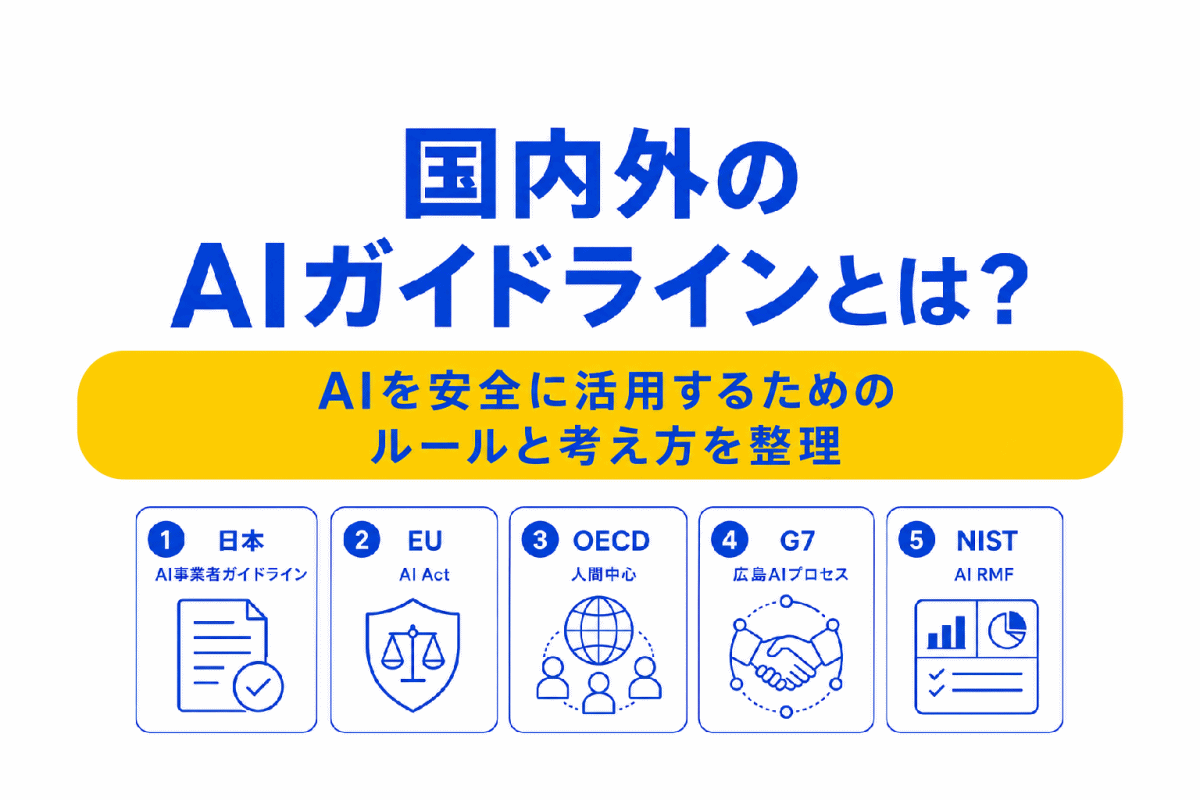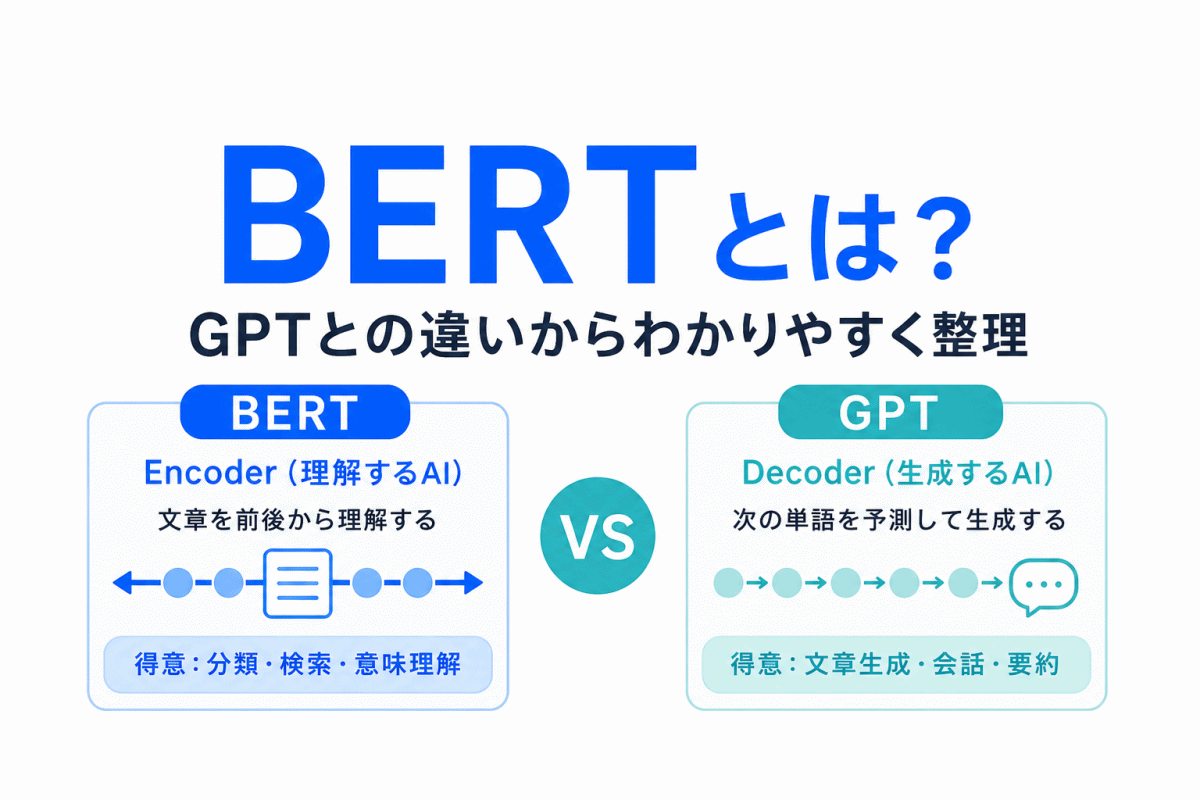
【G検定対策】BERTとは?|GPTとの違いからわかりやすく整理
seo-webmaster
G検定対策ブログ
ディープラーニングでは、AIは「間違い」を少しずつ修正しながら学習しています。
しかし、ニューラルネットワークが深くなると、その修正情報が途中でどんどん弱くなり、うまく学習できなくなることがあります。
これが「勾配消失問題」です。
特にG検定では、RNN・LSTM・Transformerなどの進化理由と深く関係している重要テーマです。
この記事では、AI内部で何が起きているのかを流れで整理しながら、「なぜ学習しにくくなるのか?」を理解型でわかりやすく解説します。
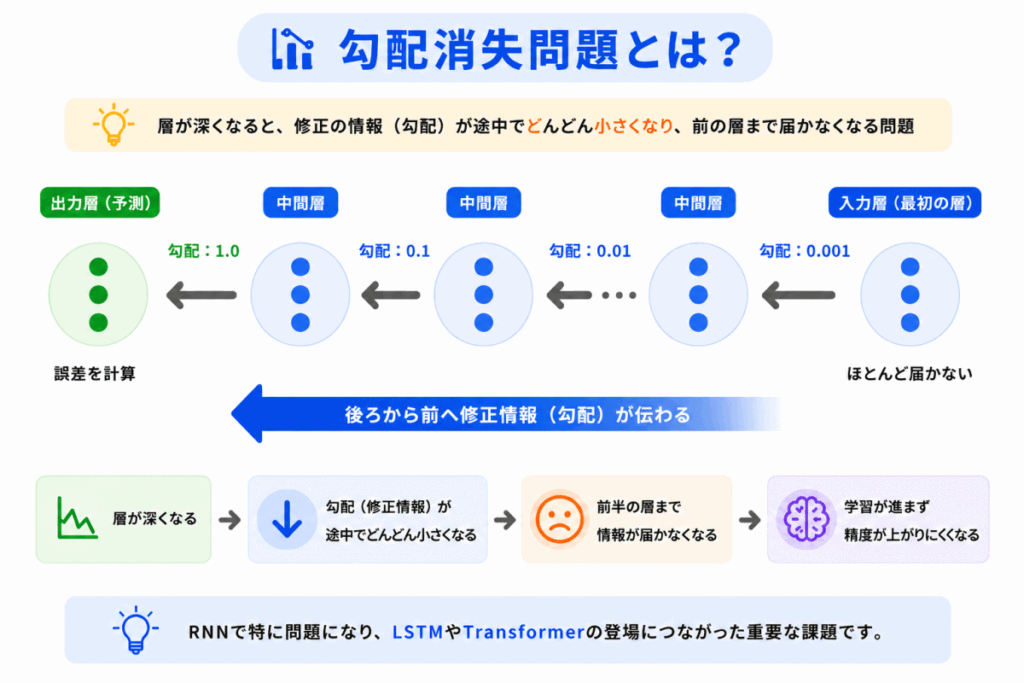
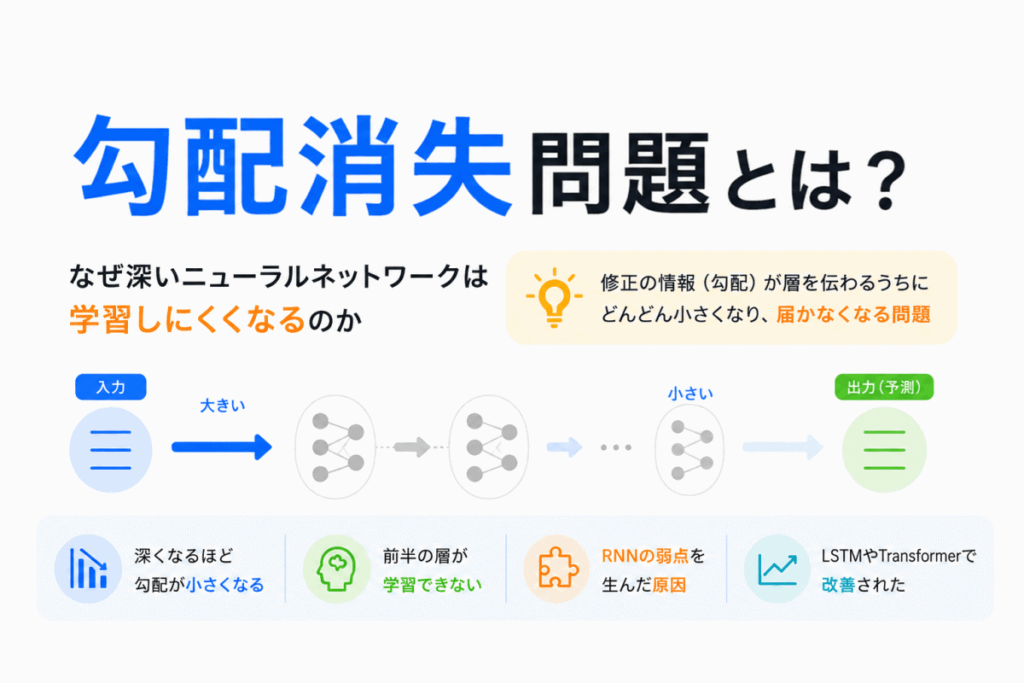
勾配消失問題とは「修正情報(勾配)が途中で弱くなり、学習しにくくなる問題」です。
ニューラルネットワークが深くなるほど、後ろから伝わる修正情報がどんどん小さくなり、前半の層まで修正が届きにくくなります。
その結果
などの問題が発生します。
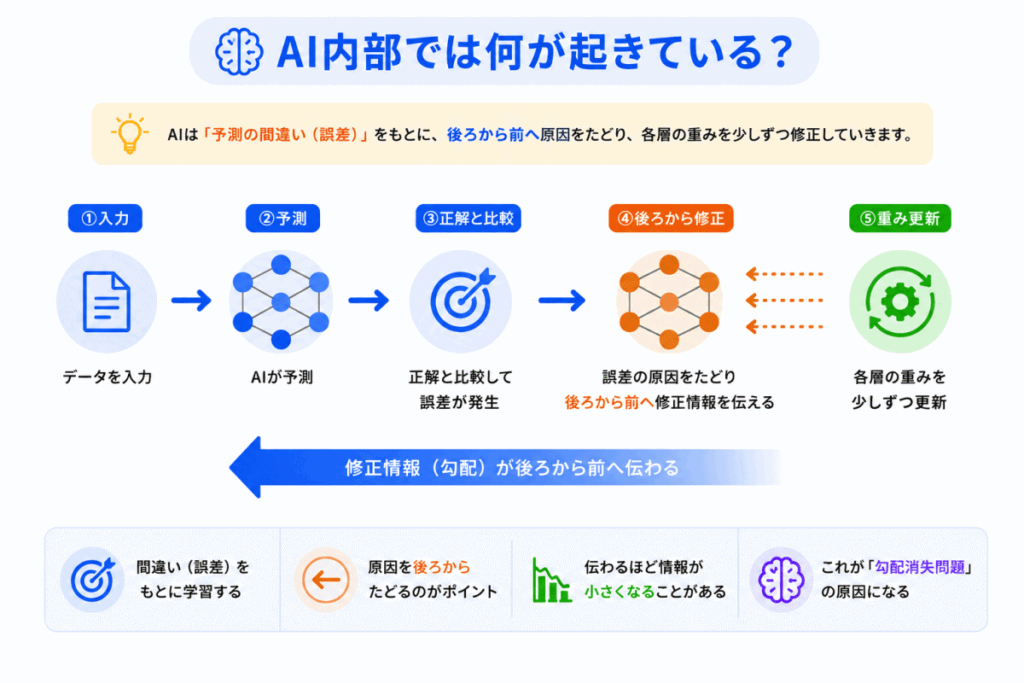
AI内部では、次の流れで学習が行われています。
ここで重要なのが「後ろから修正する」という点です。
AIは出力側から順番に
を逆方向に伝えていきます。
しかし、層が深くなると、修正情報が途中でどんどん弱くなる ことがあります。
その結果
状態になります。
これが勾配消失問題です。
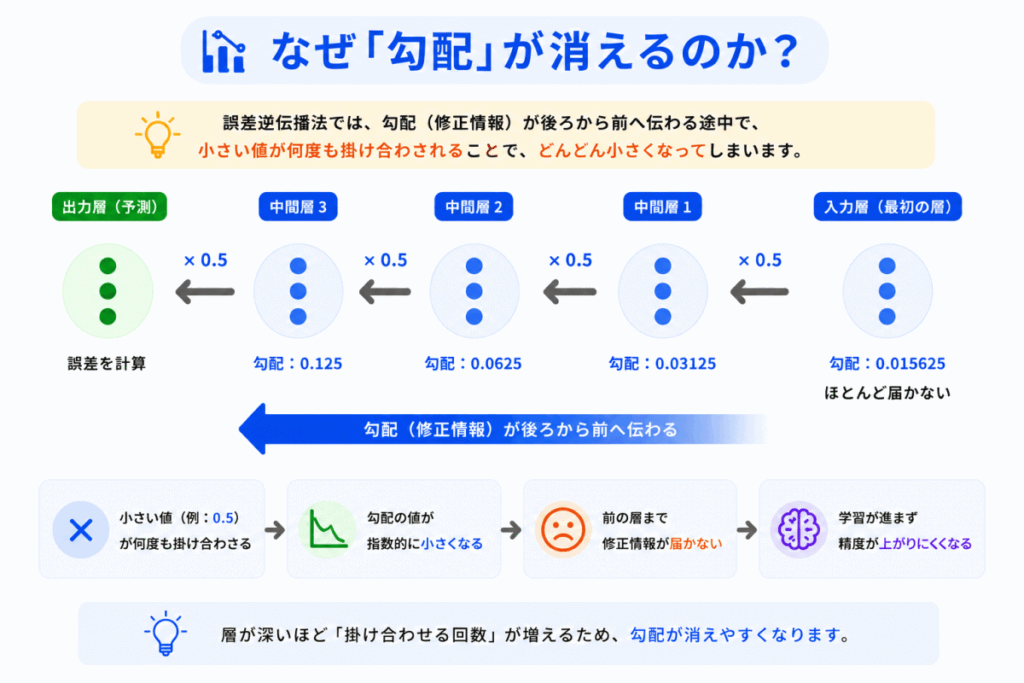
ここでいう「勾配」は「どれくらい修正するべきか?」を示す情報です。
誤差逆伝播法では、この修正量を後ろから前へ伝えていきます。
しかし途中で
が何度も掛け合わされると、数値がどんどん小さくなります。
イメージとしては
のように弱くなっていく感じです。
すると最初の層では「ほぼ修正されない」状態になります。
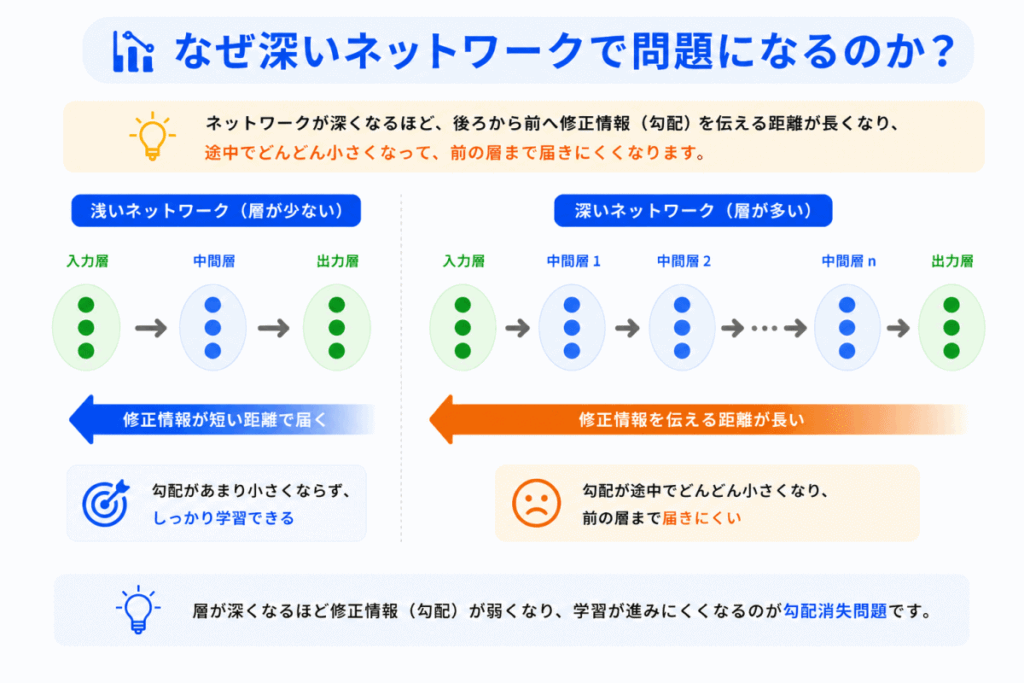
浅いネットワークでは、修正情報が短距離で届きます。
しかし、ディープラーニングでは、層が非常に多くなります。
その結果
のように長距離で修正情報を伝える必要があります。
すると途中で 修正情報が弱くなりすぎる 問題が発生します。
これが「深いほど学習が難しい」理由のひとつです。
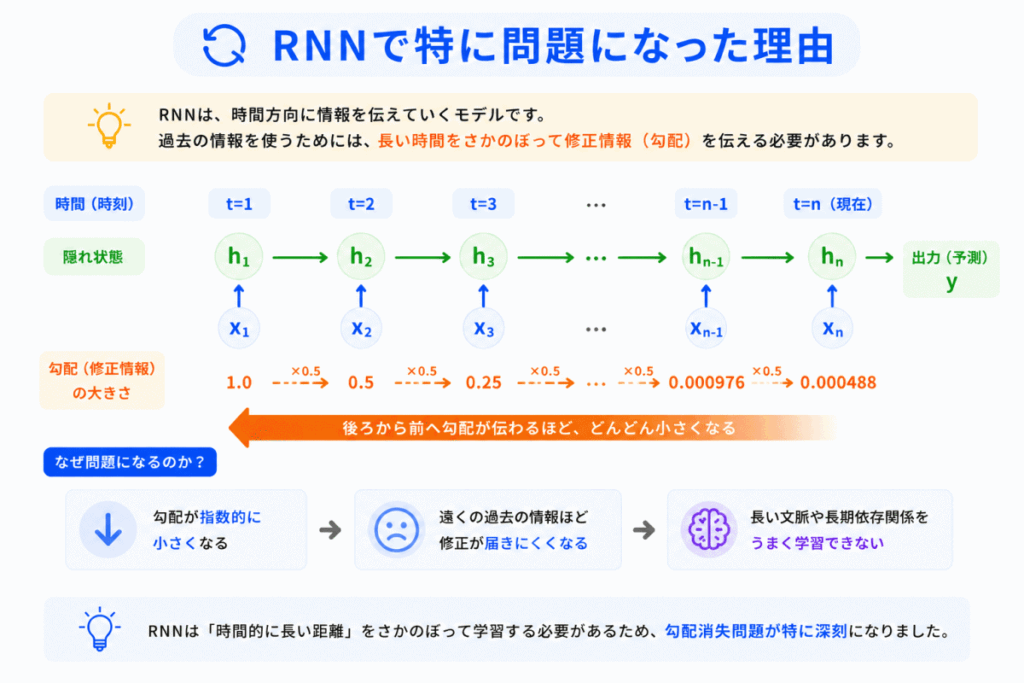
G検定ではここが重要です。
RNNは「過去情報を順番に保持する」モデルです。
しかし、文章が長くなると
のように情報伝達距離が長くなります。
すると 修正情報が途中で消えやすくなる ため
問題が発生しました。
これがRNNの弱点でした。
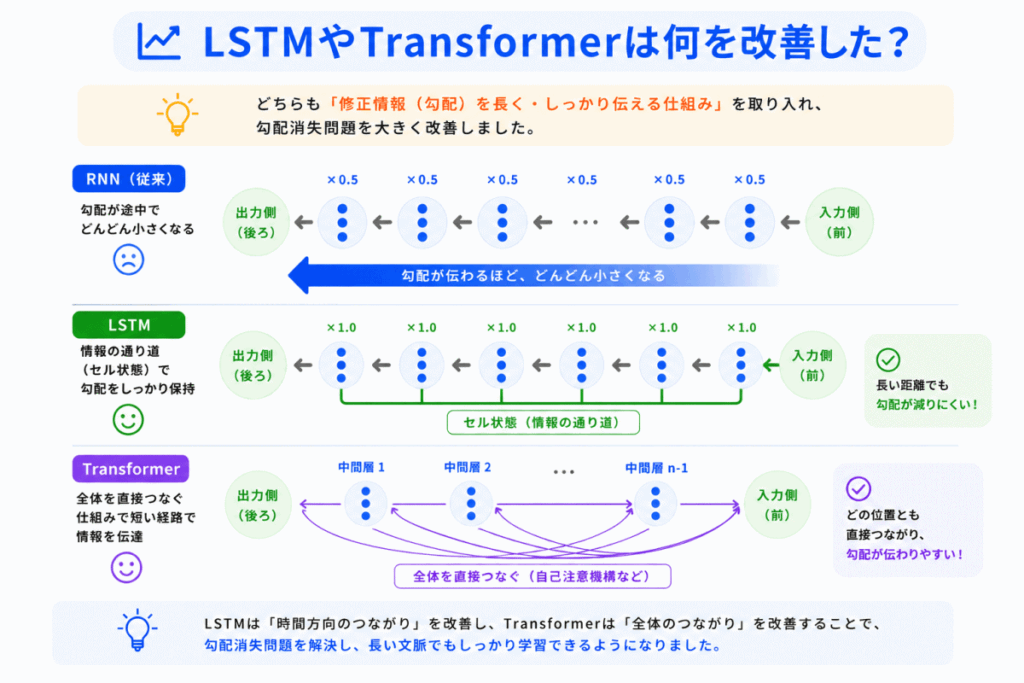
この問題を改善するために登場したのが
です。
LSTMは「重要情報を保持しやすくする」ことで改善しました。
Transformerはさらに「遠い情報を直接参照する」Attention機構を利用しました。
これによって
が大きく進化しました。
つまり、勾配消失問題は生成AI進化の歴史ともつながっている のです。
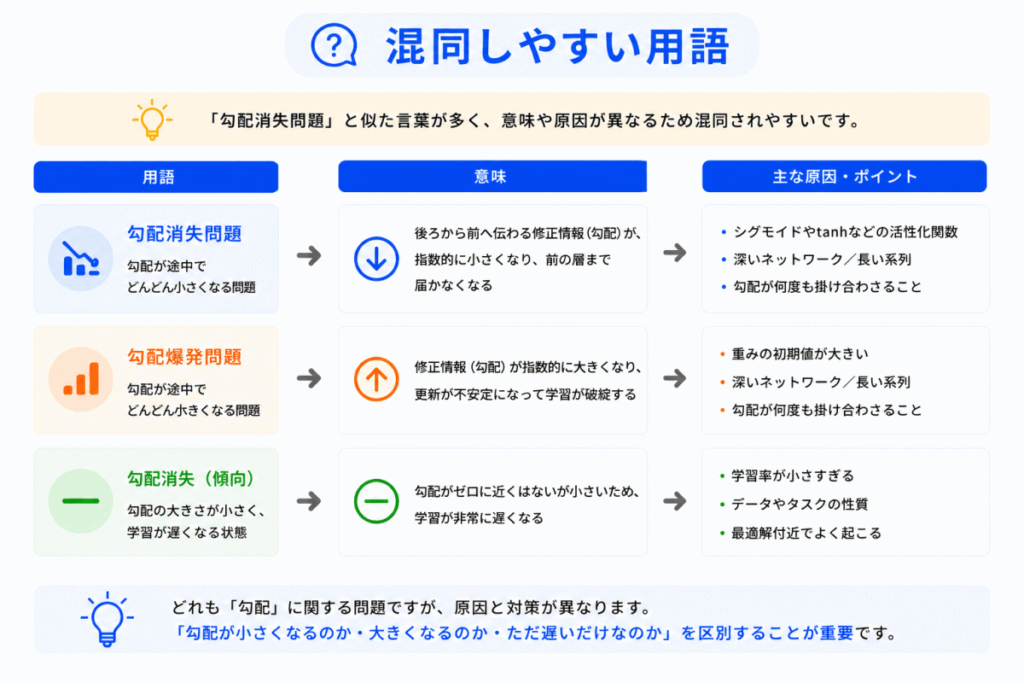
AIの学習をはじめたばかりの人は、次の用語を混同しやすいです。
特に「学習できない」という点が共通しているため混同しやすいです。
しかし、原因はそれぞれ異なります。
G検定では
として問われやすいです。
特に「なぜTransformerが重要だったのか?」を理解するには、勾配消失問題の理解が重要です。
単なる用語暗記ではなく「なぜ従来モデルが苦しかったのか?」を理解しておくと強くなります。
勾配消失問題とは「修正情報が途中で弱くなり、学習しにくくなる問題」です。
特に
で問題になりました。
そして、この問題を改善する流れが
という生成AI進化にもつながっています。
つまり勾配消失問題は「なぜ生成AIが進化したのか?」を理解する重要テーマでもあるのです。
勾配消失問題を理解するには、誤差逆伝播法、活性化関数、ニューラルネットワークの基本構造との関係をあわせて整理しておくと理解しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| 誤差逆伝播法とは? | 後ろから修正する仕組み/勾配/重み更新 |
| 活性化関数とは? | ReLU/シグモイド関数/勾配消失問題との関係 |
| ニューラルネットワークとは? | 層/重み/バイアス/深いネットワーク |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。