【G検定対策】人工知能とは?|AIの定義・強いAI・弱いAIをわかりやすく整理
seo-webmaster
G検定対策ブログ
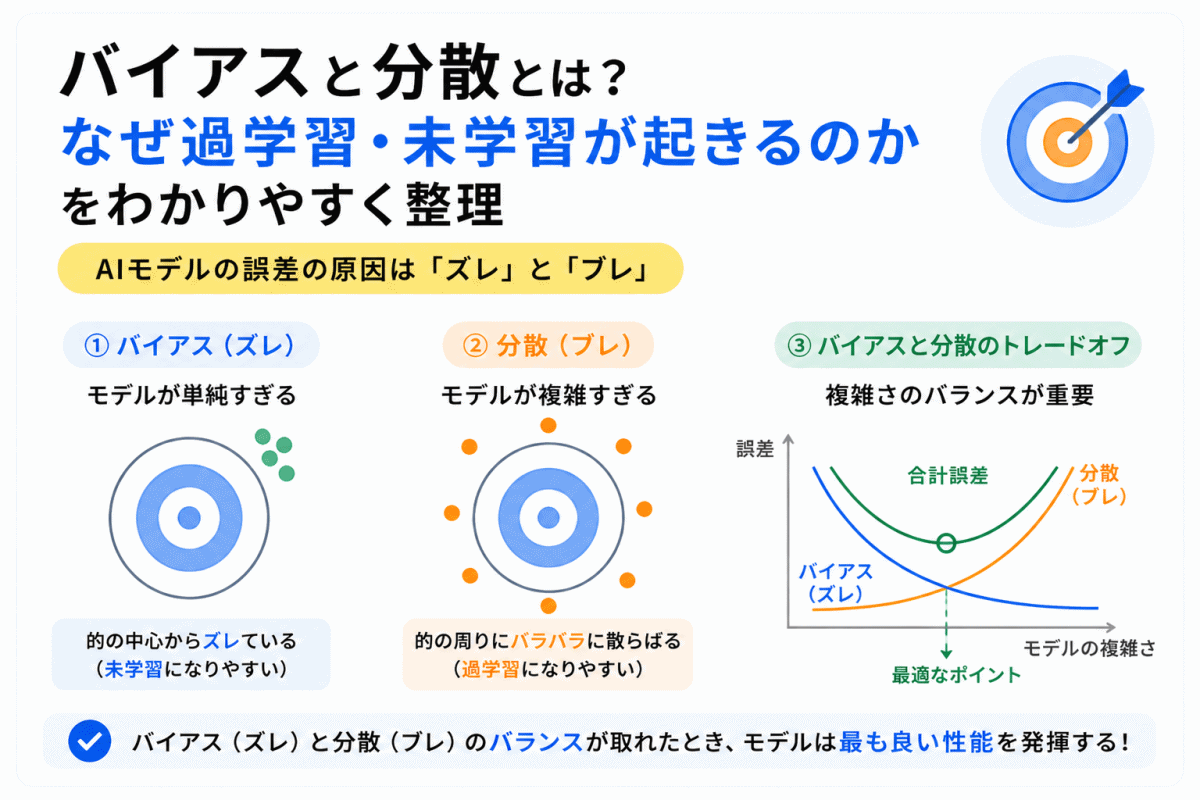
バイアスと分散は、AIモデルがうまく学習できているかを考えるための重要な見方です。
バイアスは「正解からのズレ」、分散は「データによるブレ」と考えると理解しやすくなります。
モデルが単純すぎると未学習になりやすく、複雑すぎると過学習になりやすくなります。
G検定では、バイアスと分散を単独で覚えるよりも、未学習・過学習・正則化・ドロップアウトとの関係で整理しておくことが大切です。
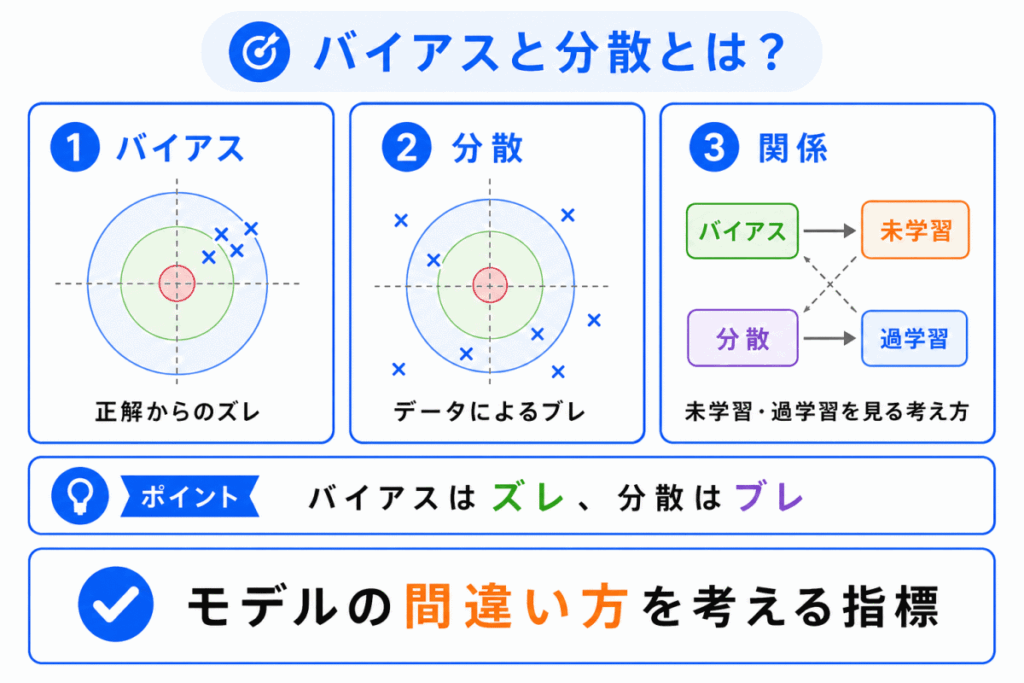
バイアスと分散は、モデルの予測がどのように間違うかを考えるための指標です。
簡単にいうと、バイアスは ズレ、分散は ブレ です。
| 用語 | 一言でいうと | 起きやすい状態 |
|---|---|---|
| バイアス | 正解からのズレ | モデルが単純すぎる |
| 分散 | データによるブレ | モデルが複雑すぎる |
バイアスが大きいと、そもそも正解に近づけていない状態になりやすいです。
一方、分散が大きいと、学習データには合っているのに、別のデータでは結果が大きく変わりやすくなります。
G検定では、バイアスと分散を 未学習と過学習を見分ける考え方 として押さえておくと理解しやすくなります。
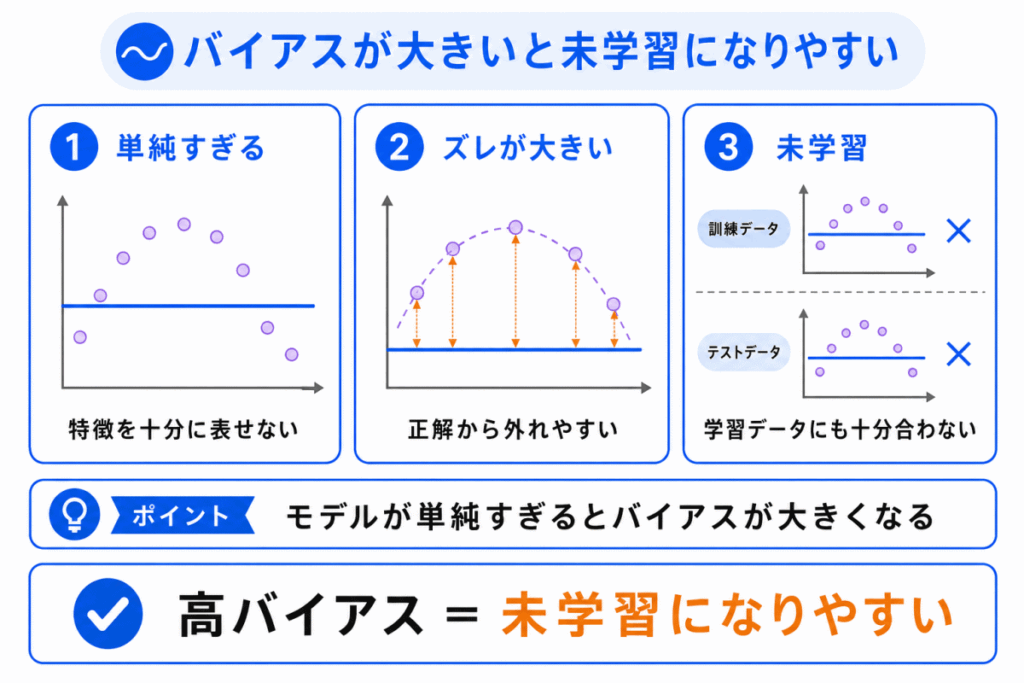
バイアスが大きいとは、モデルの予測が正解から大きくズレている状態です。
これは、モデルが単純すぎて、データの特徴を十分に表現できていないときに起こりやすくなります。
たとえば、本当は曲線のような関係があるデータを、直線だけで無理に表そうとすると、全体的にズレた予測になりやすくなります。
| 状態 | 内容 |
|---|---|
| モデルが単純すぎる | データの特徴を表現しきれない |
| バイアスが大きい | 正解からズレやすい |
| 起きやすい問題 | 未学習 |
未学習とは、学習データに対しても十分に学習できていない状態です。
つまり、バイアスが大きいモデルは、学習データにも未知のデータにも弱くなりやすいといえます。
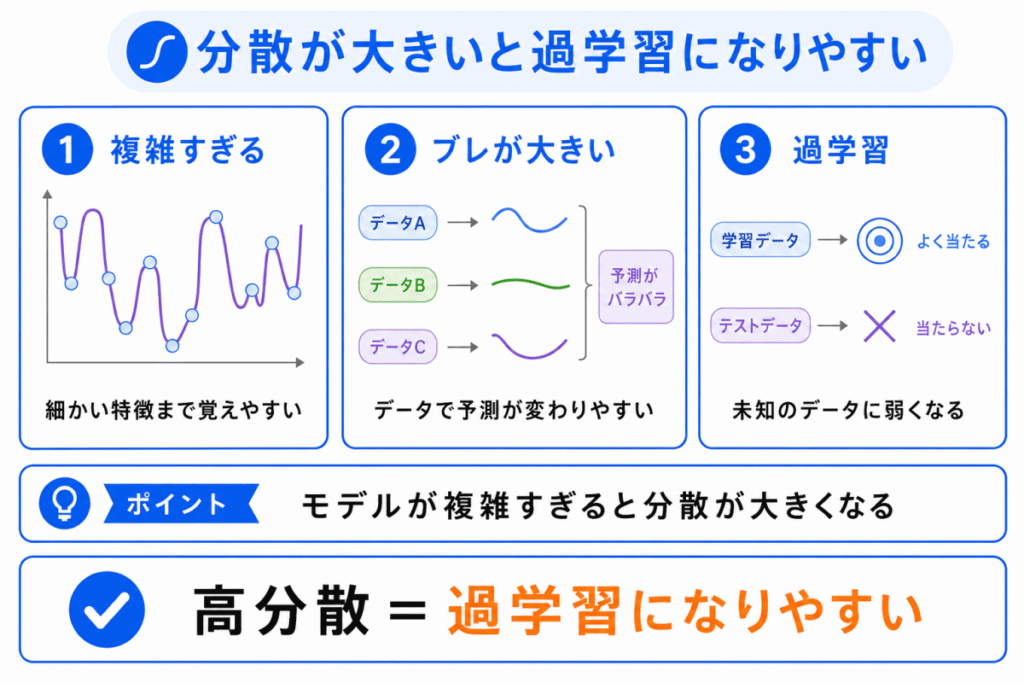
分散が大きいとは、学習データが少し変わっただけで、モデルの予測が大きく変わりやすい状態です。
これは、モデルが複雑すぎて、学習データの細かい特徴やノイズまで覚えてしまったときに起こりやすくなります。
| 状態 | 内容 |
|---|---|
| モデルが複雑すぎる | 学習データに合わせすぎる |
| 分散が大きい | データが変わると予測がブレやすい |
| 起きやすい問題 | 過学習 |
過学習とは、学習データにはよく合っているのに、未知のデータでは性能が落ちる状態です。
つまり、分散が大きいモデルは、学習データには強く見えても、新しいデータに弱くなりやすいといえます。
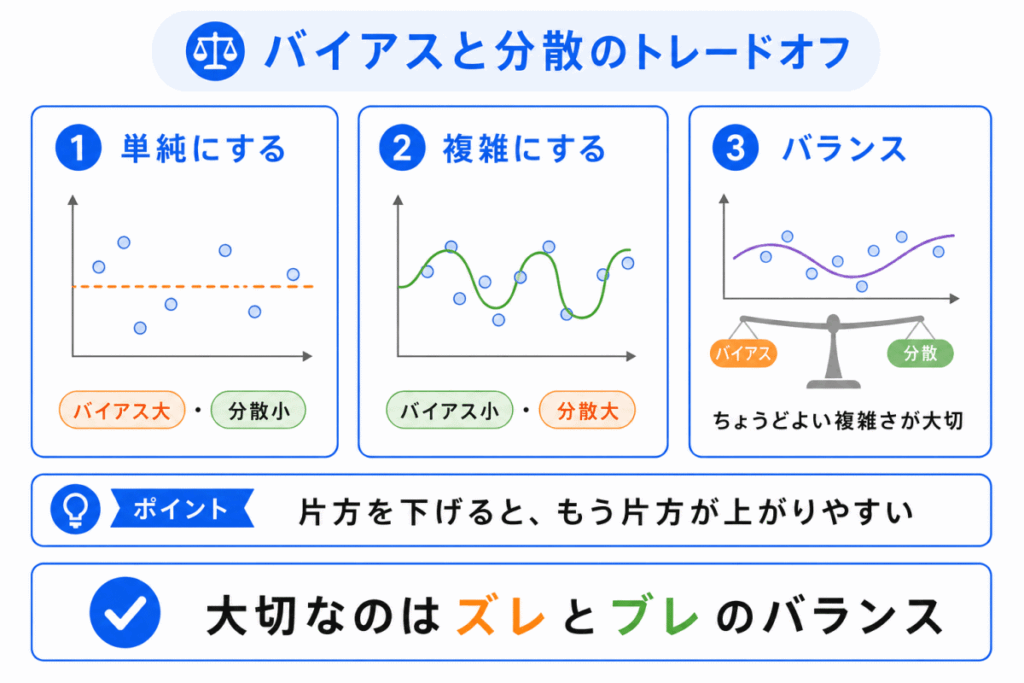
バイアスと分散は、どちらか一方だけを小さくすればよいわけではありません。
モデルを複雑にすると、バイアスは小さくなりやすいです。
しかし、複雑にしすぎると、今度は分散が大きくなりやすくなります。
反対に、モデルを単純にすると、分散は小さくなりやすいです。
しかし、単純すぎると、バイアスが大きくなりやすくなります。
| バイアス | 分散 | 起きやすい問題 |
|---|---|---|
| 大きい | 小さい | 未学習 |
| バイアス | 分散 | 起きやすい問題 |
|---|---|---|
| 小さい | 大きい | 過学習 |
| バイアス | 分散 | 起きやすい問題 |
|---|---|---|
| 適度 | 適度 | 汎化しやすい |
このように、バイアスと分散にはバランスがあります。
G検定では、この関係を バイアスと分散のトレードオフ として問われることがあります。
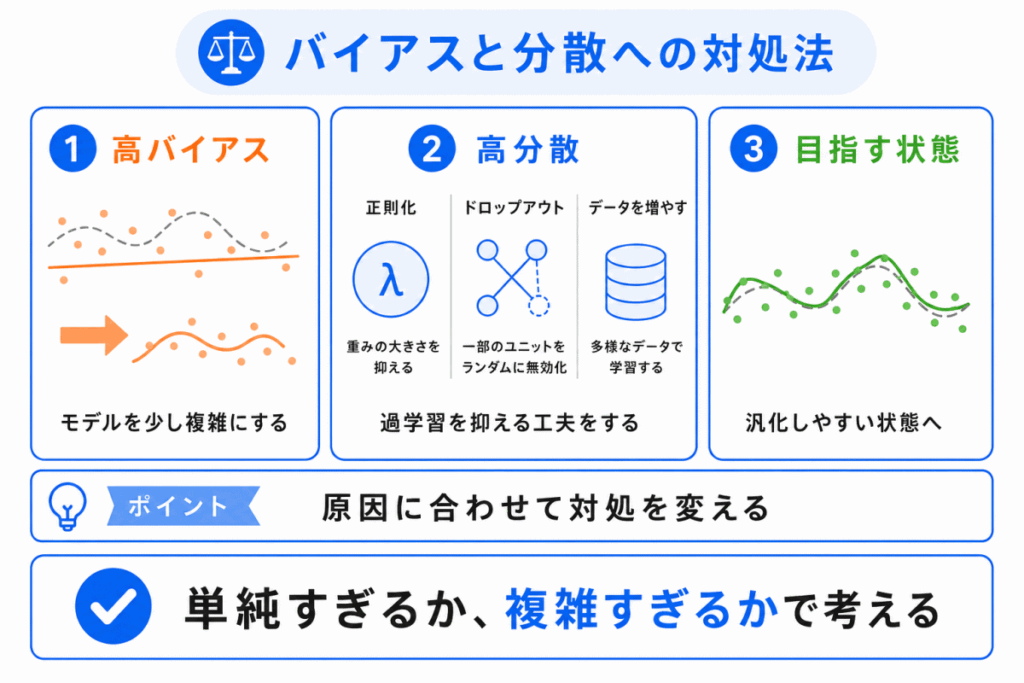
バイアスと分散への対処法は、モデルがどちらに偏っているかで変わります。
バイアスが大きい場合は、モデルが単純すぎる可能性があります。
この場合は、モデルを少し複雑にしたり、特徴量を見直したりします。
分散が大きい場合は、モデルが学習データに合わせすぎている可能性があります。
この場合は、正則化やドロップアウトなどで過学習を抑えます。
| 問題 | 起きていること | 対処の方向 |
|---|---|---|
| バイアスが大きい | 単純すぎる | モデルを複雑にする、特徴量を見直す |
| 分散が大きい | 複雑すぎる | 正則化、ドロップアウト、データ追加 |
| バランスが悪い | 未学習または過学習 | モデルの複雑さを調整する |
大切なのは、精度が低い原因を「ただ性能が悪い」と見るのではなく、単純すぎるのか、複雑すぎるのかで整理することです。
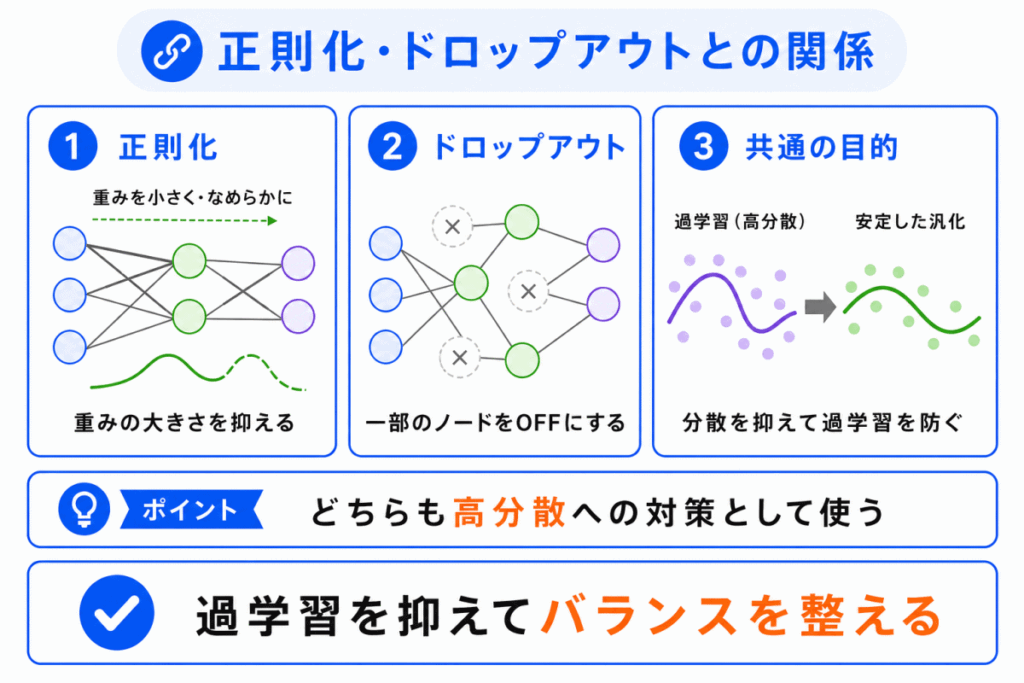
正則化やドロップアウトは、主に分散が大きくなりすぎることを抑えるために使われます。
つまり、過学習を防ぐための工夫です。
| 手法 | 役割 | 関係する問題 |
|---|---|---|
| 正則化 | モデルが複雑になりすぎるのを抑える | 過学習 |
| ドロップアウト | 一部のノードを無効化して依存を減らす | 過学習 |
| データ拡張 | 学習データを増やしたように扱う | 過学習 |
| 交差検証 | 汎化性能を確認する | 評価 |
正則化やドロップアウトを使うと、学習データへの合わせすぎを抑えやすくなります。
ただし、強くかけすぎると、今度はモデルが十分に学習できず、未学習に近づくこともあります。
そのため、バイアスと分散のバランスを見ながら調整することが重要です。
G検定では、バイアスと分散の細かい数式よりも、未学習・過学習との関係が問われやすいです。
特に、次の整理を押さえておくと判断しやすくなります。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| バイアス | 正解からのズレ |
| 分散 | データによるブレ |
| 高バイアス | モデルが単純すぎて未学習になりやすい |
| 高分散 | モデルが複雑すぎて過学習になりやすい |
| トレードオフ | 片方を下げると、もう片方が上がりやすい |
| 対策 | 正則化やドロップアウトで過学習を抑える |
「バイアス=悪い」、「分散=悪い」と単純に覚えるのではなく、どちらも大きすぎると問題になると考えると理解しやすくなります。
G検定では、次のような対応で整理しておくとよいです。
| 状態 | 起きやすい問題 |
|---|---|
| バイアスが大きい | 未学習 |
| 分散が大きい | 過学習 |
| バランスがよい | 汎化しやすい |
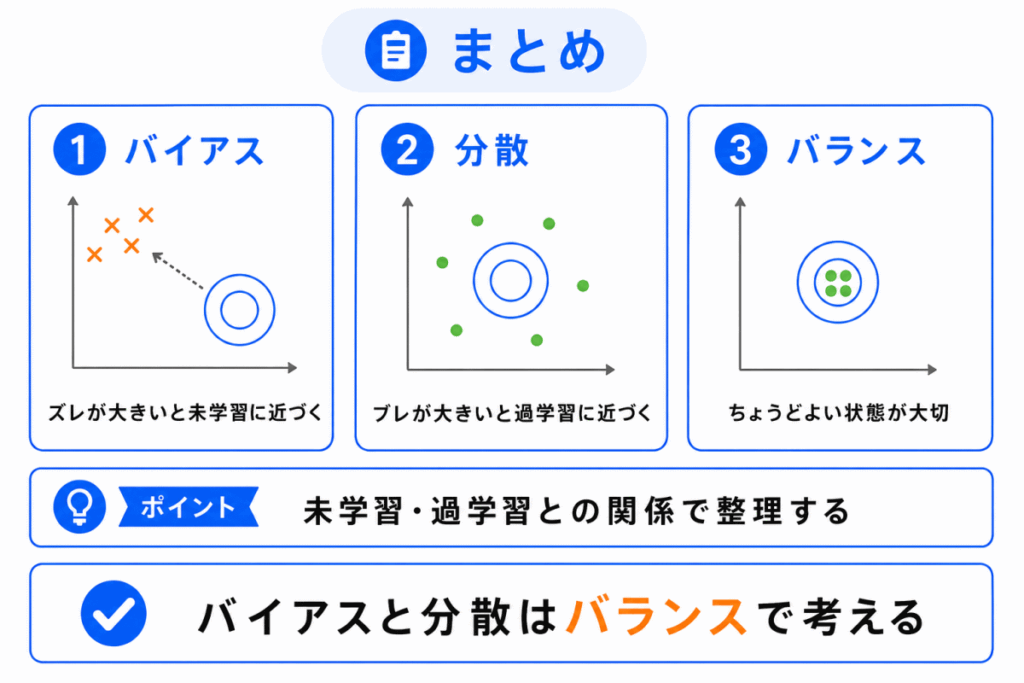
バイアスと分散は、モデルの間違い方を整理するための考え方です。
バイアスは正解からのズレ、分散はデータによるブレを表します。
| 用語 | 一言でいうと | 関係する状態 |
|---|---|---|
| バイアス | ズレ | 未学習 |
| 分散 | ブレ | 過学習 |
| 未学習 | 十分に学習できていない | 高バイアス |
| 過学習 | 学習データに合わせすぎている | 高分散 |
| 汎化 | 未知のデータにも対応できる | バランスが重要 |
モデルが単純すぎるとバイアスが大きくなり、未学習になりやすくなります。
反対に、モデルが複雑すぎると分散が大きくなり、過学習になりやすくなります。
G検定では、バイアスと分散を単独の用語として覚えるよりも、未学習・過学習・正則化・ドロップアウトとの関係 で整理しておくことが大切です。
分散が大きい状態は過学習と関係するため、過学習の記事もあわせて確認しておくと整理しやすくなります。
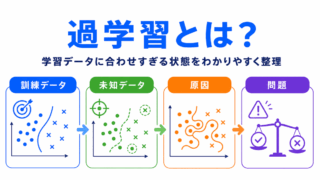
バイアスと分散を考えるうえでは、モデルの評価方法として交差検証も関係します。
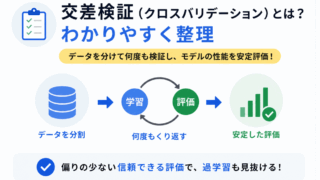
モデルの良し悪しを判断するには、バイアスと分散だけでなく評価指標の見方も重要です。

重要用語をチェックシートとしてまとめました。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認