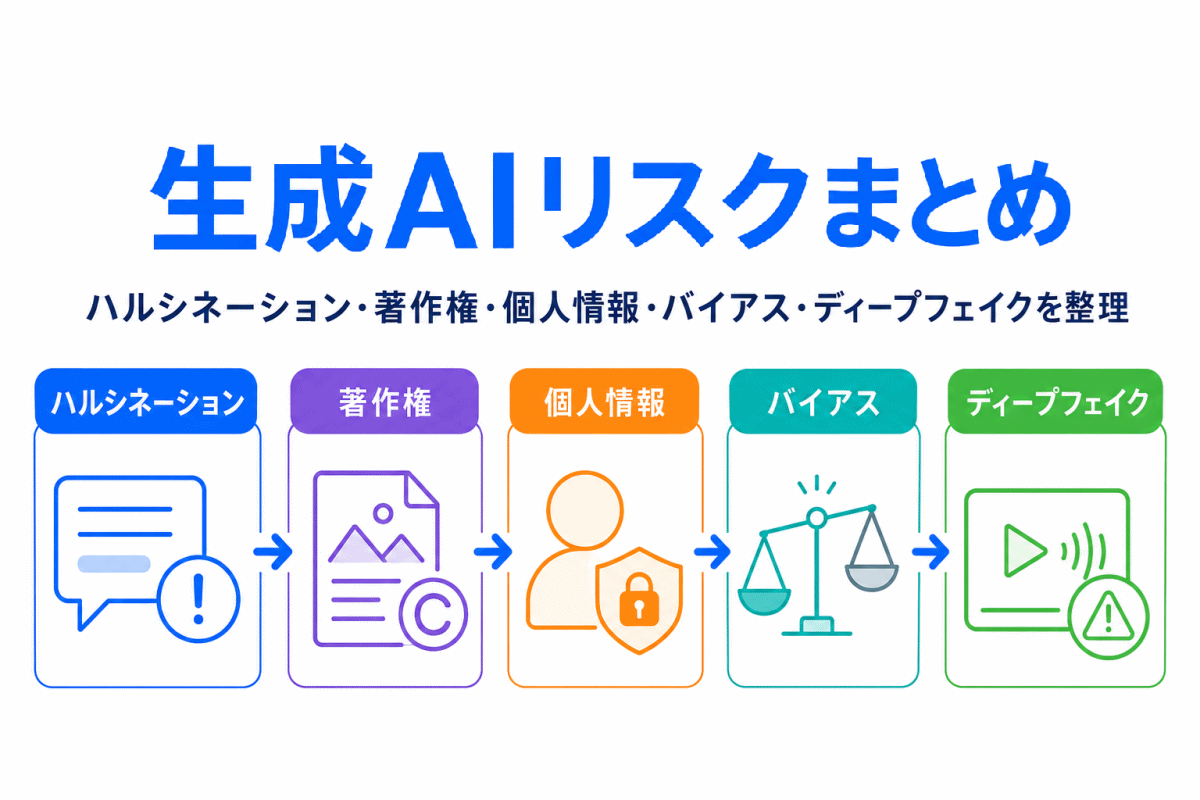
【G検定対策】生成AIリスクまとめ|ハルシネーション・著作権・個人情報・バイアス・ディープフェイクを整理
seo-webmaster
G検定対策ブログ
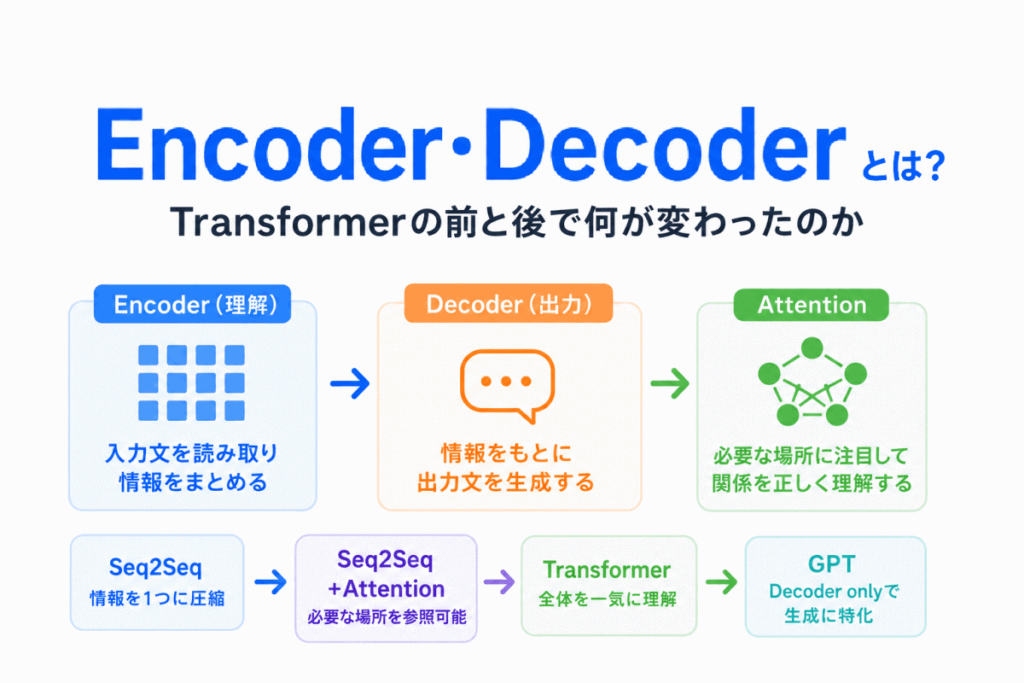
AIの文章生成や翻訳の仕組みを学んでいると、「Encoder(エンコーダ)」や「Decoder(デコーダ)」という言葉が出てきます。
しかし、単に「入力側」、「出力側」と覚えるだけでは、本当の意味は見えてきません。
重要なのは、なぜこの仕組みが必要だったのか、そしてその後のAttention・Transformer・GPTへどうつながったのかです。
Encoder・Decoderは、AIの文章処理の進化の中で非常に重要な橋渡しの技術です。
この記事では、Seq2Seq時代の課題から出発し、AttentionやTransformerによって何が変わったのかまで、流れでわかりやすく整理します。
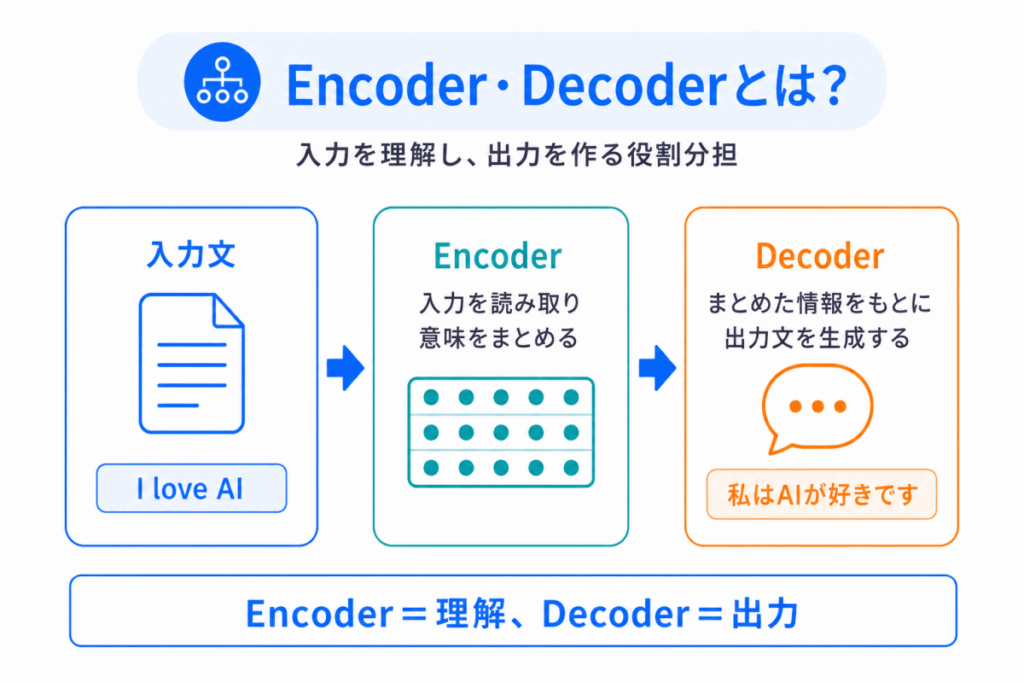
まず一言でいうと
Encoder = 入力を理解して情報に変換する仕組み
Decoder = その情報を使って出力を作る仕組み
です。
たとえば翻訳AIなら
入力
I love AI
Encoderが文章を読み取り
「これはこういう意味の文章だ」
という情報に変換します。
その後、Decoderがその情報をもとに
私はAIが好きです
という文章を生成します。
つまり
理解する役割 = Encoder
出力する役割 = Decoder
という分担です。
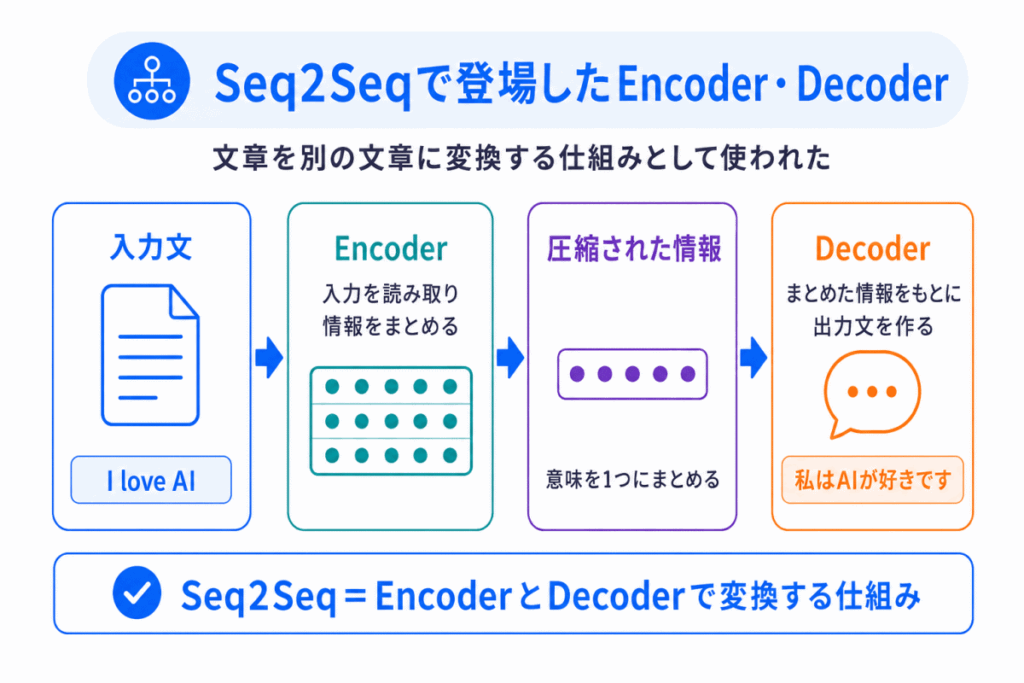
Encoder・Decoderが有名になったのは、Seq2Seq(Sequence to Sequence) という仕組みです。これは、「入力された文章を、別の文章に変換する」ために作られました。
例
このように
に変換する技術です。
入力文を最後まで読んで、情報をまとめる
まとめられた情報をもとに、1単語ずつ出力する
という流れです。
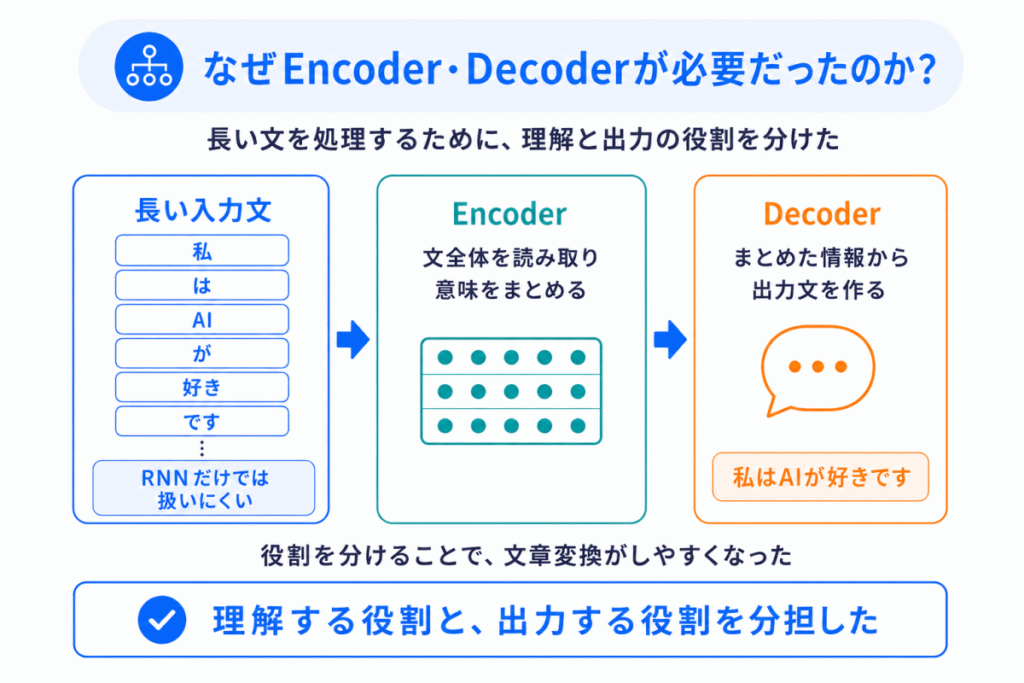
RNNだけでも文章は扱えました。
しかし、問題がありました。
RNNは
文章を読んだ結果をそのまま次に渡していく
仕組みです。
すると、長い文章になると、最初の情報が薄れてしまう という問題が起きます。
たとえば、長い英語の文章を最後まで読んで、最後の1つの情報に全部まとめてから翻訳する…
これはかなり苦しいです。
つまり、「全部を1つに圧縮する」のが限界だったのです。
そこで、Encoder が文章全体をまとめ、Decoder がその情報を使って出力する という形が生まれました。
当時としては大きな進化でした。
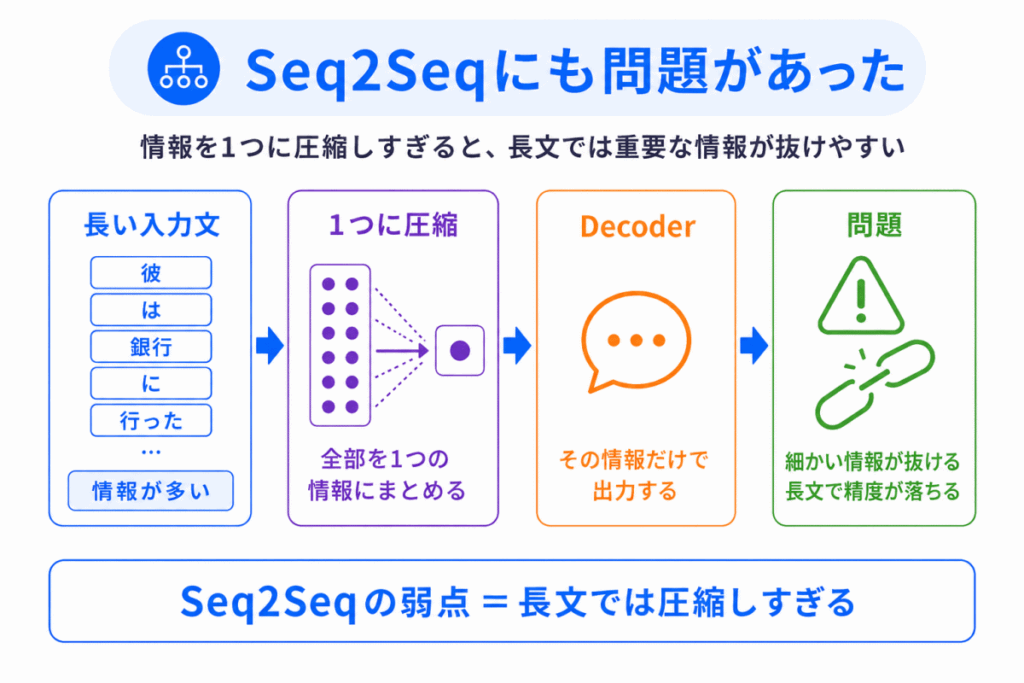
ここが重要です。
Seq2Seqは便利でしたが、実はまだ問題がありました。
それは、情報を最後に1つに圧縮しすぎる という問題です。
例
これは、短い文章ならある程度うまくいきます。
でも、文章が長くなると、最初の情報が抜けたり、細かい情報が失われたりします。
つまり、Encoder・Decoderは進化でしたが、まだ限界がありました。
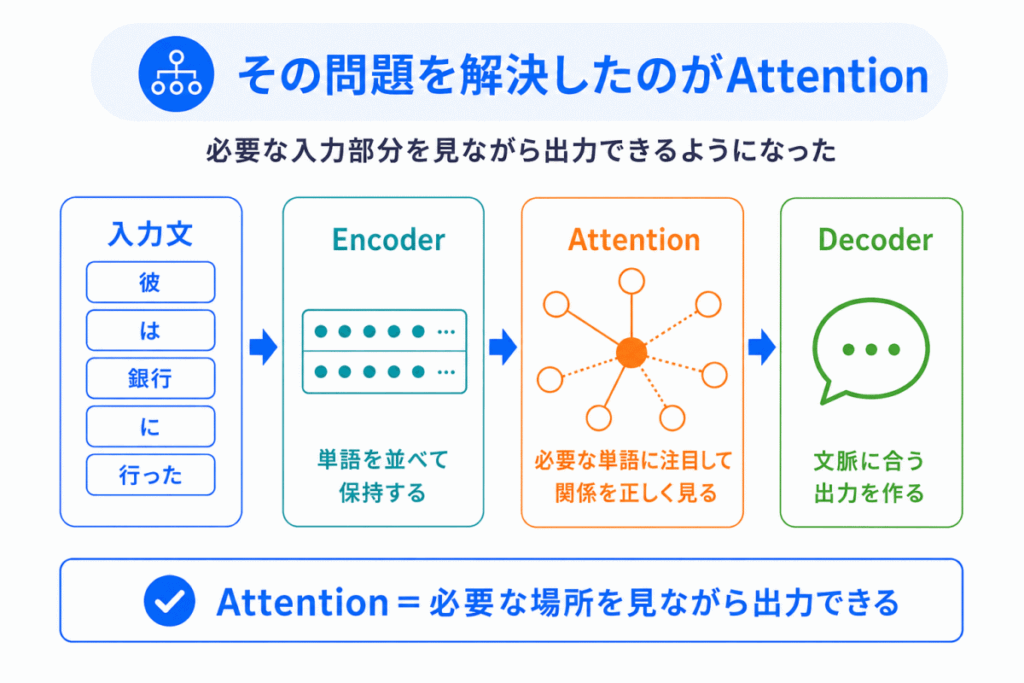
そこで登場したのが、Attention です。
これまでは、Decoderは 最後に圧縮された1つの情報 しか見られませんでした。
しかし、Attentionでは、Decoderが「必要な入力部分を直接見る」ことができるようになりました。
例
翻訳中に
ということが可能になりました。
つまり、圧縮しすぎ問題を改善した のです。
流れでいうと
となります。
これはかなり大きな進化でした。
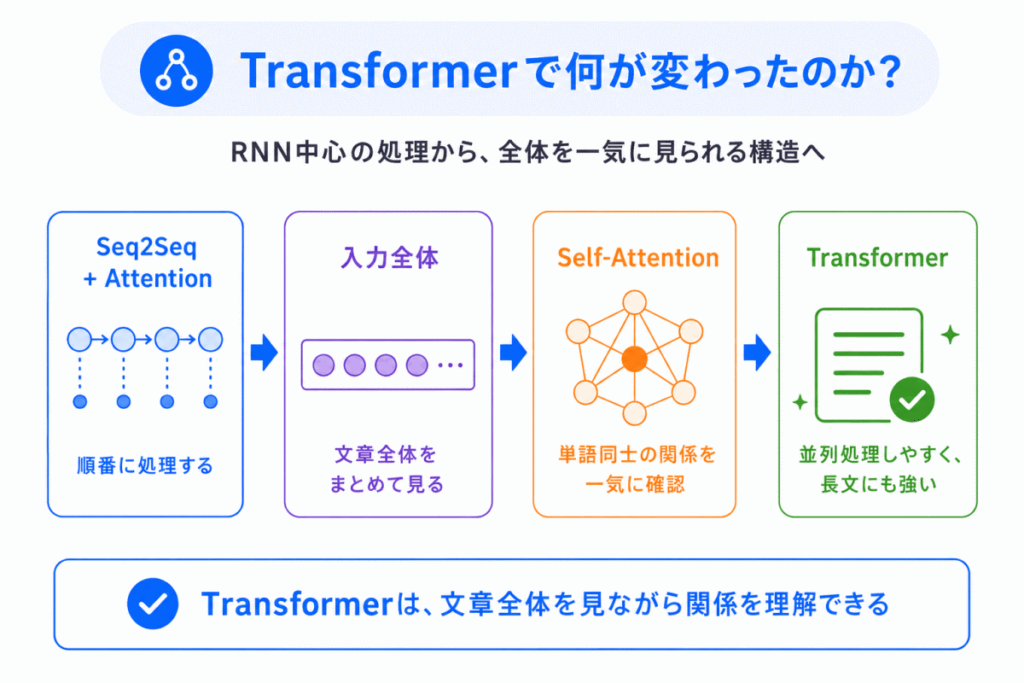
Transformerでは、さらに大きく変わります。
Seq2Seq + Attention では、RNNをベースにしていました。
つまり、前から順番に読む という制約がありました。
しかし、Transformerでは、Self-Attention を使うことで、文章全体を一気に見られるようになりました。
ここで、Transformerの構造は
Encoder:入力全体を理解する
Decoder:出力を生成する
という形になっています。
つまり、Encoder・Decoder自体は残っています。
ただし、中身の仕組みが RNN から Self-Attention に変わった のです。
ここが大事です。
役割は同じだが中身が進化した ということです。
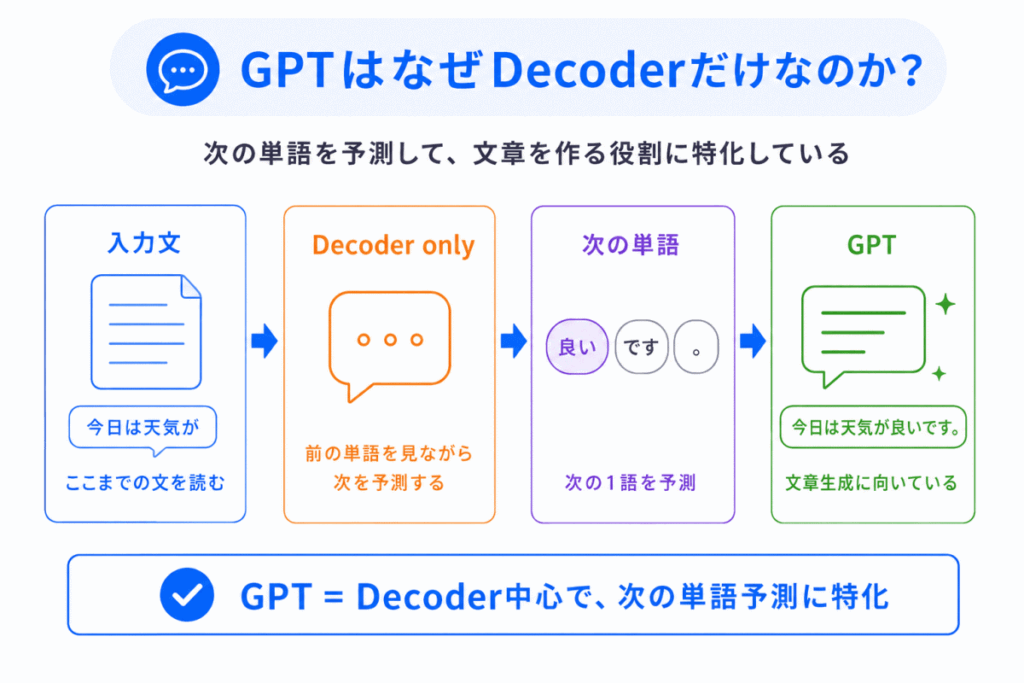
ここもよく問われます。
Transformerは本来
Encoder + Decoder
を持っています。
しかしGPTは、Decoder only です。
なぜかというと、GPTの目的は「文章を生成すること」だからです。
例
この場合、入力を完全に別で圧縮して翻訳するより、今までの文章を見ながら次を生成する 方が重要です。
そのためGPTでは、Decoderだけを強化した形になっています。
つまり
という流れです。
一覧にまとめました。
| 技術 | 構造 | 特徴 |
|---|---|---|
| Seq2Seq | Encoder + Decoder | 最後に情報を圧縮 |
| Seq2Seq + Attention | Encoder + Decoder | 必要な場所を参照できる |
| Transformer | Encoder + Decoder | Self-Attentionで全体を見る |
| GPT | Decoder only | 次の単語生成に特化 |
この流れで覚えると、技術の進化がかなりわかりやすくなります。
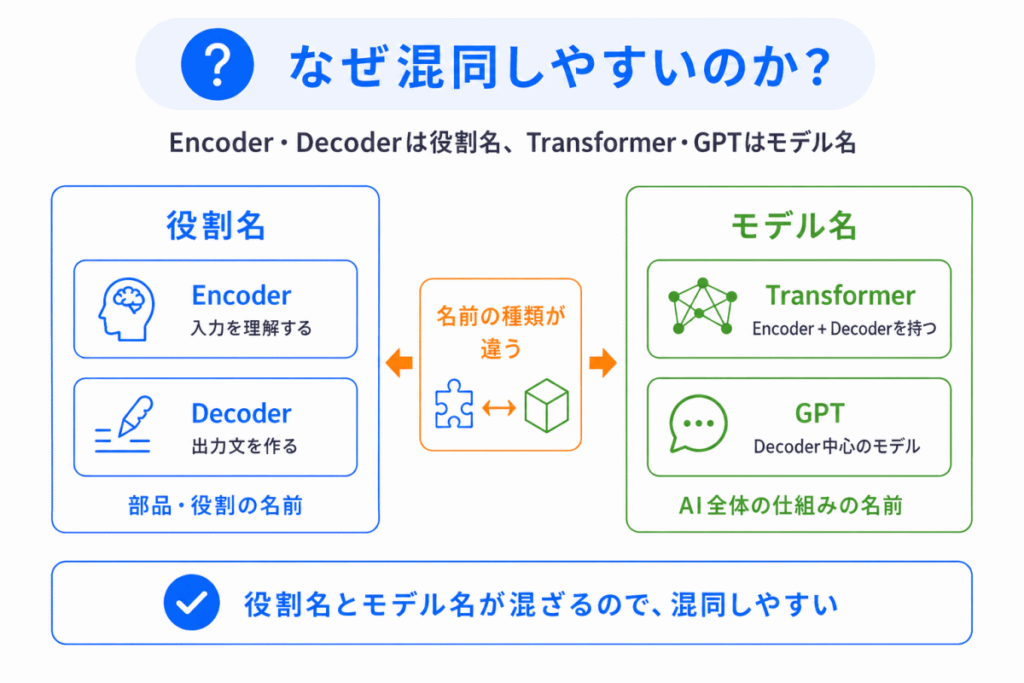
混同しやすい理由は、Encoder・Decoderは役割の名前であり、TransformerやGPTはモデル全体の名前 だからです。
たとえば、「Transformer = Encoder?」ではありません。
Transformerの中に Encoder と Decoder があります。
また
「GPT = Transformer全部?」
でもありません。
GPTは、Transformerの Decoder部分を中心に使ったモデル です。
この 部品名 モデル名 が混ざることで、混同しやすくなります。
G検定では、このような形で問われやすいです。
単語暗記ではなく、技術の流れで理解しておく のがポイントです。
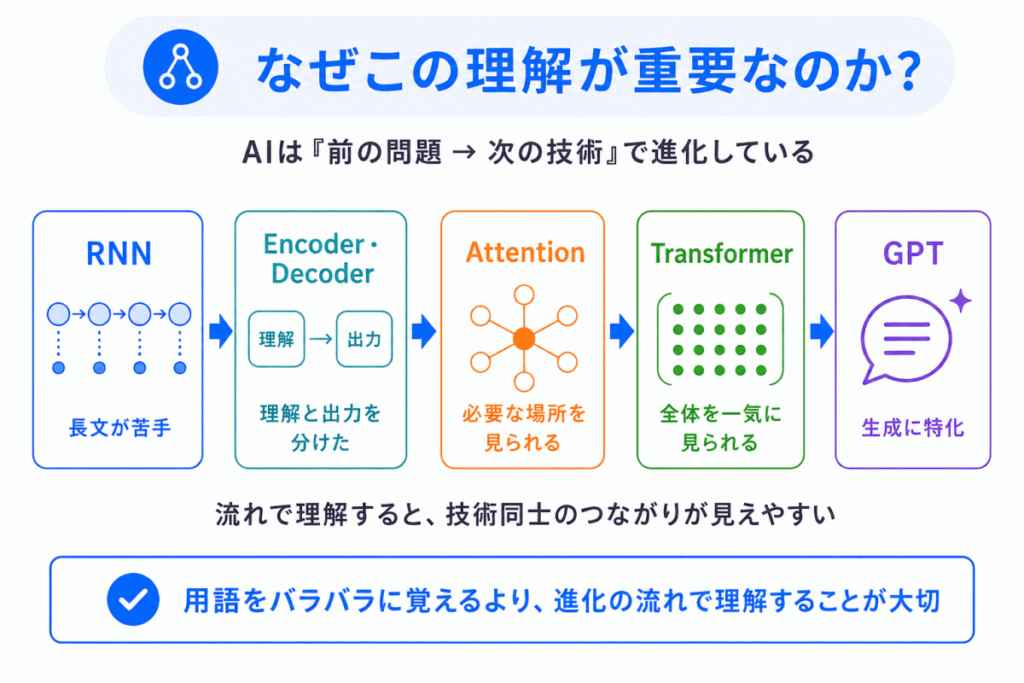
AIの技術は、いきなりTransformerやGPTが生まれたわけではありません。
という流れがあります。
つまり、前の問題 → 次の技術 で進化しています。
Encoder・Decoderは、この進化の真ん中にある非常に重要な技術です。
ここを理解すると、TransformerやGPTもかなり理解しやすくなります。
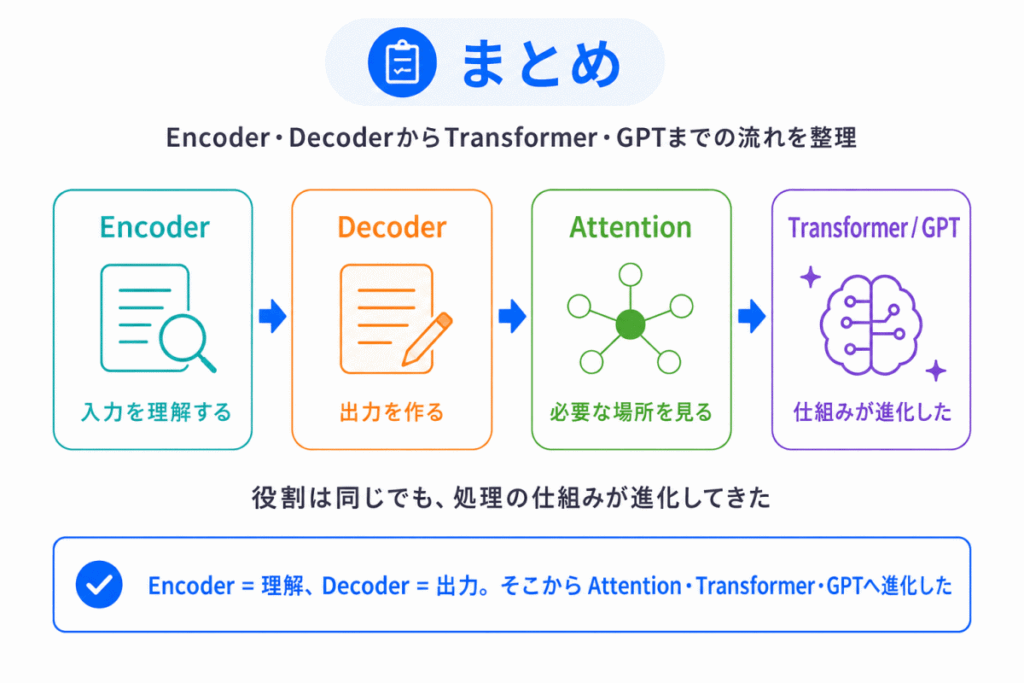
Encoder・Decoderは、AIの文章処理の進化の中で生まれた「理解する」と「出力する」の役割分担 です。
最初はSeq2Seqで、入力をまとめて出力する という形で使われました。
しかし、情報を1つに圧縮しすぎる問題があり、Attention が登場 しました。
さらにTransformerでは、Self-Attentionによって文章全体を一気に見られるようになり、GPT ではDecoderだけを使って文章生成に特化しました。
重要なのは、Encoder・Decoder を単なる用語として覚えるのではなく
で理解することです。
AIは単語暗記ではなく
の流れで理解すると、知識がつながって見えてきます。
Encoder・Decoderは、Seq2Seq、Attention、Transformer、GPT、BERTの流れを理解するうえで重要な考え方です。
関連する記事をあわせて読むと、Transformerの前後で何が変わったのか整理しやすくなります。
| 読む記事 | 確認できる内容 |
|---|---|
| Seq2Seqとは? | Encoder・Decoderの基本構造/Attention登場前の仕組み/系列変換の流れ |
| GPTとは? | GPTの基本/Transformerとの関係/Decoder側の特徴 |
| Transformerとは? | Attentionを中心にした構造/文章全体を見る仕組み/Encoder・Decoderとの関係 |
| BERTとは? | Encoder側の特徴/GPTとの違い/文章理解モデルの位置づけ |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。