【G検定対策】ディープラーニングの概要の重要用語まとめ
seo-webmaster
G検定対策ブログ
G検定では、AIや機械学習の仕組みを理解するために必要な、基礎的な数理・統計の考え方も問われます。
特に、確率、統計、平均・分散、相関、正規分布、ベクトル、行列、微分、勾配などは、数式そのものよりも「AIのどこで使われる考え方なのか」が重要です。
この記事では、「AIに必要な数理・統計知識」に関する重要用語を、試験前に確認しやすいように短く整理します。
「AIに必要な数理・統計知識」は、機械学習やディープラーニングを理解するための土台になる分野です。
AIは、データの傾向を見つけたり、予測のズレを数値化したり、モデルの重みを調整したりします。そのため、確率・統計・線形代数・微分の考え方が関係します。
細かい計算をすべて覚えるよりも、まずは 「データのばらつきを見る」、「関係性を見る」、「数値をベクトルや行列で扱う」、「損失を小さくする方向を考える」 という役割で整理すると理解しやすくなります。
| 見るポイント | 押さえる内容 |
|---|---|
| 確率 | 不確実な出来事を数値で表す |
| 統計 | データの傾向やばらつきを整理する |
| 代表値 | 平均値・中央値・最頻値 |
| ばらつき | 分散・標準偏差 |
| 関係性 | 相関・共分散 |
| 分布 | 正規分布、二項分布など |
| 線形代数 | ベクトル・行列でデータを扱う |
| 微分 | 損失を小さくする方向を考える |
確率は、不確実な出来事がどれくらい起こりやすいかを数値で表す考え方です。
機械学習では、分類の確率、予測の不確実性、ベイズ推定などと関係します。
| 用語 | 一言でいうと |
|---|---|
| 確率 | ある出来事が起こる可能性を数値で表したもの |
| 事象 | 確率で扱う出来事 |
| 標本空間 | 起こりうる結果全体 |
| 余事象 | ある事象が起こらないこと |
| 和事象 | どちらか一方、または両方が起こること |
| 積事象 | 複数の事象が同時に起こること |
| 条件付き確率 | ある条件のもとで事象が起こる確率 |
| 独立 | 一方の事象がもう一方に影響しないこと |
| 従属 | 一方の事象がもう一方に影響すること |
| ベイズの定理 | 条件付き確率を使って確率を更新する考え方 |
| 尤度 | そのモデルからデータが生じるもっともらしさ |
| 事前確率 | データを見る前の確率 |
| 事後確率 | データを見た後に更新された確率 |
確率の用語は、次のように整理すると理解しやすくなります。
| 用語 | 見分け方 |
|---|---|
| 条件付き確率 | 条件があるときの確率 |
| 独立 | 互いに影響しない |
| ベイズの定理 | 新しい情報で確率を更新する |
| 尤度 | データから見たモデルのもっともらしさ |
統計は、データの傾向やばらつきを整理する考え方です。
AIでは、データを理解したり、モデルの評価を行ったりするときに使われます。
| 用語 | 一言でいうと |
|---|---|
| 統計 | データを集めて傾向を読み取る考え方 |
| 記述統計 | データの特徴を要約する方法 |
| 推測統計 | 一部のデータから全体を推測する方法 |
| 母集団 | 本来知りたい対象全体 |
| 標本 | 母集団から取り出した一部のデータ |
| サンプリング | 標本を取り出すこと |
| 標本数 | データの数 |
| 推定 | データから未知の値を推測すること |
| 検定 | 仮説が妥当かをデータで判断すること |
| 帰無仮説 | 棄却できるかを確認する仮説 |
| 対立仮説 | 主張したい仮説 |
| p値 | 偶然で起きる可能性の大きさ |
| 信頼区間 | 推定値が含まれそうな範囲 |
G検定では、細かい統計検定の計算よりも、データから傾向を読み取る考え方として押さえるのが現実的です。
| 用語 | 役割 |
|---|---|
| 記述統計 | データを要約する |
| 推測統計 | 一部から全体を推測する |
| 推定 | 未知の値を予測する |
| 検定 | 仮説が妥当か確認する |
代表値は、データ全体をひとつの値で表すための指標です。
平均値、中央値、最頻値は、似ていますが使いどころが異なります。
| 用語 | 一言でいうと |
|---|---|
| 代表値 | データ全体を代表する値 |
| 平均値 | データを合計して個数で割った値 |
| 中央値 | データを並べたとき真ん中にくる値 |
| 最頻値 | 最も多く出てくる値 |
| 最大値 | データの中で最も大きい値 |
| 最小値 | データの中で最も小さい値 |
| 範囲 | 最大値と最小値の差 |
| 外れ値 | 他のデータから大きく外れた値 |
平均値・中央値・最頻値は、次のように整理すると覚えやすいです。
| 用語 | 一言でいうと |
|---|---|
| 代表値 | データ全体を代表する値 |
| 平均値 | データを合計して個数で割った値 |
| 中央値 | データを並べたとき真ん中にくる値 |
| 最頻値 | 最も多く出てくる値 |
| 最大値 | データの中で最も大きい値 |
| 最小値 | データの中で最も小さい値 |
| 範囲 | 最大値と最小値の差 |
| 外れ値 | 他のデータから大きく外れた値 |
外れ値がある場合、平均値だけを見るとデータの実態を誤解することがあります。
ばらつきは、データがどれくらい散らばっているかを表します。
AIでは、データの分布やモデルの安定性を考えるときに関係します。
| 用語 | 一言でいうと |
|---|---|
| ばらつき | データの散らばり具合 |
| 偏差 | 各データと平均値の差 |
| 分散 | データのばらつきの大きさ |
| 標準偏差 | 分散の平方根で、ばらつきを見やすくした値 |
| 四分位数 | データを4つに分ける位置の値 |
| 四分位範囲 | 中央付近のばらつきを表す範囲 |
| 変動係数 | 平均に対するばらつきの大きさ |
| 標準化 | 平均0、分散1に近づけること |
| 正規化 | 値の範囲をそろえること |
分散と標準偏差は、どちらもばらつきを見る指標です。
| 用語 | 見分け方 |
|---|---|
| 分散 | ばらつきを二乗で表す |
| 標準偏差 | 元の単位に近い形でばらつきを見る |
| 標準化 | 平均と分散をそろえる |
| 正規化 | 値の範囲をそろえる |
標準化や正規化は、機械学習の前処理とも関係します。
複数のデータの関係を見るときに、相関や共分散を使います。
機械学習では、特徴量同士の関係を確認するときにも役立ちます。
| 用語 | 一言でいうと |
|---|---|
| 相関 | 2つの変数がどの程度一緒に変化するか |
| 正の相関 | 一方が増えると、もう一方も増えやすい関係 |
| 負の相関 | 一方が増えると、もう一方は減りやすい関係 |
| 無相関 | 直線的な関係がほとんどない状態 |
| 相関係数 | 相関の強さを-1〜1で表す値 |
| 共分散 | 2つの変数が一緒に変化する度合い |
| 因果関係 | 一方が原因となってもう一方に影響する関係 |
| 擬似相関 | 関係があるように見えるが直接の因果ではない相関 |
相関と因果関係は混同しやすいポイントです。
| 用語 | 見分け方 |
|---|---|
| 相関 | 一緒に変化する関係 |
| 因果関係 | 原因と結果の関係 |
| 擬似相関 | 関係があるように見えるだけの場合がある |
相関があるからといって、必ず因果関係があるとは限りません。
確率分布は、データや確率がどのように広がっているかを表します。
統計や機械学習では、データの性質を理解するために使われます。
| 用語 | 一言でいうと |
|---|---|
| 確率分布 | 値とその起こりやすさの対応 |
| 離散分布 | とびとびの値を扱う分布 |
| 連続分布 | 連続した値を扱う分布 |
| 正規分布 | 平均を中心に左右対称に広がる分布 |
| 標準正規分布 | 平均0、分散1の正規分布 |
| 二項分布 | 成功・失敗の回数を扱う分布 |
| ベルヌーイ分布 | 成功か失敗かの2値を扱う分布 |
| 一様分布 | どの値も同じくらい起こる分布 |
| ポアソン分布 | 一定時間内の発生回数を扱う分布 |
| 中心極限定理 | 標本平均が正規分布に近づくという考え方 |
確率分布は、まず代表的な分布のイメージを押さえるとよいです。
| 分布 | 見分け方 |
|---|---|
| 正規分布 | 平均を中心に山型 |
| 二項分布 | 成功・失敗の回数 |
| ベルヌーイ分布 | 1回の成功・失敗 |
| 一様分布 | どの値も同じくらい |
| ポアソン分布 | 一定時間内の発生回数 |
線形代数は、データをベクトルや行列で扱うための考え方です。
AIでは、特徴量、画像データ、ニューラルネットワークの計算などに関係します。
| 用語 | 一言でいうと |
|---|---|
| 線形代数 | ベクトルや行列を扱う数学 |
| スカラー | 1つの数値 |
| ベクトル | 複数の数値を並べたもの |
| 行列 | 数値を表のように並べたもの |
| テンソル | ベクトルや行列を拡張した多次元配列 |
| 次元 | データを表す軸や要素の数 |
| 転置 | 行と列を入れ替えること |
| 内積 | 2つのベクトルの向きの近さを見る計算 |
| ノルム | ベクトルの大きさ |
| 固有値 | 行列の性質を表す値 |
| 固有ベクトル | 行列変換で方向が変わらないベクトル |
| 主成分分析 | データのばらつきをよく表す軸に変換する方法 |
| PCA | 主成分分析のこと |
ベクトル・行列・テンソルは、データの形として整理すると理解しやすいです。
| 用語 | データのイメージ |
|---|---|
| スカラー | 1つの数 |
| ベクトル | 数の並び |
| 行列 | 縦横に並んだ数 |
| テンソル | 多次元に並んだ数 |
画像データやニューラルネットワークの重みも、行列やテンソルとして扱われます。
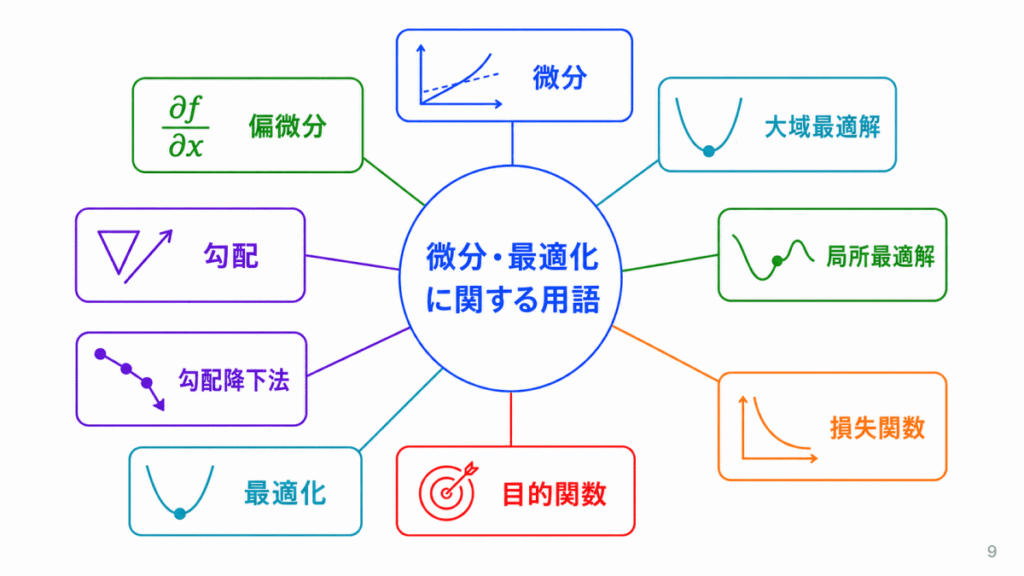
微分は、関数がどの方向にどれくらい変化するかを見る考え方です。
ディープラーニングでは、損失を小さくする方向を見つけるために使われます。
| 用語 | 一言でいうと |
|---|---|
| 微分 | 変化の度合いを見る計算 |
| 偏微分 | 複数の変数のうち1つに注目して微分すること |
| 導関数 | 微分によって得られる関数 |
| 傾き | 変化の方向や大きさ |
| 勾配 | 多変数での傾きをまとめたもの |
| 勾配降下法 | 損失が小さくなる方向へ更新する方法 |
| 最適化 | 目的の値がよくなるように調整すること |
| 目的関数 | 最小化または最大化したい関数 |
| 損失関数 | 予測と正解のズレを測る関数 |
| 局所最適解 | 一部の範囲では良いが全体では最良でない解 |
| 大域最適解 | 全体で最も良い解 |
| 鞍点 | 勾配が小さいが最適解ではない点 |
微分は、ディープラーニングの学習と強く関係します。
| 用語 | 役割 |
|---|---|
| 損失関数 | 間違いを測る |
| 勾配 | どちらに直すかを示す |
| 勾配降下法 | 損失が小さくなる方向へ進む |
| 最適化 | よりよいパラメータを探す |
数式を深く覚えるよりも、「損失を小さくする方向を見つけるために勾配を使う」と理解しておくとよいです。
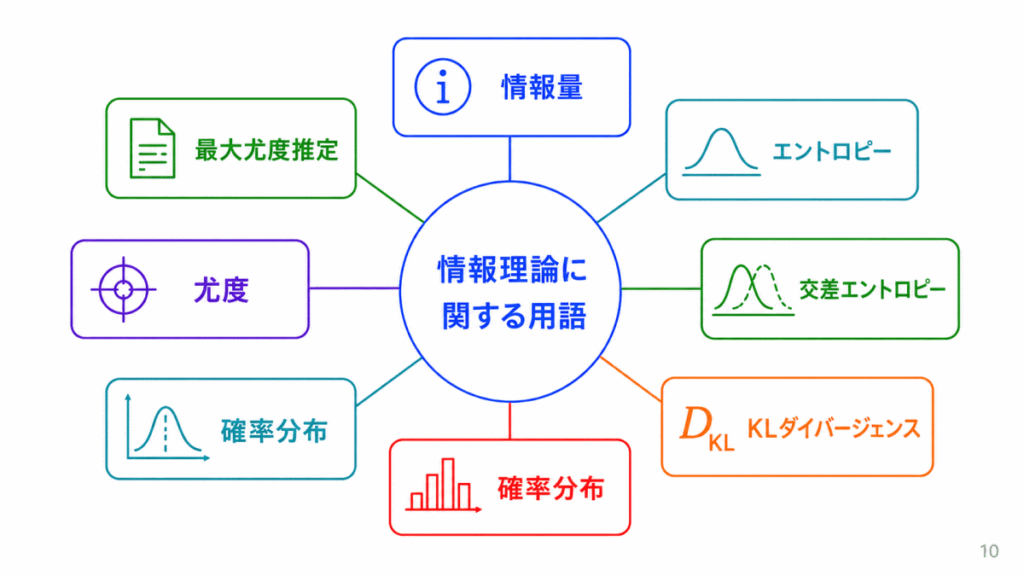
情報理論は、情報の量や不確実性を扱う考え方です。
AIでは、交差エントロピー誤差や分類の学習などと関係します。
| 用語 | 一言でいうと |
|---|---|
| 情報量 | どれくらい珍しい情報かを表す量 |
| エントロピー | 不確実性の大きさ |
| 交差エントロピー | 2つの確率分布のズレを測る考え方 |
| KLダイバージェンス | 2つの分布の違いを測る指標 |
| 確率分布 | 値と起こりやすさの対応 |
| 尤度 | データがそのモデルから出るもっともらしさ |
| 最大尤度推定 | 尤度が最大になるようにパラメータを決める方法 |
情報理論の用語は、分類や損失関数と関係します。
| 用語 | 関係する内容 |
|---|---|
| エントロピー | 不確実性 |
| 交差エントロピー | 分類の損失関数 |
| KLダイバージェンス | 分布の違い |
| 尤度 | モデルのもっともらしさ |
この分野では、数式を細かく計算するよりも、用語の意味やAIとの関係が問われやすいです。
特に、平均・分散・標準偏差、相関、正規分布、ベクトル、行列、勾配は押さえておきたい用語です。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| 平均値 | データをならした値 |
| 中央値 | 並べたとき真ん中の値 |
| 分散 | データのばらつき |
| 標準偏差 | ばらつきを見やすくした値 |
| 相関 | 2つの変数が一緒に変化する関係 |
| 因果関係 | 原因と結果の関係 |
| 正規分布 | 平均を中心に左右対称の分布 |
| ベクトル | 複数の数値を並べたもの |
| 行列 | 数値を表のように並べたもの |
| テンソル | 多次元配列 |
| 微分 | 変化の度合いを見る |
| 勾配 | 損失を小さくする方向を示す |
| 勾配降下法 | 勾配を使ってパラメータを更新する |
| エントロピー | 不確実性の大きさ |
特に、微分・勾配・勾配降下法は、ディープラーニングの学習の流れとつなげて覚えると理解しやすくなります。
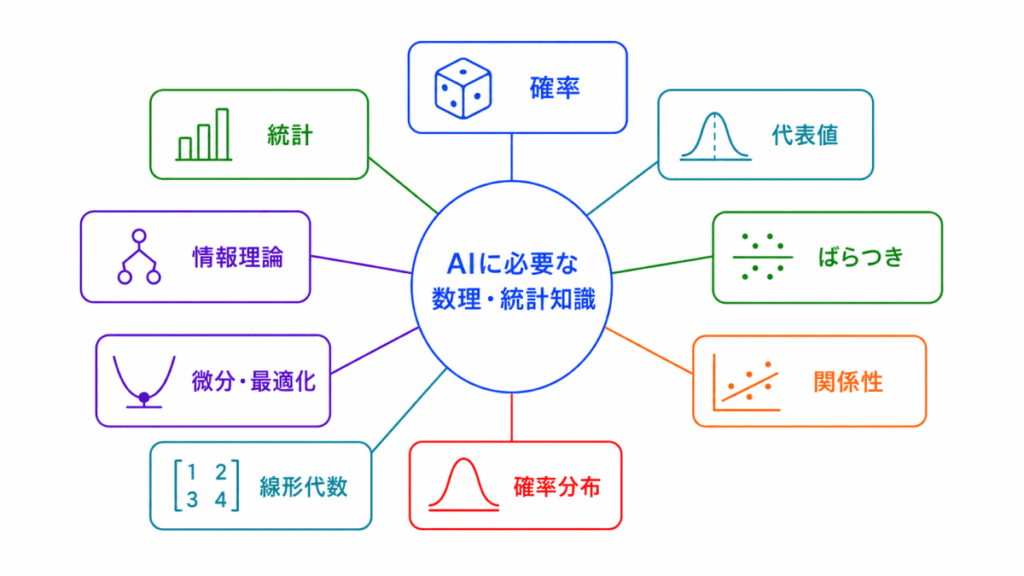
「AIに必要な数理・統計知識」は、AIや機械学習を理解するための土台になる分野です。
確率・統計はデータの傾向や不確実性を扱い、線形代数はデータをベクトルや行列で表し、微分は損失を小さくする方向を考えるために使われます。
試験前は、細かい計算式よりも
という役割を確認しておきましょう。
用語の意味をもう少し詳しく確認したい場合は、関連する解説記事もあわせて確認しておきましょう。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 重要用語チェックシート | G検定の重要用語/8分野別の確認/一言まとめ/印刷用チェック/試験直前の見直し |
| 8分野別の記事一覧 | G検定8分野の分類/苦手分野別の記事確認/作成済み記事一覧/学習順の整理 |
| G検定理解ロードマップ | G検定の学習順序/8分野の入口/AIの全体像/機械学習・ディープラーニング・法律倫理の確認ルート |
| 機械学習とディープラーニングの違い | AI・機械学習・ディープラーニングの関係/特徴量設計/教師あり・教師なし・強化学習との違い |
| 教師あり・教師なし・強化学習の違い | 正解ラベルを使う学習/正解なしで構造を見る学習/報酬で行動を改善する学習 |
| CNN・RNN・Transformerの違い | CNNは画像/RNNは時系列/Transformerは文章・生成AIで重要になる理由 |
| 画像認識の歴史 | 画像認識の発展/CNN/AlexNet/ILSVRC/物体検出・セグメンテーションへの流れ |
| 生成AIリスクまとめ | ハルシネーション/著作権/個人情報/アルゴリズムバイアス/ディープフェイク/安全な生成AI活用 |
| AI倫理・AI法律とは? | AI倫理と法律の違い/個人情報/著作権/公平性/透明性/説明責任/AIを安全に使う考え方 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。