【G検定対策】ディープラーニングの概要まとめ|ニューラルネットワーク・学習の流れ・過学習をつなげて理解する
seo-webmaster
G検定対策ブログ
G検定では、機械学習やディープラーニングの仕組みだけでなく、AIを理解するための数理・統計知識も問われます。
期待値、分散、標準偏差、相関係数、確率分布、条件付き確率、ベイズの定理、ベクトル、行列、微分、正規化、標準化、情報量、エントロピーは、それぞれ別々の用語に見えます。
しかし、流れで見ると、AIが「データを数字として扱い、学習し、予測し、評価するための考え方」です。
この記事では、AIに必要な数理・統計知識を、G検定で混同しやすい用語とつなげて整理します。
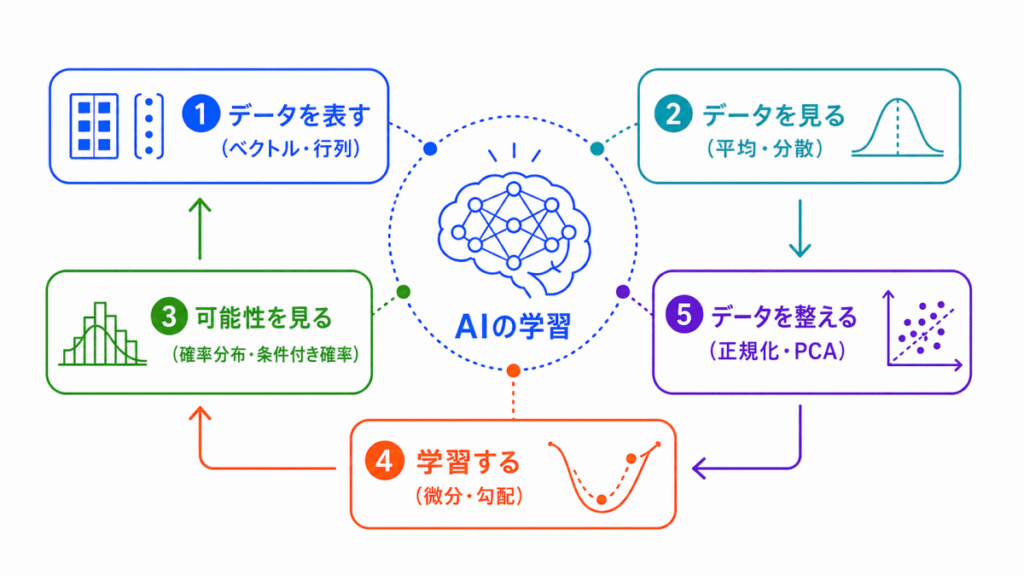
AIに必要な数理・統計知識とは、AIがデータを扱うための土台になる考え方です。
AIは、画像、文章、音声、表データをそのまま理解しているわけではありません。
多くの場合、データを数値に変換して扱います。
そのため、G検定では「数式を完璧に解けるか」よりも、「その考え方がAIのどこで使われるのか」を理解することが大切です。
整理すると、次のようになります。
| テーマ | 見るポイント | 一言でいうと |
|---|---|---|
| 統計 | データの中心やばらつき | データの特徴を数字で整理する |
| 確率 | 起こりやすさや不確かさ | 予測や分類の可能性を考える |
| 線形代数 | ベクトルや行列 | データを数字のまとまりとして扱う |
| 微分 | 変化の方向 | 損失を小さくする方向を探す |
| 前処理 | データの整え方 | AIが学習しやすい形にする |
この分野は、計算問題だけを解く分野ではありません。
AIの学習や予測を、数字の考え方から理解する分野です。
G検定の得点率で表示される分野は8分野です。その8分野の7番目の分野のまとめ記事がこの記事です。そして、さらに詳細な記事へとつながります。
イメージ図で表すと次の図になります。

この分野で出てくる重要用語をまとめて確認したい場合は、こちらの記事も参考になります。
AIに必要な数理・統計知識では、データをどう見るか、AIがどう学習するかを理解します。
重要なテーマは、次のように整理できます。
| 項目 | 学ぶ内容 |
|---|---|
| 期待値・分散・標準偏差 | データの平均的な値やばらつきを理解する |
| 相関係数・共分散・偏相関係数 | データ同士の関係性を理解する |
| 確率分布 | どの値がどれくらい起こりやすいかを理解する |
| 条件付き確率・ベイズの定理 | 条件や観測結果をもとに可能性を考える |
| ベクトル・行列 | AIがデータを数値のまとまりとして扱う仕組みを理解する |
| 微分 | 損失を小さくするための重み更新を理解する |
| 正規化・標準化・PCA | AIが学習しやすいデータに整える考え方を理解する |
| 情報量・エントロピー | 珍しさや不確かさを数値で表す考え方を理解する |
この分野を理解すると、機械学習、ディープラーニング、データ前処理、損失関数の関係が見えやすくなります。
期待値・分散・標準偏差 を整理すると次のようになります。
たとえば、平均点が同じテストでも、全員が平均点付近に集まっている場合と、高得点・低得点に大きく分かれている場合では、データの意味が違います。
AIでは、データのばらつきが大きいと、学習や評価に影響することがあります。
そのため、期待値・分散・標準偏差は、データの状態を理解する基本になります。
平均的な値とばらつきを詳しく確認したい場合は、こちらの記事で整理しています。
相関係数・共分散・偏相関係数 を整理すると次のようになります。
AIでは、特徴量同士の関係を見るときに関係します。
ただし、相関があるからといって、必ず因果関係があるとは限りません。
ここはG検定でも混同しやすいポイントです。
相関、共分散、分散の違いを詳しく確認したい場合は、こちらの記事で整理しています。

確率分布は、どの値や結果がどれくらい起こりやすいかを表す考え方です。
AIでは、予測結果を確率として扱う場面があります。
たとえば、画像分類で「犬の確率が高い」、「猫の確率も少しある」のように、候補ごとの可能性を考えます。
このとき、確率分布の考え方が関係します。
G検定では、正規分布、二項分布、ベルヌーイ分布、ポアソン分布などの名前が出てきます。
細かい計算よりも、それぞれがどのような場面を表すのかを押さえましょう。
代表的な確率分布を整理したい場合は、こちらの記事がおすすめです。
条件付き確率は、ある条件のもとで、別の出来事が起こる確率を見る考え方です。
たとえば、単に「雨が降る確率」を見るのではなく、「雲が多いという条件のもとで雨が降る確率」を考えるイメージです。
AIでは、特徴をもとに分類や予測を行う場面と関係します。
ある情報が与えられたときに、どの分類に入りやすいかを考えるときに使われます。
条件付き確率の基本を確認したい場合は、こちらの記事で整理しています。
ベイズの定理は、条件付き確率を使って、観測された情報から原因や分類の可能性を考える方法です。
たとえば、ある特徴が見られたときに、どの分類に属する可能性が高いかを考えるイメージです。
G検定では、ナイーブベイズなどの理解につながります。
ベイズの定理は、式だけを暗記するよりも、「結果を見て、原因や分類の可能性を考える」と理解すると整理しやすいです。
ベイズの定理とAIの推論を整理したい場合は、こちらの記事がおすすめです。
ベクトルは、複数の数値をひとまとまりにしたものです。
行列は、数値を行と列に並べたものです。
AIでは、文章、画像、音声、表データなどを、数値のまとまりとして扱います。
たとえば、年齢、身長、体重のような情報を並べると、1人分のデータをベクトルとして表せます。
複数人のデータを並べると、行列のように扱えます。
ニューラルネットワークでも、重みや入力データを数値のまとまりとして処理します。
AIがデータを数字として扱う考え方を確認したい場合は、こちらの記事で整理しています。
微分は、少し変えたときに結果がどれくらい変わるかを見る考え方です。
AIでは、損失を小さくするために重みを調整します。
このとき、重みをどちらの方向に動かせば損失が小さくなるのかを考えます。
ここで、微分や勾配の考え方が使われます。
流れで見ると、次のようになります。
G検定では、微分を「損失を小さくする方向を探すための考え方」として押さえると理解しやすいです。
微分と勾配降下法の関係を確認したい場合は、こちらの記事で整理しています。
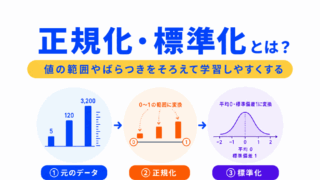
正規化は、値の範囲をそろえる処理です。
標準化は、平均や標準偏差を基準にして、データのスケールをそろえる処理です。
AIでは、特徴量ごとに数値の大きさが違うと、学習がうまく進みにくくなることがあります。
たとえば、年齢、身長、年収、購入回数のように、値の範囲が大きく違うデータをそのまま使うと、数値の大きい特徴量が強く影響して見えることがあります。
そのため、正規化や標準化でスケールを整えます。
ただし、正規化と正則化は別の考え方です。
正規化はデータの前処理、正則化は過学習を防ぐ工夫です。
正規化、標準化、正則化の違いを整理したい場合は、こちらの記事がおすすめです。
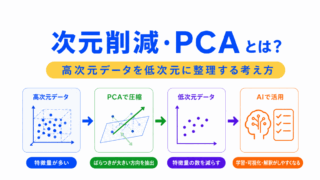
次元削減は、特徴量の数を減らして、データを扱いやすくする考え方です。
PCAは、主成分分析とも呼ばれ、データの情報をできるだけ残しながら、少ない軸で表現する方法です。
特徴量が多すぎると、計算量が増えたり、ノイズの影響を受けたり、過学習しやすくなったりします。
そのため、重要な情報を残しながら特徴量を減らすことがあります。
G検定では、PCAを「高次元データを低次元に圧縮する代表的な方法」として押さえると整理しやすいです。
次元削減とPCAの基本を確認したい場合は、こちらの記事で整理しています。
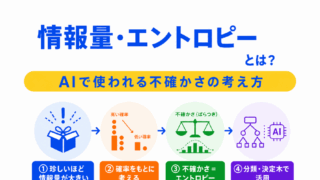
情報量は、1つの出来事が起きたときに得られる情報の大きさを表す考え方です。
エントロピーは、確率分布全体の不確かさを表す考え方です。
どれが起こるかわからないほど、エントロピーは大きくなります。
決定木では、データを分けたときに不確かさがどれくらい減ったかを見る考え方と関係します。
分類問題では、交差エントロピーが損失関数として使われることがあります。
情報量、エントロピー、交差エントロピーの違いを整理したい場合は、こちらの記事がおすすめです。
数理・統計は、AIの一部だけで使われるものではありません。
データを準備する段階から、学習、予測、評価まで関係します。
整理すると、次のようになります。
| AIの流れ | 関係する考え方 | 役割 |
|---|---|---|
| データを表す | ベクトル・行列 | データを数値のまとまりとして扱う |
| データを見る | 期待値・分散・標準偏差 | 中心やばらつきを確認する |
| 関係を見る | 相関係数・共分散 | 特徴量同士の関係を確認する |
| 可能性を見る | 確率分布・条件付き確率 | どの結果が起こりやすいかを見る |
| 学習する | 微分・勾配 | 損失を小さくする方向を探す |
| データを整える | 正規化・標準化・PCA | 学習しやすい形にする |
このように見ると、数理・統計はAIの裏側を理解するための地図のようなものです。
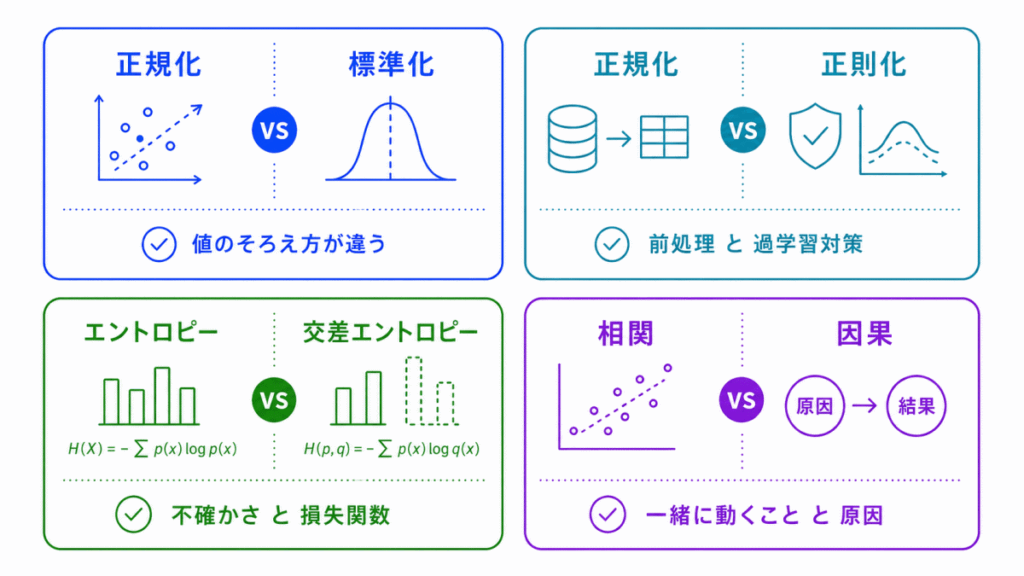
数理・統計では、名前が似ている用語や、役割が近い用語があります。
G検定では、特に違いを整理しておくことが大切です。
| 用語 | 違い | 押さえ方 |
|---|---|---|
| 分散・標準偏差 | どちらもばらつきを見る | 標準偏差は元の単位に近く、直感的に見やすい |
| 相関・因果 | 相関があっても原因とは限らない | 一緒に動くことと、原因であることは別 |
| 条件付き確率・ベイズの定理 | 条件付き確率を使って、観測結果から可能性を考える | ベイズの定理は逆向きに考えるイメージ |
| エントロピー・交差エントロピー | エントロピーは不確かさ、交差エントロピーは損失関数として使われる | 見ている対象が違う |
| 正規化・標準化・正則化 | 正規化と標準化は前処理、正則化は過学習対策 | 名前は似ているが目的が違う |
用語を見たときは、「何を表しているのか」、「どの場面で使うのか」をセットで確認しましょう。
G検定では、数理・統計の細かい計算よりも、意味や使われる場面を理解しているかが重要です。
特に、次のような観点で問われやすいです。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 用語の意味 | 期待値、分散、確率分布、微分などが何を表すか |
| 用語の違い | 正規化と標準化、相関と因果、エントロピーと交差エントロピーなど |
| AIとの関係 | 学習、予測、評価、前処理のどこで使うか |
| 機械学習との関係 | 分類、回帰、決定木、ナイーブベイズとのつながり |
| ディープラーニングとの関係 | 損失関数、勾配降下法、誤差逆伝播法との関係 |
数理・統計が苦手な場合でも、最初から難しい式を追いかける必要はありません。
まずは、AIの流れの中で「何のために使われるのか」を押さえましょう。
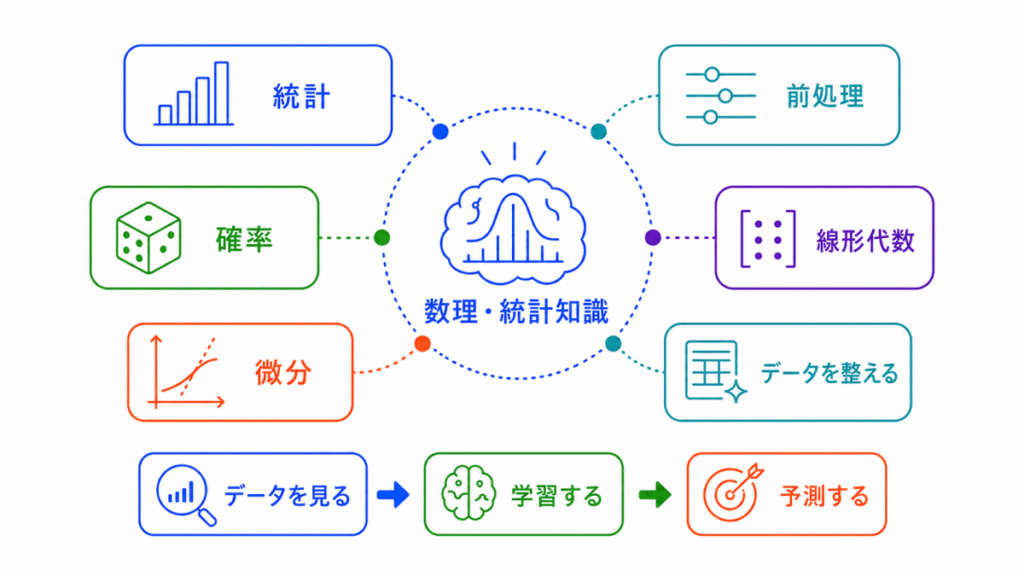
AIに必要な数理・統計知識は、AIがデータを扱い、学習し、予測し、評価するための土台です。
期待値、分散、標準偏差は、データの中心やばらつきを見る考え方です。
相関係数、共分散、偏相関係数は、データ同士の関係を見る考え方です。
確率分布、条件付き確率、ベイズの定理は、起こりやすさや条件付きの可能性を考えるために使われます。
ベクトルや行列は、AIがデータを数値のまとまりとして扱うために重要です。
微分は、損失を小さくする方向を探すために使われます。
正規化、標準化、次元削減、PCAは、AIが学習しやすいデータに整えるための考え方です。
情報量やエントロピーは、珍しさや不確かさを数値で表す考え方です。
G検定では、数式を丸暗記するよりも、用語の意味、違い、AIとの関係をつなげて理解しましょう。
数理・統計の重要用語を一覧で確認したい場合は、こちらの記事も参考になります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 数理・統計の重要用語 | 期待値/分散/標準偏差/相関係数/確率分布/条件付き確率/ベイズの定理/ベクトル・行列/微分 |
| 期待値・分散・標準偏差とは? | 平均的な値/データのばらつき/標準偏差/AIの予測・評価との関係 |
| 確率分布とは? | 確率変数/離散型・連続型/ベルヌーイ分布/二項分布/正規分布/ポアソン分布 |
| ベイズの定理とは? | 条件付き確率/観測結果から可能性を更新する考え方/ナイーブベイズ/分類・推論との関係 |
| ベクトル・行列とは? | AIがデータを数値のまとまりとして扱う考え方/特徴量/重み/ニューラルネットワークとの関係 |
| 微分とは? | 少し変えたときの変化/損失を小さくする方向/勾配降下法/重みの更新 |
| 情報量・エントロピーとは? | 珍しさを表す情報量/不確かさを表すエントロピー/決定木/交差エントロピーとの関係 |
| 理解型予想問題まとめ | 混同しやすい用語/予想問題/分野別チェック |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。