【2026年初旬版】G検定はどの分野からどのくらい出る?受験者目線で割合を整理してみた
seo-webmaster
G検定対策ブログ
G検定では、機械学習の基本的な考え方や、教師あり学習・教師なし学習・強化学習の違いがよく問われます。
特に、分類・回帰・クラスタリング、学習データ・テストデータ、過学習・汎化性能、モデル・アルゴリズム・パラメータなどは、用語だけを見ると混同しやすい分野です。
この記事では、「機械学習の概要」に関する重要用語を、試験前に確認しやすいように短く整理します。
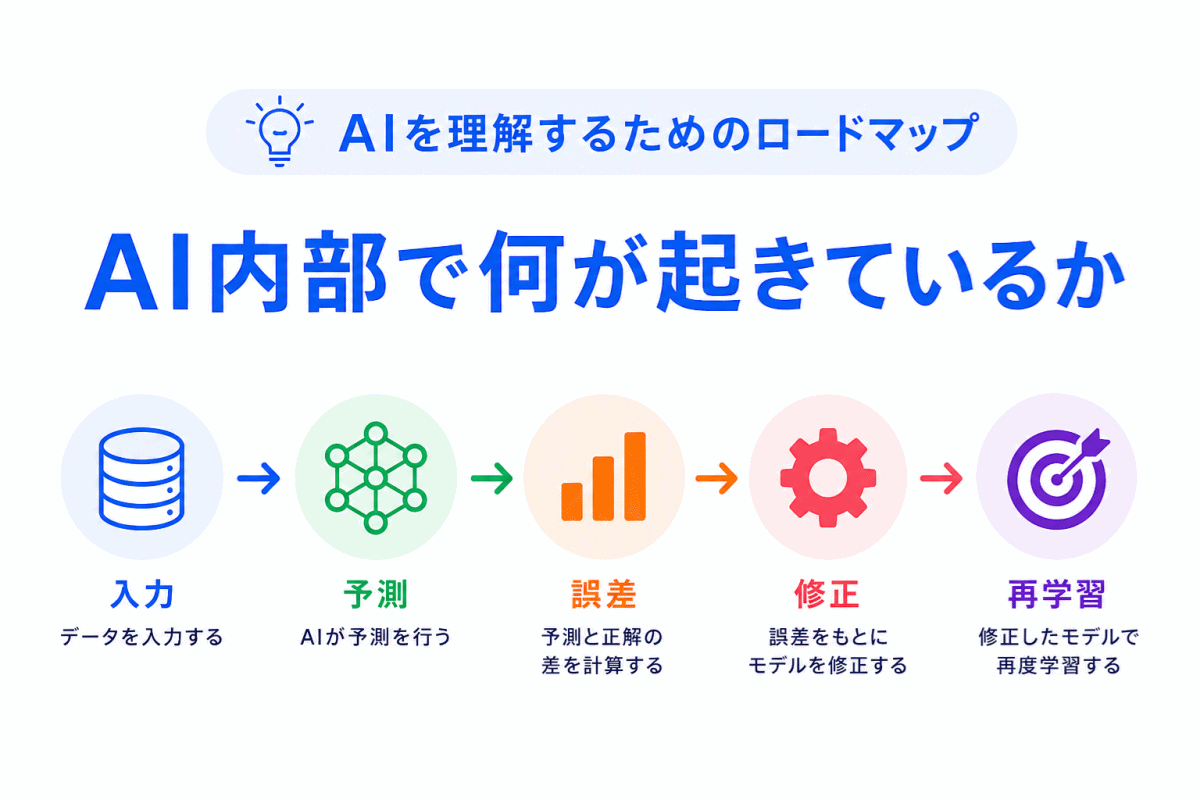
「機械学習の概要」は、AIがデータからどのように学習し、予測や判断を行うのかを整理する分野です。
機械学習では、人間がすべてのルールを手作業で決めるのではなく、データからパターンを学習します。そのため、教師あり学習・教師なし学習・強化学習の違いや、分類・回帰・クラスタリングの役割を押さえることが大切です。
細かいアルゴリズムを丸暗記するよりも、まずは 「何を学習するのか」、「正解データがあるのか」、「何を予測するのか」 を整理すると理解しやすくなります。
| 見るポイント | 押さえる内容 |
|---|---|
| 機械学習の基本 | データからパターンを学ぶ考え方 |
| 学習の種類 | 教師あり学習・教師なし学習・強化学習の違い |
| 予測の種類 | 分類・回帰・クラスタリングの違い |
| データの分け方 | 学習データ・検証データ・テストデータ |
| モデルの性能 | 汎化、過学習、未学習 |
| 代表的な手法 | 回帰、決定木、SVM、k-meansなど |
まずは、機械学習そのものに関する基本用語です。
G検定では、モデル・アルゴリズム・パラメータ・ハイパーパラメータの違いが混同しやすいポイントです。
| 用語 | 一言でいうと |
|---|---|
| 機械学習 | データからパターンやルールを学ぶ方法 |
| モデル | データから学んだ予測や判断の仕組み |
| アルゴリズム | 学習や予測を行うための手順 |
| パラメータ | 学習によって調整される値 |
| ハイパーパラメータ | 学習前に人間が設定する値 |
| 特徴量 | 予測に使うデータの特徴 |
| ラベル | 教師あり学習で使う正解データ |
| 学習 | データから規則性を見つけること |
| 推論 | 学習済みモデルを使って予測すること |
| 予測 | 入力データから結果を出すこと |
| 目的変数 | 予測したい対象 |
| 説明変数 | 予測に使う情報 |
| データセット | 学習や評価に使うデータの集まり |
モデルとアルゴリズムは似ていますが、モデルは「学習後にできた予測の仕組み」、アルゴリズムは「学習するための手順」と考えると整理しやすくなります。
機械学習では、学習方法を大きく 教師あり学習・教師なし学習・強化学習 に分けて考えます。
| 用語 | 一言でいうと |
|---|---|
| 教師あり学習 | 正解データを使って学習する方法 |
| 教師なし学習 | 正解データなしでデータの構造を見つける方法 |
| 強化学習 | 報酬をもとに行動を改善する学習 |
| 半教師あり学習 | 少量の正解データと大量の正解なしデータを使う学習 |
| 自己教師あり学習 | データ自身から擬似的な正解を作って学習する方法 |
| 教師データ | 入力と正解がセットになったデータ |
| 正解ラベル | 教師あり学習で使う正解 |
| 報酬 | 強化学習で行動の良し悪しを示す値 |
| エージェント | 強化学習で行動する主体 |
| 環境 | エージェントが行動する対象や場 |
特に重要なのは、教師あり学習・教師なし学習・強化学習の違いです。
| 学習方法 | 見分け方 |
|---|---|
| 教師あり学習 | 正解データがある |
| 教師なし学習 | 正解データがない |
| 強化学習 | 報酬をもとに行動を改善する |
G検定では、「この例はどの学習方法か」を問われることがあるため、正解ラベルの有無や報酬の有無で判断できるようにしておきましょう。
教師あり学習では、入力データと正解データのペアを使って学習します。
代表的なタスクは、分類と回帰です。
| 用語 | 一言でいうと |
|---|---|
| 教師あり学習 | 正解データを使って学習する方法 |
| 分類 | データをカテゴリに分けること |
| 回帰 | 数値を予測すること |
| 二値分類 | 2つのクラスに分ける分類 |
| 多クラス分類 | 3つ以上のクラスに分ける分類 |
| 線形回帰 | 直線で数値を予測する方法 |
| ロジスティック回帰 | 分類に使われる回帰系の手法 |
| k近傍法 | 近くのデータを参考に分類する方法 |
| 決定木 | 条件分岐で予測する方法 |
| ランダムフォレスト | 複数の決定木を組み合わせる方法 |
| SVM | 境界線をうまく引いて分類する方法 |
| ナイーブベイズ | 確率をもとに分類する方法 |
| 勾配ブースティング | 弱いモデルを順に改善していく方法 |
| アンサンブル学習 | 複数のモデルを組み合わせる方法 |
分類と回帰は特に混同しやすいです。
| 用語 | 見分け方 |
|---|---|
| 分類 | カテゴリを予測する |
| 回帰 | 数値を予測する |
たとえば、メールが迷惑メールかどうかを判断するのは分類、住宅価格を予測するのは回帰です。
教師なし学習では、正解データを使わずに、データの構造や似ているグループを見つけます。
| 用語 | 一言でいうと |
|---|---|
| 教師なし学習 | 正解データなしでデータの構造を見つける方法 |
| クラスタリング | 似たデータをグループに分けること |
| k-means | データをk個のグループに分ける方法 |
| 階層的クラスタリング | 階層構造でデータをまとめる方法 |
| 次元削減 | 情報を保ちながら特徴量の数を減らすこと |
| 主成分分析 | データのばらつきをよく表す軸に変換する方法 |
| PCA | 主成分分析のこと |
| t-SNE | 高次元データを可視化しやすくする方法 |
| 自己組織化マップ | 似たデータを近くに配置する方法 |
| アソシエーション分析 | 一緒に起きやすい関係を見つける方法 |
| 外れ値検知 | 通常とは異なるデータを見つけること |
教師なし学習では、分類とクラスタリングの違いが重要です。
| 用語 | 見分け方 |
|---|---|
| 分類 | 正解ラベルを使ってカテゴリを予測する |
| クラスタリング | 正解ラベルなしで似たデータをまとめる |
クラスタリングは「分ける」という意味では分類に似ていますが、正解ラベルを使わない点が大きな違いです。
強化学習では、エージェントが環境の中で行動し、報酬をもとによりよい行動を学習します。
| 用語 | 一言でいうと |
|---|---|
| 強化学習 | 報酬をもとに行動を改善する学習 |
| エージェント | 行動する主体 |
| 環境 | エージェントが行動する場 |
| 状態 | 現在の状況 |
| 行動 | エージェントが選ぶ動き |
| 報酬 | 行動の良し悪しを示す値 |
| 方策 | どの状態でどの行動を選ぶかのルール |
| 価値関数 | 将来得られる報酬の見込み |
| Q学習 | 行動の価値を学習する強化学習 |
| マルコフ決定過程 | 状態・行動・報酬で考える強化学習の枠組み |
| 探索 | 新しい行動を試すこと |
| 活用 | すでに良いとわかっている行動を選ぶこと |
強化学習は、教師あり学習のように正解ラベルを直接与えるのではなく、行動の結果として得られる報酬をもとに学習します。
機械学習では、モデルを作るためのデータと、性能を確認するためのデータを分けます。
| 用語 | 一言でいうと |
|---|---|
| 学習データ | モデルを学習させるためのデータ |
| 訓練データ | 学習データとほぼ同じ意味 |
| 検証データ | モデル調整に使う確認用データ |
| テストデータ | 最終的な性能評価に使うデータ |
| ホールドアウト法 | データを学習用と評価用に分ける方法 |
| 交差検証 | データを分けて複数回評価する方法 |
| k分割交差検証 | データをk個に分けて評価する方法 |
| データリーク | 評価用データの情報が学習に混ざること |
| 前処理 | 学習しやすい形にデータを整えること |
| 正規化 | データのスケールをそろえること |
| 標準化 | 平均0、分散1に近づけること |
| 欠損値 | データが抜けている値 |
| 外れ値 | 他のデータから大きく外れた値 |
学習データとテストデータを混ぜてしまうと、正しく性能を評価できません。
そのため、データを分ける考え方は、評価指標や過学習ともつながります。
機械学習では、学習データに対する成績だけでなく、未知のデータに対応できるかが重要です。
| 用語 | 一言でいうと |
|---|---|
| 汎化 | 未知のデータにも対応できること |
| 汎化性能 | 未知データへの対応力 |
| 過学習 | 学習データに合わせすぎること |
| 未学習 | モデルが十分に学習できていない状態 |
| バイアス | 正解からのズレ |
| 分散 | データによる予測のブレ |
| バイアス・バリアンストレードオフ | 単純すぎても複雑すぎても性能が落ちる関係 |
| 正則化 | モデルが複雑になりすぎるのを抑える方法 |
| L1正則化 | 不要な特徴量を0にしやすい正則化 |
| L2正則化 | 重みを小さく抑える正則化 |
| 早期終了 | 性能が悪化する前に学習を止める方法 |
| データ拡張 | データを増やしたように扱う方法 |
過学習と未学習は、次のように整理できます。
| 用語 | 状態 |
|---|---|
| 過学習 | 学習データに合わせすぎて、未知データに弱い |
| 未学習 | 学習が足りず、学習データにも未知データにも弱い |
G検定では、過学習の原因や対策も問われやすいため、正則化や交差検証とセットで確認しておくとよいです。
モデルの性能を見るときは、単純な正解率だけでなく、目的に応じた評価指標を使います。
| 用語 | 一言でいうと |
|---|---|
| 評価指標 | モデルの性能を測るための指標 |
| 精度 | 全体の正解率 |
| 適合率 | 陽性と予測した中で本当に陽性だった割合 |
| 再現率 | 実際の陽性をどれだけ拾えたか |
| F1値 | 適合率と再現率のバランス |
| 混同行列 | 予測と実際の結果を表にしたもの |
| TP | 陽性を正しく陽性と予測 |
| FP | 陰性を誤って陽性と予測 |
| FN | 陽性を誤って陰性と予測 |
| TN | 陰性を正しく陰性と予測 |
| ROC曲線 | 閾値を変えたときの性能を見る曲線 |
| AUC | ROC曲線の下の面積 |
評価指標は、「何を避けたいか」で使い分けます。
| 指標 | 使う場面 |
|---|---|
| 精度 | データの偏りが少ないとき |
| 適合率 | 誤判定を減らしたいとき |
| 再現率 | 見逃しを減らしたいとき |
| F1値 | 適合率と再現率を両方見たいとき |
この分野では、機械学習の種類や、似た用語の違いが問われやすいです。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| 教師あり学習 | 正解ラベルを使う |
| 教師なし学習 | 正解ラベルを使わない |
| 強化学習 | 報酬をもとに行動を改善する |
| 分類 | カテゴリを予測する |
| 回帰 | 数値を予測する |
| クラスタリング | 似たデータをグループ化する |
| 過学習 | 学習データに合わせすぎる |
| 汎化性能 | 未知データへの対応力 |
| パラメータ | 学習で調整される値 |
| ハイパーパラメータ | 学習前に人間が設定する値 |
| 適合率 | 誤判定を減らしたいときに重視 |
| 再現率 | 見逃しを減らしたいときに重視 |
特に、教師あり学習・教師なし学習・強化学習、分類・回帰・クラスタリング、過学習・汎化性能は、セットで整理しておくと対応しやすくなります。
「機械学習の概要」は、G検定の中でも土台になる分野です。教師あり学習、教師なし学習、強化学習の違いを理解すると、分類・回帰・クラスタリング、過学習、評価指標なども整理しやすくなります。
試験前は、細かいアルゴリズムをすべて深く覚えるよりも
という大きな違いをまず確認しておきましょう。
用語の意味をもう少し詳しく確認したい場合は、関連する解説記事もあわせて確認しておきましょう。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 8分野別の記事一覧 | G検定8分野の分類/苦手分野別の記事確認/作成済み記事一覧/学習順の整理 |
| G検定理解ロードマップ | G検定の学習順序/8分野の入口/AIの全体像/機械学習・ディープラーニング・法律倫理の確認ルート |
| 機械学習とディープラーニングの違い | AI・機械学習・ディープラーニングの関係/特徴量設計/教師あり・教師なし・強化学習との違い |
| 教師あり・教師なし・強化学習の違い | 正解ラベルを使う学習/正解なしで構造を見る学習/報酬で行動を改善する学習 |
| CNN・RNN・Transformerの違い | CNNは画像/RNNは時系列/Transformerは文章・生成AIで重要になる理由 |
| 画像認識の歴史 | 画像認識の発展/CNN/AlexNet/ILSVRC/物体検出・セグメンテーションへの流れ |
| 生成AIリスクまとめ | ハルシネーション/著作権/個人情報/アルゴリズムバイアス/ディープフェイク/安全な生成AI活用 |
| AI倫理・AI法律とは? | AI倫理と法律の違い/個人情報/著作権/公平性/透明性/説明責任/AIを安全に使う考え方 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。