【G検定|理解型予想問題】損失関数・勾配降下法・学習率
seo-webmaster
G検定対策ブログ
バイアスと分散は、重要テーマです。
ただし
を言葉だけで覚えていると、少し聞き方が変わっただけで混乱しやすくなります。
この記事では
まで含めて整理していきます。
機械学習における「バイアス」の説明として、最も適切なものはどれか?
C
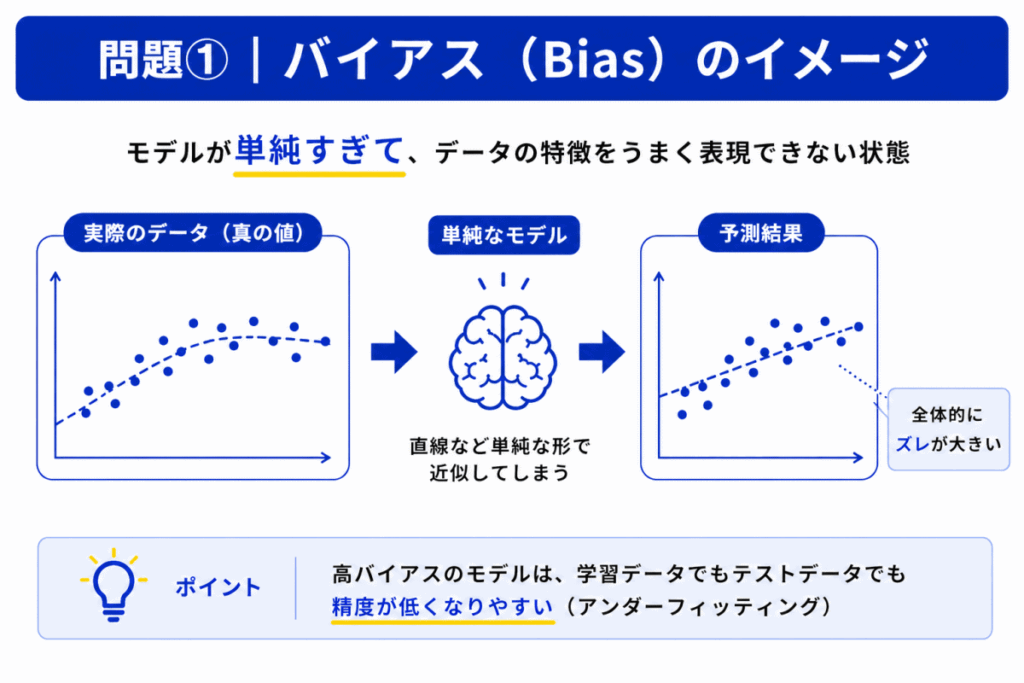
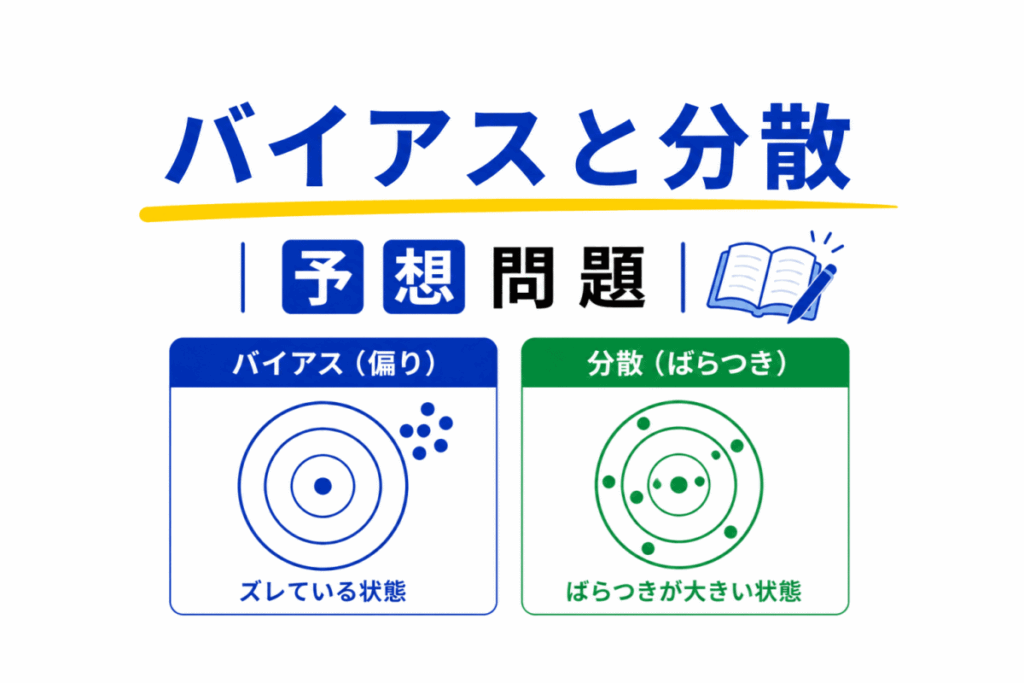
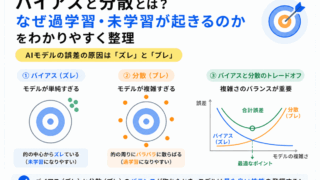
バイアス(Bias)は「予測が全体的にズレる傾向」を表します。
つまり
では、データの特徴を十分学習できず「そもそも予測がズレやすい」状態になります。
これが「高バイアス」です。
高バイアスでは
という特徴があります。
機械学習における「分散」の説明として、最も適切なものはどれか?
A
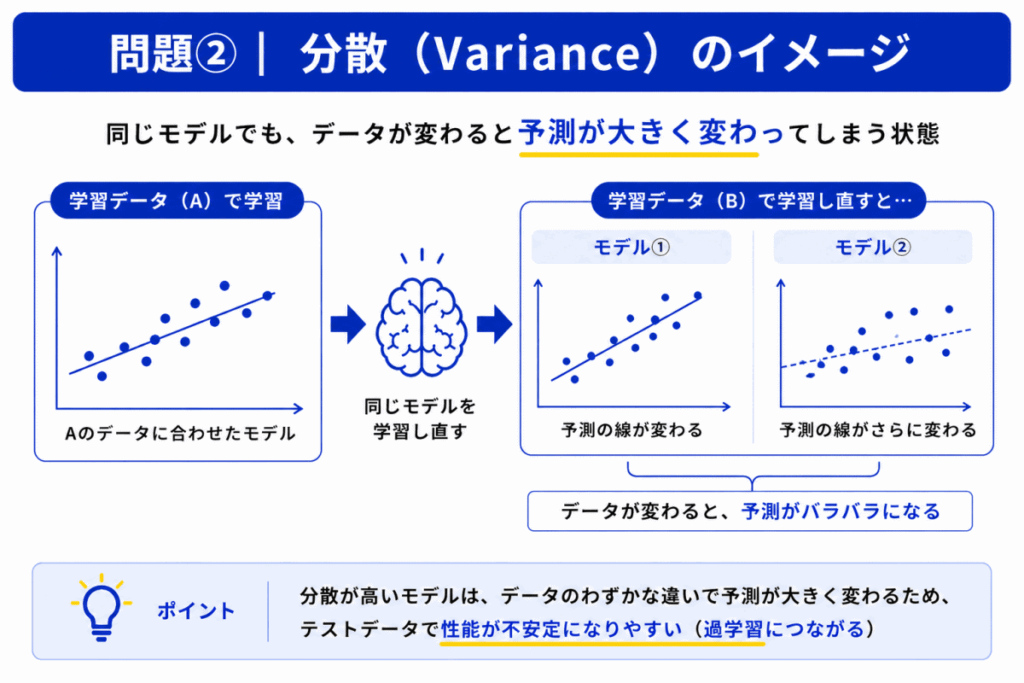
分散(Variance)は「データによって予測が変わりやすい状態」を表します。
複雑すぎるモデルでは
まで学習してしまい「データが少し変わるだけで予測も大きく変わる」状態になります。
これが「高分散」です。
高分散では
が起きやすくなります。
これは過学習と深く関係しています。
高バイアスなモデルで起きやすい現象として、最も適切なものはどれか?
B
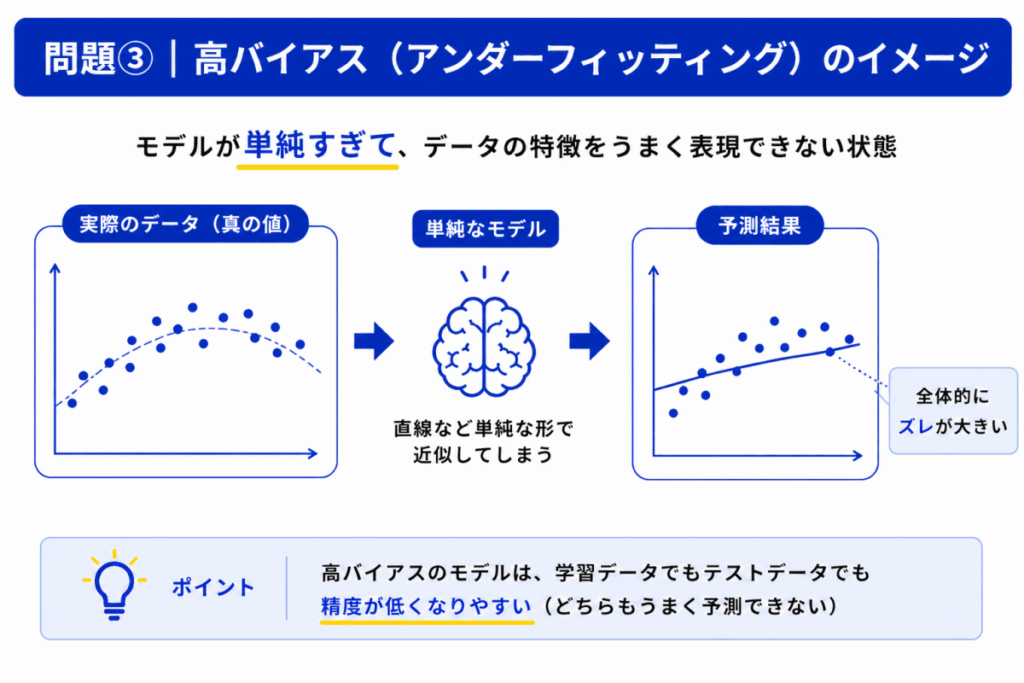
高バイアスでは「モデルが単純すぎる」ことが問題になります。
そのため
をうまく表現できません。
結果として「全体的に精度が低い」状態になります。
これは アンダーフィッティング(過小適合)とも呼ばれます。
高分散なモデルで起きやすい現象として、最も適切なものはどれか?
C
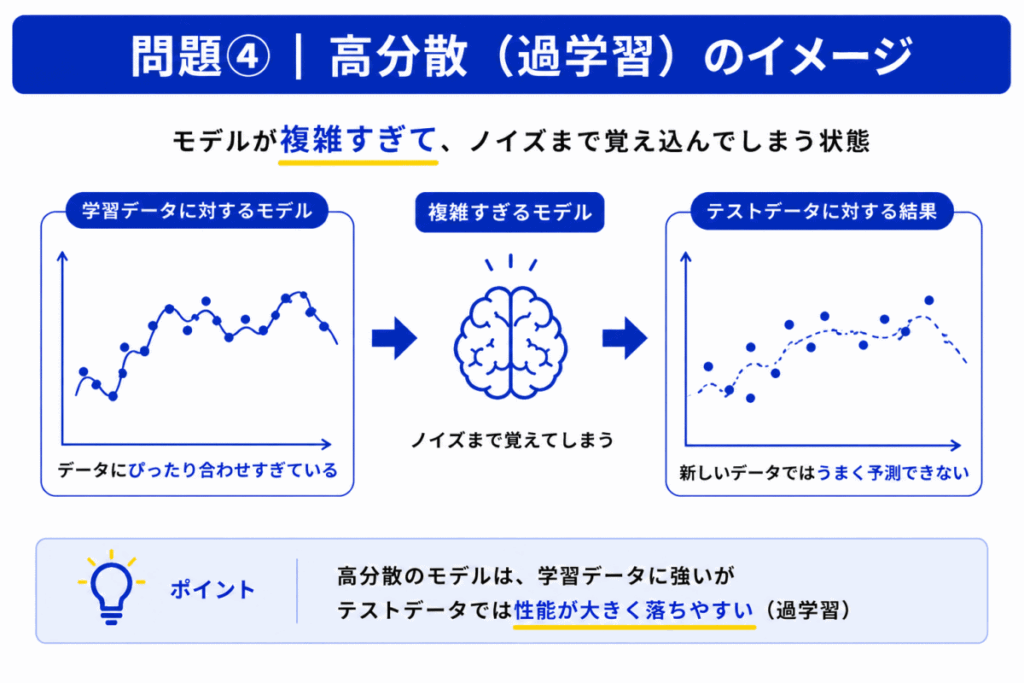
高分散では「モデルが複雑すぎる」ことが問題になります。
その結果、本来学習しなくてもよい
まで覚え込んでしまいます。
これにより「学習データには強いが、本番に弱い」状態になります。
これは 過学習(Overfitting)と強く関係しています。
「過学習」に最も関係が深いものはどれか?
B
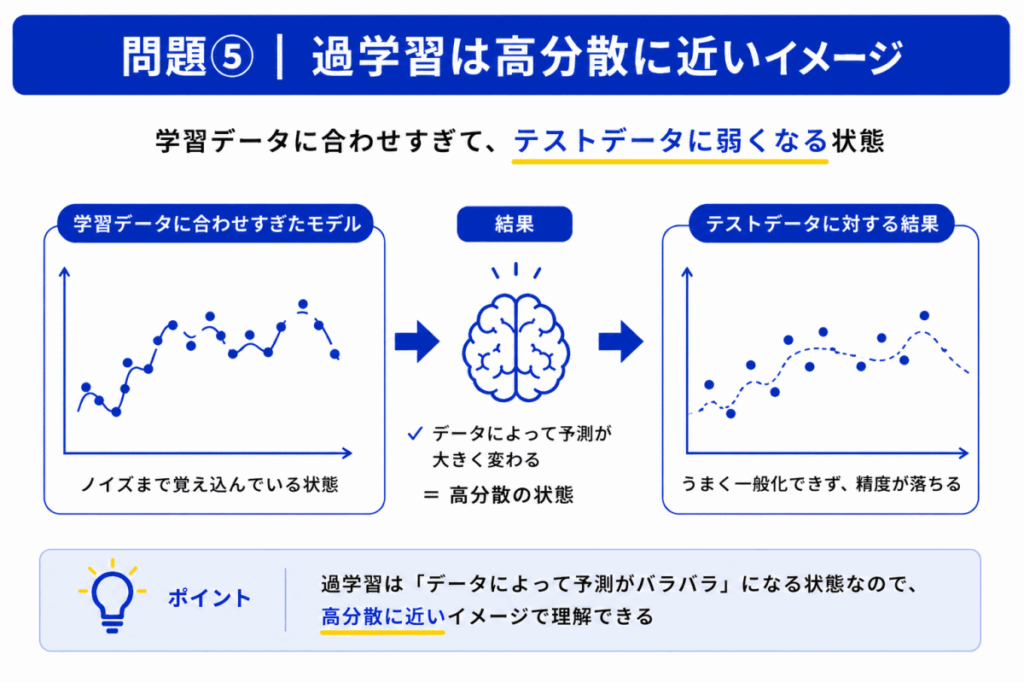
過学習は「学習データに合わせすぎた状態」です。
つまり
まで覚えてしまっています。
これは「データによって予測が大きく変わる」高分散の特徴と一致します。
ここは試験でもかなり重要です。
整理すると
となります。
複雑なモデルほど高分散になりやすい理由として、最も適切なものはどれか?
B
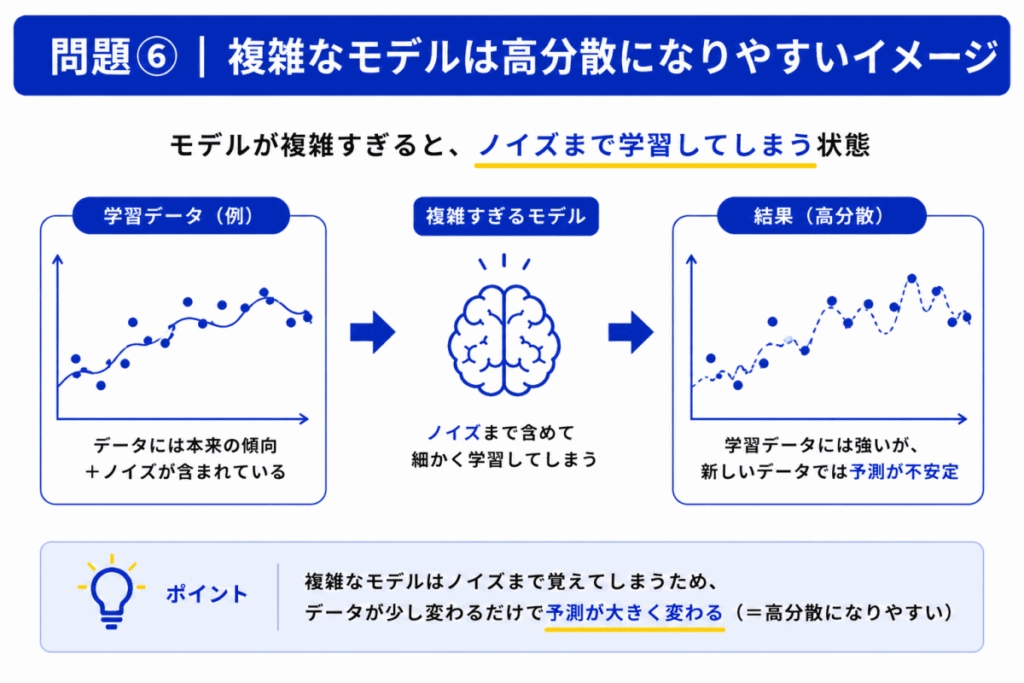
モデルが複雑になると「表現力」が上がります。
これは一見良さそうですが、同時に
まで学習しやすくなります。
結果として「データ変更への弱さ」が増えてしまいます。
これが高分散です。
つまり「賢すぎるモデル」が危険になることがあります。
これは誤解しやすいポイントです。
バイアスと分散を初心者が混同しやすい理由として、最も適切なものはどれか?
B
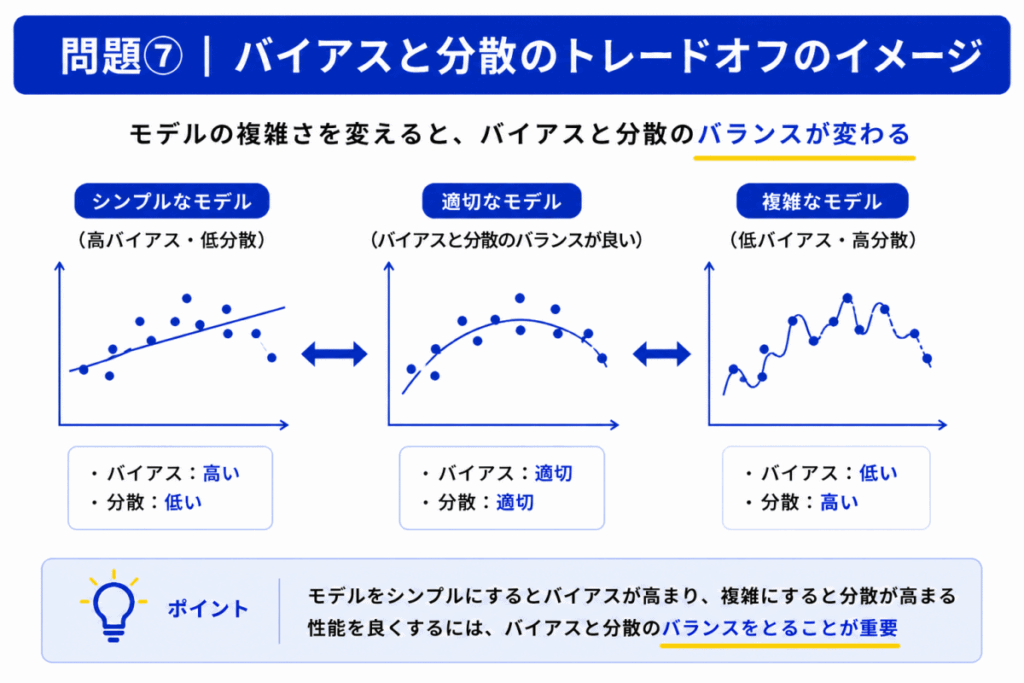
初心者が混乱しやすい理由は「どちらも精度が悪く見える」からです。
しかし実際は
| 状態 | 原因 |
|---|---|
| 高バイアス | 単純すぎる |
| 高分散 | 複雑すぎる |
という違いがあります。
つまり「悪くなる理由」が真逆なのです。
ここを暗記だけで覚えると
が頭の中でバラバラになります。
重要なのは「モデルが単純すぎるのか?」、「複雑すぎるのか?」を線で理解することです。
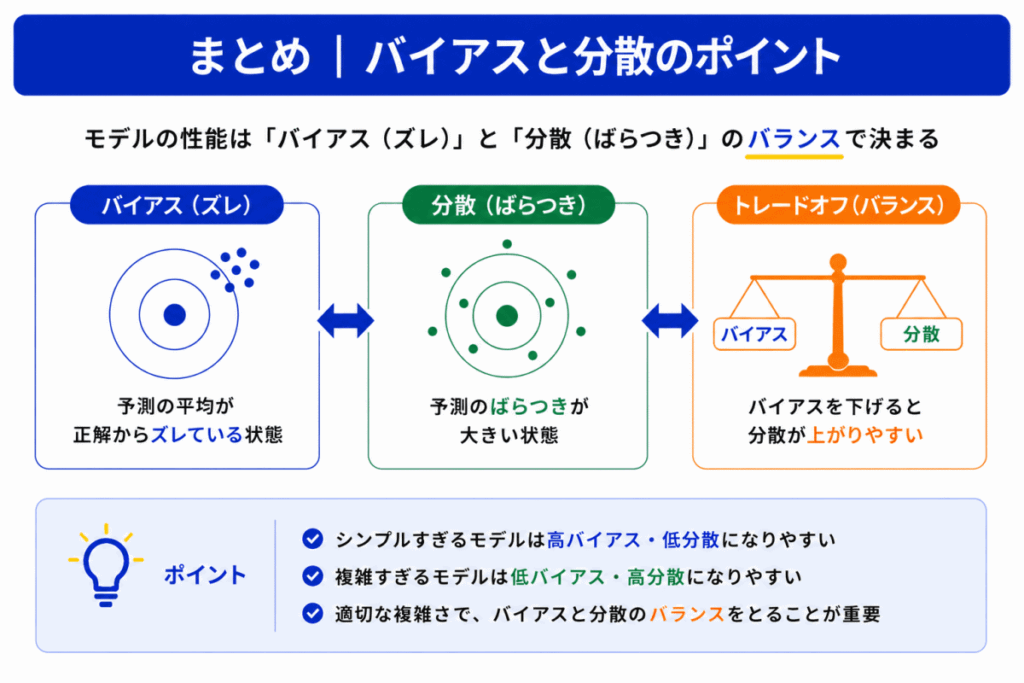
バイアスと分散は、非常に重要なテーマです。
ただし
を単語だけで覚えると、少し聞き方が変わっただけで混乱しやすくなります。
重要なのは
という関係を整理することです。
この関係が理解できると
なども線で理解しやすくなります。
G検定では「単語暗記」より「なぜそうなるのか」を意識すると、問い方変更にも強くなります。
この予想問題よりもバイアスと分散の詳しく整理しています。
もっと詳しく学習したい方はご覧ください。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。