【G検定対策】物体検出の代表モデルを整理|R-CNN・YOLO・SSDの違い
seo-webmaster
G検定対策ブログ
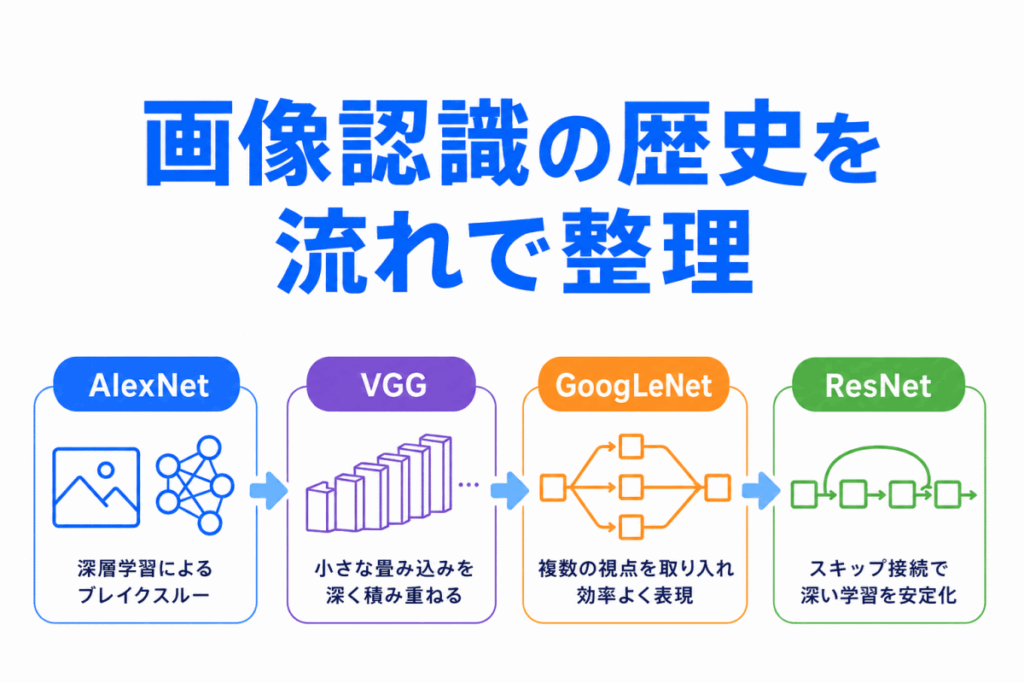
画像認識の歴史では AlexNet、VGG、GoogLeNet、ResNet など、似た名前のモデルが続いて登場します。
AIの学習をはじめたばかりの人にとっては、年号や名前だけを覚えようとすると、どれが何をした技術なのか混乱しやすい分野です。
この記事では、画像認識の歴史を「どのモデルが何を改善したのか」という流れで整理します。
G検定では、細かい構造をすべて暗記するよりも、CNNがなぜ重要になり、代表的なモデルがどのように発展したのかを理解しておくことが大切です。
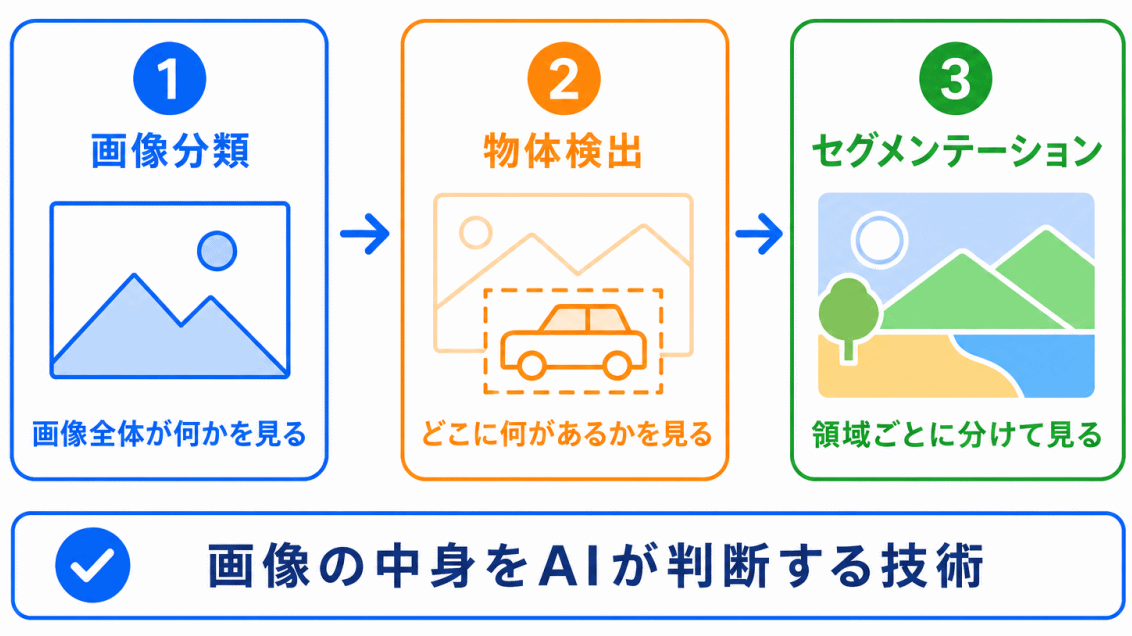
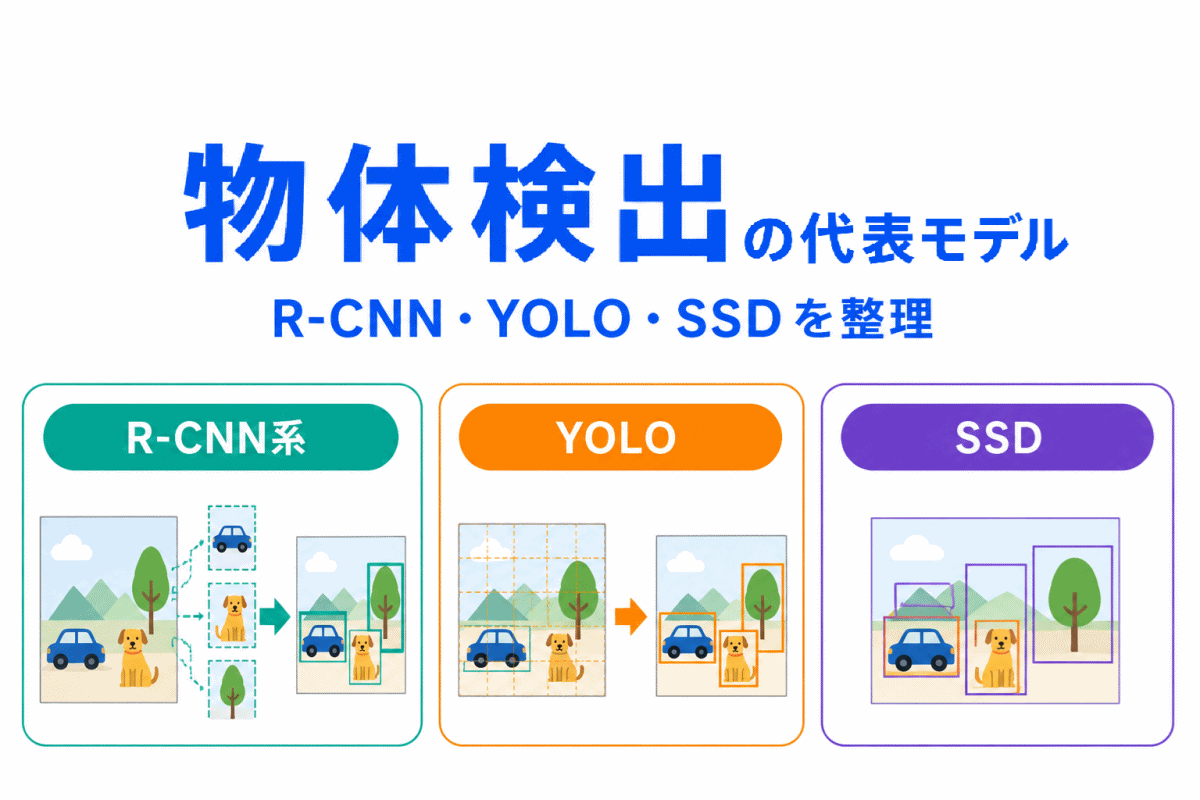
画像認識とは、AIが画像の中身を判断する技術です。
たとえば、画像を見て「犬」、「猫」、「車」などを判断したり、画像の中のどこに物体があるかを見つけたりします。
画像認識では、主に次のような処理が登場します。
| 用語 | ざっくりした意味 |
|---|---|
| 画像分類 | 画像全体が何かを判断する |
| 物体検出 | 画像の中のどこに何があるかを見つける |
| セグメンテーション | 画像を領域ごとに分ける |
まずは、画像認識を
画像全体を見るのか、位置を見るのか、領域を見るのか
で整理するとわかりやすくなります。
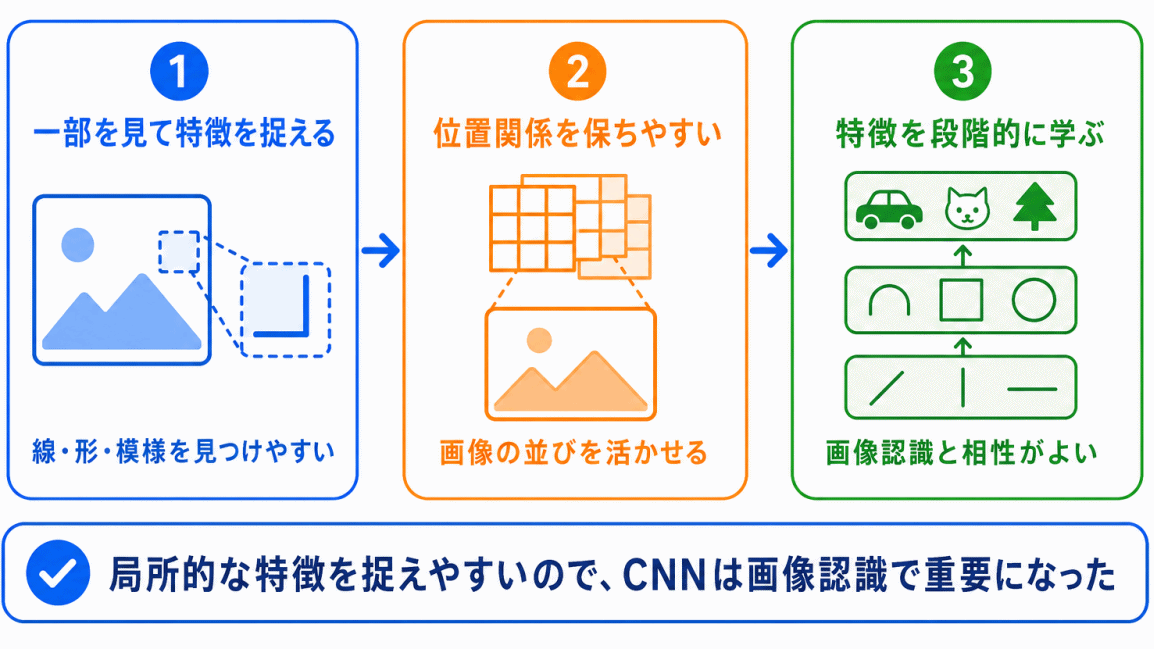
画像認識で重要になったのが、CNNです。
CNNは、画像の一部に注目しながら特徴を取り出す仕組みを持っています。
画像は、文章のように1列に並んだ情報ではなく、縦と横に広がるデータです。そのため、画像の中にある線、形、模様、輪郭などをうまく捉える必要があります。
CNNは、画像の局所的な特徴を捉えやすいため、画像認識と相性がよいモデルとして発展しました。
| 技術 | 得意なこと |
|---|---|
| CNN | 画像の特徴を捉える |
| RNN | 順番のあるデータを扱う |
| Transformer | 重要な部分に注目する |
ここではまず
画像認識といえばCNNが重要
と整理しておくと理解しやすいです。
ただし、現在はTransformerも画像認識に使われるため、「CNNだけ」と覚えるのではなく、画像認識の発展でCNNが大きな役割を持ったと理解するのが安全です。
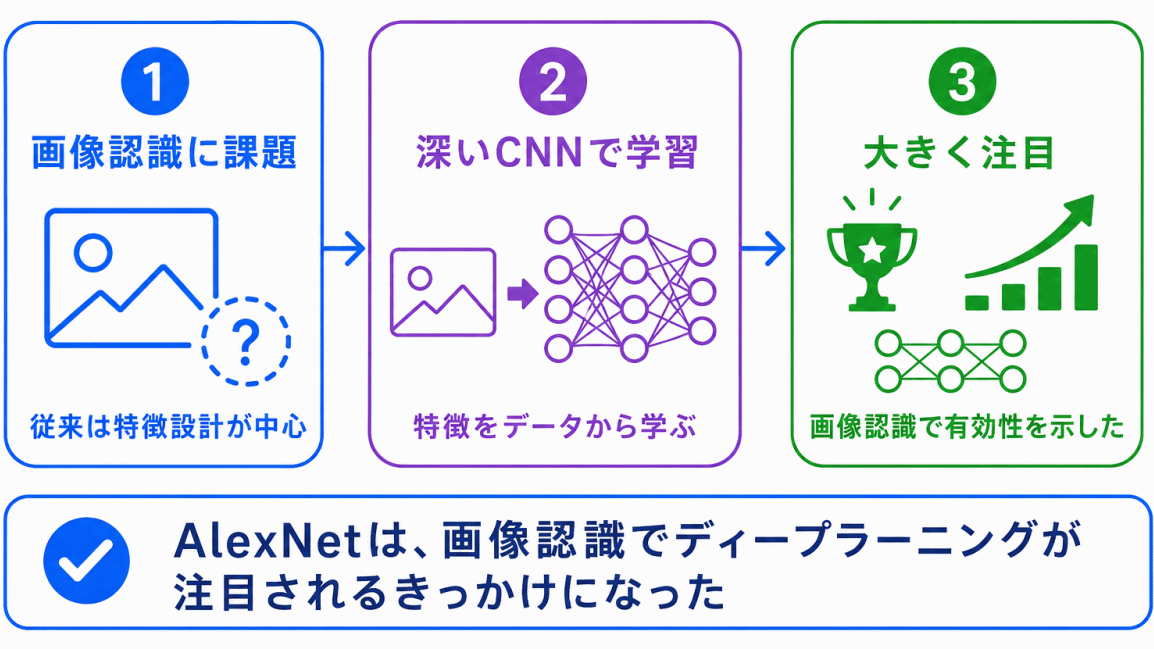
AlexNetは、画像認識の歴史でとても重要なモデルです。
AlexNetは、ディープラーニングが画像認識の分野で大きく注目されるきっかけになりました。
それまでの画像認識では、人間が特徴を設計する考え方が強くありました。しかし、AlexNetでは深いニューラルネットワークを使い、画像の特徴をデータから学習する流れが強くなりました。
| モデル | ざっくりした特徴 |
|---|---|
| AlexNet | ディープラーニングが画像認識で注目されたきっかけ |
AlexNetは
画像認識でも深いニューラルネットワークが有効だと示したモデル
として整理するとよいです。
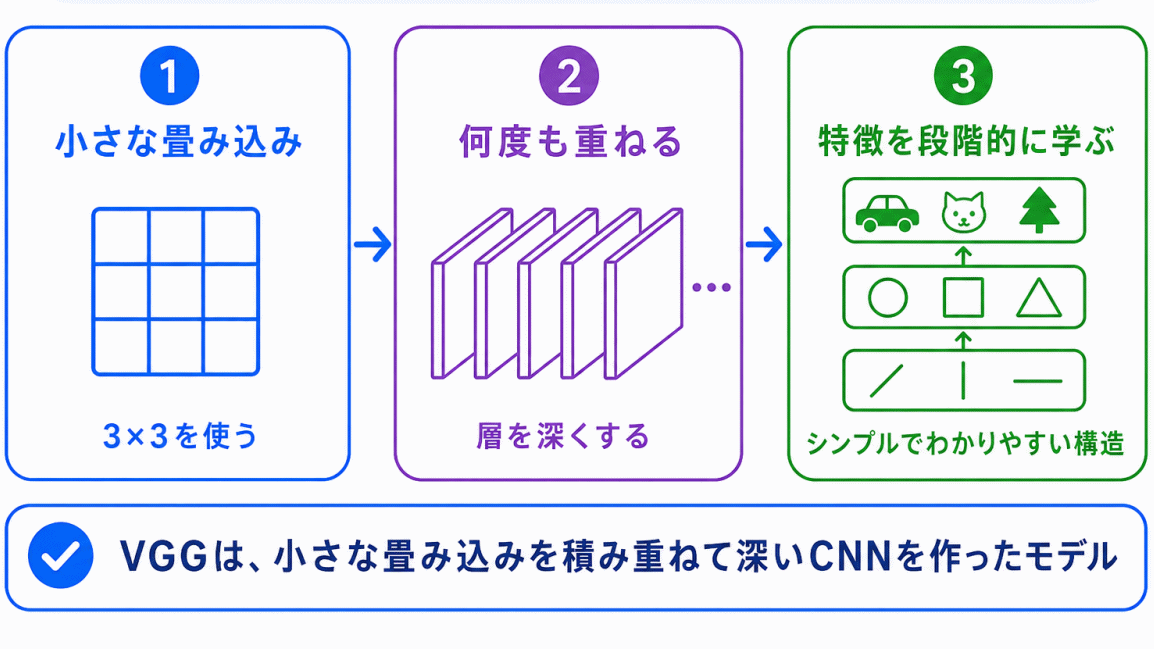
VGGは、CNNをよりシンプルで深い構造として整理したモデルです。
ポイントは、小さな畳み込みフィルタを重ねることです。
大きな処理を一度に行うのではなく、小さな処理を何層も重ねることで、画像の特徴を段階的に捉えやすくしました。
| モデル | 覚え方 |
|---|---|
| VGG | 小さな畳み込みを重ねて深くする |
VGGは、細かい構造を暗記するよりも
シンプルな畳み込みを重ねて、深いCNNを作った
と理解すると混同しにくくなります。
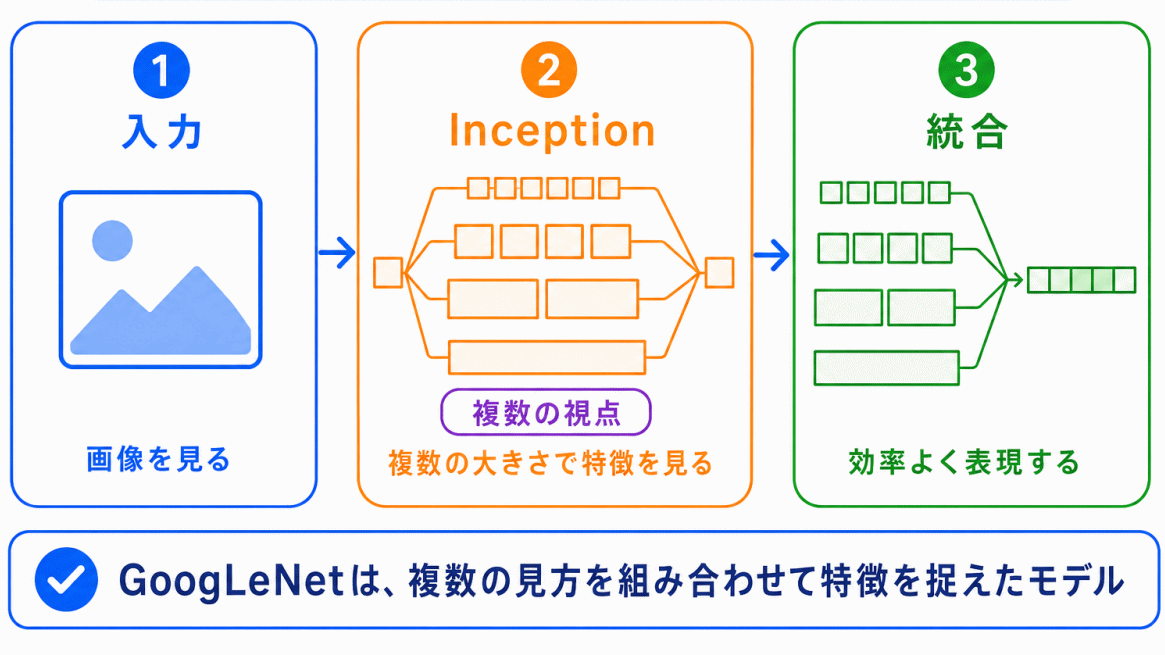
GoogLeNetは、Inceptionという考え方と結びつけて整理するとわかりやすいです。
Inceptionでは、画像を見るときに、1つのサイズの処理だけでなく、複数の見方を組み合わせます。
画像の特徴は、小さな部分に出ることもあれば、広い範囲に出ることもあります。そのため、複数のサイズで特徴を捉える考え方が重要になります。
| モデル | 覚え方 |
|---|---|
| GoogLeNet | Inceptionで複数の見方を組み合わせる |
GoogLeNetは
画像をいろいろな大きさの視点で見るモデル
として整理すると覚えやすいです。
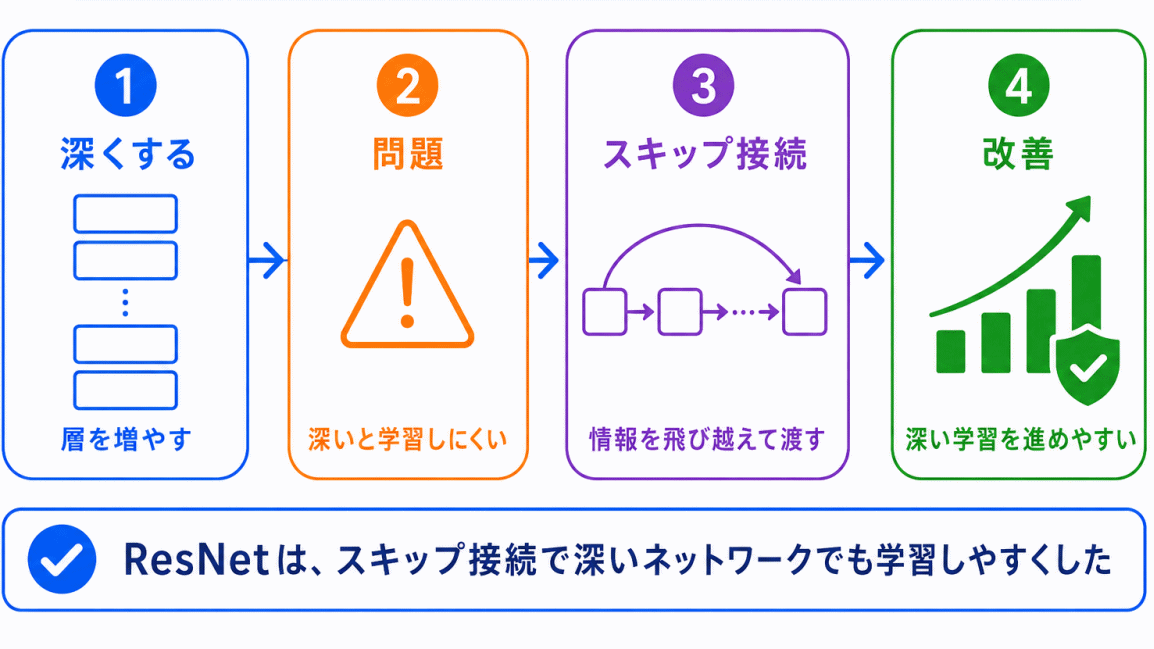
ResNetは、画像認識の歴史で特に混同しやすいモデルです。
ポイントは、残差学習とスキップ接続です。
ニューラルネットワークは、層を深くすればするほど性能が上がりそうに見えます。しかし、深くしすぎると学習がうまく進みにくくなる問題があります。
ResNetでは、途中の情報を飛び越えて先の層へ渡すスキップ接続によって、深いネットワークでも学習しやすくしました。
| モデル | 覚え方 |
|---|---|
| GoogLeNet | Inceptionで複数の見方を組み合わせる |
ResNetは
深くしたいけれど、学習しにくくなる問題を改善したモデル
として理解するとよいです。
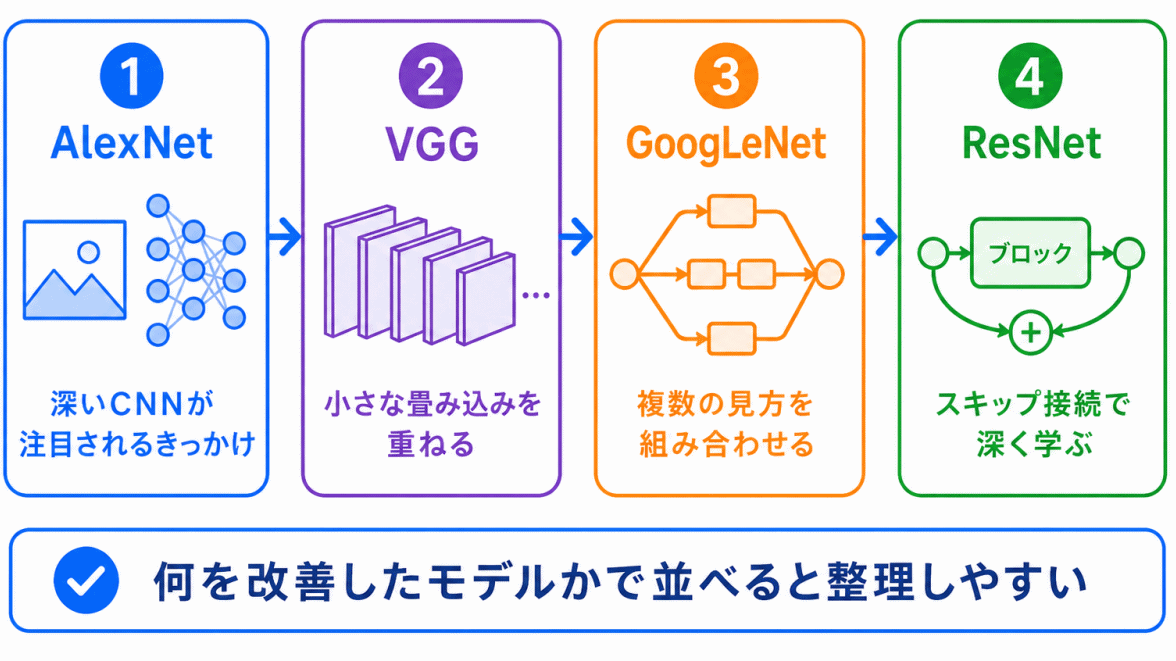
画像認識の歴史は、年号だけで覚えるよりも、モデルごとの役割で整理するとわかりやすくなります。
| モデル | ざっくりした役割 |
|---|---|
| AlexNet | ディープラーニングが画像認識で注目されたきっかけ |
| VGG | 小さな畳み込みを重ねて深くした |
| GoogLeNet | Inceptionで複数の見方を組み合わせた |
| ResNet | スキップ接続で深くしても学習しやすくした |
流れで見ると、次のように整理できます。
深いCNNが注目される
→ 小さな畳み込みを重ねる
→ 複数の見方を組み合わせる
→ さらに深くしても学習しやすくする
このように見ると、モデル名がバラバラの暗記ではなく、画像認識がどう進化したのかが見えやすくなります。
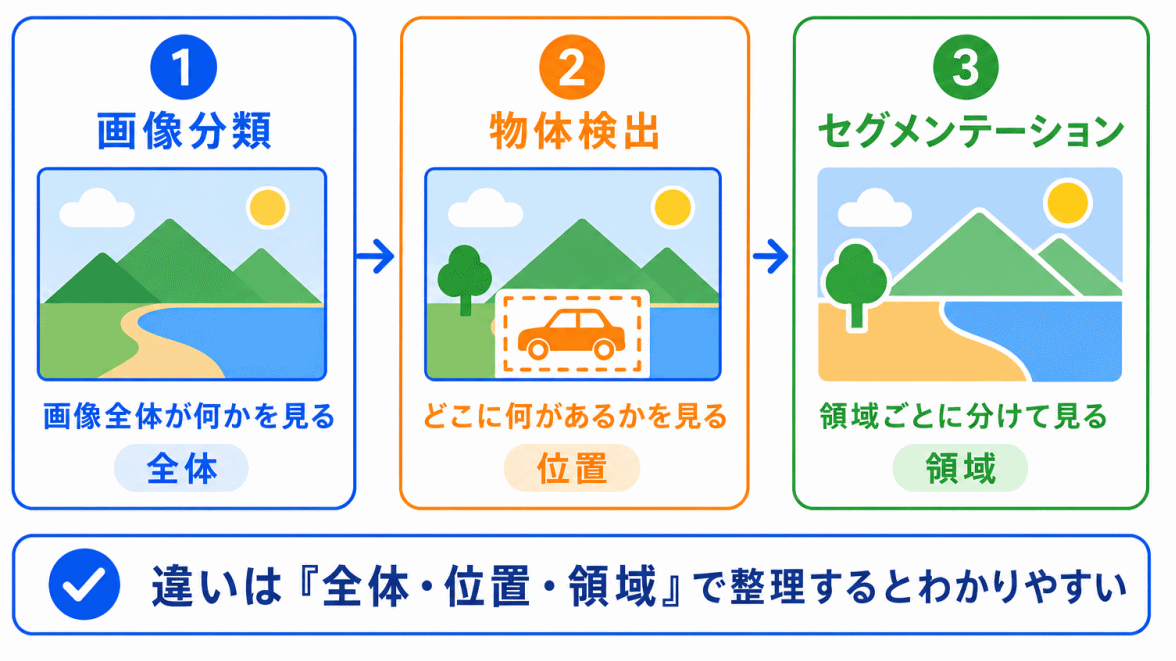
画像認識では、モデル名だけでなく、画像をどう扱うかも混同しやすいポイントです。
特に、画像分類、物体検出、セグメンテーションはセットで整理しておくとよいです。
| 用語 | 見ているもの |
|---|---|
| 画像分類 | 画像全体が何か |
| 物体検出 | どこに何があるか |
| セグメンテーション | どの領域が何か |
たとえば、猫の画像があるとします。
画像分類では、「これは猫の画像」と判断します。
物体検出では、「画像のこの位置に猫がいる」と判断します。
セグメンテーションでは、「このピクセルの領域が猫」と細かく分けます。
つまり、違いは次のように整理できます。
| 処理 | 一言でいうと |
|---|---|
| 画像分類 | 全体を見る |
| 物体検出 | 位置を見る |
| セグメンテーション | 領域を見る |
この3つは、G検定でも混同しやすいので、全体・位置・領域で覚えると整理しやすいです。
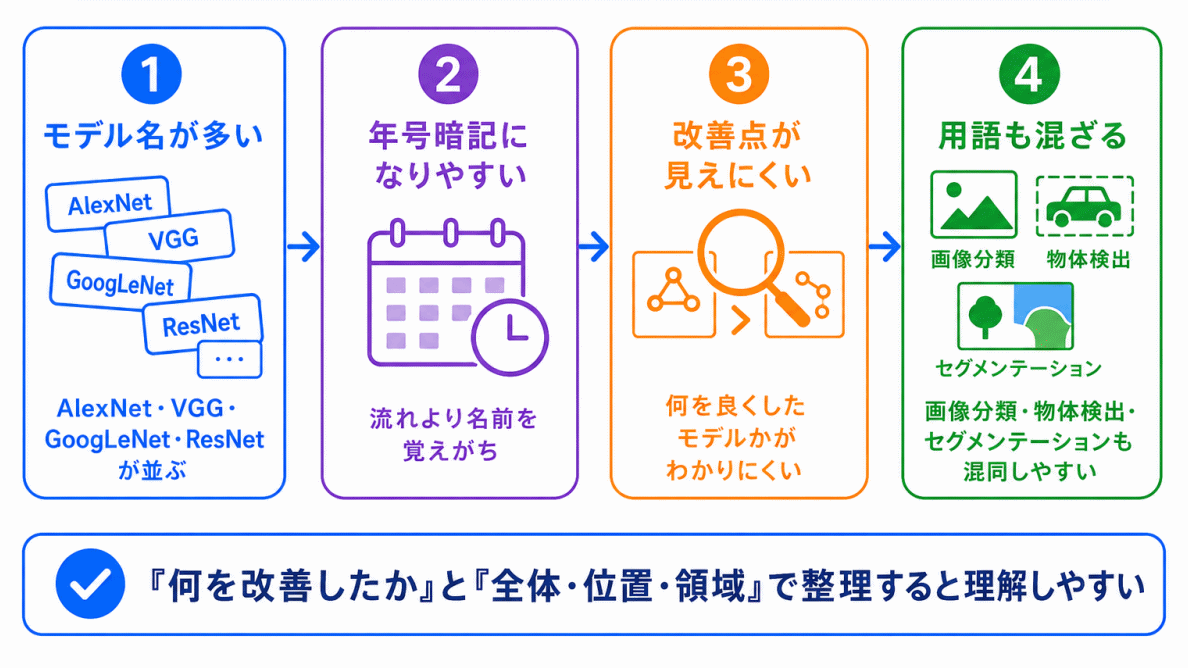
画像認識の歴史が混同しやすい理由は、モデル名だけを見ても、何を改善したのかがわかりにくいからです。
| 混同しやすいポイント | 整理の見方 |
|---|---|
| モデル名が似ている | 何を改善したモデルかで見る |
| 年号暗記になりやすい | 技術の流れで見る |
| CNN関連の用語が多い | 画像の特徴をどう捉えるかで見る |
| 画像分類・物体検出・セグメンテーションが混ざる | 全体・位置・領域で分ける |
特に、AlexNet、VGG、GoogLeNet、ResNetは、名前だけを覚えようとすると混乱しやすくなります。
そのため
どのモデルが、前の技術のどんな課題を改善したのか
で整理することが大切です。
G検定では、画像認識の歴史について、細かい実装よりも、代表的なモデルの特徴や関係が問われやすいです。
| 問われやすいポイント | 整理のしかた |
|---|---|
| 画像認識で重要なモデル | CNN |
| ディープラーニングが注目されたきっかけ | AlexNet |
| 小さな畳み込みを重ねる | VGG |
| Inceptionと関係が深い | GoogLeNet |
| 残差学習・スキップ接続 | ResNet |
| 画像全体を判断する | 画像分類 |
| 画像内の位置を見つける | 物体検出 |
| 領域ごとに分ける | セグメンテーション |
覚えるときは、次のように並べると理解しやすくなります。
このように、モデル名と改善点をセットで覚えると、問い方が変わっても対応しやすくなります。
画像認識の歴史は
画像の特徴を、より深く、よりうまく、より学習しやすく捉えるための進化
として整理できます。
| 流れ | ざっくりした意味 |
|---|---|
| AlexNet | 深いCNNの有効性を示した |
| VGG | 小さな畳み込みを重ねた |
| GoogLeNet | 複数の見方を組み合わせた |
| ResNet | 深いモデルを学習しやすくした |
画像認識では、モデル名だけを覚えるよりも
画像の特徴をどう捉える工夫なのか
で見ることが大切です。
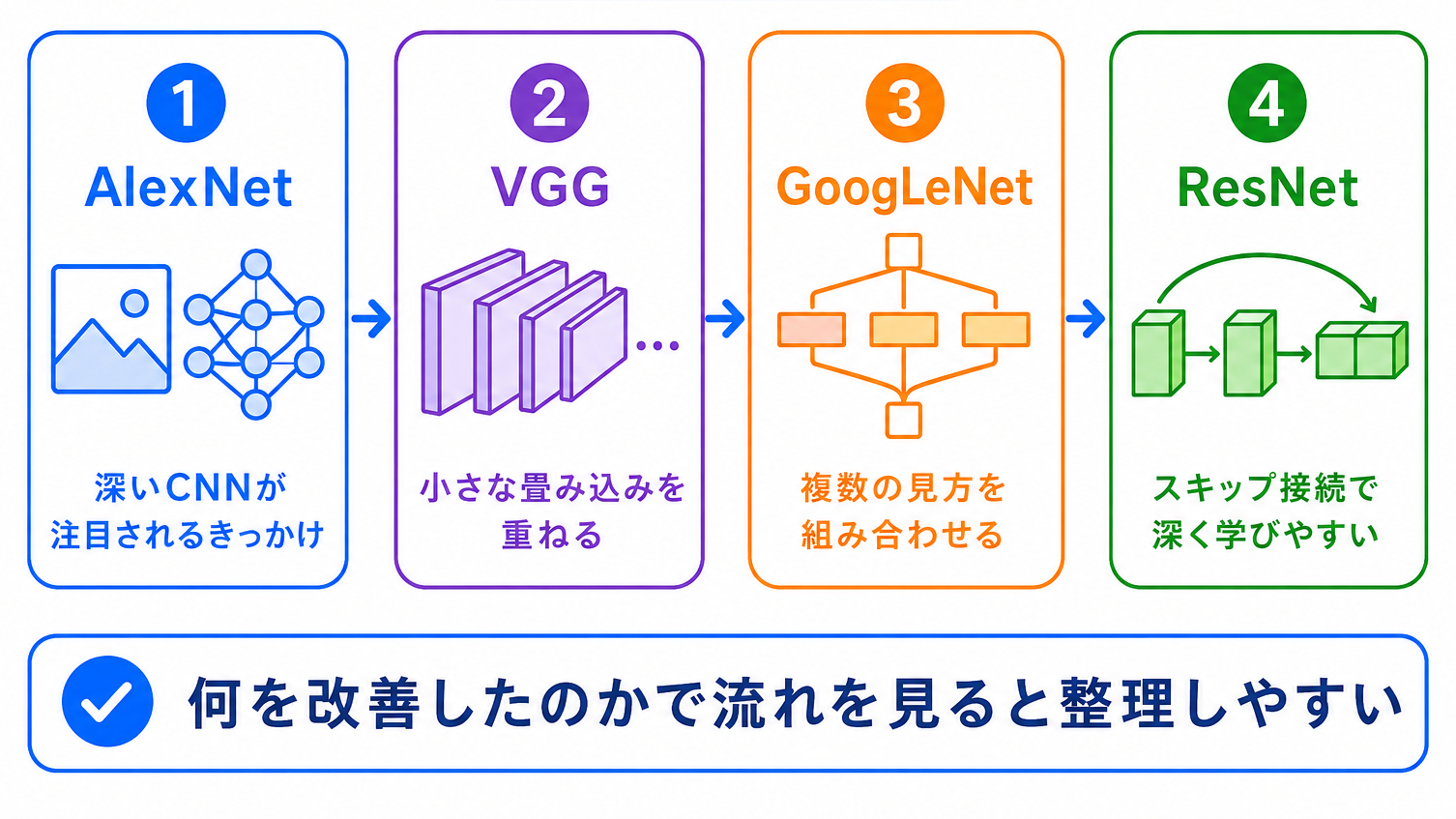
画像認識の歴史は、似たようなモデル名が続くため、暗記だけでは混乱しやすい分野です。
AlexNet は、ディープラーニングが画像認識で注目されるきっかけになりました。
VGG は、小さな畳み込みを重ねて深いCNNを作りました。
GoogLeNet は、Inceptionによって複数の見方を組み合わせました。
ResNet は、スキップ接続によって、深いネットワークでも学習しやすくしました。
また、画像認識では、画像分類、物体検出、セグメンテーションの違いも重要です。
この3つは
画像全体か、位置か、領域か
で整理すると理解しやすくなります。
G検定では、画像認識の歴史を年号だけで覚えるよりも
どのモデルが何を改善したのか
を流れで理解しておくことが大切です。
画像認識の歴史を理解したら、CNN・RNN・Transformerの違い、ディープラーニングの応用例、勾配消失問題、Transformerとの関係もあわせて整理しておくと理解しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| CNN・RNN・Transformerの違い | CNN/RNN/Transformer/得意なデータの違い |
| ディープラーニングの応用例とは? | 画像認識/自然言語処理/音声認識/生成AI |
| 勾配消失問題とは? | 深いネットワーク/学習のしにくさ/ResNetとの関係 |
| Transformerとは? | Attention/文脈理解/CNNとの違い |
| AI技術の進化とは? | AI技術の流れ/課題と改善/用語同士の関係 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。