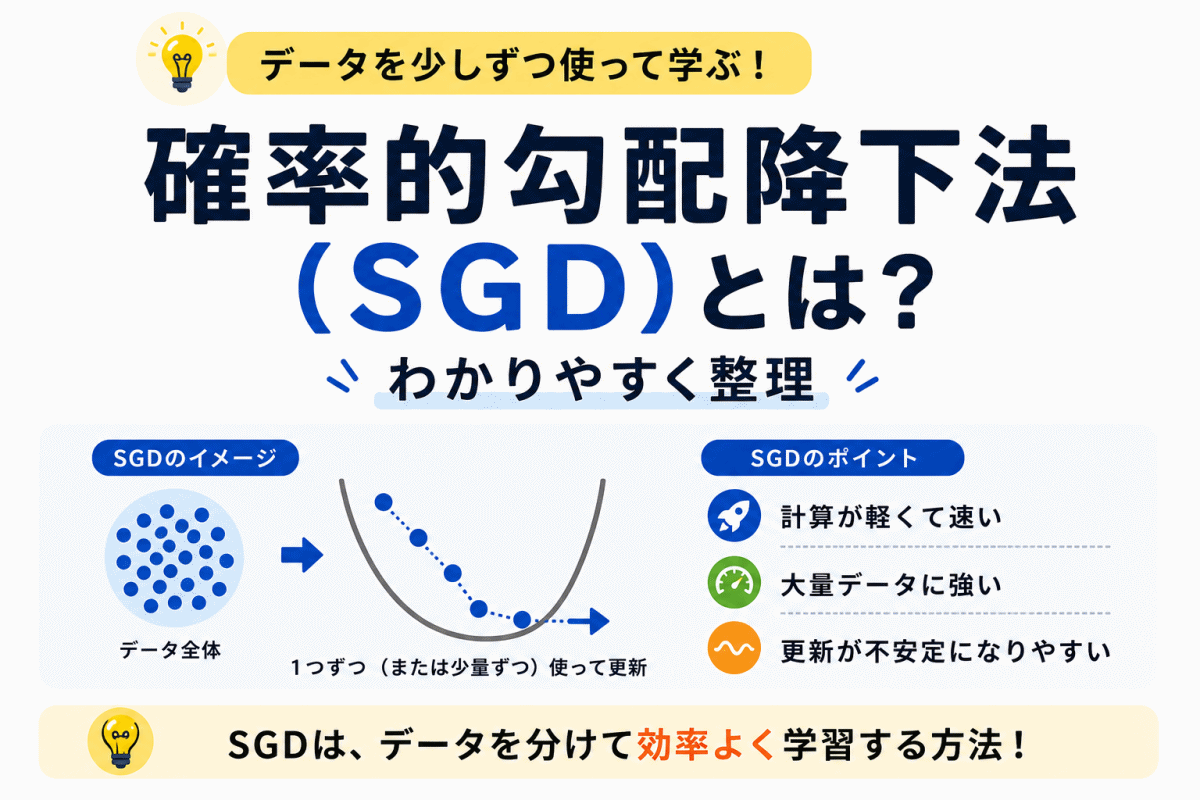
【G検定対策】確率的勾配降下法(SGD)とは?わかりやすく整理
seo-webmaster
SEO・ウェブマスターブログ
AIは、データからパターンを学習します。
しかし、データをそのままモデルに入力すれば、必ずうまく学習できるわけではありません。
データの中から、AIが学習しやすい形の情報を作ることが重要になります。この作業が特徴量設計です。
G検定では、特徴量、データ前処理、モデル性能、過学習、汎化性能などがつながって問われることがあります。
この記事では、特徴量設計の意味を、データ前処理との違いとあわせて整理します。
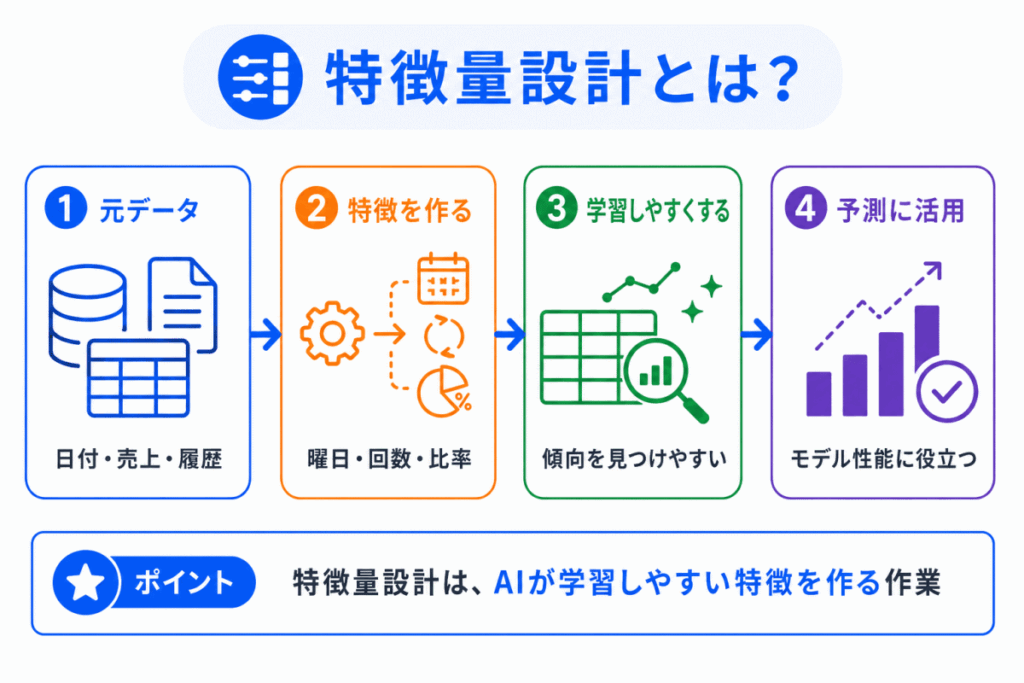
特徴量設計とは、AIが学習しやすいように、データから役に立つ特徴を作る作業です。
特徴量とは、モデルが学習に使う入力データのことです。
たとえば、売上を予測するAIを作る場合、単に「日付」をそのまま使うだけでなく、そこから「曜日」、「月」、「祝日かどうか」、「セール期間かどうか」などを作ることがあります。
このように、モデルがパターンを見つけやすいように情報を作ることが特徴量設計です。
ポイントは、特徴量設計は「データをきれいにする作業」ではなく、AIが学習しやすい見方を作る作業だという点です。
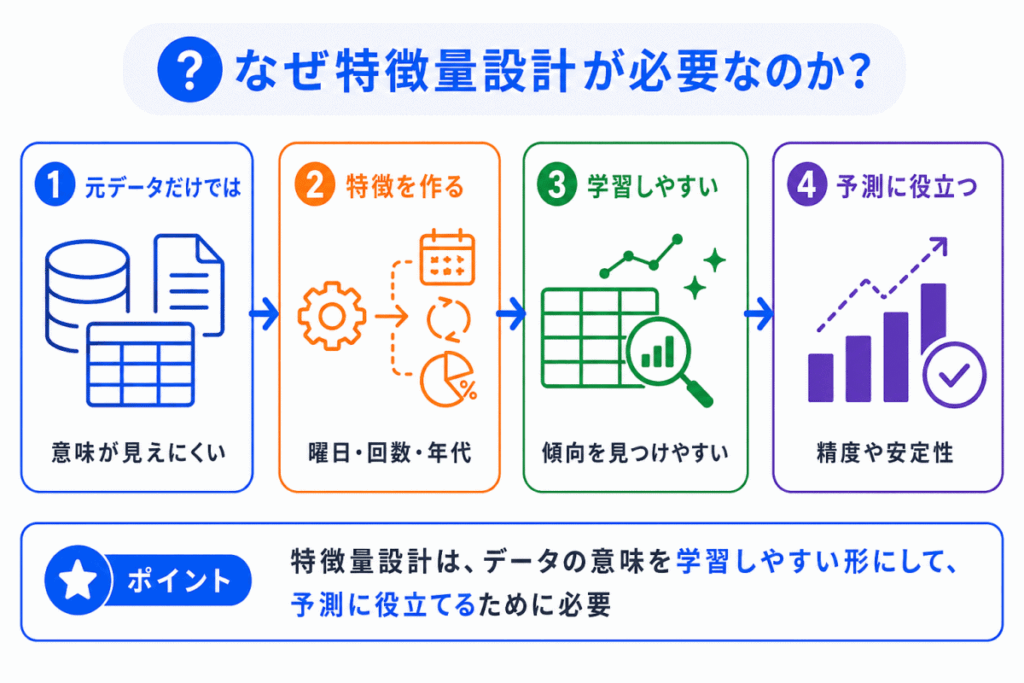
AIは、人間のように「この情報が重要そうだ」と意味を理解して判断しているわけではありません。
モデルは、入力された特徴量からパターンを見つけます。そのため、入力される特徴量がわかりにくいと、重要なパターンを学習しにくくなります。
たとえば、日付データをそのまま入力するだけでは、「曜日によって売上が変わる」、「月末に利用が増える」、「祝日に来店数が変わる」といった傾向を学習しにくいことがあります。
そこで、日付から「曜日」、「月」、「祝日かどうか」などを作ると、AIが傾向を見つけやすくなる場合があります。
ただし、特徴量を増やせば必ず性能が上がるわけではありません。関係のない特徴量を増やしすぎると、かえって過学習につながることがあります。
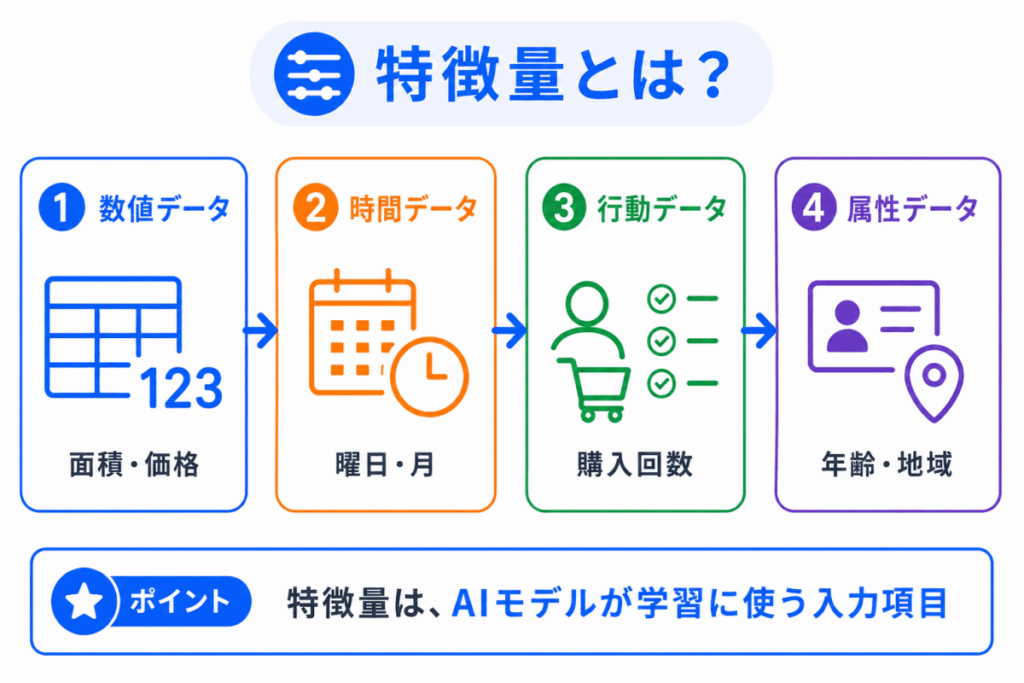
特徴量とは、AIモデルが学習に使う入力項目です。
表形式のデータであれば、各列が特徴量になることが多いです。
たとえば、住宅価格を予測する場合、面積、築年数、駅からの距離、部屋数などが特徴量になります。
売上予測であれば、日付、商品、価格、曜日、セール有無などが特徴量になります。退会予測であれば、利用回数、最終ログイン日、利用頻度などが特徴量になります。
ディープラーニングでは、特徴をモデルが自動的に学習することもあります。
一方で、表形式データや業務データでは、人間が目的に応じて特徴量を作ることが重要になる場合があります。
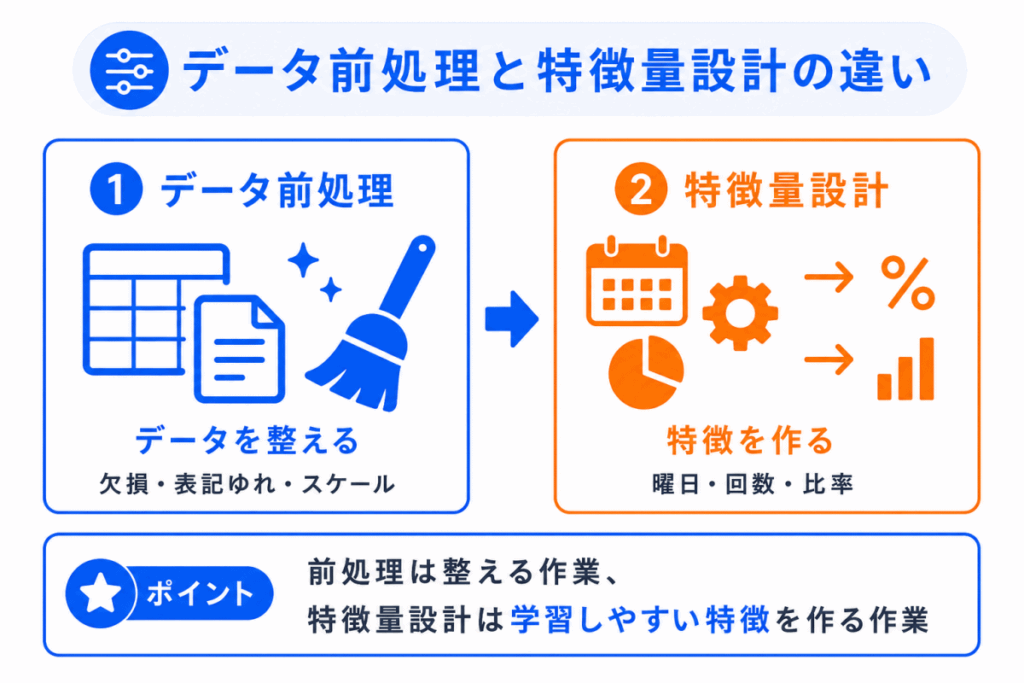
データ前処理と特徴量設計は、どちらもAIにデータを入力する前に行う作業です。
ただし、役割は少し違います。
たとえば、「2026/06/12」、「2026年6月12日」、「06-12-2026」のような日付表記をそろえるのはデータ前処理です。
一方、その日付から「金曜日」、「6月」、「平日」、「月末に近い」などの情報を作るのは特徴量設計です。
整理すると、次のようになります。
| 用語 | 一言でいうと | 例 |
|---|---|---|
| データ前処理 | データを使える形に整える作業 | 欠損値を補完する、表記ゆれを統一する、スケールをそろえる |
| 特徴量設計 | AIが学習しやすい特徴を作る作業 | 日付から曜日を作る、年齢から年代を作る、回数や比率を作る |
G検定では、両者を完全に別物として覚えるよりも、AI開発の流れの中で役割の違いを理解することが大切です。
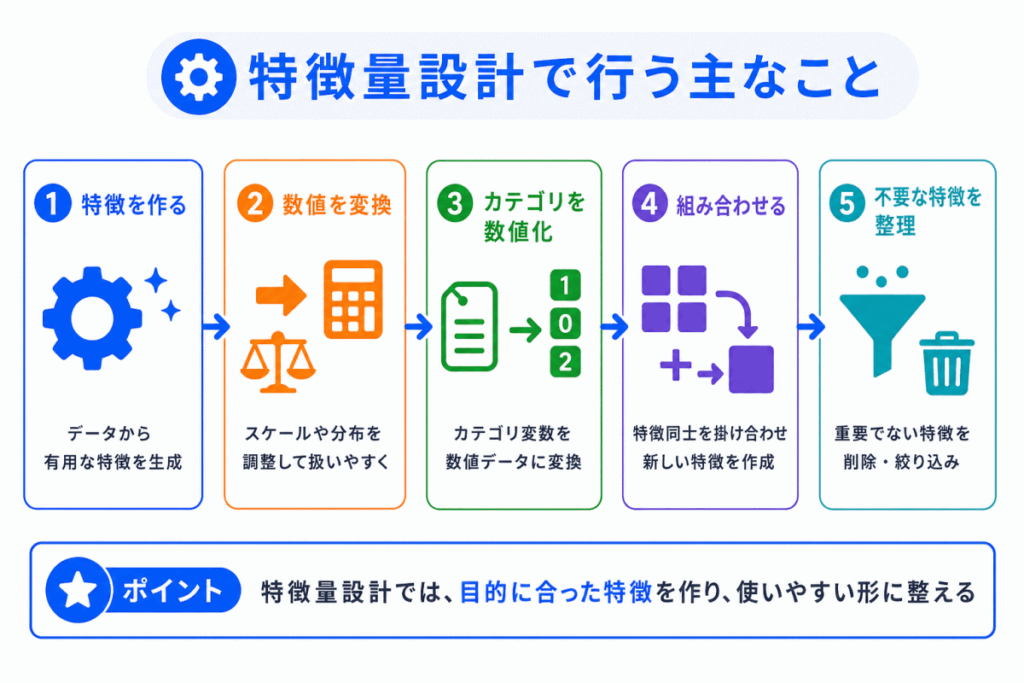
特徴量設計では、元のデータをそのまま使うだけでなく、目的に合わせて新しい特徴を作ったり、使いやすい形に変えたりします。
主な作業は以下のように整理できます。
| 作業 | 内容 |
|---|---|
| 新しい特徴量を作る | 日付から曜日、年齢から年代、購入履歴から購入回数などを作る |
| 数値を変換する | 極端な値の影響を減らすために、対数変換などを行うことがある |
| カテゴリを数値化する | 性別、地域、商品カテゴリなどをモデルが扱いやすい形に変える |
| 複数の情報を組み合わせる | 売上と来店数から客単価を作るなど、意味のある比率を作る |
| 不要な特徴量を減らす | 予測に関係が薄い情報やノイズになりやすい情報を整理する |
特徴量設計では、「何でも増やす」のではなく、予測したい目的に対して役に立つ情報を作ることが重要です。
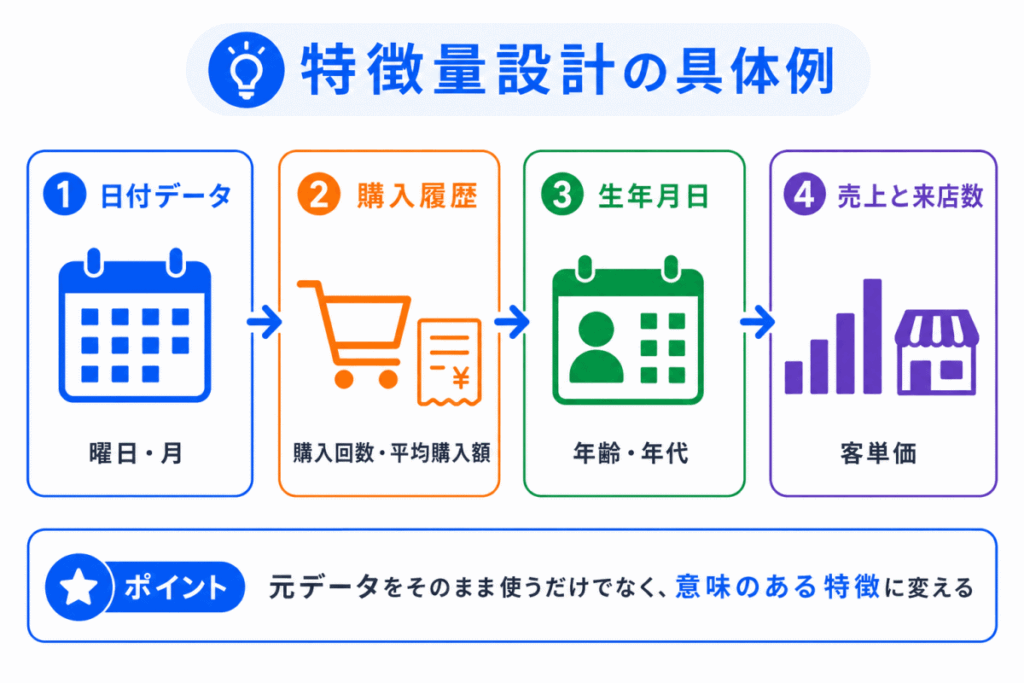
特徴量設計は、少し抽象的に感じやすい用語です。
具体例で見ると理解しやすくなります。
たとえば、日付データからは「曜日」、「月」、「祝日かどうか」などを作れます。これにより、曜日や季節による変化をAIが学習しやすくなります。
生年月日からは「年齢」や「年代」を作れます。購入履歴からは「購入回数」、「最終購入日」、「平均購入額」などを作れます。
アクセスログであれば、「閲覧回数」、「滞在時間」、「直近アクセス」などが特徴量になります。
このように、元データをそのまま使うだけでなく、予測したい目的に合わせて意味のある形に変えることが特徴量設計です。
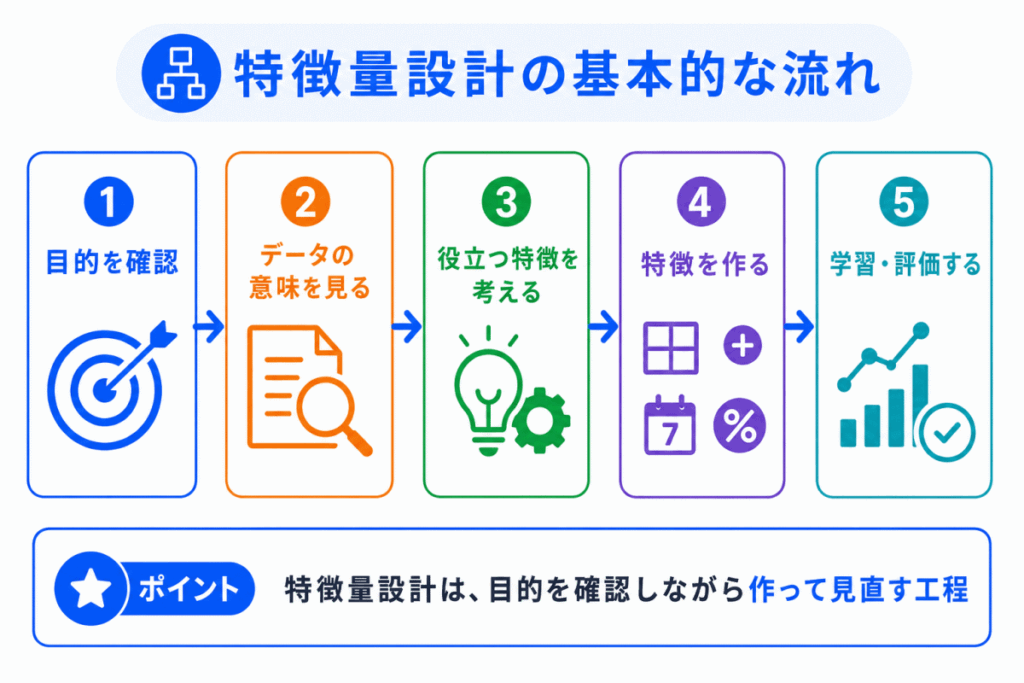
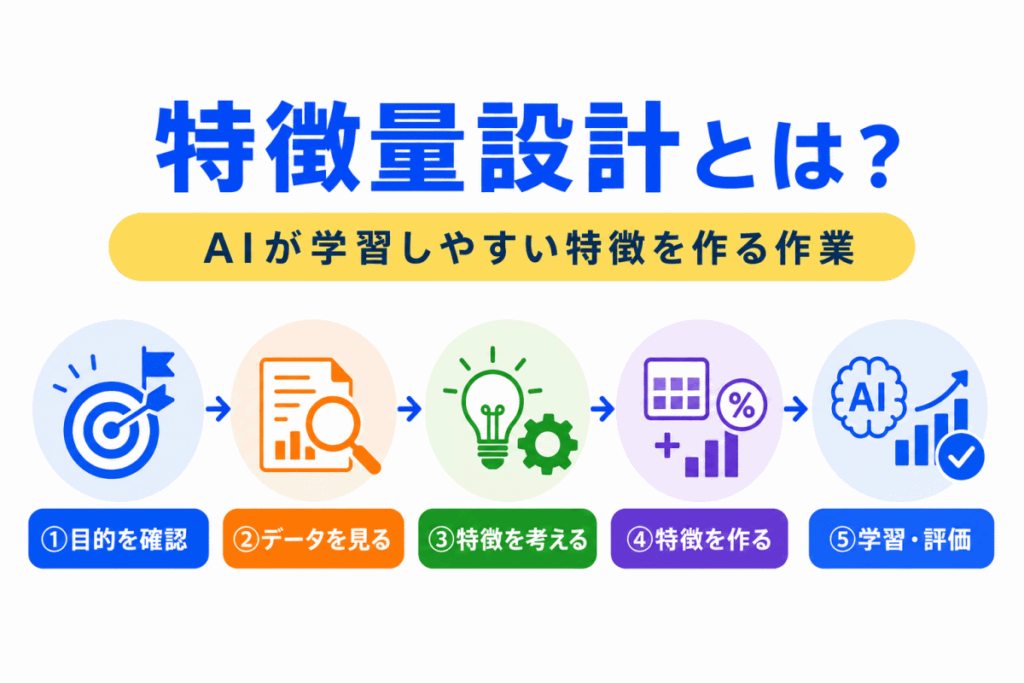
特徴量設計は、いきなり思いつきで特徴を作る作業ではありません。
予測したい目的を確認し、元データの意味を見ながら、役に立つ特徴を作っていきます。
基本的な流れは以下のようになります。
特徴量設計では、作った特徴量が本当に役に立っているかを評価することも大切です。
作って終わりではなく、モデル性能や汎化性能を見ながら調整していきます。
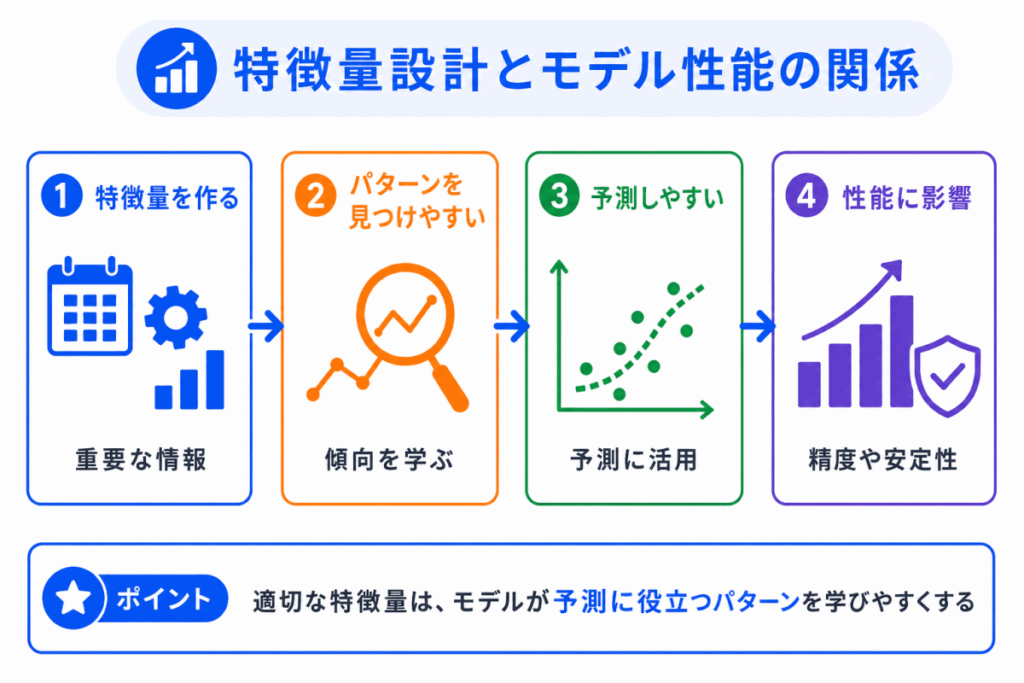
特徴量設計は、モデル性能に影響することがあります。
同じアルゴリズムを使っていても、入力する特徴量が変わると、学習できるパターンが変わるためです。
目的に合った特徴量があると、予測に役立つパターンを学習しやすくなります。
一方で、重要な情報が特徴量に含まれていないと、モデルが必要なパターンを学習しにくくなります。
また、不要な特徴量が多いと、ノイズまで学習してしまうことがあります。特徴量が多すぎると、学習データに合いすぎて、未知のデータに弱くなることもあります。
特徴量設計は、モデルを複雑にするための作業ではありません。
目的に合った情報を、モデルが学習しやすい形にするための作業です。
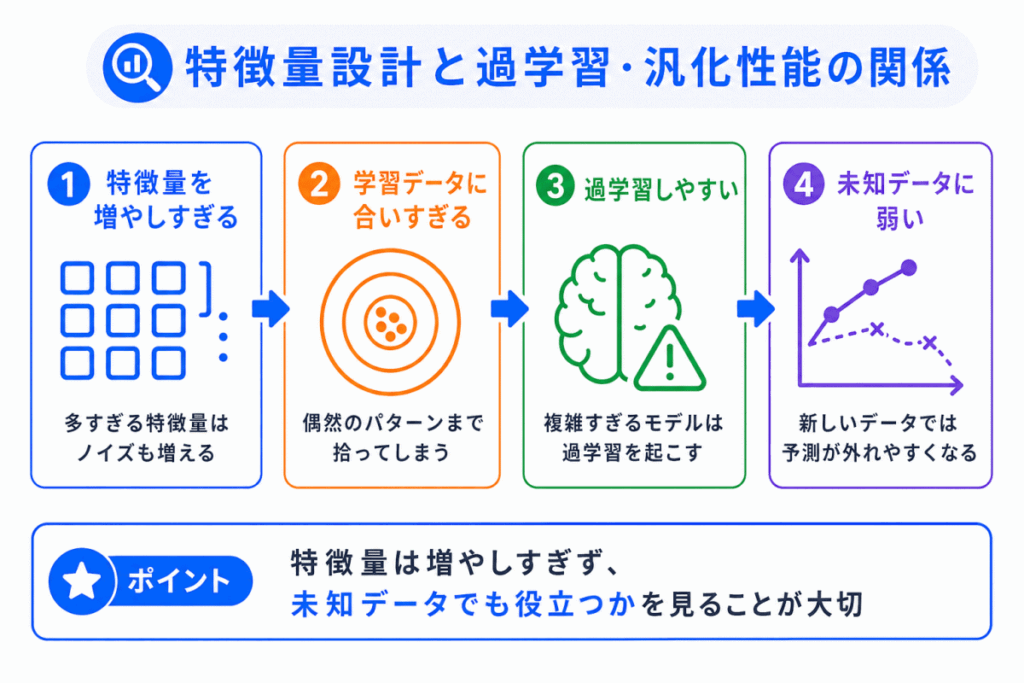
特徴量設計は、過学習や汎化性能とも関係します。
過学習とは、学習データに合いすぎて、未知のデータに弱くなる状態です。
特徴量を増やしすぎたり、学習データだけに偶然現れる特徴を使ったりすると、過学習につながることがあります。
たとえば、学習データではたまたま当てはまる特徴をモデルが強く覚えてしまうと、学習データでは高い性能に見えることがあります。
しかし、その特徴が新しいデータでは役に立たない場合、本番ではうまく予測できません。
特徴量設計では、学習データでの性能だけでなく、未知のデータでもうまく予測できるかを意識する必要があります。
そのため、交差検証や評価指標とあわせて理解すると、特徴量設計の意味がつかみやすくなります。
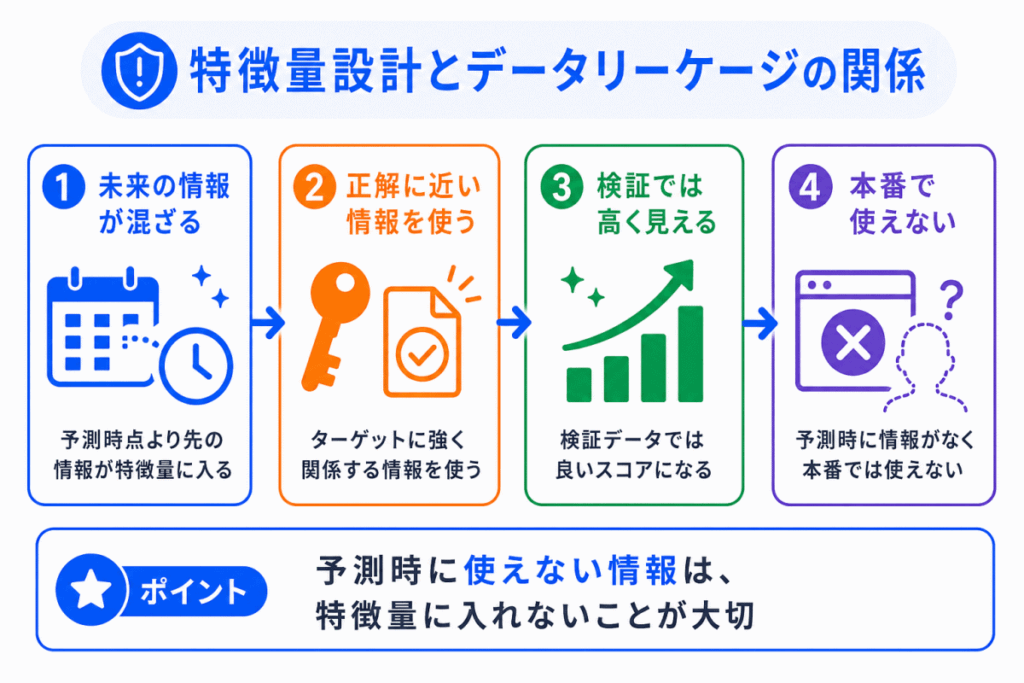
特徴量設計で注意したいのが、データリーケージです。
データリーケージとは、本来は予測時に使えない情報が、学習データに混ざってしまうことです。
たとえば、退会を予測するモデルを作るときに、「退会日」や「退会後の行動」を特徴量に入れてしまうと、正解に近い情報を使って学習してしまうことになります。
特徴量設計とデータリーケージの関係は、以下のように整理できます。
| 観点 | 注意点 |
|---|---|
| 未来の情報 | 予測時点ではまだわからない情報を特徴量に入れない |
| 正解に近すぎる情報 | 目的変数を直接示すような情報を特徴量に入れない |
| 学習時だけ使える情報 | 本番運用で取得できない情報を特徴量に入れない |
データリーケージが起きると、学習時や検証時の性能は高く見えるのに、本番ではうまく予測できないことがあります。
特徴量設計では、「その情報は予測時点で本当に使えるのか?」を確認することが大切です。
G検定では、特徴量設計だけを細かい実装手順として問うよりも、機械学習の流れやモデル性能との関係で問われる可能性があります。
押さえるポイントは以下の通りです。
| 問われやすい観点 | 押さえるポイント |
|---|---|
| 特徴量の意味 | モデルが学習に使う入力項目のこと |
| 特徴量設計の意味 | AIが学習しやすい特徴を作る作業 |
| データ前処理との違い | 前処理は整える作業、特徴量設計は特徴を作る作業 |
| モデル性能との関係 | 適切な特徴量は、予測に役立つパターンの学習を助ける |
| 過学習との関係 | 不要な特徴量や多すぎる特徴量は、過学習につながることがある |
| データリーケージとの関係 | 予測時点で使えない情報を特徴量に入れないことが重要 |
G検定対策では、特徴量設計を単独で暗記するよりも、データ前処理、過学習、汎化性能、評価指標、データリーケージとつなげて理解しておくと整理しやすくなります。
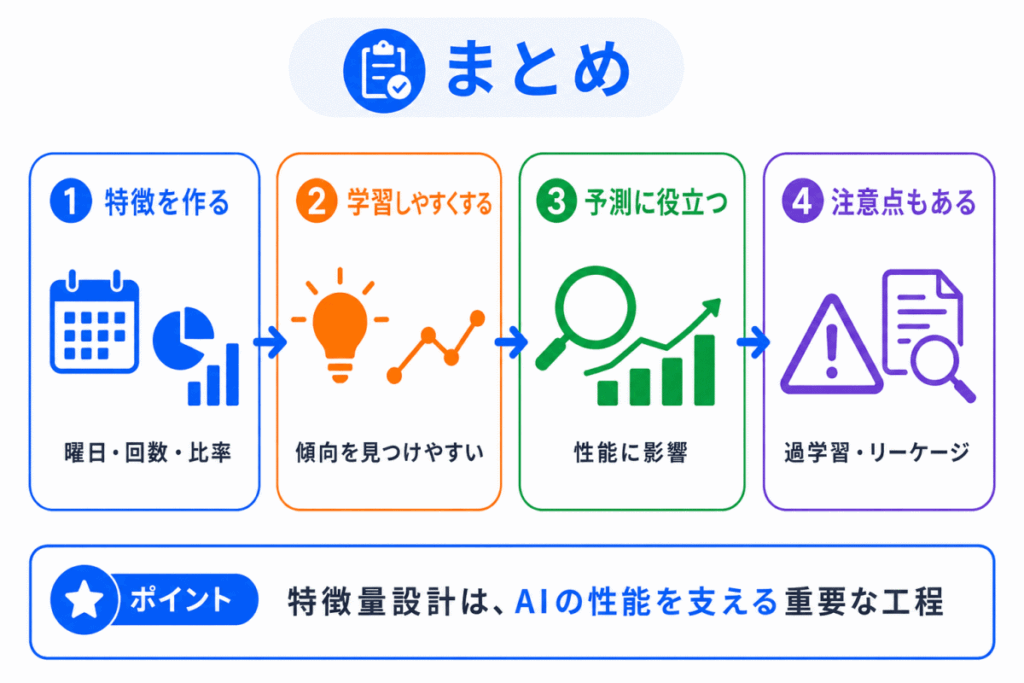
特徴量設計とは、AIが学習しやすいように、データから役に立つ特徴を作る作業です。
データ前処理が「データを使える形に整える作業」だとすると、特徴量設計は「AIが学習しやすい見方を作る作業」です。
まとめると、以下のようになります。
| 項目 | 押さえるポイント |
|---|---|
| 特徴量 | モデルが学習に使う入力項目 |
| 特徴量設計 | AIが学習しやすい特徴を作る作業 |
| データ前処理との違い | 前処理は整える、特徴量設計は特徴を作る |
| モデル性能との関係 | 適切な特徴量は、予測に役立つパターンの学習を助ける |
| 注意点 | 特徴量を増やしすぎると、過学習やデータリーケージにつながることがある |
特徴量設計は、AIの性能を支える重要な工程です。
特に表形式データや業務データでは、どの情報をどの形でAIに渡すかが、学習のしやすさや予測の安定性に大きく関係します。
G検定では、特徴量設計を「AIが学習しやすい特徴を作る作業」と押さえたうえで、データ前処理や過学習との違い・関係を整理しておきましょう。
データ前処理と特徴量設計の違いを整理すると、AI開発の前工程が理解しやすくなります。
データの良し悪しを先に理解すると、なぜ特徴量設計の前に確認が必要なのかが見えやすくなります。

特徴量設計は、教師あり学習の予測問題と特に関係します。分類・回帰とのつながりも確認しておくと理解しやすくなります。
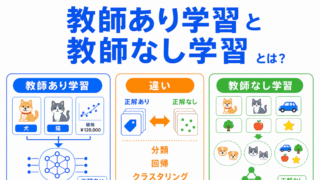
特徴量を増やしすぎると、学習データに合いすぎることがあります。過学習との関係もあわせて確認しておきましょう。
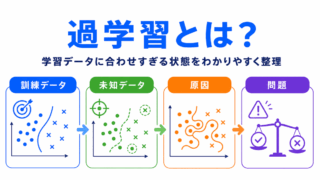
特徴量設計は、過学習や未学習の原因とも関係します。バイアスと分散の考え方とつなげると整理しやすくなります。
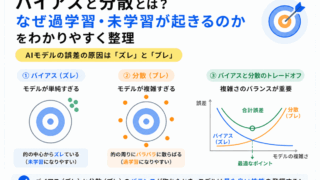
作った特徴量が本当に役立つかを確認するには、評価方法の理解も必要です。
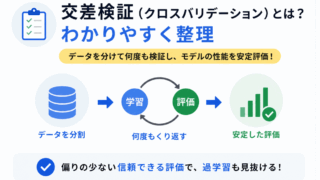
特徴量設計の効果は、最終的に評価指標で確認します。精度・適合率・再現率の違いも押さえておきましょう。
重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認