【G検定対策】ディープラーニングの概要まとめ|ニューラルネットワーク・学習の流れ・過学習をつなげて理解する
seo-webmaster
G検定対策ブログ
G検定は、AIの基本用語だけでなく、機械学習、ディープラーニング、画像認識、自然言語処理、生成AI、社会実装、数理・統計、法律・倫理まで幅広く問われます。
試験前にすべての記事を読み返すのは大変なので、重要用語を8分野に分けて整理しておくと、自分がどこを忘れているのかを見つけやすくなります。
この記事では、G検定で押さえておきたい用語を分野ごとに短く整理し、試験直前の確認に使いやすい形でまとめます。
G検定の出題範囲は広いため、この記事ではすべての用語を網羅するのではなく、試験前に意味を思い出しておきたい重要な用語を中心に整理しています。
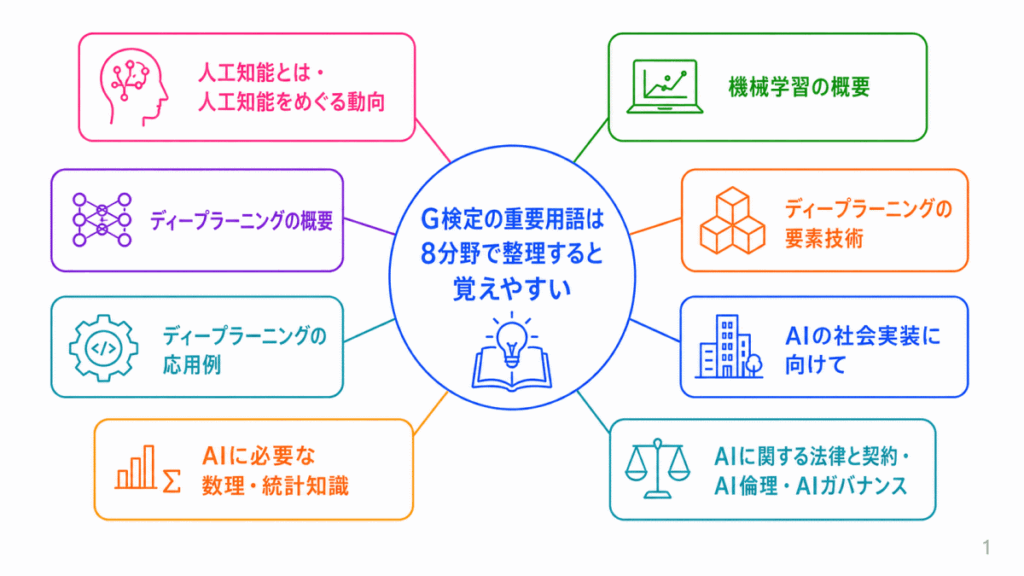
G検定の範囲は広いため、用語をバラバラに覚えようとすると混乱しやすくなります。
特に、AIの歴史、機械学習、ディープラーニング、生成AI、法律・倫理などは、それぞれが別々に見えて、実際にはつながっています。
たとえば、ディープラーニングの要素技術を理解するには、ニューラルネットワークや損失関数、勾配降下法の理解が必要です。画像認識や自然言語処理を理解するには、CNN、RNN、Transformerなどの違いを整理しておく必要があります。
この記事では、G検定で問われやすい用語を次の8分野に分けて確認します。
| 分野 | 主な内容 |
|---|---|
| 人工知能とは・人工知能をめぐる動向 | AIの定義、AIブーム、探索、推論、知識表現 |
| 機械学習の概要 | 教師あり学習、教師なし学習、強化学習、代表手法 |
| ディープラーニングの概要 | ニューラルネットワーク、学習の流れ、過学習 |
| ディープラーニングの要素技術 | CNN、RNN、Transformer、活性化関数、最適化 |
| ディープラーニングの応用例 | 画像認識、自然言語処理、音声認識、生成AI |
| AIの社会実装に向けて | PoC、MLOps、説明可能性、公平性、AIガバナンス |
| AIに必要な数理・統計知識 | 確率、統計、ベクトル、行列、微分、評価指標 |
| AIに関する法律と契約・AI倫理・AIガバナンス | 個人情報保護、著作権、契約、倫理、ガバナンス |
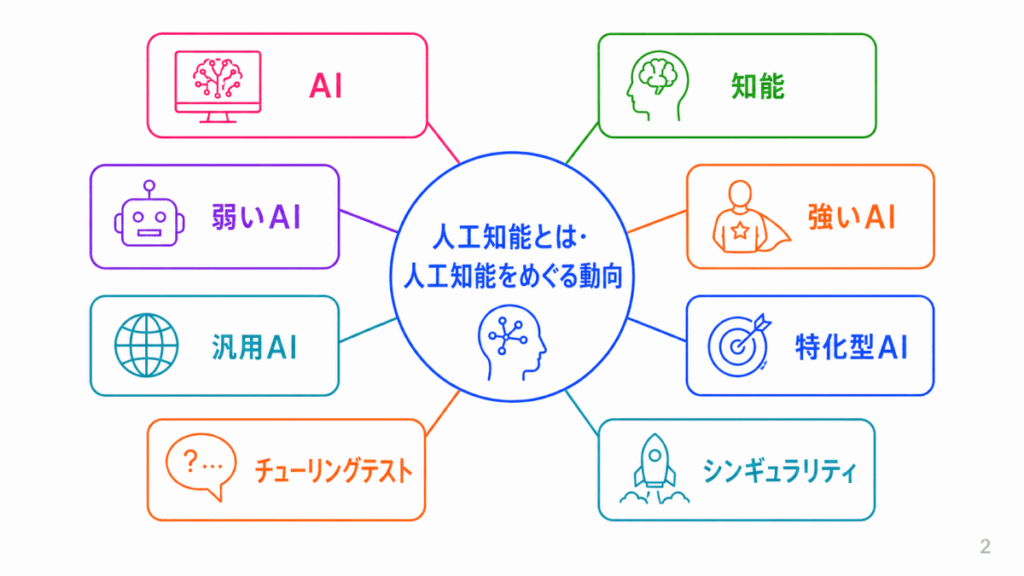
この分野では、AIとは何か、AI研究がどのように発展してきたのかを確認します。
G検定では、単に「AI=人工知能」と覚えるだけでなく、第一次AIブーム、第二次AIブーム、第三次AIブームで何が注目されたのか、なぜ限界があったのかを整理しておくことが大切です。
| 用語 | 一言でいうと |
|---|---|
| 人工知能 | 人間の知的な働きをコンピュータで実現しようとする技術 |
| AI | Artificial Intelligenceの略。人工知能のこと |
| AI効果 | 実用化されるとAIとは呼ばれにくくなる現象 |
| 強いAI | 人間のような意識や理解を持つAI |
| 弱いAI | 特定の目的に特化して働くAI |
| 汎用AI | 幅広い課題に対応できるAI |
| 特化型AI | 特定の作業に特化したAI |
| 第一次AIブーム | 探索や推論が注目された時期 |
| 第二次AIブーム | エキスパートシステムが注目された時期 |
| 第三次AIブーム | 機械学習・ディープラーニングが注目された時期 |
| 探索 | 多くの選択肢から答えを探すこと |
| 推論 | 与えられた知識から結論を導くこと |
| 知識表現 | 知識をコンピュータで扱える形にすること |
| エキスパートシステム | 専門家の知識をルール化したAI |
| フレーム問題 | 関係ある情報だけを選ぶのが難しい問題 |
| シンボルグラウンディング問題 | 記号と現実の意味を結びつける難しさ |
| シンギュラリティ | AIが人間の知能を超えるとされる仮説 |
AIの歴史は、技術名だけでなく「何が期待され、どこに限界があったのか」で整理すると覚えやすくなります。
| 時期 | 注目された考え方/限界 |
|---|---|
| 第一次AIブーム | 探索・推論/現実の複雑な問題に弱かった |
| 第二次AIブーム | 知識表現・エキスパートシステム/人間の知識をすべて書くのが難しかった |
| 第三次AIブーム | 機械学習・ディープラーニング/データ、計算資源、説明可能性などが課題 |
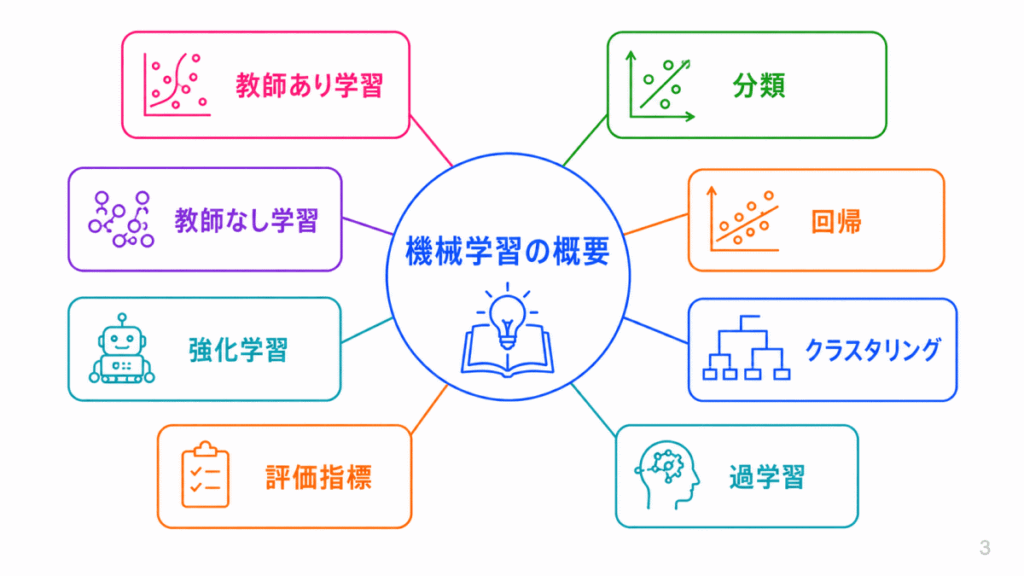
機械学習は、データからパターンを学び、予測や分類に使う方法です。
G検定では、教師あり学習、教師なし学習、強化学習の違いがよく問われます。特に、分類、回帰、クラスタリング、次元削減、強化学習の用語は混同しやすいため、役割で整理しておくと理解しやすくなります。
| 用語 | 一言でいうと |
|---|---|
| 機械学習 | データからルールやパターンを学ぶ方法 |
| 教師あり学習 | 正解データを使って学習する方法 |
| 教師なし学習 | 正解データなしでデータの構造を見つける方法 |
| 強化学習 | 報酬をもとに行動を改善する方法 |
| 分類 | データをカテゴリに分けること |
| 回帰 | 数値を予測すること |
| クラスタリング | 似ているデータをグループに分けること |
| 次元削減 | データの情報を保ちながら特徴を少なくすること |
| 汎化 | 未知のデータにも対応できること |
| 過学習 | 学習データに合わせすぎて未知のデータに弱くなること |
| 特徴量 | 予測や分類に使うデータの特徴 |
| ラベル | 教師あり学習で使う正解情報 |
| 手法 | 一言でいうと |
|---|---|
| 線形回帰 | 直線的な関係で数値を予測する方法 |
| ロジスティック回帰 | 分類に使われる回帰という名前の手法 |
| k-NN | 近くにあるデータをもとに分類する方法 |
| SVM | 境界線を使ってデータを分ける方法 |
| 決定木 | 条件分岐で予測する方法 |
| ランダムフォレスト | 複数の決定木を組み合わせる方法 |
| 勾配ブースティング | 弱いモデルを順番に改善する方法 |
| 手法 | 一言でいうと |
|---|---|
| k-means | データを指定した数のグループに分ける方法 |
| 階層的クラスタリング | データの近さをもとに階層的にまとめる方法 |
| PCA | データの特徴を少ない軸にまとめる次元削減の手法 |
| 主成分分析 | PCAのこと |
| アソシエーション分析 | 一緒に起こりやすい関係を見つける方法 |
| 用語 | 一言でいうと |
|---|---|
| エージェント | 行動する主体 |
| 環境 | エージェントが行動する対象 |
| 状態 | 現在の状況 |
| 行動 | エージェントが選ぶ動き |
| 報酬 | 行動の良し悪しを示す値 |
| 方策 | どの状態でどの行動を選ぶかのルール |
| 価値関数 | 状態や行動の良さを表す関数 |
| Q学習 | 行動の価値を学習する強化学習の手法 |
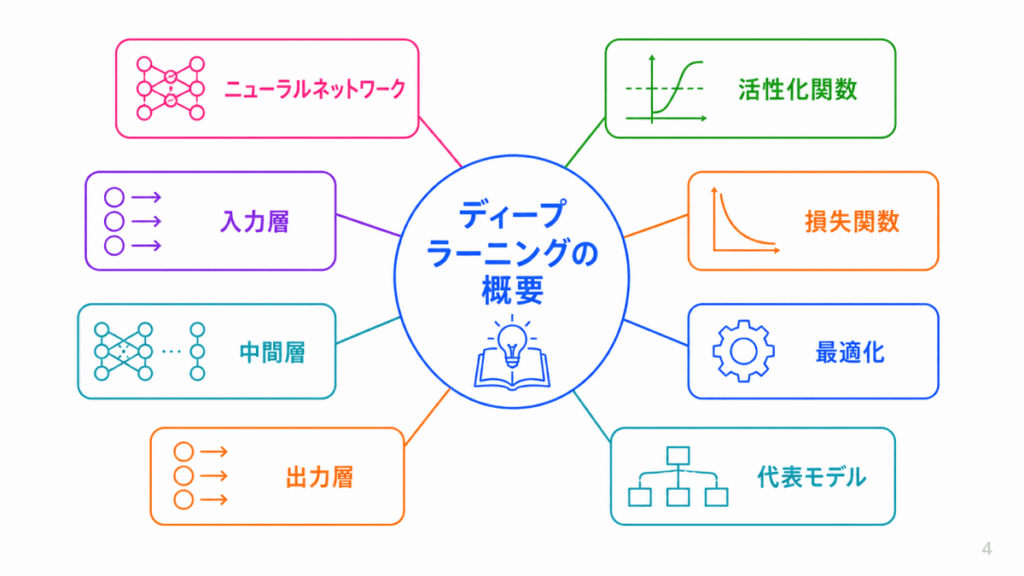
ディープラーニングは、多層のニューラルネットワークを使う機械学習の方法です。
G検定では、ニューラルネットワークの構造、重み、バイアス、損失関数、誤差逆伝播法、勾配降下法などが関連して問われます。用語を別々に覚えるよりも、「予測する→間違いを測る→重みを直す」という流れで整理すると理解しやすくなります。
| 用語 | 一言でいうと |
|---|---|
| ディープラーニング | 多層のニューラルネットワークを使う機械学習 |
| ニューラルネットワーク | 人間の神経回路を参考にしたモデル |
| 入力層 | データを受け取る層 |
| 隠れ層 | 特徴を変換しながら学習する層 |
| 出力層 | 予測結果を出す層 |
| ノード | ニューラルネットワーク内の計算単位 |
| 重み | 入力の重要度を調整する値 |
| バイアス | 出力を調整するための値 |
| 活性化関数 | 出力を変換し、非線形性を加える関数 |
| 損失関数 | 予測と正解のズレを測る関数 |
| 誤差逆伝播法 | 誤差を後ろから前へ伝えて重みを更新する方法 |
| 勾配降下法 | 損失が小さくなる方向に重みを更新する方法 |
| 学習率 | 重みをどれくらい更新するかを決める値 |
| エポック | 学習データ全体を何回学習したかを表す単位 |
| バッチ | 一度に学習に使うデータのまとまり |
| 流れ | 役割 |
|---|---|
| データを入力する | モデルに情報を入れる |
| 予測する | 現在の重みで答えを出す |
| 損失を計算する | 予測と正解のズレを測る |
| 誤差を逆向きに伝える | どこを直すべきかを計算する |
| 重みを更新する | 次の予測がよくなるように調整する |
ディープラーニングの要素技術では、モデルの種類や学習を安定させるための工夫が問われます。
G検定では、CNN、RNN、Transformerの違い、活性化関数、正則化、ドロップアウト、バッチ正規化、最適化手法などが混同されやすいポイントです。
| 用語 | 一言でいうと |
|---|---|
| CNN | 画像認識に強いニューラルネットワーク |
| 畳み込み | 画像の一部から特徴を取り出す処理 |
| フィルタ | 特徴を取り出すための小さな窓 |
| プーリング | 特徴マップを小さくまとめる処理 |
| パディング | 入力の周囲を埋めて出力サイズを調整する処理 |
| RNN | 系列データを扱うニューラルネットワーク |
| LSTM | RNNの長期依存の問題に対応したモデル |
| GRU | LSTMを簡略化したモデル |
| Transformer | Attentionを中心にしたモデル |
| Attention | 重要な部分に注目する仕組み |
| Self-Attention | 同じ系列内の要素同士の関係を見る仕組み |
| Multi-Head Attention | 複数の視点でAttentionを行う仕組み |
| 位置エンコーディング | 単語の順番をモデルに伝える仕組み |
| ソフトマックス関数 | 出力を確率の形に変換する関数 |
| ReLU | 負の値を0にする活性化関数 |
| シグモイド関数 | 出力を0〜1に変換する関数 |
| ドロップアウト | 一部のノードを無効化して過学習を抑える方法 |
| 正則化 | モデルが複雑になりすぎるのを抑える方法 |
| バッチ正規化 | 学習を安定させるために値の分布を整える方法 |
| モデル | 得意なデータ/覚え方 |
|---|---|
| CNN | 画像/近くの特徴を取り出す |
| RNN | 時系列・文章/順番を扱う |
| Transformer | 文章・生成AI/重要な部分に注目する |
ディープラーニングは、画像認識、自然言語処理、音声認識、生成AIなど、さまざまな分野で使われています。
G検定では、応用例そのものだけでなく、どの技術がどの分野で使われるのかも問われます。画像認識ならCNN、自然言語処理や生成AIならTransformer、音声や系列データならRNNやTransformerと関連づけて整理しておくと理解しやすくなります。
| 用語 | 一言でいうと |
|---|---|
| 画像分類 | 画像全体が何かを判定する技術 |
| 物体検出 | 画像内の物体の種類と位置を検出する技術 |
| セグメンテーション | 画像を領域ごとに分ける技術 |
| セマンティックセグメンテーション | 同じ種類の領域をまとめて分ける方法 |
| インスタンスセグメンテーション | 同じ種類でも個体ごとに分ける方法 |
| パノプティックセグメンテーション | セマンティックとインスタンスを組み合わせる方法 |
| 自然言語処理 | 人間の言葉をコンピュータで扱う技術 |
| 形態素解析 | 文を意味のある最小単位に分ける処理 |
| 単語埋め込み | 単語を数値ベクトルで表す方法 |
| Word2Vec | 単語の意味をベクトルで表す手法 |
| BERT | 文脈を双方向に理解する言語モデル |
| GPT | 次の単語を予測しながら文章を生成するモデル |
| 生成AI | 文章・画像・音声などを生成するAI |
| LLM | 大規模言語モデル |
| RAG | 外部情報を検索して回答に活用する仕組み |
| ファインチューニング | 学習済みモデルを特定の目的に合わせて追加学習すること |
| ゼロショット学習 | 事前例なしで新しい課題に対応すること |
| 音声認識 | 音声を文字や意味に変換する技術 |
| 異常検知 | 普段と違う状態を見つける技術 |
| モデル | 一言でいうと |
|---|---|
| AlexNet | 画像認識でディープラーニングが注目されるきっかけになったモデル |
| VGG | 小さな畳み込みを重ねたシンプルなCNN |
| GoogLeNet | Inceptionモジュールを使ったモデル |
| ResNet | スキップ結合で深いネットワークを学習しやすくしたモデル |
| R-CNN | 候補領域を使う物体検出モデル |
| YOLO | 画像全体を一度に見て物体検出するモデル |
| SSD | 複数スケールで物体検出するモデル |
| U-Net | 医用画像などのセグメンテーションで使われるモデル |
| Mask R-CNN | 物体検出とインスタンスセグメンテーションを行うモデル |
AIは、モデルを作れば終わりではありません。実際に使うには、データの準備、検証、運用、改善、説明責任、リスク管理が必要です。
G検定では、AIを社会で使うときの考え方として、PoC、MLOps、説明可能性、公平性、データリーケージ、AIガバナンスなどが問われます。
| 用語 | 一言でいうと |
|---|---|
| PoC | 小さく試して実現可能性を確認すること |
| MLOps | 機械学習モデルを継続的に運用・改善する仕組み |
| データリーケージ | 本来使ってはいけない情報が学習や評価に混ざること |
| 説明可能性 | AIの判断理由を説明できること |
| 解釈可能性 | モデルの仕組みや判断を人間が理解しやすいこと |
| 公平性 | 特定の属性に不利な判断を避けること |
| 透明性 | AIの仕組みや使い方が見えやすいこと |
| アカウンタビリティ | 結果に対して説明責任を果たすこと |
| AIガバナンス | AIを組織として適切に管理する仕組み |
| ヒューマンインザループ | 人間が判断や確認に関与する仕組み |
| モデルの劣化 | 時間の経過で精度が下がること |
| ドリフト | 学習時と運用時でデータの性質が変わること |
| エッジAI | 端末側でAIを動かす仕組み |
| 量子化 | モデルを軽量化するために重みの表現を小さくすること |
| プルーニング | 不要な重みや接続を削ること |
| 蒸留 | 大きなモデルの知識を小さなモデルに移すこと |
AIを理解するには、数理・統計の考え方も必要です。
G検定では、難しい計算そのものよりも、平均、分散、相関、確率、ベクトル、行列、微分、勾配などの意味が問われることがあります。数式を丸暗記するよりも、「AIのどこで使われるのか」を意識すると理解しやすくなります。
| 用語 | 一言でいうと |
|---|---|
| 平均 | データの中心を表す値 |
| 分散 | データのばらつきを表す値 |
| 標準偏差 | 分散の平方根で、ばらつきの大きさを表す値 |
| 相関 | 2つのデータの関係性 |
| 相関係数 | 相関の強さを数値で表したもの |
| 偏相関係数 | 他の変数の影響を除いた相関 |
| 共分散 | 2つの変数が一緒に変化する度合い |
| 確率 | ある出来事が起こる可能性 |
| 条件付き確率 | ある条件のもとで別の出来事が起こる確率 |
| 期待値 | 確率を考慮した平均的な値 |
| ベクトル | 数値を並べて表したもの |
| 行列 | 数値を表の形に並べたもの |
| 微分 | 変化の大きさを調べる方法 |
| 勾配 | 損失を減らすために進む方向 |
| 正規分布 | 平均を中心に左右対称に広がる分布 |
| 尤度 | 観測データが得られるもっともらしさ |
| エントロピー | 情報の不確実さを表す指標 |
| KLダイバージェンス | 2つの確率分布の違いを測る指標 |
| 用語 | 一言でいうと |
|---|---|
| 精度 | 全体のうち正解した割合 |
| 適合率 | 陽性と予測した中で本当に陽性だった割合 |
| 再現率 | 本当の陽性をどれだけ拾えたか |
| F1値 | 適合率と再現率のバランス |
| TP | 陽性を正しく陽性と予測 |
| FP | 陰性を誤って陽性と予測 |
| FN | 陽性を誤って陰性と予測 |
| TN | 陰性を正しく陰性と予測 |
| 交差検証 | データを分けて複数回評価する方法 |
| ホールドアウト法 | 学習用と評価用にデータを分ける方法 |
AIを使うときは、技術だけでなく、法律、契約、倫理、社会的な影響も重要になります。
G検定では、個人情報保護、著作権、プライバシー、公平性、説明可能性、AIガバナンスなどが問われます。特に生成AIの普及により、著作権や個人情報、学習データの扱いは重要なテーマになっています。
| 用語 | 一言でいうと |
|---|---|
| 個人情報 | 個人を識別できる情報 |
| 個人情報保護法 | 個人情報の取り扱いを定める法律 |
| 匿名加工情報 | 個人を識別できないよう加工した情報 |
| 仮名加工情報 | 他の情報と照合しないと個人を識別できないよう加工した情報 |
| プライバシー | 個人の私生活や情報を守る考え方 |
| 著作権 | 創作物を保護する権利 |
| 著作者人格権 | 著作者の人格的利益を守る権利 |
| ライセンス | 利用条件を定めた許可 |
| 秘密保持契約 | 情報を外部に漏らさないための契約 |
| 委託契約 | 業務を外部に依頼するときの契約 |
| 倫理 | 社会的に望ましい行動の考え方 |
| バイアス | データや判断に含まれる偏り |
| 差別 | 特定の属性に不利な扱いをすること |
| 公平性 | 偏りのある判断を避ける考え方 |
| 透明性 | AIの仕組みや目的が見えやすいこと |
| 説明可能性 | 判断理由を説明できること |
| AIガバナンス | AIを適切に管理する仕組み |
| リスク管理 | 問題が起きる可能性を把握し対策すること |
| ハルシネーション | AIが事実と異なる内容をもっともらしく出力すること |
| フェイクニュース | 事実と異なる情報をニュースのように見せるもの |
| ディープフェイク | AIで本物のように作られた偽画像・偽動画・偽音声 |
G検定では、用語の意味をそのまま問う問題だけでなく、似た用語の違いや、具体例に当てはめて選ぶ問題も出ます。
特に、次のような混同に注意が必要です。
| 混同しやすい用語 | 見分け方 |
|---|---|
| AI・機械学習・ディープラーニング | 範囲の広さで整理する |
| 教師あり学習・教師なし学習・強化学習 | 正解データや報酬の有無で整理する |
| 分類・回帰・クラスタリング | 何を予測・整理するのかで見分ける |
| 画像分類・物体検出・セグメンテーション | 画像全体・位置・領域で整理する |
| CNN・RNN・Transformer | 画像・系列・Attentionで整理する |
| 損失関数・勾配降下法・学習率 | 間違いを測る、方向を決める、更新幅を決める |
| 適合率・再現率・F1値 | 誤検出を減らす、見逃しを減らす、バランスを見る |
| 説明可能性・透明性・公平性 | 理由、見えやすさ、偏りで整理する |
| 個人情報・著作権・倫理 | データ、創作物、社会的な望ましさで整理する |
用語を暗記するだけでは、選択肢が少し変わったときに迷いやすくなります。
そのため、試験前は「意味」、「違い」、「使われる場面」をセットで確認するのがおすすめです。
G検定の重要用語は、バラバラに覚えるよりも、8分野に分けて整理すると理解しやすくなります。
AIの基本や歴史は全体の土台になり、機械学習とディープラーニングは技術理解の中心になります。さらに、画像認識や自然言語処理、生成AIなどの応用例、社会実装、数理・統計、法律・倫理までつなげて理解することで、用語の意味だけでなく、試験での問われ方にも対応しやすくなります。
試験前は、すべてを細かく読み直すよりも、まずは重要用語を見て、忘れている分野や混同しやすい分野を見つけることが大切です。
この記事をチェックリストとして使い、気になる分野は個別の記事で深掘りしていきましょう。
用語の意味をもう少し詳しく確認したい場合は、関連する解説記事もあわせて確認しておきましょう。
| おすすめ記事 | 確認できる内容 |
|---|---|
| 8分野別の記事一覧 | G検定8分野の分類/苦手分野別の記事確認/作成済み記事一覧/学習する順番の整理 |
| G検定理解ロードマップ | G検定の学習順序/8分野の入口/AIの全体像/機械学習・ディープラーニング・法律倫理の確認ルート |
| 機械学習とディープラーニングの違い | AI・機械学習・ディープラーニングの関係/特徴量設計/教師あり・教師なし・強化学習との違い |
| 教師あり・教師なし・強化学習の違い | 正解ラベルを使う学習/正解なしで構造を見る学習/報酬で行動を改善する学習 |
| CNN・RNN・Transformerの違い | CNNは画像/RNNは時系列/Transformerは文章・生成AIで重要になる理由 |
| 画像認識の歴史 | 画像認識の発展/CNN/AlexNet/ILSVRC/物体検出・セグメンテーションへの流れ |
| 生成AIリスクまとめ | ハルシネーション/著作権/個人情報/アルゴリズムバイアス/ディープフェイク/安全な生成AI活用 |
| AI倫理・AI法律とは? | AI倫理と法律の違い/個人情報/著作権/公平性/透明性/説明責任/AIを安全に使う考え方 |
| 理解型予想問題まとめ | 混同しやすい用語/予想問題/分野別チェック |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。