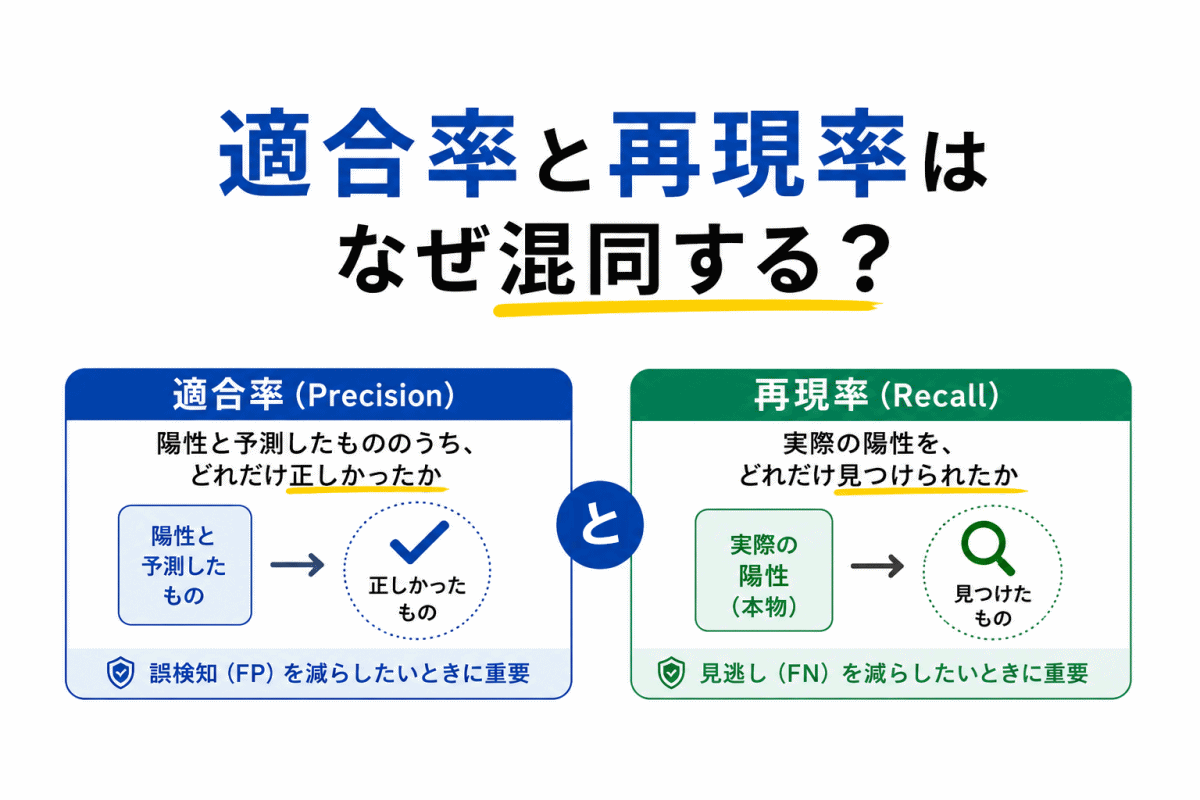
【G検定|理解型予想問題】適合率と再現率はなぜ混同する?
seo-webmaster
G検定対策ブログ
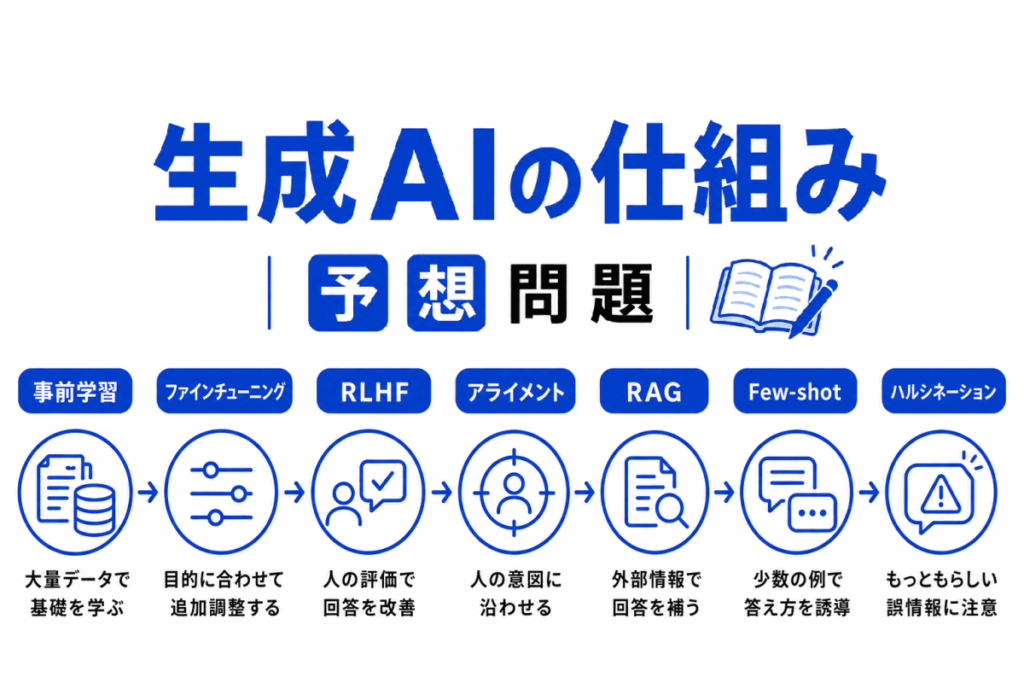
生成AIの仕組みを学ぶとき、事前学習、ファインチューニング、RLHF、RAG、アライメントなど、似たように見える用語が一気に登場します。
どれも「AIをよくするための仕組み」に見えるため、名前だけで覚えると混同しやすくなります。
この記事では、生成AIがまず大量データで基礎力を身につけ、その後に目的に合わせて調整され、人間の意図に近づけられ、必要に応じて外部情報で補われる流れを、理解型予想問題で整理します。
単語を暗記するのではなく「どの段階の話か」、「何を改善する話か」で見分けられるようにしていきます。
事前学習の説明として最も適切なものはどれか?
B
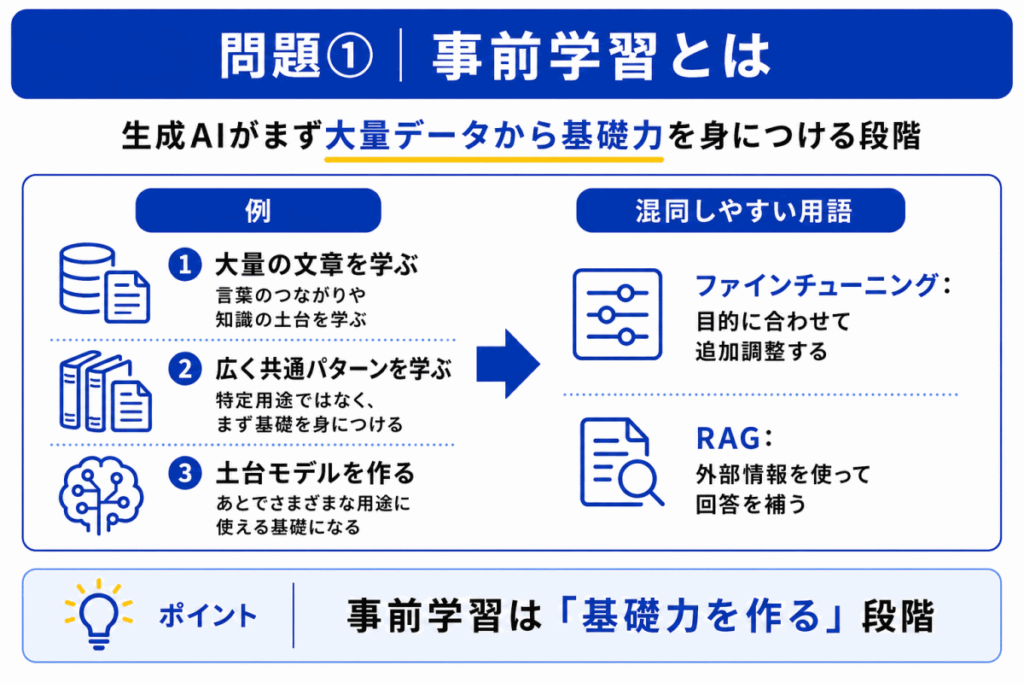
事前学習とは、AIが大量の文章データなどから、言葉のつながりや文脈、表現のパターンを学ぶ段階です。
ここで重要なのは、事前学習は特定の仕事だけを覚える段階ではないということです。
たとえば、文章生成、要約、翻訳、質問応答などに使える土台を作るために、まず広い知識や言語パターンを学びます。
| 用語 | 中心となる役割 |
|---|---|
| 事前学習 | 基礎力を作る |
| ファインチューニング | 目的に合わせる |
| RAG | 外部情報で補う |
事前学習もファインチューニングも、どちらも「学習」です。
そのため、名前だけで覚えると混同しやすくなります。
見分けるポイントは、広く基礎力を作るのが事前学習、特定用途に寄せるのがファインチューニングです。
ファインチューニングの説明として最も適切なものはどれか?
A
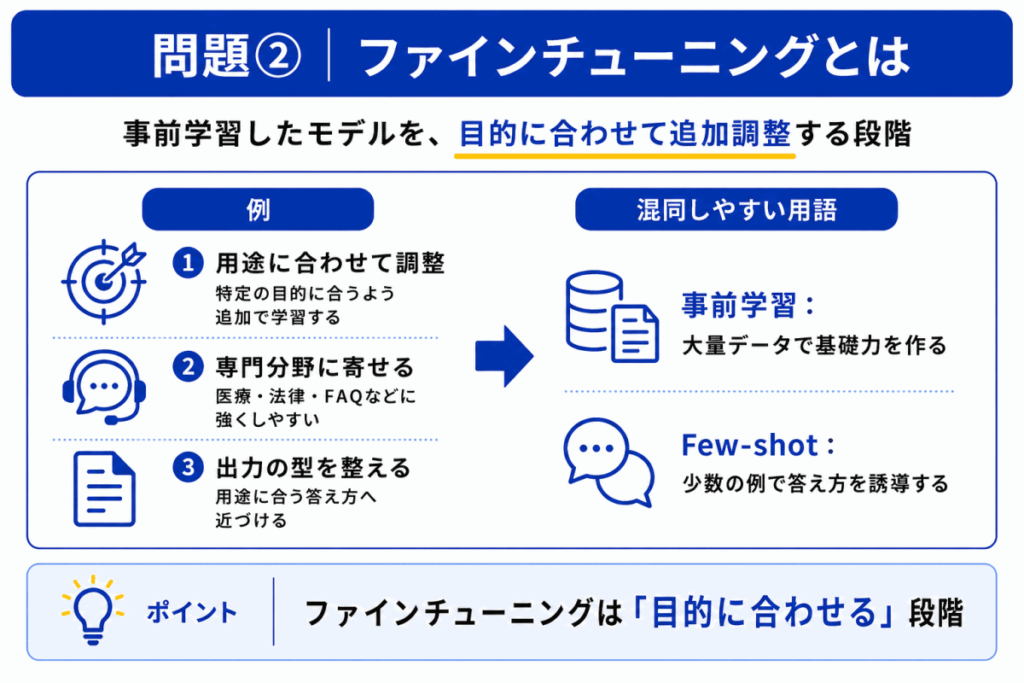
ファインチューニングとは、すでに事前学習されたモデルを、特定の目的やタスクに合わせて追加で調整することです。
事前学習で作られたモデルは、広く使える基礎力を持っています。
そこに対して、医療、法律、カスタマーサポート、社内文書対応など、目的に合わせたデータでさらに学習させることで、用途に合った出力をしやすくします。
| 段階 | イメージ |
|---|---|
| 事前学習 | 広く基礎力を身につける |
| ファインチューニング | 目的に合わせて専門化する |
事前学習もファインチューニングも、モデルの中身を変える「学習」です。
ただし、役割は違います。
事前学習は土台作り、ファインチューニングは目的別の調整 です。
RLHFの説明として最も適切なものはどれか?
B
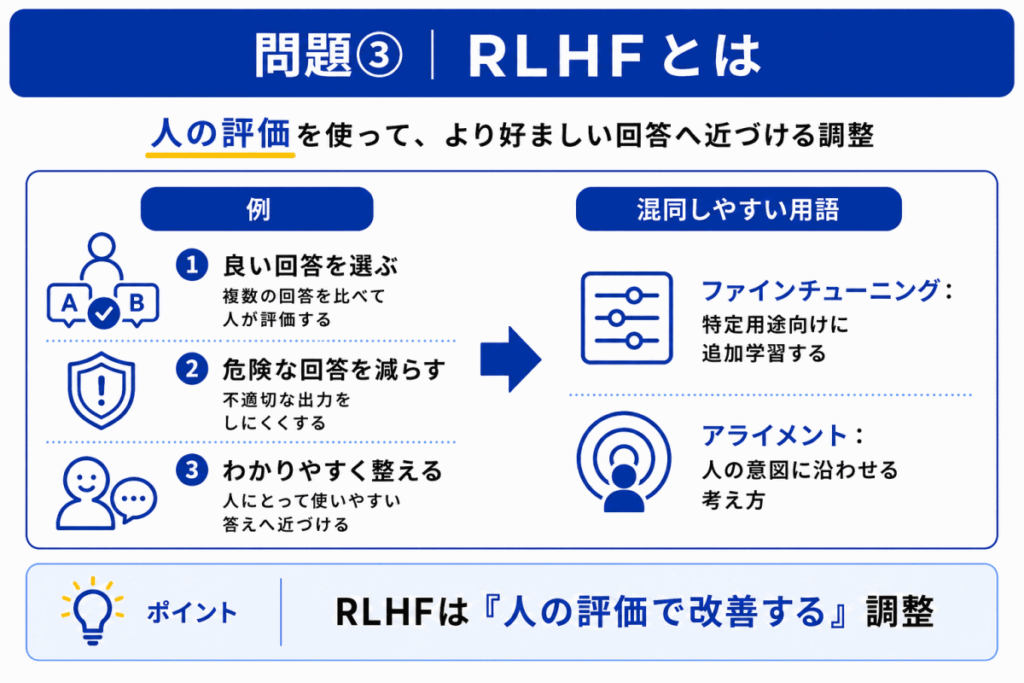
RLHFは、Reinforcement Learning from Human Feedbackの略で、人間のフィードバックを使ってAIの回答を調整する考え方です。
生成AIは、ただ文章を作れるだけでは十分ではありません。
ユーザーにとってわかりやすい回答、危険性の低い回答、意図に合った回答を出せるように、人間の評価を使って調整します。
| 用語 | 役割 |
|---|---|
| RLHF | 人間の評価で回答を調整する |
| アライメント | 人間の意図に沿うように整える |
| RAG | 外部情報を使って回答を補う |
RLHFとアライメントはかなり混同しやすいです。
理由は、どちらも人間にとって望ましいAIに近づける話だからです。
ただし、整理すると
です。
アライメントの説明として最も適切なものはどれか?
A
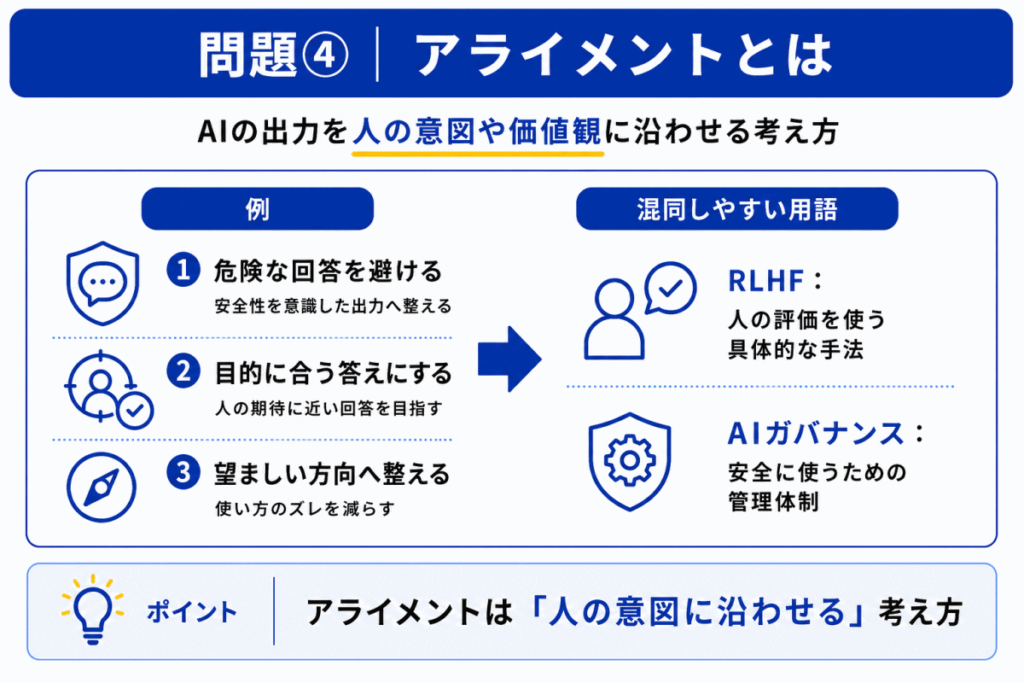
アライメントとは、AIの出力や行動を、人間の意図や価値観、社会的に望ましい方向に沿わせる考え方です。
生成AIは、文章を作る能力が高くても、そのままでは必ずしも人間の意図に合った回答をするとは限りません。
そのため、危険な出力を避ける、ユーザーの目的に合う回答をする、誤解を招きにくくするなどの調整が重要になります。
| 用語 | 整理 |
|---|---|
| RLHF | 人間の評価を使う方法 |
| アライメント | 人間の意図に沿わせる考え方 |
| AIガバナンス | 安全に使うための管理体制 |
アライメントは、RLHFやAIガバナンスと混同されやすいです。
特にRLHFとは近い関係にあります。
ただし、アライメントは目的、RLHFはその目的に近づけるための方法の一つと整理すると見分けやすくなります。
RAGの説明として最も適切なものはどれか?
B
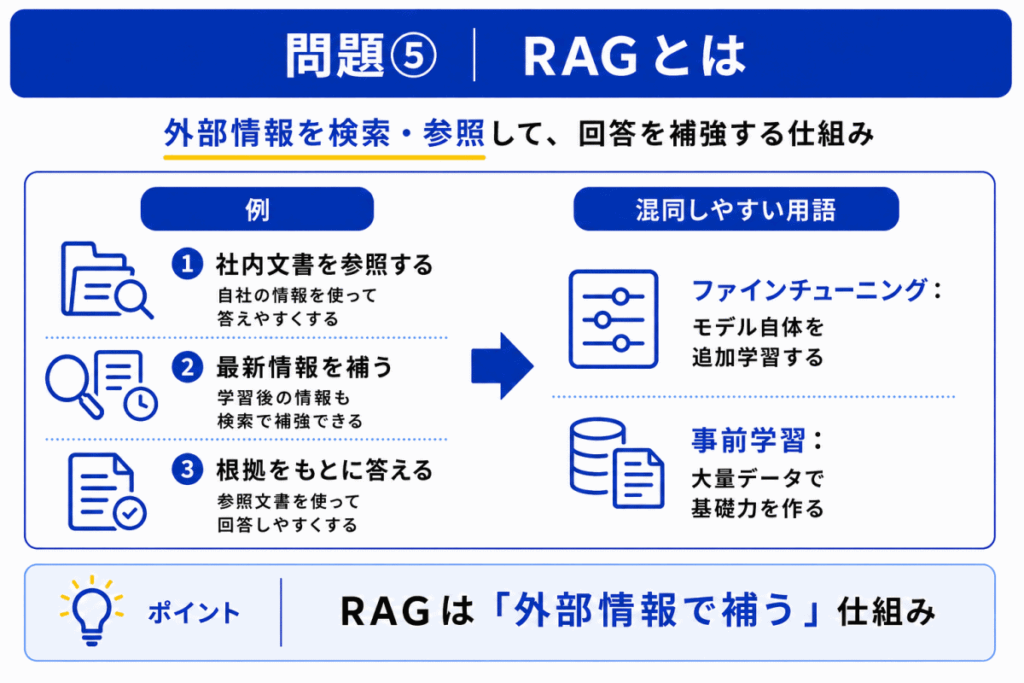
RAGは、Retrieval-Augmented Generationの略で、外部情報を検索・参照して生成AIの回答を補う仕組みです。
生成AIは、事前学習した知識だけで回答すると、情報が古かったり、事実と違う内容を出したりすることがあります。
そこで、社内文書、FAQ、データベース、検索結果などを参照しながら回答することで、回答の根拠を補強します。
| 用語 | 何をするか |
|---|---|
| ファインチューニング | モデル自体を追加学習で調整する |
| RAG | 外部情報を参照して回答を補う |
| ハルシネーション | もっともらしい誤情報を出す |
RAGとファインチューニングは、どちらも「AIを特定用途で使いやすくする方法」に見えます。
ただし違いは明確です。
この違いを押さえると混同しにくくなります。
ハルシネーションとRAGの関係として最も適切なものはどれか?
B
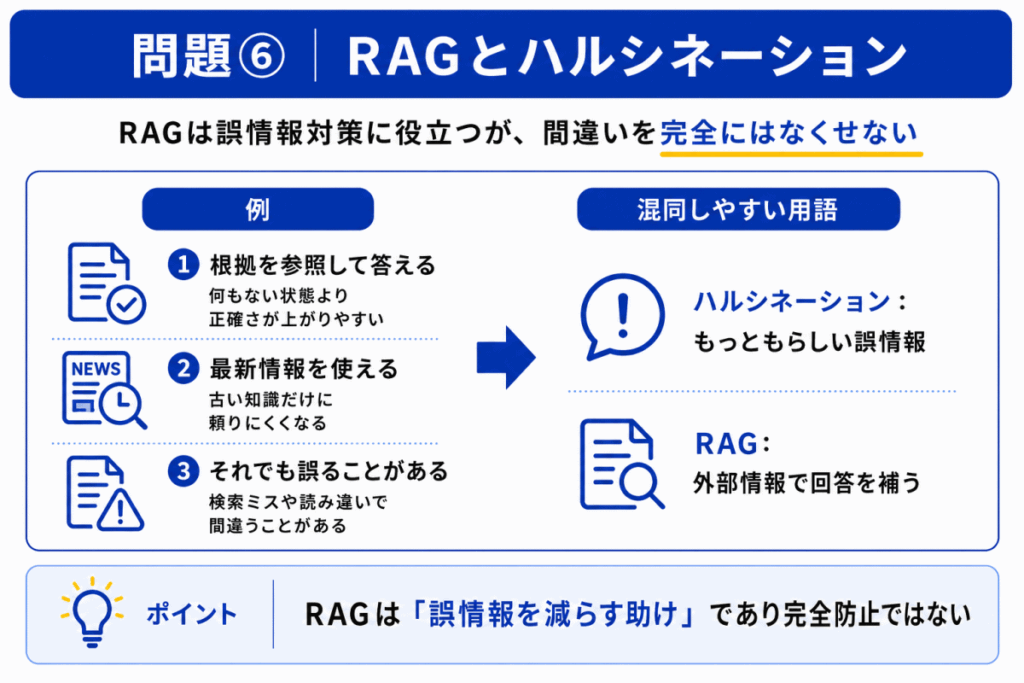
ハルシネーションとは、生成AIがもっともらしく見える誤情報を出す現象です。
RAGは、外部情報を参照して回答を作るため、ハルシネーションを減らす対策として役立つ場合があります。
ただし、RAGを使えば必ず正しくなるわけではありません。
参照する情報が古い、検索結果が不適切、AIが参照情報を読み違える、といった問題があれば、誤った回答になる可能性はあります。
| 用語 | 関係 |
|---|---|
| ハルシネーション | もっともらしい誤情報 |
| RAG | 外部情報で回答を補う |
| 注意点 | 完全な防止策ではない |
RAGはハルシネーション対策として紹介されることが多いため、 RAG = 誤情報を完全になくす仕組み と誤解しやすくなります。
正しくは、RAGはハルシネーションを減らす助けになるが、完全に防ぐものではないです。
Zero-shot・One-shot・Few-shotの説明として最も適切なものはどれか?
A

Zero-shot、One-shot、Few-shotは、AIに与える例の数によって整理される考え方です。
| 用語 | 例の数 |
|---|---|
| Zero-shot | 例なし |
| One-shot | 例を1つ |
| Few-shot | 少数の例 |
これは、モデルを追加学習するというより、プロンプト内でどれだけ例を示すかに関係します。
たとえば、Few-shotでは、いくつかの回答例を示してから質問することで、AIが出力形式や意図をつかみやすくなります。
Zero-shot・One-shot・Few-shotは、ファインチューニングと混同されやすいです。
どちらも「AIを目的に合わせる」ように見えるからです。
ただし、整理すると
という違いがあります。
生成AIの仕組みの組み合わせとして正しいものはどれか?
B
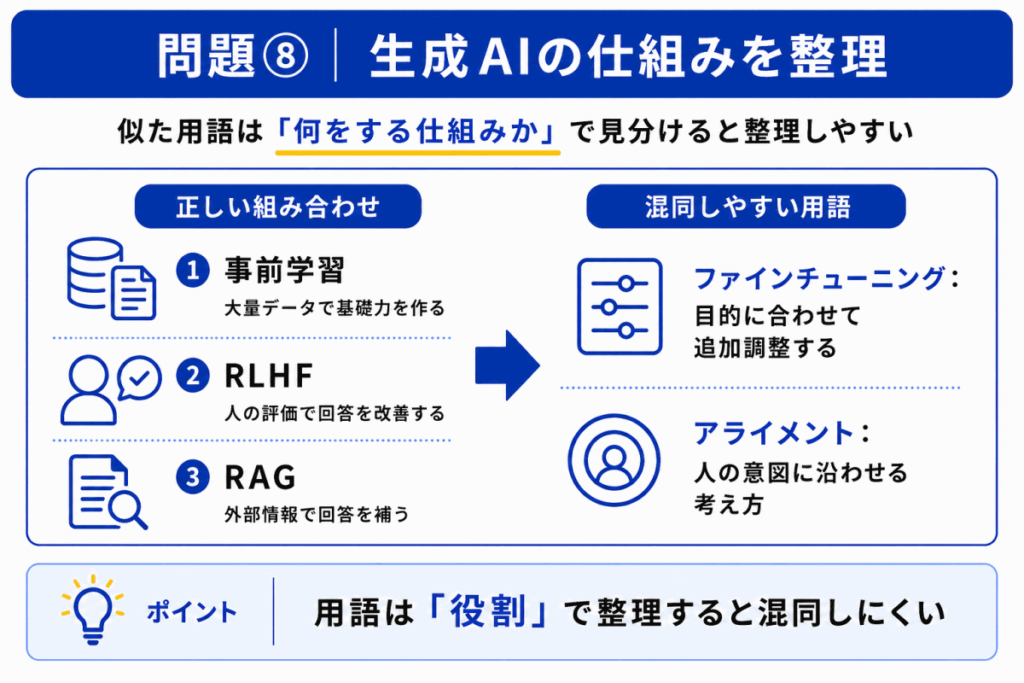
正しい組み合わせは、RLHF:人間の評価を使って回答を調整するです。
他の選択肢は、用語と役割が入れ替わっています。
| 選択肢 | なぜ違う? |
|---|---|
| A | 外部情報を検索して補うのはRAG |
| C | 大量データで基礎力を作るのは事前学習 |
| D | 判断理由を説明しやすくするのはXAIに近い |
生成AIの仕組みは、似た用語が多いため、何を改善する話なのかで整理することが大切です。
生成AIの仕組みを一覧で整理したのが下の表です。
| 用語 | 何の話か | 見分けるポイント |
|---|---|---|
| 事前学習 | 基礎力作り | 大量データから広く学ぶ |
| ファインチューニング | 目的別調整 | 特定用途に合わせて追加学習する |
| RLHF | 人間評価による調整 | 人間が好ましい回答を評価する |
| アライメント | 人間の意図に沿わせる | 目指す方向性の話 |
| RAG | 外部情報による補強 | 検索・文書参照で回答を補う |
| Zero-shot | 例なしで対応 | 追加学習ではなく指示で対応する |
| One-shot | 例を1つ示す | 1つの例で答え方を示す |
| Few-shot | 少数の例を示す | 複数例で出力を誘導する |
| ハルシネーション | 生成AIの失敗 | もっともらしい誤情報を出す |
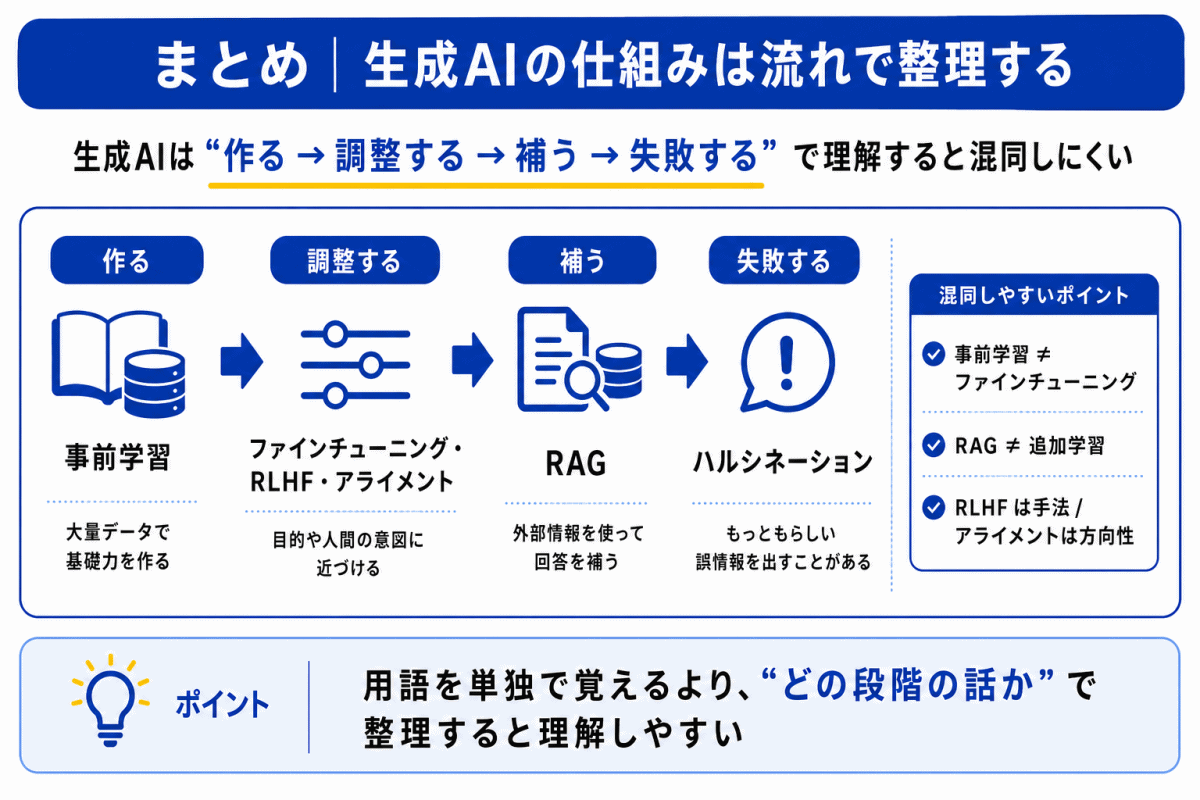
生成AIの仕組みは、用語を1つずつ暗記しようとすると混同しやすくなります。
特に、事前学習、ファインチューニング、RLHF、RAG、アライメントは、どれも「AIをよくする仕組み」に見えるため、名前だけで覚えると選択肢で迷いやすくなります。
大切なのは、次のように役割で整理することです。
生成AIは、いきなり正確で安全な回答ができるわけではありません。
まず大量データで基礎力を作り、目的に合わせて調整し、人間の評価を使って望ましい回答に近づけ、必要に応じて外部情報で補います。
それでも誤情報を出すことがあるため、ハルシネーションへの注意が必要です。
つまり、生成AIの理解では「どう作られるか」だけでなく、「どう調整されるか」、「どう補われるか」、「どこで失敗するか」まで流れで見ること が大切です。
G検定の重要な用語をまとめています。