【G検定対策】PoCとは?|AI導入前に効果を検証する考え方をわかりやすく整理
seo-webmaster
G検定対策ブログ
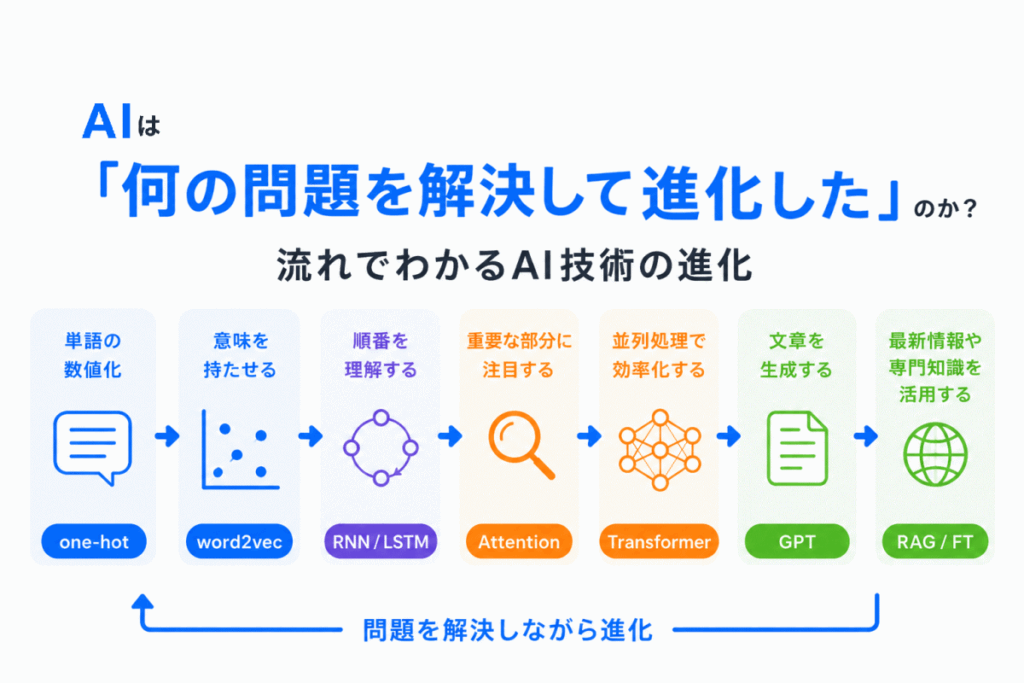
G検定(AI)の用語を学んでいると、CNN・RNN・Transformer・GPT・RAGなど、次々に新しい言葉が出てきて「結局何が違うの?」と混乱しやすくなります。
ですが、AI技術は バラバラに生まれたわけではありません。
実際は、前の技術で起きた問題を解決するために、次の技術が生まれるという流れを繰り返して進化してきました。
この流れがわかると、AIの学習は一気に整理しやすくなります。
単なる用語暗記ではなく「何に困って、どう改善したのか?」で理解できるからです。
これはG検定では非常に重要で、単語だけを覚えるよりも、技術同士のつながりや進化の理由を理解している方が、問い方が変わっても対応しやすくなります。
この記事では、AIの進化を「問題 → 解決」の流れで整理しながら、AI技術がどう発展してきたのかをわかりやすく解説します。
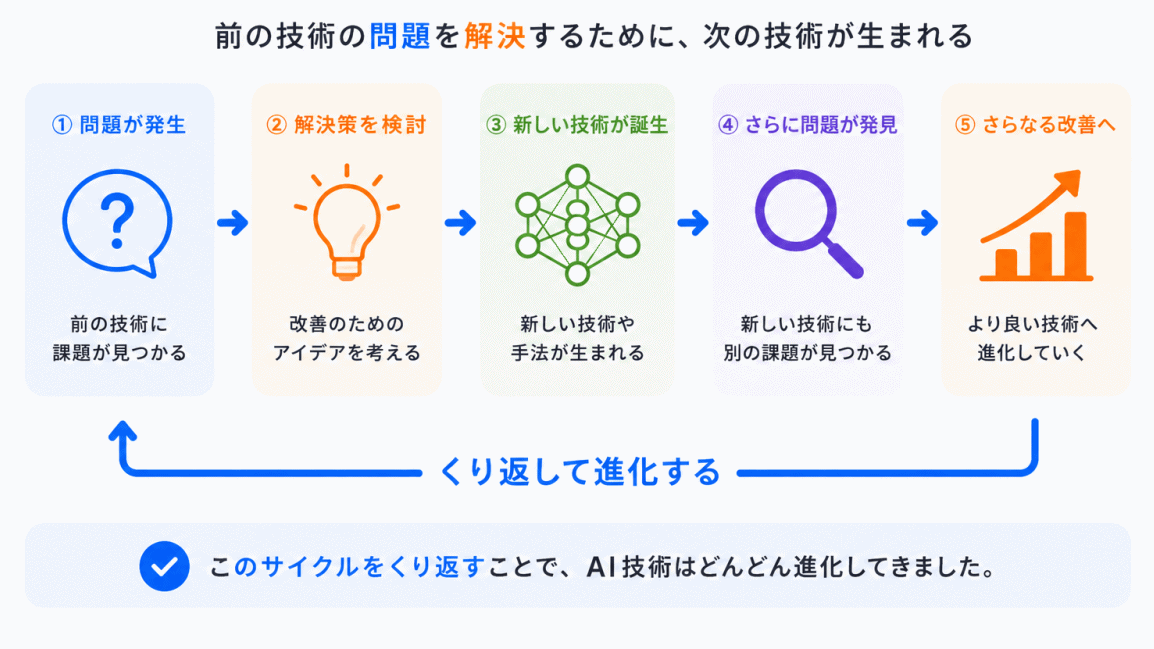
AI技術は、いきなり今の形になったわけではありません。
基本的には、次の流れを何度も繰り返しています。
つまり
AIの進化 = 問題解決の歴史
とも言えます。
これを知ると、AI用語が「単なる暗記対象」ではなく、前後関係のある流れとして理解できるようになります。
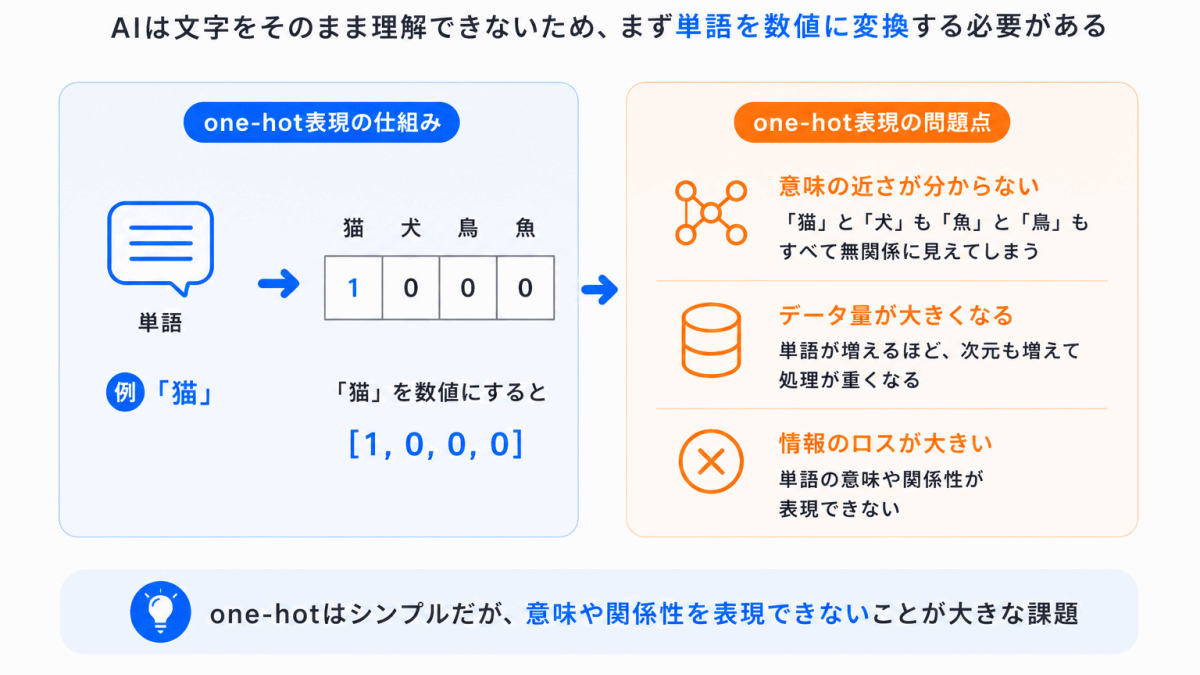
AIは文字をそのまま理解できません。
まずは「単語を数値化する」必要がありました。
例えば「猫」という単語を
0, 0, 1, 0, 0 …
のような数字に変換します。
これはシンプルですが、大きな問題がありました。
ここで生まれたのが
です。
これにより
として表現できるようになりました。
つまり
「単語を数値にする」から「意味を持った数値にする」へ進化した
のです。
> 単語埋め込み(Embedding)とは?(サイト内リンク)
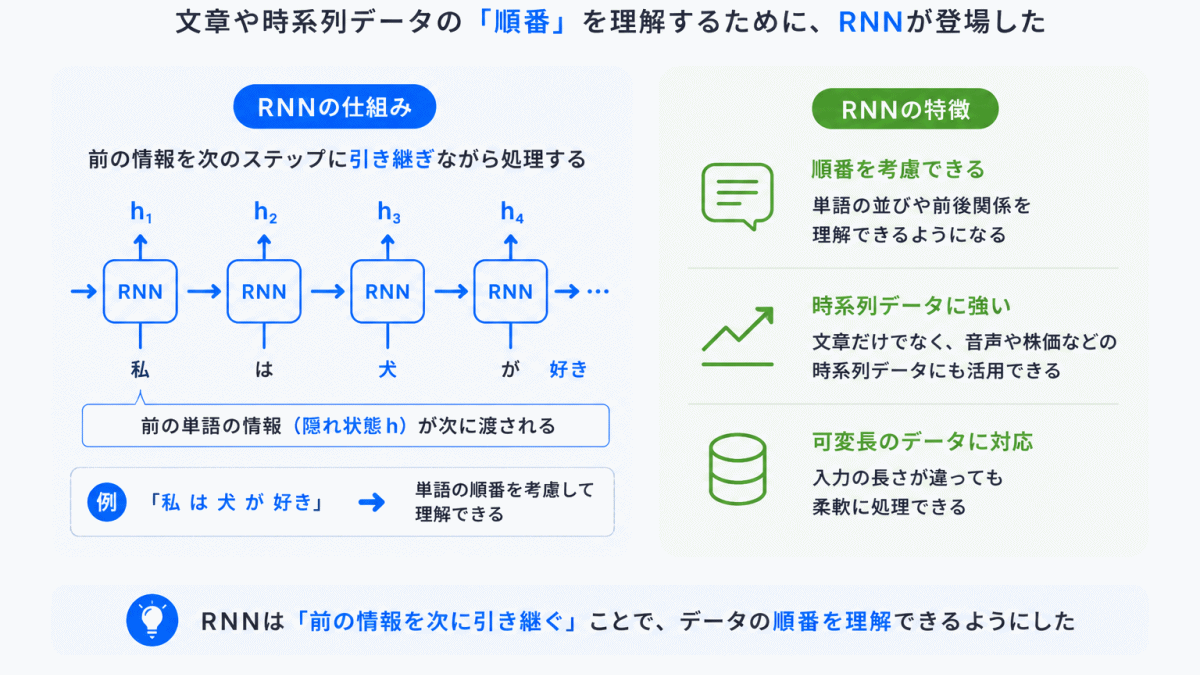
単語を数値にできても、次の問題がありました。
「順番」が重要な文章をどう扱うのか?
例えば
同じ単語でも意味が変わります。
RNNは 前の情報を次に引き継ぐ 仕組みを持っていました。
これにより、文章の順番を考慮できるようになりました。
しかし、問題もありました。
> CNN・RNN・Transformerとは?(サイト内リンク)
文章が長くなると…
という問題が出ました。
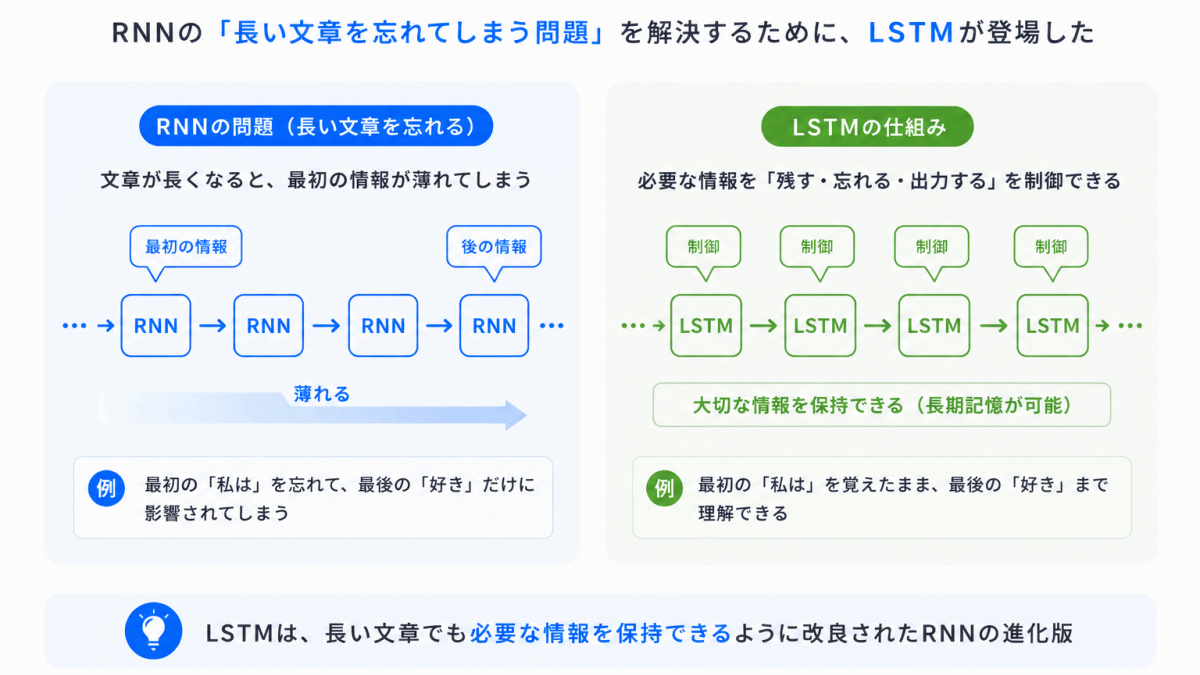
RNNの弱点を改善するために生まれたのが LSTM です。
LSTMは
を制御する仕組みを持ちました。
これにより、長い文章でも以前より情報を保持しやすくなりました。
でも、まだ問題がありました。
LSTMは順番に処理するため
という問題がありました。
ここで生まれたのが Attention です。
Attentionは 全部を均等に見るのではなく、重要な場所に注目する という考え方です。
例えば「私は昨日買った本を読んだ」なら「読んだ」が何に関係するかを重点的に見ます。
これにより、長い文章の理解がかなり改善しました。
> Attentionとは?(サイト内リンク)
Attentionは優秀でしたが、さらに進化したのが Transformer です。
Transformerは
という特徴を持ちました。ここでAIは大きく進化します。
この技術が後の生成AIの土台になります。
> Transformerとは?(サイト内リンク)
Transformerの次に登場したのが GPT です。
GPTは
できるようになりました。
ここでAIは「分類するAI」から「生成するAI」へ大きく進化しました。
> GPTとは?(サイト内リンク)
しかし、問題もあります。
GPTは
という問題があります。
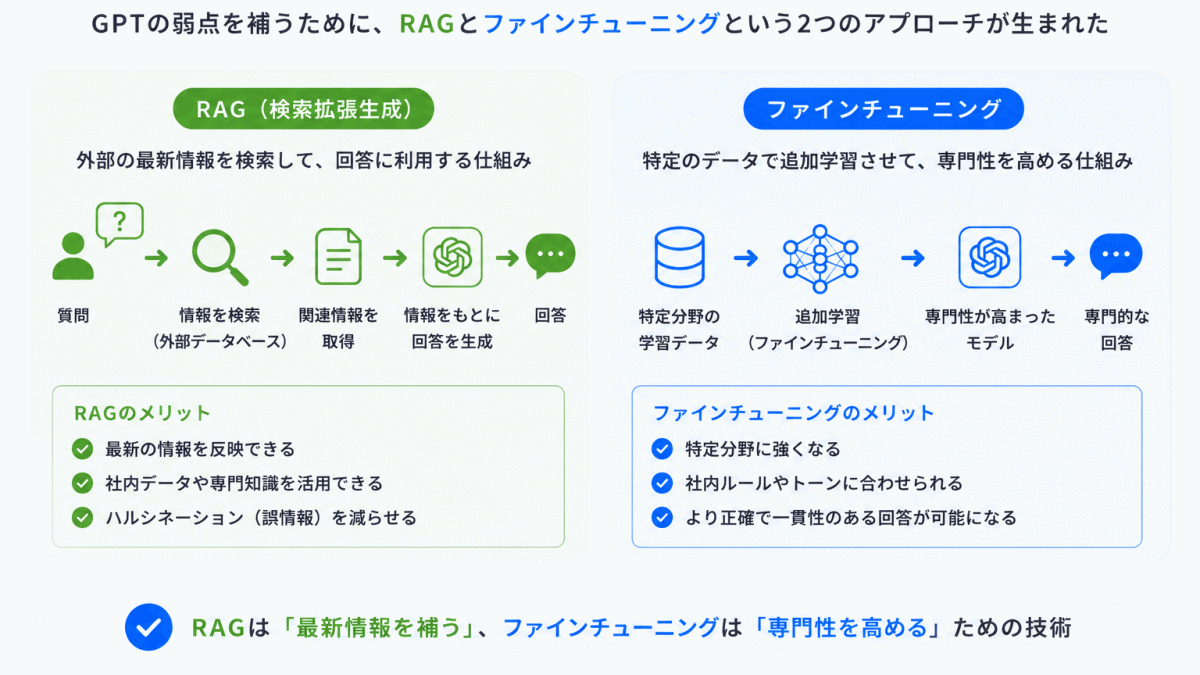
GPTの弱点を改善するために次の技術が生まれました。
外部情報を検索して使う → 最新情報に強い
> RGAとは?(サイト内リンク)
特定分野で再学習する → 専門化できる
> ファインチューニングとは?(サイト内リンク)
つまり、GPT単体の弱点を補う技術 として使われています。
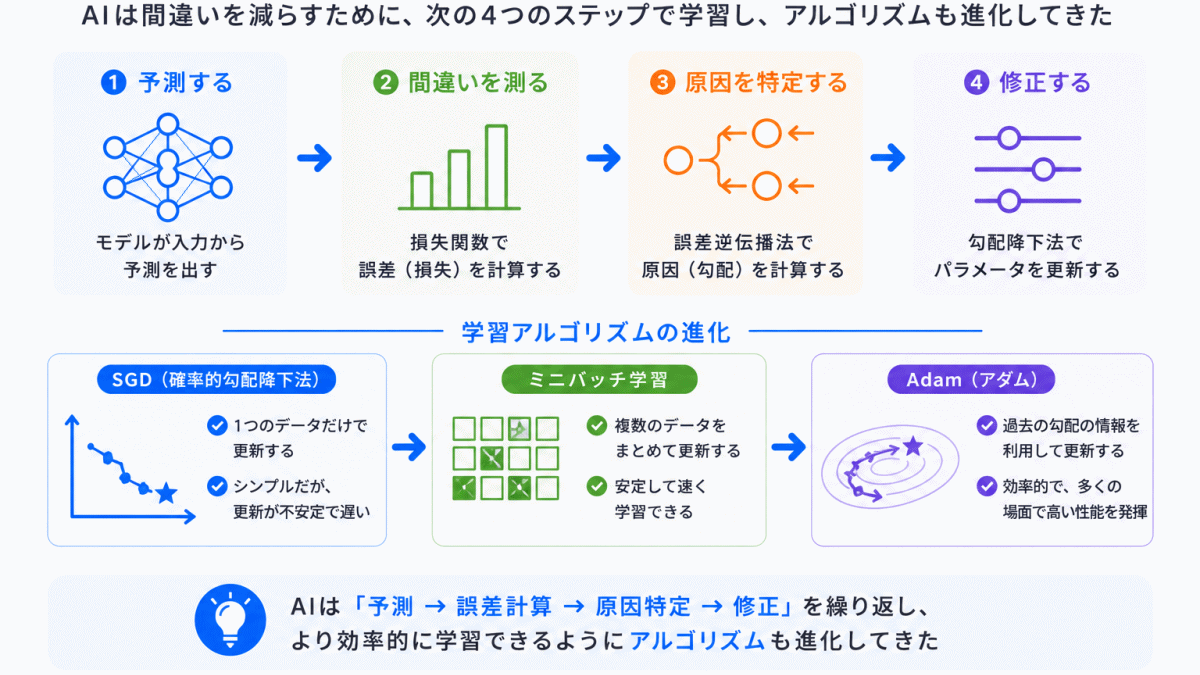
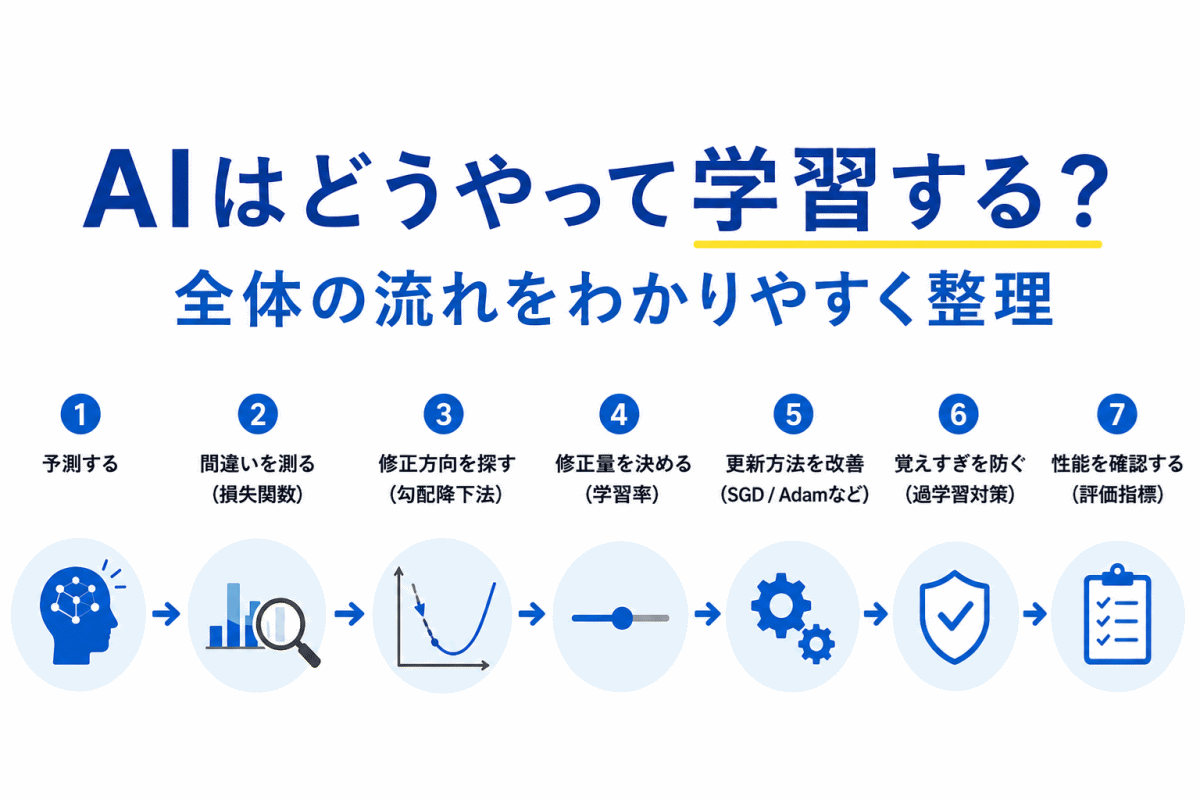
AIは予測するだけでは終わりません。
問題は どう修正するか です。
ここで必要になったのが
です。
でもこれも課題がありました。
普通の勾配降下法は
という問題がありました。
> 勾配降下法とは?(サイト内リンク)
少しずつ更新する
> SGD(確率的勾配降下法)とは?(サイト内リンク)
一部データごとに学習する
> ミニバッチとは?(サイト内リンク)
学習をより安定化・効率化する
> Adamとは?(サイト内リンク)
つまり、AIの「修正方法」も進化してきた のです。
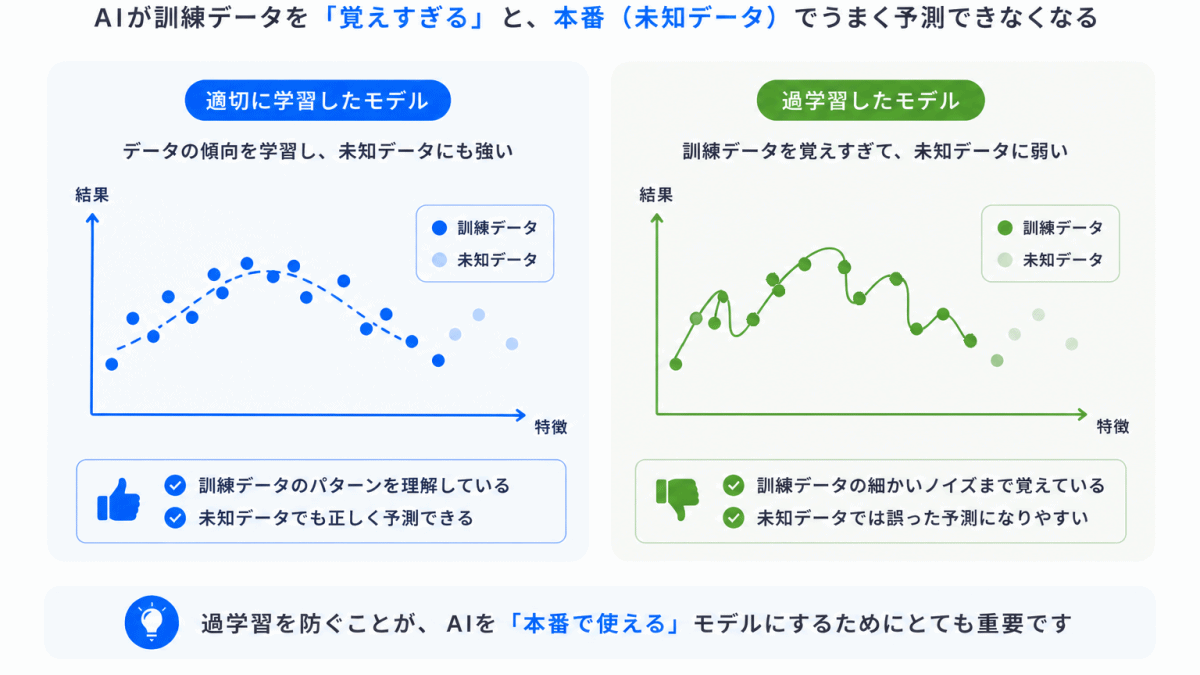
AIは学習すればするほど良い… とは限りません。
問題は 覚えすぎる ことです。これを 過学習 と言います。
過学習すると
という問題が起きます。
> 過学習とは?(サイト内リンク)
これを防ぐために
が使われます。
つまり、覚えすぎないようにする技術 が必要になったのです。
> 正則化とは?(サイト内リンク)
> ドロップアウトとは?(サイト内リンク)

最後の問題は 評価 です。
「正解率が高い = 良いAI」とは 限りません。
例えば医療AIなら 病気を見逃す方が危険です。
そこで
が使い分けられます。
つまり、目的に応じて評価方法も進化した のです。
> 精度・適合率・再現率とは?(サイト内リンク)
> 評価指標の使い分け方は?(サイト内リンク)
G検定では、この流れをそのまま問うというより「前の技術の弱点を次の技術がどう改善したか?」という形で出題されることがあります。
例えば
このため、単語単体ではなく「何の問題を解決した技術なのか」で覚えることが重要です。

AIの学習をはじめたばかりの人は、用語を1つずつ暗記しようとして混乱しやすいです。
でも本当は、AIは
の流れで進化しています。
この流れで理解すると
という大きなメリットがあります。
これはかなり重要な考え方です。
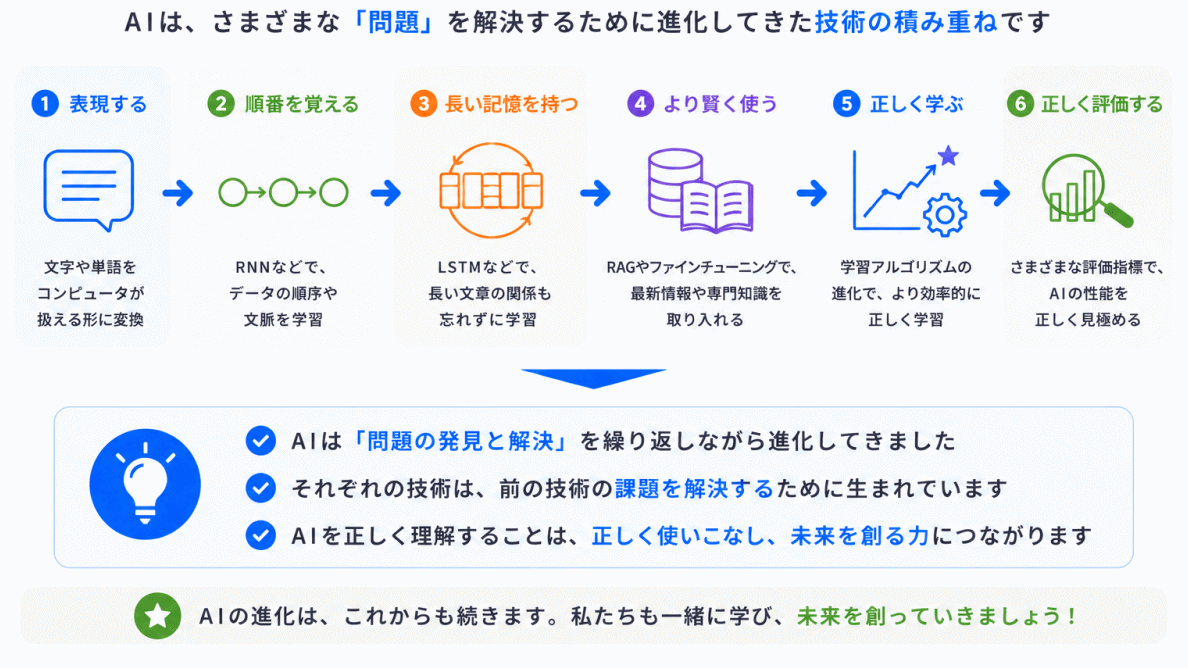
AI技術は、突然すごい技術が生まれて進化したわけではありません。
実際は、前の技術の問題を解決するために、次の技術が生まれる という流れの連続です。
この流れが見えると、AI用語はバラバラな暗記ではなく、「なぜ生まれたのか」で理解できるようになります。
AIを学ぶときは、単語を覚えるより「何の問題を解決したのか?」を見ることが、理解への近道です。
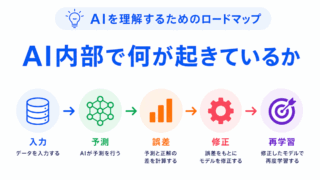
AIの内部で何が起きているのかをまとめました。
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。