【G検定対策】試験前に確認したいAI・機械学習・生成AIの重要用語まとめ
seo-webmaster
SEO・ウェブマスターブログ
G検定では、ディープラーニングの全体像だけでなく、学習を成立させるための要素技術も問われます。
特に、活性化関数、損失関数、最適化手法、正則化、ドロップアウト、バッチ正規化、畳み込み、Attentionなどは、名前だけを見ると役割が混同しやすい分野です。
この記事では、「ディープラーニングの要素技術」に関する重要用語を、試験前に確認しやすいように短く整理します。
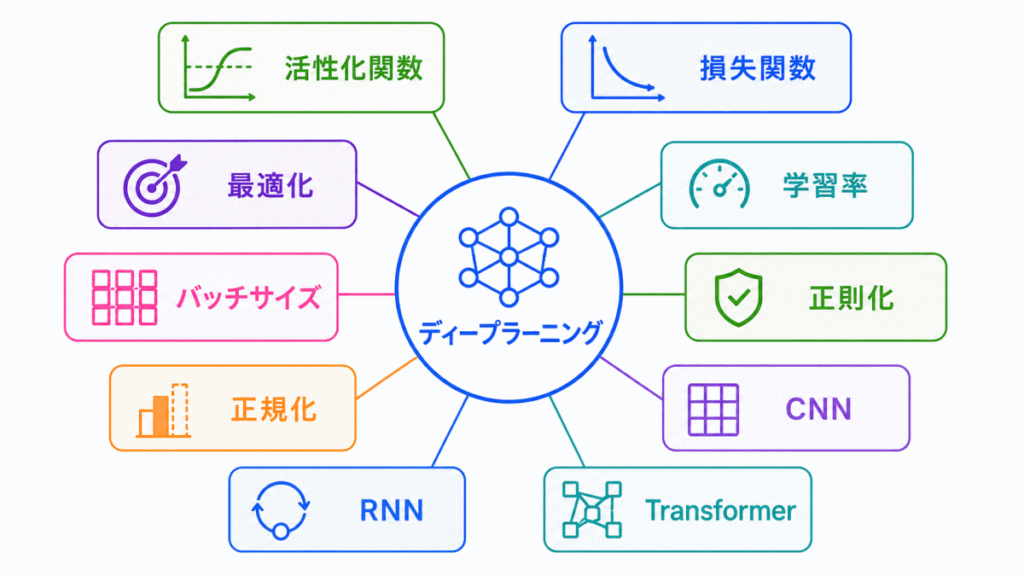
「ディープラーニングの要素技術」は、ニューラルネットワークをうまく学習させるための部品や工夫を整理する分野です。
ディープラーニングは、単に層を深くすればよいわけではありません。活性化関数で非線形性を加え、損失関数で間違いを測り、最適化手法で重みを更新し、正則化やドロップアウトで過学習を抑えます。
細かい数式を丸暗記するよりも、まずは 「何を測る技術なのか」「何を更新する技術なのか」「何を防ぐ技術なのか」 を整理すると理解しやすくなります。
| 見るポイント | 押さえる内容 |
|---|---|
| 活性化関数 | 出力を変換して非線形性を加える |
| 損失関数 | 予測と正解のズレを測る |
| 最適化手法 | 損失が小さくなるように重みを更新する |
| 過学習対策 | 汎化性能を高めるための工夫 |
| 正規化・標準化 | データや学習を安定させる処理 |
| CNNの要素技術 | 畳み込み、プーリング、特徴マップなど |
| 系列処理の技術 | RNN、LSTM、Attention、Transformerなど |
活性化関数は、ニューラルネットワークの出力を変換する関数です。
単純な直線的な変換だけでは複雑な関係を表せないため、活性化関数によって非線形性を加えます。
| 用語 | 一言でいうと |
|---|---|
| 活性化関数 | ノードの出力を変換する関数 |
| 非線形性 | 直線だけでは表せない性質 |
| ステップ関数 | しきい値を境に出力を切り替える関数 |
| シグモイド関数 | 出力を0〜1に変換する関数 |
| tanh関数 | 出力を-1〜1に変換する関数 |
| ReLU | 負の値を0、正の値をそのまま出す関数 |
| Leaky ReLU | 負の値も少し残すReLU |
| ソフトマックス関数 | 複数クラスの確率に変換する関数 |
| 恒等関数 | 入力をそのまま出力する関数 |
| 出力関数 | 出力層で使われる関数 |
活性化関数は、使われる場所で整理すると覚えやすくなります。
| 活性化関数 | 使われやすい場面 |
|---|---|
| ReLU | 隠れ層でよく使われる |
| シグモイド関数 | 二値分類や0〜1の出力 |
| ソフトマックス関数 | 多クラス分類の出力層 |
| 恒等関数 | 回帰の出力層 |
G検定では、ReLUがディープラーニングの学習を進めやすくした点も押さえておくとよいです。
損失関数は、モデルの予測がどれくらい間違っているかを測る関数です。
分類と回帰では、よく使われる損失関数が異なります。
| 用語 | 一言でいうと |
|---|---|
| 損失関数 | 予測と正解のズレを測る関数 |
| 誤差関数 | 損失関数とほぼ同じ意味で使われることがある |
| 目的関数 | 最小化または最大化したい関数 |
| 損失 | 予測の間違いの大きさ |
| 平均二乗誤差 | 回帰でよく使う損失関数 |
| MSE | 平均二乗誤差のこと |
| 交差エントロピー誤差 | 分類でよく使う損失関数 |
| バイナリ交差エントロピー | 二値分類で使われる損失関数 |
| カテゴリカル交差エントロピー | 多クラス分類で使われる損失関数 |
| 尤度 | データがそのモデルから生じるもっともらしさ |
損失関数は、タスクの種類とセットで整理すると覚えやすくなります。
| タスク | よく使われる損失関数 |
|---|---|
| 回帰 | 平均二乗誤差 |
| 二値分類 | バイナリ交差エントロピー |
| 多クラス分類 | カテゴリカル交差エントロピー |
損失関数は「間違いを測るもの」であり、勾配降下法は「その間違いが小さくなる方向へ更新する方法」です。
最適化手法は、損失が小さくなるように重みやバイアスを更新する方法です。
ディープラーニングでは、勾配を使って少しずつパラメータを調整します。
| 用語 | 一言でいうと |
|---|---|
| 最適化 | 損失が小さくなるように調整すること |
| 勾配 | 損失が変化する方向を示す傾き |
| 勾配降下法 | 損失が小さくなる方向へ更新する方法 |
| 確率的勾配降下法 | 一部のデータを使って更新する方法 |
| SGD | 確率的勾配降下法のこと |
| ミニバッチ学習 | データを小分けにして学習する方法 |
| Momentum | 過去の更新方向を考慮する方法 |
| AdaGrad | パラメータごとに学習率を調整する方法 |
| RMSprop | AdaGradの学習率低下を改善した方法 |
| Adam | MomentumとRMSpropの考え方を組み合わせた方法 |
| 局所最適解 | 一部の範囲では良いが全体では最良でない解 |
| 鞍点 | 勾配が小さいが最適解ではない点 |
最適化手法は、すべてを同じ重さで覚えるよりも、まずはSGDとAdamを中心に整理すると理解しやすくなります。
| 用語 | 見分け方 |
|---|---|
| 勾配降下法 | 損失が小さくなる方向へ進む基本の考え方 |
| SGD | 一部のデータを使って少しずつ更新する |
| Momentum | 更新方向に勢いをつける |
| AdaGrad | パラメータごとに学習率を調整する |
| Adam | 学習率を調整しながら効率よく更新する |
G検定では、最適化手法の細かい数式よりも、役割や違いを押さえることが重要です。
ディープラーニングでは、学習の進み方を決める設定も重要です。
特に、学習率、エポック、バッチサイズ、イテレーションは混同しやすい用語です。
| 用語 | 一言でいうと |
|---|---|
| 学習率 | 一回でどれくらい重みを更新するかを決める値 |
| エポック | 学習データ全体を何回使ったか |
| バッチサイズ | 一度に使うデータ数 |
| バッチ | 一度に処理するデータのまとまり |
| ミニバッチ | 小分けにしたデータのまとまり |
| イテレーション | パラメータ更新の回数 |
| ハイパーパラメータ | 学習前に人間が設定する値 |
| 初期値 | 学習を始める前のパラメータの値 |
| 収束 | 学習が安定して損失があまり変わらなくなること |
| 発散 | 学習が不安定になり損失が大きくなること |
学習率・エポック・バッチサイズは、次のように分けると覚えやすくなります。
| 用語 | 見分け方 |
|---|---|
| 学習率 | どのくらい修正するか |
| エポック | データ全体を何周するか |
| バッチサイズ | 一度にどのくらいのデータを使うか |
| イテレーション | 何回更新したか |
学習率が大きすぎると学習が不安定になり、小さすぎると学習に時間がかかります。
ディープラーニングは表現力が高いため、学習データに合わせすぎる過学習が起きやすくなります。
そのため、汎化性能を高める工夫が重要です。
| 用語 | 一言でいうと |
|---|---|
| 過学習 | 学習データに合わせすぎること |
| 汎化性能 | 未知データへの対応力 |
| 正則化 | モデルが複雑になりすぎるのを抑える方法 |
| L1正則化 | 不要な重みを0にしやすい正則化 |
| L2正則化 | 重みを小さく抑える正則化 |
| 重み減衰 | 重みが大きくなりすぎるのを抑える方法 |
| ドロップアウト | 一部のノードを無効化して過学習を抑える方法 |
| 早期終了 | 性能が悪化する前に学習を止める方法 |
| データ拡張 | データを増やしたように扱う方法 |
| アンサンブル学習 | 複数のモデルを組み合わせる方法 |
過学習対策は、何を抑えるのかで整理すると覚えやすくなります。
| 手法 | 役割 |
|---|---|
| 正則化 | 重みが大きくなりすぎるのを抑える |
| ドロップアウト | 特定のノードへの依存を減らす |
| 早期終了 | 過学習が進む前に学習を止める |
| データ拡張 | 学習データを増やしたように扱う |
| アンサンブル学習 | 複数モデルで予測を安定させる |
G検定では、正則化、ドロップアウト、データ拡張の違いが問われやすいです。
正規化や標準化は、データのスケールを整え、学習を安定させるための処理です。
バッチ正規化は、ニューラルネットワーク内部の学習を安定させる技術として押さえておきましょう。
| 用語 | 一言でいうと |
|---|---|
| 前処理 | 学習しやすい形にデータを整えること |
| 正規化 | データのスケールを一定の範囲にそろえること |
| 標準化 | 平均0、分散1に近づけること |
| バッチ正規化 | 各層の入力を整えて学習を安定させる方法 |
| Batch Normalization | バッチ正規化のこと |
| 内部共変量シフト | 学習中に層の入力分布が変わる問題 |
| 欠損値処理 | 抜けているデータを処理すること |
| 外れ値処理 | 大きく外れた値を処理すること |
正規化・標準化・バッチ正規化は、名前が似ていますが役割が異なります。
| 用語 | 見分け方 |
|---|---|
| 正規化 | 値の範囲をそろえる |
| 標準化 | 平均と分散をそろえる |
| バッチ正規化 | ニューラルネットワーク内部の学習を安定させる |
バッチ正規化は、学習を安定させ、深いネットワークを学習しやすくする技術として整理しておくとよいです。
CNNは画像認識でよく使われるニューラルネットワークです。
畳み込み層やプーリング層を使って、画像の特徴を段階的に取り出します。
| 用語 | 一言でいうと |
|---|---|
| CNN | 画像認識でよく使われるニューラルネットワーク |
| 畳み込みニューラルネットワーク | CNNのこと |
| 畳み込み層 | 画像の特徴を取り出す層 |
| フィルタ | 画像から特徴を取り出す小さな窓 |
| カーネル | フィルタとほぼ同じ意味で使われる |
| 特徴マップ | 畳み込みによって得られる特徴の集まり |
| プーリング層 | 特徴を圧縮する層 |
| 最大プーリング | 範囲内の最大値を取り出す処理 |
| 平均プーリング | 範囲内の平均値を取り出す処理 |
| ストライド | フィルタを動かす幅 |
| パディング | 画像の周囲を埋める処理 |
| 全結合層 | すべてのノードをつなぐ層 |
CNNの要素技術は、次のように整理すると覚えやすくなります。
| 用語 | 役割 |
|---|---|
| 畳み込み層 | 特徴を取り出す |
| プーリング層 | 特徴を圧縮する |
| フィルタ | 特徴を検出する |
| 特徴マップ | 取り出された特徴 |
| パディング | 端の情報を扱いやすくする |
| ストライド | フィルタを動かす間隔 |
CNNは、画像分類、物体検出、セグメンテーションなどの基礎になります。
RNNは、時系列データや文章など、順番に意味があるデータを扱うためのニューラルネットワークです。
| 用語 | 一言でいうと |
|---|---|
| RNN | 系列データを扱うニューラルネットワーク |
| 再帰型ニューラルネットワーク | RNNのこと |
| 系列データ | 順番に意味があるデータ |
| 時系列データ | 時間の順番を持つデータ |
| 隠れ状態 | 過去の情報を保持する内部状態 |
| 勾配消失問題 | 前の情報が学習に伝わりにくくなる問題 |
| 勾配爆発 | 勾配が大きくなりすぎて学習が不安定になる問題 |
| LSTM | 長期依存を扱いやすくしたRNN |
| GRU | LSTMを簡略化したRNN |
| 双方向RNN | 前後両方向の情報を使うRNN |
| Seq2Seq | 入力系列から出力系列を生成するモデル |
RNN・LSTM・GRUは、次のように整理すると覚えやすくなります。
| 用語 | 見分け方 |
|---|---|
| RNN | 系列データを扱う基本モデル |
| LSTM | 長期依存を扱いやすくしたモデル |
| GRU | LSTMを簡略化したモデル |
| Seq2Seq | 入力系列から出力系列を作るモデル |
RNNは自然言語処理の基礎として重要ですが、現在はTransformer系のモデルも重要になっています。
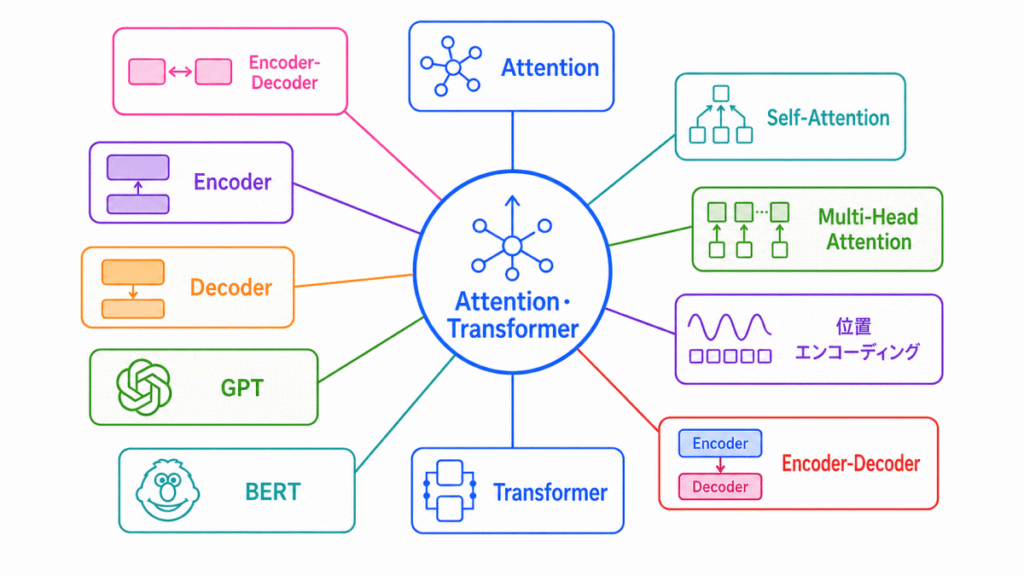
Attentionは、入力の中で重要な部分に注目する仕組みです。
Transformerは、Attentionを中心に構成されたモデルで、自然言語処理や生成AIの基礎になっています。
| 用語 | 一言でいうと |
|---|---|
| Attention | 重要な部分に注目する仕組み |
| 注意機構 | Attentionのこと |
| Self-Attention | 同じ系列内の単語同士の関係を見る仕組み |
| Multi-Head Attention | 複数の視点でAttentionを行う仕組み |
| Transformer | Attentionを中心にしたモデル |
| 位置エンコーディング | 単語の順番情報を加える仕組み |
| Encoder | 入力を理解する部分 |
| Decoder | 出力を生成する部分 |
| Encoder-Decoder | 入力理解と出力生成を組み合わせた構造 |
| BERT | Encoderを使った双方向の言語モデル |
| GPT | Decoderを使った文章生成モデル |
Attention・Transformerは、次のように整理すると理解しやすくなります。
| 用語 | 役割 |
|---|---|
| Attention | 重要な部分に注目する |
| Self-Attention | 入力内の単語同士の関係を見る |
| Multi-Head Attention | 複数の視点で関係を見る |
| Transformer | Attentionを中心にしたモデル |
| 位置エンコーディング | 順番情報を補う |
G検定では、Transformerが自然言語処理や生成AIと強く関係する点も押さえておくとよいです。
この分野では、要素技術の名前だけでなく、それぞれが何のための技術なのか が問われやすいです。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| 活性化関数 | 非線形性を加える |
| ReLU | 隠れ層でよく使われる |
| ソフトマックス関数 | 多クラス分類の出力で使われる |
| 損失関数 | 予測と正解のズレを測る |
| 勾配降下法 | 損失が小さくなる方向へ更新する |
| Adam | 効率よく学習しやすい最適化手法 |
| 正則化 | モデルの複雑さを抑える |
| ドロップアウト | 一部のノードを無効化する |
| バッチ正規化 | 学習を安定させる |
| 畳み込み層 | 画像の特徴を取り出す |
| プーリング層 | 特徴を圧縮する |
| LSTM | 長期依存を扱いやすくする |
| Attention | 重要な部分に注目する |
| Transformer | Attentionを中心にしたモデル |
特に、活性化関数・損失関数・最適化手法・正則化は、役割が違うのにまとめて出てくるため、混同しやすい分野です。
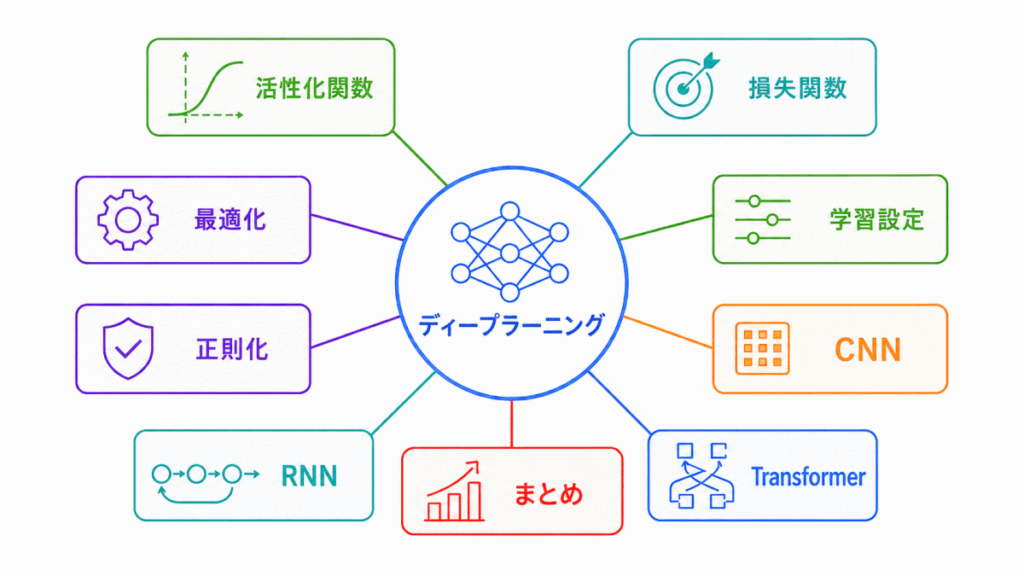
「ディープラーニングの要素技術」は、ニューラルネットワークを学習させるための部品や工夫を整理する分野です。
活性化関数で非線形性を加え、損失関数で間違いを測り、最適化手法で重みを更新し、正則化やドロップアウトで過学習を抑えます。
試験前は、細かい数式よりも
という役割をまず確認しておきましょう。
用語の意味をもう少し詳しく確認したい場合は、関連する解説記事もあわせて確認しておきましょう。
G検定の出題範囲を全体で整理したい場合は、8分野に分けたまとめ記事も確認しておきましょう。

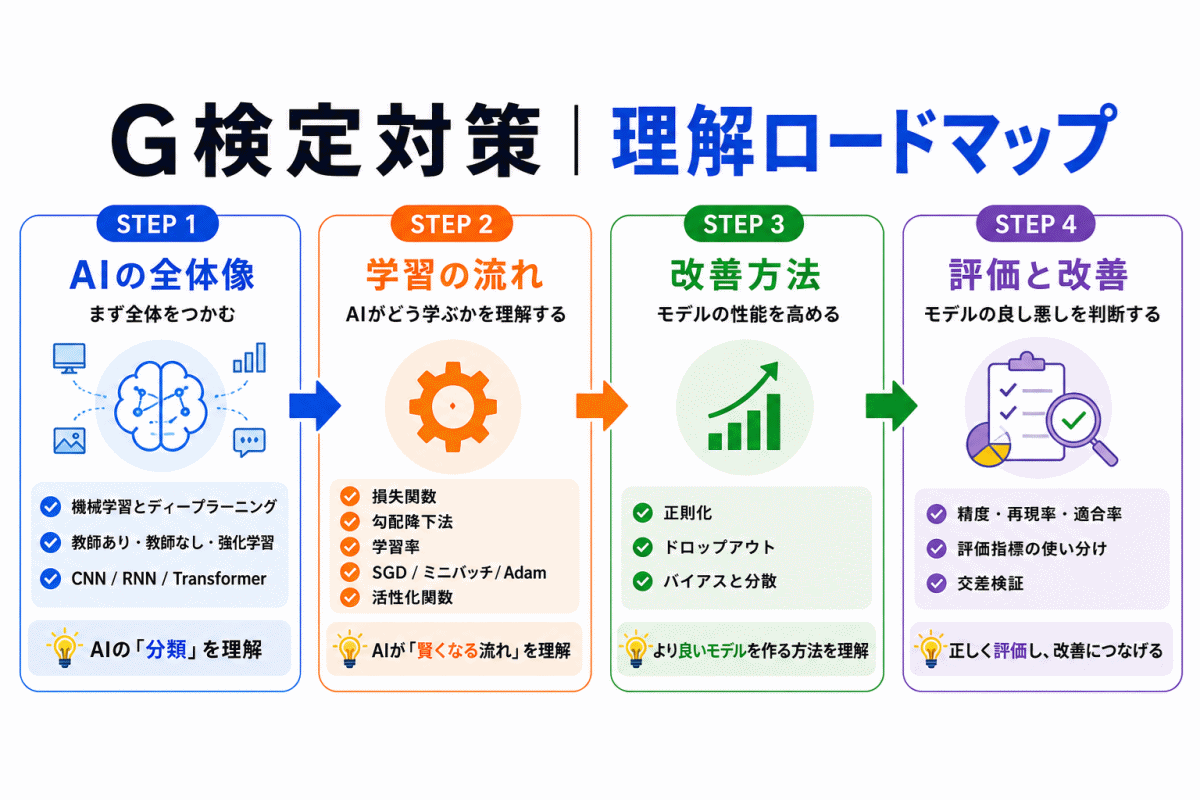
どの順番で学習すればよいか迷う場合は、G検定対策の学習ロードマップも参考になります。
機械学習とディープラーニングの関係があいまいな場合は、違いを整理した記事で確認しておきましょう。
学習方法の違いを整理したい場合は、教師あり学習・教師なし学習・強化学習の比較記事も役立ちます。
ディープラーニングの代表モデルを整理したい場合は、CNN・RNN・Transformerの違いも確認しておきましょう。
AlexNet、VGG、GoogLeNet、ResNetなどの流れを確認したい場合は、画像認識の歴史の記事がおすすめです。
生成AIの用語とあわせて、ハルシネーションや著作権などのリスクも整理しておきましょう。
技術用語だけでなく、AI倫理・法律・ガバナンスの考え方も試験前に確認しておくと安心です。
1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認