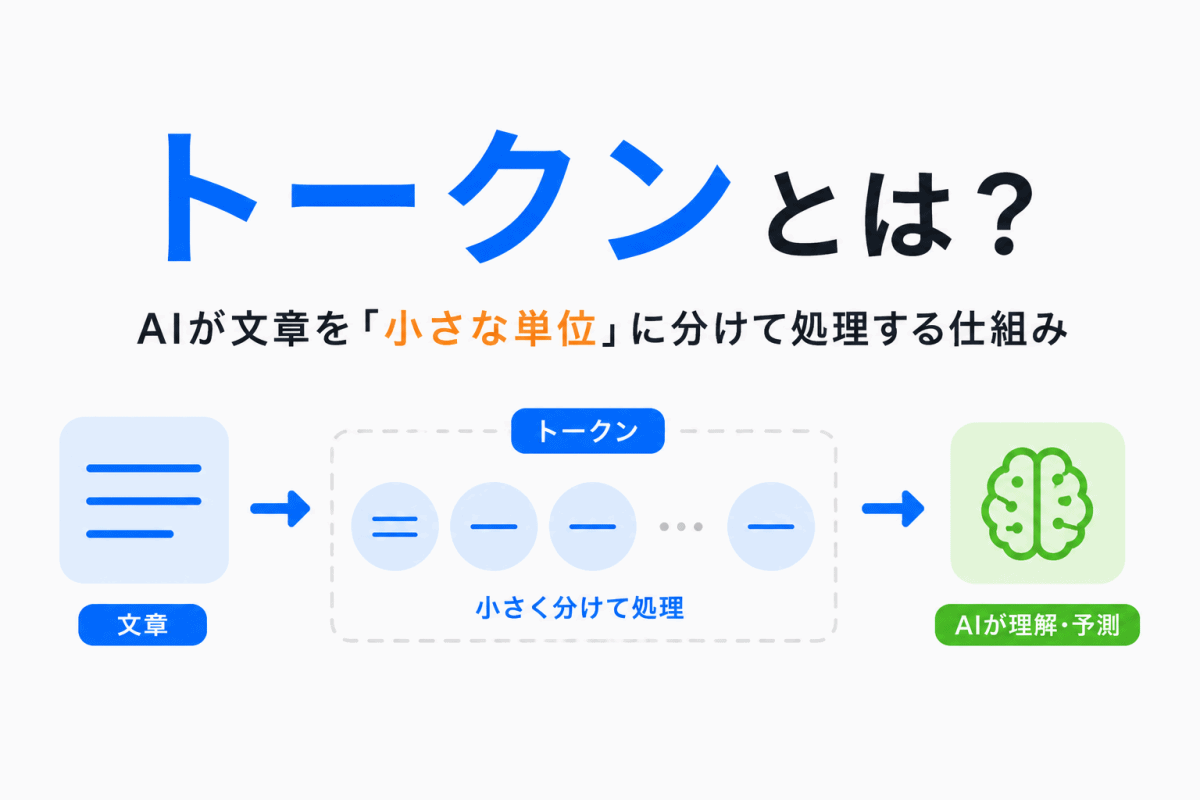
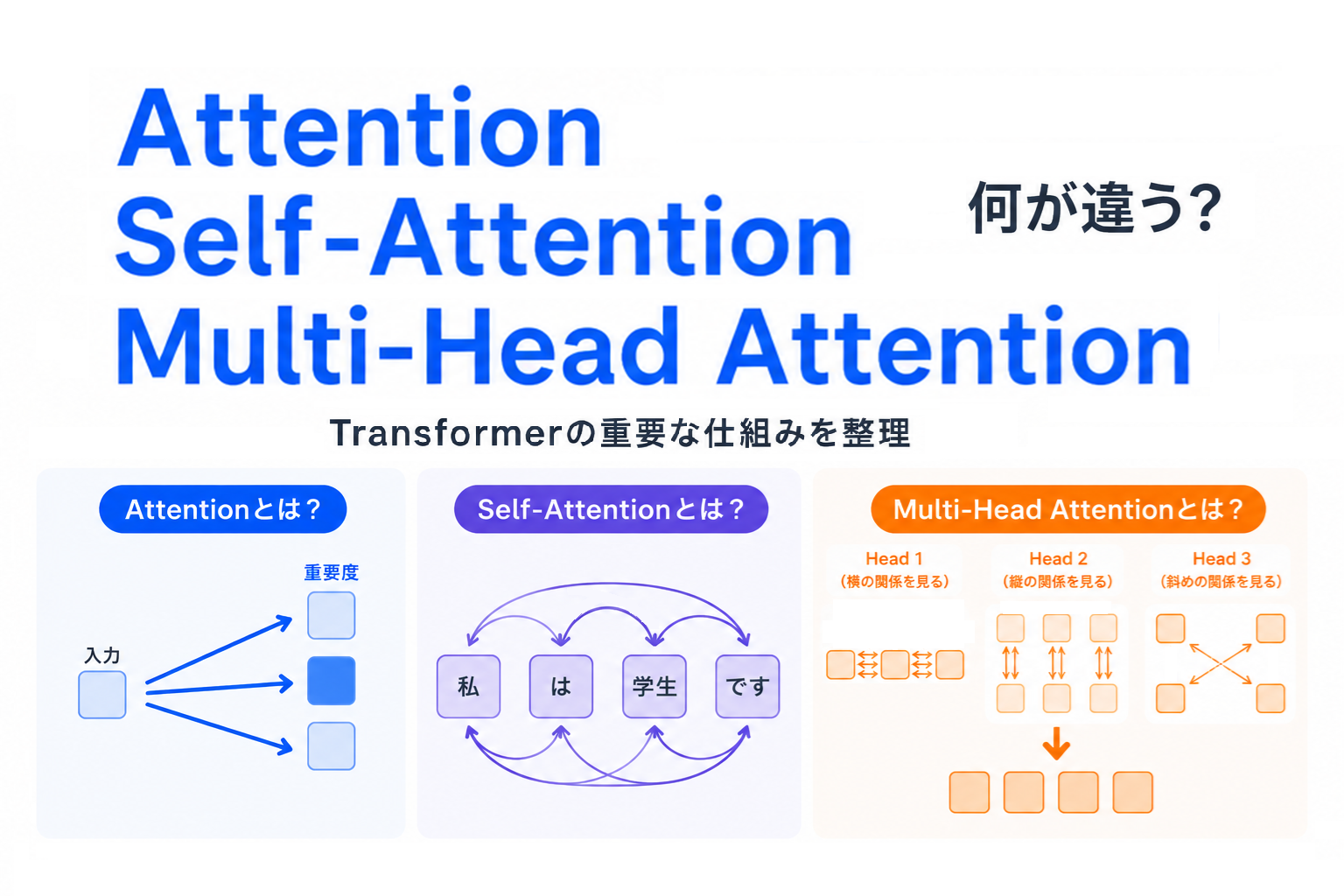
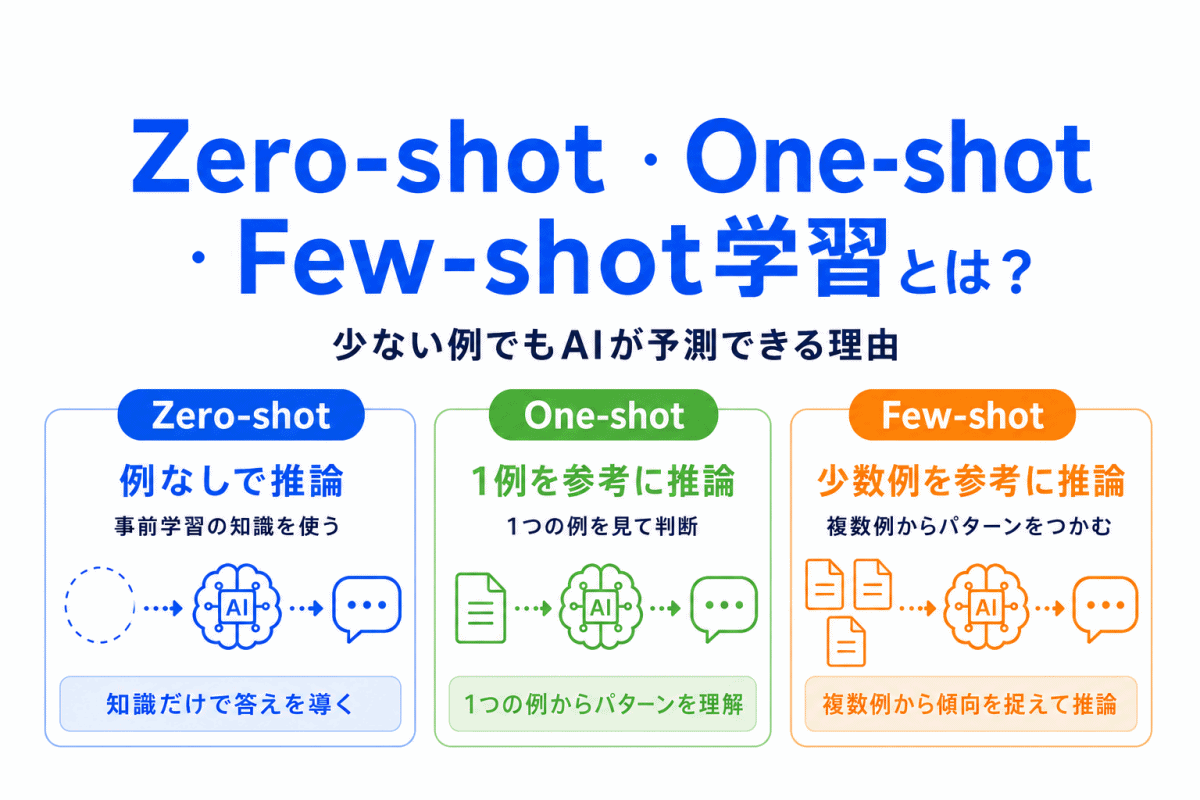
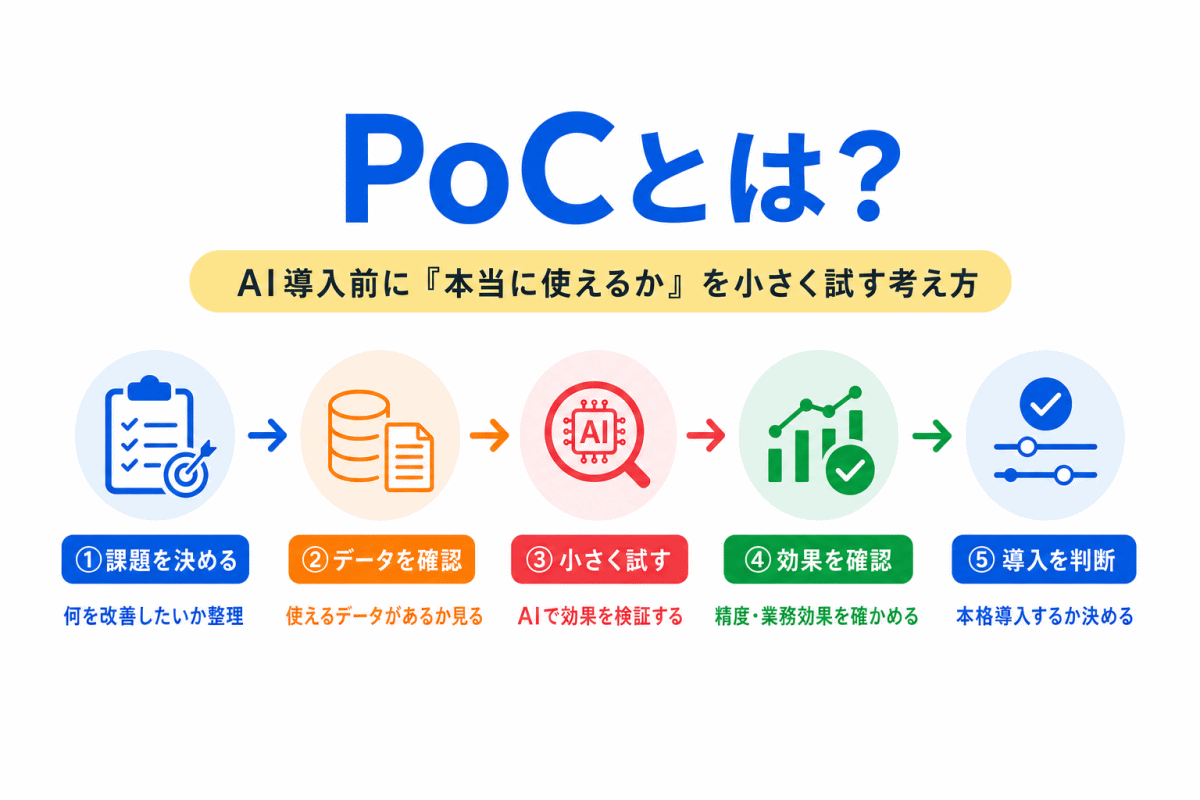
【G検定対策】トークンとは?|AIが文章を「細かく分けて理解する仕組み」
seo-webmaster
G検定対策ブログ
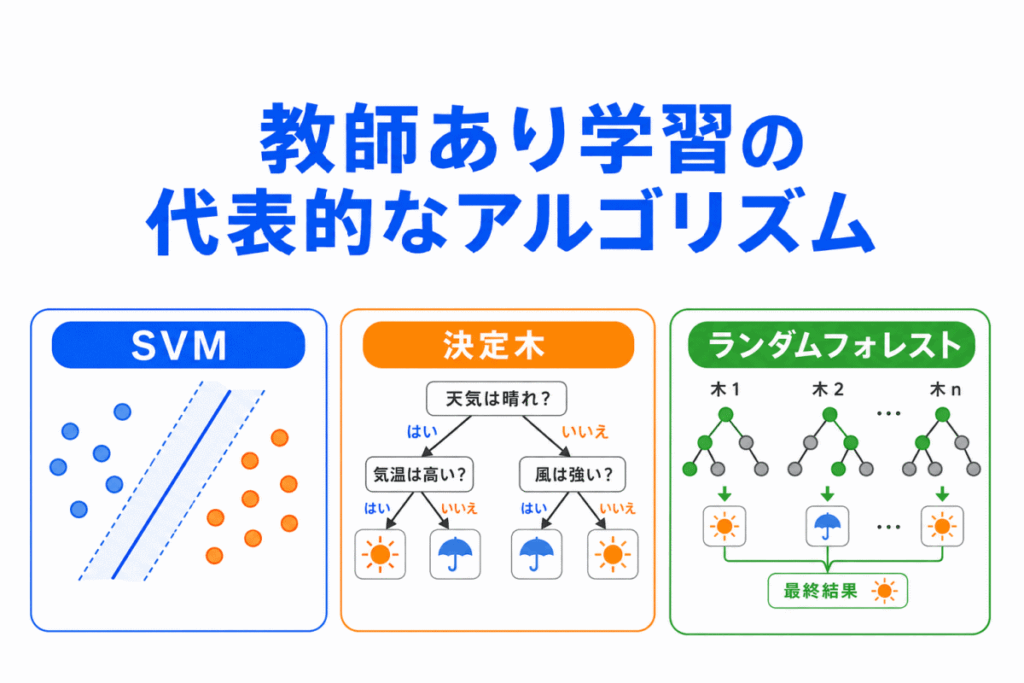
教師あり学習は、正解データを使ってAIに学習させる方法です。
ただし、「教師あり学習」という言葉だけを覚えても、G検定では少し足りません。
実際には、分類や回帰といった問題を解くために、決定木、SVM、ランダムフォレストなど、さまざまなアルゴリズムが使われます。
この記事では、AIの学習をはじめたばかりの人向けに、代表的な教師あり学習のアルゴリズムを、細かい数式ではなく「どんな考え方で予測するのか」という視点で整理します。
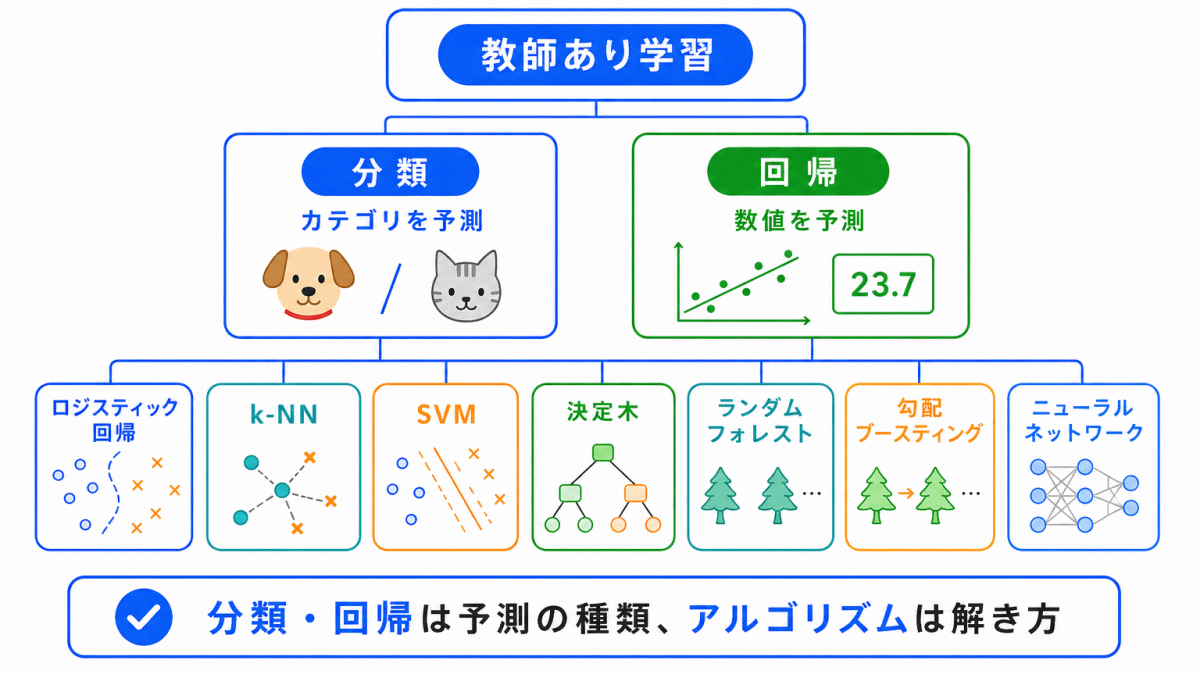
教師あり学習では、正解データを使って予測できるように学習します。
その中には、主に 分類 と 回帰 があります。
| 見る観点 | 内容 |
|---|---|
| 教師あり学習 | 正解データを使って学習する方法 |
| 分類 | カテゴリを予測する |
| 回帰 | 数値を予測する |
| アルゴリズム | 分類や回帰を解くための具体的な方法 |
大事なのは、分類・回帰は「何を予測するか」 であり、決定木やSVMは「どう予測するか」という点です。
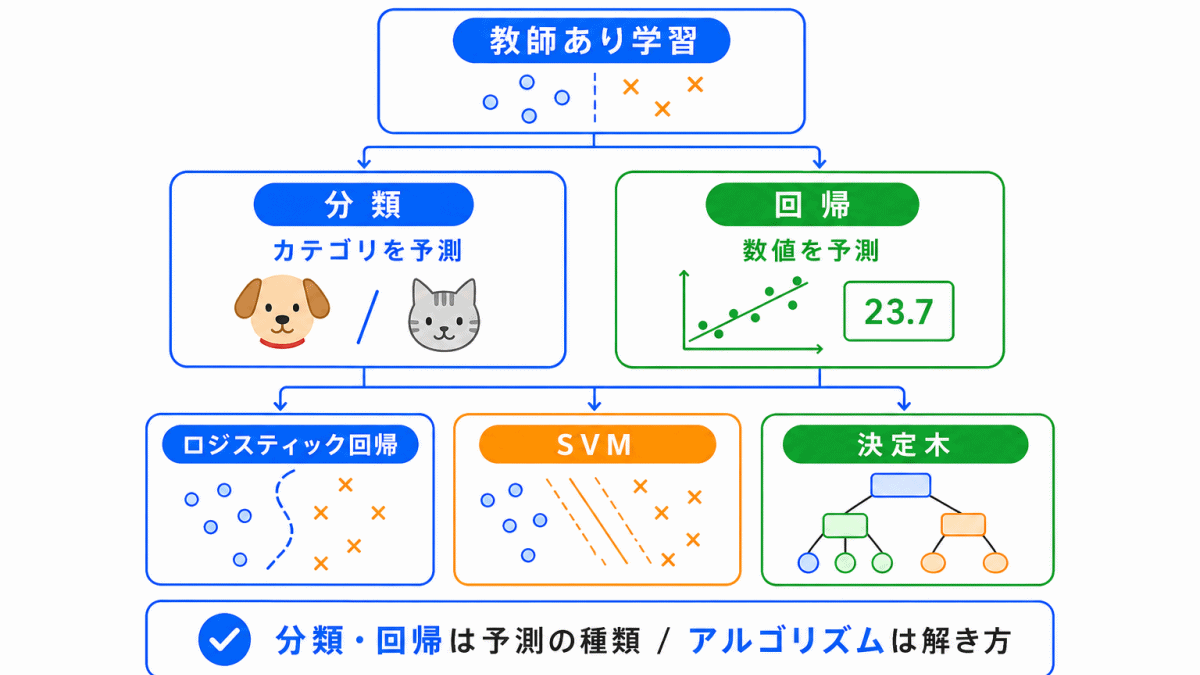
教師あり学習を理解するときは、次の3つを分けて考えると整理しやすくなります。
| 観点 | 例 | 一言でいうと |
|---|---|---|
| 学習方法 | 教師あり学習 | 正解データを使う学習 |
| 問題の種類 | 分類・回帰 | 何を予測するか |
| 具体的な方法 | 決定木・SVM・ランダムフォレストなど | どう予測するか |
たとえば、犬か猫かを判定する問題は「分類」です。
その分類問題を解く方法として、決定木やSVM、ニューラルネットワークなどを使うことがあります。
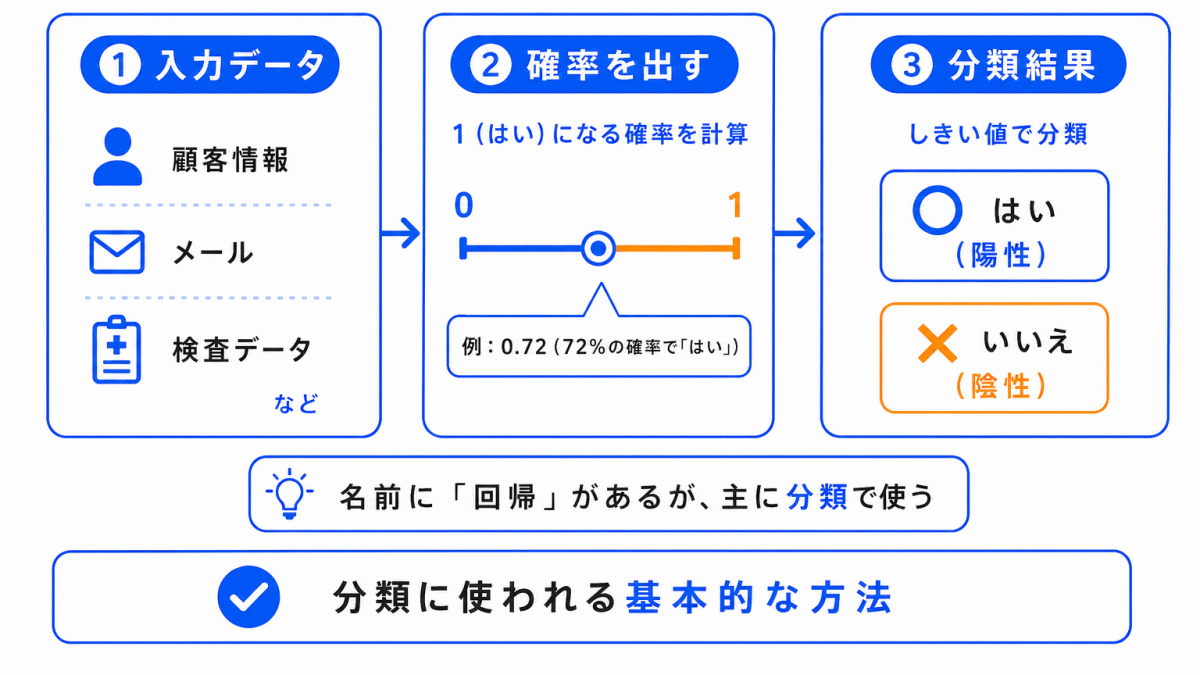
ロジスティック回帰は、主に 分類 に使われる代表的なアルゴリズムです。
名前に「回帰」と入っていますが、G検定では分類に使われる方法として整理しておくと理解しやすいです。
たとえば、次のような場面で使われます。
| 入力 | 予測するもの |
|---|---|
| メール本文 | 迷惑メールかどうか |
| 顧客情報 | 解約しそうかどうか |
| 検査データ | 陽性か陰性か |
ロジスティック回帰は、結果が「AかBか」のような分類問題で使われることが多い方法です。
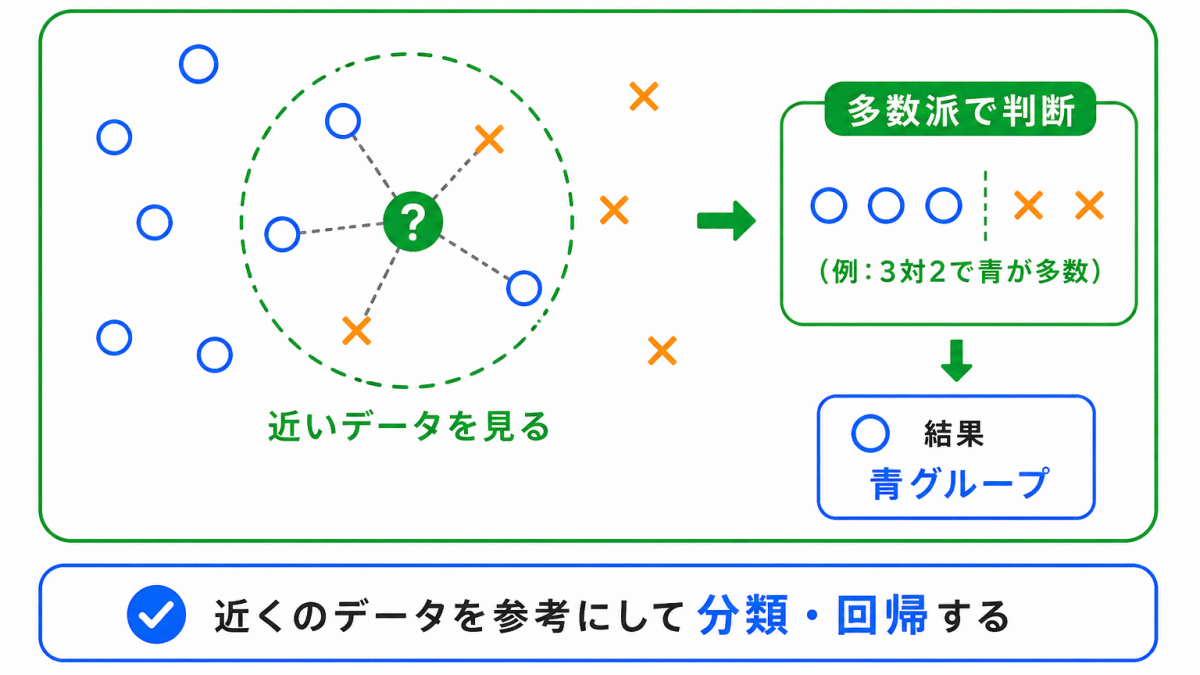
k近傍法は、近くにあるデータを参考にして判断する方法です。
新しいデータが来たとき、その近くにあるデータを見て、「近くに多いカテゴリは何か」をもとに分類します。
たとえば、犬と猫の画像データがあるとします。
新しい画像が犬のデータに近ければ「犬」と判断し、猫のデータに近ければ「猫」と判断するイメージです。
| 特徴 | 内容 |
|---|---|
| 考え方 | 近くにあるデータを参考にする |
| 使われる場面 | 分類・回帰 |
| 覚え方 | 近いデータに聞く方法 |
k-NNは、仕組みはイメージしやすいですが、データが多いと計算量が増えやすい点もあります。
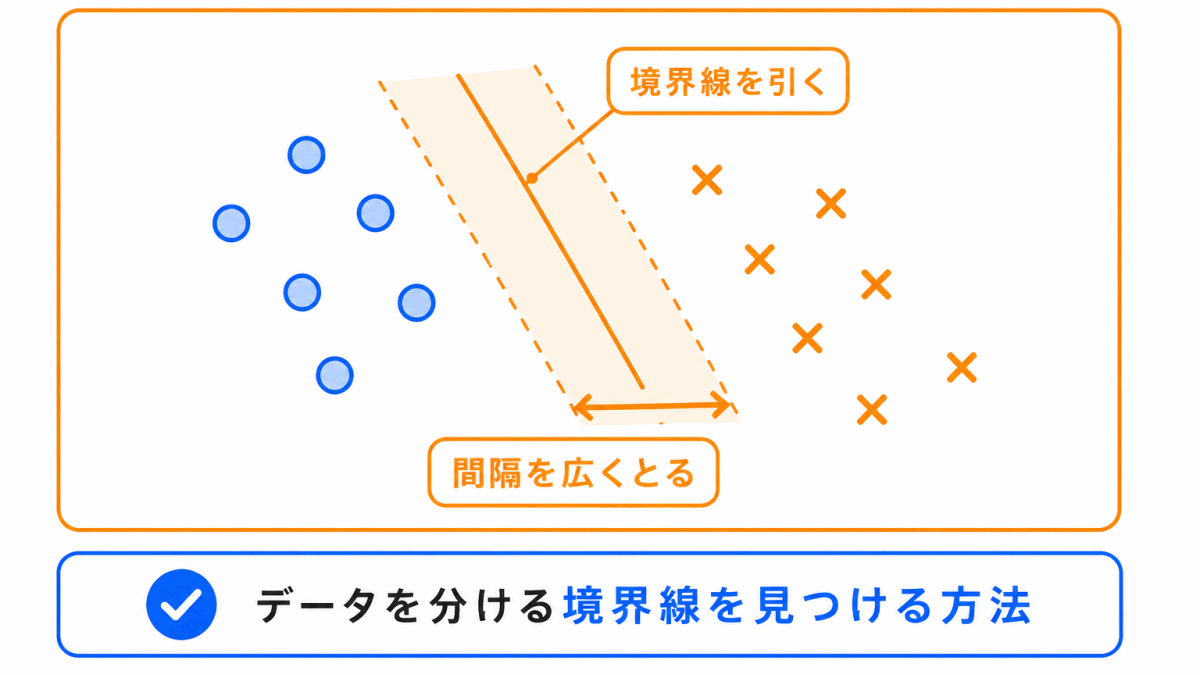
SVMは、データを分ける境界線をうまく引く方法です。
正式にはサポートベクターマシンと呼ばれます。
分類問題では、データを2つのグループに分ける境界を考えます。
SVMでは、その境界をできるだけうまく引き、分類しやすくします。
| 特徴 | 内容 |
|---|---|
| 正式名称 | サポートベクターマシン |
| 主な用途 | 分類 |
| 考え方 | データを分ける境界を見つける |
| イメージ | できるだけ余裕のある線を引く |
SVMは、単に境界線を引くのではなく、グループ同士の間隔をできるだけ広く取る考え方が特徴です。
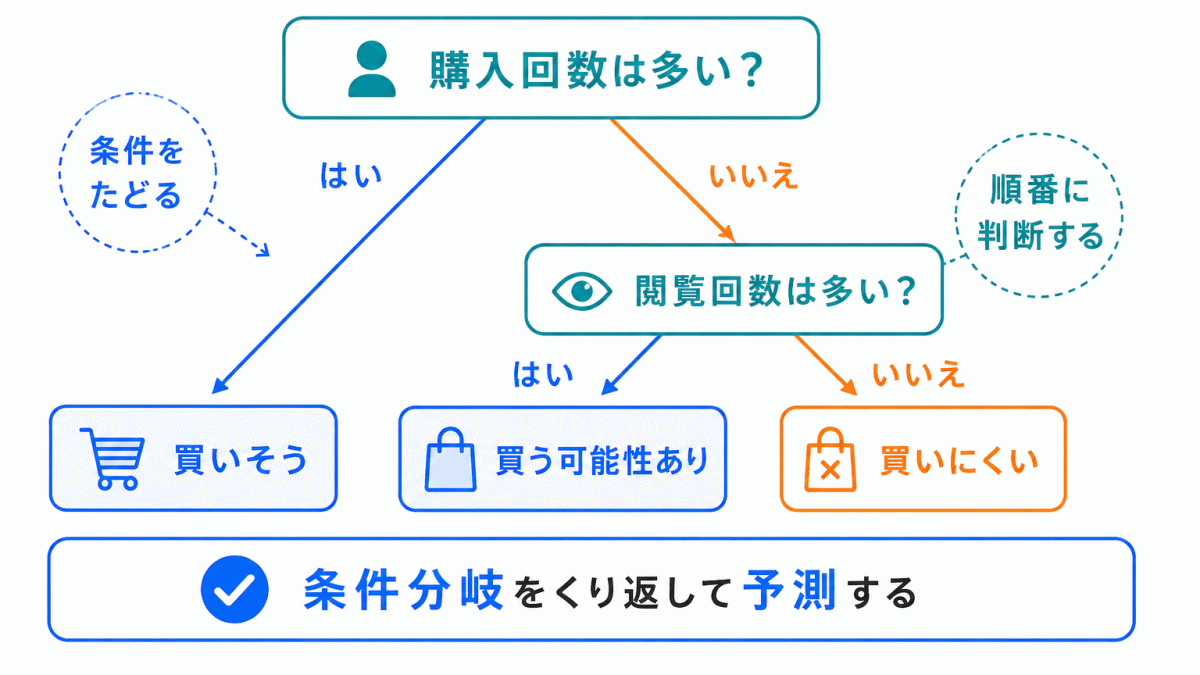
決定木は、条件分岐を使って判断する方法です。
「この条件に当てはまるか?」を順番にたどって、最終的な予測を行います。
たとえば、顧客が商品を買うかどうかを予測する場合、次のように考えます。
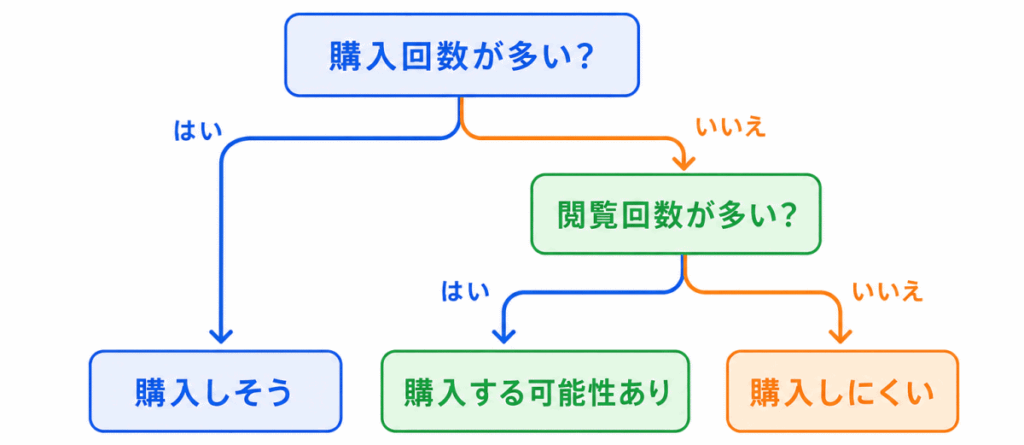
決定木は、判断の流れが見えやすいのが特徴です。
| 特徴 | 内容 |
|---|---|
| 考え方 | 条件分岐で判断する |
| 使われる場面 | 分類・回帰 |
| 長所 | 判断の流れがわかりやすい |
| 注意点 | 複雑にしすぎると過学習しやすい |
決定木はわかりやすい反面、細かく分けすぎると学習データに合わせすぎてしまうことがあります。
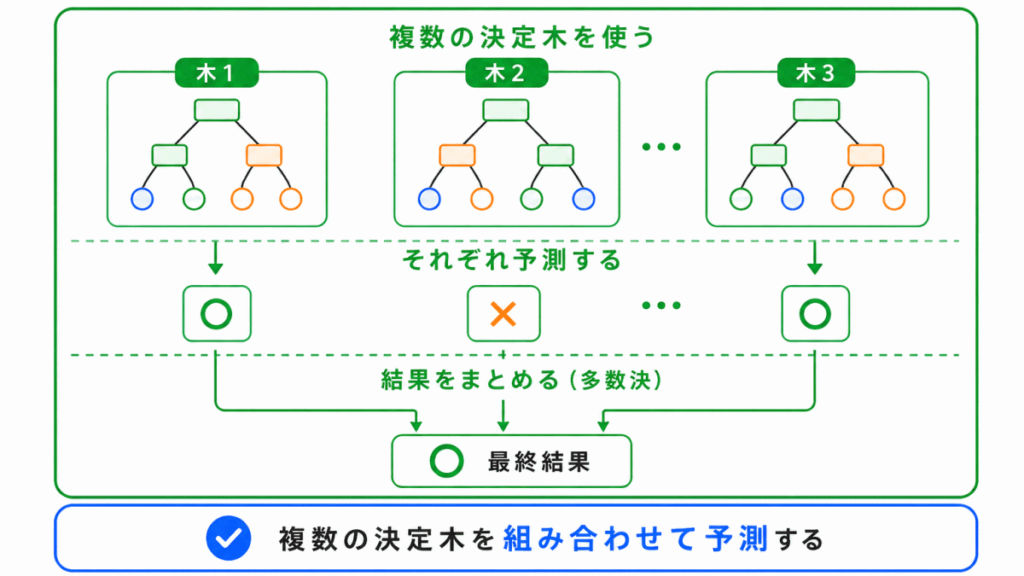
ランダムフォレストは、複数の決定木を組み合わせる方法です。
1本の決定木だけで判断するのではなく、たくさんの決定木を作り、その結果を組み合わせて予測します。
| 用語 | 一言でいうと |
|---|---|
| 決定木 | 1本の木で判断する |
| ランダムフォレスト | 複数の決定木で判断する |
「フォレスト」は森という意味です。
つまり、ランダムフォレストは、たくさんの決定木を集めた方法と考えるとわかりやすいです。
複数のモデルを組み合わせるため、1本の決定木よりも安定した予測をしやすくなります。
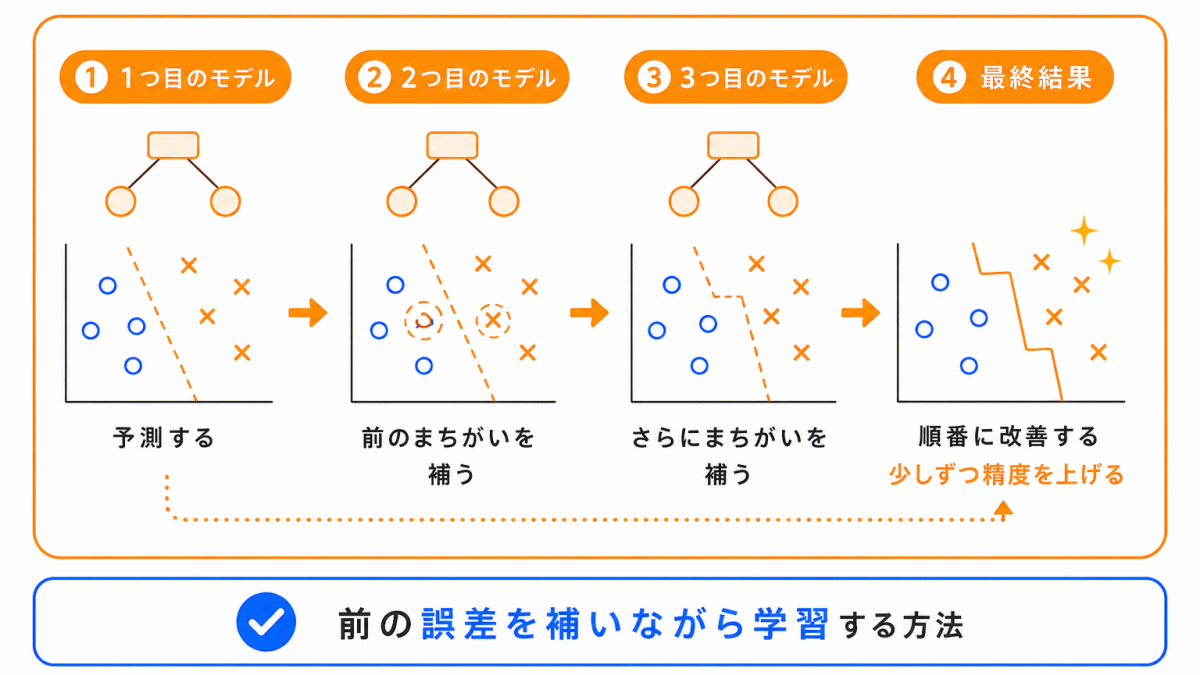
勾配ブースティングは、前のモデルの間違いを補うように、モデルを順番に重ねていく方法です。
ランダムフォレストと同じく、複数のモデルを組み合わせる考え方ですが、仕組みが少し違います。
| 方法 | 考え方 |
|---|---|
| ランダムフォレスト | 複数の決定木を並列に使う |
| 勾配ブースティング | 間違いを補うように順番に学習する |
勾配ブースティングは、予測性能が高くなりやすい方法として使われます。
ただし、G検定対策では、まず「複数のモデルを組み合わせる方法の一種」と整理しておけば十分です。
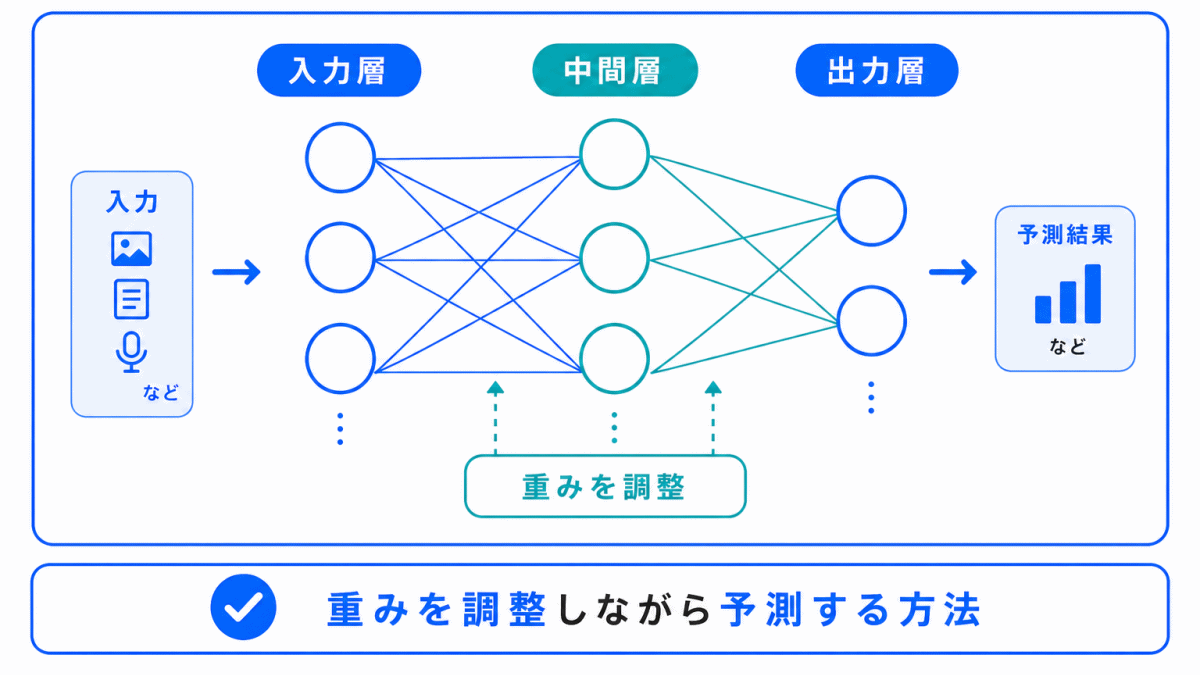
ニューラルネットワークも、教師あり学習で使われる代表的な方法の1つです。
入力データを受け取り、重みを調整しながら、出力が正解に近づくように学習します。
| 観点 | 内容 |
|---|---|
| 入力 | 画像・文章・数値データなど |
| 学習 | 重みを調整する |
| 目的 | 予測を正解に近づける |
| 関係 | ディープラーニングの基礎になる |
ニューラルネットワークを深くしたものが、ディープラーニングにつながります。
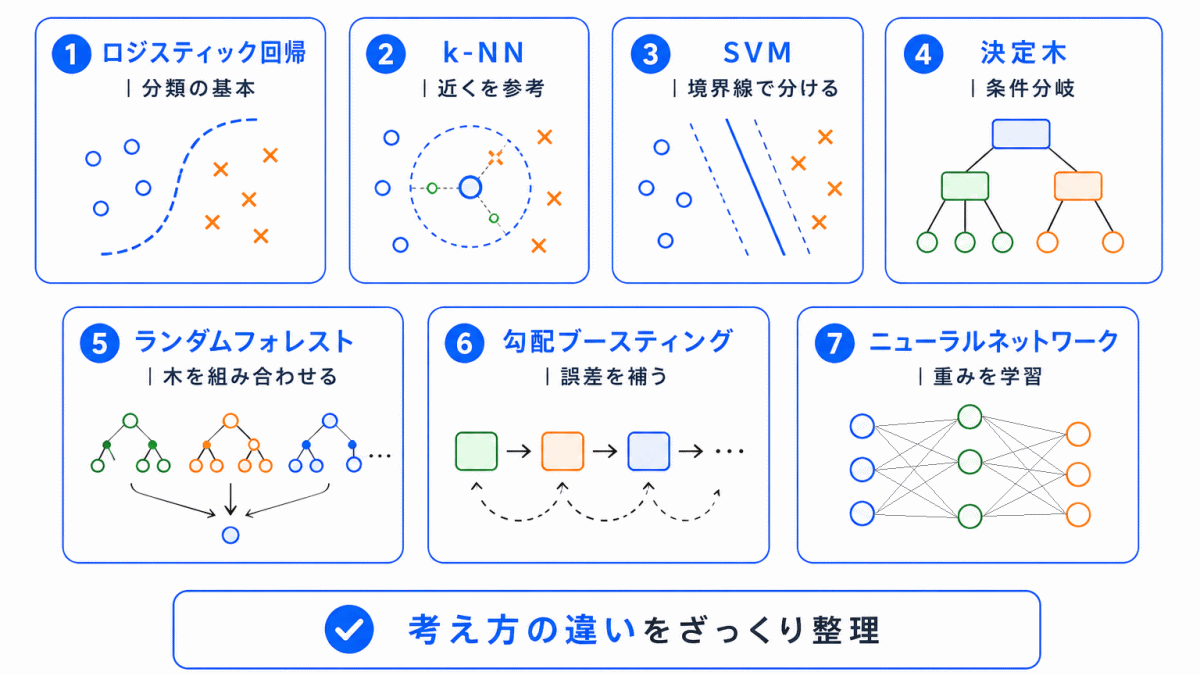
教師あり学習の代表的なアルゴリズムを一覧で整理すると、次のようになります。
| アルゴリズム | 一言でいうと | 主な用途 |
|---|---|---|
| ロジスティック回帰 | 分類に使われる基本的な方法 | 分類 |
| k-NN | 近くのデータを参考にする方法 | 分類・回帰 |
| SVM | 境界線をうまく引く方法 | 分類 |
| 決定木 | 条件分岐で判断する方法 | 分類・回帰 |
| ランダムフォレスト | 複数の決定木を組み合わせる方法 | 分類・回帰 |
| 勾配ブースティング | 間違いを補うように学習する方法 | 分類・回帰 |
| ニューラルネットワーク | 重みを調整して複雑な関係を学ぶ方法 | 分類・回帰 |
すべてを細かく覚える必要はありません。
まずは、それぞれの「考え方の違い」を押さえることが大切です。
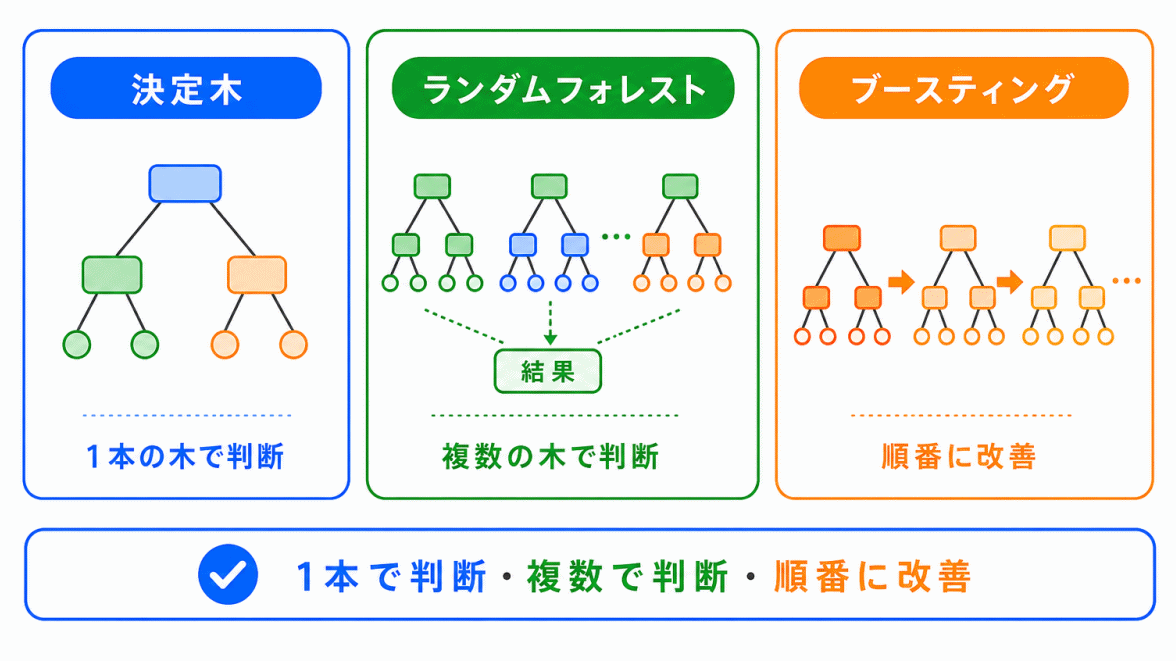
決定木、ランダムフォレスト、ブースティングは混同しやすい用語です。
| 用語 | 違い |
|---|---|
| 決定木 | 条件分岐で判断する1本の木 |
| ランダムフォレスト | 複数の決定木をまとめて使う |
| ブースティング | 間違いを補うようにモデルを順番に作る |
この3つは、「木」を使う方法としてつながっています。
このように流れで整理すると、違いが見えやすくなります。
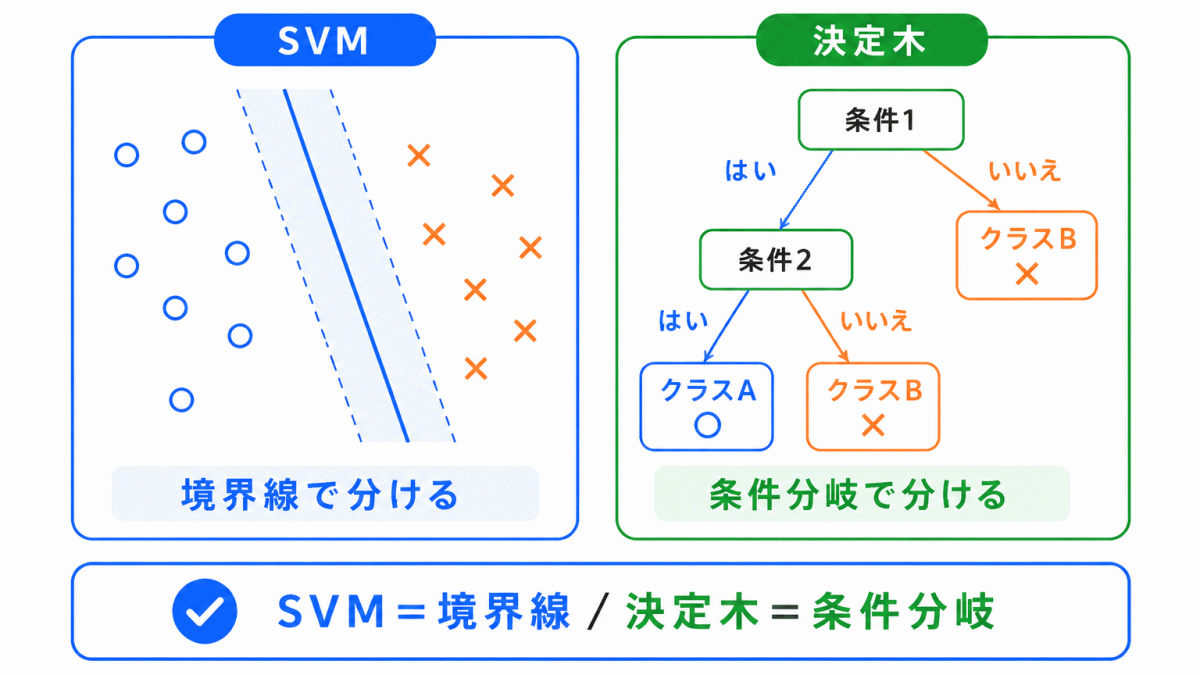
SVMと決定木も、どちらも分類に使われることがあります。
ただし、考え方は違います。
| 用語 | 考え方 |
|---|---|
| SVM | データを分ける境界を見つける |
| 決定木 | 条件分岐で判断する |
SVMは「どこに境界を引くか」を考える方法です。
決定木は「どの条件で分けるか」を考える方法です。
どちらも分類に使えるため、G検定では「分類問題で使われる代表的な手法」として整理しておくとよいです。
G検定では、細かい計算よりも、用語の意味や関係が問われやすいです。
たとえば、次のような見分け方が大切です。
| 問われ方 | 選ぶ用語 |
|---|---|
| 条件分岐で判断する | 決定木 |
| 複数の決定木を組み合わせる | ランダムフォレスト |
| データを分ける境界を見つける | SVM |
| 近くのデータを参考にする | k-NN |
| 分類に使われるが名前に回帰が入る | ロジスティック回帰 |
| 複数のモデルを組み合わせる | アンサンブル学習 |
特に、ランダムフォレストはアンサンブル学習の代表例として問われることがあります。
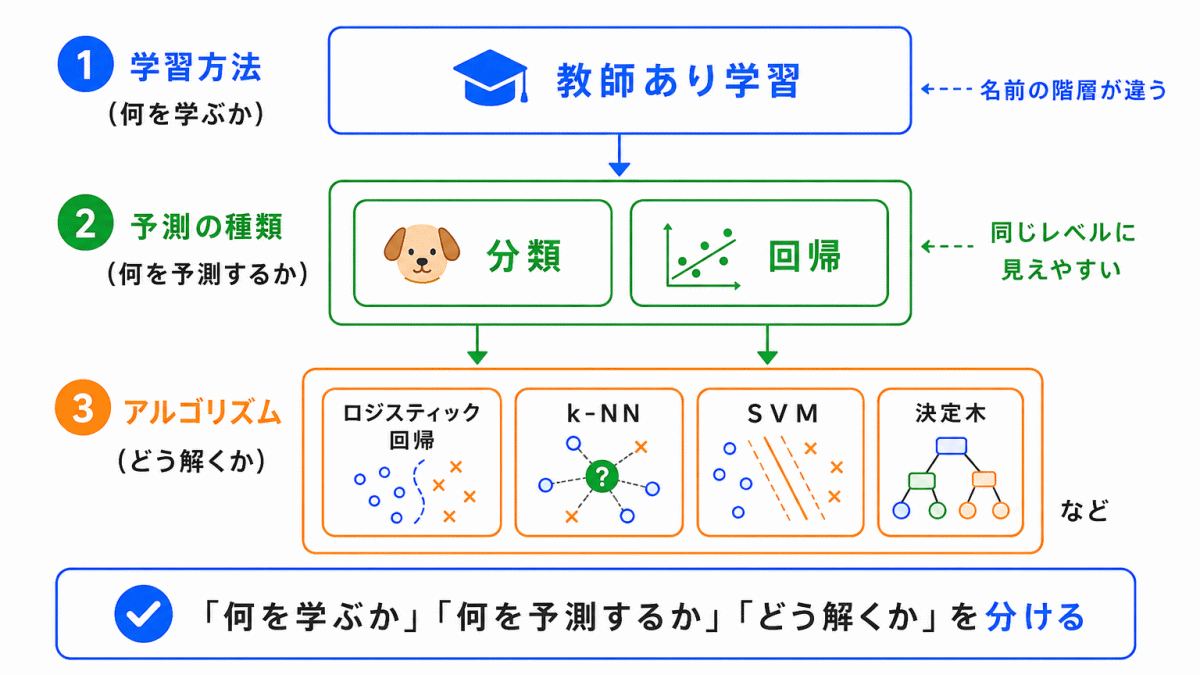
教師あり学習のアルゴリズムは、名前だけを見ると混同しやすいです。
理由は、次の3つが頭の中で混ざりやすいからです。
| 混同しやすいもの | 例 |
|---|---|
| 学習方法 | 教師あり学習 |
| 問題の種類 | 分類・回帰 |
| 具体的な方法 | SVM・決定木・ランダムフォレスト |
たとえば、分類は「問題の種類」です。
SVMや決定木は、その分類問題を解くための「方法」です。
この階層を分けて考えると、混同しにくくなります。
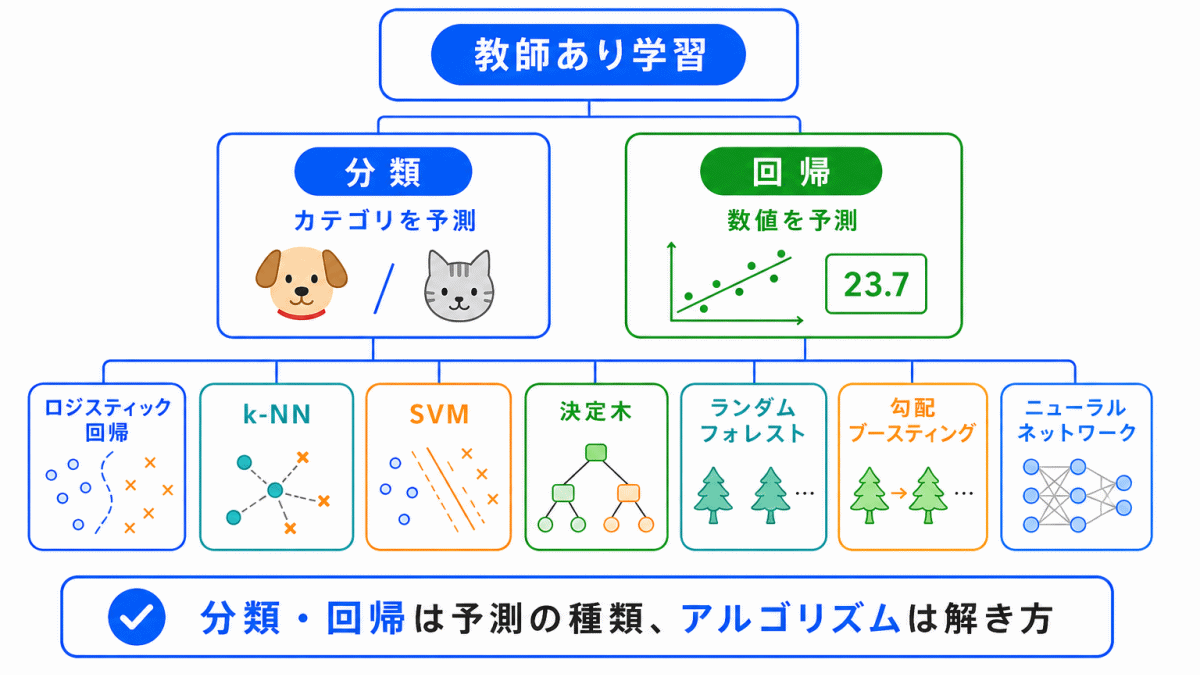
教師あり学習では、正解データを使って分類や回帰を行います。
その分類や回帰を解くための具体的な方法として、ロジスティック回帰、k-NN、SVM、決定木、ランダムフォレスト、勾配ブースティング、ニューラルネットワークなどがあります。
G検定では、細かい数式よりも、それぞれのアルゴリズムがどのような考え方なのか、どの用語と関係するのかを整理しておくことが大切です。
教師あり学習の代表的なアルゴリズムを整理したら、教師あり学習と教師なし学習の違い、アンサンブル学習、過学習、評価指標との関係もあわせて確認しておくと理解しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 教師あり学習と教師なし学習とは? | 教師あり学習/教師なし学習/分類・回帰・クラスタリング |
| アンサンブル学習とは? | 複数モデルの組み合わせ/ランダムフォレスト/ブースティング |
| 過学習とは? | 学習データへの合わせすぎ/汎化性能/過学習対策 |
| 評価指標の使い分け方とは? | 精度/適合率/再現率/F1値の使い分け |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。