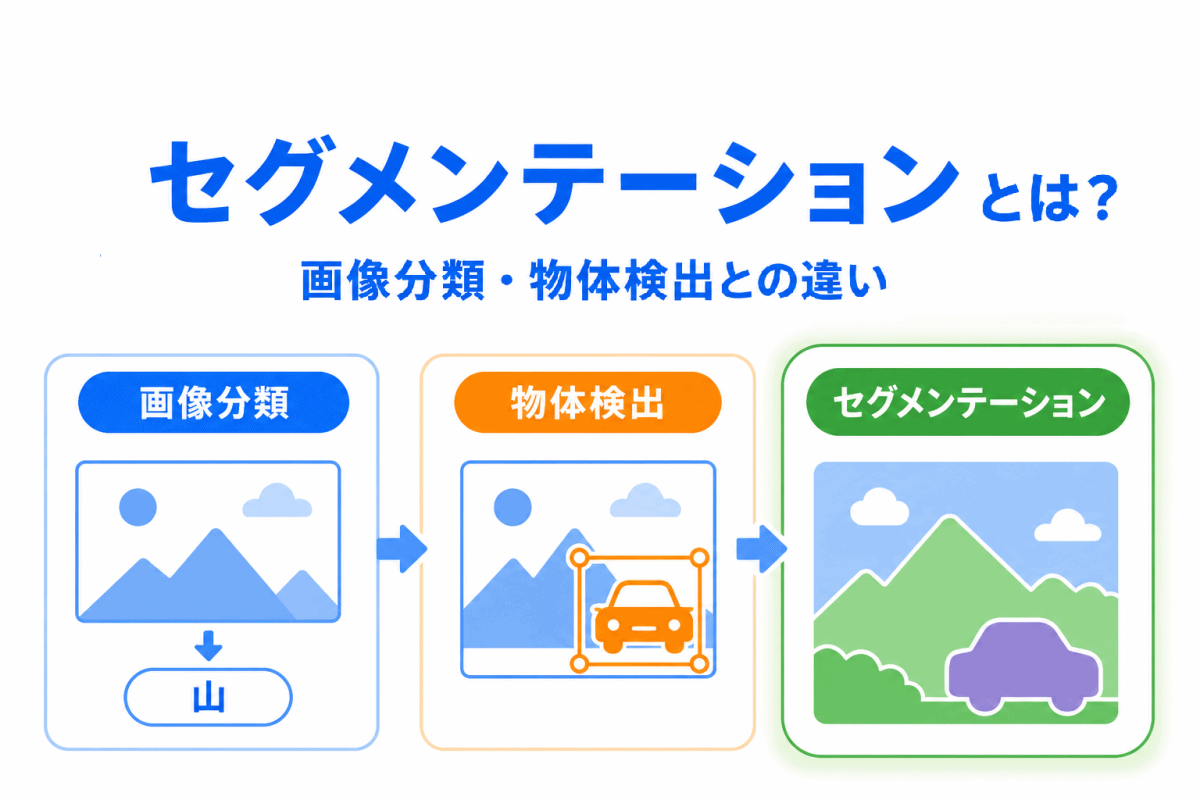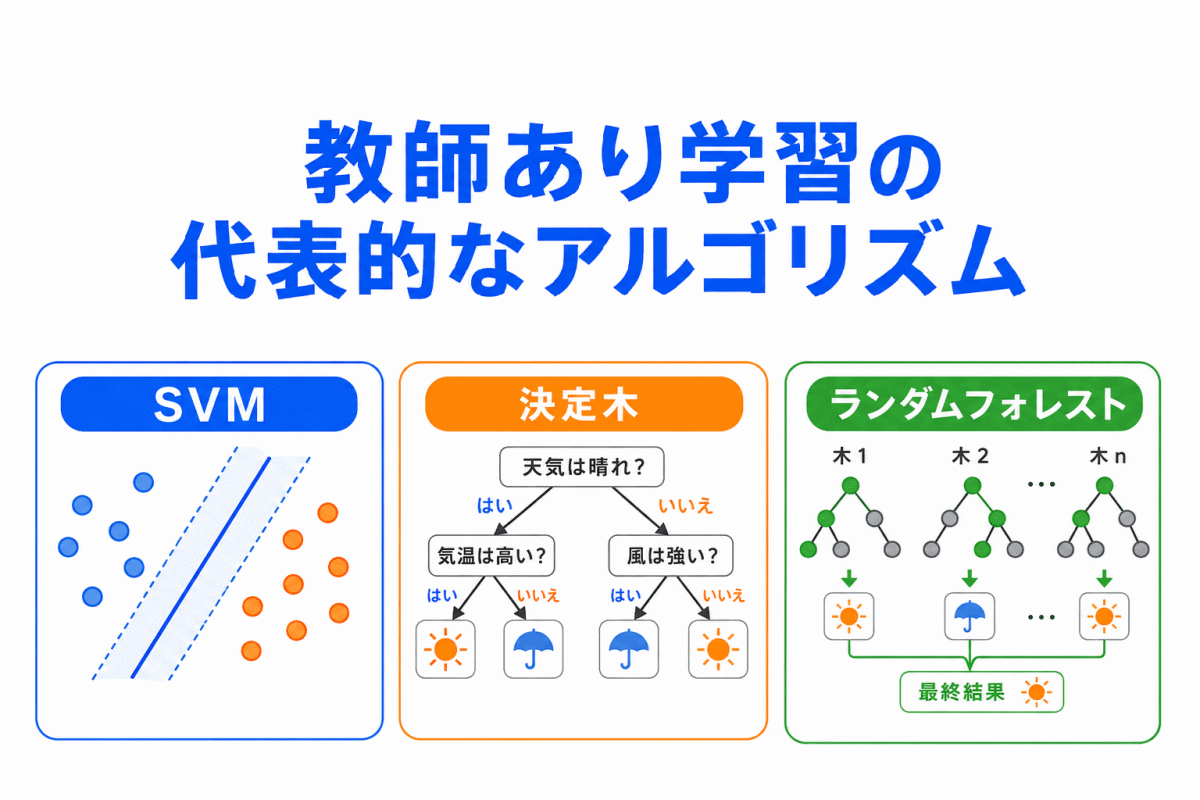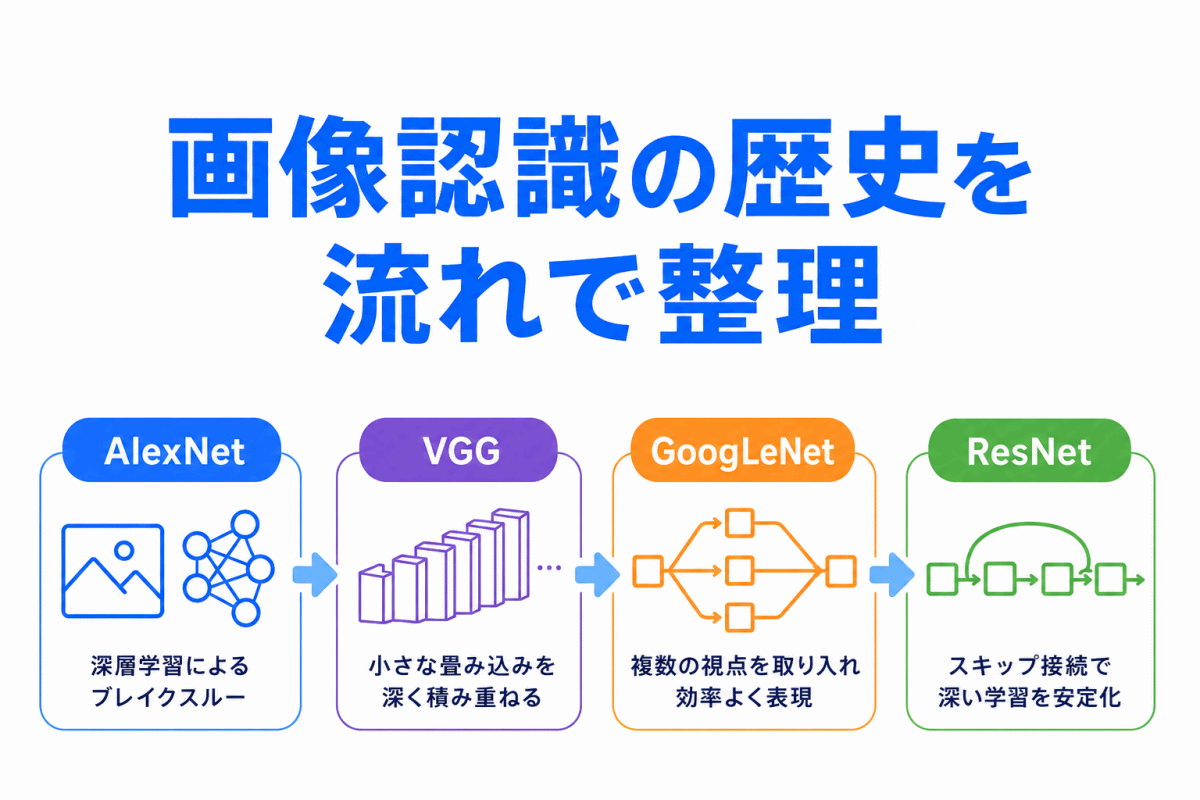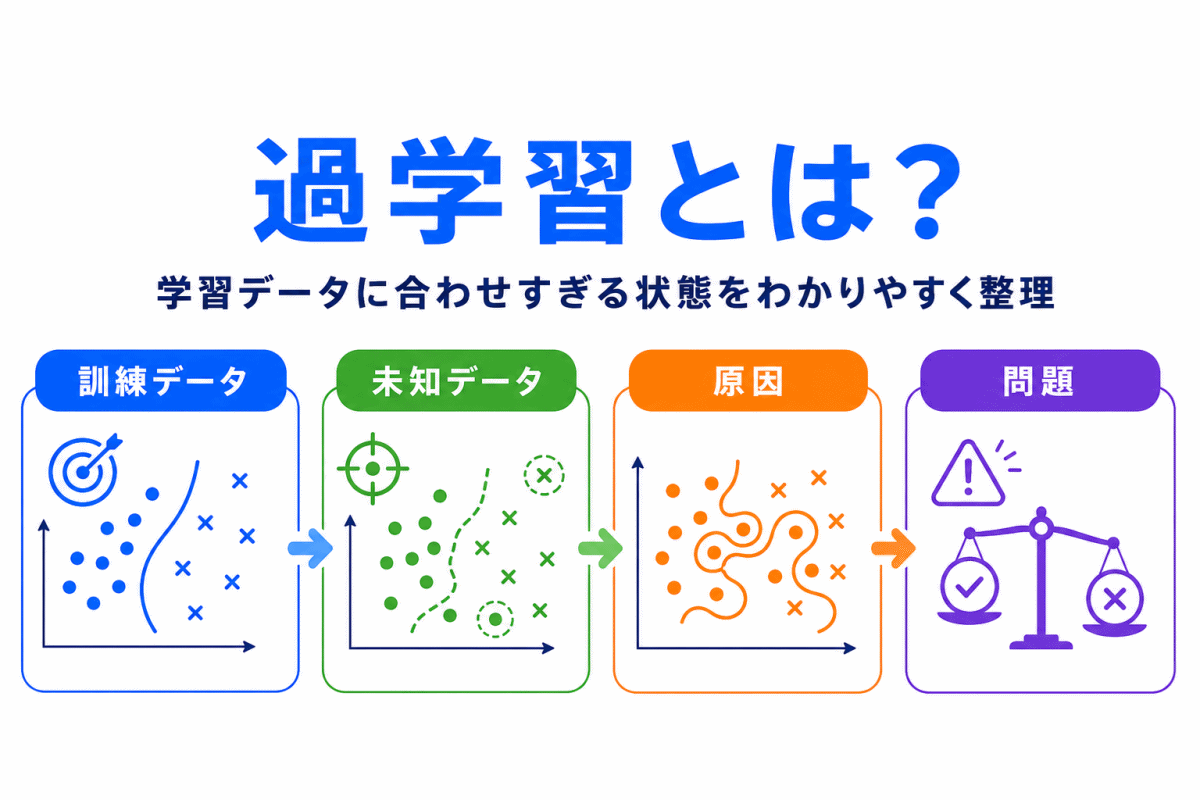
【G検定対策】過学習とは?わかりやすく整理
seo-webmaster
G検定対策ブログ

深層強化学習は、強化学習にディープラーニングを組み合わせた考え方です。
強化学習では、エージェントが環境の中で行動し、その結果として得られる報酬をもとに、よりよい行動を学習します。
ただし、状態や行動の組み合わせが多くなると、表のようにすべてを覚えるのが難しくなります。
そこで、ニューラルネットワークを使って、状態や行動価値を扱えるようにしたものが深層強化学習です。
G検定では、強化学習、Q学習、DQN、AlphaGo、探索との関係を混同しないことが重要です。
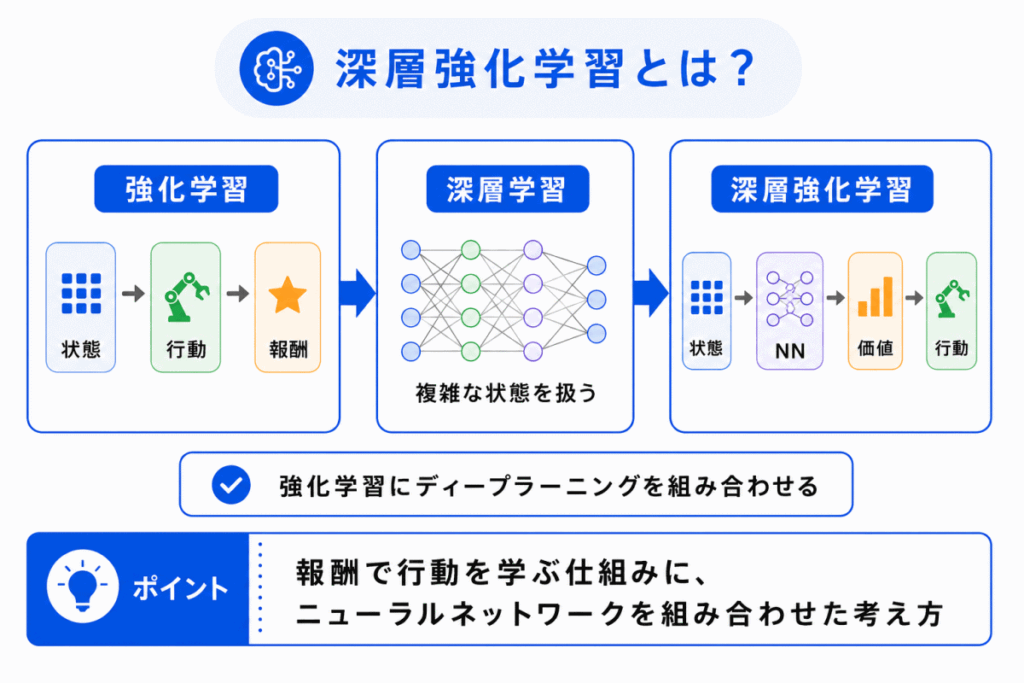
深層強化学習とは、強化学習にディープラーニングを組み合わせた学習方法 です。
強化学習では、AIが環境の中で行動し、報酬をもとに行動を改善します。
深層強化学習では、その判断や価値の推定にニューラルネットワークを使います。
| 用語 | 意味 |
|---|---|
| 強化学習 | 報酬をもとに、よりよい行動を学ぶ考え方 |
| ディープラーニング | ニューラルネットワークを使って特徴やパターンを学ぶ方法 |
| 深層強化学習 | 強化学習にディープラーニングを組み合わせた方法 |
覚え方は、次のようにするとシンプルです。
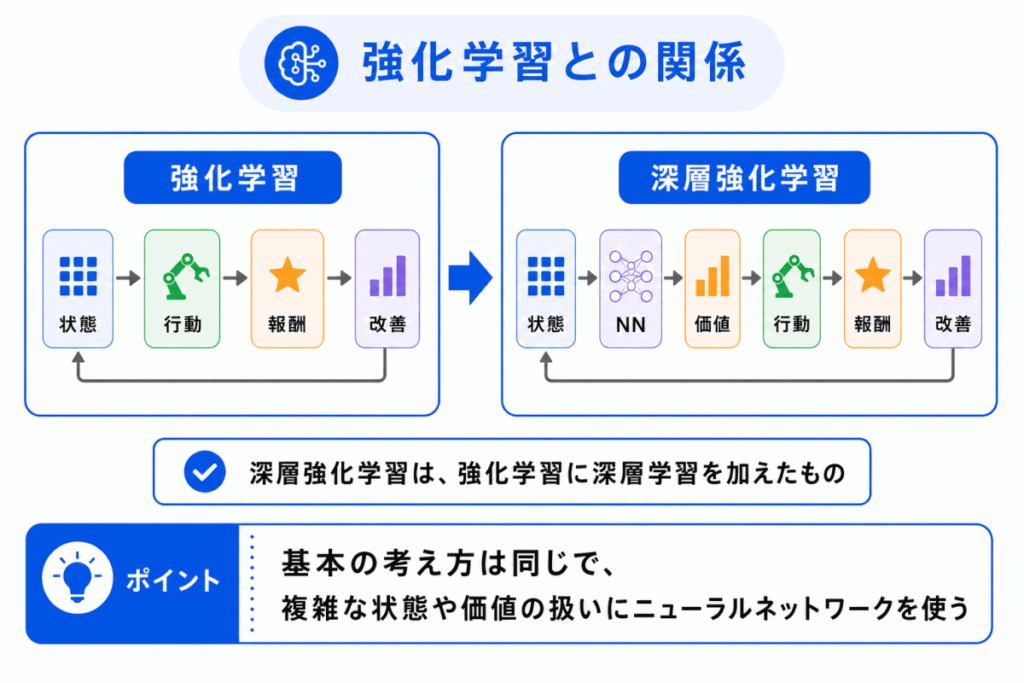
深層強化学習は、強化学習の一種です。
強化学習の基本は、エージェント、環境、状態、行動、報酬の関係で考えます。
深層強化学習でも、この基本構造は同じです。
違いは、状態や行動価値の扱いにニューラルネットワークを使う点です。
| 観点 | 強化学習 | 深層強化学習 |
|---|---|---|
| 基本の考え方 | 報酬をもとに行動を改善する | 報酬をもとに行動を改善する |
| 扱う状態 | 比較的単純な状態を想定しやすい | 画像など複雑な状態も扱いやすい |
| 価値の表し方 | 表や関数で表す | ニューラルネットワークで近似する |
| 代表例 | Q学習 | DQN、AlphaGo |
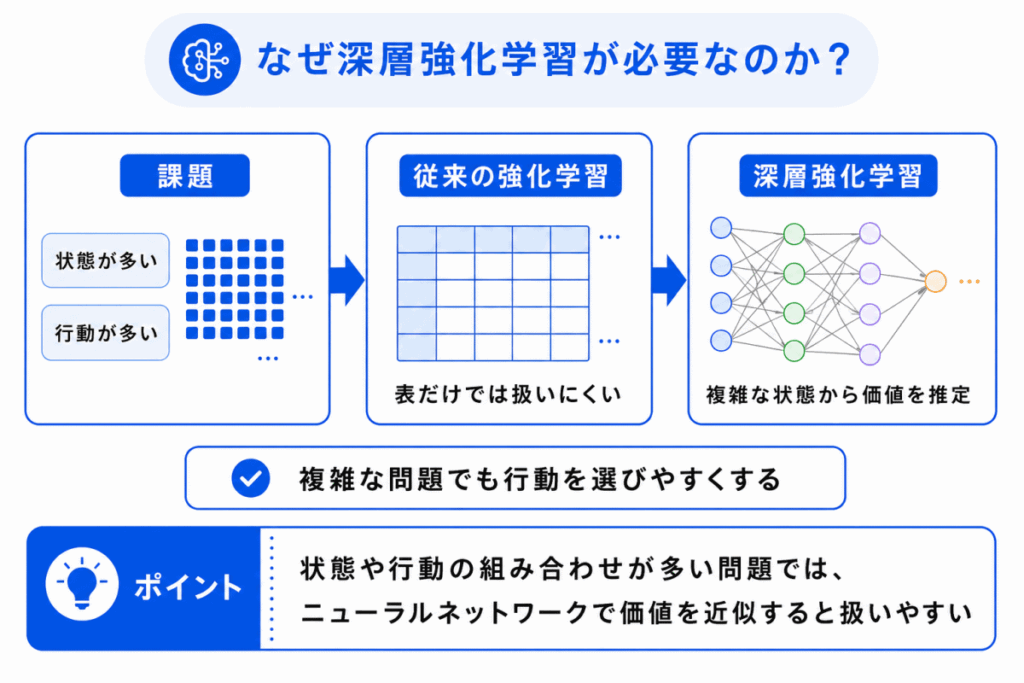
強化学習では、状態と行動の組み合わせごとに、どの行動がよいかを学びます。
しかし、現実の問題では状態の数が非常に多くなります。
たとえば、ゲーム画面、ロボットのセンサー情報、囲碁の盤面などは、単純な表だけで管理するのが難しくなります。
そこで、ニューラルネットワークを使って、複雑な状態から行動の価値を推定します。
つまり、深層強化学習は、強化学習をより複雑な問題に使いやすくするための考え方です。
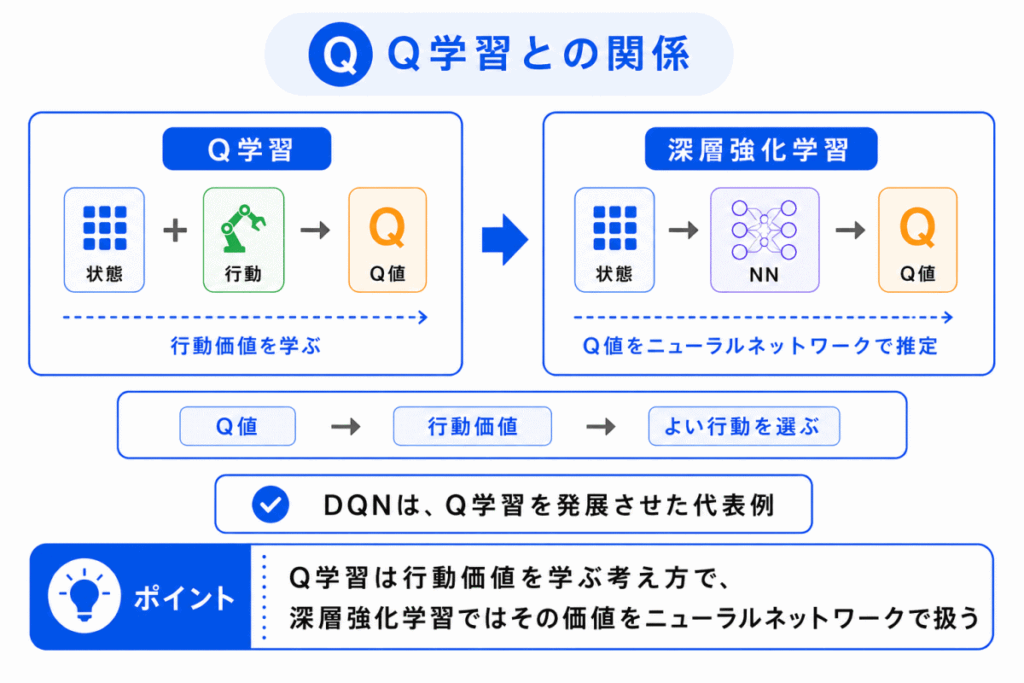
Q学習は、強化学習の代表的な手法です。
Q学習では、ある状態である行動を取ったときに、将来的にどれくらいよい結果が期待できるかを学びます。
この価値を Q値 と呼びます。
| 用語 | 意味 |
|---|---|
| Q値 | ある状態で、ある行動を取る価値 |
| Q学習 | Q値を更新しながら、よい行動を学ぶ方法 |
| DQN | Q学習にニューラルネットワークを組み合わせた方法 |
G検定では、Q学習と DQN の関係を押さえると理解しやすくなります。
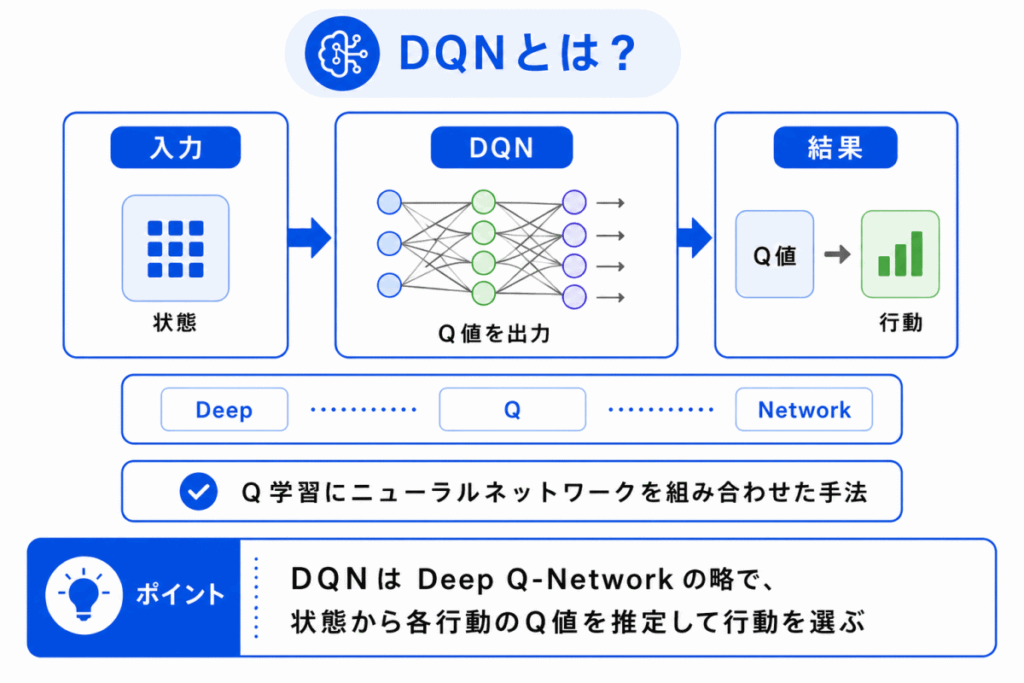
DQN は、Deep Q-Network の略です。
DQN は、Q学習にディープラーニングを組み合わせた代表的な深層強化学習の手法です。
通常のQ学習では、状態と行動の組み合わせごとにQ値を管理します。
DQN では、ニューラルネットワークを使ってQ値を推定します。
DQN のポイントは、Q値をニューラルネットワークで近似することです。
| 項目 | Q学習 | DQN |
|---|---|---|
| 価値の扱い | Q値を表のように扱う | Q値をニューラルネットワークで推定する |
| 得意な問題 | 状態数が少ない問題 | 状態数が多い問題 |
| 関係 | 強化学習の代表例 | 深層強化学習の代表例 |
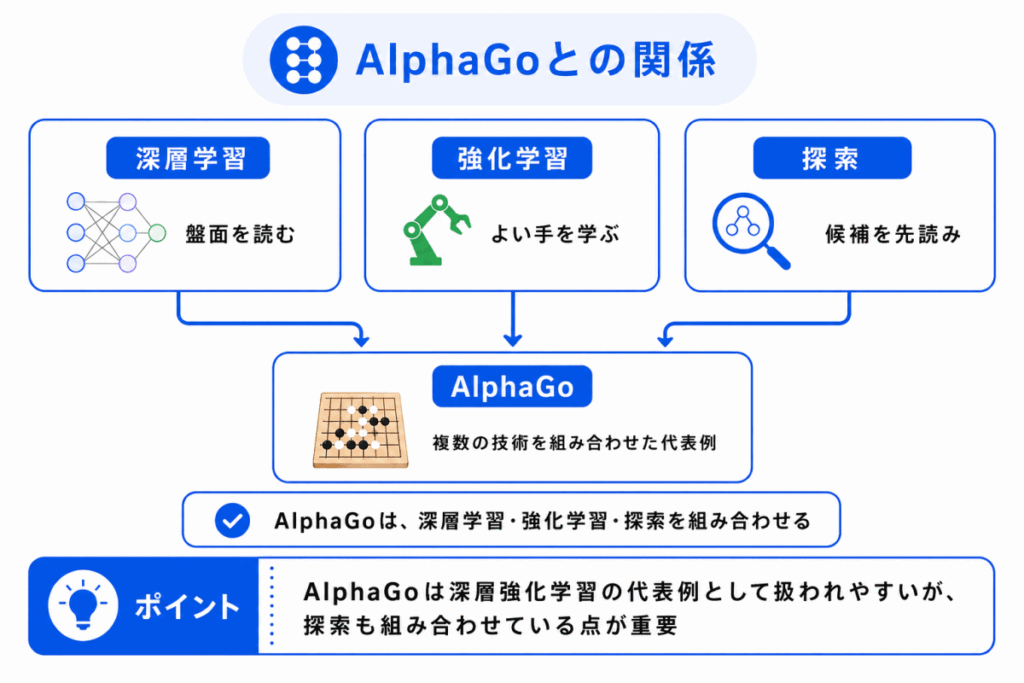
AlphaGoは、深層強化学習の代表例としてよく取り上げられます。
AlphaGoは、囲碁で高い性能を示したAIです。
重要なのは、AlphaGoを単に「深層強化学習だけ」と覚えるのではなく、複数の技術を組み合わせた代表例として理解することです。
| 技術 | AlphaGoとの関係 |
|---|---|
| ディープラーニング | 盤面からよい手や価値を学ぶ |
| 強化学習 | 対局を通じて、よりよい手を学ぶ |
| 探索 | 候補手を先読みして、よい手を選ぶ |
G検定向けには、次のように覚えるとよいです。
「探索手法の違い」で学んだMini-Max法やαβ法とは直接同じものではありませんが、
候補を先読みして、よりよい手を選ぶ という意味では、探索の考え方とつながります。
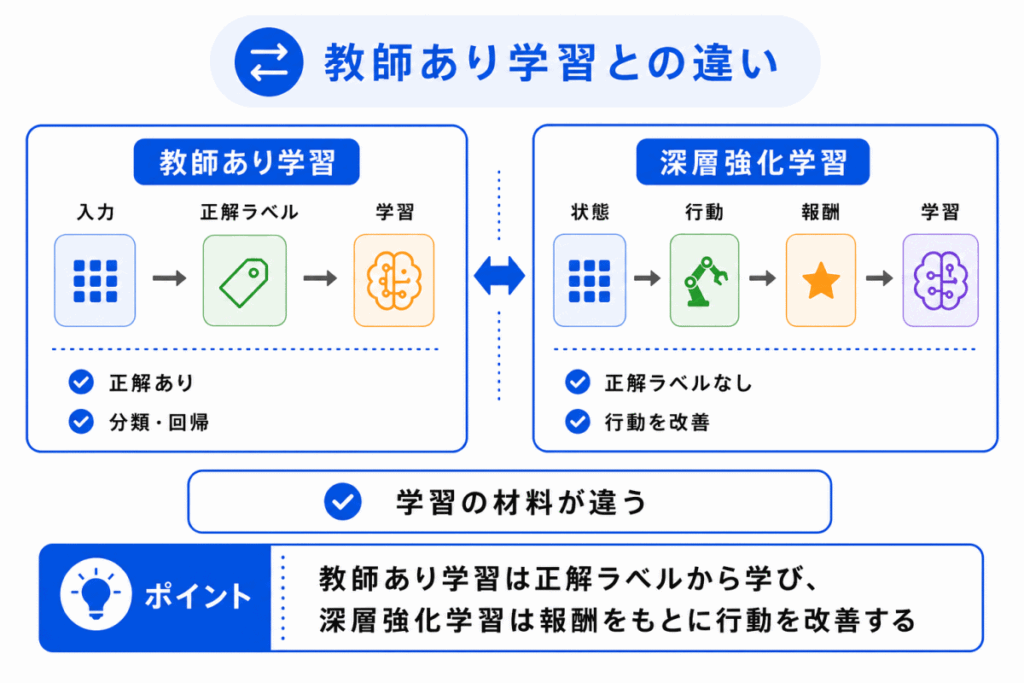
深層強化学習は、教師あり学習とは学習の仕方が違います。
教師あり学習では、入力データと正解ラベルの組み合わせを使って学習します。
一方、強化学習では、各行動に対してすぐに正解が与えられるとは限りません。
行動の結果として得られる報酬をもとに、よい行動を学んでいきます。
| 観点 | 教師あり学習 | 深層強化学習 |
|---|---|---|
| 学習の材料 | 入力データと正解ラベル | 状態、行動、報酬 |
| 正解 | あらかじめ与えられる | 報酬を通じて間接的に学ぶ |
| 目的 | 正解に近い予測をする | 将来の報酬が大きくなる行動を選ぶ |
| 例 | 画像分類、スパム判定 | ゲームAI、ロボット制御、囲碁AI |
ここで大事なのは、深層強化学習は「正解ラベルを覚える学習」ではないという点です。
行動した結果をもとに、よい行動を見つけていく学習です。
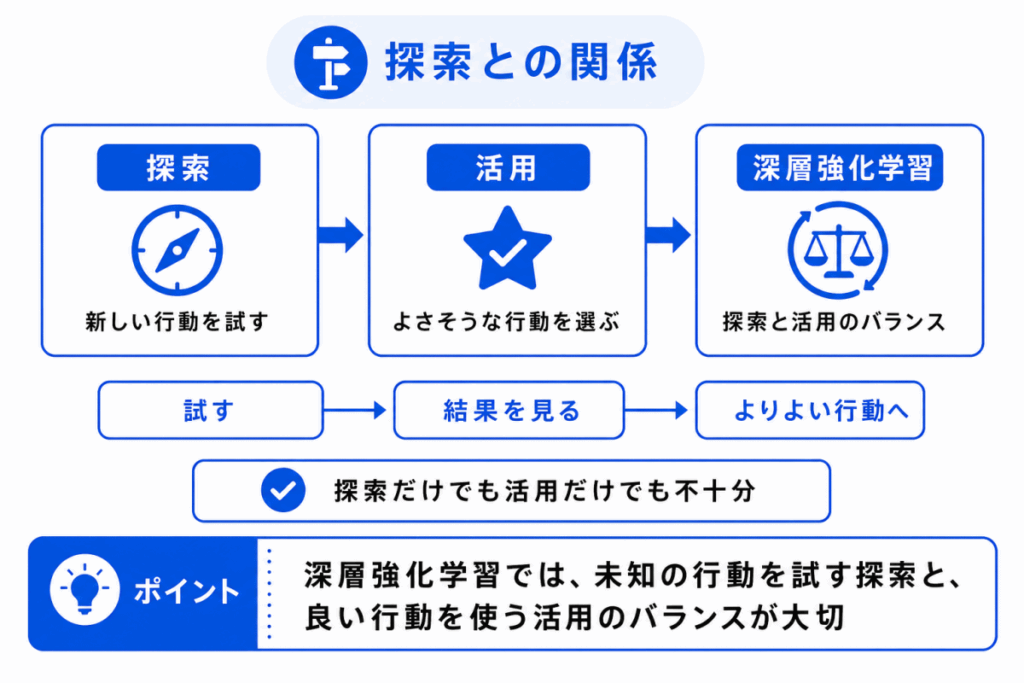
深層強化学習は、探索とも関係します。
強化学習では、すでに良さそうだとわかっている行動を選ぶだけでは、もっとよい行動を見つけられない可能性があります。
一方で、試しすぎると、報酬が低い行動ばかり選んでしまう可能性もあります。
このバランスが、探索と活用です。
| 用語 | 意味 |
|---|---|
| 探索 | まだ十分に試していない行動を試すこと |
| 活用 | これまでの経験から良さそうな行動を選ぶこと |
| 探索と活用のバランス | 新しい行動を試すことと、良い行動を使うことのバランス |
G検定では、探索手法そのものと深層強化学習を完全に同一視しないことが大切です。
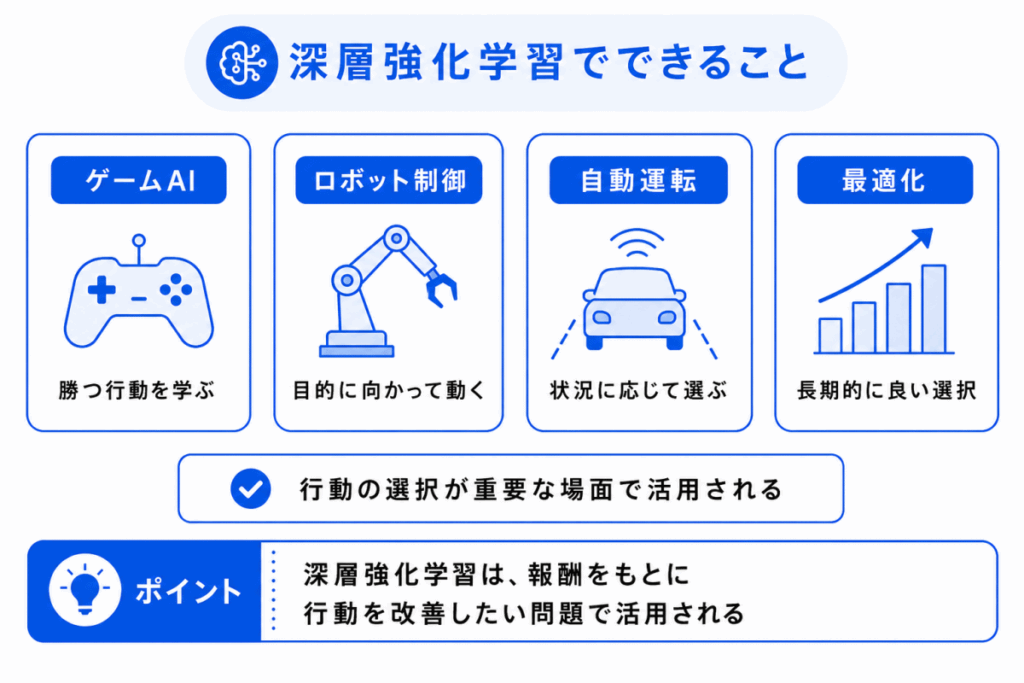
深層強化学習は、行動の選択が重要な問題で使われます。
代表例としては、ゲームAI、ロボット制御、自動運転、推薦、最適化などがあります。
| 活用例 | 何を学ぶか |
|---|---|
| ゲームAI | 勝つためにどの行動を選ぶか |
| ロボット制御 | 目的を達成するためにどう動くか |
| 自動運転 | 状況に応じてどの操作を選ぶか |
| 推薦や最適化 | 長期的に良い結果につながる選択をどう行うか |
ただし、G検定対策では、応用例を細かく暗記するよりも、
報酬をもとに行動を改善する強化学習に、ニューラルネットワークを組み合わせたもの と理解する方が重要です。
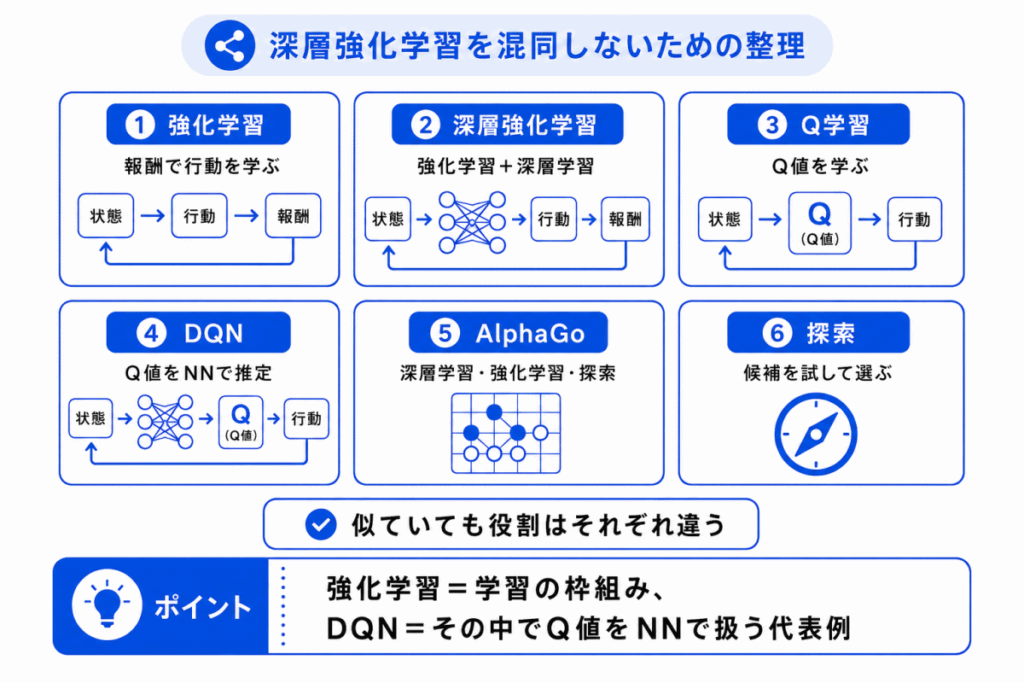
深層強化学習は、周辺用語と混同しやすいです。
特に、「強化学習」、「Q学習」、「DQN」、「AlphaGo」、「探索」はセットで整理しておきましょう。
| 用語 | 一言でいうと | 混同しないポイント |
|---|---|---|
| 強化学習 | 報酬で行動を学ぶ | 学習の基本枠組み |
| 深層強化学習 | 強化学習に深層学習を組み合わせる | 状態や価値をニューラルネットワークで扱う |
| Q学習 | 行動価値を学ぶ | Q値を更新して行動を選ぶ |
| DQN | Q学習にニューラルネットワークを使う | 深層強化学習の代表例 |
| AlphaGo | 囲碁AIの代表例 | 深層学習、強化学習、探索を組み合わせる |
| 探索 | 候補を調べる | 行動を学ぶ仕組みそのものではない |
覚え方としては、次の流れがわかりやすいです。
G検定では、深層強化学習そのものの細かい数式よりも、周辺用語との関係を問われる可能性があります。
特に、次のような観点で整理しておくとよいです。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 強化学習との関係 | 深層強化学習は、強化学習にディープラーニングを組み合わせたもの |
| DQNとの関係 | DQNは、Q学習にニューラルネットワークを組み合わせた代表例 |
| AlphaGoとの関係 | 深層学習、強化学習、探索を組み合わせた代表例 |
| 教師あり学習との違い | 正解ラベルではなく、報酬をもとに行動を改善する |
| 探索との違い | 探索は候補を調べる考え方であり、強化学習そのものとは役割が違う |
選択肢で迷ったときは、次のように考えると整理しやすくなります。
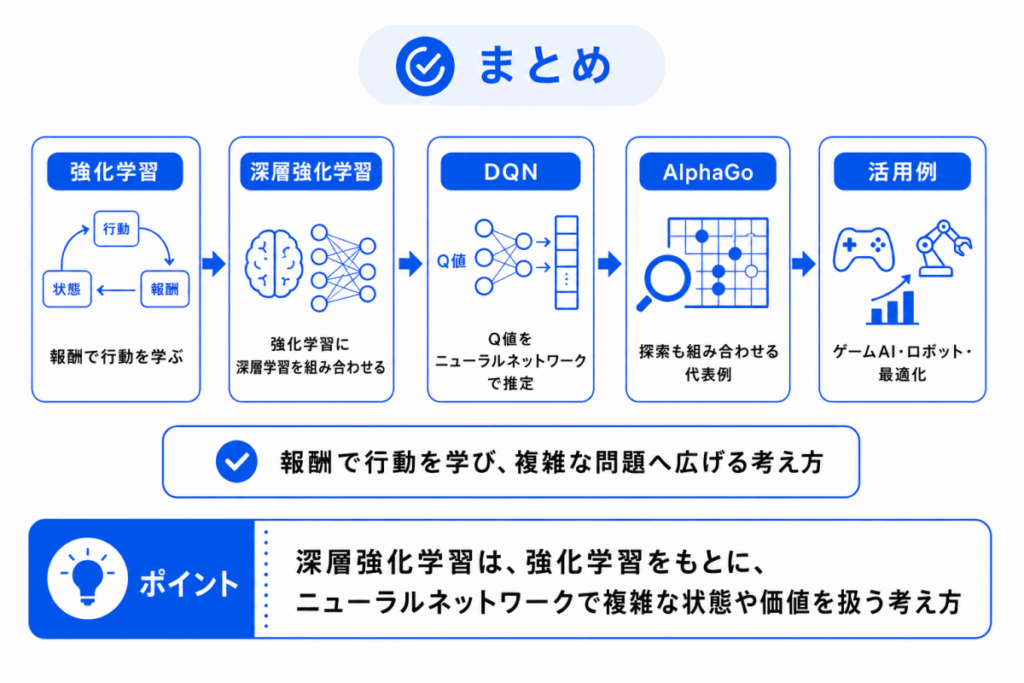
深層強化学習は、強化学習とディープラーニングを組み合わせた考え方です。
強化学習は、報酬をもとに行動を改善します。
深層強化学習では、ニューラルネットワークを使って、複雑な状態や行動価値を扱います。
G検定では、DQN や AlphaGo との関係を押さえておくと理解しやすくなります。
| 用語 | 覚え方 |
|---|---|
| 強化学習 | 報酬で行動を学ぶ |
| 深層強化学習 | 強化学習に深層学習を組み合わせる |
| Q学習 | 行動価値であるQ値を学ぶ |
| DQN | Q学習にニューラルネットワークを組み合わせる |
| AlphaGo | 深層学習、強化学習、探索を組み合わせた代表例 |
深層強化学習を理解すると、「強化学習」、「Q学習」、「DQN」、「AlphaGo」、「探索」のつながりが整理しやすくなります。
暗記ではなく、報酬で学ぶ強化学習を、ニューラルネットワークで複雑な問題に広げたもの と考えると理解しやすいです。
深層強化学習は、強化学習、探索、ニューラルネットワーク、ディープラーニングの概要とあわせて確認すると理解しやすくなります。
| リンク先 | 確認できる内容 |
|---|---|
| 強化学習とは? | 報酬/エージェント/環境/行動の関係 |
| 探索手法の違い | 幅優先探索/深さ優先探索/Mini-Max法/αβ法 |
| ニューラルネットワークとは? | 入力/重み/出力/学習の基本 |
| ディープラーニングの概要まとめ | ニューラルネットワーク/学習の流れ/過学習 |
| 機械学習の概要まとめ | 教師あり学習/教師なし学習/強化学習 |
| AIはどうやって学習する? | データ/損失/重み更新/学習の流れ |
| AIの技術の進化 | 探索/機械学習/深層学習/生成AIの流れ |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。