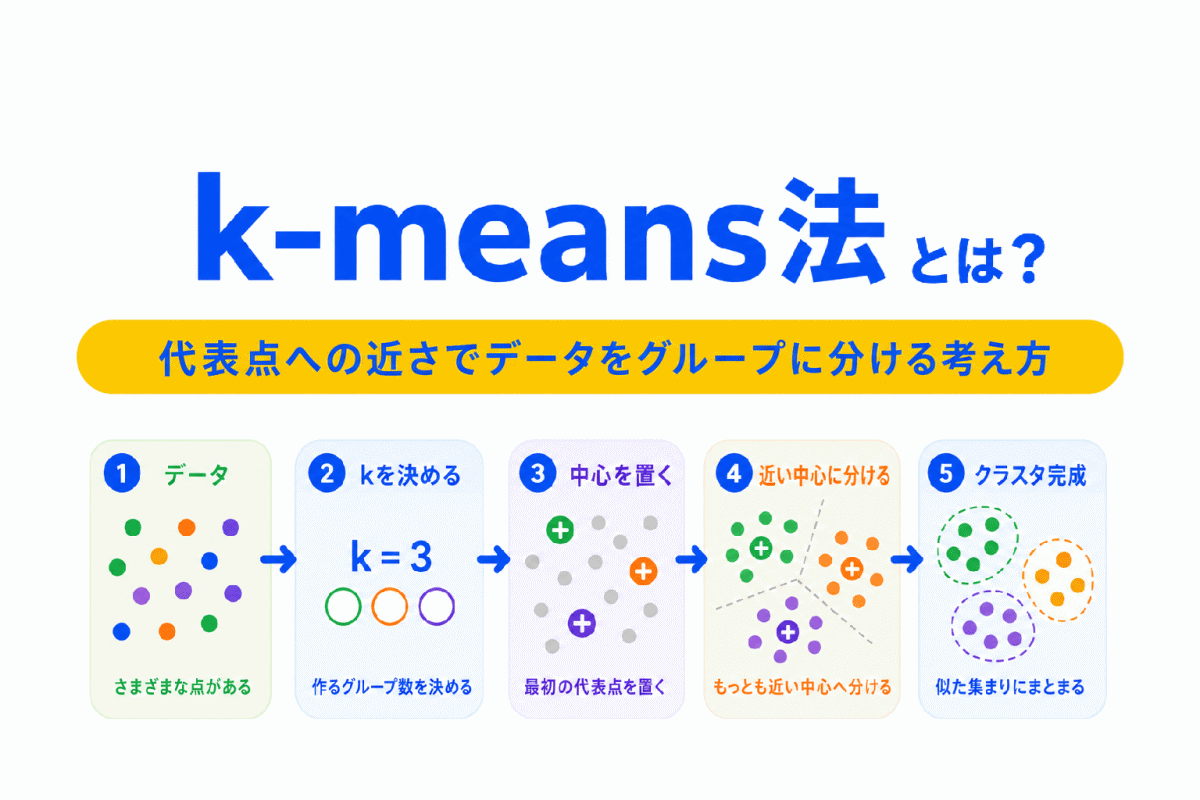
【G検定対策】k-means法とは?|似たデータを代表点に近いグループへ分ける考え方を整理
seo-webmaster
G検定対策ブログ

正則化は、過学習を防ぐために重要な考え方です。
AIは学習データに合わせすぎると、学習データではよく当たっても、新しいデータに弱くなることがあります。
そこで、モデルが複雑になりすぎないように制約を加えるのが正則化です。
この記事では、正則化の基本イメージから、L1正則化・L2正則化・ドロップアウトとの関係まで、G検定で混同しやすいポイントを中心に整理します。
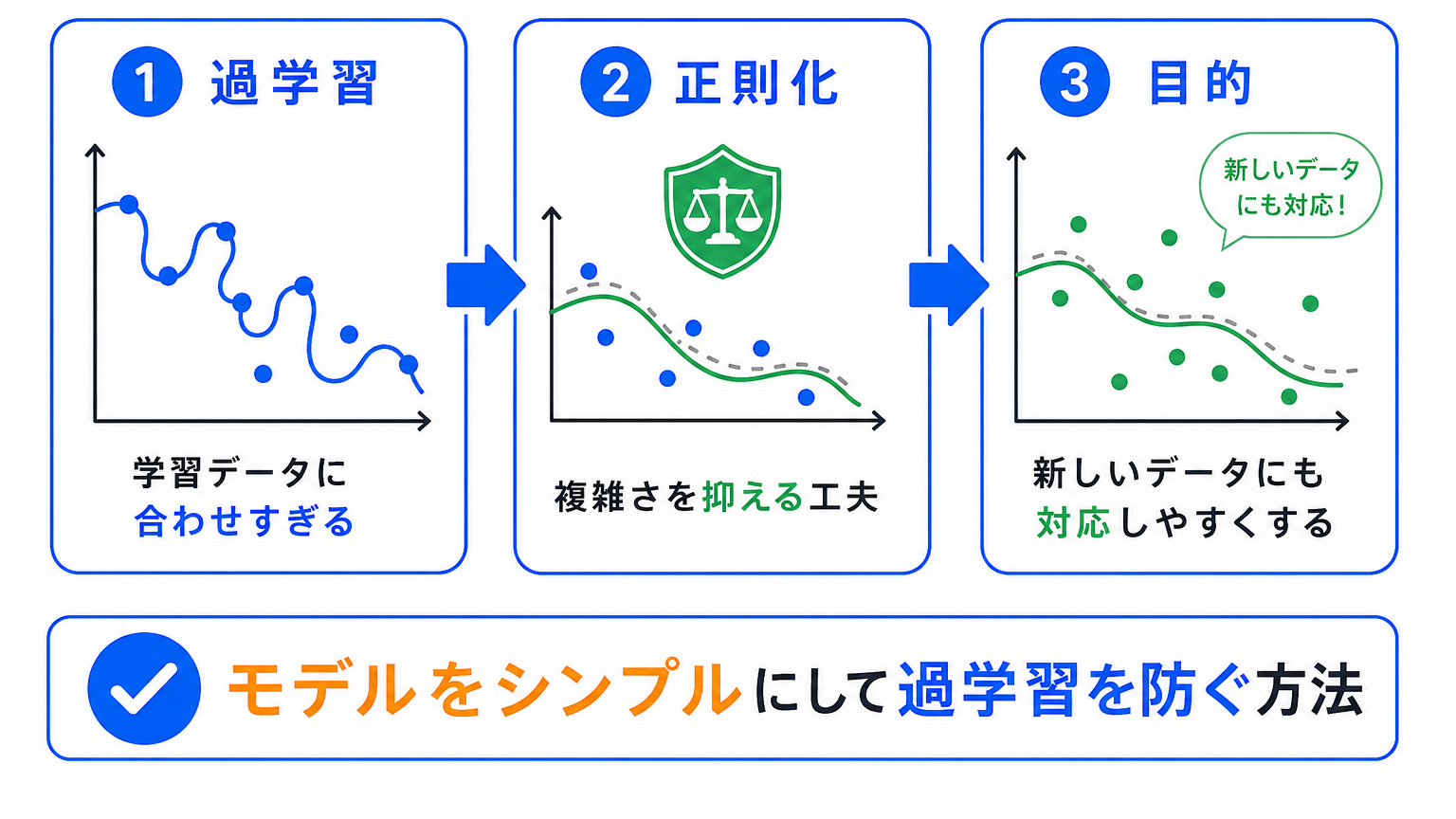
正則化とは、モデルが複雑になりすぎないようにして、過学習を防ぐ工夫です。
AIは、学習データに細かく合わせすぎると、新しいデータに対応しにくくなります。
正則化は、その「合わせすぎ」を抑えるために使われます。
| 用語 | 一言でいうと |
|---|---|
| 過学習 | 学習データに合わせすぎた状態 |
| 正則化 | モデルの複雑さを抑える工夫 |
| 汎化性能 | 新しいデータにも対応する力 |
正則化は、精度を直接上げる魔法の方法ではありません。
学習データだけに合わせすぎず、新しいデータにも対応しやすくするための考え方です。
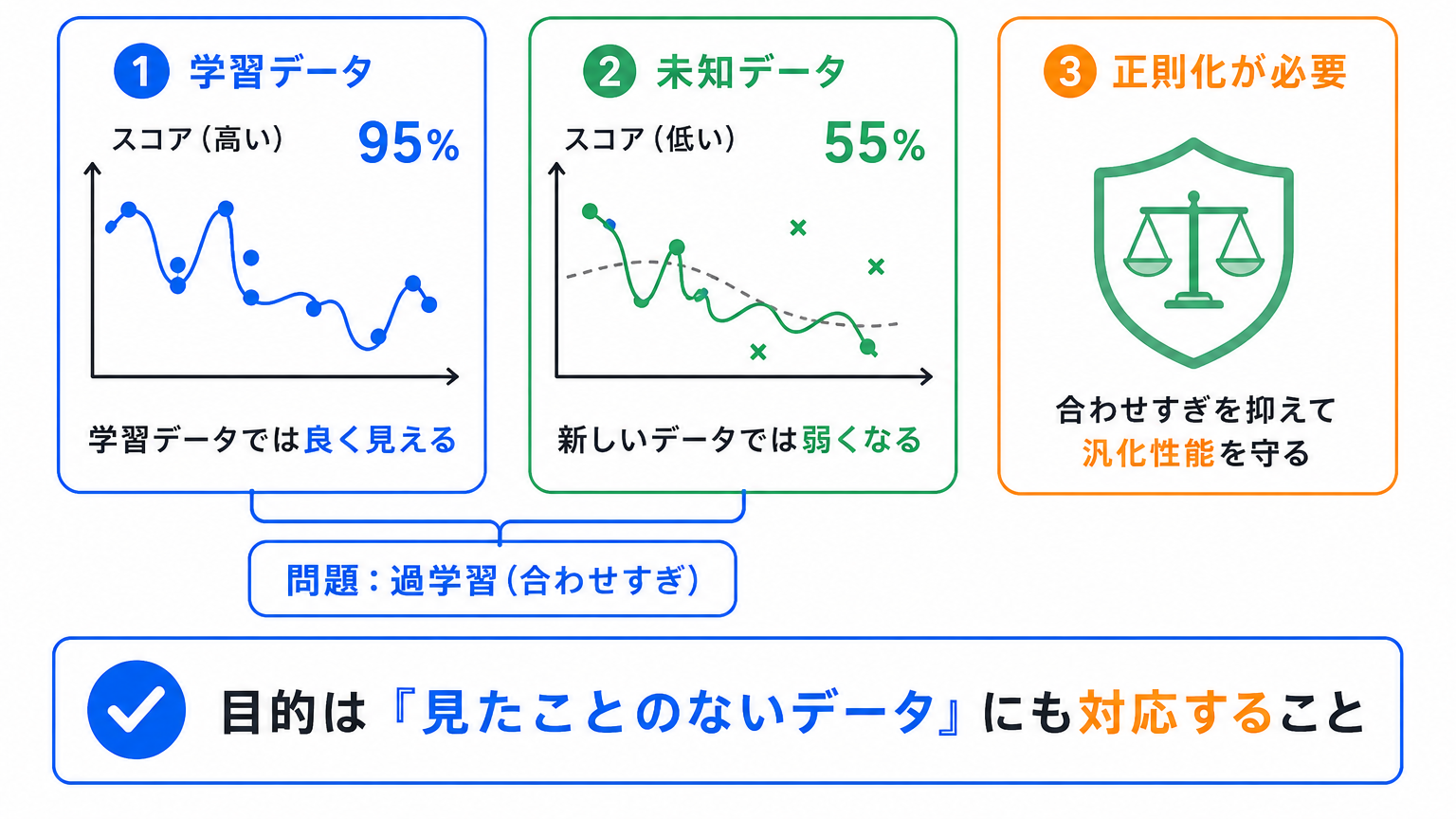
正則化が必要なのは、AIの目的が「学習データで正解すること」だけではないからです。
本当に大切なのは、まだ見たことのないデータにも対応できることです。
| 状態 | 学習データ | 新しいデータ |
|---|---|---|
| 学習不足 | 弱い | 弱い |
| ちょうどよい学習 | 強い | 強い |
| 過学習 | 強い | 弱い |
過学習しているモデルは、学習データでは高い精度に見えます。
しかし、新しいデータに弱い場合、実際に使う場面ではうまく働きません。
正則化は、モデルが学習データに合わせすぎるのを抑え、汎化性能を高めやすくするための工夫 です。
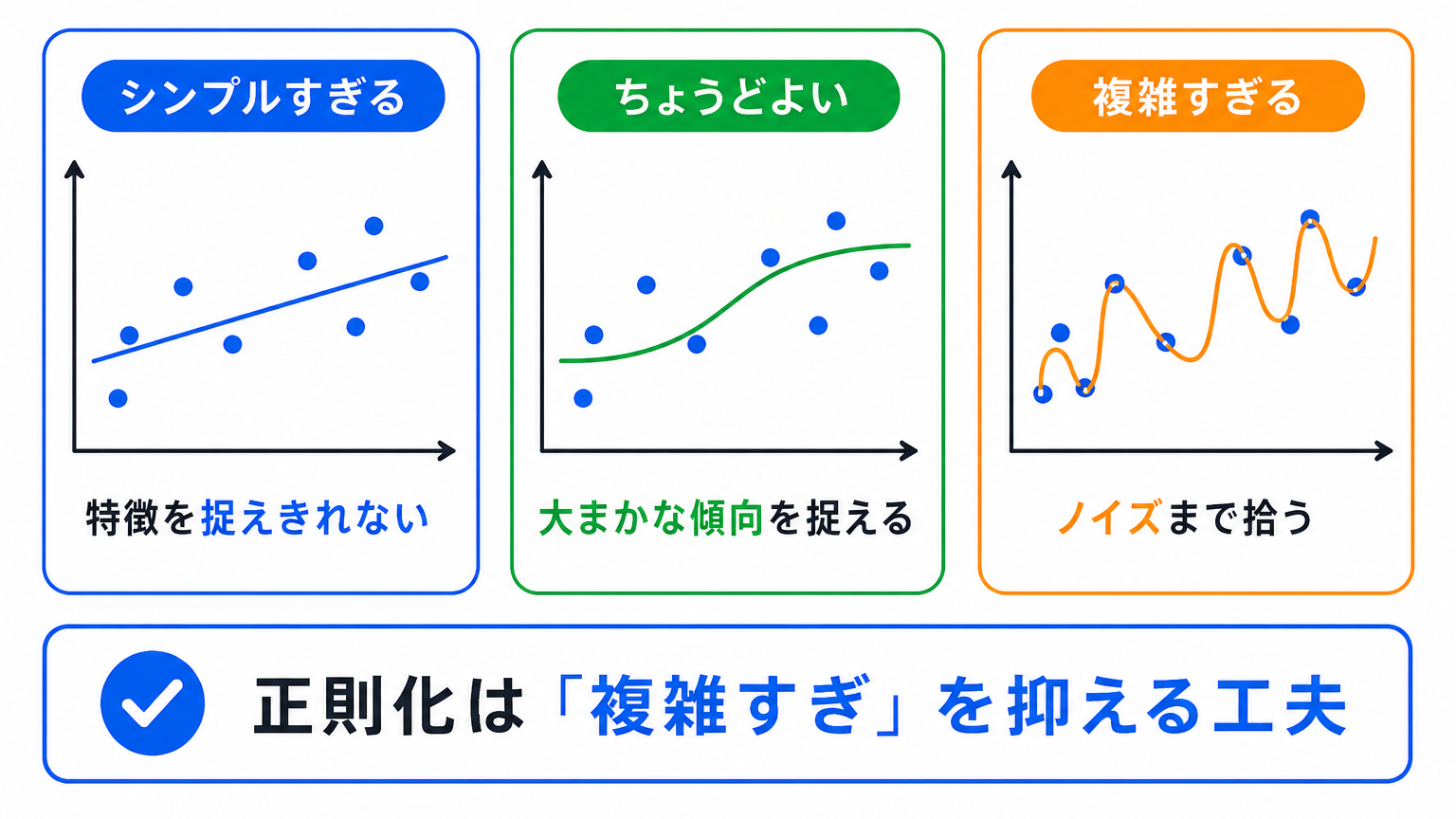
正則化は、モデルをシンプルに保つための考え方です。
たとえば、データに対して線を引くとします。
| モデルの状態 | イメージ |
|---|---|
| シンプルすぎる | データの特徴を十分に捉えられない |
| ちょうどよい | 大まかな傾向を捉えられる |
| 複雑すぎる | 細かいノイズまで拾ってしまう |
複雑すぎるモデルは、学習データの細かい特徴まで覚えてしまいやすくなります。
正則化は、そうした複雑すぎるモデルにならないように調整します。
つまり、細かい例外をすべて覚えるのではなく、大まかなパターンを学びやすくするための工夫 です。
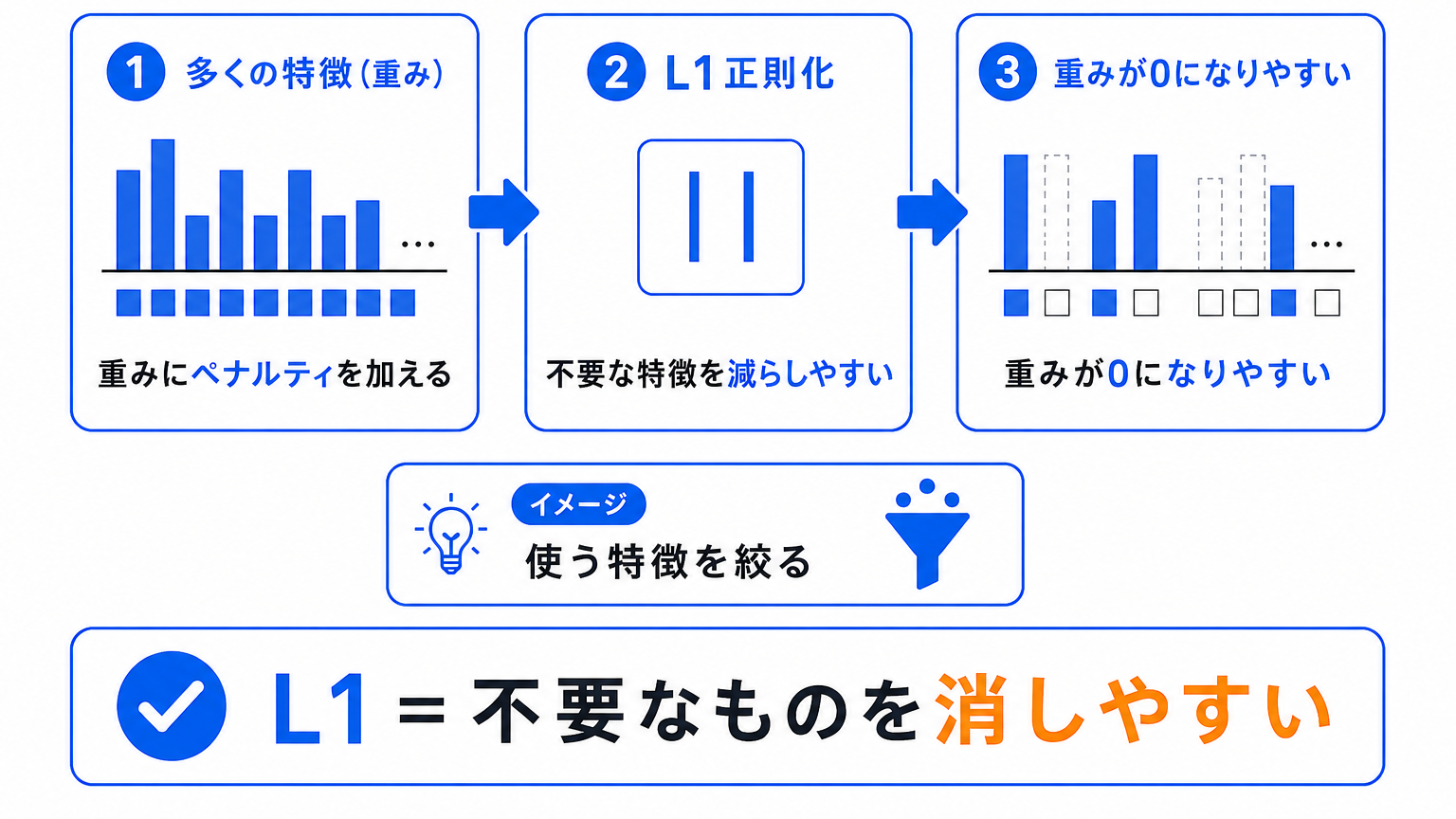
L1正則化は、重みの絶対値の合計にペナルティを加える方法です。
少し難しく見えますが、G検定対策では次のように押さえると分かりやすいです。
L1正則化は、不要な特徴の重みを0に近づけやすい方法 です。
そのため、使う特徴を減らし、モデルをシンプルにしやすい特徴があります。
| 項目 | L1正則化 |
|---|---|
| 何をするか | 重みにペナルティを加える |
| 特徴 | 不要な特徴を0にしやすい |
| イメージ | 使う特徴を絞る |
L1正則化は、たくさんある特徴の中から、重要なものを残したいときに関係します。
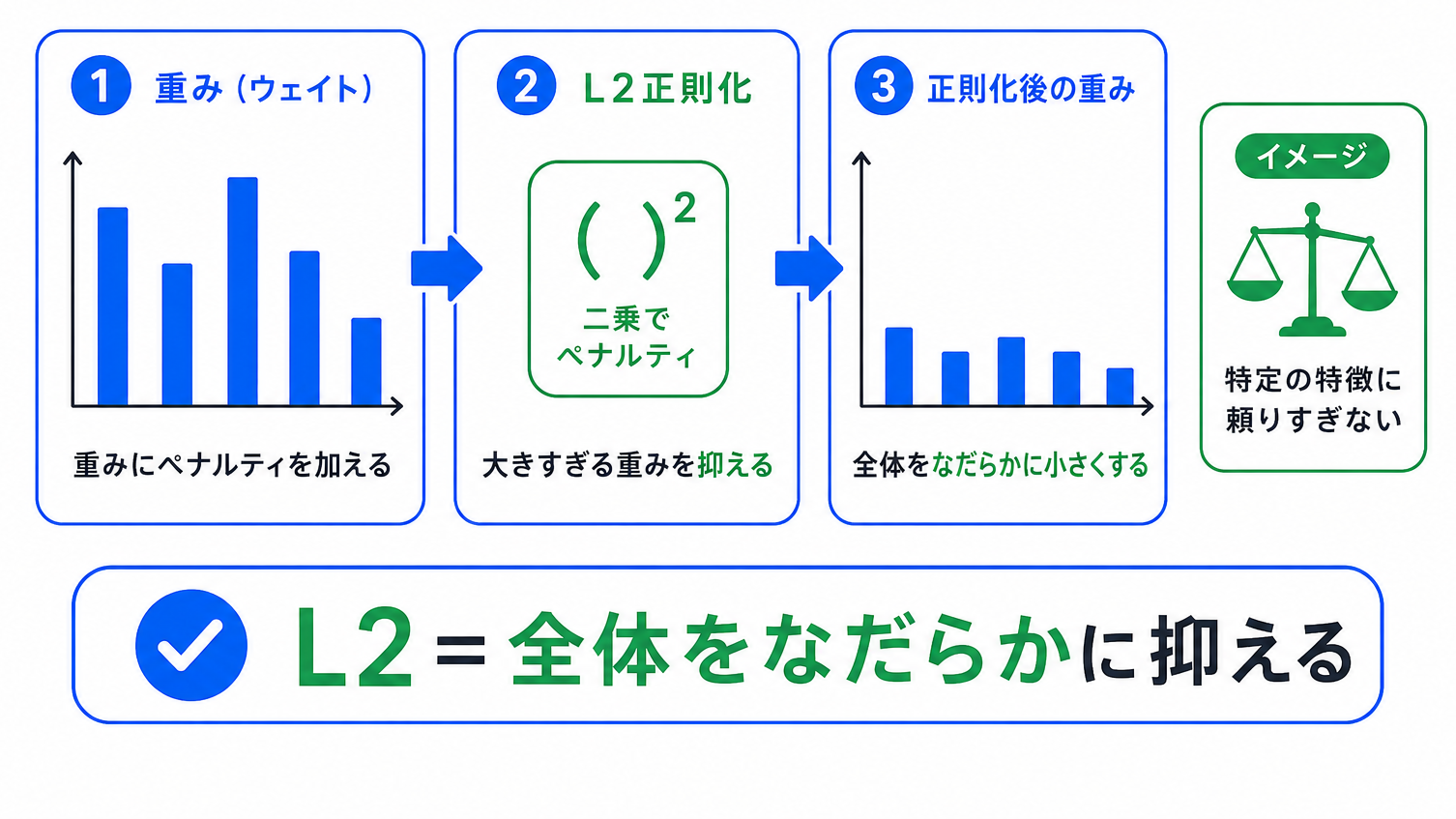
L2正則化は、重みの二乗和にペナルティを加える方法です。
G検定対策では、次のように押さえると分かりやすいです。
L2正則化は、重みが大きくなりすぎるのを全体的に抑える方法 です。
L1正則化のように一部の重みを0にしやすいというより、全体の重みをなだらかに小さくするイメージです。
| 項目 | L2正則化 |
|---|---|
| 何をするか | 重みにペナルティを加える |
| 特徴 | 大きすぎる重みを抑える |
| イメージ | 全体をなだらかに抑える |
L2正則化は、特定の特徴に頼りすぎないようにするための工夫として整理できます。
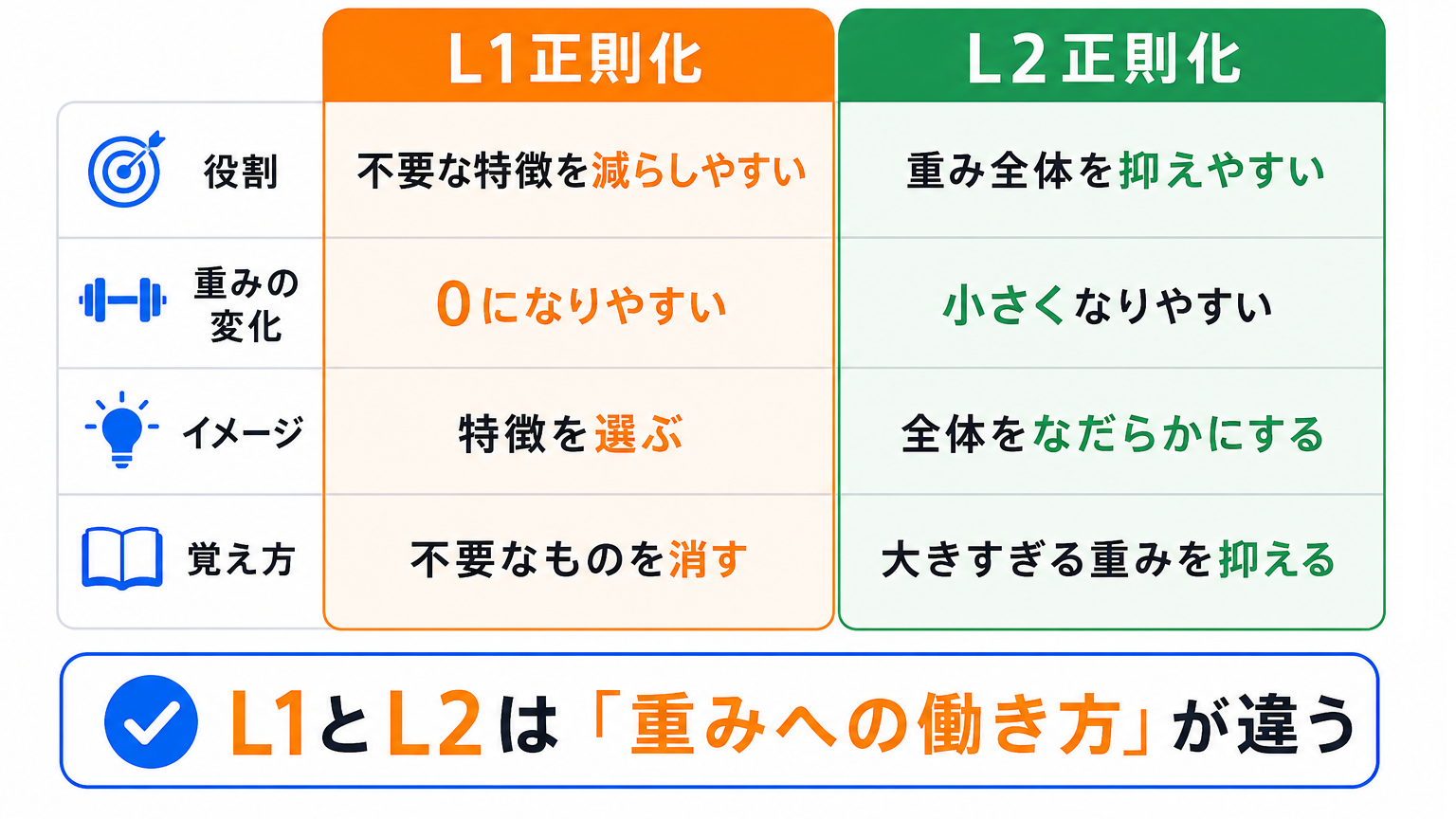
L1正則化とL2正則化は、どちらも過学習を防ぐために使われます。
違いは、重みへの働き方です。
| 比較 | L1正則化 | L2正則化 |
|---|---|---|
| 役割 | 不要な特徴を減らしやすい | 重み全体を抑えやすい |
| 重みの変化 | 0になりやすい | 小さくなりやすい |
| イメージ | 特徴を選ぶ | 全体をなだらかにする |
| 覚え方 | 不要なものを消す | 大きすぎる重みを抑える |
ざっくり覚えるなら
です。
G検定では、数式を細かく覚えるよりも、この違いを整理しておく方が重要です。
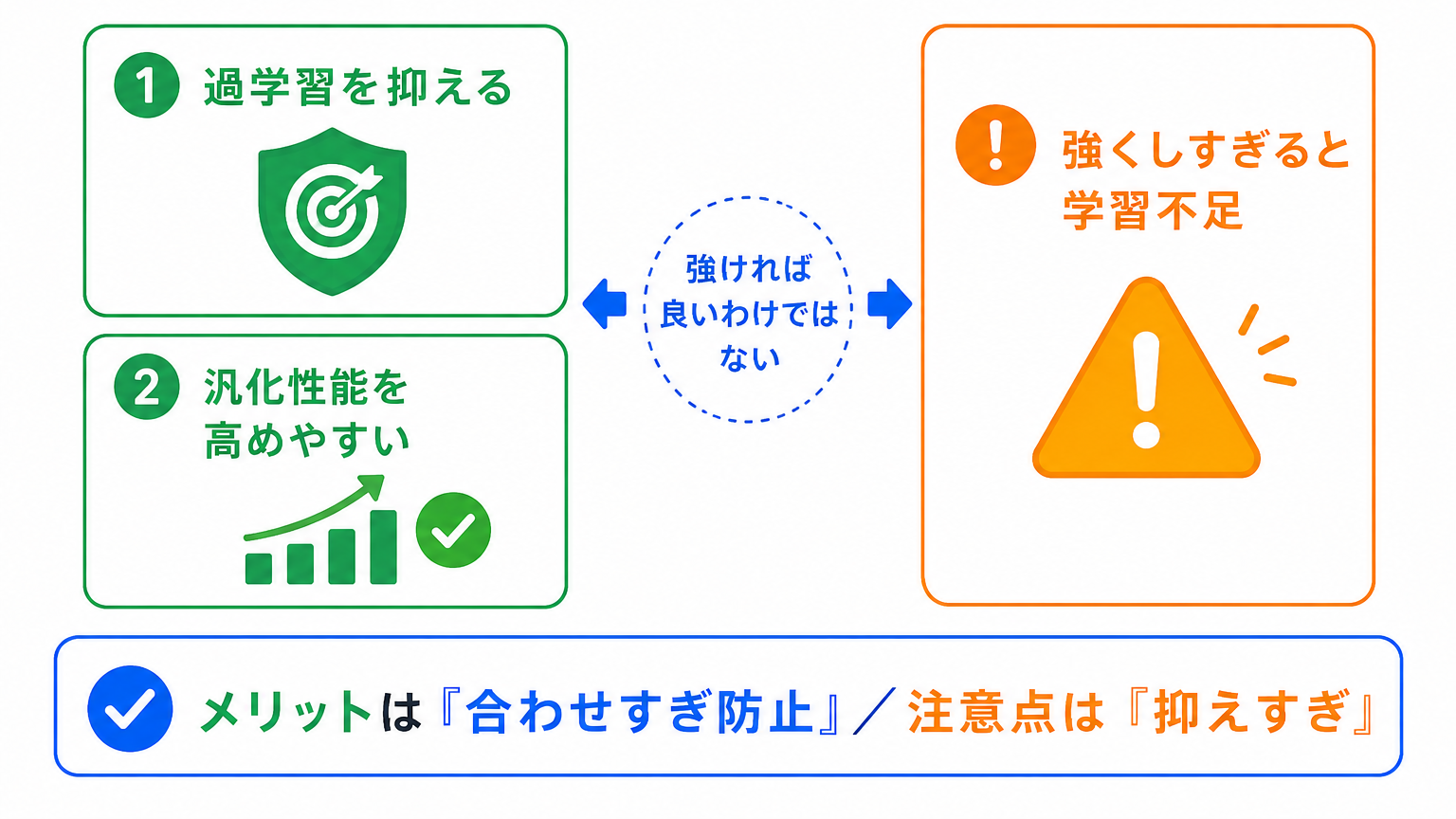
正則化のメリットは、過学習を抑えやすくなることです。
モデルが学習データに合わせすぎるのを防ぎ、新しいデータにも対応しやすくなります。
| メリット | 内容 |
|---|---|
| 過学習を抑える | 学習データに合わせすぎるのを防ぐ |
| 汎化性能を高めやすい | 新しいデータに対応しやすくする |
| モデルをシンプルにしやすい | 複雑になりすぎるのを抑える |
ただし、正則化を強くしすぎると、モデルが十分に学習できなくなることがあります。
つまり、過学習を防ぐつもりが、今度は学習不足になる可能性があります。
正則化は、強ければ強いほど良いというものではありません。
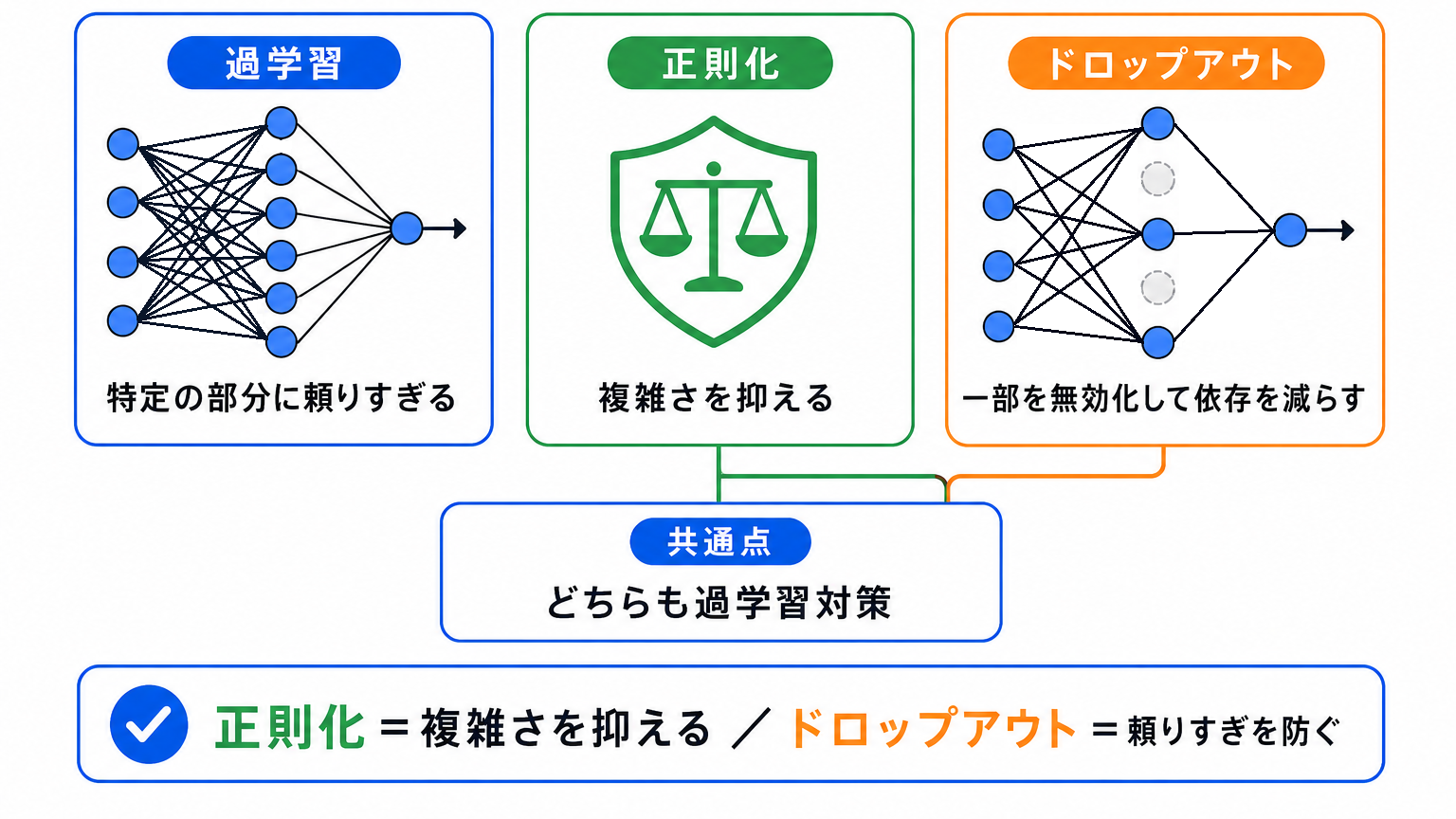
ドロップアウトも、過学習を防ぐための方法です。
ニューラルネットワークの一部のニューロンを、一時的に使わないようにして学習します。
これにより、特定のニューロンに頼りすぎることを防ぎます。
| 用語 | 役割 |
|---|---|
| 正則化 | モデルが複雑になりすぎるのを抑える |
| ドロップアウト | 一部のニューロンへの依存を減らす |
| 共通点 | どちらも過学習対策 |
正則化とドロップアウトは、まったく同じものではありません。
ただし、どちらも学習データに合わせすぎるのを防ぐための工夫として整理できます。
正則化、正規化、標準化は名前が似ていますが、役割は違います。
正則化はモデル側の調整、正規化と標準化はデータ側の前処理として整理すると理解しやすくなります。
| 用語 | 意味 | 見分け方 |
|---|---|---|
| 正則化 | モデルが複雑になりすぎないようにして、過学習を防ぐ考え方 | モデル側を調整する |
| 正規化 | データの値の範囲を、0〜1など一定の範囲にそろえる前処理 | 値の範囲をそろえる |
| 標準化 | 平均や標準偏差を使って、データのスケールをそろえる前処理 | 平均0、標準偏差1に近づける |
G検定では、正則化は過学習とセットで問われやすいです。
| 問われやすい内容 | 押さえるポイント |
|---|---|
| 正則化の目的 | 過学習を防ぐ |
| 正則化のイメージ | モデルの複雑さを抑える |
| L1正則化 | 不要な特徴を0にしやすい |
| L2正則化 | 大きすぎる重みを抑える |
| ドロップアウトとの関係 | どちらも過学習対策 |
特に注意したいのは、次のような誤解です。
| 誤解しやすい表現 | 正しい整理 |
|---|---|
| 正則化はモデルを複雑にする方法 | 複雑になりすぎるのを抑える方法 |
| 正則化は学習データの精度だけを上げる方法 | 未知データへの対応を意識した工夫 |
| L1とL2は同じ働きをする | 重みへの働き方が違う |
| ドロップアウトと正則化は完全に同じ | どちらも過学習対策だが方法は違う |
問題文で
といった言葉が出てきたら、正則化との関係を意識すると整理しやすくなります。
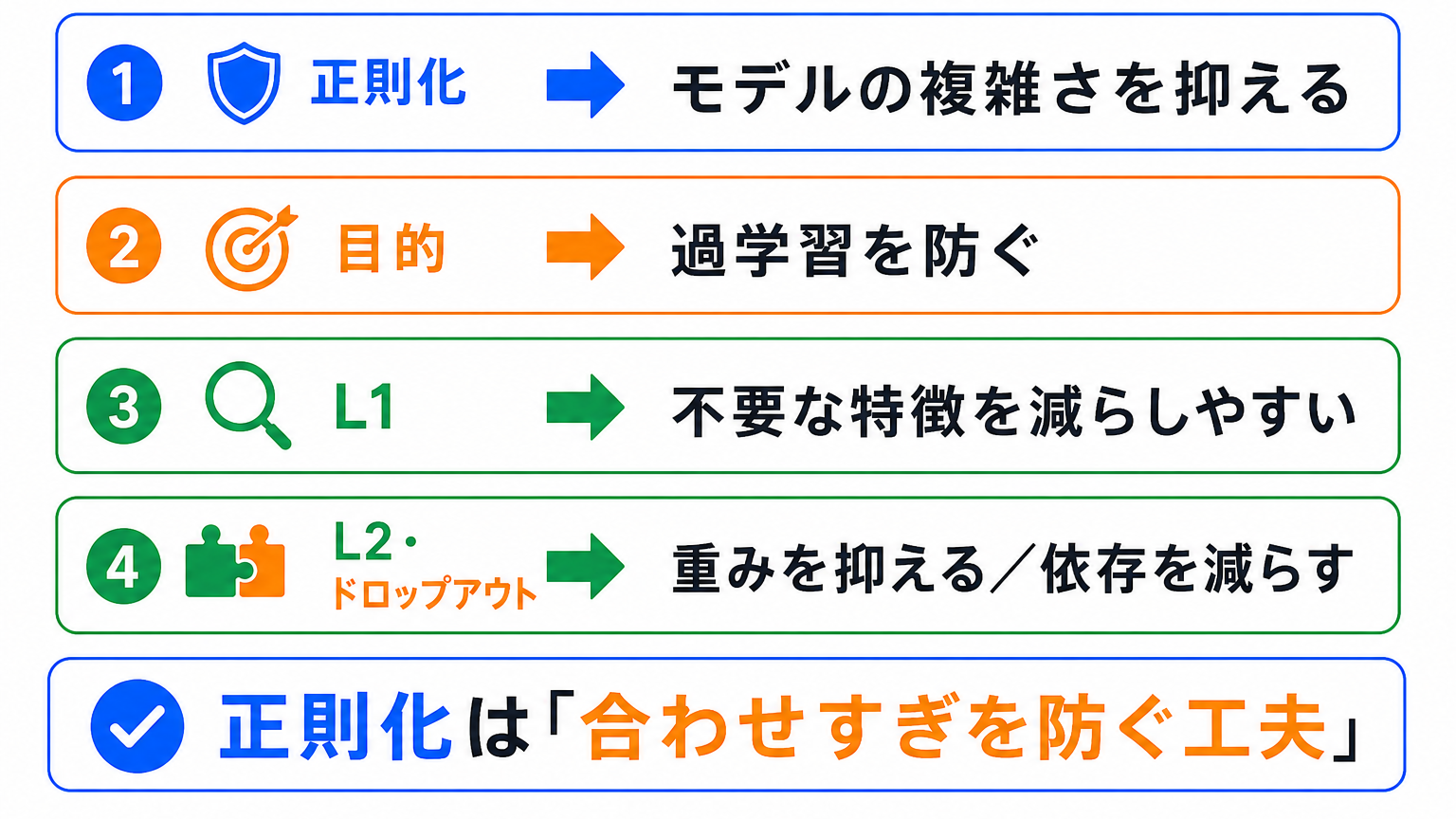
正則化とは、モデルが複雑になりすぎないようにして、過学習を防ぐための工夫です。
AIは、学習データに合わせすぎると、新しいデータに弱くなることがあります。
正則化は、その「合わせすぎ」を抑え、汎化性能を高めやすくするために使われます。
最後に整理すると、次のようになります。
| 用語 | 一言でいうと |
|---|---|
| 正則化 | モデルの複雑さを抑える工夫 |
| 過学習 | 学習データに合わせすぎた状態 |
| L1正則化 | 不要な特徴を0にしやすい |
| L2正則化 | 大きすぎる重みを全体的に抑える |
| ドロップアウト | 一部のニューロンへの依存を減らす |
| 汎化性能 | 新しいデータにも対応する力 |
G検定では、正則化を単独で覚えるよりも、過学習・汎化性能・L1正則化・L2正則化・ドロップアウトとつなげて理解しておくことが大切です。
正則化は、モデルが学習データに合わせすぎるのを防ぐための重要な考え方です。
ドロップアウト、バイアスと分散、重み、過学習対策の予想問題まであわせて確認しておくと整理しやすくなります。
| おすすめ記事 | 確認できる内容 |
|---|---|
| ドロップアウトとは? | 一部のノードを無効化する学習/過学習対策/正則化との関係 |
| バイアスと分散とは? | 未学習・過学習の原因/モデルの複雑さとの関係/汎化性能の見方 |
| 重みとは? | どの情報を重要視するか/重みを調整する流れ/正則化との関係 |
| 過学習・正則化・ドロップアウト予想問題 | 混同しやすい用語の確認/引っかけポイント/理解型の問題演習 |
| 正規化・正則化の違い予想問題 | 正規化/正則化/過学習対策/正規化層 |
G検定で重要な用語をチェックシートとしてまとめました。
G検定で混同しやすい用語をチェックシートとしてまとめました。
公式テキスト

Amazonで確認
楽天市場で確認
合格時に使用した問題集

Amazonで確認
楽天市場で確認
※:1回目の受験の際、定番と言われている黒い問題集も購入しましたが、本番とは乖離している印象でした。