【G検定対策】生成AIリスクまとめ|ハルシネーション・著作権・個人情報・バイアス・ディープフェイクを整理
seo-webmaster
SEO・ウェブマスターブログ
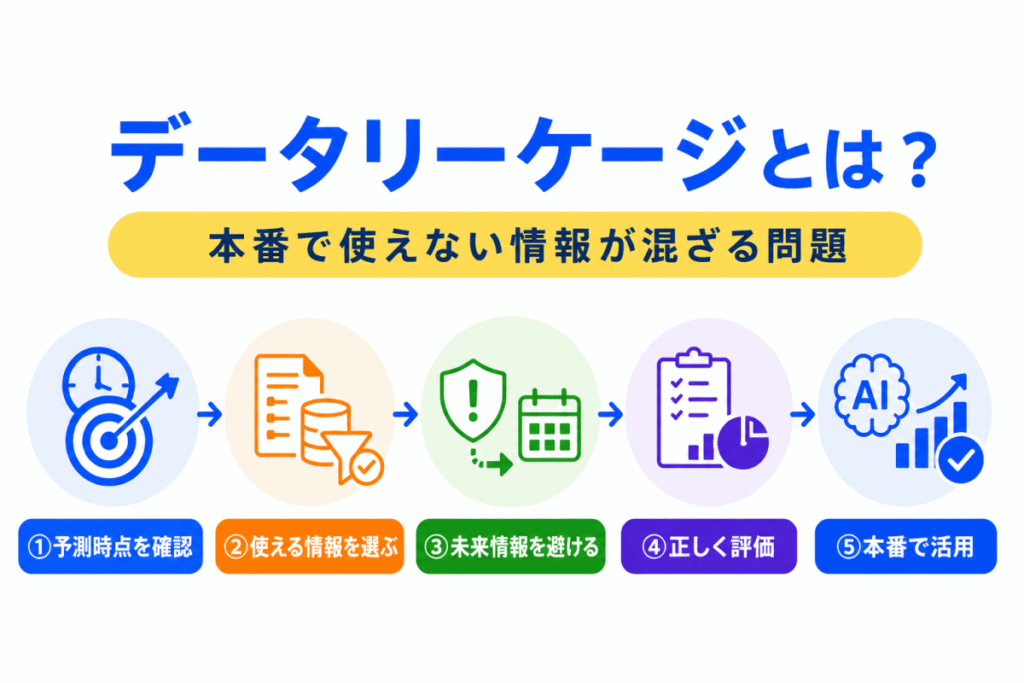
公式テキストでは「データリーク」と記載されていますが、G検定シラバスでは「データリーケージ」とあるのでここでは「データリーケージ」とします。
AIモデルの評価がとても高いと、一見するとよいモデルに見えます。
しかし、その高い評価が「本番では使えない情報」を見てしまった結果だった場合、実際に使う場面ではうまく予測できません。
このように、学習や評価の段階で、本来は予測時に使えない情報が混ざってしまう問題をデータリーケージといいます。
この記事では、データリーケージの意味、特徴量設計との関係、過学習・汎化性能・交差検証とのつながりを、G検定対策としてわかりやすく整理します。
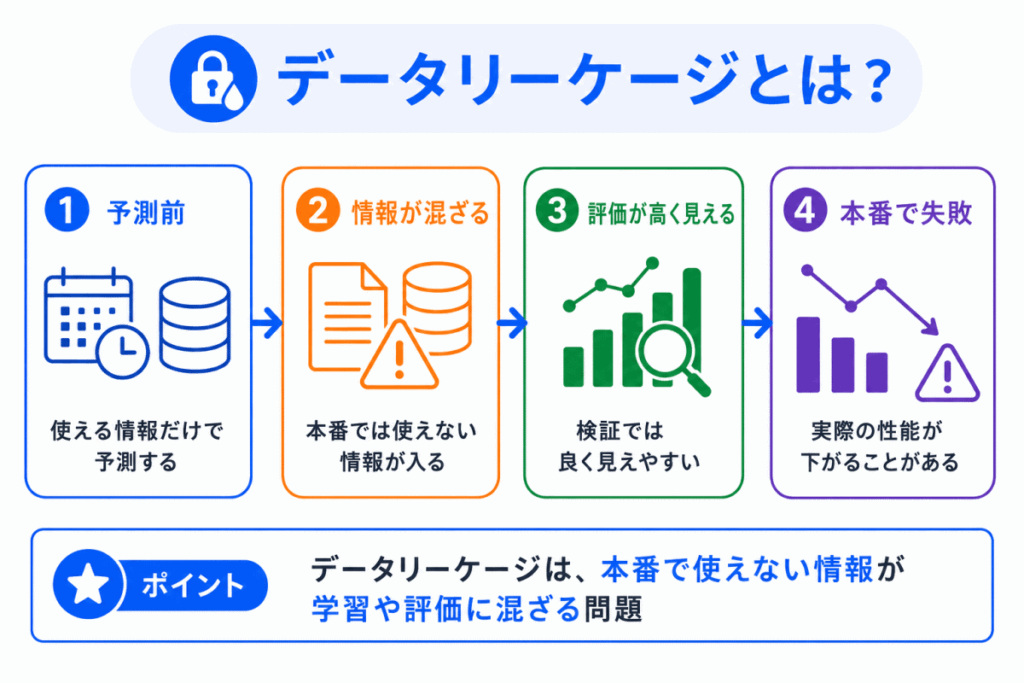
データリーケージとは、AIモデルの学習や評価のときに、本来は予測時点で使えない情報がデータに混ざってしまう問題 です。
たとえば、ある人が商品を購入するかを予測したいのに、購入後にしかわからない情報を特徴量に入れてしまうと、モデルは現実には使えない情報を見て学習してしまいます。
その結果、検証データでは高い精度に見えても、本番では同じ情報が使えないため、予測性能が大きく下がることがあります。
ここで注意したいのは、データリーケージは「個人情報の漏えい」とは少し意味が違うという点です。
G検定で出てくるデータリーケージは、主に 機械学習の評価が不自然に高く見えてしまう原因 として理解するとわかりやすいです。
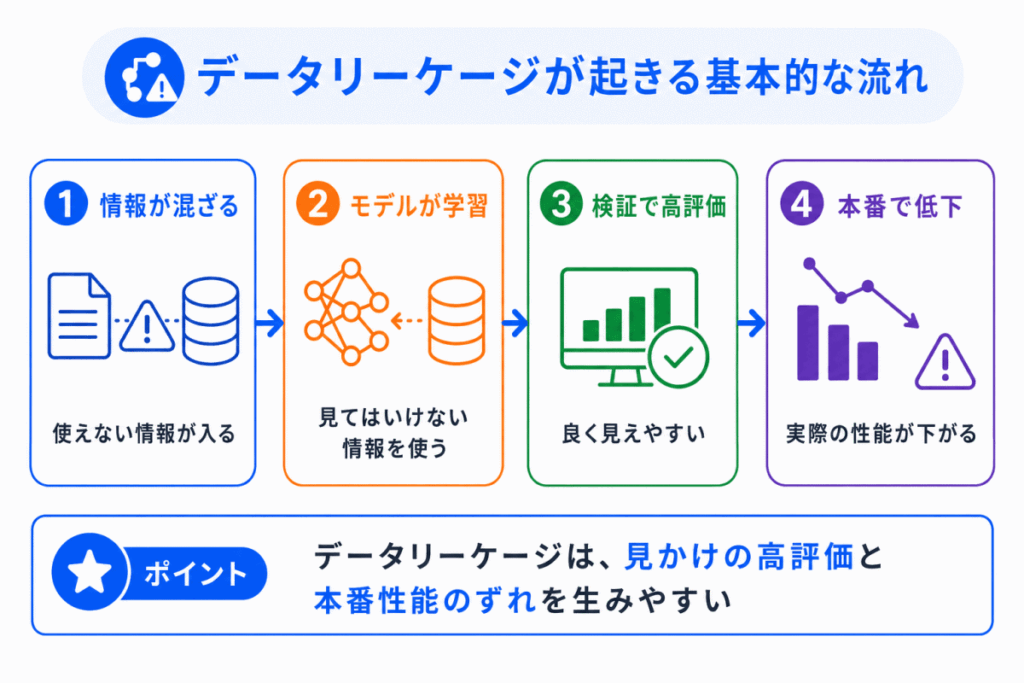
データリーケージが起きると、モデルは本来知らないはずの情報を使って学習してしまいます。
その流れは、次のように整理できます。
| 流れ | 起きていること | 問題点 |
|---|---|---|
| 予測時には使えない情報が混ざる | 未来の情報や正解に近い情報が、学習データや特徴量に入ってしまう | 本番では同じ条件で予測できない |
| モデルがその情報を手がかりに学習する | AIモデルが、本来見てはいけない情報を使ってパターンを学習する | 実力ではなく、漏れた情報に頼った予測になる |
| 検証では高性能に見える | 検証データでも高い精度やF1値が出ることがある | モデルの性能が実際より高く見える |
| 本番では同じ情報が使えない | 実際の運用時には、学習時に使った情報を取得できない | 検証時と本番時の条件がずれる |
| 実際の予測性能が下がる | 本番環境では、検証時ほど正しく予測できなくなる | AI導入後の失敗につながることがある |
ポイントは、検証時の評価が高いこと自体が危険なのではなく、その評価が正しい条件で測れているかです。
データリーケージがあると、モデルの実力以上に評価が高く見えてしまいます。
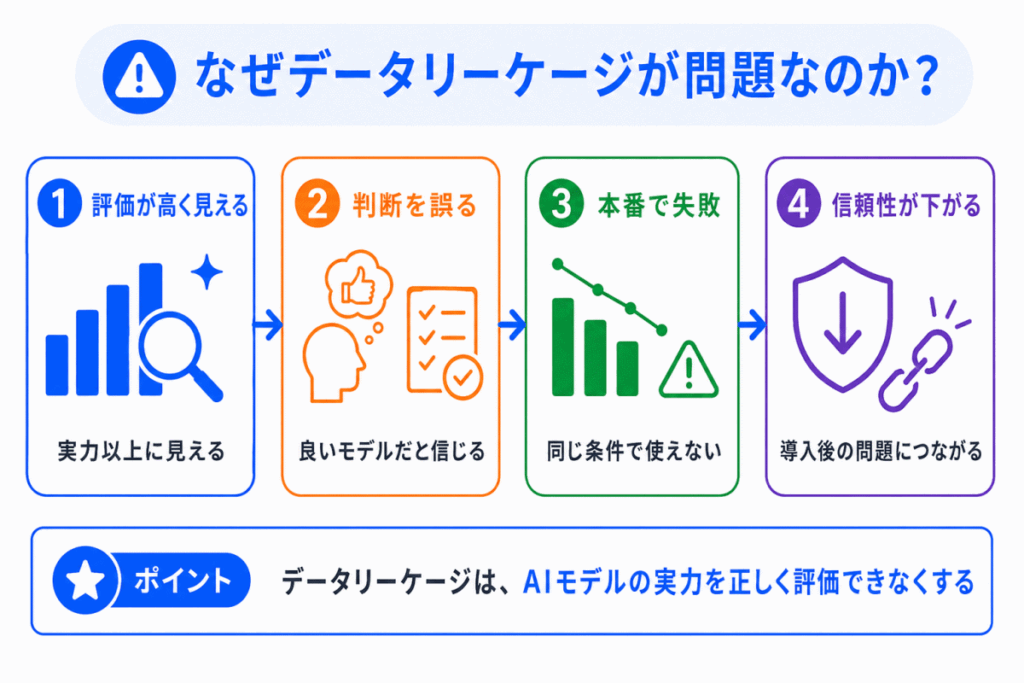
データリーケージが問題なのは、AIモデルの性能を正しく評価できなくなるからです。
通常、AIモデルは学習データで学習し、検証データやテストデータで性能を確認します。
しかし、そこに未来の情報や正解に近すぎる情報が混ざると、モデルは簡単に答えを当てられるように見えてしまいます。
その結果、次のような問題が起きます。
つまり、データリーケージは単なるデータのミスではなく、AIモデルの信頼性を大きく下げる問題 です。
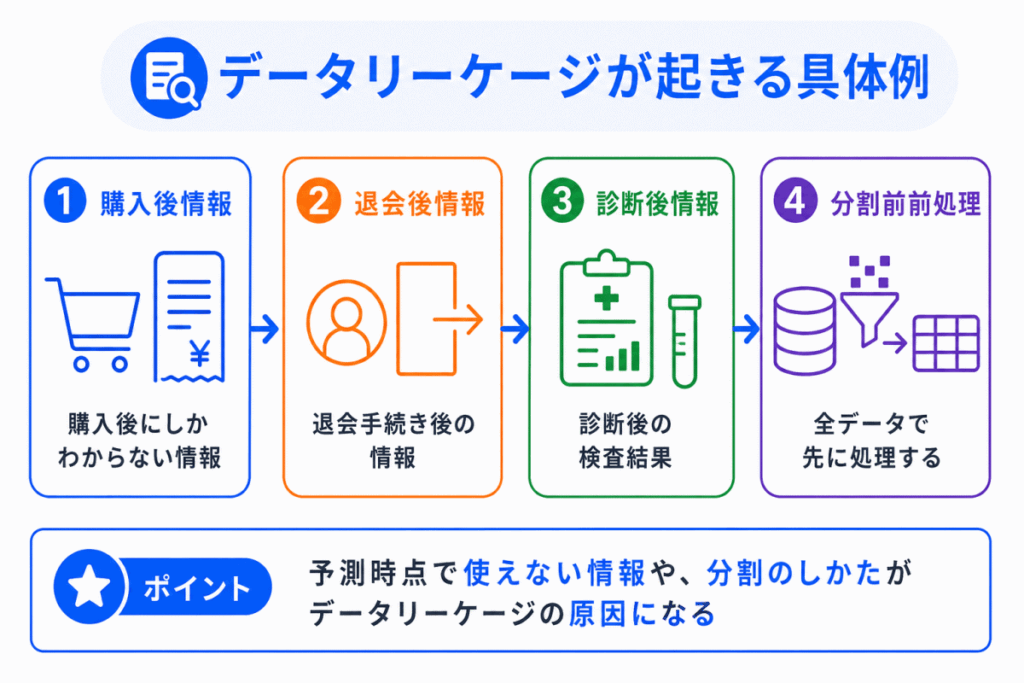
データリーケージは、特徴量を作るときや、学習データと検証データを分けるときに起きやすいです。
代表的な例を整理すると、次のようになります。
| 例 | 問題点 | なぜ危険か |
|---|---|---|
| 購入予測に購入後の情報を使う | 予測時点ではまだわからない情報を使っている | 本番では同じ特徴量を使えない |
| 退会予測に退会手続き後の情報を使う | 正解に近すぎる情報が混ざっている | モデルが実質的に答えを見てしまう |
| 病気の予測に診断後の検査結果を使う | 予測したい時点より後の情報を使っている | 実際の早期予測には使えない |
| 全データで前処理してから分割する | 検証データの情報が学習側に混ざることがある | 評価が実力より高く見える |
特に重要なのは、その情報が予測したい時点で本当に使えるかです。
予測時点で使えない情報を特徴量に入れると、データリーケージにつながります。
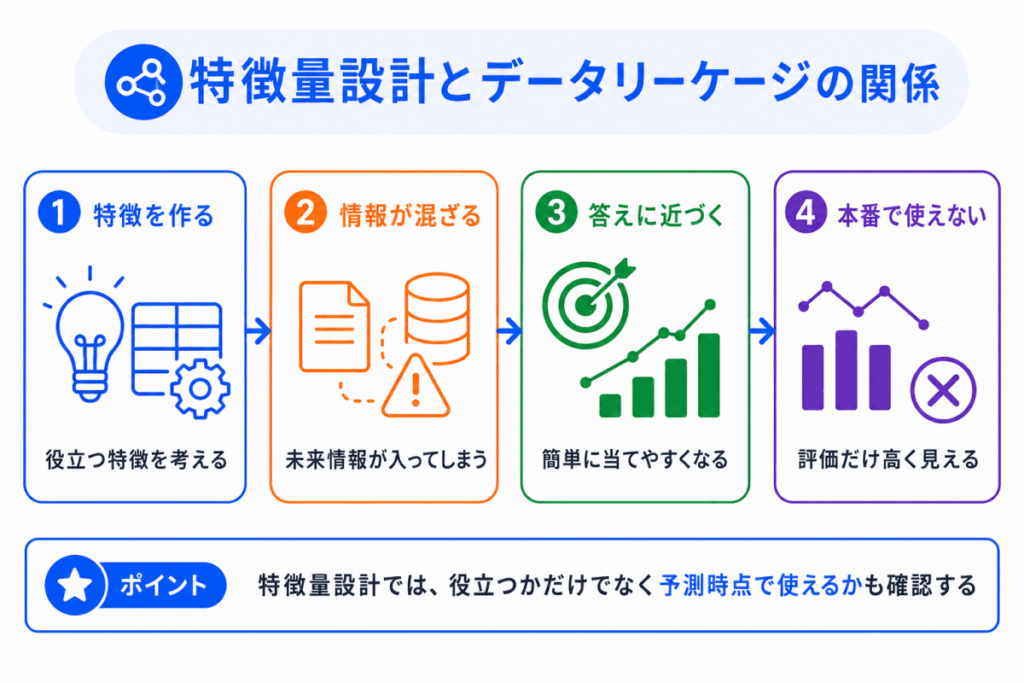
データリーケージは、特徴量設計と強く関係します。
特徴量設計は、AIが学習しやすい特徴を作る作業です。
しかし、作った特徴量の中に未来の情報や正解に近すぎる情報が含まれていると、モデルは現実には使えない情報を手がかりにしてしまいます。
関係を流れで見ると、次のようになります。
つまり、特徴量設計では「役に立つ特徴を作る」だけでなく、予測時点で使ってよい特徴量かを確認することが大切です。
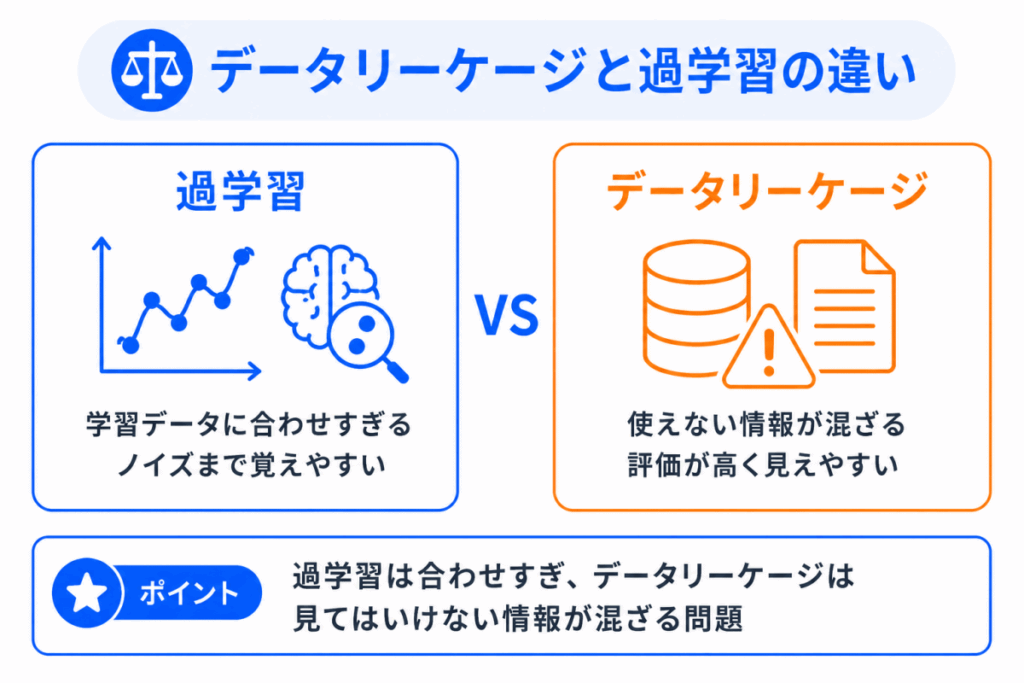
データリーケージと過学習は、どちらも「検証や本番で問題になる」ため混同しやすい用語です。
ただし、原因は少し違います。
過学習は、学習データに合わせすぎて未知のデータに弱くなる問題です。
一方、データリーケージは、モデルが本来見てはいけない情報を見てしまう問題です。
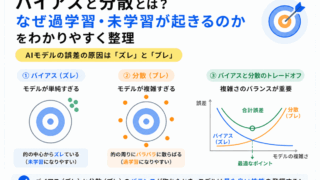
どちらも汎化性能を下げる原因になりますが、G検定では次のように見分けると整理しやすいです。
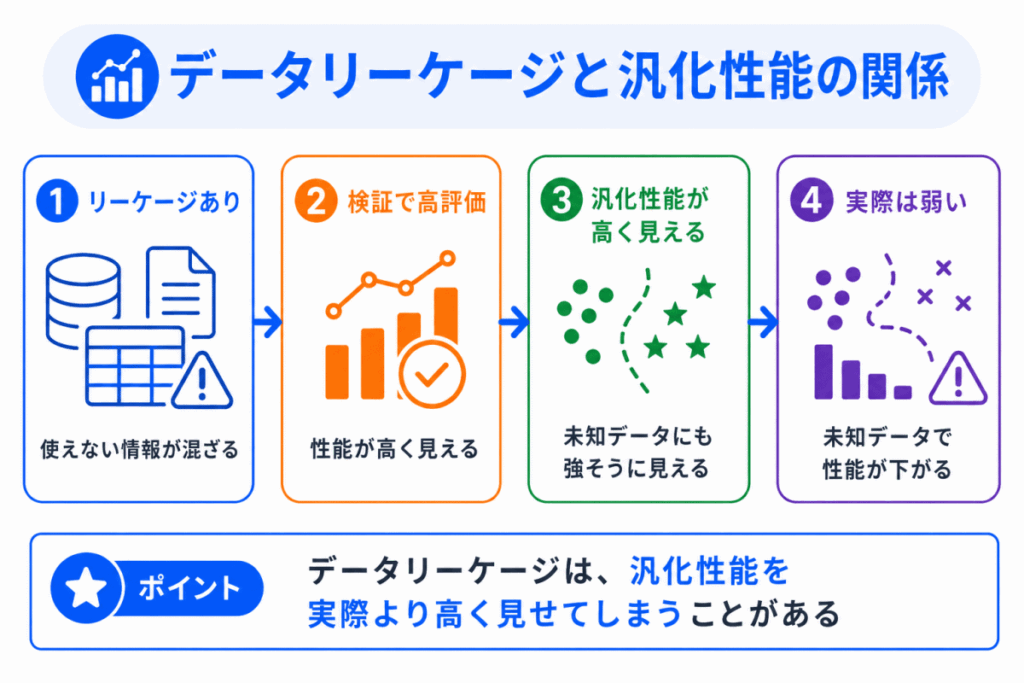
汎化性能とは、学習に使っていない未知のデータに対して、どれだけうまく予測できるかを表す考え方です。
データリーケージがあると、検証データでは高い評価が出ることがあります。
しかし、その評価は本番環境に近い条件で測れていないため、実際の汎化性能を正しく表していない可能性があります。
つまり、データリーケージは、汎化性能を高く見せてしまう問題ともいえます。
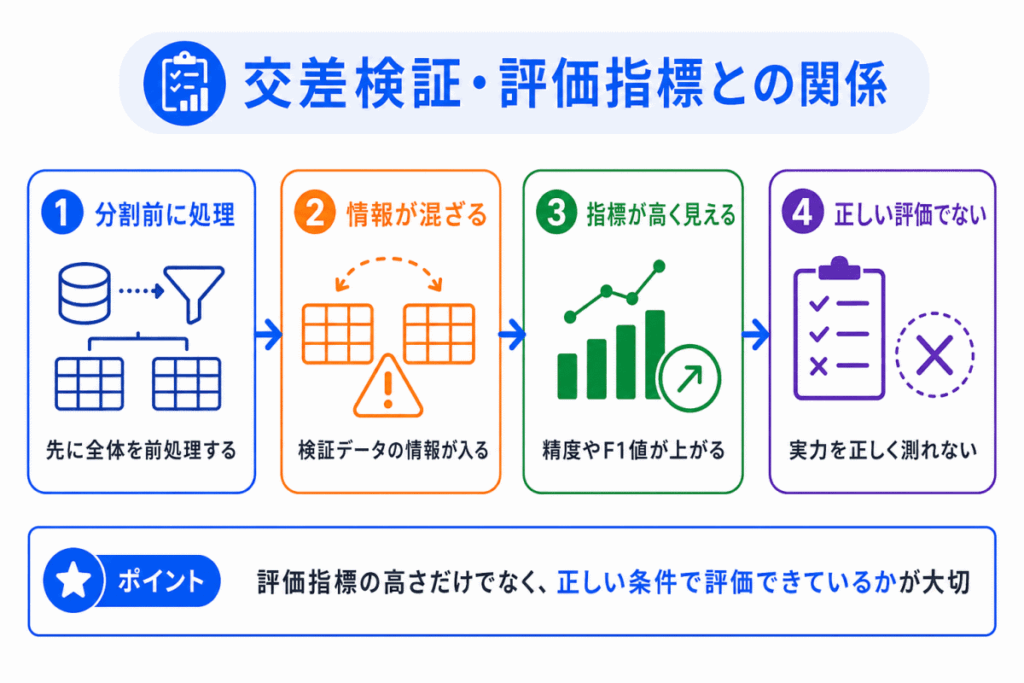
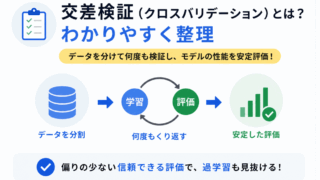
交差検証や評価指標は、モデルの性能を確認するために使います。
しかし、データリーケージがある状態で交差検証をしても、正しい評価にはなりません。
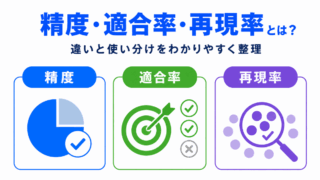
また、精度、適合率、再現率、F1値などの評価指標が高くても、その値が信頼できるとは限りません。
関係を整理すると、次のようになります。
| 観点 | 注意点 |
|---|---|
| 交差検証 | 分割前の処理で検証データの情報が混ざると、評価が高く見えることがある |
| 評価指標 | データリーケージがあると、精度やF1値などが実力以上に高く見えることがある |
| 本番運用 | 本番で取得できない情報を使って評価していると、導入後に性能が下がる |
評価指標を見るときは、数値の高さだけでなく、その評価が正しい条件で行われているかを確認する必要があります。
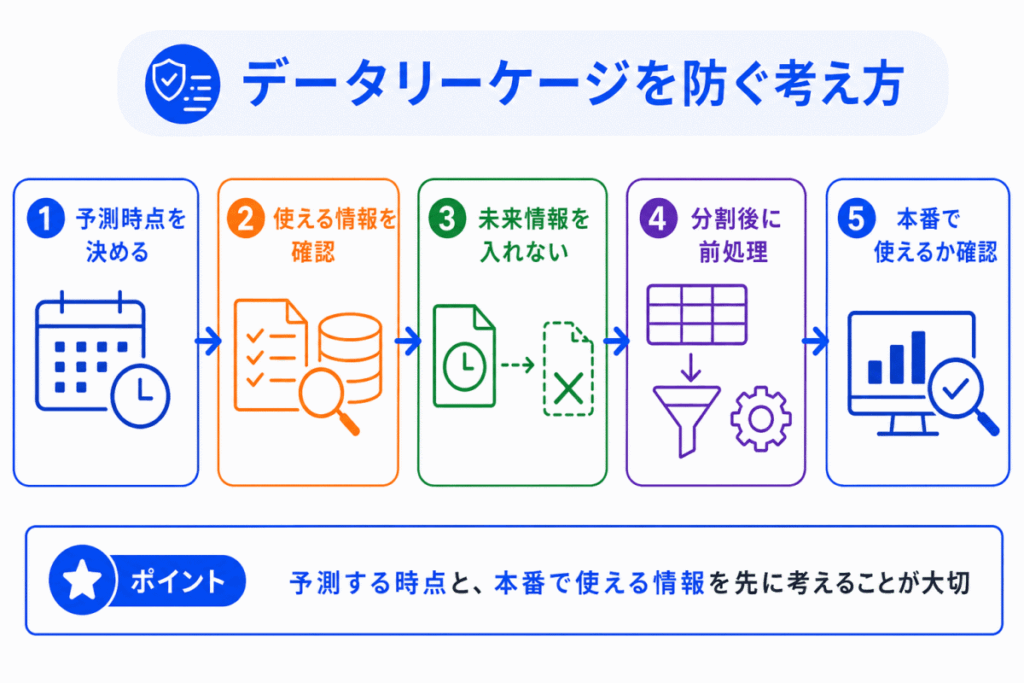
データリーケージを防ぐには、予測したい時点をはっきりさせることが大切です。
「いつ予測するのか」、「その時点で何の情報が使えるのか」を確認してから、特徴量を作る必要があります。
主な考え方は、次のように整理できます。
| 考え方 | 内容 |
|---|---|
| 予測時点を決める | どの時点で予測するのかを先に明確にする |
| 未来の情報を入れない | 予測時点より後にしかわからない情報を特徴量にしない |
| 正解に近すぎる情報を避ける | 目的変数を直接示すような情報を特徴量に入れない |
| 分割後に前処理する | 学習データと検証データを分けた後に、必要な前処理を行う |
| 本番で使えるか確認する | 作った特徴量が実際の運用時にも取得できるか確認する |
特に、特徴量設計では「この特徴量は役に立ちそうか」だけでなく、本番で使える情報かをセットで考えることが重要です。
G検定では、データリーケージそのものの細かい実装よりも、意味や起きる原因を理解しているかが問われやすいです。
整理すると、次のようになります。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 意味 | 本来予測時に使えない情報が、学習や評価に混ざる問題 |
| 特徴量設計との関係 | 未来の情報や正解に近い情報を特徴量にすると起きやすい |
| 評価への影響 | 検証では高性能に見えても、本番では性能が下がることがある |
| 過学習との違い | 過学習は学習データに合わせすぎる問題、データリーケージは見てはいけない情報が混ざる問題 |
| 防ぎ方 | 予測時点で使える情報だけを特徴量にする |
G検定対策では、次の一文で覚えると整理しやすいです。
データリーケージは、AIモデルの評価を正しく見るうえで重要な考え方です。
特徴量設計では、AIが学習しやすい特徴を作ることが大切ですが、本番で使えない情報を入れてしまうと、モデルの評価が実力以上に高く見えてしまいます。
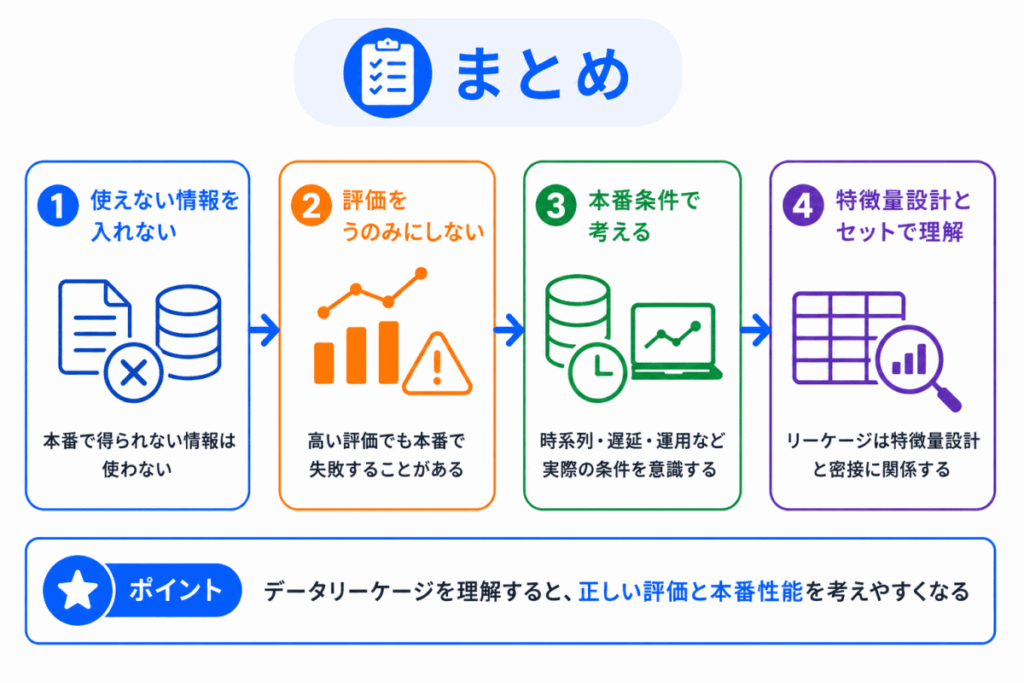
最後に、重要ポイントを整理します。
| 項目 | ポイント |
|---|---|
| データリーケージ | 予測時に使えない情報が学習や評価に混ざる問題 |
| 起きやすい場面 | 特徴量設計、前処理、データ分割、交差検証 |
| 問題点 | 検証では高性能に見えても、本番で性能が下がることがある |
| 過学習との違い | 過学習は学習データに合わせすぎる問題、データリーケージは見てはいけない情報が混ざる問題 |
| 防ぐ考え方 | 予測時点で使える情報だけを特徴量にする |
データリーケージを理解すると、特徴量設計、交差検証、評価指標、本番運用のつながりが見えやすくなります。
G検定では、単に「評価が高いモデルがよい」と考えるのではなく、その評価が正しい条件で測られているか まで意識しておくことが大切です。
特徴量設計とデータリーケージは、セットで理解するとAI開発の失敗を防ぎやすくなります。

データリーケージを防ぐには、前処理のタイミングや目的を理解しておくことが大切です。
データそのものに問題があると、AIの評価や本番性能にも影響します。

データリーケージと過学習は混同しやすいため、違いを整理しておくと理解しやすくなります。
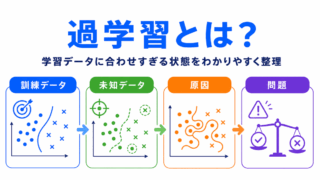
未知データへの強さを理解するには、バイアスと分散の考え方も重要です。
モデルの評価が本当に信頼できるかを考えるには、交差検証の理解が役立ちます。
評価指標の数値が高いだけで判断しないために、精度・適合率・再現率の違いも確認しておきましょう。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認