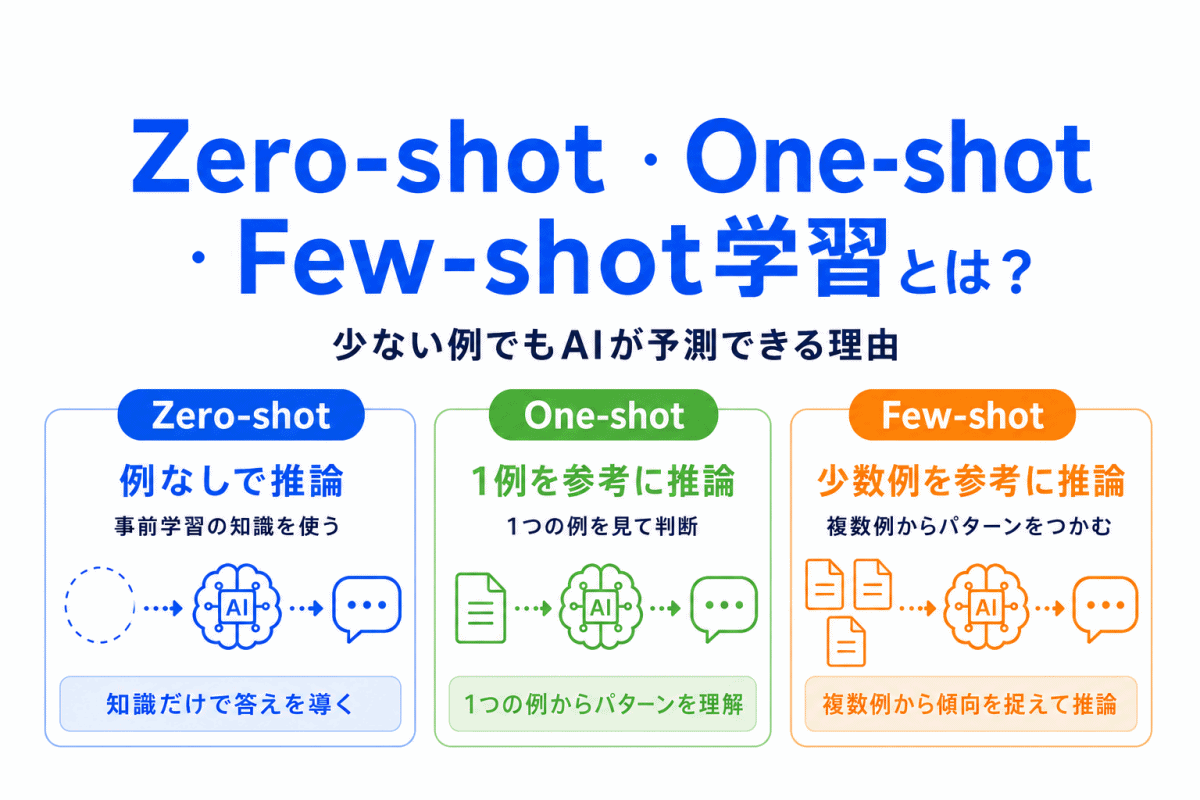
【G検定対策】Zero-shot・One-shot・Few-shot学習とは?|少ない例でもAIが予測できる理由をわかりやすく整理
seo-webmaster
SEO・ウェブマスターブログ
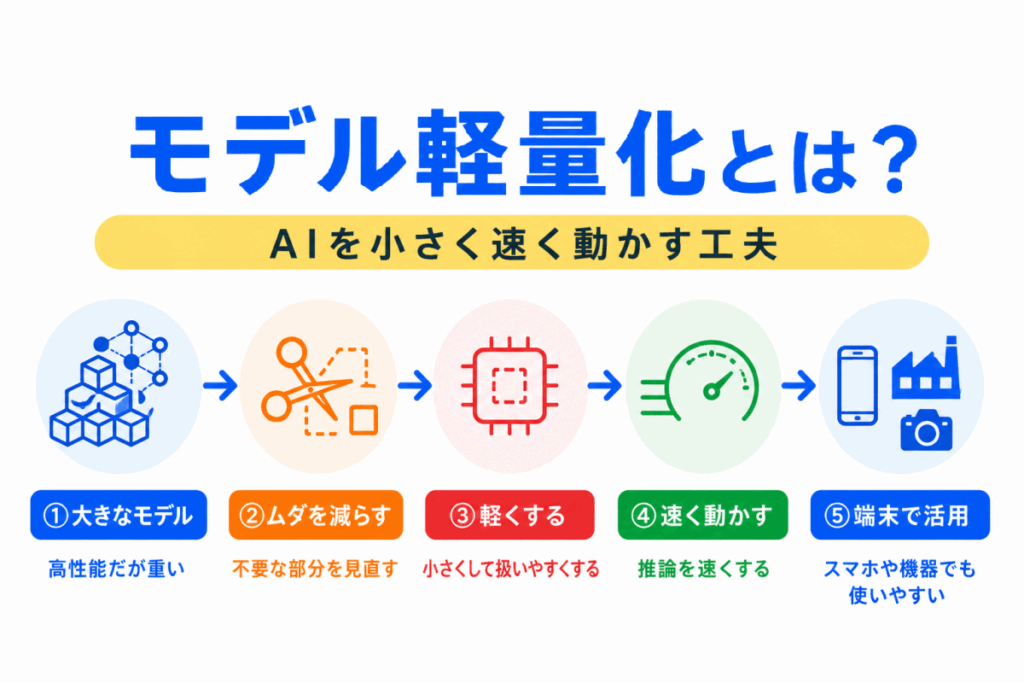
AIモデルは、性能を高めようとすると大きく複雑になりやすいです。
しかし、実際にAIを使う場面では、必ずしも大きなモデルをそのまま使えるとは限りません。
スマホ、カメラ、工場の機械、自動車などでAIを動かす場合、計算能力・メモリ・電力・通信環境に制約があります。
そこで重要になるのが、モデル軽量化 です。
この記事では、モデル軽量化とは何か、なぜ必要なのか、エッジAIとの関係、蒸留・量子化・枝刈りの違いを、G検定対策としてわかりやすく整理します。
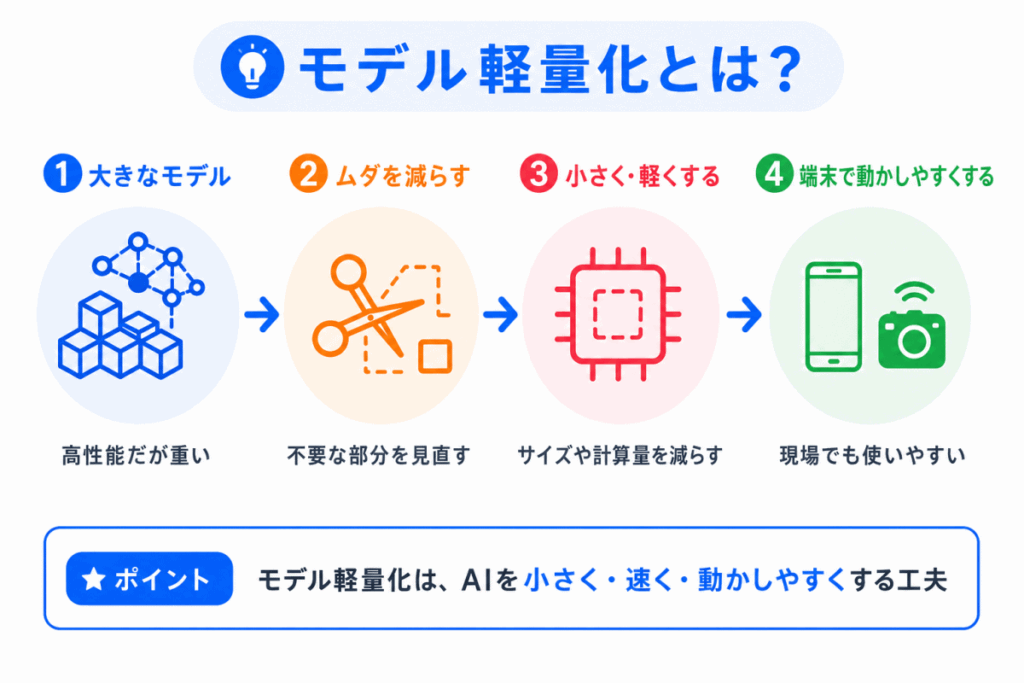
モデル軽量化とは、AIモデルの性能をできるだけ保ちながら、モデルを小さく・速く・動かしやすくする工夫 です。
AIモデルは、たくさんの重みや計算を使って予測します。
モデルが大きくなるほど、複雑な判断ができる一方で、計算に時間がかかったり、メモリを多く使ったりします。
そのため、実際のサービスや端末で使うには、モデルを扱いやすい形にする必要があります。
つまり、モデル軽量化は、AIを「作る」だけでなく、実際に使える形に近づけるための工夫 です。
ポイントは、単に小さくすればよいわけではないことです。
小さくしすぎると、予測性能が下がることがあります。
そのため、モデル軽量化では、性能と軽さのバランス が重要になります。
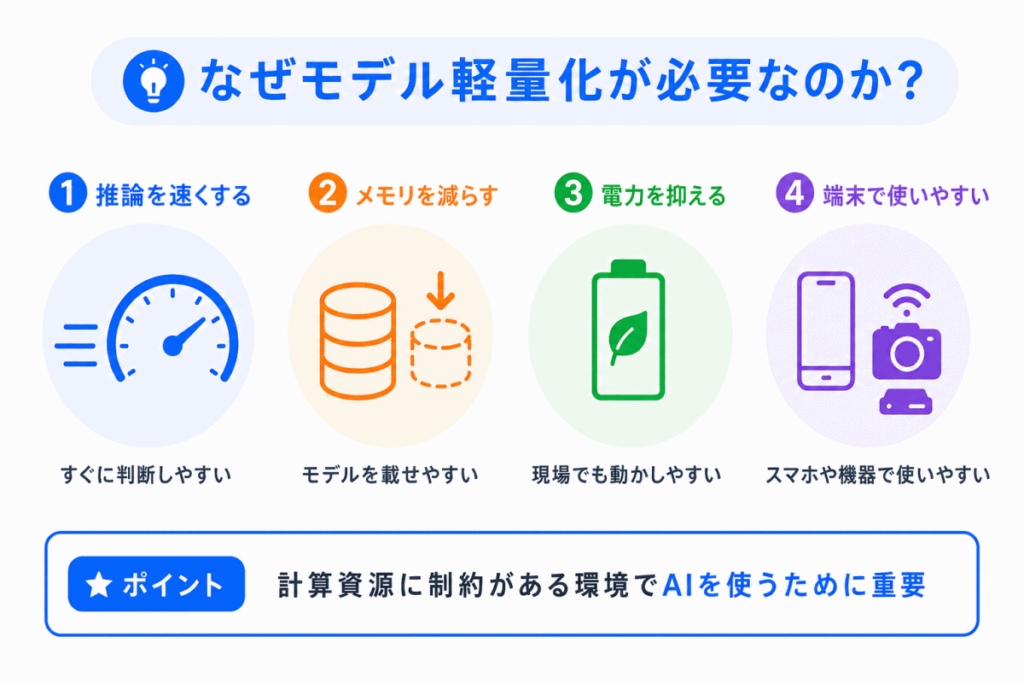
モデル軽量化が必要になる理由は、AIを実際に使う場面では制約があるからです。
クラウド上の大きなサーバーであれば、大きなモデルを動かしやすいです。
しかし、スマホやカメラ、工場の機械などの端末側では、使える計算資源が限られます。
そのため、大きなモデルをそのまま動かすと、処理が遅くなったり、電力を多く使ったり、端末に載せられなかったりします。
モデル軽量化は、特にリアルタイム性が必要な場面で重要です。
たとえば、カメラで異常を検知する場合、判断に時間がかかると意味がありません。
その場ですぐに判断するためには、軽くて速いモデルが必要になります。
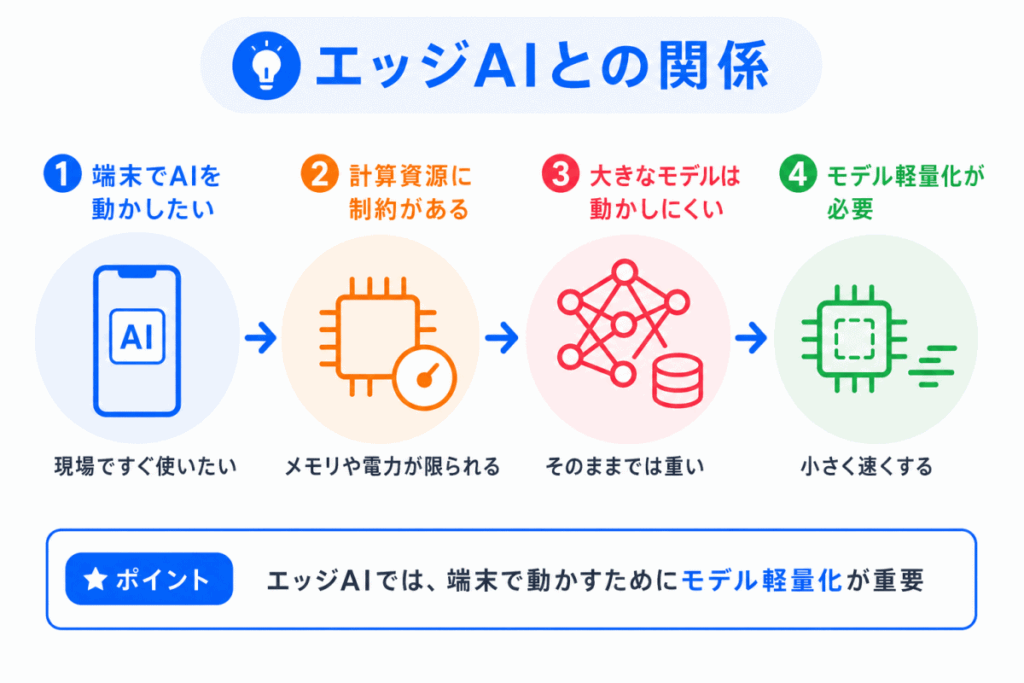
エッジAIでは、クラウドではなく端末側でAIを動かします。
端末側は計算資源や電力に制約があるため、大きなモデルをそのまま使いにくいです。
そのため、モデル軽量化が重要になります。
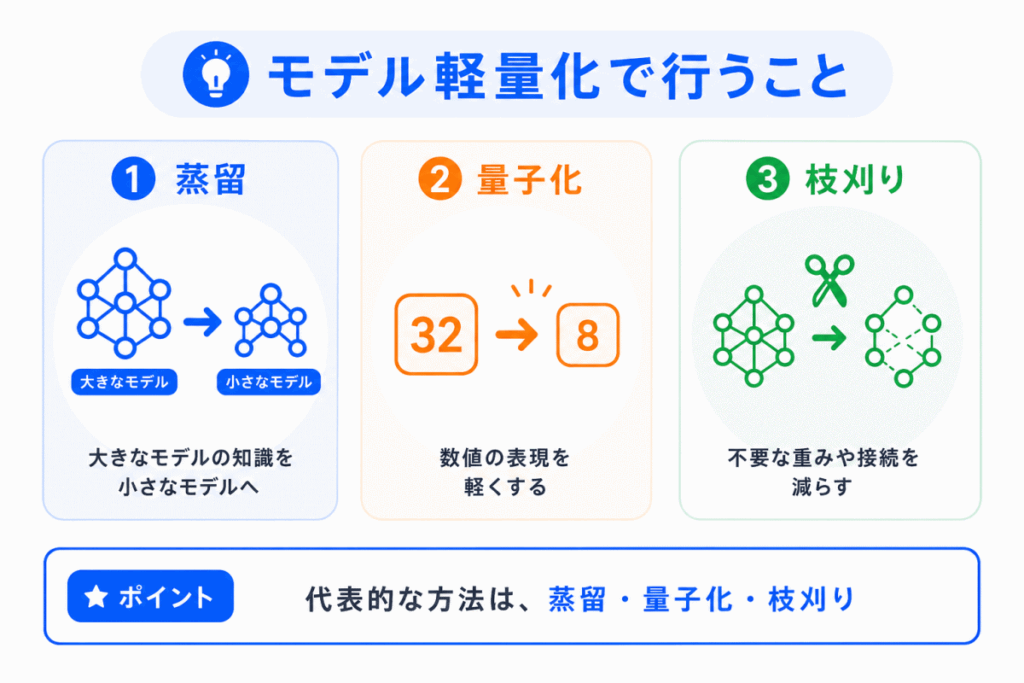
モデル軽量化では、主にモデルのサイズや計算量を減らします。
ただし、やみくもに削るのではなく、予測性能をできるだけ保ちながら軽くすることが大切です。
代表的な方法には、蒸留、量子化、枝刈り があります。
G検定では、細かい実装方法よりも、まずはそれぞれの考え方を押さえることが重要です。
特に、蒸留・量子化・枝刈りは名前だけで覚えると混同しやすいです。
「何を軽くしているのか」で整理すると理解しやすくなります。
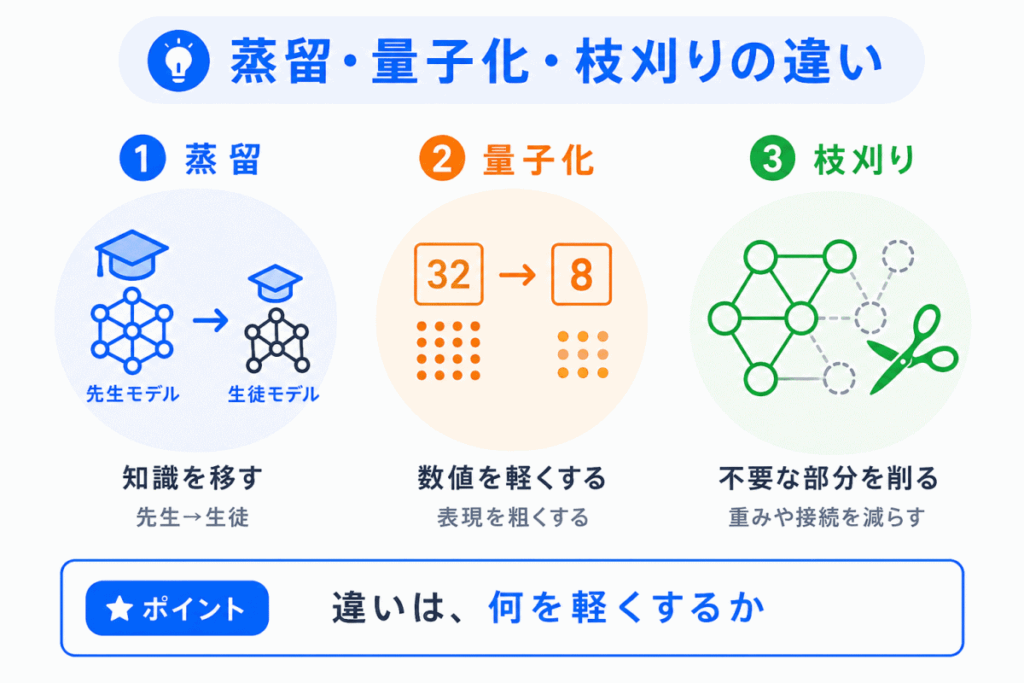
モデル軽量化で混同しやすいのが、蒸留・量子化・枝刈りです。
それぞれの違いは、軽くする方法にあります。
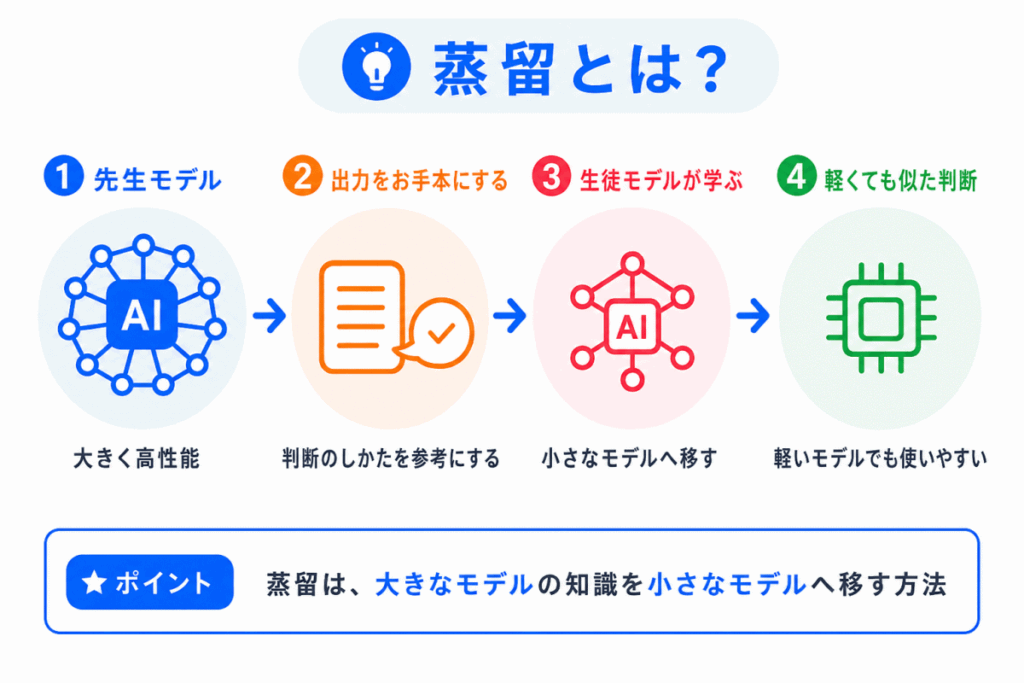
蒸留とは、大きなモデルの知識を、小さなモデルに学ばせる方法です。
大きく高性能なモデルを「先生モデル」、小さなモデルを「生徒モデル」と考えると理解しやすいです。
先生モデルの出力を参考にして、生徒モデルが似たような判断をできるように学習します。
蒸留は、性能の高いモデルの考え方を、小さなモデルに引き継がせるイメージです。
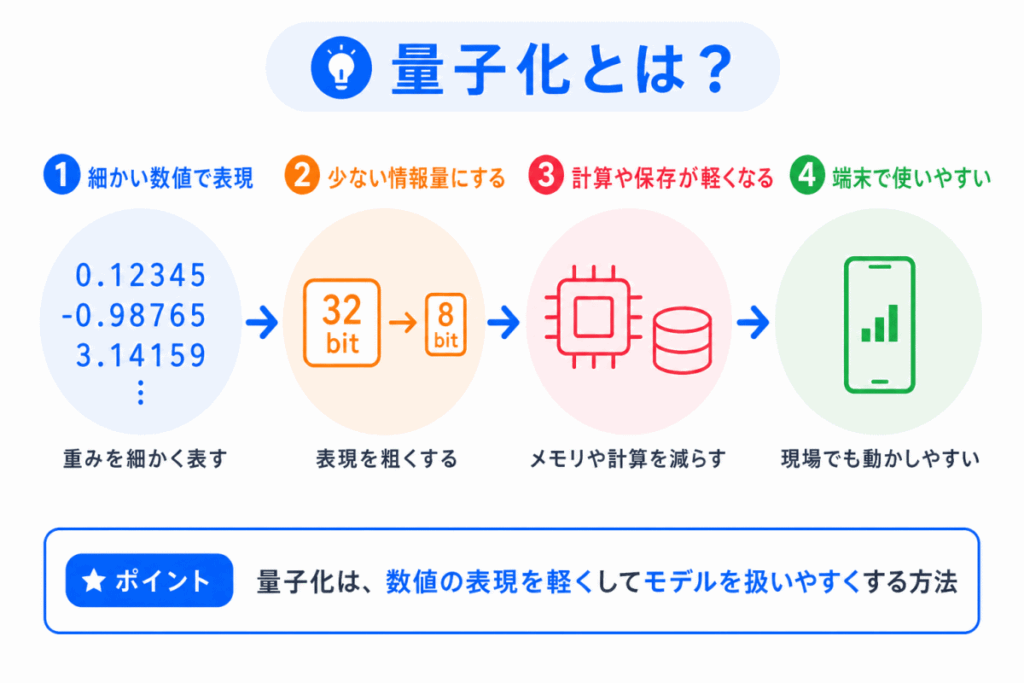
量子化とは、モデル内で使う数値の表現を粗くして、計算や保存を軽くする方法です。
AIモデルでは、多くの重みが数値として保存されています。
この数値を細かく表現すると精度は高くなりますが、メモリや計算量が増えます。
そこで、数値の表現を少し粗くすることで、モデルを軽くします。
たとえば、細かい小数で表していた数値を、より少ない情報量で表すイメージです。
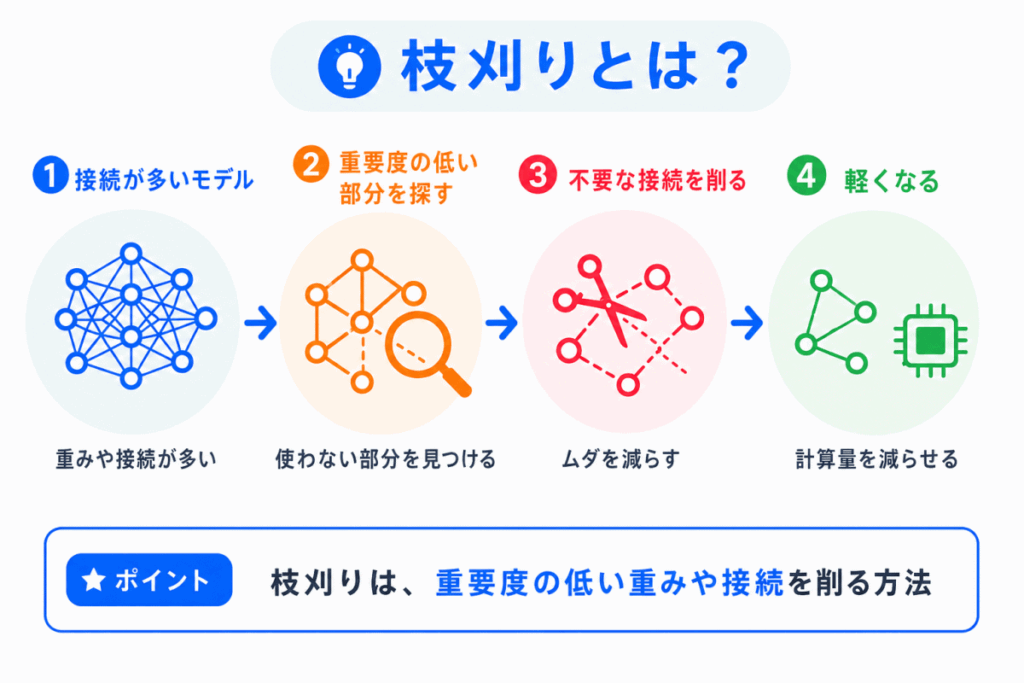
枝刈りとは、モデルの中で重要度の低い重みやつながりを削る方法です。
ニューラルネットワークには、多くの重みや接続があります。
その中には、予測にあまり影響しない部分もあります。
そのような部分を削ることで、モデルを小さくしたり、計算を減らしたりします。
名前の通り、木の不要な枝を切るようなイメージです。
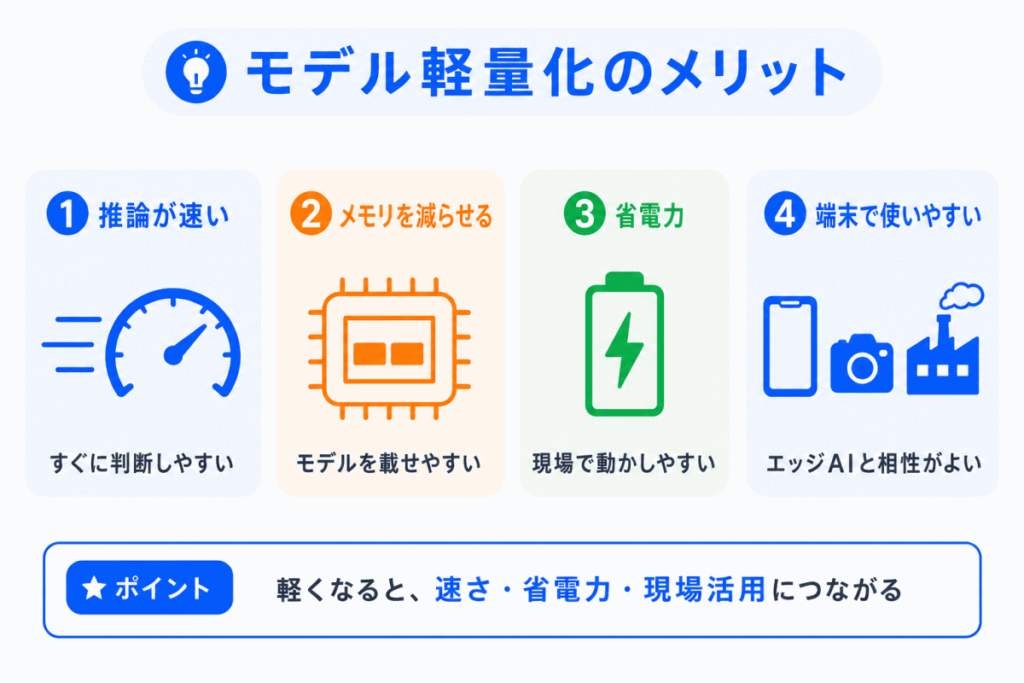
モデル軽量化のメリットは、AIを実際の環境で使いやすくできることです。
特に、エッジAIやリアルタイム処理では大きな意味があります。
モデルが軽くなると、クラウドに送らず端末側で判断しやすくなります。
そのため、低遅延、通信量削減、プライバシー保護にもつながります。

モデル軽量化にはメリットがありますが、注意点もあります。
一番大きいのは、軽くしすぎると性能が下がる可能性があることです。
モデルを小さくする、数値を粗くする、不要な部分を削るという処理は、うまく行えば効率化になります。
しかし、必要な情報まで削ってしまうと、予測の精度が落ちることがあります。
モデル軽量化は、単にモデルを小さくする作業ではありません。
実際の利用場面に合わせて、速度・精度・メモリ・電力のバランスを取ることが重要です。
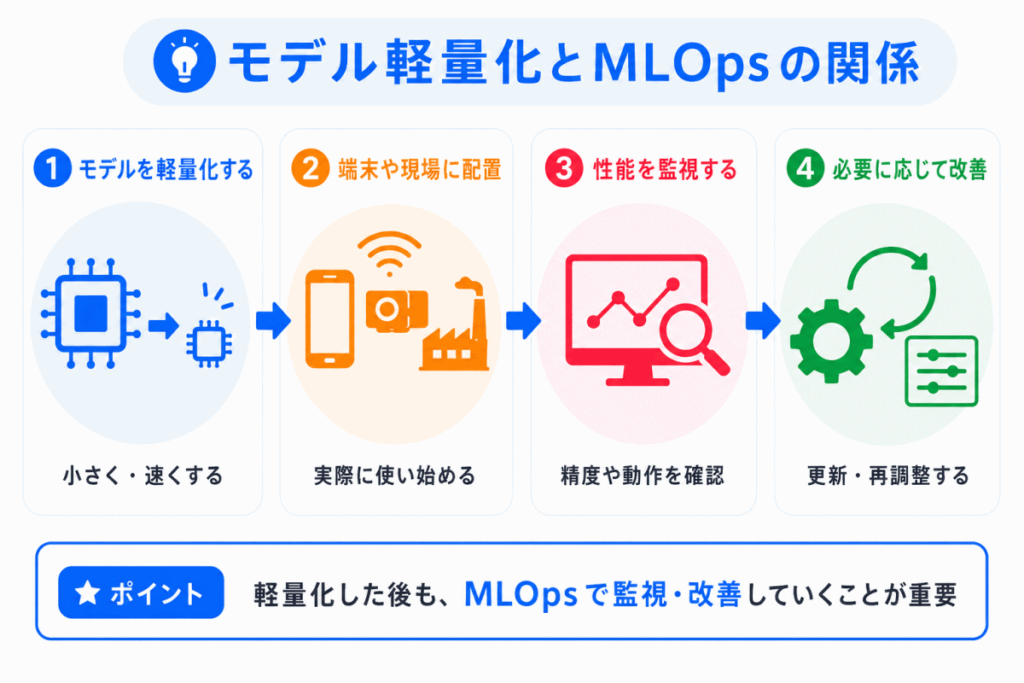
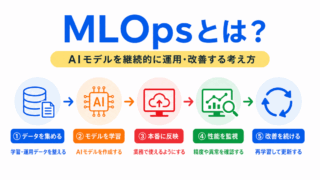
モデル軽量化は、軽くして終わりではありません。
現場に配置した後も、精度や動作を確認し、必要に応じて更新・再調整する必要があります。
この運用・改善の考え方がMLOpsです。
G検定では、モデル軽量化を「エッジAIで使いやすくするために、モデルを小さく・速くする工夫」と整理しておくと理解しやすいです。
モデル軽量化は、エッジAIとの関係で次のように整理すると覚えやすくなります。
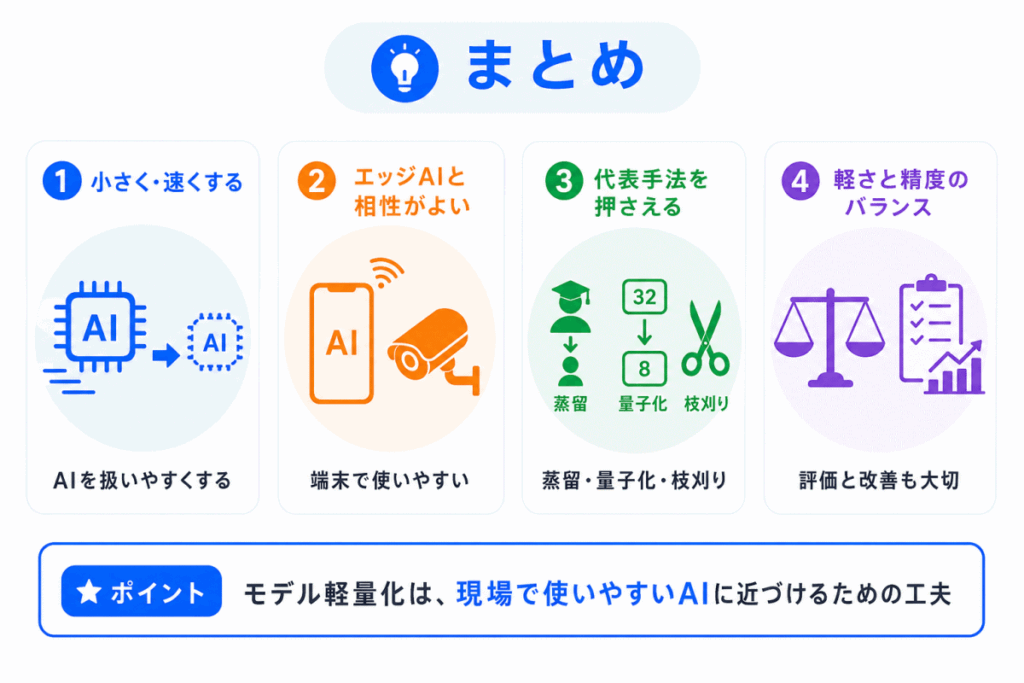
モデル軽量化とは、AIモデルの性能をできるだけ保ちながら、モデルを小さく・速く・動かしやすくする工夫です。
特に、スマホやカメラ、工場の機器など、端末側でAIを動かすエッジAIと深く関係します。
代表的な方法には、蒸留、量子化、枝刈りがあります。
蒸留は、大きなモデルの知識を小さなモデルに移す方法です。
量子化は、数値の表現を粗くして軽くする方法です。
枝刈りは、重要度の低い重みや接続を削る方法です。G検定対策では、モデル軽量化を単独で暗記するよりも、エッジAIやMLOpsとつなげて理解するのがおすすめです。
AIを作るだけでなく、現場で使い続けるために、モデル軽量化が必要になると整理しておきましょう。
エッジAIを先に理解しておくと、なぜモデル軽量化が必要になるのかが見えやすくなります。
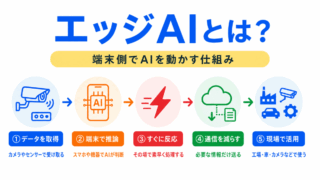
AIモデルを現場で使い続ける流れを理解するには、MLOpsもあわせて押さえておくとつながります。
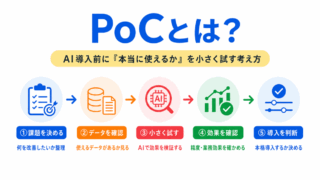
AI導入前に小さく試す考え方を理解しておくと、社会実装の流れが整理しやすくなります。
モデル軽量化は、ディープラーニングの要素技術とも関係するため、全体像を確認しておくと理解しやすくなります。

AIを実際に使うための用語をまとめて確認したい場合は、社会実装分野の重要用語も役立ちます。
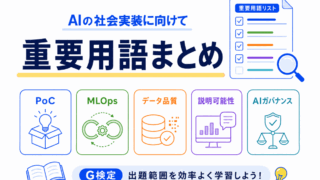
モデルを軽くする目的は、AIを現場で使いやすくすることなので、社会実装分野全体の整理にもつながります。

用語の意味をまとめて確認したい場合は、G検定で覚えたいAI用語一覧もあわせて読んでみてください。

1回目不合格でした。不合格だった原因を分析しました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認