【G検定対策】ディープラーニングの応用例の重要用語まとめ
seo-webmaster
SEO・ウェブマスターブログ
AIは、モデルを作っただけでは実際の業務で使えるとは限りません。
データを集め、前処理を行い、効果を小さく検証し、本番導入後も継続的に監視・改善していく必要があります。
G検定では、AIモデルそのものだけでなく、AIを社会や業務の中で安全に使うための考え方も問われます。
この記事では、PoC、MLOps、エッジAI、モデル軽量化、アノテーション、データ品質、データ前処理、特徴量設計、データリーケージをつなげて、AIの社会実装に向けた流れを整理します。
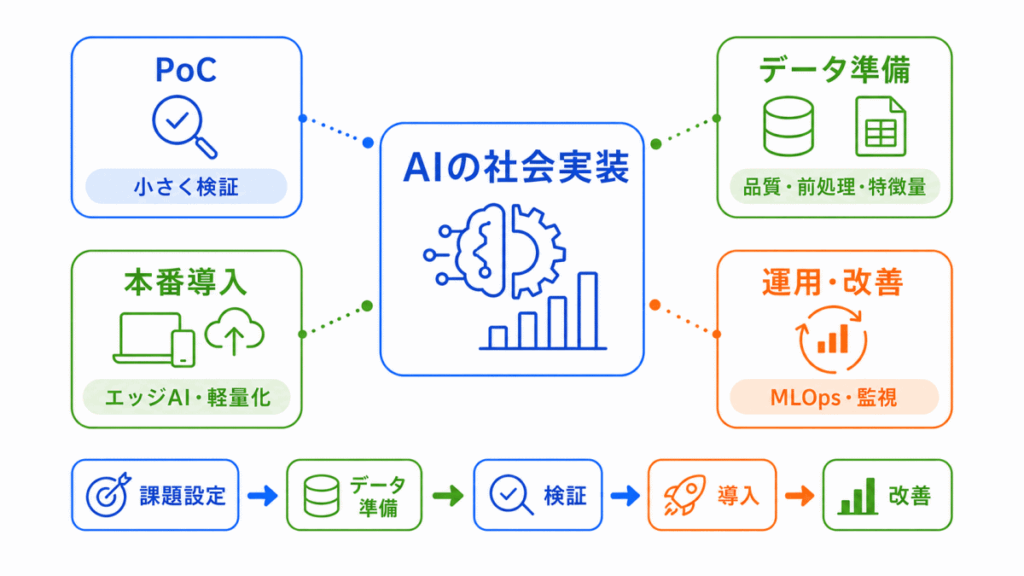
AIの社会実装に向けてとは、AIモデルを作るだけでなく、実際の業務や社会の中で使える形にし、継続的に運用・改善していく考え方です。
AIの学習をはじめたばかりの人は、AI開発というと「モデルを作ること」をイメージしやすいかもしれません。
しかし、実際には データの準備、効果検証、本番導入、運用、改善、リスク管理まで含めて考える必要があります。
AIの社会実装で見るべき観点は、次のように整理できます。
| 観点 | 内容 | 関係する用語 |
|---|---|---|
| 導入前の検証 | AIを使うことで効果があるか、小さく試す | PoC |
| データの準備 | AIが学習しやすいデータを整える | アノテーション、データ品質、データ前処理 |
| 特徴の作成 | AIが判断しやすい情報を作る | 特徴量設計、データリーケージ |
| 本番導入 | 実際の業務やサービスでAIを使えるようにする | エッジAI、モデル軽量化 |
| 運用・改善 | 導入後も性能を監視し、必要に応じて改善する | MLOps、AIガバナンス |
関連記事
AIの社会実装では、AIを作るだけでなく、導入前の検証から運用後の改善までを流れで考えることが大切です。
AIの社会実装は、モデルを作って終わりではありません。
課題を決め、データを準備し、効果を検証し、本番導入後も運用していく流れで考えます。
流れで見ると、次のようになります。
この流れの中で重要なのは、最初から大きく導入しないことです。
まずはPoCで小さく試し、効果や課題を確認したうえで、本格導入や運用改善につなげます。
AI導入の流れを個別に理解したい場合は、まずPoCから確認すると全体像をつかみやすくなります。
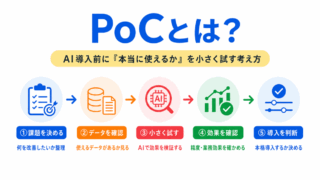
PoCとは、Proof of Conceptの略で、AIを本格導入する前に「本当に効果がありそうか」を小さく検証することです。
AIは、理論上はうまくいきそうに見えても、実際のデータや業務では期待通りに動かないことがあります。
そのため、いきなり本番導入するのではなく、まず小さな範囲で試すことが重要です。
PoCの役割は、次のように整理できます。
| 観点 | 内容 | 注意点 |
|---|---|---|
| 目的 | AI導入の効果を小さく確認する | 検証だけで終わらせないことが大切 |
| 確認すること | 精度、費用、業務への効果、実現可能性などを見る | 評価指標だけで判断しない |
| 成功した後 | 本格導入に向けて設計を進める | 運用体制も考える必要がある |
| 失敗しやすい点 | PoCではうまくいったが、本番では使えない | 本番データや業務条件との違いに注意する |
PoCは、AI導入の入り口です。
ただし、PoCで高い評価が出たからといって、そのまま本番で成功するとは限りません。
PoCは、AI導入前に「本当に使えそうか」を小さく確認する工程です。
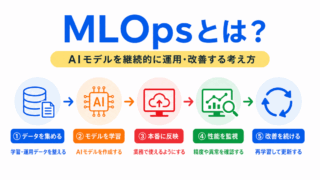
MLOpsとは、機械学習モデルを本番環境で安定して運用し、継続的に改善するための考え方です。
AIモデルは、一度作ればずっと同じ性能で使えるわけではありません。
データの傾向が変わったり、利用環境が変わったりすると、モデルの性能が下がることがあります。
MLOpsで行うことは、次のように整理できます。
| 項目 | 内容 | なぜ必要か |
|---|---|---|
| モデルの管理 | どのモデルを使っているかを管理する | 変更履歴や再現性を保つため |
| 性能の監視 | 本番導入後の精度やF1値などを確認する | 性能低下に気づくため |
| 再学習 | 新しいデータを使ってモデルを更新する | 環境変化に対応するため |
| 運用の自動化 | 学習、評価、デプロイを効率化する | 継続的に改善しやすくするため |
| リスク管理 | 誤判定や偏り、説明可能性などを確認する | 安全にAIを使うため |
MLOpsは、AIを「作る」段階よりも、AIを「使い続ける」段階で重要になります。
AIモデルを本番で使い続けるには、導入後の監視や改善の考え方も必要です。
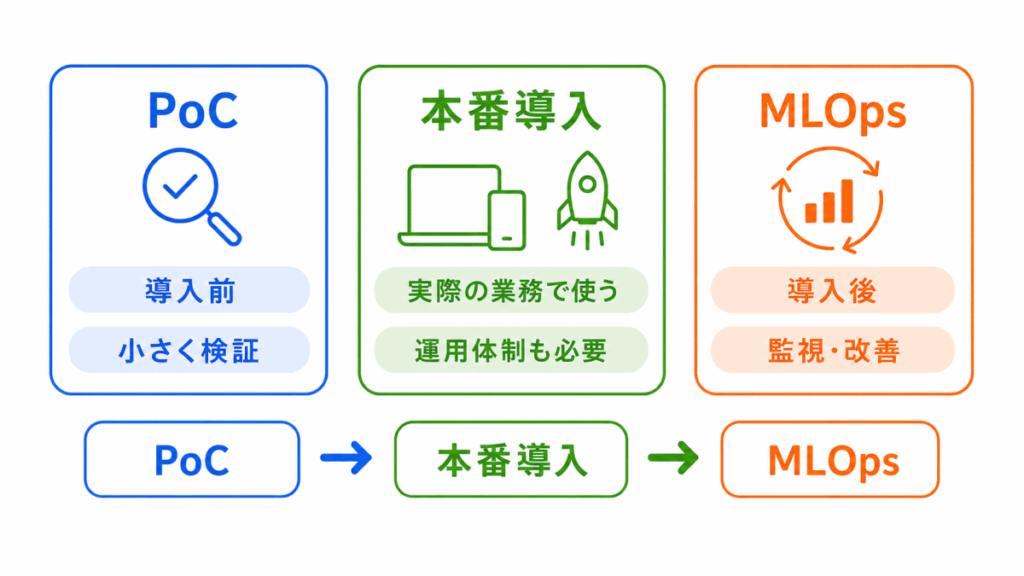
PoC、本格導入、MLOpsは似て見えますが、役割が違います。
違いは、次のように整理できます。
関係を流れで見ると、次のようになります。
| 用語 | 一言でいうと | 主な目的 |
|---|---|---|
| PoC | 導入前に小さく試す | AIで効果が出そうか確認する |
| 本格導入 | 実際の業務で使う | AIを業務やサービスに組み込む |
| MLOps | 導入後に運用・改善する | AIモデルを安定して使い続ける |
G検定では、PoCとMLOpsを混同しないことが大切です。
PoCは導入前の検証、MLOpsは導入後の運用・改善です。
PoCとMLOpsは混同しやすいので、「導入前」と「導入後」の違いで整理しておくと理解しやすくなります。
AIの社会実装では、モデルだけでなくデータの準備が重要です。
どれだけ高度なモデルを使っても、データに問題があれば、AIは正しく学習できません。
データ準備に関係する用語は、次のように整理できます。
| 用語 | 一言でいうと | 社会実装での役割 |
|---|---|---|
| アノテーション | データに正解ラベルを付ける作業 | 教師あり学習で正解データを作る |
| データ品質 | AIが学習しやすいデータかどうか | 欠損、ノイズ、偏り、ラベルミスを確認する |
| データ前処理 | データを使える形に整える作業 | 欠損値処理、外れ値処理、正規化などを行う |
| 特徴量設計 | AIが学習しやすい特徴を作る考え方 | 予測に役立つ情報を整理する |
| データリーケージ | 本番で使えない情報が混ざる問題 | 評価が不自然に高く見える原因になる |
データ準備の流れを見ると、次のようになります。
社会実装では、AIモデルの性能だけでなく、データの作り方や整え方も重要になります。
AIの社会実装では、モデルだけでなく、学習に使うデータの状態も性能に大きく影響します。

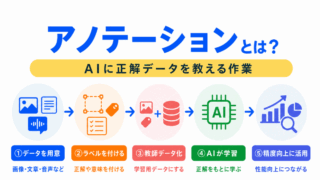
アノテーションとは、データに正解ラベルを付ける作業です。
たとえば、画像に「犬」、「猫」とラベルを付けたり、文章に「ポジティブ」、「ネガティブ」と分類を付けたりします。
教師あり学習では、AIが正解を見ながら学習するため、アノテーションの品質が重要になります。
アノテーションで注意する点は、次のように整理できます。
| 注意点 | 内容 |
|---|---|
| ラベルミス | 間違った正解ラベルがあると、AIが誤ったパターンを学習する |
| 基準のばらつき | 人によって判断基準が違うと、データの一貫性が下がる |
| データの偏り | 特定の種類のデータに偏ると、本番で弱くなることがある |
| コスト | 大量のデータに正解を付けるには時間と費用がかかる |
アノテーションは、単なる作業ではなく、AIの性能を左右する重要な工程です。
教師あり学習では、AIに正解を教えるためのアノテーションが重要になります。
データ品質とは、AIが正しく学習しやすいデータかどうかを表す考え方です。
データに欠損、ノイズ、ラベルミス、偏りがあると、AIは本来学ぶべきパターンをうまく学べません。
そのため、AIを社会実装する前に、データの状態を確認することが大切です。
データ品質の問題は、次のように整理できます。
| 問題 | 内容 | AIへの影響 |
|---|---|---|
| 欠損 | 必要な値が抜けている | 正しく学習できないことがある |
| ノイズ | 不要な情報や誤差が混ざっている | 不要なパターンまで学習することがある |
| ラベルミス | 正解ラベルが間違っている | 誤った関係を学習することがある |
| データの偏り | 特定の条件や属性にデータが偏っている | 未知のデータや本番環境に弱くなることがある |
データ品質が低いと、検証ではよさそうに見えても、本番では安定しないAIになることがあります。
データ品質が低いと、AIは不要な特徴や誤ったパターンを学習してしまうことがあります。
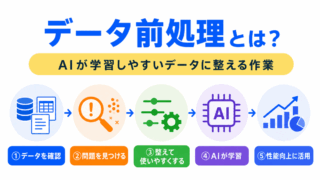
データ前処理とは、AIが学習しやすいようにデータを整える作業です。
現実のデータは、そのままではAIが扱いにくいことがあります。
欠損値を処理したり、外れ値を確認したり、数値のスケールをそろえたりすることで、AIが学習しやすい状態にします。
データ前処理で行うことは、次のように整理できます。
| 処理 | 内容 |
|---|---|
| 欠損値処理 | 抜けている値を補完したり、除外したりする |
| 外れ値処理 | 極端な値を確認し、必要に応じて処理する |
| ノイズ除去 | 不要な情報や誤ったデータを取り除く |
| 正規化・標準化 | 数値のスケールをそろえる |
| カテゴリ変数の変換 | 文字やカテゴリをAIが扱いやすい形に変換する |
ただし、前処理はタイミングにも注意が必要です。
学習データと検証データを分ける前に全データで処理すると、検証データの情報が学習側に混ざることがあります。
正しい前処理の流れは、次のようになります。
データをAIが学習しやすい形に整える流れは、データ前処理の記事で詳しく整理しています。
特徴量設計とは、AIが学習しやすい特徴を作る考え方です。
特徴量とは、AIが予測に使う情報のことです。
たとえば、購入予測であれば、閲覧回数、購入履歴、利用頻度などが特徴量になります。
特徴量設計で見るべき観点は、次のように整理できます。
| 観点 | 内容 | 注意点 |
|---|---|---|
| 予測に役立つか | 目的変数と関係しそうな情報を選ぶ | 関係のない情報を増やしすぎない |
| 本番で使えるか | 実際の予測時点で取得できる情報か確認する | 未来の情報を使わない |
| わかりやすいか | 人が意味を説明しやすい特徴にする | 説明可能性にも関係する |
| 偏りがないか | 特定の条件に偏りすぎていないか確認する | 公平性や汎化性能に影響する |
特徴量設計では、「役に立つ特徴か」だけでなく、「予測時点で使える特徴か」を確認することが重要です。
特徴量設計では、予測に役立つ情報を作るだけでなく、本番で使える情報かどうかも確認します。

データリーケージとは、本番の予測時には使えない情報が、学習や評価に混ざってしまうことです。
これは個人情報の漏えいという意味ではなく、機械学習の評価で「本来見てはいけない情報を見てしまう問題」を指します。
データリーケージがあると、検証では高性能に見えても、本番では同じ情報が使えず性能が下がることがあります。
データリーケージが起きる流れは、次のようになります。
データリーケージは、特徴量設計、前処理、交差検証、評価指標と関係します。
G検定では、単に「精度が高い」ではなく、「その評価が正しい条件で行われているか」を考えることが大切です。
検証では高性能に見えても本番で失敗する原因として、データリーケージも押さえておきましょう。

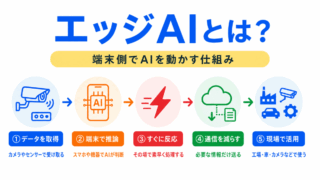
エッジAIとは、クラウドではなく、スマートフォン、カメラ、センサー、工場の機器など、端末側でAIを動かす仕組みです。
クラウドにデータを送らず端末側で処理できるため、通信遅延を減らしたり、プライバシー保護に役立ったりします。
一方で、端末は計算資源が限られるため、軽いモデルが必要になります。
エッジAIの特徴は、次のように整理できます。
| 観点 | 内容 | 関係するポイント |
|---|---|---|
| 処理場所 | 端末側でAIを動かす | クラウドに送らず処理できる |
| メリット | 低遅延、通信量削減、プライバシー保護につながる | リアルタイム処理に向いている |
| 課題 | 端末の計算能力やメモリに制約がある | モデルを軽くする必要がある |
| 関係する技術 | モデル軽量化、量子化、蒸留、枝刈りなど | 小さく速いAIにする |
エッジAIは、AIを現実の機器や現場で使うための重要な考え方です。
端末側でAIを動かすエッジAIは、AIを現場で使うための重要な考え方です。
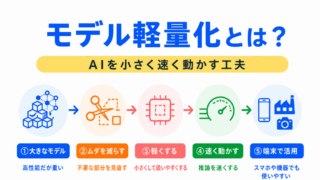
モデル軽量化とは、AIモデルを小さく、速く、扱いやすくするための工夫です。
高性能なAIモデルは、計算量が多く、メモリも多く使うことがあります。
そのままではスマートフォンやセンサーなどの端末で動かしにくいため、モデル軽量化が必要になります。
モデル軽量化の代表的な考え方は、次のように整理できます。
| 方法 | 内容 | 目的 |
|---|---|---|
| 量子化 | 重みや計算の精度を下げて軽くする | 計算量やメモリ使用量を減らす |
| 枝刈り | 重要度の低い重みや接続を削る | モデルを小さくする |
| 知識蒸留 | 大きなモデルの知識を小さなモデルに移す | 軽いモデルでも性能を保ちやすくする |
| 軽量モデル設計 | 最初から軽く動く構造を使う | 端末側で使いやすくする |
モデル軽量化は、エッジAIや本番運用とセットで理解するとわかりやすくなります。
エッジAIや本番運用では、AIモデルを小さく速くするモデル軽量化も重要になります。
AIの社会実装では、PoCではうまくいっても、本番導入後に失敗することがあります。
原因は、モデルの精度だけではありません。
本番運用で失敗しやすいポイントは、次のように整理できます。
| 失敗しやすい点 | 起きること | 対策の考え方 |
|---|---|---|
| PoCで終わる | 検証はできたが、本番導入につながらない | 運用体制や業務への組み込みも考える |
| データ品質が低い | 欠損、ノイズ、ラベルミスにより性能が安定しない | データ品質を確認し、前処理で整える |
| データリーケージがある | 検証では高性能でも、本番で性能が落ちる | 予測時点で使える情報だけを使う |
| 運用監視がない | 性能低下に気づけない | MLOpsで監視・改善する |
| 説明や管理が不足する | 判断理由や責任範囲が不明確になる | AIガバナンスや説明可能性も考える |
AIの社会実装では、「作ること」よりも「使い続けられる形にすること」が重要です。
本番運用では、モデル性能だけでなく、データ、運用体制、リスク管理まで含めて考える必要があります。
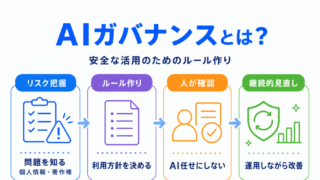
AIガバナンスとは、AIを安全・公平・適切に活用するための管理の考え方です。
AIの社会実装では、性能だけでなく、説明可能性、公平性、個人情報、著作権、責任の所在なども考える必要があります。
そのため、MLOpsとAIガバナンスはセットで理解すると整理しやすくなります。
MLOpsとAIガバナンスの違いは、次のように整理できます。
| 用語 | 主な目的 | 見るポイント |
|---|---|---|
| MLOps | AIモデルを安定して運用・改善する | 性能監視、再学習、デプロイ、モデル管理 |
| AIガバナンス | AIを安全・公平・適切に管理する | 説明可能性、公平性、リスク、ルール、責任 |
MLOpsは「運用改善」、AIガバナンスは「安全な管理」と考えると区別しやすいです。
AIを安全に使い続けるには、MLOpsだけでなくAIガバナンスの考え方も必要です。
G検定では、AIの社会実装について、単語の意味だけでなく、導入前・導入後・データ準備・運用管理の関係を問われることがあります。
問われやすい観点は、次のように整理できます。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| PoCの意味 | AIを本格導入する前に、小さく効果を検証すること |
| MLOpsの意味 | AIモデルを本番環境で継続的に運用・改善する考え方 |
| PoCとMLOpsの違い | PoCは導入前の検証、MLOpsは導入後の運用・改善 |
| データ品質の重要性 | 欠損、ノイズ、ラベルミス、偏りはAIの性能に影響する |
| データリーケージ | 本番で使えない情報が学習や評価に混ざる問題 |
| エッジAI | 端末側でAIを動かす仕組み。低遅延やプライバシー保護に関係する |
| モデル軽量化 | 端末や本番環境で使いやすいようにAIモデルを小さく速くする工夫 |
| AIガバナンス | AIを安全・公平・適切に管理する考え方 |
G検定対策では、個別用語をバラバラに覚えるより、AI導入の流れに沿って理解することが大切です。
試験前にこの分野をまとめて確認したい場合は、重要用語まとめもあわせて見ると整理しやすくなります。
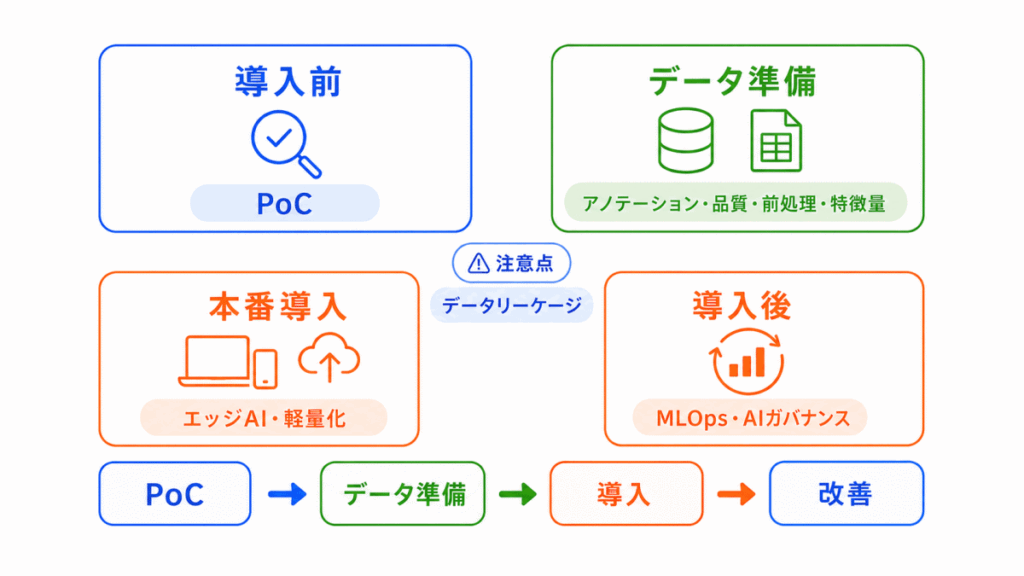
AIの社会実装に向けてでは、AIモデルの作成だけでなく、データ準備、効果検証、本番導入、運用改善、リスク管理まで含めて考えます。
最後に、重要ポイントを整理します。
| 項目 | ポイント |
|---|---|
| AIの社会実装 | AIを実際の業務や社会で使える形にし、継続的に運用すること |
| PoC | 本格導入前に、小さく効果を検証すること |
| MLOps | 導入後のAIモデルを監視・改善しながら運用する考え方 |
| データ準備 | アノテーション、データ品質、前処理、特徴量設計が重要になる |
| データリーケージ | 本番で使えない情報が混ざると、評価が実力以上に高く見えることがある |
| エッジAI・モデル軽量化 | 端末側や本番環境でAIを使いやすくするために重要 |
| AIガバナンス | AIを安全・公平・適切に活用するための管理の考え方 |
AIの社会実装は、単にAIを作る話ではありません。
「検証する」、「データを整える」、「本番で使う」、「運用し続ける」、「安全に管理する」という流れで理解すると、G検定でも整理しやすくなります。
AI導入前の検証について理解したい場合は、PoCの記事から確認すると流れをつかみやすくなります。
AIモデルを導入後に安定して使い続ける考え方は、MLOpsの記事で詳しく整理できます。
端末側でAIを動かす考え方を理解すると、社会実装の具体例がイメージしやすくなります。
エッジAIや本番運用では、AIモデルを小さく速くする工夫も重要になります。
AIの性能を安定させるには、モデルだけでなくデータそのものの品質も確認する必要があります。
データをAIが学習しやすい形に整える流れは、データ前処理の記事で確認できます。
検証では高性能に見えても本番で失敗する原因として、データリーケージも押さえておきましょう。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認